 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Work in Progress: Temporally Extended Auxiliary Tasks
Apr 16, 2020
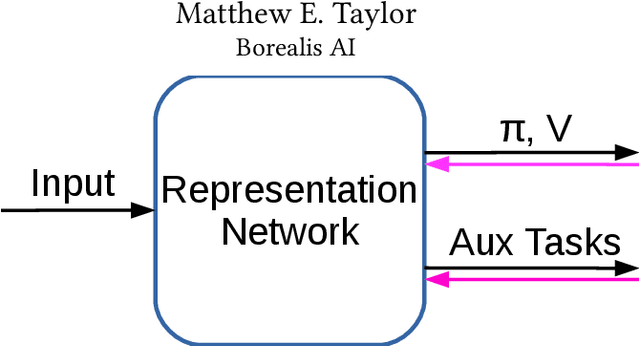

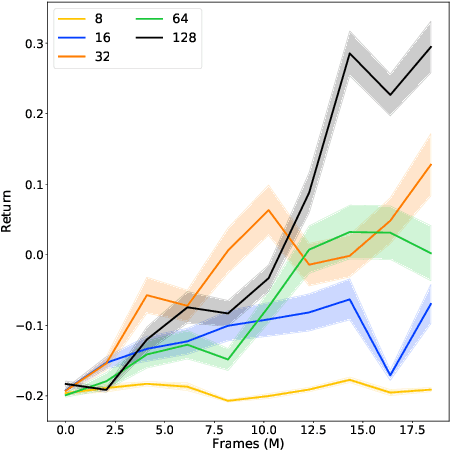
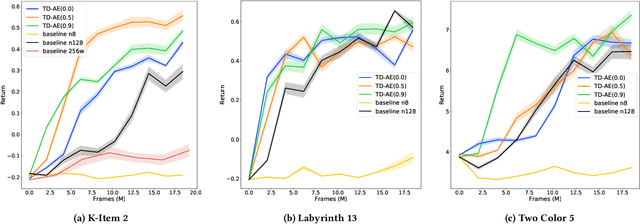
Predictive auxiliary tasks have been shown to improve performance in numerous reinforcement learning works, however, this effect is still not well understood. The primary purpose of the work presented here is to investigate the impact that an auxiliary task's prediction timescale has on the agent's policy performance. We consider auxiliary tasks which learn to make on-policy predictions using temporal difference learning. We test the impact of prediction timescale using a specific form of auxiliary task in which the input image is used as the prediction target, which we refer to as temporal difference autoencoders (TD-AE). We empirically evaluate the effect of TD-AE on the A2C algorithm in the VizDoom environment using different prediction timescales. While we do not observe a clear relationship between the prediction timescale on performance, we make the following observations: 1) using auxiliary tasks allows us to reduce the trajectory length of the A2C algorithm, 2) in some cases temporally extended TD-AE performs better than a straight autoencoder, 3) performance with auxiliary tasks is sensitive to the weight placed on the auxiliary loss, 4) despite this sensitivity, auxiliary tasks improved performance without extensive hyper-parameter tuning. Our overall conclusions are that TD-AE increases the robustness of the A2C algorithm to the trajectory length and while promising, further study is required to fully understand the relationship between auxiliary task prediction timescale and the agent's performance.
Memory-efficient Learning for Large-scale Computational Imaging
Dec 11, 2019
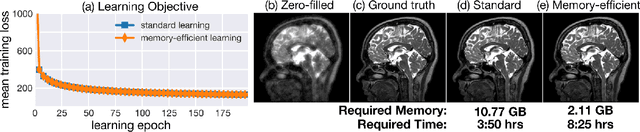
Computational imaging systems jointly design computation and hardware to retrieve information which is not traditionally accessible with standard imaging systems. Recently, critical aspects such as experimental design and image priors are optimized through deep neural networks formed by the unrolled iterations of classical physics-based reconstructions (termed physics-based networks). However, for real-world large-scale systems, computing gradients via backpropagation restricts learning due to memory limitations of graphical processing units. In this work, we propose a memory-efficient learning procedure that exploits the reversibility of the network's layers to enable data-driven design for large-scale computational imaging. We demonstrate our methods practicality on two large-scale systems: super-resolution optical microscopy and multi-channel magnetic resonance imaging.
