 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-Time Object Detection and Localization in Compressive Sensed Video on Embedded Hardware
Dec 23, 2019


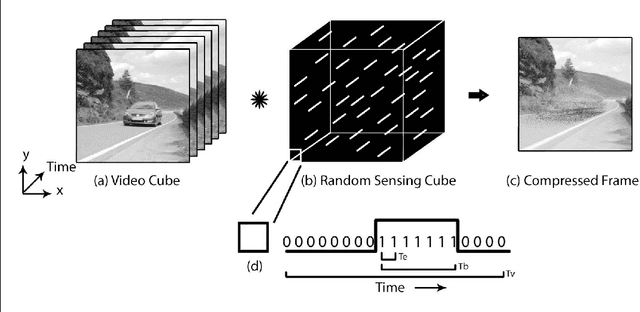

Every day around the world, interminable terabytes of data are being captured for surveillance purposes. A typical 1-2MP CCTV camera generates around 7-12GB of data per day. Frame-by-frame processing of such enormous amount of data requires hefty computational resources. In recent years, compressive sensing approaches have shown impressive results in signal processing by reducing the sampling bandwidth. Different sampling mechanisms were developed to incorporate compressive sensing in image and video acquisition. Pixel-wise coded exposure is one among the promising sensing paradigms for capturing videos in the compressed domain, which was also realized into an all-CMOS sensor \cite{Xiong2017}. Though cameras that perform compressive sensing save a lot of bandwidth at the time of sampling and minimize the memory required to store videos, we cannot do much in terms of processing until the videos are reconstructed to the original frames. But, the reconstruction of compressive-sensed (CS) videos still takes a lot of time and is also computationally expensive. In this work, we show that object detection and localization can be possible directly on the CS frames (easily upto 20x compression). To our knowledge, this is the first time that the problem of object detection and localization on CS frames has been attempted. Hence, we also created a dataset for training in the CS domain. We were able to achieve a good accuracy of 46.27\% mAP(Mean Average Precision) with the proposed model with an inference time of 23ms directly on the compressed frames(approx. 20 original domain frames), this facilitated for real-time inference which was verified on NVIDIA TX2 embedded board. Our framework will significantly reduce the communication bandwidth, and thus reduction in power as the video compression will be done at the image sensor processing core.
Fully Using Classifiers for Weakly Supervised Semantic Segmentation with Modified Cues
Apr 03, 2019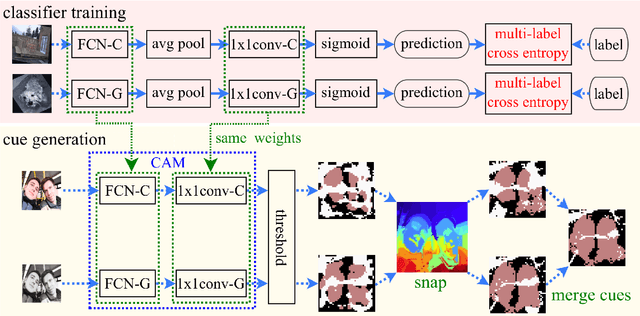
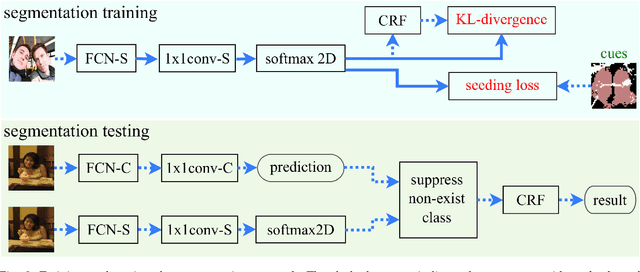
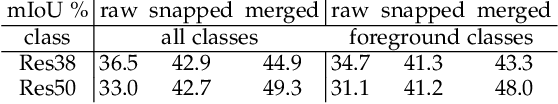
