 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CorGAN: Correlation-Capturing Convolutional Generative Adversarial Networks for Generating Synthetic Healthcare Records
Mar 04, 2020

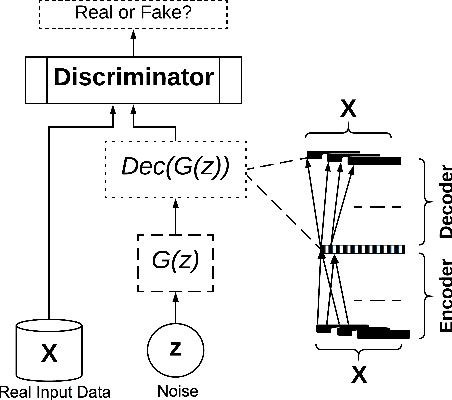


Deep learning models have demonstrated high-quality performance in areas such as image classification and speech processing. However, creating a deep learning model using electronic health record (EHR) data, requires addressing particular privacy challenges that are unique to researchers in this domain. This matter focuses attention on generating realistic synthetic data while ensuring privacy. In this paper, we propose a novel framework called correlation-capturing Generative Adversarial Network (CorGAN), to generate synthetic healthcare records. In CorGAN we utilize Convolutional Neural Networks to capture the correlations between adjacent medical features in the data representation space by combining Convolutional Generative Adversarial Networks and Convolutional Autoencoders. To demonstrate the model fidelity, we show that CorGAN generates synthetic data with performance similar to that of real data in various Machine Learning settings such as classification and prediction. We also give a privacy assessment and report on statistical analysis regarding realistic characteristics of the synthetic data. The software of this work is open-source and is available at: https://github.com/astorfi/cor-gan.
The Fashion IQ Dataset: Retrieving Images by Combining Side Information and Relative Natural Language Feedback
May 30, 2019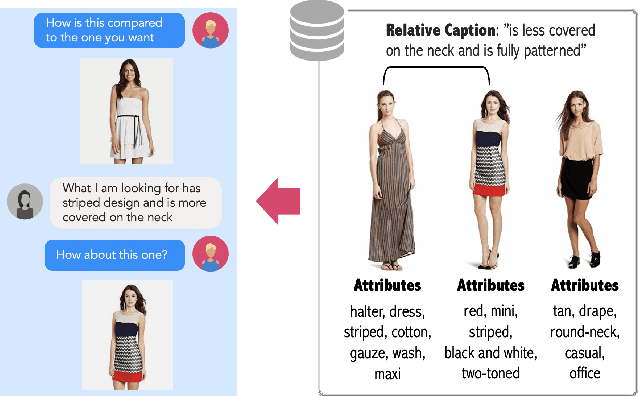
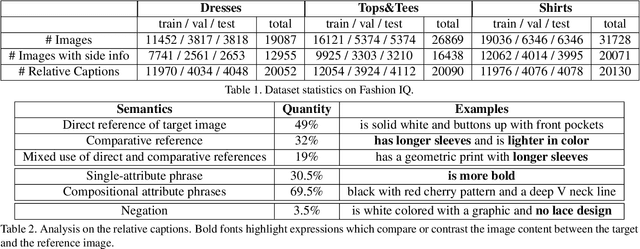
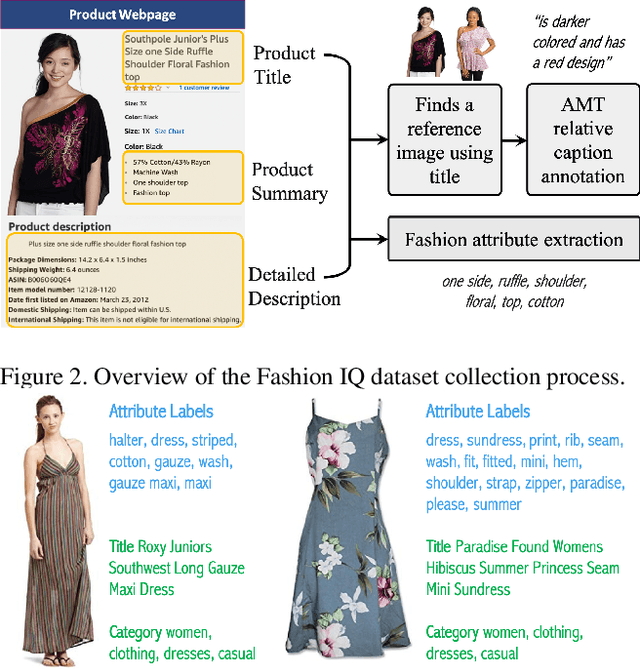
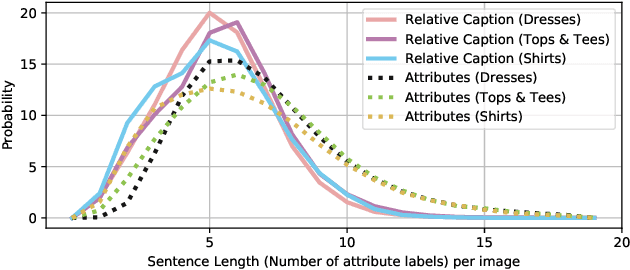
