 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Deep Analysis Dictionaries -- Part II: Convolutional Dictionaries
Jan 31, 2020
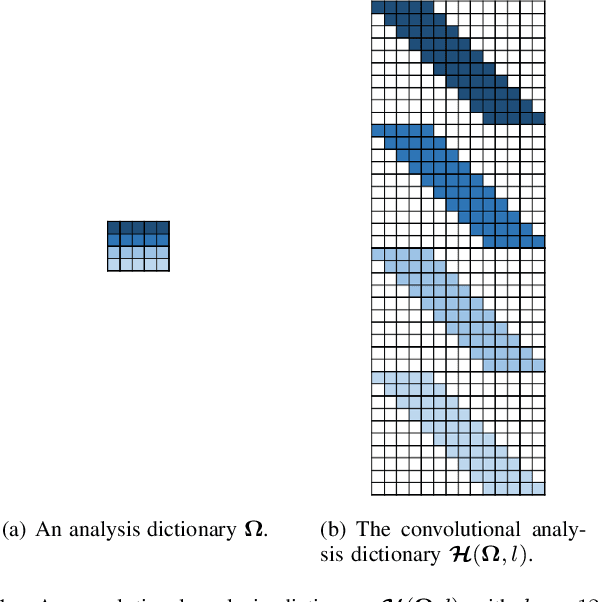

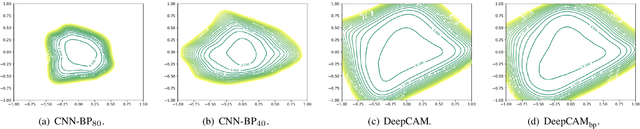
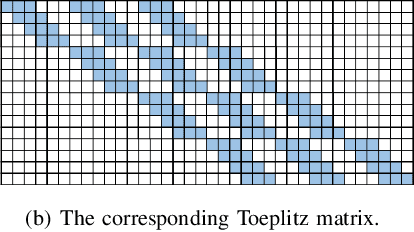
In this paper, we introduce a Deep Convolutional Analysis Dictionary Model (DeepCAM) by learning convolutional dictionaries instead of unstructured dictionaries as in the case of deep analysis dictionary model introduced in the companion paper. Convolutional dictionaries are more suitable for processing high-dimensional signals like for example images and have only a small number of free parameters. By exploiting the properties of a convolutional dictionary, we present an efficient convolutional analysis dictionary learning approach. A L-layer DeepCAM consists of L layers of convolutional analysis dictionary and element-wise soft-thresholding pairs and a single layer of convolutional synthesis dictionary. Similar to DeepAM, each convolutional analysis dictionary is composed of a convolutional Information Preserving Analysis Dictionary (IPAD) and a convolutional Clustering Analysis Dictionary (CAD). The IPAD and the CAD are learned using variations of the proposed learning algorithm. We demonstrate that DeepCAM is an effective multilayer convolutional model and, on single image super-resolution, achieves performance comparable with other methods while also showing good generalization capabilities.
A PCA-Based Super-Resolution Algorithm for Short Image Sequences
Jan 18, 2012


In this paper, we present a novel, learning-based, two-step super-resolution (SR) algorithm well suited to solve the specially demanding problem of obtaining SR estimates from short image sequences. The first step, devoted to increase the sampling rate of the incoming images, is performed by fitting linear combinations of functions generated from principal components (PC) to reproduce locally the sparse projected image data, and using these models to estimate image values at nodes of the high-resolution grid. PCs were obtained from local image patches sampled at sub-pixel level, which were generated in turn from a database of high-resolution images by application of a physically realistic observation model. Continuity between local image models is enforced by minimizing an adequate functional in the space of model coefficients. The second step, dealing with restoration, is performed by a linear filter with coefficients learned to restore residual interpolation artifacts in addition to low-resolution blurring, providing an effective coupling between both steps of the method. Results on a demanding five-image scanned sequence of graphics and text are presented, showing the excellent performance of the proposed method compared to several state-of-the-art two-step and Bayesian Maximum a Posteriori SR algorithms.
