 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
No-reference image quality assessment through the von Mises distribution
Feb 14, 2012
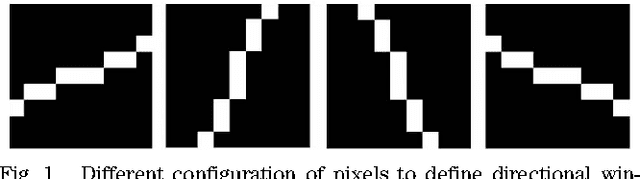

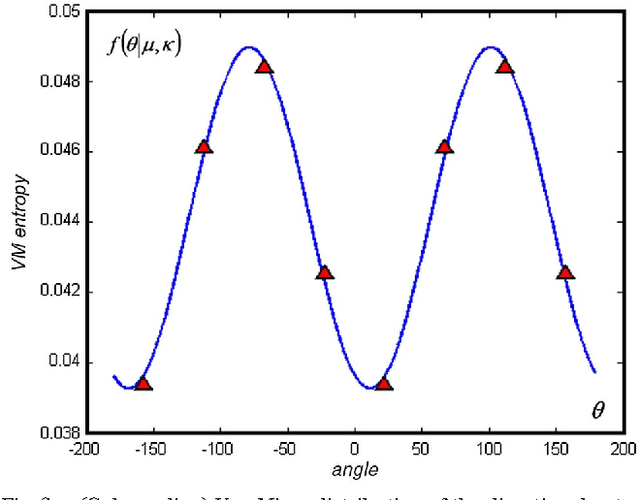

An innovative way of calculating the von Mises distribution (VMD) of image entropy is introduced in this paper. The VMD's concentration parameter and some fitness parameter that will be later defined, have been analyzed in the experimental part for determining their suitability as a image quality assessment measure in some particular distortions such as Gaussian blur or additive Gaussian noise. To achieve such measure, the local R\'{e}nyi entropy is calculated in four equally spaced orientations and used to determine the parameters of the von Mises distribution of the image entropy. Considering contextual images, experimental results after applying this model show that the best-in-focus noise-free images are associated with the highest values for the von Mises distribution concentration parameter and the highest approximation of image data to the von Mises distribution model. Our defined von Misses fitness parameter experimentally appears also as a suitable no-reference image quality assessment indicator for no-contextual images.
Image classification based on support vector machine and the fusion of complementary features
Nov 05, 2015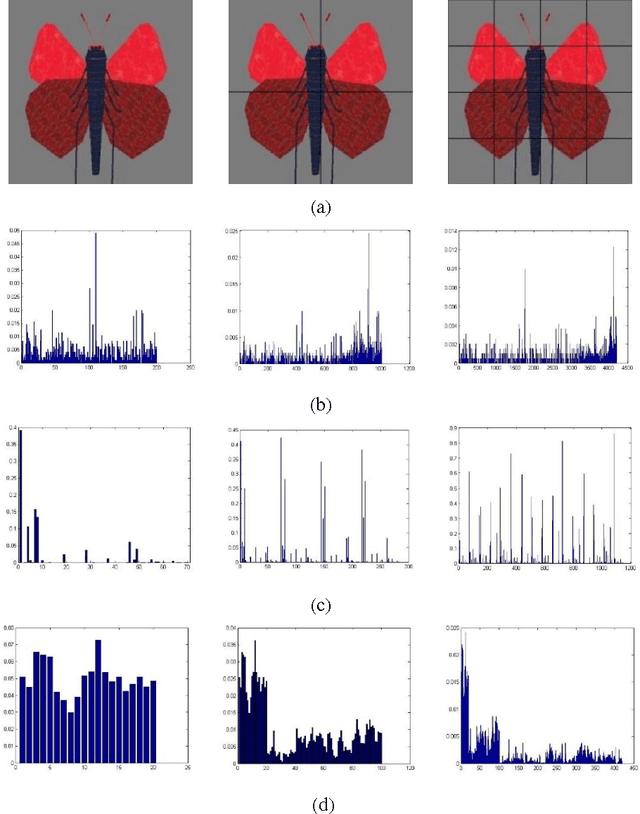
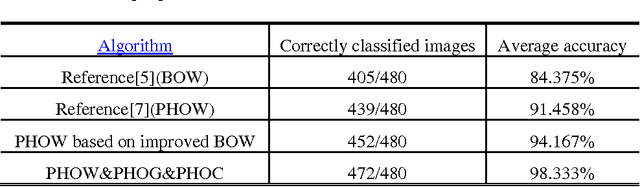
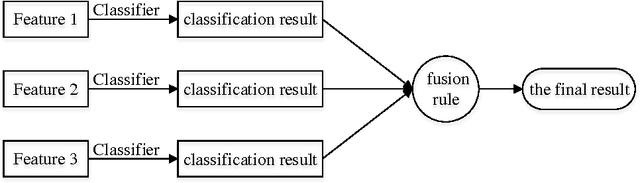
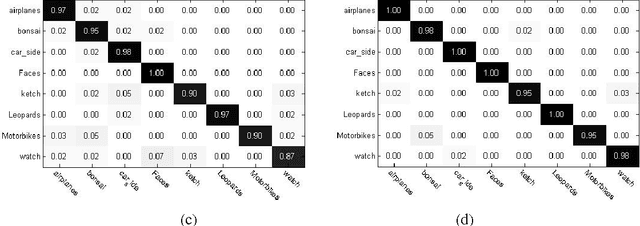
Image Classification based on BOW (Bag-of-words) has broad application prospect in pattern recognition field but the shortcomings are existed because of single feature and low classification accuracy. To this end we combine three ingredients: (i) Three features with functions of mutual complementation are adopted to describe the images, including PHOW (Pyramid Histogram of Words), PHOC (Pyramid Histogram of Color) and PHOG (Pyramid Histogram of Orientated Gradients). (ii) The improvement of traditional BOW model is presented by using dense sample and an improved K-means clustering method for constructing the visual