 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
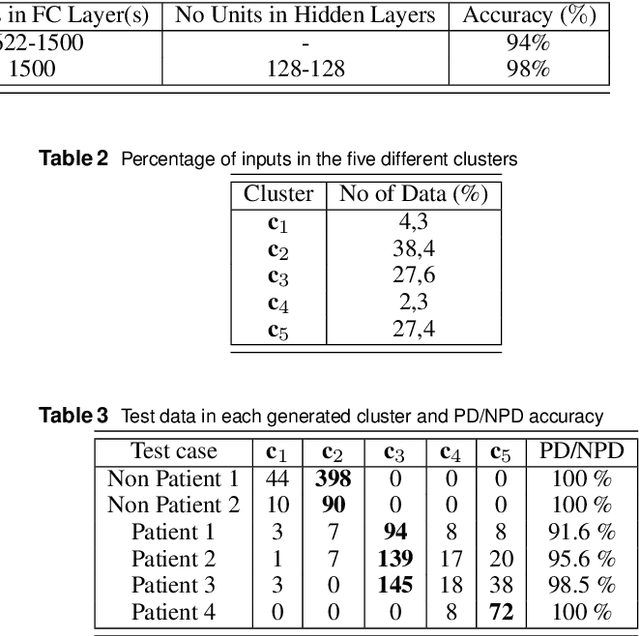
Joint Learning of Self-Representation and Indicator for Multi-View Image Clustering
May 11, 2019

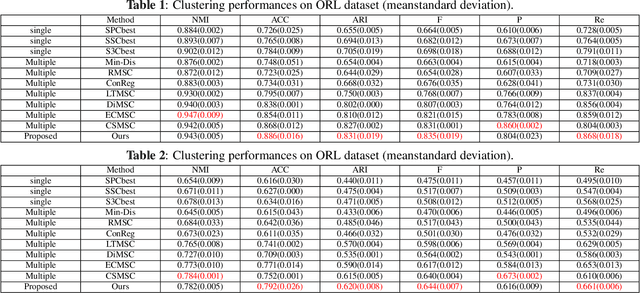
Multi-view subspace clustering aims to divide a set of multisource data into several groups according to their underlying subspace structure. Although the spectral clustering based methods achieve promotion in multi-view clustering, their utility is limited by the separate learning manner in which affinity matrix construction and cluster indicator estimation are isolated. In this paper, we propose to jointly learn the self-representation, continue and discrete cluster indicators in an unified model. Our model can explore the subspace structure of each view and fusion them to facilitate clustering simultaneously. Experimental results on two benchmark datasets demonstrate that our method outperforms other existing competitive multi-view clustering methods.
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Mar 17, 2020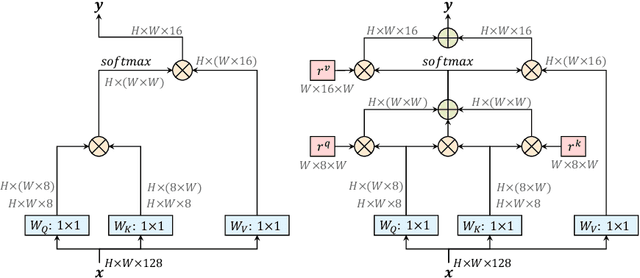
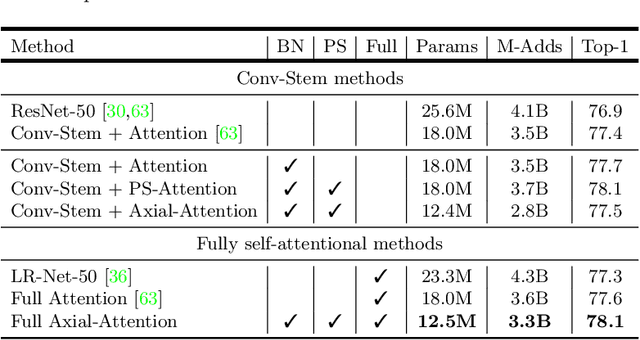
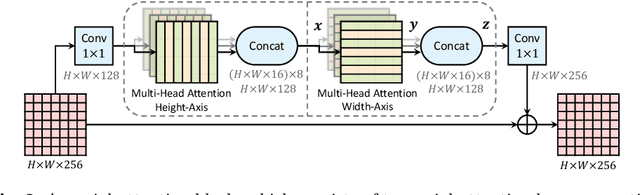
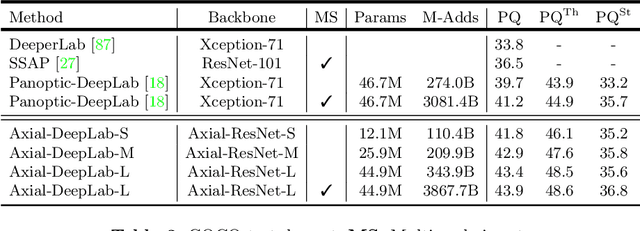
Convolution exploits locality for efficiency at a cost of missing long range context. Self-attention has been adopted to augment CNNs with non-local interactions. Recent works prove it possible to stack self-attention layers to obtain a fully attentional network by restricting the attention to a local region. In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D self-attentions. This reduces computation complexity and allows performing attention within a larger or even global region. In companion, we also propose a position-sensitive self-attention design. Combining both yields our position-sensitive axial-attention layer, a novel building block that one could stack to form axial-attention models for image classification and dense prediction. We demonstrate the effectiveness of our model on four large-scale datasets. In particular, our model outperforms all existing stand-alone self-attention