 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PDH : Probabilistic deep hashing based on MAP estimation of Hamming distance
May 21, 2019
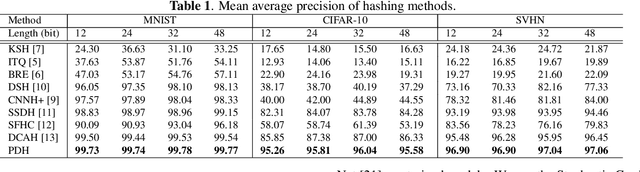
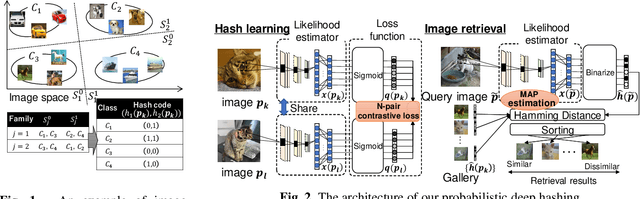
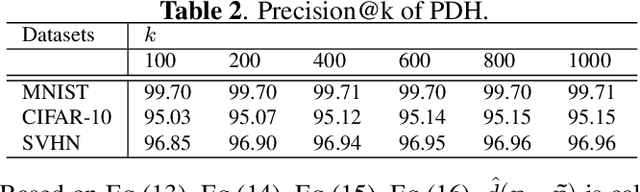
With the growth of image on the web, research on hashing which enables high-speed image retrieval has been actively studied. In recent years, various hashing methods based on deep neural networks have been proposed and achieved higher precision than the other hashing methods. In these methods, multiple losses for hash codes and the parameters of neural networks are defined. They generate hash codes that minimize the weighted sum of the losses. Therefore, an expert has to tune the weights for the losses heuristically, and the probabilistic optimality of the loss function cannot be explained. In order to generate explainable hash codes without weight tuning, we theoretically derive a single loss function with no hyperparameters for the hash code from the probability distribution of the images. By generating hash codes that minimize this loss function, highly accurate image retrieval with probabilistic optimality is performed. We evaluate the performance of hashing using MNIST, CIFAR-10, SVHN and show that the proposed method outperforms the state-of-the-art hashing methods.
Thermodynamic Cost of Edge Detection in Artificial Neural Network(ANN)-Based Processors
Mar 18, 2020
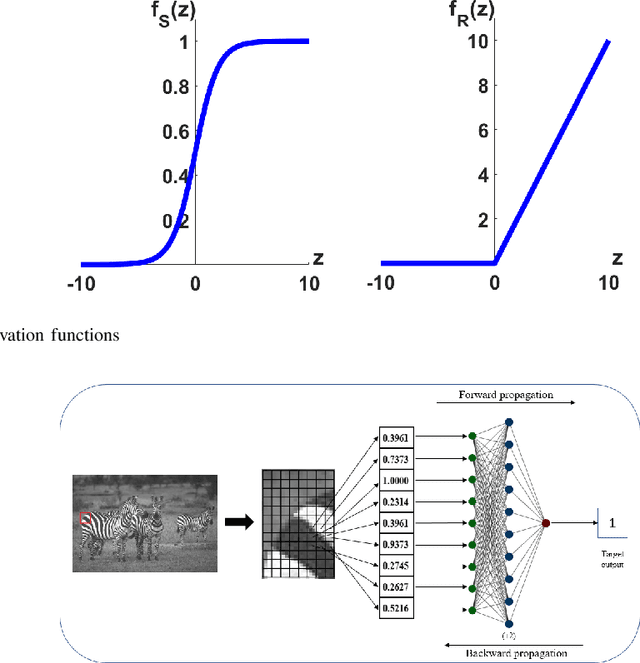

Architecture-based heat dissipation analyses allows us to reveal fundamental sources of inefficiency in a given processor and thereby provide us with roadmaps to design less dissipative computing schemes independent of technology-bases used to implement the processor. In this work, we study architectural-level contributions to energy dissipation in Artificial Neural Network (ANN)-based processors that are trained to perform edge detection task. We compare the training and information processing cost ofANNs to that of conventional architectures and algorithms using 64-pixel binary image. Our results reveal the inherent efficiency advantages of ANN networks trained for specific tasks over general purpose processors based on von Neumann architecture.We also compare the proposed performance improvements to that of CAPs and show the reduction in dissipation for special purpose processors. Lastly, we calculate the change in dissipation as a result of change in input data structure and show the effect of randomness on energetic cost of information processing. The results we obtain provide a basis for comparison for task-based fundamental energy efficiency analyses for a range of processors and therefore contribute to the study of architecture-level descriptions of processors and thermodynamic cost calculations based on physics of computation.