dictionary. (iii) An adaptive feature-weight adjusted image categorization algorithm based on the SVM and the fusion of multiple features is adopted. Experiments carried out on Caltech 101 database confirm the validity of the proposed approach. From the experimental results can be seen that the classification accuracy rate of the proposed method is improved by 7%-17% higher than that of the traditional BOW methods. This algorithm makes full use of global, local and spatial information and has significant improvements to the classification accuracy.
Reconstructing continuously heterogeneous structures from single particle cryo-EM with deep generative models
Sep 11, 2019
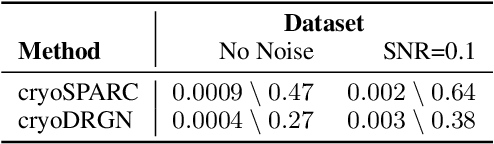
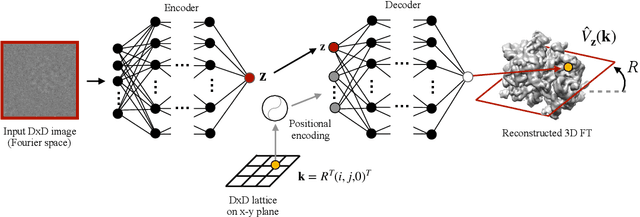
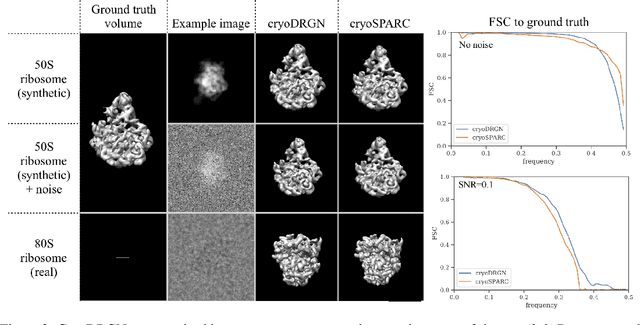
Cryo-electron microscopy (cryo-EM) is a powerful technique for determining the structure of proteins and other macromolecular complexes at near-atomic resolution. In single particle cryo-EM, the central problem is to reconstruct the three-dimensional structure of a macromolecule from $10^{4-7}$ noisy and randomly oriented two-dimensional projections. However, the imaged protein complexes may exhibit structural variability, which complicates reconstruction and is typically addressed using discrete clustering approaches that fail to capture the full range of protein dynamics. Here, we introduce a novel method for cryo-EM reconstruction that extends naturally to modeling continuous generative factors of structural heterogeneity. This method encodes structures in Fourier space using coordinate-based deep neural networks, and trains these networks from unlabeled 2D cryo-EM images by combining exact inference over image orientation with variational inference for structural heterogeneity. We demonstrate that the proposed method, termed cryoDRGN, can perform ab initio reconstruction of 3D protein complexes from simulated and real 2D cryo-EM image data. To our knowledge, cryoDRGN is the first neural network-based approach for cryo-EM reconstruction and the first end-to-end method for directly reconstructing continuous ensembles of protein structures from cryo-EM images.