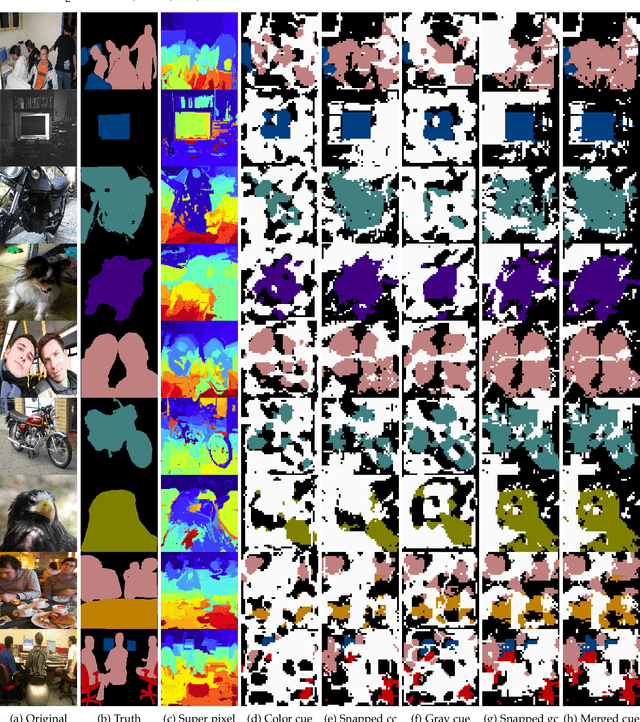
This paper proposes a novel weakly-supervised semantic segmentation method using image-level label only. The class-specific activation maps from the well-trained classifiers are used as cues to train a segmentation network. The well-known defects of these cues are coarseness and incompleteness. We use super-pixel to refine them, and fuse the cues extracted from both a color image trained classifier and a gray image trained classifier to compensate for their incompleteness. The conditional random field is adapted to regulate the training process and to refine the outputs further. Besides initializing the segmentation network, the previously trained classifier is also used in the testing phase to suppress the non-existing classes. Experimental results on the PASCAL VOC 2012 dataset illustrate the effectiveness of our method.
AttentionRNN: A Structured Spatial Attention Mechanism
May 22, 2019
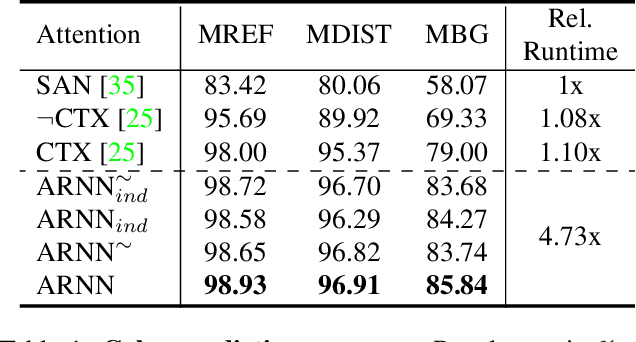
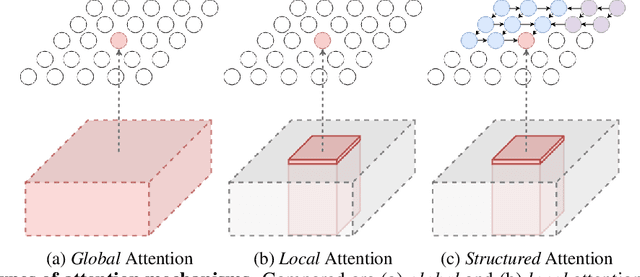
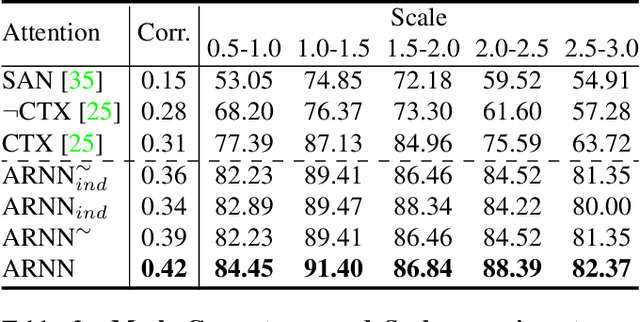
Visual attention mechanisms have proven to be integrally important constituent components of many modern deep neural architectures. They provide an efficient and effective way to utilize visual information selectively, which has shown to be especially valuable in multi-modal learning tasks. However, all prior attention frameworks lack the ability to explicitly model structural dependencies among attention variables, making it difficult to predict consistent attention masks. In this paper we develop a novel structured spatial attention mechanism which is end-to-end trainable and can be integrated with any feed-forward convolutional neural network. This proposed AttentionRNN layer explicitly enforces structure over the spatial attention variables by sequentially predicting attention values in the spatial mask in a bi-directional raster-scan and inverse raster-scan order. As a result, each attention value depends not only on local image or contextual information, but also on the previously predicted attention values. Our experiments show consistent quantitative and qualitative improvements on a variety of recognition tasks and datasets; including image categorization, question answering and image generation.
