 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
6DoF Object Pose Estimation via Differentiable Proxy Voting Loss
Feb 10, 2020
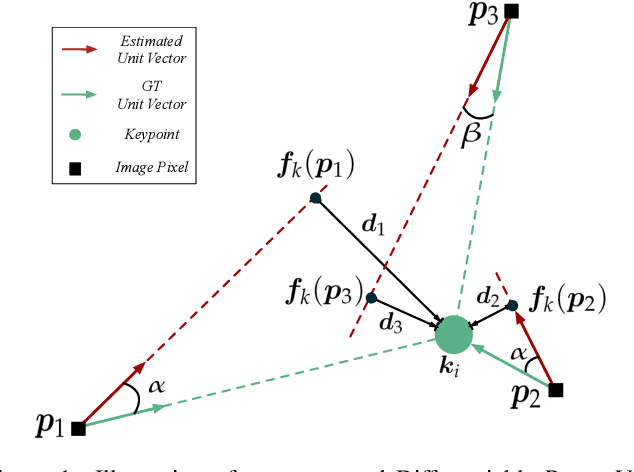
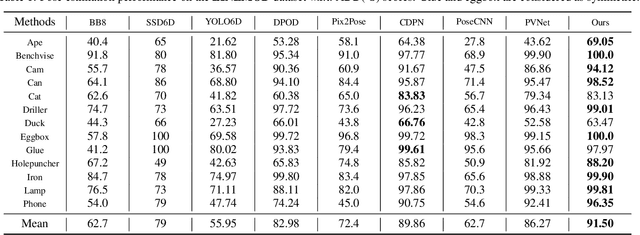
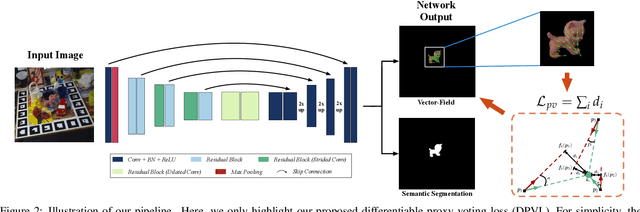
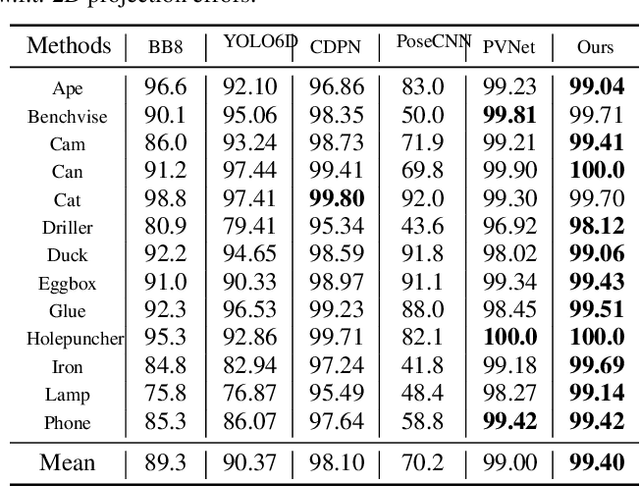
Estimating a 6DOF object pose from a single image is very challenging due to occlusions or textureless appearances. Vector-field based keypoint voting has demonstrated its effectiveness and superiority on tackling those issues. However, direct regression of vector-fields neglects that the distances between pixels and keypoints also affect the deviations of hypotheses dramatically. In other words, small errors in direction vectors may generate severely deviated hypotheses when pixels are far away from a keypoint. In this paper, we aim to reduce such errors by incorporating the distances between pixels and keypoints into our objective. To this end, we develop a simple yet effective differentiable proxy voting loss (DPVL) which mimics the hypothesis selection in the voting procedure. By exploiting our voting loss, we are able to train our network in an end-to-end manner. Experiments on widely used datasets, i.e. LINEMOD and Occlusion LINEMOD, manifest that our DPVL improves pose estimation performance significantly and speeds up the training convergence.