Adversarial Pyramid Network for Video Domain Generalization
Dec 08, 2019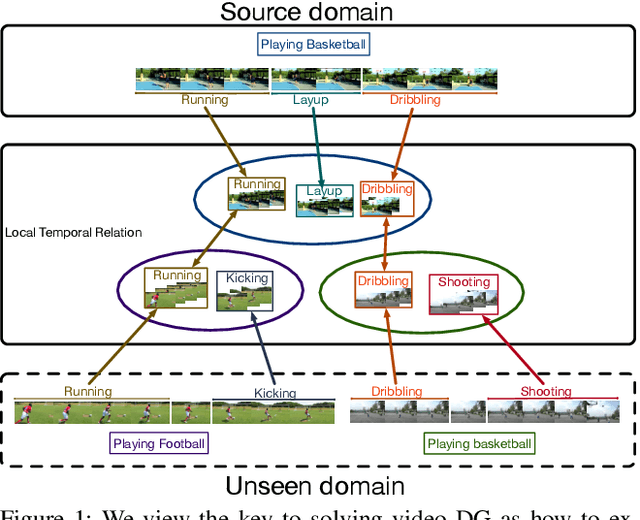
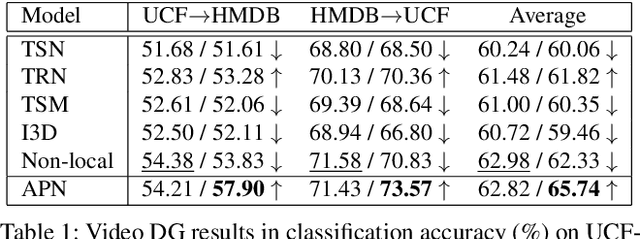
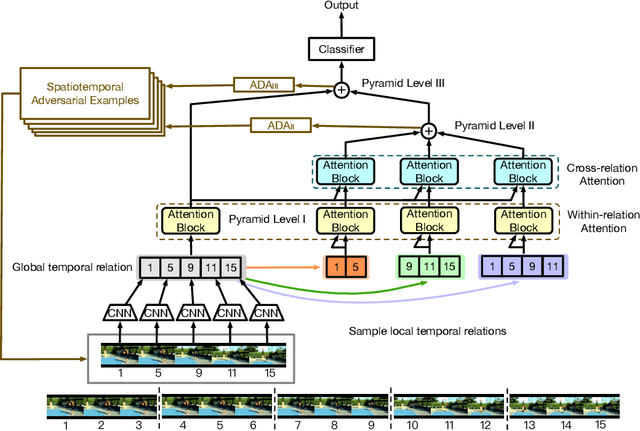

This paper introduces a new research problem of video domain generalization (video DG) where most state-of-the-art action recognition networks degenerate due to the lack of exposure to the target domains of divergent distributions. While recent advances in video understanding focus on capturing the temporal relations of the long-term video context, we observe that the global temporal features are less generalizable in the video DG settings. The reason is that videos from other unseen domains may have unexpected absence, misalignment, or scale transformation of the temporal relations, which is known as the temporal domain shift. Therefore, the video DG is even more challenging than the image DG, which is also under-explored, because of the entanglement of the spatial and temporal domain shifts. This finding has led us to view the key to video DG as how to effectively learn the local-relation features of different time scales that are more generalizable, and how to exploit them along with the global-relation features to maintain the discriminability. This paper presents the Adversarial Pyramid Network (APN), which captures the local-relation, global-relation, and multilayer cross-relation features progressively. This pyramid network not only improves the feature transferability from the view of representation learning, but also enhances the diversity and quality of the new data points that can bridge different domains when it is integrated with an improved version of the image DG adversarial data augmentation method. We construct four video DG benchmarks: UCF-HMDB, Something-Something, PKU-MMD, and NTU, in which the source and target domains are divided according to different datasets, different consequences of actions, or different camera views. The APN consistently outperforms previous action recognition models over all benchmarks.
