 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Augmented Semantic Signatures of Airborne LiDAR Point Clouds for Determining Change in Time-varying Data
Apr 29, 2020
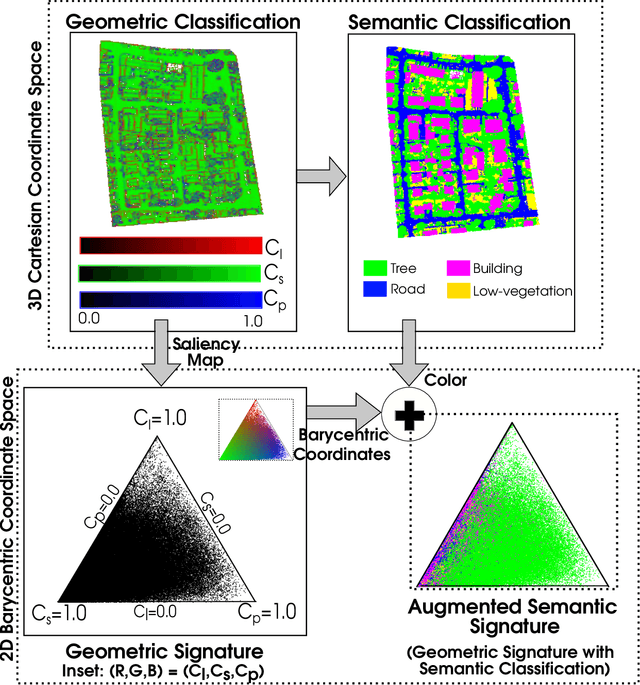
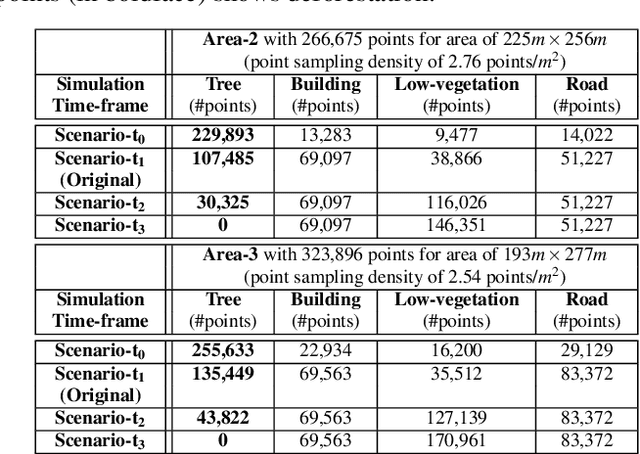
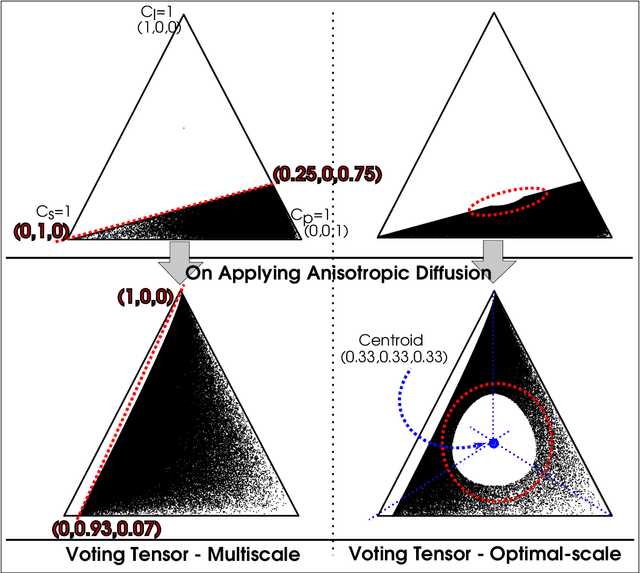
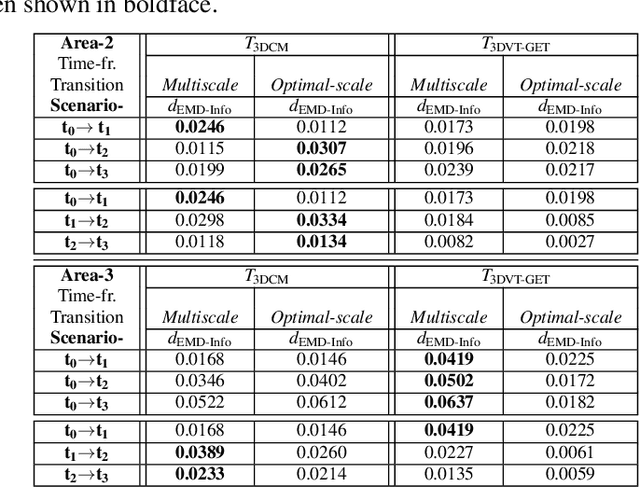
LiDAR point clouds provide rich geometric information, which is particularly useful for the analysis of complex scenes of urban regions. Finding structural and semantic differences between two different three-dimensional point clouds, say, of the same region but acquired at different time instances is an important problem. Usually, the data capture has inconsistencies when taken at different time instances, e.g., sampling densities, and the orientation of the flight path. Hence, change detection involves computationally expensive registration and segmentation. We are interested in capturing the relative differences in the geometric uncertainty and semantic content of the point cloud without the registration process. Hence, we propose an orientation-invariant geometric signature of the point cloud, which integrates its probabilistic geometric and semantic classifications. We study different properties of the geometric signature, which are image-based encoding of geometric uncertainty and semantic content. We explore different metrics to determine differences between these signatures, which in turn compare point clouds without performing point-to-point