We contribute a new dataset and a novel method for natural language based fashion image retrieval. Unlike previous fashion datasets, we provide natural language annotations to facilitate the training of interactive image retrieval systems, as well as the commonly used attribute based labels. We propose a novel approach and empirically demonstrate that combining natural language feedback with visual attribute information results in superior user feedback modeling and retrieval performance relative to using either of these modalities. We believe that our dataset can encourage further work on developing more natural and real-world applicable conversational shopping assistants.
Active Bayesian Assessment for Black-Box Classifiers
Feb 16, 2020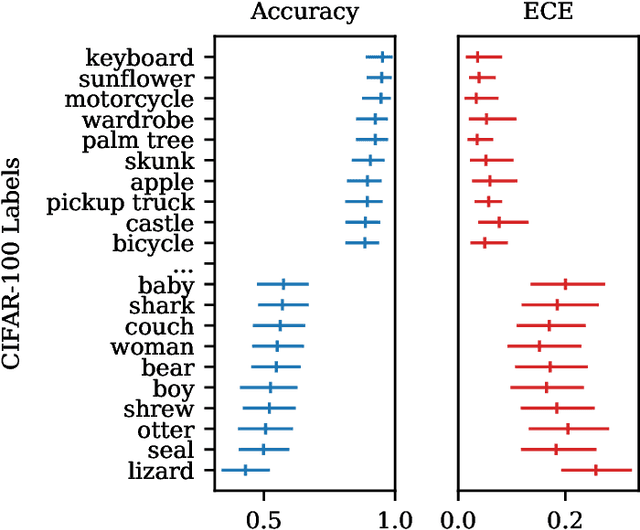
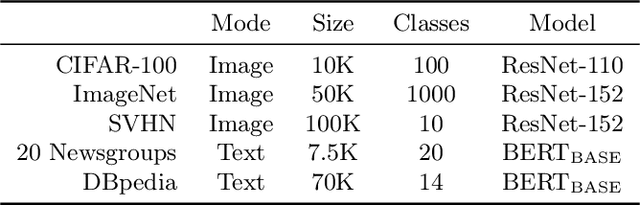
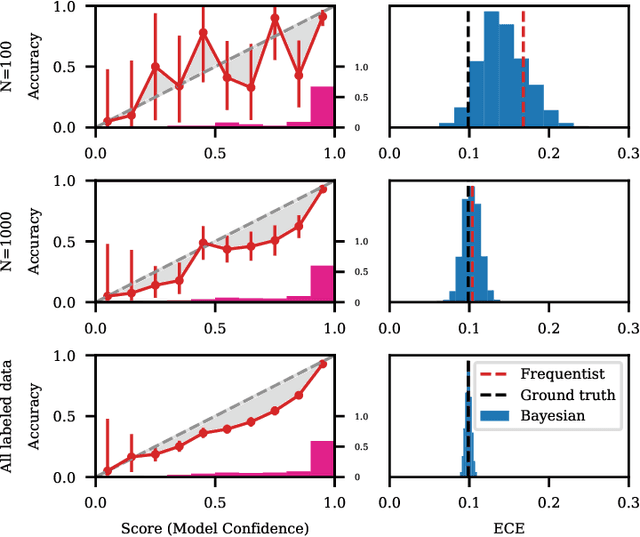

Recent advances in machine learning have led to increased deployment of black-box classifiers across a wide variety of applications. In many such situations there is a crucial need to assess the performance of these pre-trained models, for instance to ensure sufficient predictive accuracy, or that class probabilities are well-calibrated. Furthermore, since labeled data may be scarce or costly to collect, it is desirable for such assessment be performed in an efficient manner. In this paper, we introduce a Bayesian approach for model assessment that satisfies these desiderata. We develop inference strategies to quantify uncertainty for common assessment metrics (accuracy, misclassification cost, expected calibration error), and propose a framework for active assessment using this uncertainty to guide efficient selection of instances for labeling. We illustrate the benefits of our approach in experiments assessing the performance of modern neural classifiers (e.g., ResNet and BERT) on several standard image and text classification datasets.