BCD-Net for Low-dose CT Reconstruction: Acceleration, Convergence, and Generalization
Aug 04, 2019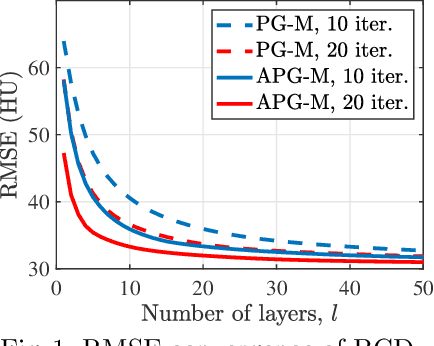

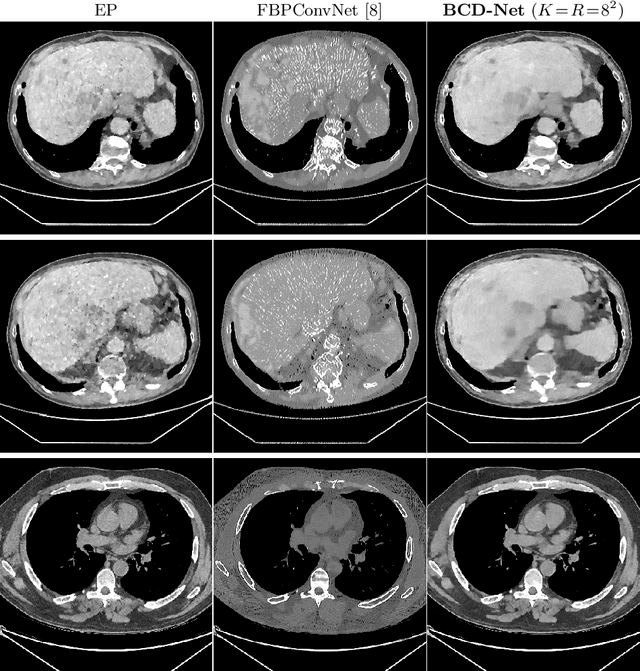
Obtaining accurate and reliable images from low-dose computed tomography (CT) is challenging. Regression convolutional neural network (CNN) models that are learned from training data are increasingly gaining attention in low-dose CT reconstruction. This paper modifies the architecture of an iterative regression CNN, BCD-Net, for fast, stable, and accurate low-dose CT reconstruction, and presents the convergence property of the modified BCD-Net. Numerical results with phantom data show that applying faster numerical solvers to model-based image reconstruction (MBIR) modules of BCD-Net leads to faster and more accurate BCD-Net; BCD-Net significantly improves the reconstruction accuracy, compared to the state-of-the-art MBIR method using learned transforms; BCD-Net achieves better image quality, compared to a state-of-the-art iterative NN architecture, ADMM-Net. Numerical results with clinical data show that BCD-Net generalizes significantly better than a state-of-the-art deep (non-iterative) regression NN, FBPConvNet, that lacks MBIR modules.