IRNet: Instance Relation Network for Overlapping Cervical Cell Segmentation
Aug 19, 2019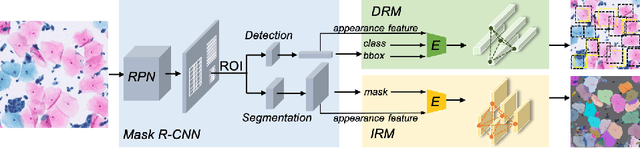
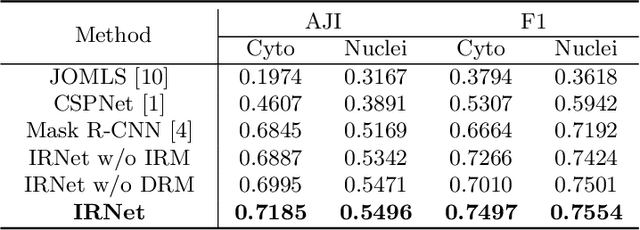
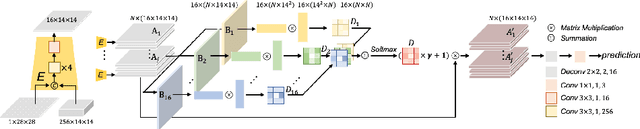
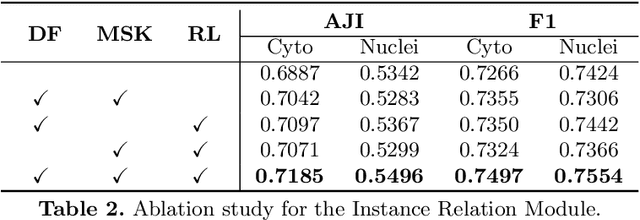
Cell instance segmentation in Pap smear image remains challenging due to the wide existence of occlusion among translucent cytoplasm in cell clumps. Conventional methods heavily rely on accurate nuclei detection results and are easily disturbed by miscellaneous objects. In this paper, we propose a novel Instance Relation Network (IRNet) for robust overlapping cell segmentation by exploring instance relation interaction. Specifically, we propose the Instance Relation Module to construct the cell association matrix for transferring information among individual cell-instance features. With the collaboration of different instances, the augmented features gain benefits from contextual information and improve semantic consistency. Meanwhile, we proposed a sparsity constrained Duplicate Removal Module to eliminate the misalignment between classification and localization accuracy for candidates selection. The largest cervical Pap smear (CPS) dataset with more than 8000 cell annotations in Pap smear image was constructed for comprehensive evaluation. Our method outperforms other methods by a large margin, demonstrating the effectiveness of exploring instance relation.