Cap2Det: Learning to Amplify Weak Caption Supervision for Object Detection
Jul 23, 2019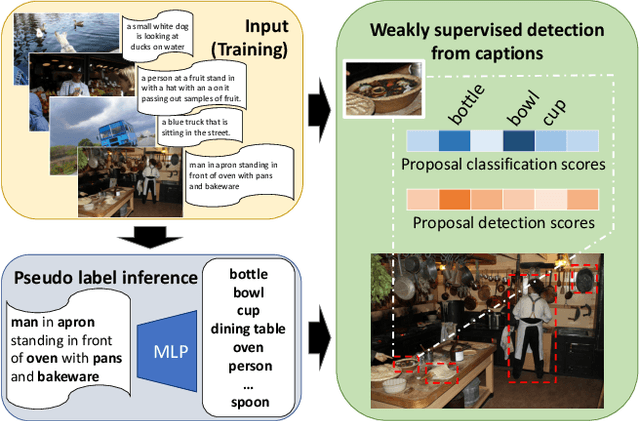
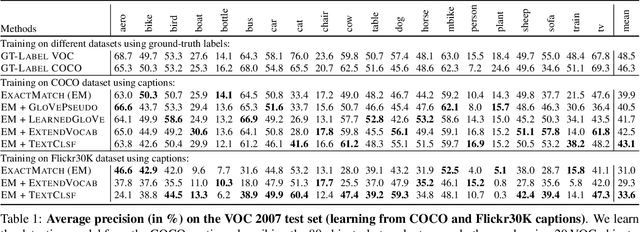
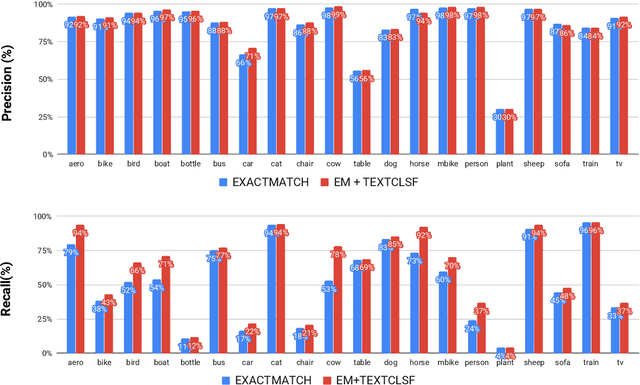
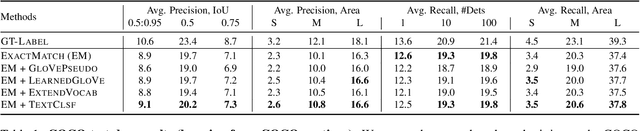
Learning to localize and name object instances is a fundamental problem in vision, but state-of-the-art approaches rely on expensive bounding box supervision. While weakly supervised detection (WSOD) methods relax the need for boxes to that of image-level annotations, even cheaper supervision is naturally available in the form of unstructured textual descriptions that users may freely provide when uploading image content. However, straightforward approaches to using such data for WSOD wastefully discard captions that do not exactly match object names. Instead, we show how to squeeze the most information out of these captions by training a text-only classifier that generalizes beyond dataset boundaries. Our discovery provides an opportunity for learning detection models from noisy but more abundant and freely-available caption data. We also validate our model on three classic object detection benchmarks and achieve state-of-the-art WSOD performance.
