 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Spatially-Adaptive Normalization
Apr 06, 2020
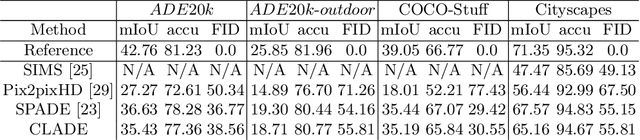
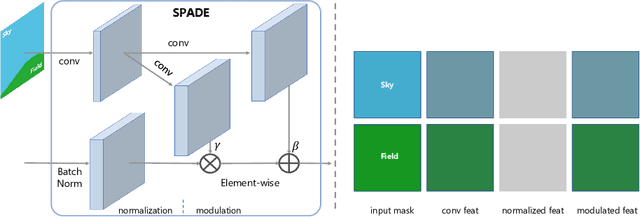


Spatially-adaptive normalization is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to preserve the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the true advantages inside the box is still highly demanded, to help reduce the significant computation and parameter overheads introduced by these new structures. In this paper, from a return-on-investment point of view, we present a deep analysis of the effectiveness of SPADE and observe that its advantages actually come mainly from its semantic-awareness rather than the spatial-adaptiveness. Inspired by this point, we propose class-adaptive normalization (CLADE), a lightweight variant that is not adaptive to spatial positions or layouts. Benefited from this design, CLADE greatly reduces the computation cost while still being able to preserve the semantic information during the generation. Extensive experiments on multiple challenging datasets demonstrate that while the resulting fidelity is on par with SPADE, its overhead is much cheaper than SPADE. Take the generator for ADE20k dataset as an example, the extra parameter and computation cost introduced by CLADE are only 4.57% and 0.07% while that of SPADE are 39.21% and 234.73% respectively.
On the String Kernel Pre-Image Problem with Applications in Drug Discovery
Dec 04, 2014The pre-image problem has to be solved during inference by most structured output predictors. For string kernels, this problem corresponds to finding the string associated to a given input. An algorithm capable of solving or finding good approximations to this problem would have many applications in computational biology and other fields. This work uses a recent result on combinatorial optimization of linear predictors based on string kernels to develop, for the pre-image, a low complexity upper bound valid for many string kernels. This upper bound is used with success in a branch and bound searching algorithm. Applications and results in the discovery of druggable peptides are presented and discussed.
DSAL-GAN: Denoising based Saliency Prediction with Generative Adversarial Networks
Apr 02, 2019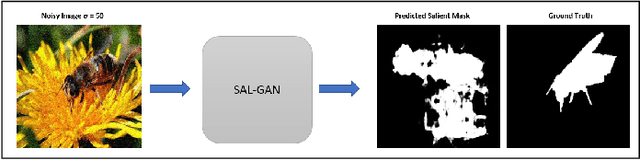