Conditional Gaussian Distribution Learning for Open Set Recognition
Mar 20, 2020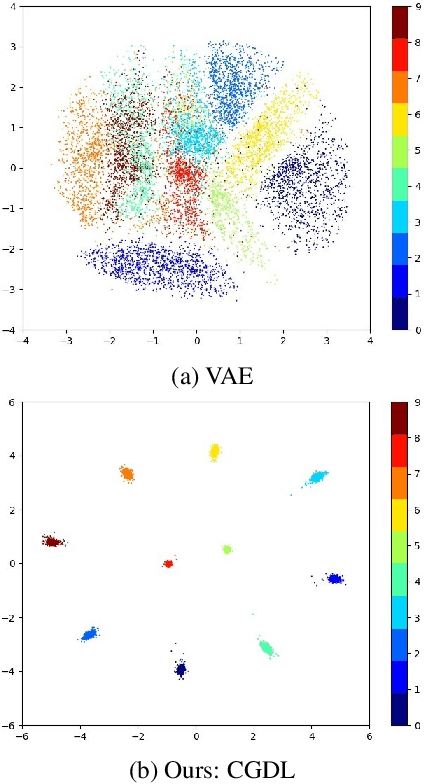
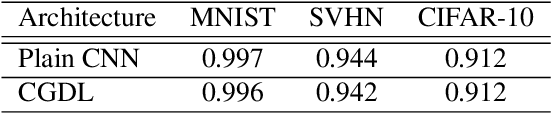
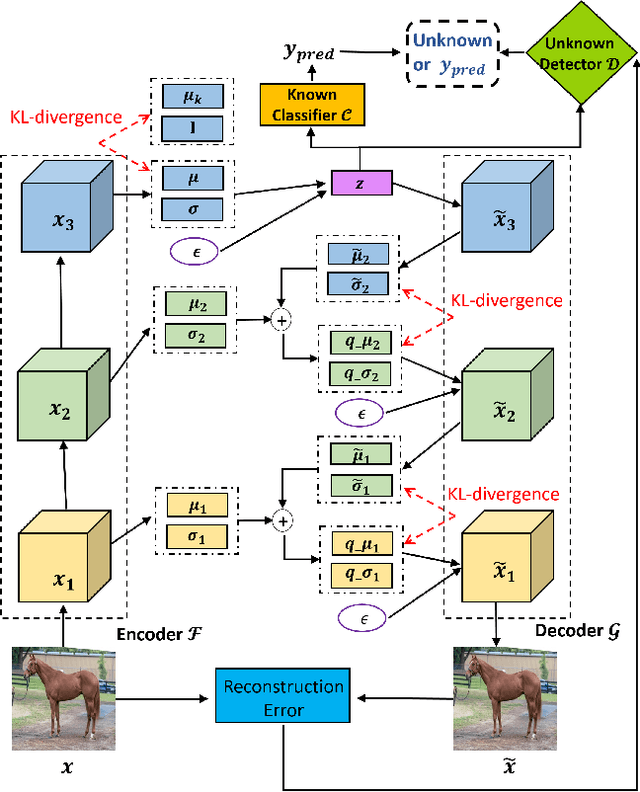

Deep neural networks have achieved state-of-the-art performance in a wide range of recognition/classification tasks. However, when applying deep learning to real-world applications, there are still multiple challenges. A typical challenge is that unknown samples may be fed into the system during the testing phase and traditional deep neural networks will wrongly recognize the unknown sample as one of the known classes. Open set recognition is a potential solution to overcome this problem, where the open set classifier should have the ability to reject unknown samples as well as maintain high classification accuracy on known classes. The variational auto-encoder (VAE) is a popular model to detect unknowns, but it cannot provide discriminative representations for known classification. In this paper, we propose a novel method, Conditional Gaussian Distribution Learning (CGDL), for open set recognition. In addition to detecting unknown samples, this method can also classify known samples by forcing different latent features to approximate different Gaussian models. Meanwhile, to avoid information hidden in the input vanishing in the middle layers, we also adopt the probabilistic ladder architecture to extract high-level abstract features. Experiments on several standard image datasets reveal that the proposed method significantly outperforms the baseline method and achieves new state-of-the-art results.