Semantic Change Pattern Analysis
Mar 07, 2020
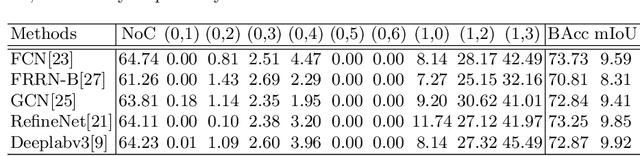
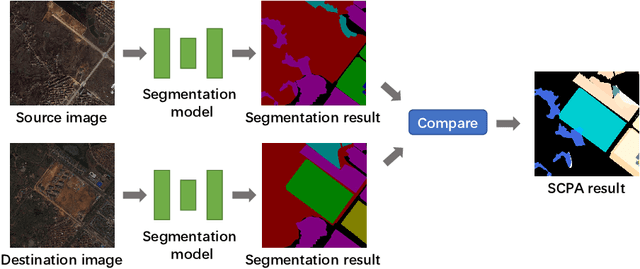
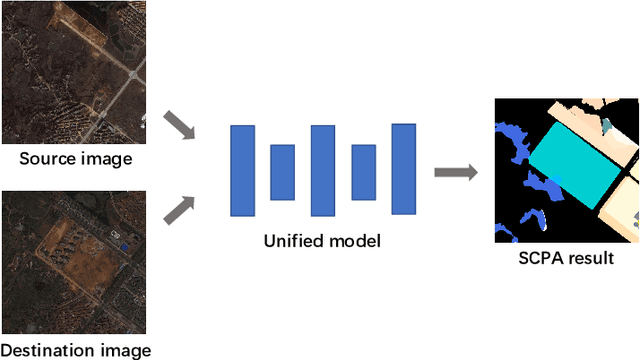
Change detection is an important problem in vision field, especially for aerial images. However, most works focus on traditional change detection, i.e., where changes happen, without considering the change type information, i.e., what changes happen. Although a few works have tried to apply semantic information to traditional change detection, they either only give the label of emerging objects without taking the change type into consideration, or set some kinds of change subjectively without specifying semantic information. To make use of semantic information and analyze change types comprehensively, we propose a new task called semantic change pattern analysis for aerial images. Given a pair of co-registered aerial images, the task requires a result including both where and what changes happen. We then describe the metric adopted for the task, which is clean and interpretable. We further provide the first well-annotated aerial image dataset for this task. Extensive baseline experiments are conducted as reference for following works. The aim of this work is to explore high-level information based on change detection and facilitate the development of this field with the publicly available dataset.
Adversarial-Based Knowledge Distillation for Multi-Model Ensemble and Noisy Data Refinement
Aug 22, 2019
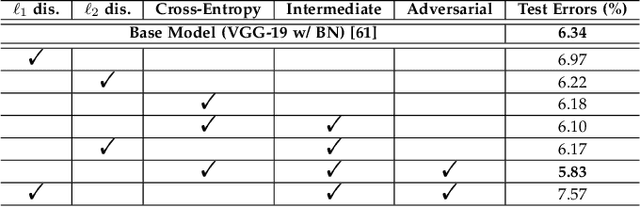
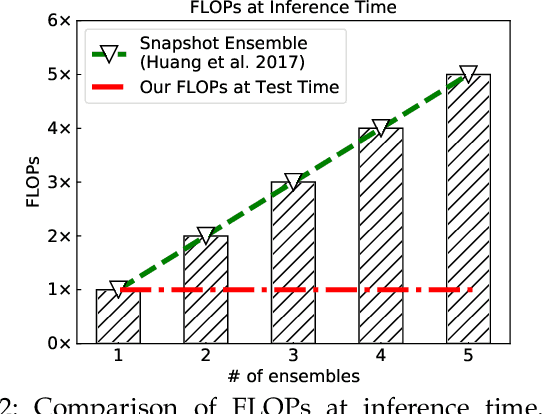
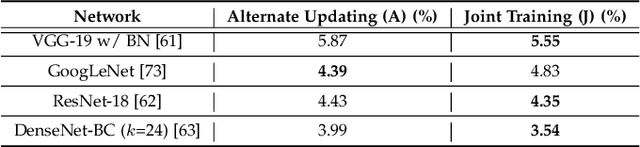
Generic Image recognition is a fundamental and fairly important visual problem in computer vision. One of the major challenges of this task lies in the fact that single image usually has multiple objects inside while the labels are still one-hot, another one is noisy and sometimes missing labels when annotated by humans. In this paper, we focus on tackling these challenges accompanying with two different image recognition problems: multi-model ensemble and noisy data recognition with a unified framework. As is well-known, usually the best performing deep neural models are ensembles of multiple base-level