registration. We have observed that a point cloud with four semantic classes, namely, buildings, trees, road, and low-vegetation, that the tree class shows a characteristic pattern. Thus, we use a case study of airborne LiDAR point clouds where the visual and the quantitative comparisons of the geometric signatures of point clouds are useful in demonstrating changes during a thematic event, such as progressive deforestation, in the topography of an urban region. Our results show that the differences in the signatures corroborate with the geometric and semantic differences of the point clouds.
Characterization of migrated seismic volumes using texture attributes: a comparative study
Jan 30, 2019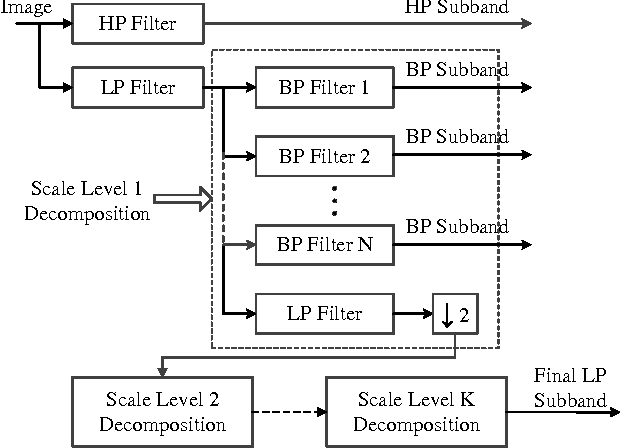
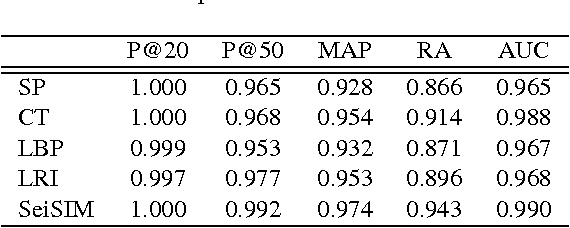

In this paper, we examine several typical texture attributes developed in the image processing community in recent years with respect to their capability of characterizing a migrated seismic volume. These attributes are generated in either frequency or space domain, including steerable pyramid, curvelet, local binary pattern, and local radius index. The comparative study is performed within an image retrieval framework. We evaluate these attributes in terms of retrieval accuracy. It is our hope that this comparative study will help acquaint the seismic interpretation community with the many available powerful image texture analysis techniques, providing more alternative attributes for their seismic exploration.