ResDepth: Learned Residual Stereo Reconstruction
Jan 22, 2020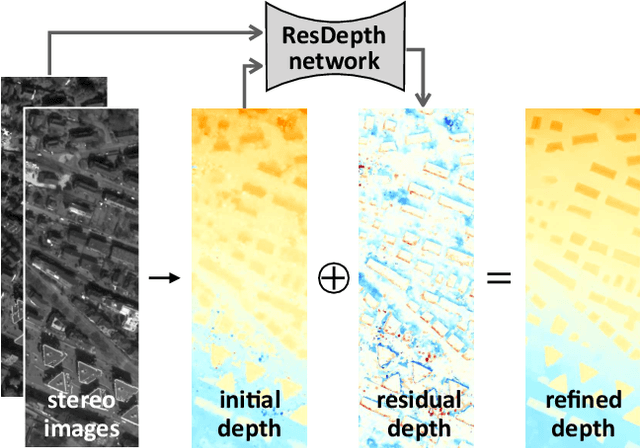

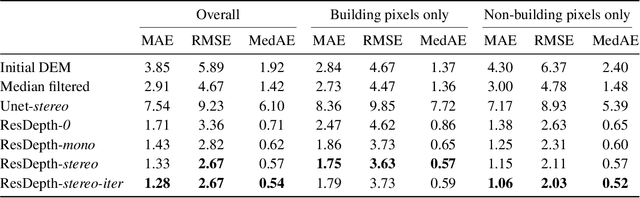

We propose an embarrassingly simple, but very effective scheme for high-quality dense stereo reconstruction: (i) generate an approximate reconstruction with your favourite stereo matcher; (ii) rewarp the input images with that approximate model; and (iii) with the initial reconstruction and the warped images as input, train a deep network to enhance the reconstruction by regressing a residual correction. The strategy to only learn the residual greatly simplifies the learning problem. A standard Unet without bells and whistles is enough to reconstruct even small surface details, like dormers and roof substructures in satellite images. We also investigate residual reconstruction with less information and find that even a single image is enough to greatly improve an approximate reconstruction. Our full model reduces the mean absolute error of state-of-the-art stereo reconstruction systems by >50%, both in our target domain of satellite stereo and on stereo pairs from the ETH3D benchmark.
ClearGrasp: 3D Shape Estimation of Transparent Objects for Manipulation
Oct 14, 2019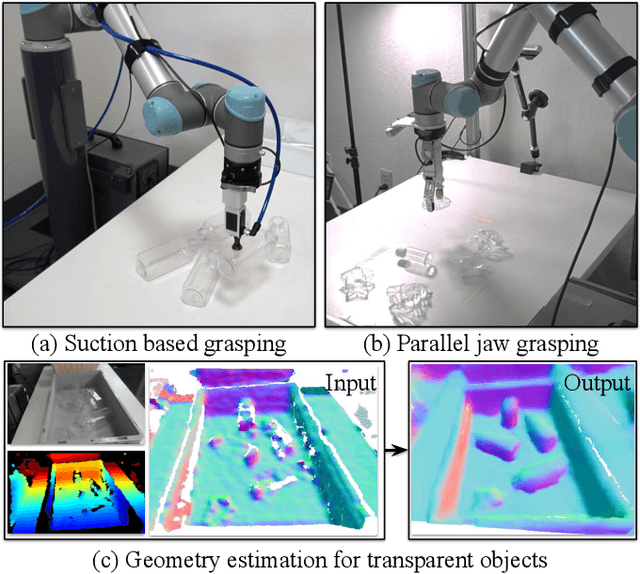

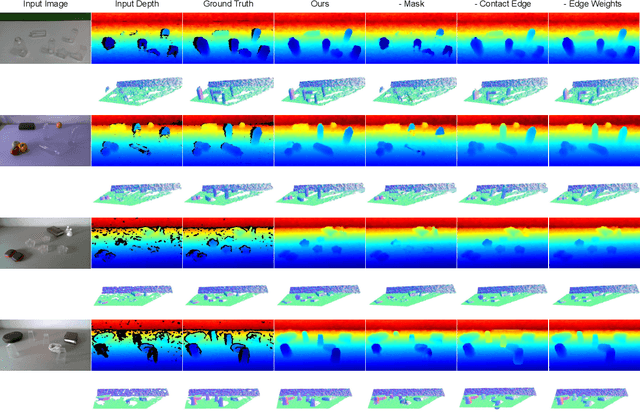
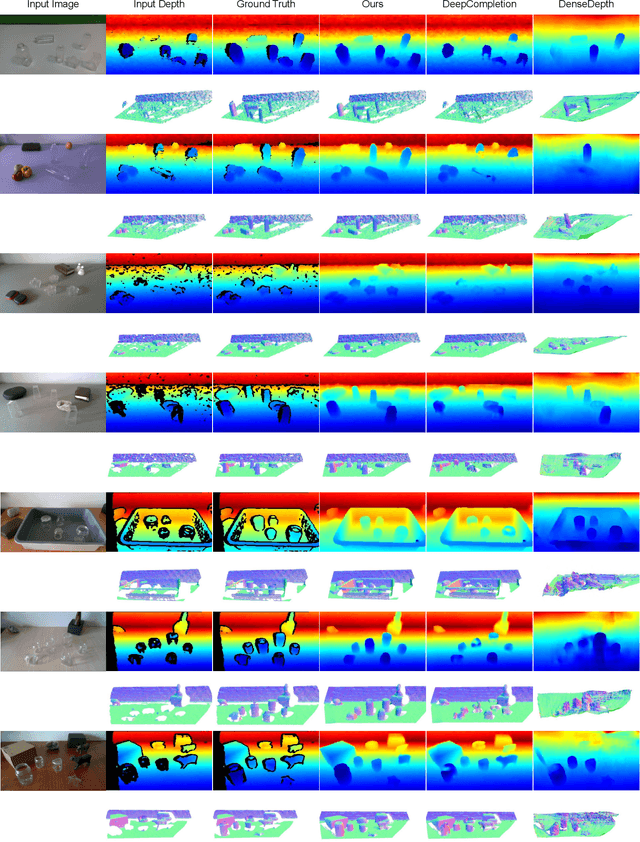
Transparent objects are a common part of everyday life, yet they possess unique visual properties that make them incredibly difficult for standard 3D sensors to produce accurate depth estimates for. In many cases, they often appear as noisy or distorted approximations of the surfaces that lie behind them. To address these challenges, we present ClearGrasp -- a deep learning approach for estimating accurate 3D geometry of transparent objects from a single RGB-D image for robotic manipulation. Given a single RGB-D image of transparent