networks, as it can mitigate the variation or noise containing in the dataset. Unfortunately, the space required to store these many networks, and the time required to execute them at runtime, prohibit their use in applications where test sets are large (e.g., ImageNet). In this paper, we present a method for compressing large, complex trained ensembles into a single network, where the knowledge from a variety of trained deep neural networks (DNNs) is distilled and transferred to a single DNN. In order to distill diverse knowledge from different trained (teacher) models, we propose to use adversarial-based learning strategy where we define a block-wise training loss to guide and optimize the predefined student network to recover the knowledge in teacher models, and to promote the discriminator network to distinguish teacher vs. student features simultaneously. Extensive experiments on CIFAR-10/100, SVHN, ImageNet and iMaterialist Challenge Dataset demonstrate the effectiveness of our MEAL method. On ImageNet, our ResNet-50 based MEAL achieves top-1/5 21.79%/5.99% val error, which outperforms the original model by 2.06%/1.14%. On iMaterialist Challenge Dataset, our MEAL obtains a remarkable improvement of top-3 1.15% (official evaluation metric) on a strong baseline model of ResNet-101.
$ N^4 $-Fields: Neural Network Nearest Neighbor Fields for Image Transforms
Jul 03, 2014
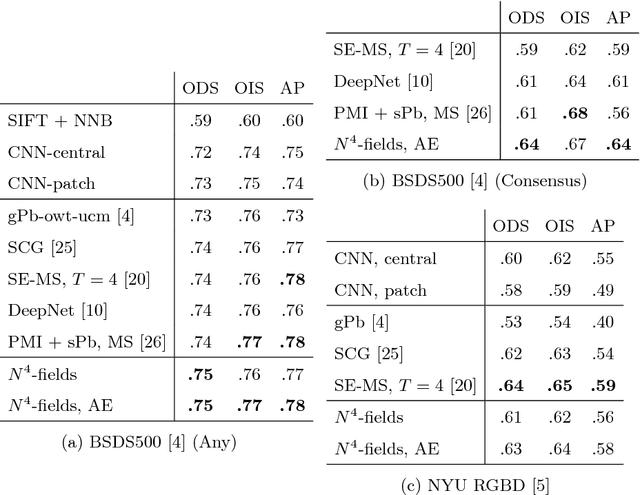
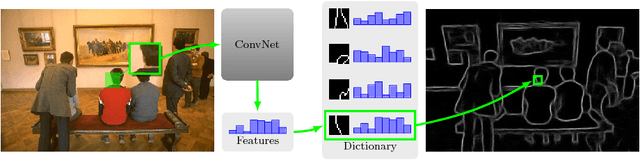

We propose a new architecture for difficult image processing operations, such as natural edge detection or thin object segmentation. The architecture is based on a simple combination of convolutional neural networks with the nearest neighbor search. We focus our attention on the situations when the desired image transformation is too hard for a neural network to learn explicitly. We show that in such situations, the use of the nearest neighbor search on top of the network output allows to improve the results considerably and to account for the underfitting effect during the neural network training. The approach is validated on three challenging benchmarks, where the performance of the proposed architecture matches or exceeds the state-of-the-art.