Video Interpolation and Prediction with Unsupervised Landmarks
Sep 06, 2019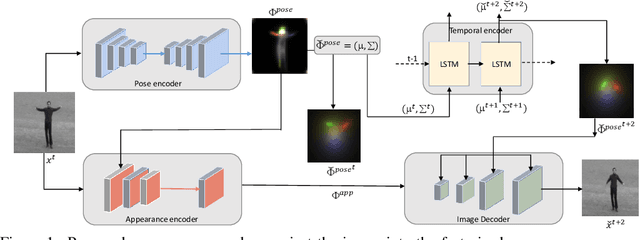
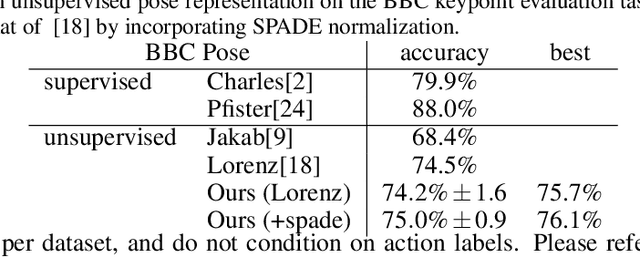
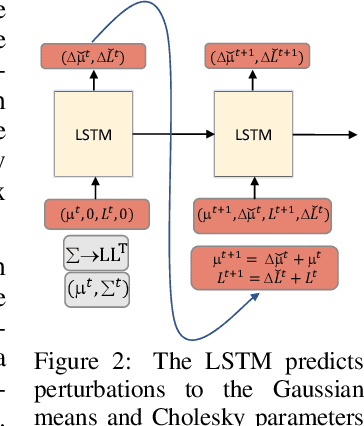
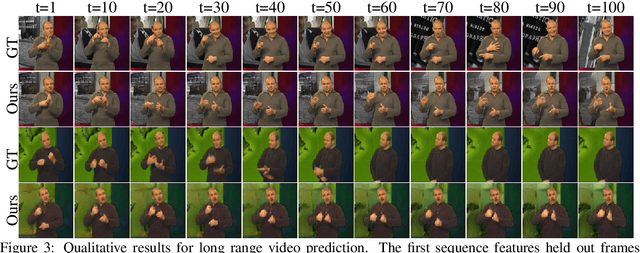
Prediction and interpolation for long-range video data involves the complex task of modeling motion trajectories for each visible object, occlusions and dis-occlusions, as well as appearance changes due to viewpoint and lighting. Optical flow based techniques generalize but are suitable only for short temporal ranges. Many methods opt to project the video frames to a low dimensional latent space, achieving long-range predictions. However, these latent representations are often non-interpretable, and therefore difficult to manipulate. This work poses video prediction and interpolation as unsupervised latent structure inference followed by a temporal prediction in this latent space. The latent representations capture foreground semantics without explicit supervision such as keypoints or poses. Further, as each landmark can be mapped to a coordinate indicating where a semantic part is positioned, we can reliably interpolate within the coordinate domain to achieve predictable motion interpolation. Given an image decoder capable of mapping these landmarks back to the image domain, we are able to achieve high-quality long-range video interpolation and extrapolation by operating on the landmark representation space.