Relationship-Aware Spatial Perception Fusion for Realistic Scene Layout Generation
Sep 02, 2019
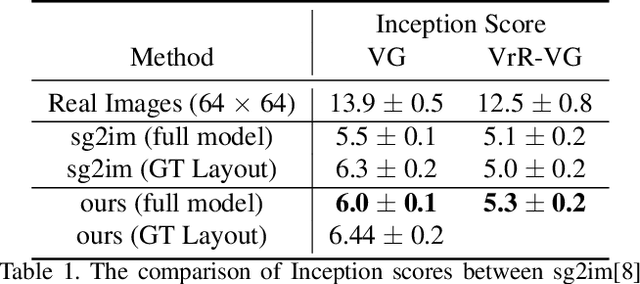
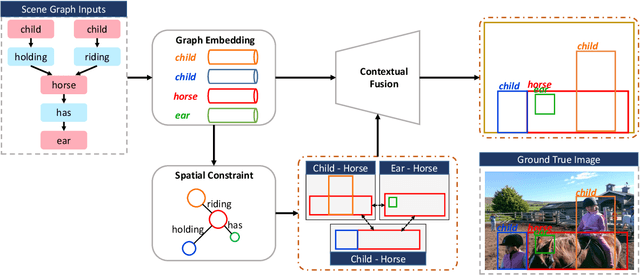
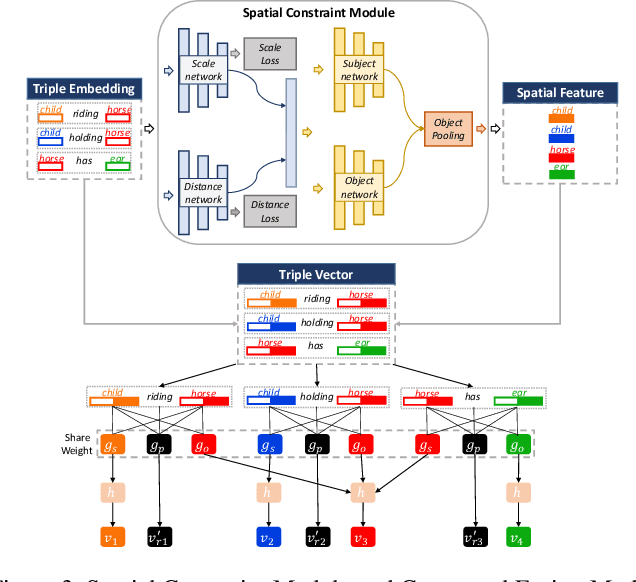
The significant progress on Generative Adversarial Networks (GANs) have made it possible to generate surprisingly realistic images for single object based on natural language descriptions. However, controlled generation of images for multiple entities with explicit interactions is still difficult to achieve due to the scene layout generation heavily suffer from the diversity object scaling and spatial locations. In this paper, we proposed a novel framework for generating realistic image layout from textual scene graphs. In our framework, a spatial constraint module is designed to fit reasonable scaling and spatial layout of object pairs with considering relationship between them. Moreover, a contextual fusion module is introduced for fusing pair-wise spatial information in terms of object dependency in scene graph. By using these two modules, our proposed framework tends to generate more commonsense layout which is helpful for realistic image generation. Experimental results including quantitative results, qualitative results and user studies on two different scene graph datasets demonstrate our proposed framework's ability to generate complex and logical layout with multiple objects from scene graph.