LPaintB: Learning to Paint from Self-SupervisionLPaintB: Learning to Paint from Self-Supervision
Jun 17, 2019

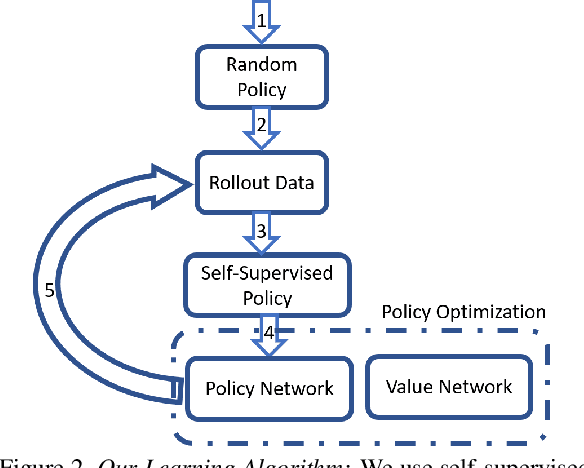

We present a novel reinforcement learning-based natural media painting algorithm. Our goal is to reproduce a reference image using brush strokes and we encode the objective through observations. Our formulation takes into account that the distribution of the reward in the action space is sparse and training a reinforcement learning algorithm from scratch can be difficult. We present an approach that combines self-supervised learning and reinforcement learning to effectively transfer negative samples into positive ones and change the reward distribution. We demonstrate the benefits of our painting agent to reproduce reference images with brush strokes. The training phase takes about one hour and the runtime algorithm takes about 30 seconds on a GTX1080 GPU reproducing a 1000x800 image with 20,000 strokes.
Learning from a Teacher using Unlabeled Data
Nov 13, 2019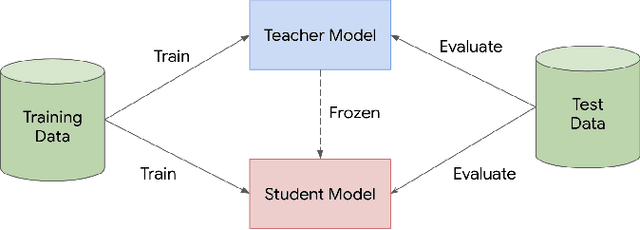
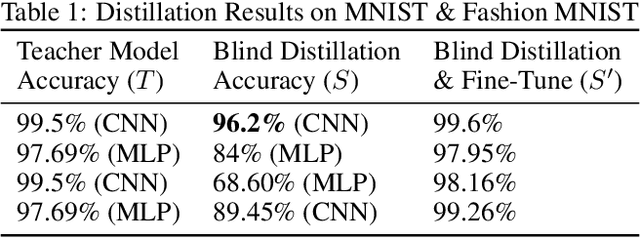

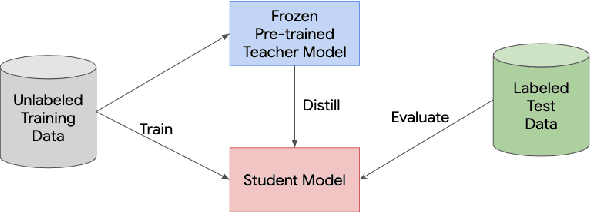
Knowledge distillation is a widely used technique for model compression. We posit that the teacher model used in a distillation setup, captures relationships between classes, that extend beyond the original dataset. We empirically show that a teacher model can transfer this knowledge to a student model even on an {\it out-of-distribution} dataset. Using this approach, we show promising results on MNIST, CIFAR-10, and Caltech-256 datasets using unlabeled image data from different sources. Our results are encouraging and help shed further light from the perspective of understanding knowledge distillation and utilizing unlabeled data to improve model quality.