Lane Boundary Geometry Extraction from Satellite Imagery
Feb 06, 2020



Autonomous driving car is becoming more of a reality, as a key component,high-definition(HD) maps shows its value in both market place and industry. Even though HD maps generation from LiDAR or stereo/perspective imagery has achieved impressive success, its inherent defects cannot be ignored. In this paper, we proposal a novel method for Highway HD maps modeling using pixel-wise segmentation on satellite imagery and formalized hypotheses linking, which is cheaper and faster than current HD maps modeling approaches from LiDAR point cloud and perspective view imagery, and let it becomes an ideal complementary of state of the art. We also manual code/label an HD road model dataset as ground truth, aligned with Bing tile image server, to train, test and evaluate our methodology. This dataset will be publish at same time to contribute research in HD maps modeling from aerial imagery.
Unity Style Transfer for Person Re-Identification
Mar 04, 2020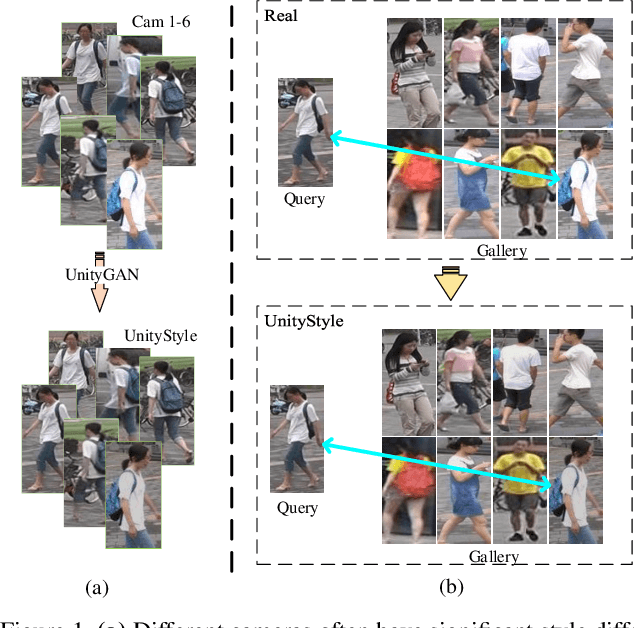
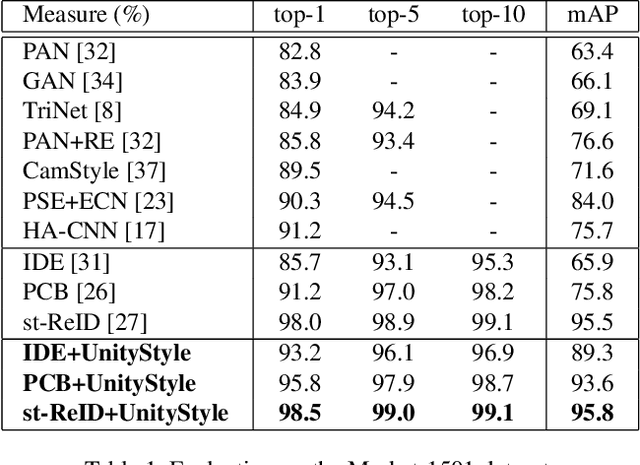

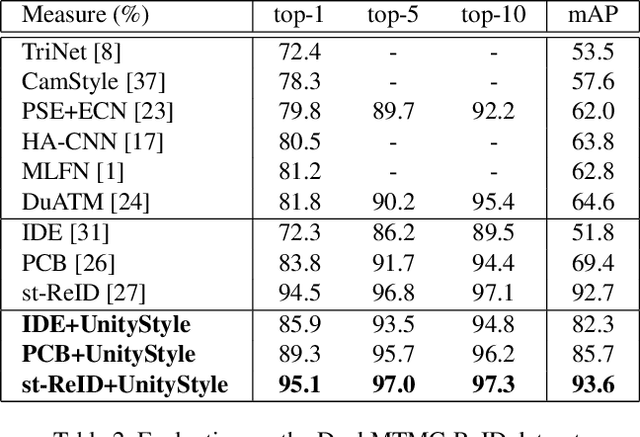
Style variation has been a major challenge for person re-identification, which aims to match the same pedestrians across different cameras. Existing works attempted to address this problem with camera-invariant descriptor subspace learning. However, there will be more image artifacts when the difference between the images taken by different cameras is larger. To solve this problem, we propose a UnityStyle adaption method, which can smooth the style disparities within the same camera and across different cameras. Specifically, we firstly create UnityGAN to learn the style changes between