objects, ClearGrasp uses deep convolutional networks to infer surface normals, masks of transparent surfaces, and occlusion boundaries. It then uses these outputs to refine the initial depth estimates for all transparent surfaces in the scene. To train and test ClearGrasp, we construct a large-scale synthetic dataset of over 50,000 RGB-D images, as well as a real-world test benchmark with 286 RGB-D images of transparent objects and their ground truth geometries. The experiments demonstrate that ClearGrasp is substantially better than monocular depth estimation baselines and is capable of generalizing to real-world images and novel objects. We also demonstrate that ClearGrasp can be applied out-of-the-box to improve grasping algorithms' performance on transparent objects. Code, data, and benchmarks will be released. Supplementary materials available on the project website: https://sites.google.com/view/cleargrasp
Multi-scale GANs for Memory-efficient Generation of High Resolution Medical Images
Jul 02, 2019
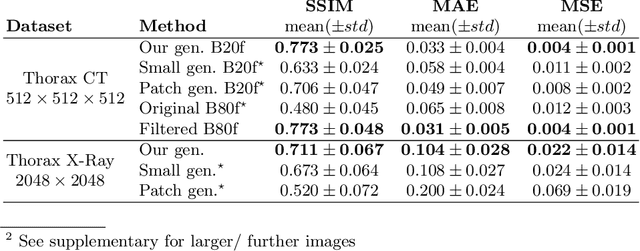
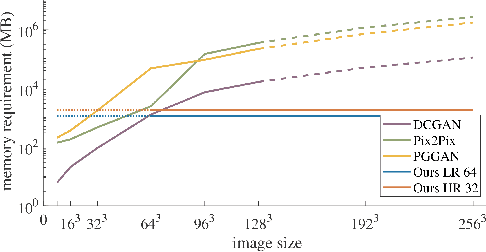
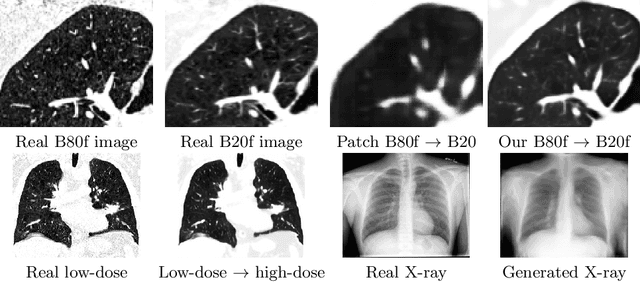
Currently generative adversarial networks (GANs) are rarely applied to medical images of large sizes, especially 3D volumes, due to their large computational demand. We propose a novel multi-scale patch-based GAN approach to generate large high resolution 2D and 3D images. Our key idea is to first learn a low-resolution version of the image and then generate patches of successively growing resolutions conditioned on previous scales. In a domain translation use-case scenario, 3D thorax CTs of size 512x512x512 and thorax X-rays of size 2048x2048 are generated and we show that, due to the constant GPU memory demand of our method, arbitrarily large images of high resolution can be generated. Moreover, compared to common patch-based approaches, our multi-resolution scheme enables better image quality and prevents patch artifacts.