On Automation and Medical Image Interpretation, With Applications for Laryngeal Imaging
Jan 14, 2013
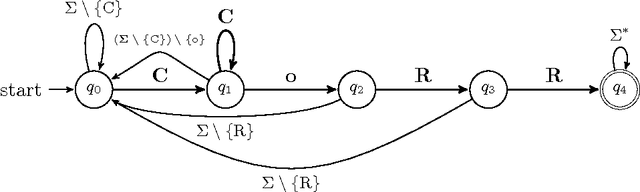

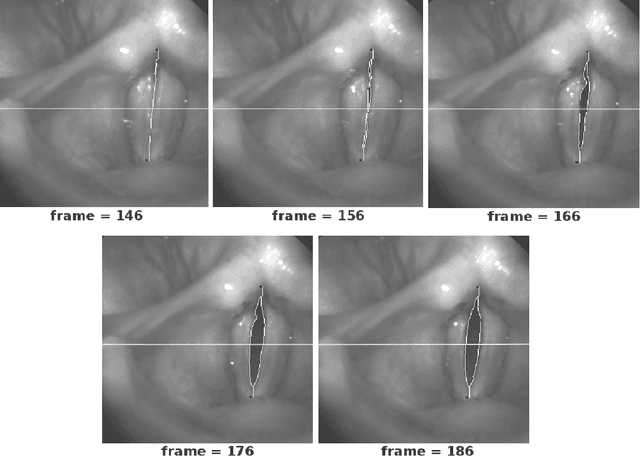
Indeed, these are exciting times. We are in the heart of a digital renaissance. Automation and computer technology allow engineers and scientists to fabricate processes that amalgamate quality of life. We anticipate much growth in medical image interpretation and understanding, due to the influx of computer technologies. This work should serve as a guide to introduce the reader to core themes in theoretical computer science, as well as imaging applications for understanding vocal-fold vibrations. In this work, we motivate the use of automation, review some mathematical models of computation. We present a proof of a classical problem in image analysis that cannot be automated by means of algorithms. Furthermore, discuss some applications for processing medical images of the vocal folds, and discuss some of the exhilarating directions the art of automation will take vocal-fold image interpretation and quite possibly other areas of biomedical image analysis.
End-to-End Trainable One-Stage Parking Slot Detection Integrating Global and Local Information
Mar 05, 2020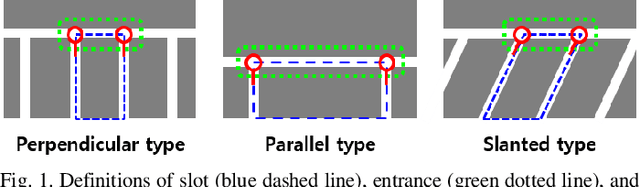
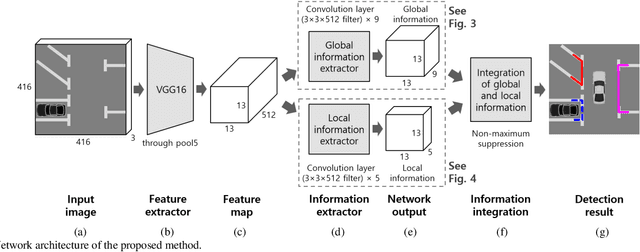

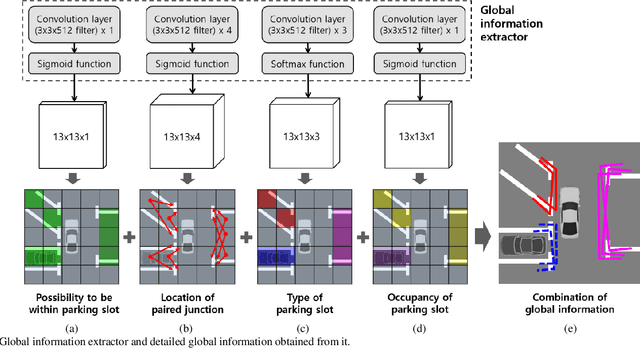
This paper proposes an end-to-end trainable one-stage parking slot detection method for around view monitor (AVM) images. The proposed method simultaneously acquires global information (entrance, type, and occupancy of parking slot) and local information (location and orientation of junction) by using a convolutional neural network (CNN), and integrates them to detect parking slots with their properties. This method divides an AVM image into a grid and performs a CNN-based feature extraction. For each cell of the grid, the global and local information of the parking slot is obtained by applying convolution filters to the extracted feature map. Final detection results are produced by integrating the global and local information of the parking slot through non-maximum suppression (NMS). Since the proposed method obtains most of the information of the parking slot using a fully convolutional network without a region proposal stage, it is an end-to-end trainable one-stage detector. In experiments, this method was quantitatively evaluated using the public dataset and outperforms previous methods by showing both recall and precision of 99.77%, type classification accuracy of 100%, and occupancy classification accuracy of 99.31% while processing 60 frames per second.