Land Use and Land Cover Classification Using Deep Learning Techniques
May 01, 2019
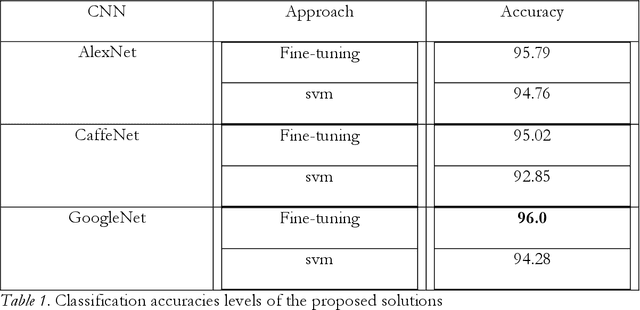
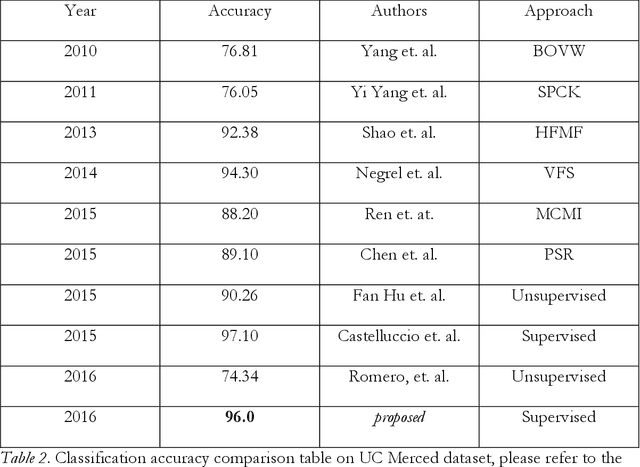
Large datasets of sub-meter aerial imagery represented as orthophoto mosaics are widely available today, and these data sets may hold a great deal of untapped information. This imagery has a potential to locate several types of features; for example, forests, parking lots, airports, residential areas, or freeways in the imagery. However, the appearances of these things vary based on many things including the time that the image is captured, the sensor settings, processing done to rectify the image, and the geographical and cultural context of the region captured by the image. This thesis explores the use of deep convolutional neural networks to classify land use from very high spatial resolution (VHR), orthorectified, visible band multispectral imagery. Recent technological and commercial applications have driven the collection a massive amount of VHR images in the visible red, green, blue (RGB) spectral bands, this work explores the potential for deep learning algorithms to exploit this imagery for automatic land use/ land cover (LULC) classification.
Microvascular Dynamics from 4D Microscopy Using Temporal Segmentation
Jan 14, 2020



Recently developed methods for rapid continuous volumetric two-photon microscopy facilitate the observation of neuronal activity in hundreds of individual neurons and changes in blood flow in adjacent blood vessels across a large volume of living brain at unprecedented spatio-temporal resolution. However, the high imaging rate necessitates fully automated image analysis, whereas tissue turbidity and photo-toxicity limitations lead to extremely sparse and noisy imagery. In this work, we extend a recently proposed deep learning volumetric blood vessel segmentation network, such that it supports temporal analysis. With this technology, we are able to track changes in cerebral blood volume over time and identify spontaneous arterial dilations that propagate towards the pial surface. This new capability is a promising step towards characterizing the hemodynamic response function upon which functional magnetic resonance imaging (fMRI) is based.