models on ImageNet. Our Axial-DeepLab improves 2.8% PQ over bottom-up state-of-the-art on COCO test-dev. This previous state-of-the-art is attained by our small variant that is 3.8x parameter-efficient and 27x computation-efficient. Axial-DeepLab also achieves state-of-the-art results on Mapillary Vistas and Cityscapes.
Optimizing Deep Learning Inference on Embedded Systems Through Adaptive Model Selection
Nov 09, 2019

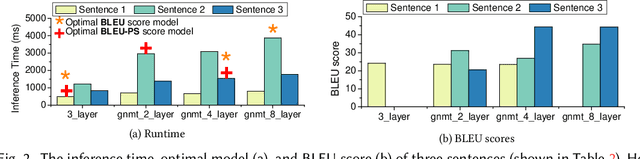

Deep neural networks ( DNNs ) are becoming a key enabling technology for many application domains. However, on-device inference on battery-powered, resource-constrained embedding systems is often infeasible due to prohibitively long inferencing time and resource requirements of many DNNs. Offloading computation into the cloud is often unacceptable due to privacy concerns, high latency, or the lack of connectivity. While compression algorithms often succeed in reducing inferencing times, they come at the cost of reduced accuracy. This paper presents a new, alternative approach to enable efficient execution of DNNs on embedded devices. Our approach dynamically determines which DNN to use for a given input, by considering the desired accuracy and inference time. It employs machine learning to develop a low-cost predictive model to quickly select a pre-trained DNN to use for a given input and the optimization constraint. We achieve this by first off-line training a predictive model, and then using the learned model to select a DNN model to use for new, unseen inputs. We apply our approach to two representative DNN domains: image classification and machine translation. We evaluate our approach on a Jetson TX2 embedded deep learning platform and consider a range of influential DNN models including convolutional and recurrent neural networks. For image classification, we achieve a 1.8x reduction in inference time with a 7.52% improvement in accuracy, over the most-capable single DNN model. For machine translation, we achieve a 1.34x reduction in inference time over the most-capable single model, with little impact on the quality of translation.