Semi-Supervised Semantic Segmentation with Cross-Consistency Training
Mar 19, 2020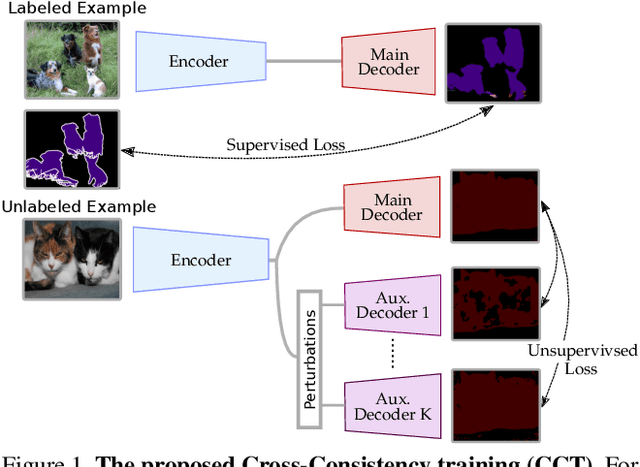
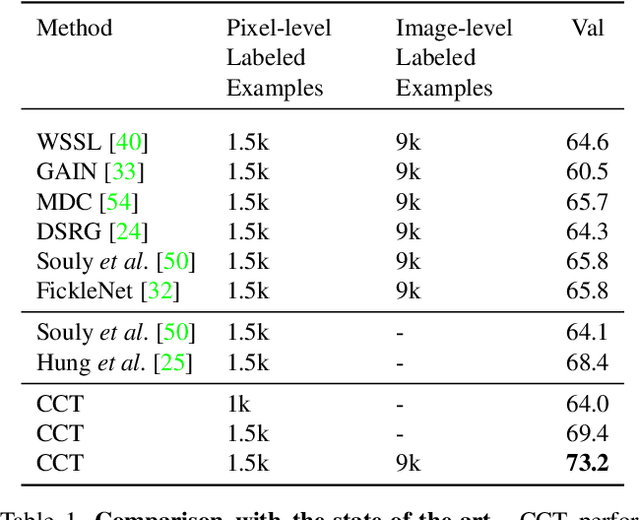

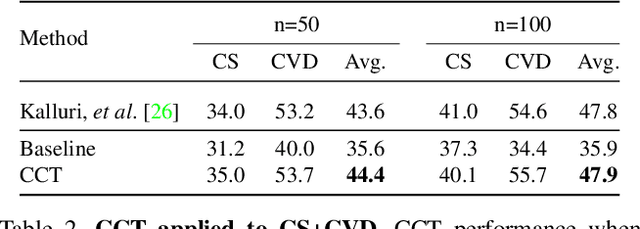
In this paper, we present a novel cross-consistency based semi-supervised approach for semantic segmentation. Consistency training has proven to be a powerful semi-supervised learning framework for leveraging unlabeled data under the cluster assumption, in which the decision boundary should lie in low-density regions. In this work, we first observe that for semantic segmentation, the low-density regions are more apparent within the hidden representations than within the inputs. We thus propose cross-consistency training, where an invariance of the predictions is enforced over different perturbations applied to the outputs of the encoder. Concretely, a shared encoder and a main decoder are trained in a supervised manner using the available labeled examples. To leverage the unlabeled examples, we enforce a consistency between the main decoder predictions and those of the auxiliary decoders, taking as inputs different perturbed versions of the encoder's output, and consequently, improving the encoder's representations. The proposed method is simple and can easily be extended to use additional training signal, such as image-level labels or pixel-level labels across different domains. We perform an ablation study to tease apart the effectiveness of each component, and conduct extensive experiments to demonstrate that our method achieves state-of-the-art results in several datasets.