CMRNet: Camera to LiDAR-Map Registration
Jul 17, 2019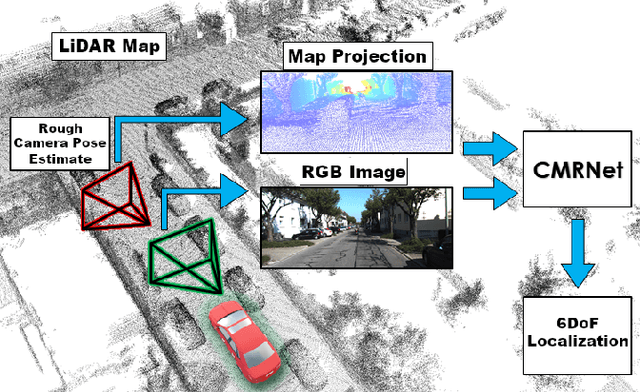


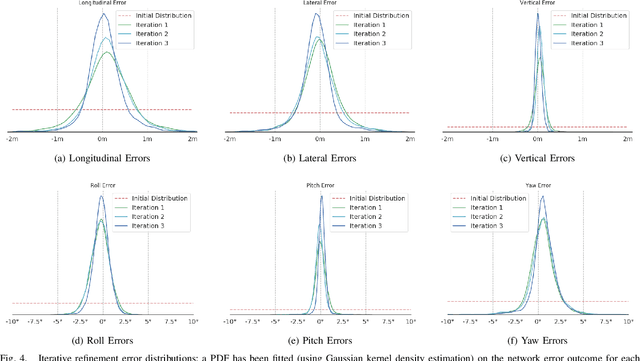
In this paper we present CMRNet, a realtime approach based on a Convolutional Neural Network to localize an RGB image of a scene in a map built from LiDAR data. Our network is not trained in the working area, i.e. CMRNet does not learn the map. Instead it learns to match an image to the map. We validate our approach on the KITTI dataset, processing each frame independently without any tracking procedure. CMRNet achieves 0.27m and 1.07deg median localization accuracy on the sequence 00 of the odometry dataset, starting from a rough pose estimate displaced up to 3.5m and 17deg. To the best of our knowledge this is the first CNN-based approach that learns to match images from a monocular camera to a given, preexisting 3D LiDAR-map.
Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
Jul 12, 2019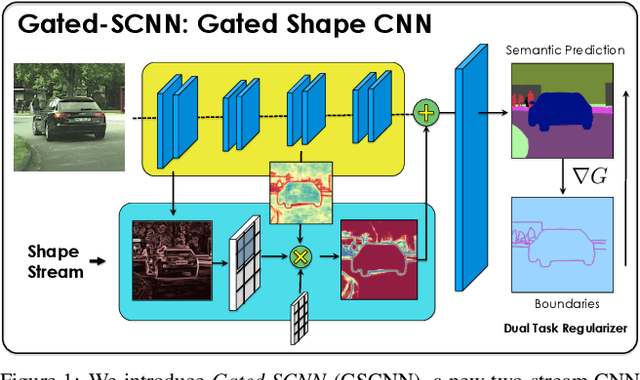
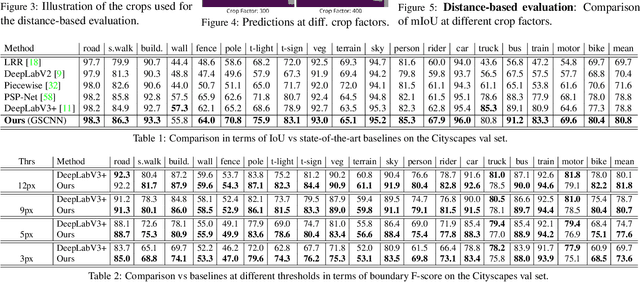
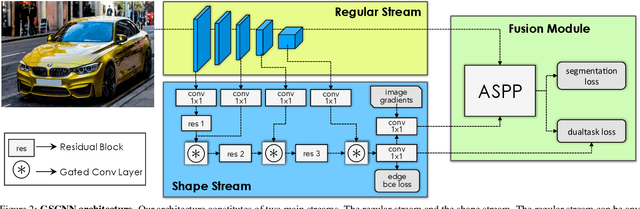

Current state-of-the-art methods for image segmentation form a dense image representation where the color, shape and texture information are all processed together inside a deep CNN. This however may not be ideal as they contain very different type of information relevant for recognition. Here, we propose a new two-stream CNN architecture for semantic segmentation that explicitly wires shape information as a separate processing branch, i.e. shape stream, that processes information in parallel to the classical stream. Key to this architecture is a new type of gates that connect the intermediate layers of the two streams. Specifically, we use the higher-level activations in the classical stream to gate the lower-level activations in the shape stream, effectively removing noise and helping the shape stream to only focus on processing the relevant boundary-related information. This enables us to use a very shallow architecture for the shape stream that operates on the image-level resolution. Our experiments show that this leads to a highly effective architecture that produces sharper predictions around object boundaries and significantly boosts performance on thinner and smaller objects. Our method achieves state-of-the-art performance on the Cityscapes benchmark, in terms of both mask (mIoU) and boundary (F-score) quality, improving by 2% and 4% over strong baselines.