nocaps: novel object captioning at scale
Dec 20, 2018
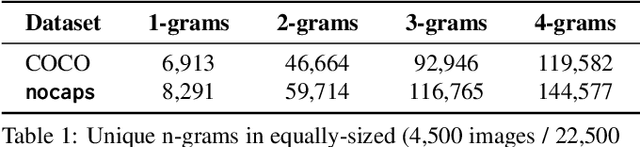
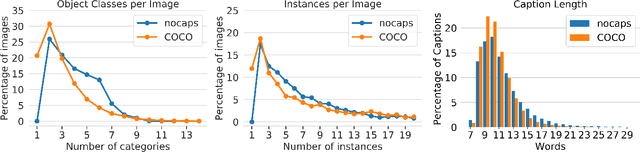
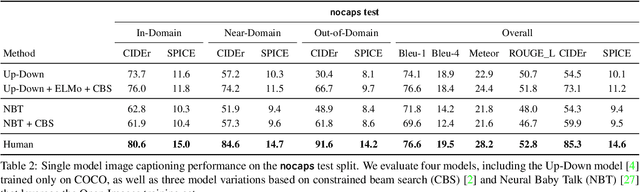
Image captioning models have achieved impressive results on datasets containing limited visual concepts and large amounts of paired image-caption training data. However, if these models are to ever function in the wild, a much larger variety of visual concepts must be learned, ideally from less supervision. To encourage the development of image captioning models that can learn visual concepts from alternative data sources, such as object detection datasets, we present the first large-scale benchmark for this task. Dubbed 'nocaps', for novel object captioning at scale, our benchmark consists of 166,100 human-generated captions describing 15,100 images from the Open Images validation and test sets. The associated training data consists of COCO image-caption pairs, plus Open Images image-level labels and object bounding boxes. Since Open Images contains many more classes than COCO, more than 500 object classes seen in test images have no training captions (hence, nocaps). We evaluate several existing approaches to novel object captioning on our challenging benchmark. In automatic evaluations these approaches show modest improvements over a strong baseline trained only on image-caption data. However, even when using ground-truth object detections, the results are significantly weaker than our human baseline - indicating substantial room for improvement.
Local Search is a Remarkably Strong Baseline for Neural Architecture Search
Apr 29, 2020



Neural Architecture Search (NAS), i.e., the automation of neural network design, has gained much popularity in recent years with increasingly complex search algorithms being proposed. Yet, solid comparisons with simple baselines are often missing. At the same time, recent retrospective studies have found many new algorithms to be no better than random search (RS). In this work we consider, for the first time, a simple Local Search (LS) algorithm for NAS. We particularly consider a multi-objective NAS formulation, with network accuracy and network complexity as two objectives, as understanding the trade-off between these two objectives is arguably the most interesting aspect of NAS. The proposed LS algorithm is compared with RS and two evolutionary algorithms (EAs), as these are often heralded as being ideal for multi-objective optimization. To promote reproducibility, we create and release two benchmark datasets containing 200K saved network evaluations for two established image classification tasks, CIFAR-10 and CIFAR-100. Our benchmarks are designed to be complementary to existing benchmarks, especially in that they are better suited for multi-objective search. We additionally consider a version of the problem with a much larger architecture space. While we find and show that the considered algorithms explore the search space in fundamentally different ways, we also find that LS substantially outperforms RS and even performs nearly as good as state-of-the-art EAs. We believe that this provides strong evidence that LS is truly a competitive baseline for NAS against which new NAS algorithms should be benchmarked.