Deep Multi-task Prediction of Lung Cancer and Cancer-free Progression from Censored Heterogenous Clinical Imaging
Nov 12, 2019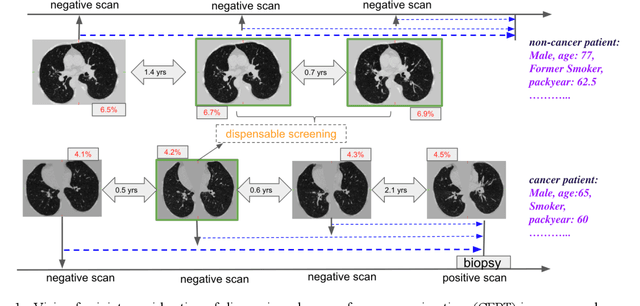
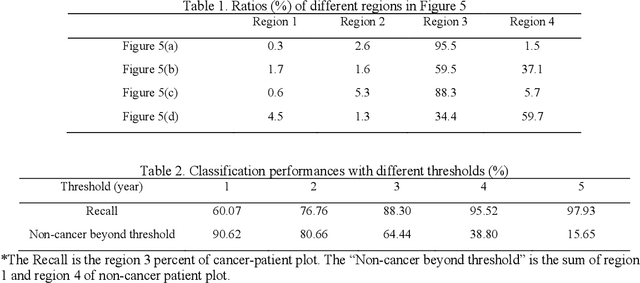
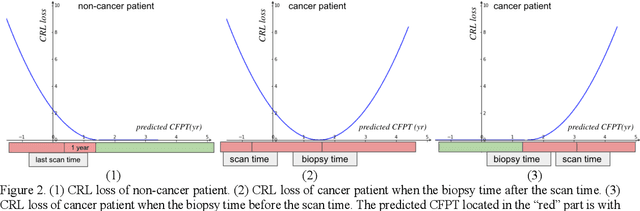
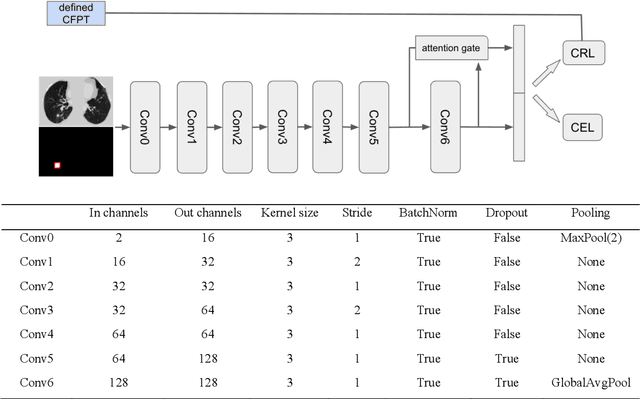
Annual low dose computed tomography (CT) lung screening is currently advised for individuals at high risk of lung cancer (e.g., heavy smokers between 55 and 80 years old). The recommended screening practice significantly reduces all-cause mortality, but the vast majority of screening results are negative for cancer. If patients at very low risk could be identified based on individualized, image-based biomarkers, the health care resources could be more efficiently allocated to higher risk patients and reduce overall exposure to ionizing radiation. In this work, we propose a multi-task (diagnosis and prognosis) deep convolutional neural network to improve the diagnostic accuracy over a baseline model while simultaneously estimating a personalized cancer-free progression time (CFPT). A novel Censored Regression Loss (CRL) is proposed to perform weakly supervised regression so that even single negative screening scans can provide small incremental value. Herein, we study 2287 scans from 1433 de-identified patients from the Vanderbilt Lung Screening Program (VLSP) and Molecular Characterization Laboratories (MCL) cohorts. Using five-fold cross-validation, we train a 3D attention-based network under two scenarios: (1) single-task learning with only classification, and (2) multi-task learning with both classification and regression. The single-task learning leads to a higher AUC compared with the Kaggle challenge winner pre-trained model (0.878 v. 0.856), and multi-task learning significantly improves the single-task one (AUC 0.895, p<0.01, McNemar test). In summary, the image-based predicted CFPT can be used in follow-up year lung cancer prediction and data assessment.