Cross-Iteration Batch Normalization
Feb 13, 2020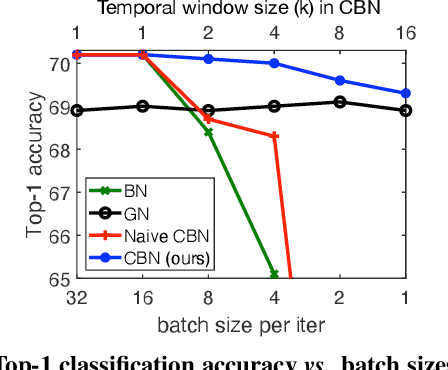

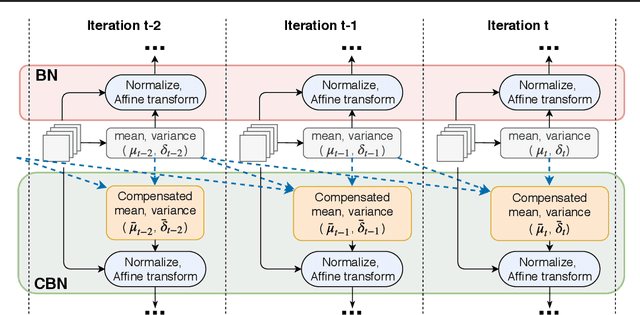

A well-known issue of Batch Normalization is its significantly reduced effectiveness in the case of small mini-batch sizes. When a mini-batch contains few examples, the statistics upon which the normalization is defined cannot be reliably estimated from it during a training iteration. To address this problem, we present Cross-Iteration Batch Normalization (CBN), in which examples from multiple recent iterations are jointly utilized to enhance estimation quality. A challenge of computing statistics over multiple iterations is that the network activations from different iterations are not comparable to each other due to changes in network weights. We thus compensate for the network weight changes via a proposed technique based on Taylor polynomials, so that the statistics can be accurately estimated and batch normalization can be effectively applied. On object detection and image classification with small mini-batch sizes, CBN is found to outperform the original batch normalization and a direct calculation of statistics over previous iterations without the proposed compensation technique.
A Deep Regression Model for Seed Identification in Prostate Brachytherapy
Jun 24, 2019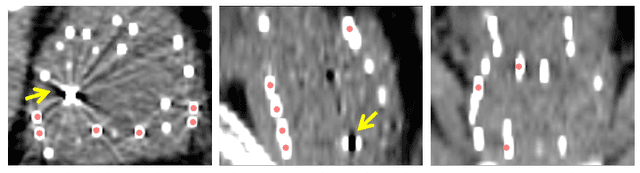
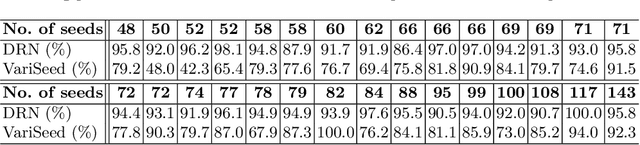

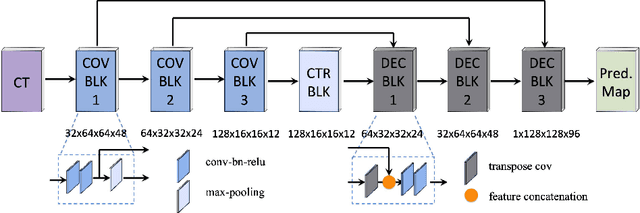
Post-implant dosimetry (PID) is an essential step of prostate brachytherapy that utilizes CT to image the prostate and allow the location and dose distribution of the radioactive seeds to be directly related to the actual prostate. However, it it a very challenging task to identify these seeds in CT images due to the severe metal artifacts and high-overlapped appearance when multiple seeds clustered together. In this paper, we propose an automatic and efficient algorithm based on 3D deep fully convolutional network for identifying implanted seeds in CT images. Our method models the seed localization task as a supervised regression problem that projects the input CT image to a map where each element represents the probability that the corresponding input voxel belongs to a seed. This deep regression model significantly suppresses image artifacts and makes the post-processing much easier and more controllable. The proposed method is validated on a large clinical database with 7820 seeds in 100 patients, in which 5534 seeds from 70 patients were used for model training and validation. Our method correctly detected 2150 of 2286 (94.1%) seeds in the 30 testing patients, yielding 16% improvement as compared to a widely-used commercial seed finder software (VariSeed, Varian, Palo Alto, CA).