Predicting Actions to Help Predict Translations
Aug 18, 2019
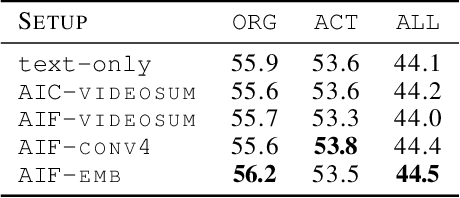


We address the task of text translation on the How2 dataset using a state of the art transformer-based multimodal approach. The question we ask ourselves is whether visual features can support the translation process, in particular, given that this is a dataset extracted from videos, we focus on the translation of actions, which we believe are poorly captured in current static image-text datasets currently used for multimodal translation. For that purpose, we extract different types of action features from the videos and carefully investigate how helpful this visual information is by testing whether it can increase translation quality when used in conjunction with (i) the original text and (ii) the original text where action-related words (or all verbs) are masked out. The latter is a simulation that helps us assess the utility of the image in cases where the text does not provide enough context about the action, or in the presence of noise in the input text.
Incremental Learning Techniques for Semantic Segmentation
Aug 08, 2019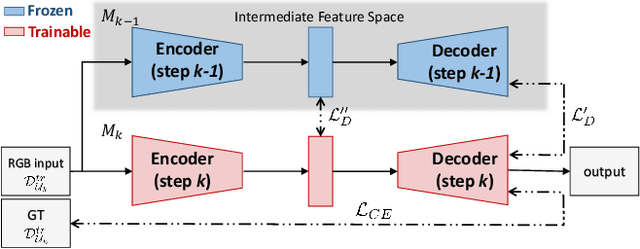
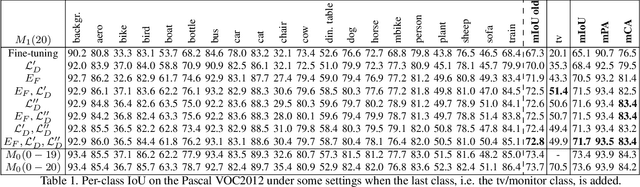
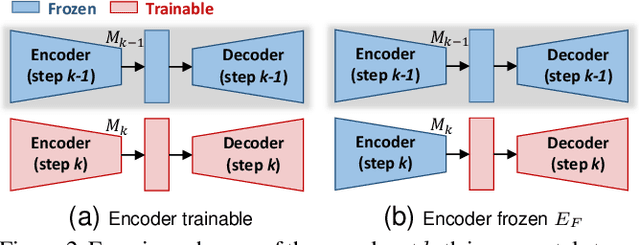
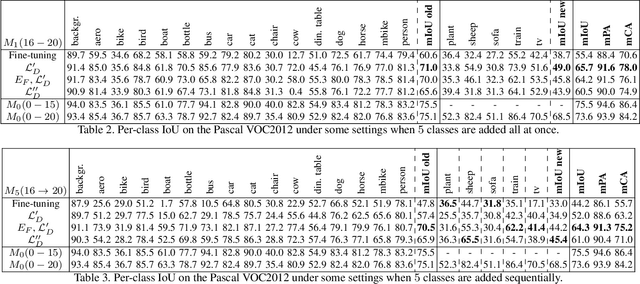
Deep learning architectures exhibit a critical drop of performance due to catastrophic forgetting when they are required to incrementally learn new tasks. Contemporary incremental learning frameworks focus on image classification and object detection while in this work we formally introduce the incremental learning problem for semantic segmentation in which a pixel-wise labeling is considered. To tackle this task we propose to distill the knowledge of the previous model to retain the information about previously learned classes, whilst updating the current model to learn the new ones. We propose various approaches working both on the output logits and on intermediate features. In opposition to some recent frameworks, we do not store any image from previously learned classes and only the last model is needed to preserve high accuracy on these classes. The experimental evaluation on the Pascal VOC2012 dataset shows the effectiveness of the proposed approaches.