Is This The Right Place? Geometric-Semantic Pose Verification for Indoor Visual Localization
Sep 02, 2019
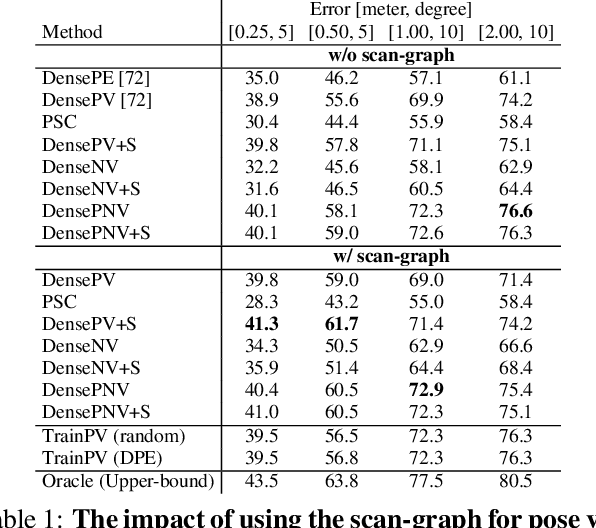
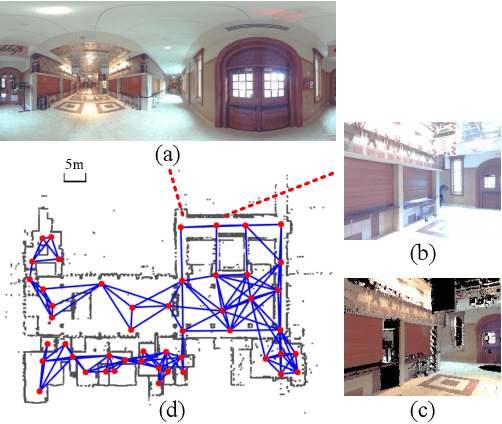
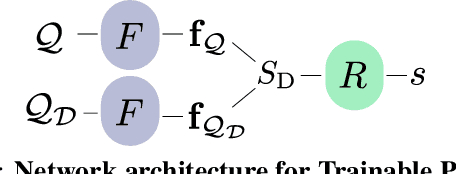
Visual localization in large and complex indoor scenes, dominated by weakly textured rooms and repeating geometric patterns, is a challenging problem with high practical relevance for applications such as Augmented Reality and robotics. To handle the ambiguities arising in this scenario, a common strategy is, first, to generate multiple estimates for the camera pose from which a given query image was taken. The pose with the largest geometric consistency with the query image, e.g., in the form of an inlier count, is then selected in a second stage. While a significant amount of research has concentrated on the first stage, there is considerably less work on the second stage. In this paper, we thus focus on pose verification. We show that combining different modalities, namely appearance, geometry, and semantics, considerably boosts pose verification and consequently pose accuracy. We develop multiple hand-crafted as well as a trainable approach to join into the geometric-semantic verification and show significant improvements over state-of-the-art on a very challenging indoor dataset.
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Feb 10, 2020
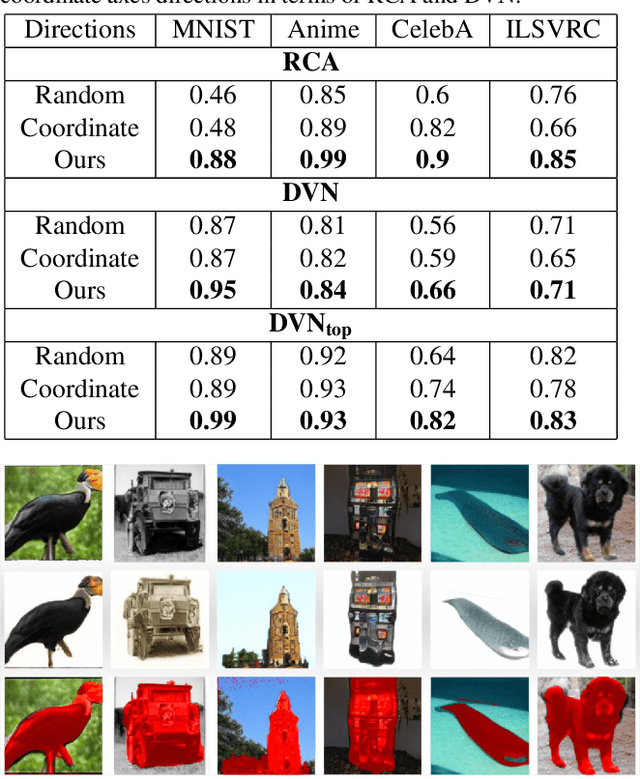


The latent spaces of typical GAN models often have semantically meaningful directions. Moving in these directions corresponds to human-interpretable image transformations, such as zooming or recoloring, enabling a more controllable generation process. However, the discovery of such directions is currently performed in a supervised manner, requiring human labels, pretrained models, or some form of self-supervision. These requirements can severely limit a range of directions existing approaches can discover. In this paper, we introduce an unsupervised method to identify interpretable directions in the latent space of a pretrained GAN model. By a simple model-agnostic procedure, we find directions corresponding to sensible semantic manipulations without any form of (self-)supervision. Furthermore, we reveal several non-trivial findings, which would be difficult to obtain by existing methods, e.g., a direction corresponding to background removal. As an immediate practical benefit of our work, we show how to exploit this finding to achieve a new state-of-the-art for the problem of saliency detection.