Old is $\mathbf{\mathcal{G}^{old}}$: Redefining the Adversarially Learned One-Class Classifier Training Paradigm
Apr 16, 2020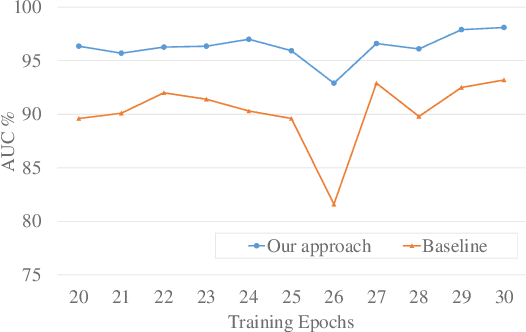

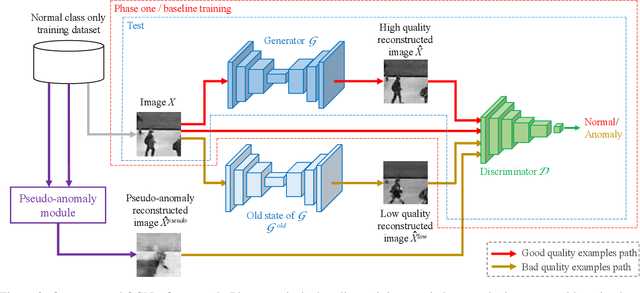

A popular method for anomaly detection is \bluetwo{to use} \blue{the} generator of an adversarial network to formulate anomaly score over reconstruction loss of input. Due to the rare occurrence of anomalies, optimizing such networks can be a cumbersome task. Another possible approach is to use both generator and discriminator for anomaly detection. However, attributed to the involvement of adversarial training, this model is often unstable in a way that the performance fluctuates drastically with each training step. In this \bluetwo{study}, we propose a framework that effectively generates stable results across a wide range of training steps and allows us to use both \blue{the} generator and the discriminator of an adversarial model for efficient and robust anomaly detection. Our approach transforms the fundamental role of a discriminator from identifying real and fake data to distinguishing between good and bad quality reconstructions. To this end, we prepare training examples for the good quality reconstruction by employing the current generator, whereas poor quality examples are obtained by utilizing an old state of the same generator. This way, the discriminator learns to detect subtle distortions that often appear in reconstructions of the anomaly inputs. Extensive experiments performed on Caltech-256 and MNIST image datasets for novelty detection show superior results. Furthermore, on UCSD Ped2 video dataset for anomaly detection, our model achieves a frame-level AUC of 98.1\%, surpassing recent state-of-the-art methods.
RF Sensing for Continuous Monitoring of Human Activities for Home Consumer Applications
Mar 21, 2020


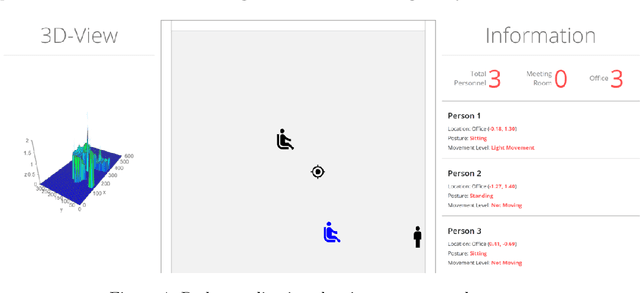
Radar for indoor monitoring is an emerging area of research and development, covering and supporting different health and wellbeing applications of smart homes, assisted living, and medical diagnosis. We report on a successful RF sensing system for home monitoring applications. The system recognizes Activities of Daily Living(ADL) and detects unique motion characteristics, using data processing and training algorithms. We also examine the challenges of continuously monitoring various human activities which can be categorized into translation motions (active mode) and in-place motions (resting mode). We use the range-map, offered by a range-Doppler radar, to obtain the transition time between these two categories, characterized by changing and constant range values, respectively. This is achieved using the Radon transform that identifies straight lines of different slopes in the range-map image. Over the in-place motion time intervals, where activities have insignificant or negligible range swath, power threshold of the radar return micro-Doppler signatures,which is employed to define the time-spans of individual activities with insignificant or negligible range swath. Finding both the transition times and the time-spans of the different motions leads to improved classifications, as it avoids decisions rendered over time windows covering mixed activities.