* 8 pages, 3 figures, 4 tables
A New Technique of Camera Calibration: A Geometric Approach Based on Principal Lines
Aug 18, 2019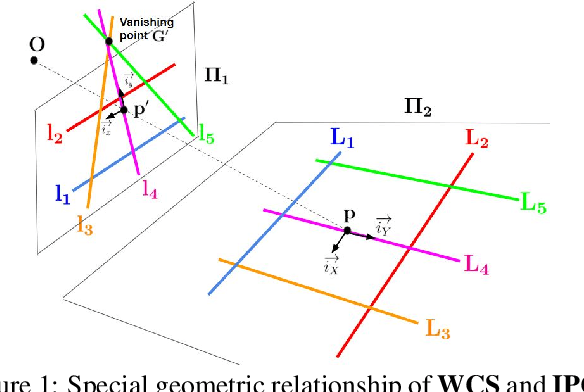
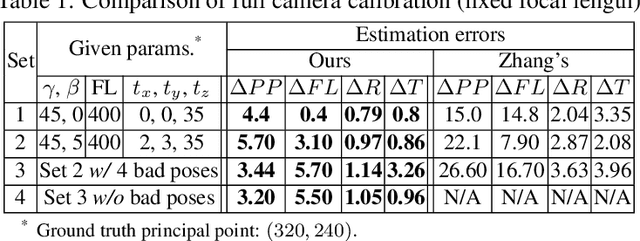
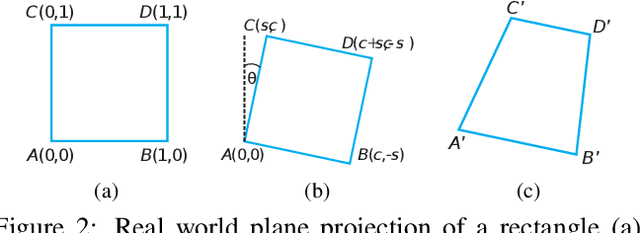
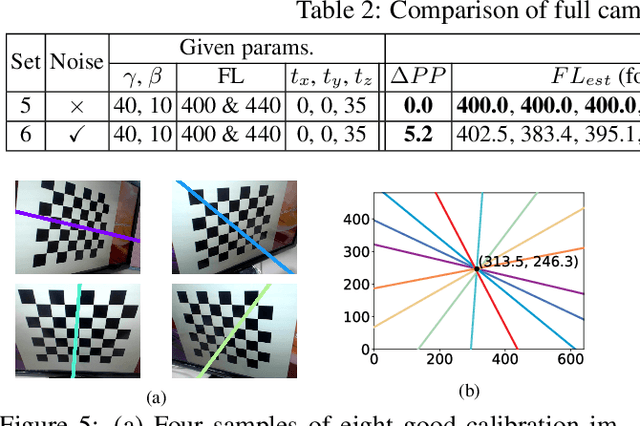
Camera calibration is a crucial prerequisite in many applications of computer vision. In this paper, a new, geometry-based camera calibration technique is proposed, which resolves two main issues associated with the widely used Zhang's method: (i) the lack of guidelines to avoid outliers in the computation and (ii) the assumption of fixed camera focal length. The proposed approach is based on the closed-form solution of principal lines (PLs), with their intersection being the principal point while each PL can concisely represent relative orientation/position (up to one degree of freedom for both) between a special pair of coordinate systems of image plane and calibration pattern. With such analytically tractable image features, computations associated with the calibration are greatly simplified, while the guidelines in (i) can be established intuitively. Experimental results for synthetic and real data show that the proposed approach does compare favorably with Zhang's method, in terms of correctness, robustness, and flexibility, and addresses issues (i) and (ii) satisfactorily.