Improving 3D Object Detection through Progressive Population Based Augmentation
Apr 02, 2020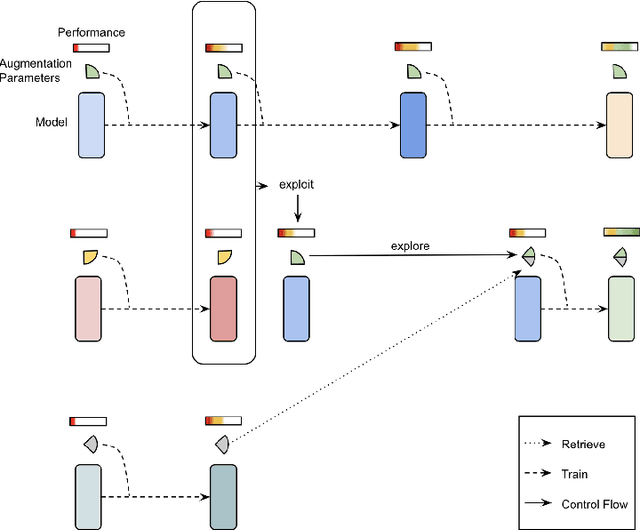
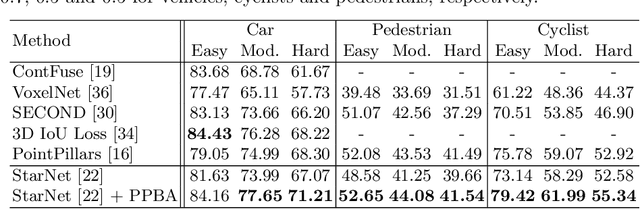

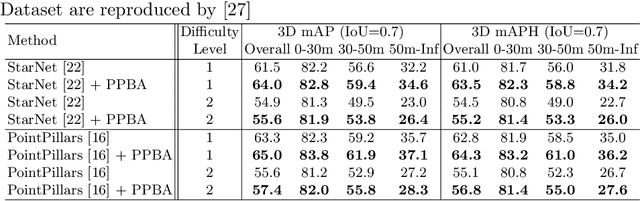
Data augmentation has been widely adopted for object detection in 3D point clouds. All previous efforts have focused on manually designing specific data augmentation methods for individual architectures, however no work has attempted to automate the design of data augmentation in 3D detection problems -- as is common in 2D image-based computer vision. In this work, we present the first attempt to automate the design of data augmentation policies for 3D object detection. We present an algorithm, termed Progressive Population Based Augmentation (PPBA). PPBA learns to optimize augmentation strategies by narrowing down the search space and adopting the best parameters discovered in previous iterations. On the KITTI test set, PPBA improves the StarNet detector by substantial margins on the moderate difficulty category of cars, pedestrians, and cyclists, outperforming all current state-of-the-art single-stage detection models. Additional experiments on the Waymo Open Dataset indicate that PPBA continues to effectively improve 3D object detection on a 20x larger dataset compared to KITTI. The magnitude of the improvements may be comparable to advances in 3D perception architectures and the gains come without an incurred cost at inference time. In subsequent experiments, we find that PPBA may be up to 10x more data efficient than baseline 3D detection models without augmentation, highlighting that 3D detection models may achieve competitive accuracy with far fewer labeled examples.