Detecting and Recovering Adversarial Examples: An Input Sensitivity Guided Method
Feb 28, 2020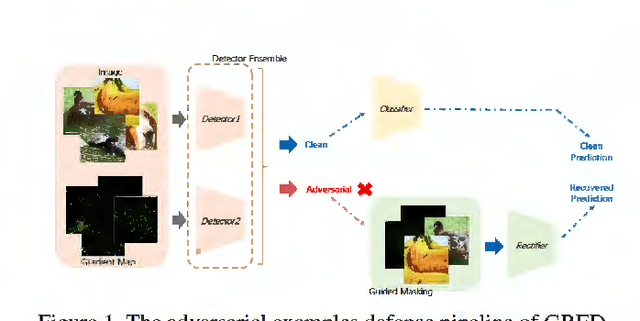
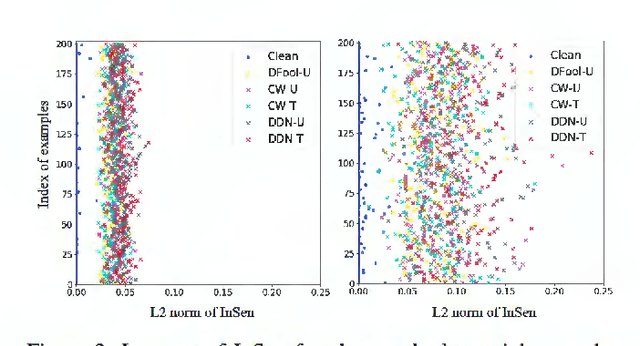
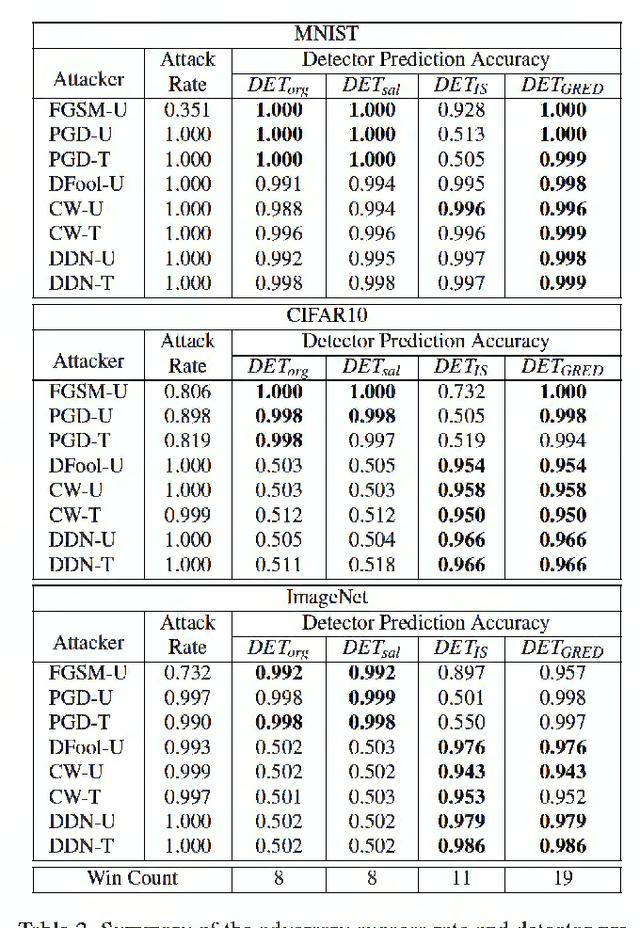
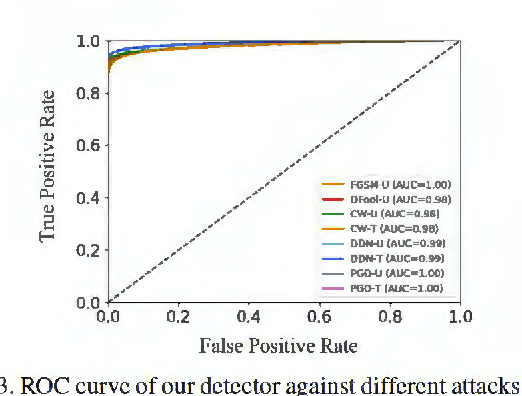
Deep neural networks undergo rapid development and achieve notable success in various tasks, including many security concerned scenarios. However, a considerable amount of works have proved its vulnerability in adversaries. To address this problem, we propose a Guided Robust and Efficient Defensive Model GRED integrating detection and recovery processes together. From the lens of the properties of gradient distribution of adversarial examples, our model detects malicious inputs effectively, as well as recovering the ground-truth label with high accuracy. Compared with commonly used adversarial training methods, our model is more efficient and outperforms state-of-the-art adversarial trained models by a large margin up to 99% on MNIST, 89 % on CIFAR-10 and 87% on ImageNet subsets. When exclusively compared with previous adversarial detection methods, the detector of GRED is robust under all threat settings with a detection rate of over 95% against most of the attacks. It is also demonstrated by empirical assessment that our model could increase attacking cost significantly resulting in either unacceptable time consuming or human perceptible image distortions.