Robust GNSS Denied Localization for UAV Using Particle Filter and Visual Odometry
Oct 26, 2019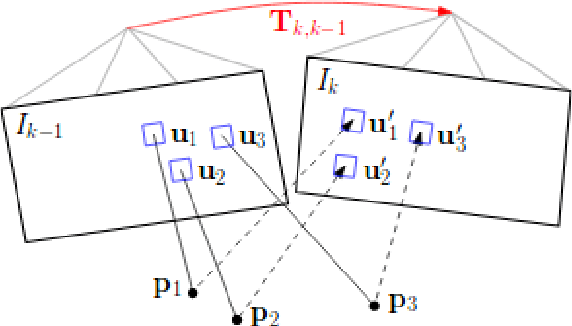
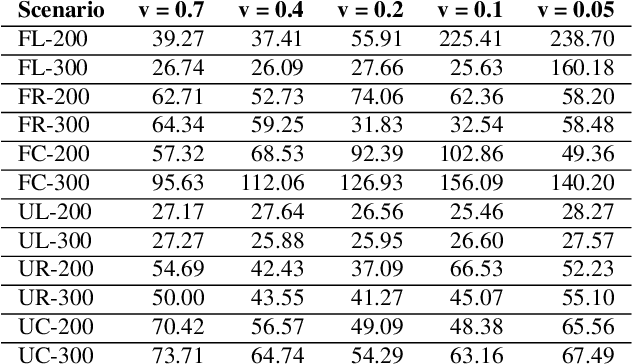
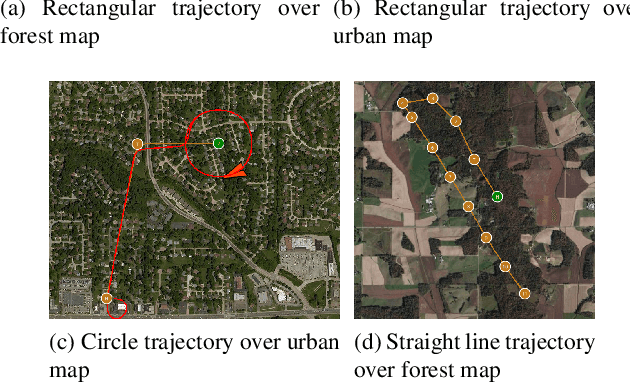
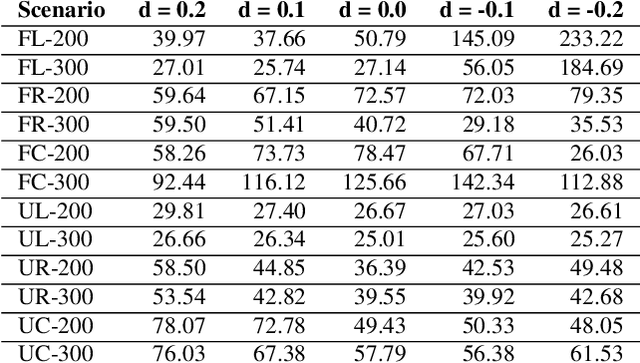
Conventional autonomous Unmanned Air Vehicle (abbr. UAV) autopilot systems use Global Navigation Satellite System (abbr. GNSS) signal for navigation. However, autopilot systems fail to navigate due to lost or jammed GNSS signal. To solve this problem, information from other sensors such as optical sensors are used. Monocular Simultaneous Localization and Mapping algorithms have been developed over the last few years and achieved state-of-the-art accuracy. Also, map matching localization approaches are used for UAV localization relatively to imagery from static maps such as Google Maps. Unfortunately, the accuracy and robustness of these algorithms are very dependent on up-to-date maps. The purpose of this research is to improve the accuracy and robustness of map relative Particle Filter based localization using a downward-facing optical camera mounted on an autonomous aircraft. This research shows how image similarity to likelihood conversion function impacts the results of Particle Filter localization algorithm. Two parametric image similarity to likelihood conversion functions (logistic and rectifying) are proposed. A dataset of simulated aerial imagery is used for experiments. The experiment results are shown, that the Particle Filter localization algorithm using the logistic function was able to surpass the accuracy of state-of-the-art ORB-SLAM2 algorithm by 2.6 times. The algorithm is shown to be able to navigate using up-to-date maps more accurately and with an average decrease of precision by 30% using out-of-date maps.