A Clonal Selection Algorithm with Levenshtein Distance based Image Similarity in Multidimensional Subjective Tourist Information and Discovery of Cryptic Spots by Interactive GHSOM
Apr 08, 2018
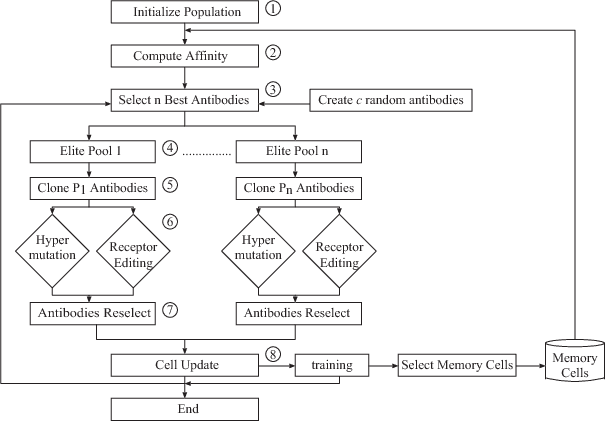
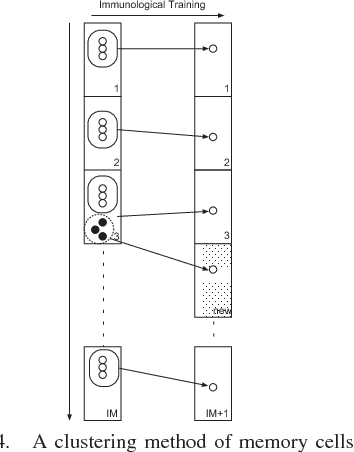
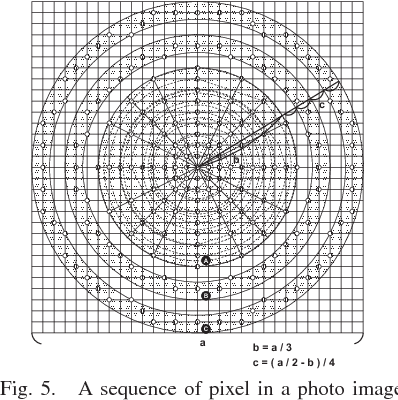
Mobile Phone based Participatory Sensing (MPPS) system involves a community of users sending personal information and participating in autonomous sensing through their mobile phones. Sensed data can also be obtained from external sensing devices that can communicate wirelessly to the phone. Our developed tourist subjective data collection system with Android smartphone can determine the filtering rules to provide the important information of sightseeing spot. The rules are automatically generated by Interactive Growing Hierarchical SOM. However, the filtering rules related to photograph were not generated, because the extraction of the specified characteristics from images cannot be realized. We propose the effective method of the Levenshtein distance to deduce the spatial proximity of image viewpoints and thus determine the specified pattern in which images should be processed. To verify the proposed method, some experiments to classify the subjective data with images are executed by Interactive GHSOM and Clonal Selection Algorithm with Immunological Memory Cells in this paper.