RUBi: Reducing Unimodal Biases in Visual Question Answering
Jun 24, 2019



Visual Question Answering (VQA) is the task of answering questions about an image. Some VQA models often exploit unimodal biases to provide the correct answer without using the image information. As a result, they suffer from a huge drop in performance when evaluated on data outside their training set distribution. This critical issue makes them unsuitable for real-world settings. We propose RUBi, a new learning strategy to reduce biases in any VQA model. It reduces the importance of the most biased examples, i.e. examples that can be correctly classified without looking at the image. It implicitly forces the VQA model to use the two input modalities instead of relying on statistical regularities between the question and the answer. We leverage a question-only model that captures the language biases by identifying when these unwanted regularities are used. It prevents the base VQA model from learning them by influencing its predictions. This leads to dynamically adjusting the loss in order to compensate for biases. We validate our contributions by surpassing the current state-of-the-art results on VQA-CP v2. This dataset is specifically designed to assess the robustness of VQA models when exposed to different question biases at test time than what was seen during training. Our code is available: github.com/cdancette/rubi.bootstrap.pytorch
Neural Mesh Refiner for 6-DoF Pose Estimation
Mar 18, 2020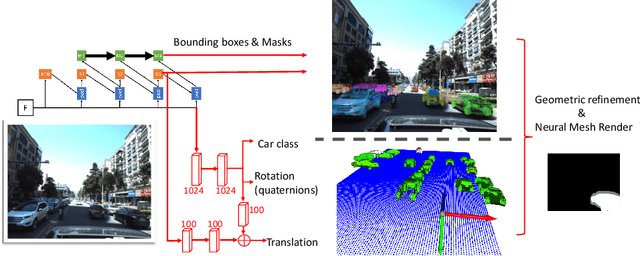
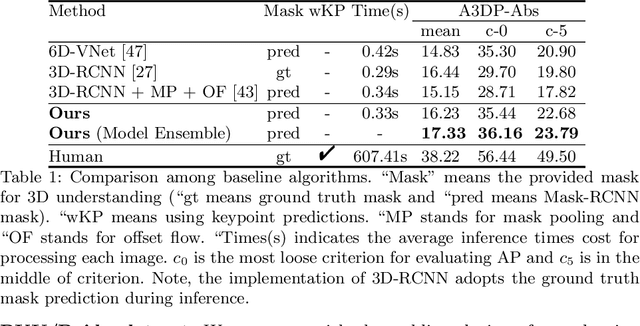
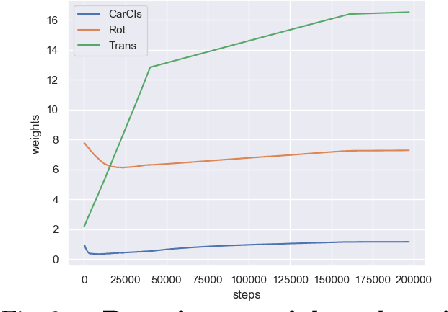
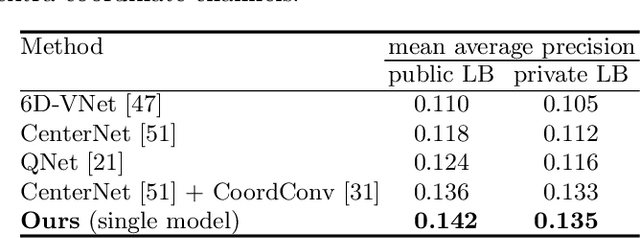
How can we effectively utilise the 2D monocular image information for recovering the 6D pose (6-DoF) of the visual objects? Deep learning has shown to be effective for robust and real-time monocular pose estimation. Oftentimes, the network learns to regress the 6-DoF pose using a naive loss function. However, due to a lack of geometrical scene understanding from the directly regressed pose estimation, there are misalignments between the rendered mesh from the 3D object and the 2D instance segmentation result, e.g., bounding boxes and masks prediction. This paper bridges the gap between 2D mask generation and 3D location prediction via a differentiable neural mesh renderer. We utilise the overlay between the accurate mask prediction and less accurate mesh prediction to iteratively optimise the direct regressed 6D pose information with a focus on translation estimation. By leveraging geometry, we demonstrate that our technique significantly improves direct regression performance on the difficult task of translation estimation and achieve the state of the art results on Peking University/Baidu - Autonomous Driving dataset and the ApolloScape 3D Car Instance dataset. The code can be found at \url{https://bit.ly/2IRihfU}.