The algorithm of the impulse noise filtration in images based on an algorithm of community detection in graphs
Dec 25, 2018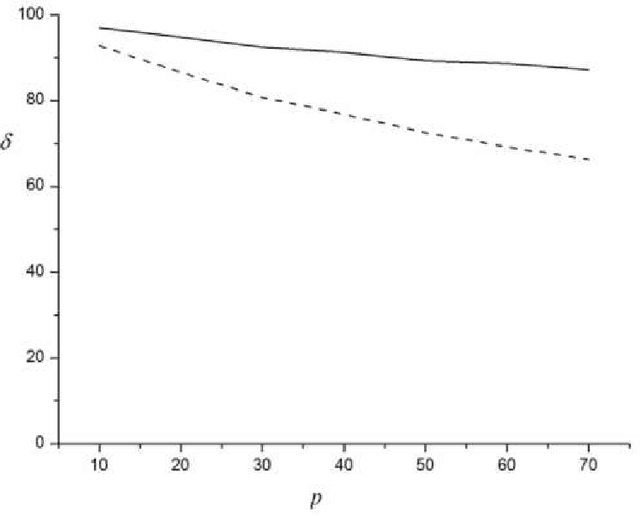

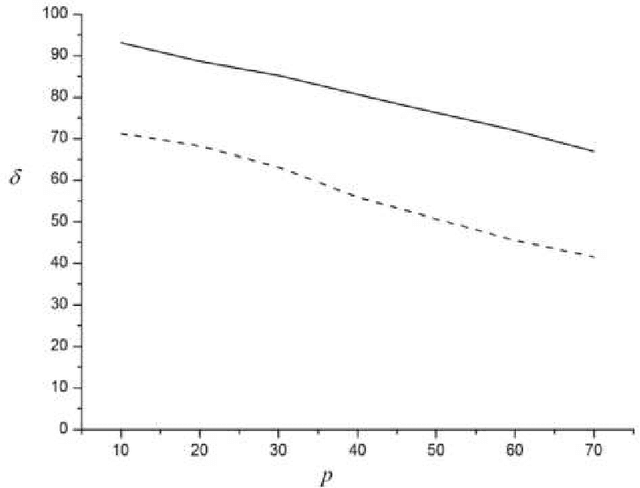

This article suggests an algorithm of impulse noise filtration, based on the community detection in graphs. The image is representing as non-oriented weighted graph. Each pixel of an image is corresponding to a vertex of the graph. Community detection algorithm is running on the given graph. Assumed that communities that contain only one pixel are corresponding to noised pixels of an image. Suggested method was tested with help of computer experiment. This experiment was conducted on grayscale, and on colored images, on artificial images and on photos. It is shown that the suggested method is better than median filter by 20% regardless of noise percent. Higher efficiency is justified by the fact that most of filters are changing all of image pixels, but suggested method is finding and restoring only noised pixels. The dependence of the effectiveness of the proposed method on the percentage of noise in the image is shown.