Radioactive data: tracing through training
Feb 03, 2020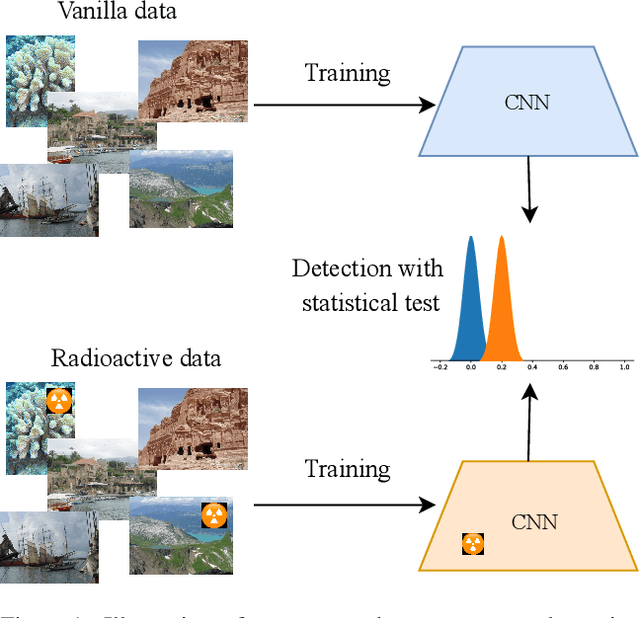
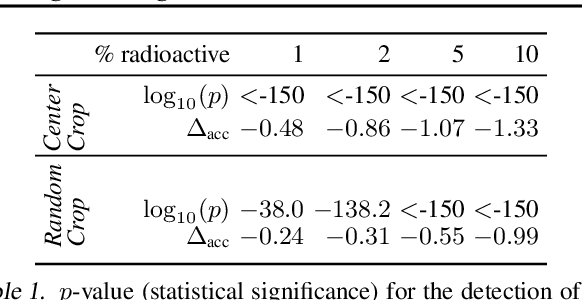
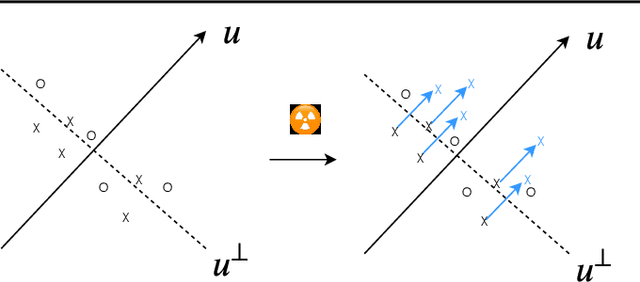
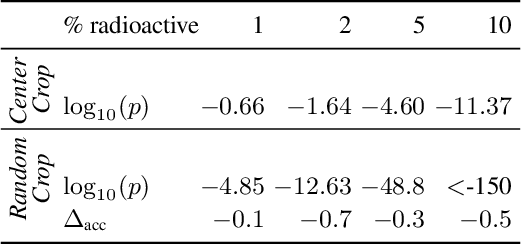
We want to detect whether a particular image dataset has been used to train a model. We propose a new technique, \emph{radioactive data}, that makes imperceptible changes to this dataset such that any model trained on it will bear an identifiable mark. The mark is robust to strong variations such as different architectures or optimization methods. Given a trained model, our technique detects the use of radioactive data and provides a level of confidence (p-value). Our experiments on large-scale benchmarks (Imagenet), using standard architectures (Resnet-18, VGG-16, Densenet-121) and training procedures, show that we can detect usage of radioactive data with high confidence (p<10^-4) even when only 1% of the data used to trained our model is radioactive. Our method is robust to data augmentation and the stochasticity of deep network optimization. As a result, it offers a much higher signal-to-noise ratio than data poisoning and backdoor methods.
A linear method for camera pair self-calibration and multi-view reconstruction with geometrically verified correspondences
Jun 28, 2019
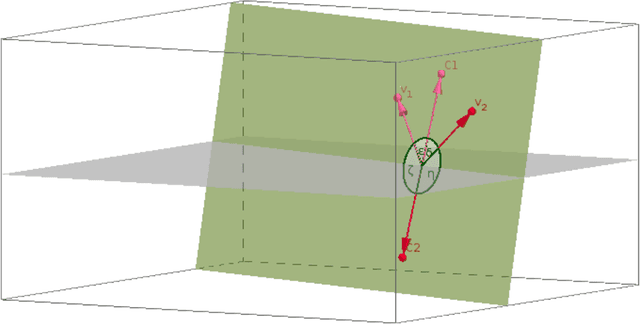
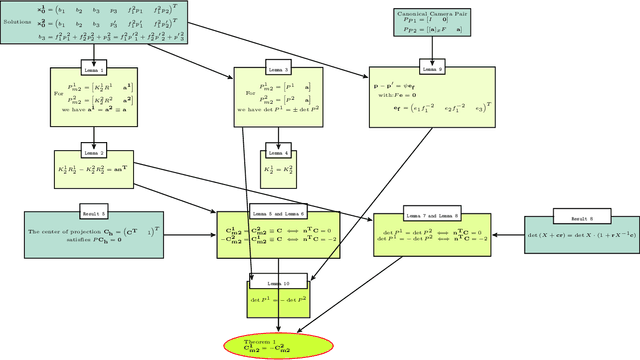

We examine 3D reconstruction of architectural scenes in unordered sets of uncalibrated images. We introduce a linear method to self-calibrate and find the metric reconstruction of a camera pair. We assume unknown and different focal lengths but otherwise known internal camera parameters and a known projective reconstruction of the camera pair. We recover two possible camera configurations in space and use the Cheirality condition, that all 3D scene points are in front of both cameras, to disambiguate the solution. We show in two Theorems, first that the two solutions are in mirror positions and then the relations between their viewing directions. Our new method performs on par (median rotation error $\Delta R = 3.49^{\circ}$) with the standard approach of Kruppa equations ($\Delta R = 3.77^{\circ}$) for self-calibration and 5-Point algorithm for calibrated metric reconstruction of a camera pair. We reject erroneous image correspondences by introducing a method to examine whether point correspondences appear in the same order along $x, y$ image axes in image pairs. We evaluate this method by its precision and recall and show that it improves the robustness of point matches in architectural and general scenes. Finally, we integrate all the introduced methods to a 3D reconstruction pipeline. We utilize the numerous camera pair metric recontructions using rotation-averaging algorithms and a novel method to average focal length estimates.