Preterm infants' pose estimation with spatio-temporal features
May 08, 2020

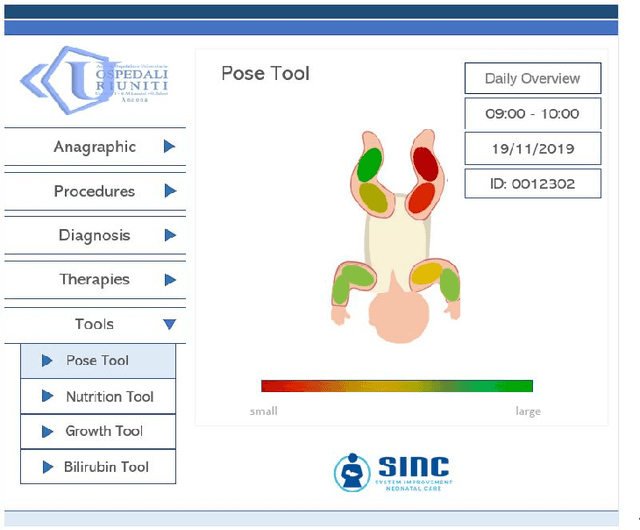
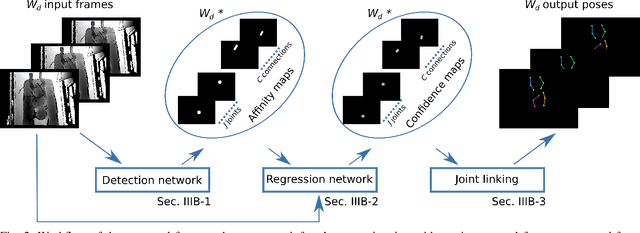
Objective: Preterm infants' limb monitoring in neonatal intensive care units (NICUs) is of primary importance for assessing infants' health status and motor/cognitive development. Herein, we propose a new approach to preterm infants' limb pose estimation that features spatio-temporal information to detect and track limb joints from depth videos with high reliability. Methods: Limb-pose estimation is performed using a deep-learning framework consisting of a detection and a regression convolutional neural network (CNN) for rough and precise joint localization, respectively. The CNNs are implemented to encode connectivity in the temporal direction through 3D convolution. Assessment of the proposed framework is performed through a comprehensive study with sixteen depth videos acquired in the actual clinical practice from sixteen preterm infants (the babyPose dataset). Results: When applied to pose estimation, the median root mean squared distance, computed among all limbs, between the estimated and the ground-truth pose was 9.06 pixels, overcoming approaches based on spatial features only (11.27pixels). Conclusion: Results showed that the spatio-temporal features had a significant influence on the pose-estimation performance, especially in challenging cases (e.g., homogeneous image intensity). Significance: This paper significantly enhances the state of art in automatic assessment of preterm infants' health status by introducing the use of spatio-temporal features for limb detection and tracking, and by being the first study to use depth videos acquired in the actual clinical practice for limb-pose estimation. The babyPose dataset has been released as the first annotated dataset for infants' pose estimation.