cameras, producing shape-stable style-unity images for each camera, which is called UnityStyle images. Meanwhile, we use UnityStyle images to eliminate style differences between different images, which makes a better match between query and gallery. Then, we apply the proposed method to Re-ID models, expecting to obtain more style-robust depth features for querying. We conduct extensive experiments on widely used benchmark datasets to evaluate the performance of the proposed framework, the results of which confirm the superiority of the proposed model.
Active Learning in Video Tracking
Jan 06, 2020
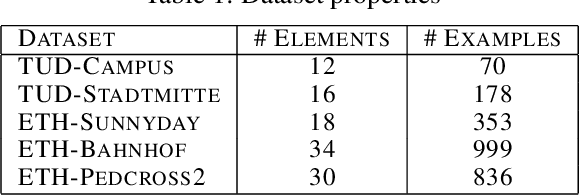
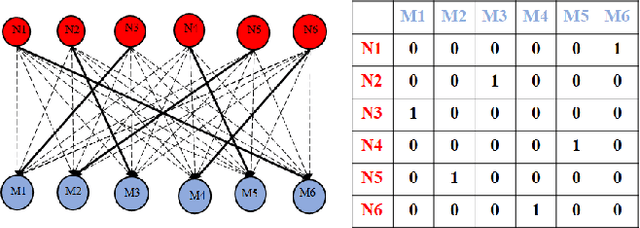
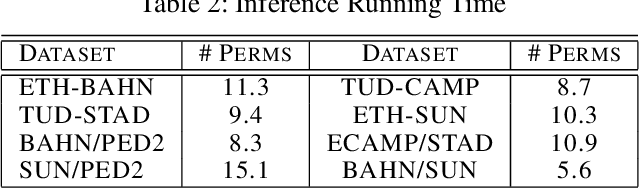
Active learning methods, like uncertainty sampling, combined with probabilistic prediction techniques have achieved success in various problems like image classification and text classification. For more complex multivariate prediction tasks, the relationships between labels play an important role in designing structured classifiers with better performance. However, computational time complexity limits prevalent probabilistic methods from effectively supporting active learning. Specifically, while non-probabilistic methods based on structured support vector machines can be tractably applied to predicting bipartite matchings, conditional random fields are intractable for these structures. We propose an adversarial approach for active learning with structured prediction domains that is tractable for matching. We evaluate this approach algorithmically in an important structured prediction problems: object tracking in videos. We demonstrate better accuracy and computational efficiency for our proposed method.
Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm
Apr 17, 2020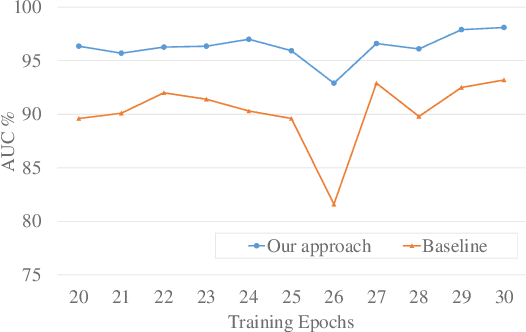

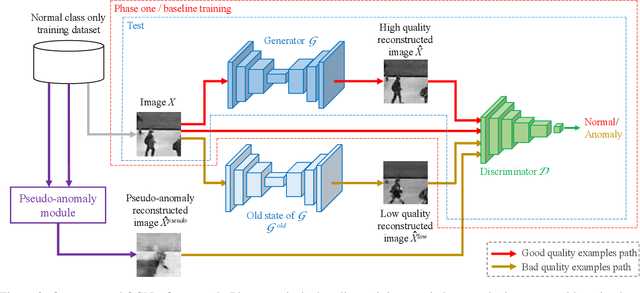

A popular method for anomaly detection is to use the generator of an adversarial network to formulate anomaly scores over reconstruction loss of input. Due to the rare occurrence of anomalies, optimizing such networks can be a cumbersome task. Another possible approach is to use both generator and discriminator for anomaly detection. However, attributed to the involvement of adversarial training, this model is often unstable in a way that the performance fluctuates drastically with each training step. In this study, we propose a framework that effectively generates stable results across a wide range of training steps and allows us to use both the generator and the discriminator of an adversarial model for efficient and robust anomaly detection. Our approach transforms the fundamental role of a discriminator from identifying real and fake data to distinguishing between good and bad quality reconstructions. To this end, we prepare training examples for the good quality reconstruction by employing the current generator, whereas poor quality examples are obtained by utilizing an old state of the same generator. This way, the discriminator learns to detect subtle distortions that often appear in reconstructions of the anomaly inputs. Extensive experiments performed on Caltech-256 and MNIST image datasets for novelty detection show superior results. Furthermore, on UCSD Ped2 video dataset for anomaly detection, our model achieves a frame-level AUC of 98.1%, surpassing recent state-of-the-art methods.
Constrained Nonnegative Matrix Factorization for Blind Hyperspectral Unmixing incorporating Endmember Independence
Apr 03, 2020
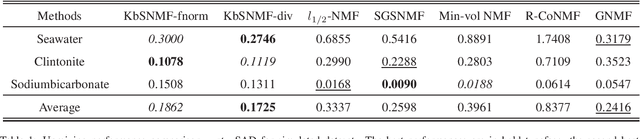
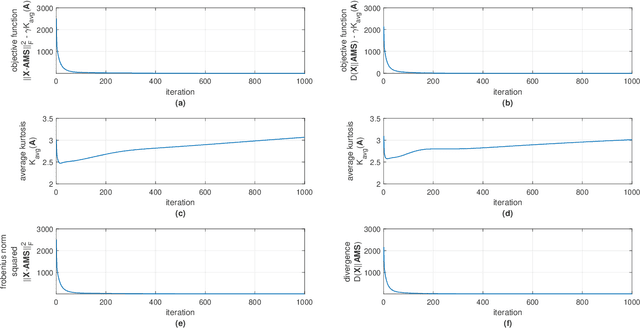
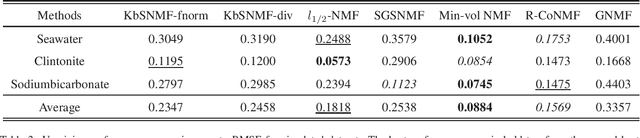
Hyperspectral unmixing (HU) has become an important technique in exploiting hyperspectral data since it decomposes a mixed pixel into a collection of endmember spectra weighted by fractional abundances. The endmembers of a hyperspectral image (HSI) are more likely to be generated by independent sources and be mixed in a macroscopic degree before arriving at the sensor element of the imaging spectrometer as mixed spectra. Over the past few decades, many attempts have focused on imposing auxiliary constraints on the conventional nonnegative matrix factorization (NMF) framework in order to effectively unmix these mixed spectra. As a promising step toward finding an optimum constraint to extract endmembers, this paper presents a novel blind HU algorithm, referred to as Kurtosis-based Smooth Nonnegative Matrix Factorization (KbSNMF) which incorporates a novel constraint based on the statistical independence of the probability density functions of endmember spectra. Imposing this constraint on the conventional NMF framework promotes the extraction of independent endmembers while further enhancing the parts-based representation of data. The proposed algorithm manages to outperform state of the art NMF-based algorithms in terms of extracting endmember spectra from hyperspectral data; therefore, it could uplift the performance of recent deep learning HU methods which utilizes the endmember spectra as supervisory input data for abundance extraction.