Adversarial Perturbations on the Perceptual Ball
Dec 19, 2019
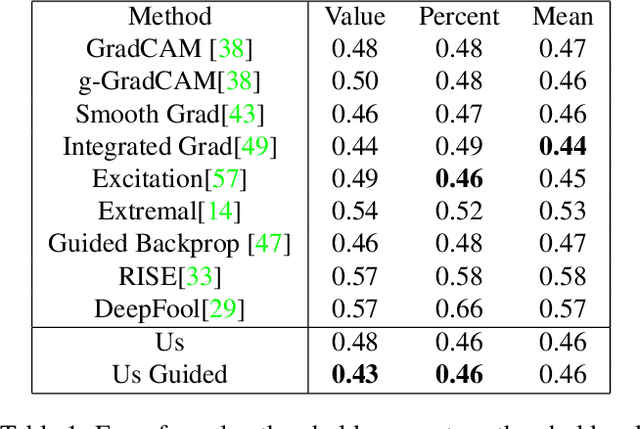

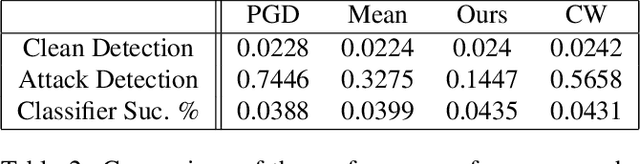
We present a simple regularisation of Adversarial Perturbations based upon the perceptual loss. While the resulting perturbations remain imperceptible to the human eye, they differ from existing adversarial perturbations in two important regards: (i) our resulting perturbations are semi-sparse,and typically make alterations to objects and regions of interest leaving the background static; (ii) our perturbations do not alter the distribution of data in the image and are undetectable by state-of-the-art-methods. As such this workreinforces the connection between explainable AI and adversarial perturbations. We show the merits of our approach by evaluating onstandard explainablity benchmarks and by defeating recenttests for detecting adversarial perturbations, substantially decreasing the effectiveness of detecting adversarial perturbations.
Verification of Deep Convolutional Neural Networks Using ImageStars
Apr 12, 2020



Convolutional Neural Networks (CNN) have redefined the state-of-the-art in many real-world applications, such as facial recognition, image classification, human pose estimation, and semantic segmentation. Despite their success, CNNs are vulnerable to adversarial attacks, where slight changes to their inputs may lead to sharp changes in their output in even well-trained networks. Set-based analysis methods can detect or prove the absence of bounded adversarial attacks, which can then be used to evaluate the effectiveness of neural network training methodology. Unfortunately, existing verification approaches have limited scalability in terms of the size of networks that can be analyzed. In this paper, we describe a set-based framework that successfully deals with real-world CNNs, such as VGG16 and VGG19, that have high accuracy on ImageNet. Our approach is based on a new set representation called the ImageStar, which enables efficient exact and over-approximative analysis of CNNs. ImageStars perform efficient set-based analysis by combining operations on concrete images with linear programming (LP). Our approach is implemented in a tool called NNV, and can verify the robustness of VGG networks with respect to a small set of input states, derived from adversarial attacks, such as the DeepFool attack. The experimental results show that our approach is less conservative and faster than existing zonotope methods, such as those used in DeepZ, and the polytope method used in DeepPoly.