Chunkflow: Distributed Hybrid Cloud Processing of Large 3D Images by Convolutional Nets
May 02, 2019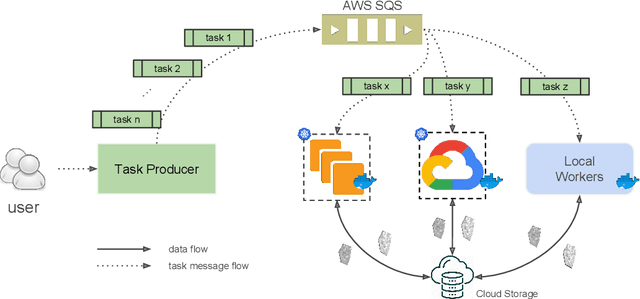
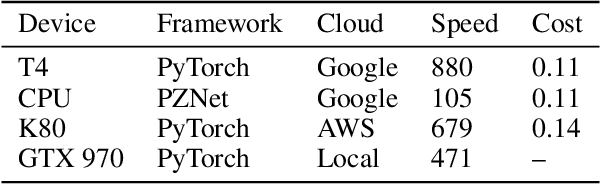
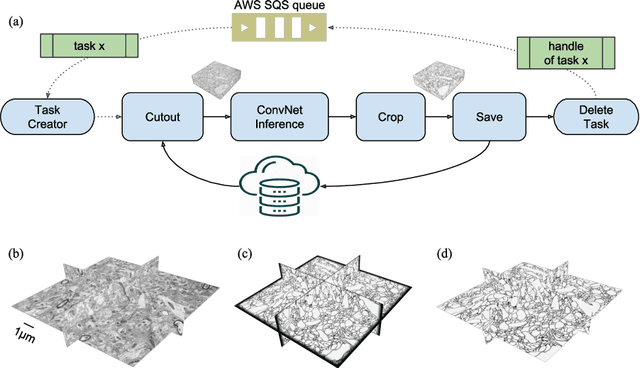
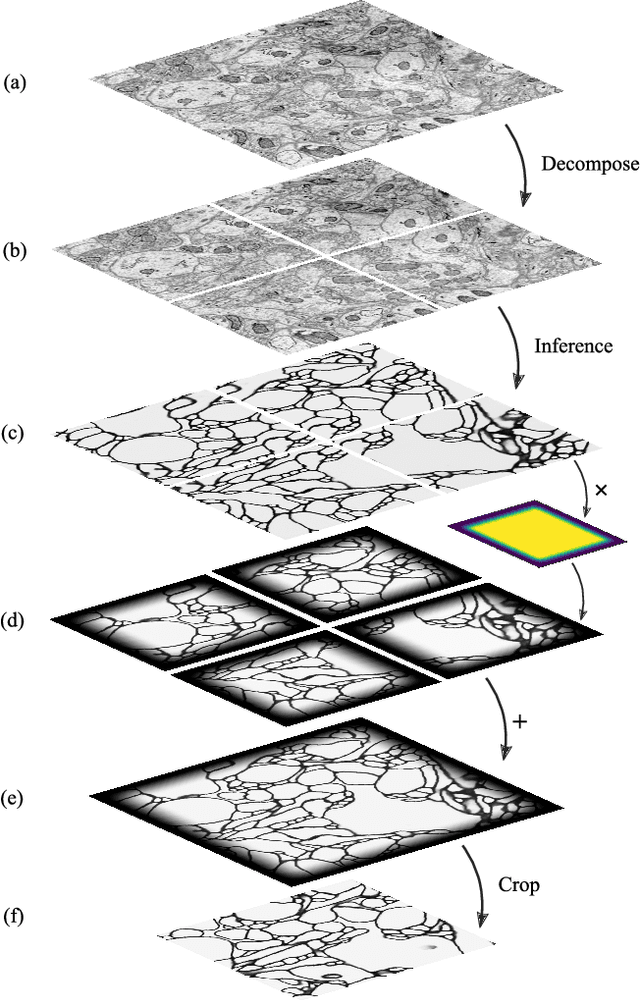
It is now common to process volumetric biomedical images using 3D Convolutional Networks (ConvNets). This can be challenging for the teravoxel and even petavoxel images that are being acquired today by light or electron microscopy. Here we introduce chunkflow, a software framework for distributing ConvNet processing over local and cloud GPUs and CPUs. The image volume is divided into overlapping chunks, each chunk is processed by a ConvNet, and the results are blended together to yield the output image. The frontend submits ConvNet tasks to a cloud queue. The tasks are executed by local and cloud GPUs and CPUs. Thanks to the fault-tolerant architecture of Chunkflow, cost can be greatly reduced by utilizing cheap unstable cloud instances. Chunkflow currently supports PyTorch for GPUs and PZnet for CPUs. To illustrate its usage, a large 3D brain image from serial section electron microscopy was processed by a 3D ConvNet with a U-Net style architecture. Chunkflow provides some chunk operations for general use, and the operations can be composed flexibly in a command line interface.