Domain Adaptive Transfer Attack (DATA)-based Segmentation Networks for Building Extraction from Aerial Images
Apr 29, 2020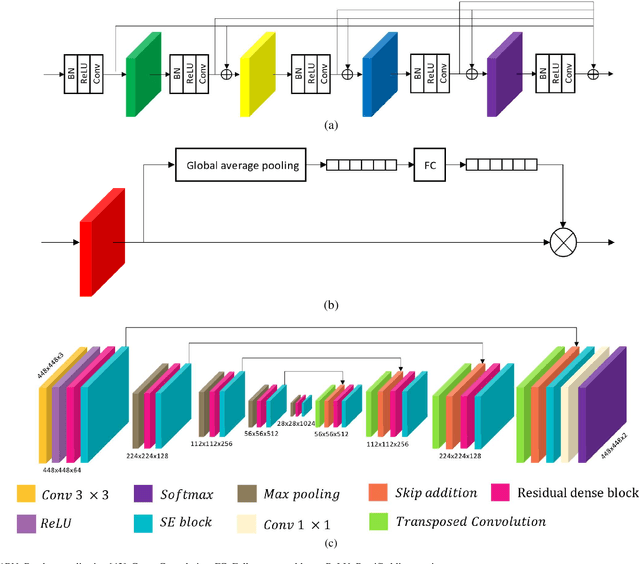



Semantic segmentation models based on convolutional neural networks (CNNs) have gained much attention in relation to remote sensing and have achieved remarkable performance for the extraction of buildings from high-resolution aerial images. However, the issue of limited generalization for unseen images remains. When there is a domain gap between the training and test datasets, CNN-based segmentation models trained by a training dataset fail to segment buildings for the test dataset. In this paper, we propose segmentation networks based on a domain adaptive transfer attack (DATA) scheme for building extraction from aerial images. The proposed system combines the domain transfer and adversarial attack concepts. Based on the DATA scheme, the distribution of the input images can be shifted to that of the target images while turning images into adversarial examples against a target network. Defending adversarial examples adapted to the target domain can overcome the performance degradation due to the domain gap and increase the robustness of the segmentation model. Cross-dataset experiments and the ablation study are conducted for the three different datasets: the Inria aerial image labeling dataset, the Massachusetts building dataset, and the WHU East Asia dataset. Compared to the performance of the segmentation network without the DATA scheme, the proposed method shows improvements in the overall IoU. Moreover, it is verified that the proposed method outperforms even when compared to feature adaptation (FA) and output space adaptation (OSA).
Pose Estimation for Texture-less Shiny Objects in a Single RGB Image Using Synthetic Training Data
Sep 23, 2019
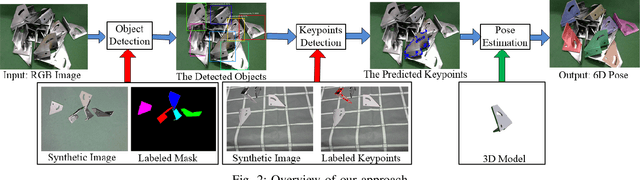


In the industrial domain, the pose estimation of multiple texture-less shiny parts is a valuable but challenging task. In this particular scenario, it is impractical to utilize keypoints or other texture information because most of them are not actual features of the target but the reflections of surroundings. Moreover, the similarity of color also poses a challenge in segmentation. In this article, we propose to divide the pose estimation process into three stages: object detection, features detection and pose optimization. A convolutional neural network was utilized to perform object detection. Concerning the reliability of surface texture, we leveraged the contour information for estimating pose. Since conventional contour-based methods are inapplicable to clustered metal parts due to the difficulties in segmentation, we use the dense discrete points along the metal part edges as semantic keypoints for contour detection. Afterward, we exploit both keypoint information and CAD model to calculate the 6D pose of each object in view. A typical implementation of deep learning methods not only requires a large amount of training data, but also relies on intensive human labor for labeling the datasets. Therefore, we propose an approach to generate datasets and label them automatically. Despite not using any real-world photos for training, a series of experiments showed that the algorithm built on synthetic data perform well in the real environment.