Joint Progressive Knowledge Distillation and Unsupervised Domain Adaptation
May 16, 2020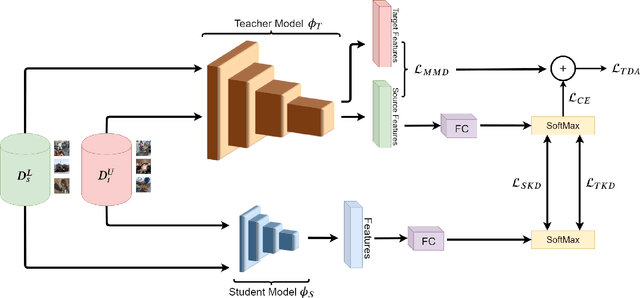

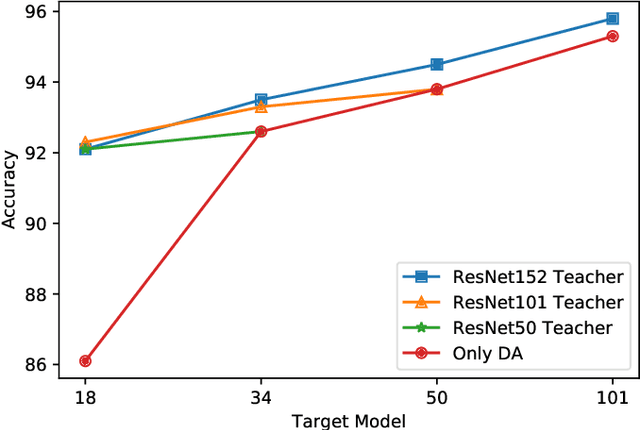

Currently, the divergence in distributions of design and operational data, and large computational complexity are limiting factors in the adoption of CNNs in real-world applications. For instance, person re-identification systems typically rely on a distributed set of cameras, where each camera has different capture conditions. This can translate to a considerable shift between source (e.g. lab setting) and target (e.g. operational camera) domains. Given the cost of annotating image data captured for fine-tuning in each target domain, unsupervised domain adaptation (UDA) has become a popular approach to adapt CNNs. Moreover, state-of-the-art deep learning models that provide a high level of accuracy often rely on architectures that are too complex for real-time applications. Although several compression and UDA approaches have recently been proposed to overcome these limitations, they do not allow optimizing a CNN to simultaneously address both. In this paper, we propose an unexplored direction -- the joint optimization of CNNs to provide a compressed model that is adapted to perform well for a given target domain. In particular, the proposed approach performs unsupervised knowledge distillation (KD) from a complex teacher model to a compact student model, by leveraging both source and target data. It also improves upon existing UDA techniques by progressively teaching the student about domain-invariant features, instead of directly adapting a compact model on target domain data. Our method is compared against state-of-the-art compression and UDA techniques, using two popular classification datasets for UDA -- Office31 and ImageClef-DA. In both datasets, results indicate that our method can achieve the highest level of accuracy while requiring a comparable or lower time complexity.
Improving Learning Effectiveness For Object Detection and Classification in Cluttered Backgrounds
Feb 27, 2020

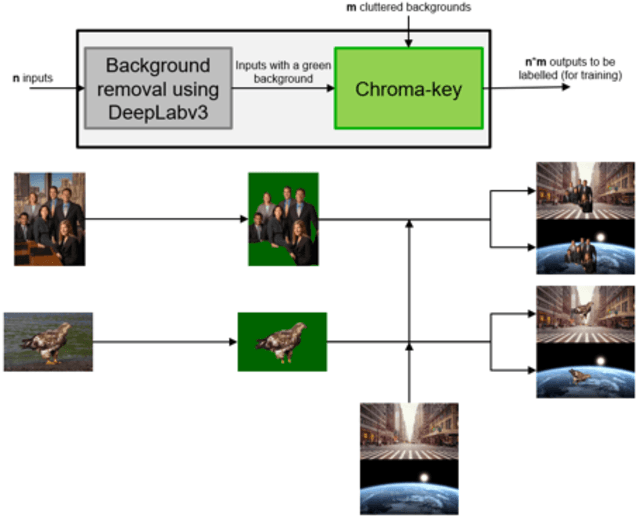
Usually, Neural Networks models are trained with a large dataset of images in homogeneous backgrounds. The issue is that the performance of the network models trained could be significantly degraded in a complex and heterogeneous environment. To mitigate the issue, this paper develops a framework that permits to autonomously generate a training dataset in heterogeneous cluttered backgrounds. It is clear that the learning effectiveness of the proposed framework should be improved in complex and heterogeneous environments, compared with the ones with the typical dataset. In our framework, a state-of-the-art image segmentation technique called DeepLab is used to extract objects of interest from a picture and Chroma-key technique is then used to merge the extracted objects of interest into specific heterogeneous backgrounds. The performance of the proposed framework is investigated through empirical tests and compared with that of the model trained with the COCO dataset. The results show that the proposed framework outperforms the model compared. This implies that the learning effectiveness of the framework developed is superior to the models with the typical dataset.