A Unified Deep Learning Approach for Prediction of Parkinson's Disease
Nov 25, 2019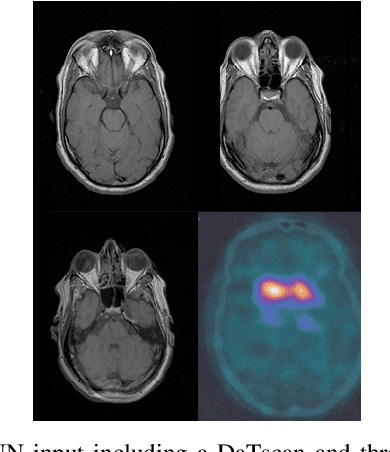

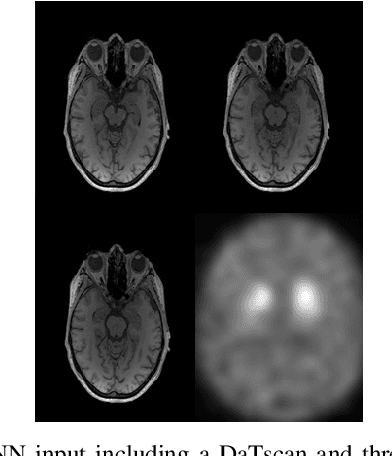
The paper presents a novel approach, based on deep learning, for diagnosis of Parkinson's disease through medical imaging. The approach includes analysis and use of the knowledge extracted by Deep Convolutional and Recurrent Neural Networks (DNNs) when trained with medical images, such as Magnetic Resonance Images and DaTscans. Internal representations of the trained DNNs constitute the extracted knowledge which is used in a transfer learning and domain adaptation manner, so as to create a unified framework for prediction of Parkinson's across different medical environments. A large experimental study is presented illustrating the ability of the proposed approach to effectively predict Parkinson's, using different medical image sets from real environments.
Efficient and Accurate Gaussian Image Filtering Using Running Sums
Jul 25, 2011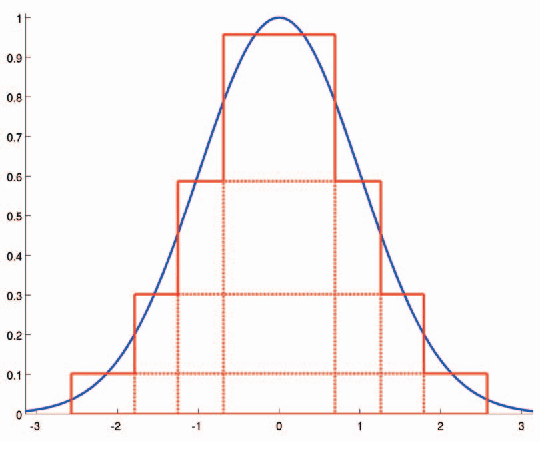
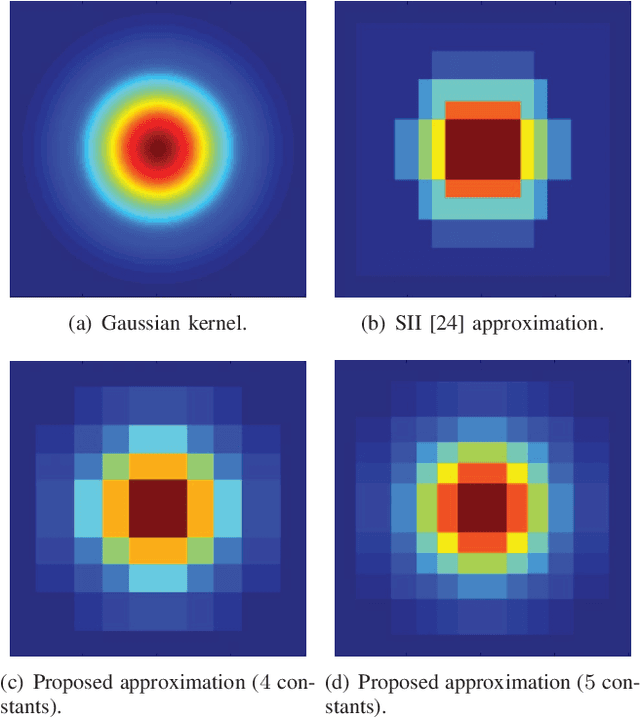
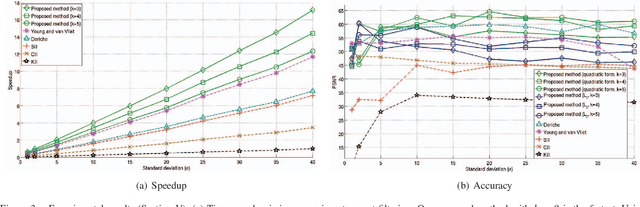
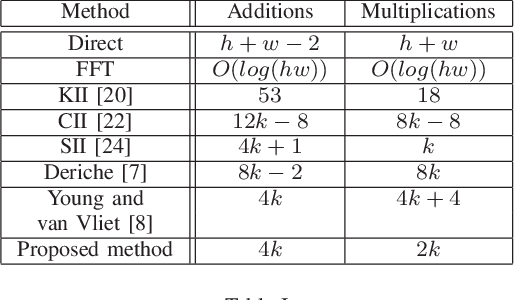
This paper presents a simple and efficient method to convolve an image with a Gaussian kernel. The computation is performed in a constant number of operations per pixel using running sums along the image rows and columns. We investigate the error function used for kernel approximation and its relation to the properties of the input signal. Based on natural image statistics we propose a quadratic form kernel error function so that the output image l2 error is minimized. We apply the proposed approach to approximate the Gaussian kernel by linear combination of constant functions. This results in very efficient Gaussian filtering method. Our experiments show that the proposed technique is faster than state of the art methods while preserving a similar accuracy.