Weighted Mean Curvature
Mar 17, 2019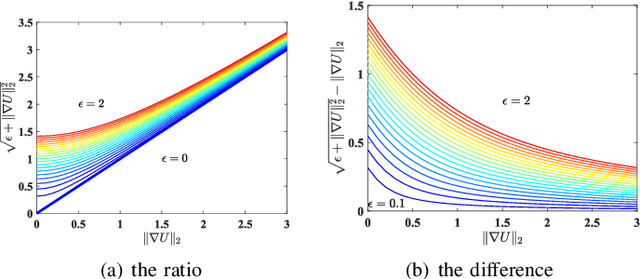
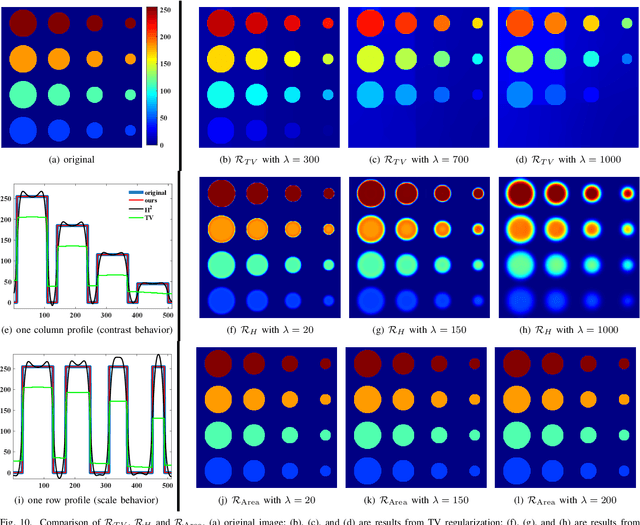
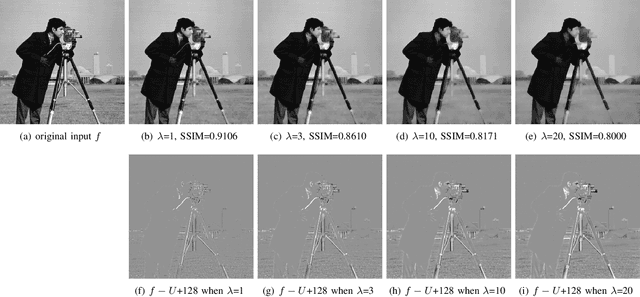

In image processing tasks, spatial priors are essential for robust computations, regularization, algorithmic design and Bayesian inference. In this paper, we introduce weighted mean curvature (WMC) as a novel image prior and present an efficient computation scheme for its discretization in practical image processing applications. We first demonstrate the favorable properties of WMC, such as sampling invariance, scale invariance, and contrast invariance with Gaussian noise model; and we show the relation of WMC to area regularization. We further propose an efficient computation scheme for discretized WMC, which is demonstrated herein to process over 33.2 giga-pixels/second on GPU. This scheme yields itself to a convolutional neural network representation. Finally, WMC is evaluated on synthetic and real images, showing its superiority quantitatively to total-variation and mean curvature.