* 12 pages
Skill Analysis with Time Series Image Data
Jan 21, 2014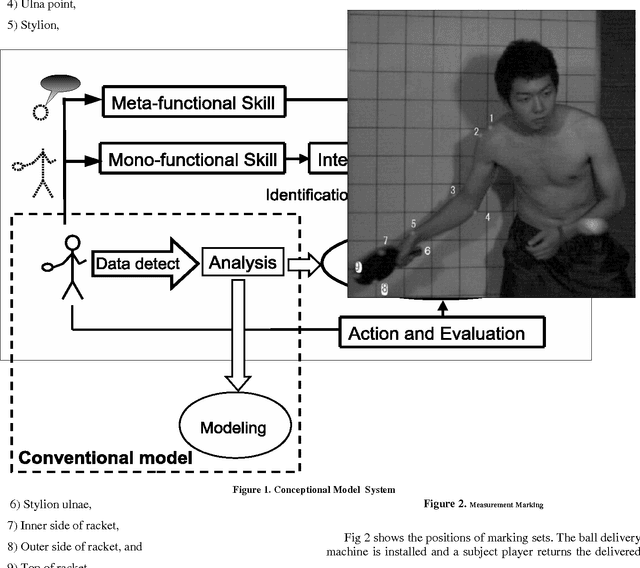
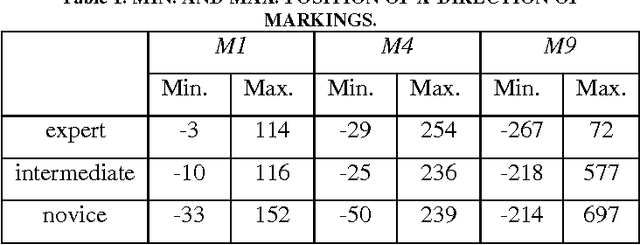

We present a skill analysis with time series image data using data mining methods, focused on table tennis. We do not use body model, but use only hi-speed movies, from which time series data are obtained and analyzed using data mining methods such as C4.5 and so on. We identify internal models for technical skills as evaluation skillfulness for the forehand stroke of table tennis, and discuss mono and meta-functional skills for improving skills.
* 5 pages, 6 figures
A Comparative Study of Histogram Equalization Based Image Enhancement Techniques for Brightness Preservation and Contrast Enhancement
Nov 16, 2013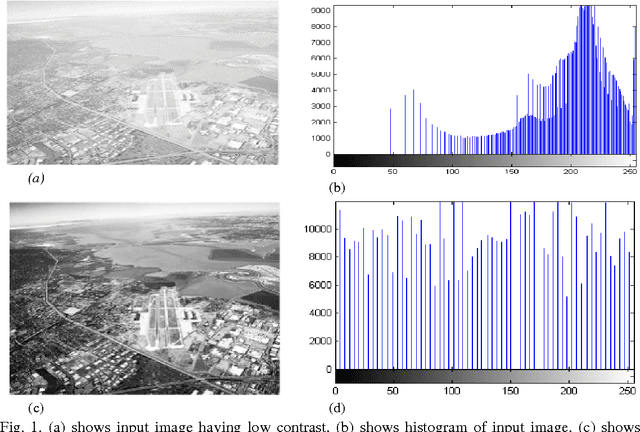


Histogram Equalization is a contrast enhancement technique in the image processing which uses the histogram of image. However histogram equalization is not the best method for contrast enhancement because the mean brightness of the output image is significantly different from the input image. There are several extensions of histogram equalization has been proposed to overcome the brightness preservation challenge. Contrast enhancement using brightness preserving bi-histogram equalization (BBHE) and Dualistic sub image histogram equalization (DSIHE) which divides the image histogram into two parts based on the input mean and median respectively then equalizes each sub histogram independently. This paper provides review of different popular histogram equalization techniques and experimental study based on the absolute mean brightness error (AMBE), peak signal to noise ratio (PSNR), Structure similarity index (SSI) and Entropy.
* 15 pages, 5 figures, 4 tables, Signal & Image Processing : An International Journal (SIPIJ)