Constrained $H^1$-regularization schemes for diffeomorphic image registration
Sep 07, 2016
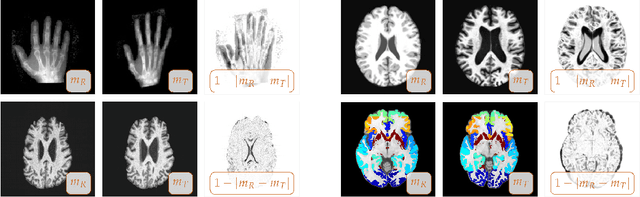
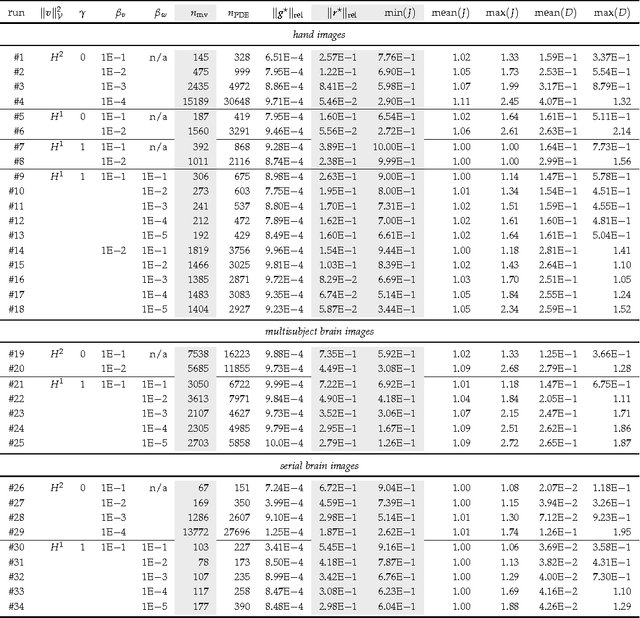
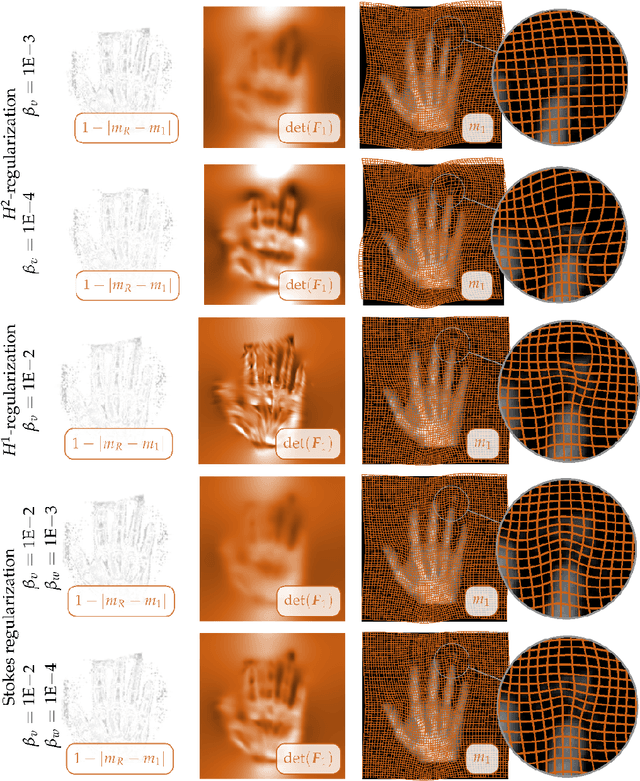
We propose regularization schemes for deformable registration and efficient algorithms for their numerical approximation. We treat image registration as a variational optimal control problem. The deformation map is parametrized by its velocity. Tikhonov regularization ensures well-posedness. Our scheme augments standard smoothness regularization operators based on $H^1$- and $H^2$-seminorms with a constraint on the divergence of the velocity field, which resembles variational formulations for Stokes incompressible flows. In our formulation, we invert for a stationary velocity field and a mass source map. This allows us to explicitly control the compressibility of the deformation map and by that the determinant of the deformation gradient. We also introduce a new regularization scheme that allows us to control shear. We use a globalized, preconditioned, matrix-free, reduced space (Gauss--)Newton--Krylov scheme for numerical optimization. We exploit variable elimination techniques to reduce the number of unknowns of our system; we only iterate on the reduced space of the velocity field. Our current implementation is