Resolution-independent meshes of super pixels
Oct 29, 2019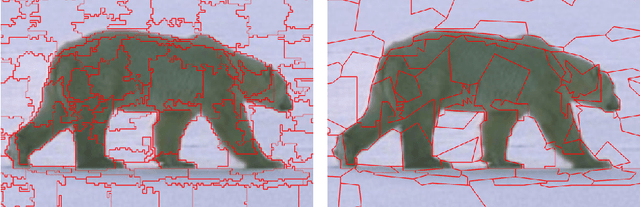

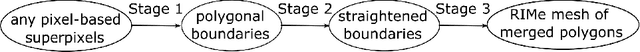
The over-segmentation into superpixels is an important preprocessing step to smartly compress the input size and speed up higher level tasks. A superpixel was traditionally considered as a small cluster of square-based pixels that have similar color intensities and are closely located to each other. In this discrete model the boundaries of superpixels often have irregular zigzags consisting of horizontal or vertical edges from a given pixel grid. However digital images represent a continuous world, hence the following continuous model in the resolution-independent formulation can be more suitable for the reconstruction problem. Instead of uniting squares in a grid, a resolution-independent superpixel is defined as a polygon that has straight edges with any possible slope at subpixel resolution. The harder continuous version of the over-segmentation problem is to split an image into polygons and find a best (say, constant) color of each polygon so that the resulting colored mesh well approximates the given image. Such a mesh of polygons can be rendered at any higher resolution with all edges kept straight. We propose a fast conversion of any traditional superpixels into polygons and guarantees that their straight edges do not intersect. The meshes based on the superpixels SEEDS (Superpixels Extracted via Energy-Driven Sampling) and SLIC (Simple Linear Iterative Clustering) are compared with past meshes based on the Line Segment Detector. The experiments on the Berkeley Segmentation Database confirm that the new superpixels have more compact shapes than pixel-based superpixels.