The Virtual Electromagnetic Interaction between Digital Images for Image Matching with Shifting Transformation
Oct 12, 2016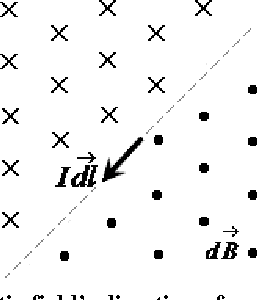
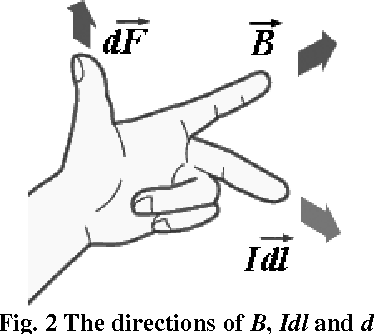
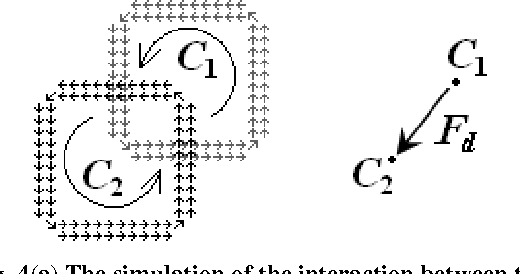
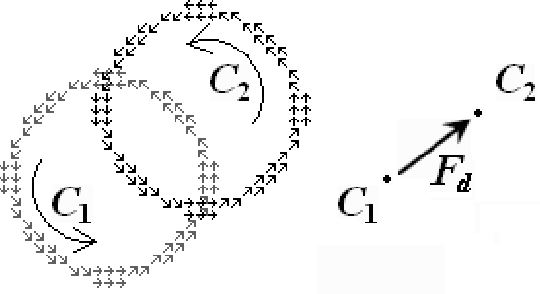
A novel way of matching two images with shifting transformation is studied. The approach is based on the presentation of the virtual edge current in images, and also the study of virtual electromagnetic interaction between two related images inspired by electromagnetism. The edge current in images is proposed as a discrete simulation of the physical current, which is based on the significant edge line extracted by Canny-like edge detection. Then the virtual interaction of the edge currents between related images is studied by imitating the electro-magnetic interaction between current-carrying wires. Based on the virtual interaction force between two related images, a novel method is presented and applied in image matching for shifting transformation. The preliminary experimental results indicate the effectiveness of the proposed method.
* 17 pages, 39 figures. arXiv admin note: substantial text overlap with arXiv:1610.03612, arXiv:1610.02762
One-Shot Informed Robotic Visual Search in the Wild
Mar 22, 2020
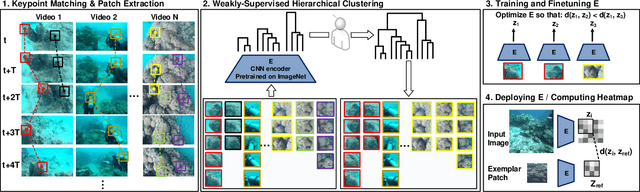


We consider the task of underwater robot navigation for the purpose of collecting scientifically-relevant video data for environmental monitoring. The majority of field robots that currently perform monitoring tasks in unstructured natural environments navigate via path-tracking a pre-specified sequence of waypoints. Although this navigation method is often necessary, it is limiting because the robot does not have a model of what the scientist deems to be relevant visual observations. Thus, the robot can neither visually search for particular types of objects, nor focus its attention on parts of the scene that might be more relevant than the pre-specified waypoints and viewpoints. In this paper we propose a method that enables informed visual navigation via a learned visual similarity operator that guides the robot's visual search towards parts of the scene that look like an exemplar image, which is given by the user as a high-level specification for data collection. We propose and evaluate a weakly-supervised video representation learning method that outperforms ImageNet embeddings for similarity tasks in the underwater domain. We also demonstrate the deployment of this similarity operator during informed visual navigation in collaborative environmental monitoring scenarios, in large-scale field trials, where the robot and a human scientist jointly search for relevant visual content.
Image Compression By Embedding Five Modulus Method Into JPEG
Apr 30, 2013
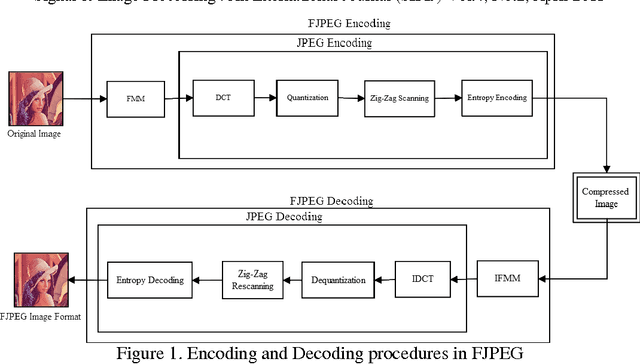

The standard JPEG format is almost the optimum format in image compression. The compression ratio in JPEG sometimes reaches 30:1. The compression ratio of JPEG could be increased by embedding the Five Modulus Method (FMM) into the JPEG algorithm. The novel algorithm gives twice the time as the standard JPEG algorithm or more. The novel algorithm was called FJPEG (Five-JPEG). The quality of the reconstructed image after compression is approximately approaches the JPEG. Standard test images have been used to support and implement the suggested idea in this paper and the error metrics have been computed and compared with JPEG.
* 9 pages, 6 tables, 6 figures