limited to the two-dimensional case. The numerical experiments demonstrate that we can control the determinant of the deformation gradient without compromising registration quality. This additional control allows us to avoid oversmoothing of the deformation map. We also demonstrate that we can promote or penalize shear while controlling the determinant of the deformation gradient.
LPaintB: Learning to Paint from Self-SupervisionLPaintB: Learning to Paint from Self-Supervision
Jun 17, 2019

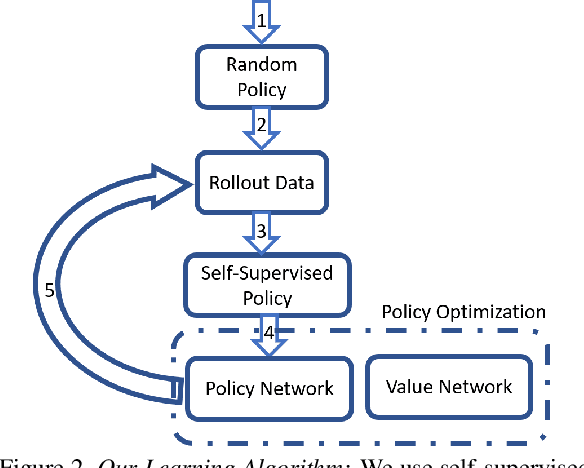

We present a novel reinforcement learning-based natural media painting algorithm. Our goal is to reproduce a reference image using brush strokes and we encode the objective through observations. Our formulation takes into account that the distribution of the reward in the action space is sparse and training a reinforcement learning algorithm from scratch can be difficult. We present an approach that combines self-supervised learning and reinforcement learning to effectively transfer negative samples into positive ones and change the reward distribution. We demonstrate the benefits of our painting agent to reproduce reference images with brush strokes. The training phase takes about one hour and the runtime algorithm takes about 30 seconds on a GTX1080 GPU reproducing a 1000x800 image with 20,000 strokes.
Iterate Averaging Helps: An Alternative Perspective in Deep Learning
Mar 02, 2020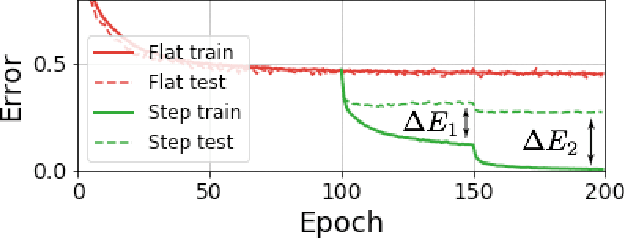

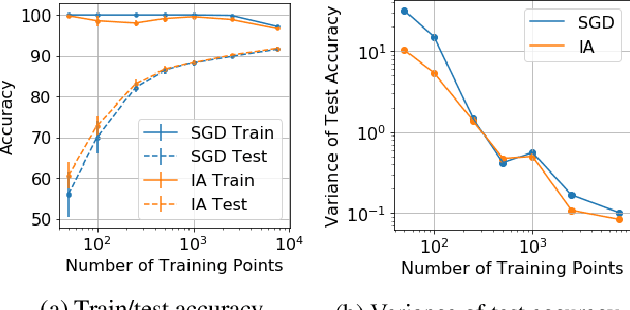
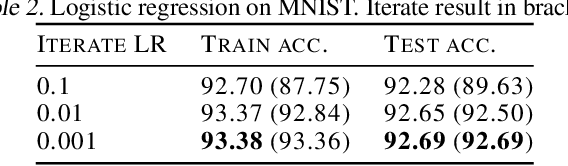
Iterate averaging has a rich history in optimisation, but has only very recently been popularised in deep learning. We investigate its effects in a deep learning context, and argue that previous explanations on its efficacy, which place a high importance on the local geometry (flatness vs sharpness) of final solutions, are not necessarily relevant. We instead argue that the robustness of iterate averaging towards the typically very high estimation noise in deep learning and the various regularisation effects averaging exert, are the key reasons for the performance gain, indeed this effect is made even more prominent due to the over-parameterisation of modern networks. Inspired by this, we propose Gadam, which combines Adam with iterate averaging to address one of key problems of adaptive optimisers that they often generalise worse. Without compromising adaptivity and with minimal additional computational burden, we show that Gadam (and its variant GadamX) achieve a generalisation performance that is consistently superior to tuned SGD and is even on par or better compared to SGD with iterate averaging on various image classification (CIFAR 10/100 and ImageNet 32$\times$32) and language tasks (PTB).
When to Use Convolutional Neural Networks for Inverse Problems
Mar 30, 2020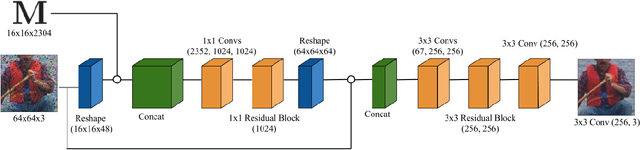

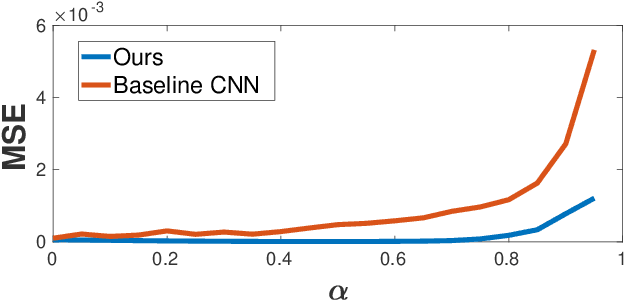
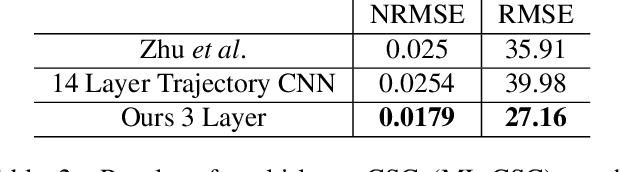
Reconstruction tasks in computer vision aim fundamentally to recover an undetermined signal from a set of noisy measurements. Examples include super-resolution, image denoising, and non-rigid structure from motion, all of which have seen recent advancements through deep learning. However, earlier work made extensive use of sparse signal reconstruction frameworks (e.g convolutional sparse coding). While this work was ultimately surpassed by deep learning, it rested on a much more developed theoretical framework. Recent work by Papyan et. al provides a bridge between the two approaches by showing how a convolutional neural network (CNN) can be viewed as an approximate solution to a convolutional sparse coding (CSC) problem. In this work we argue that for some types of inverse problems the CNN approximation breaks down leading to poor performance. We argue that for these types of problems the CSC approach should be used instead and validate this argument with empirical evidence. Specifically we identify JPEG artifact reduction and non-rigid trajectory reconstruction as challenging inverse problems for CNNs and demonstrate state of the art performance on them using a CSC method. Furthermore, we offer some practical improvements to this model and its application, and also show how insights from the CSC model can be used to make CNNs effective in tasks where their naive application fails.