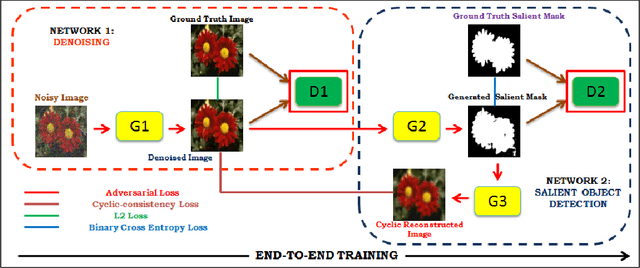

Synthesizing high quality saliency maps from noisy images is a challenging problem in computer vision and has many practical applications. Samples generated by existing techniques for saliency detection cannot handle the noise perturbations smoothly and fail to delineate the salient objects present in the given scene. In this paper, we present a novel end-to-end coupled Denoising based Saliency Prediction with Generative Adversarial Network (DSAL-GAN) framework to address the problem of salient object detection in noisy images. DSAL-GAN consists of two generative adversarial-networks (GAN) trained end-to-end to perform denoising and saliency prediction altogether in a holistic manner. The first GAN consists of a generator which denoises the noisy input image, and in the discriminator counterpart we check whether the output is a denoised image or ground truth original image. The second GAN predicts the saliency maps from raw pixels of the input denoised image using a data-driven metric based on saliency prediction method with adversarial loss. Cycle consistency loss is also incorporated to further improve salient region prediction. We demonstrate with comprehensive evaluation that the proposed framework outperforms several baseline saliency models on various performance benchmarks.
Learning Filter Basis for Convolutional Neural Network Compression
Aug 23, 2019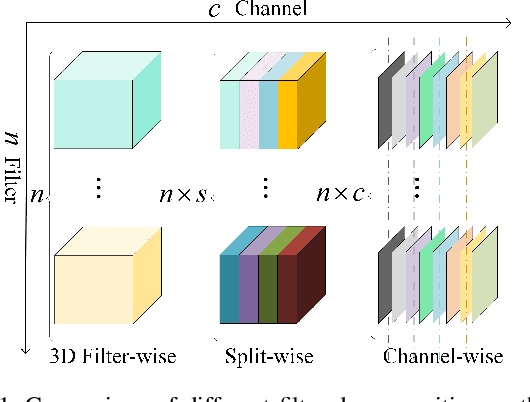
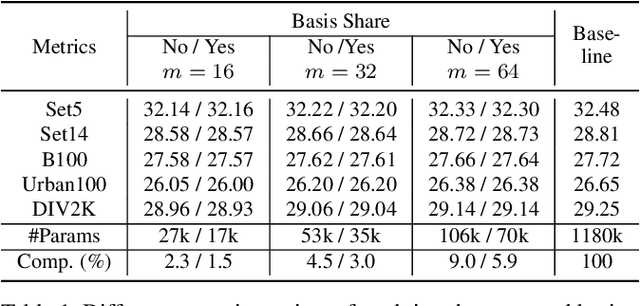
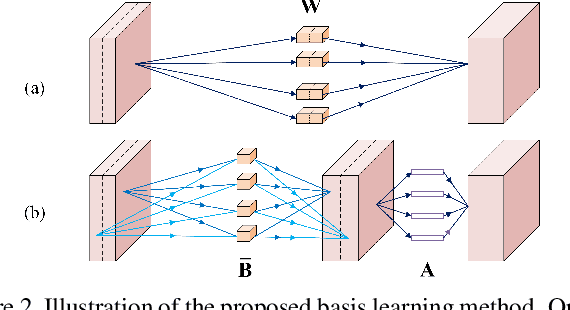
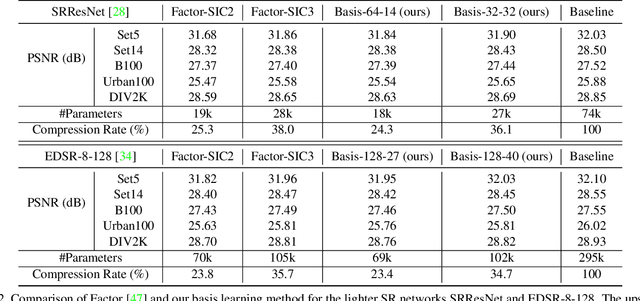
Convolutional neural networks (CNNs) based solutions have achieved state-of-the-art performances for many computer vision tasks, including classification and super-resolution of images. Usually the success of these methods comes with a cost of millions of parameters due to stacking deep convolutional layers. Moreover, quite a large number of filters are also used for a single convolutional layer, which exaggerates the parameter burden of current methods. Thus, in this paper, we try to reduce the number of parameters of CNNs by learning a basis of the filters in convolutional layers. For the forward pass, the learned basis is used to approximate the original filters and then used as parameters for the convolutional layers. We validate our proposed solution for multiple CNN architectures on image classification and image super-resolution benchmarks and compare favorably to the existing state-of-the-art in terms of reduction of parameters and preservation of accuracy.
Appearance Shock Grammar for Fast Medial Axis Extraction from Real Images
Apr 06, 2020

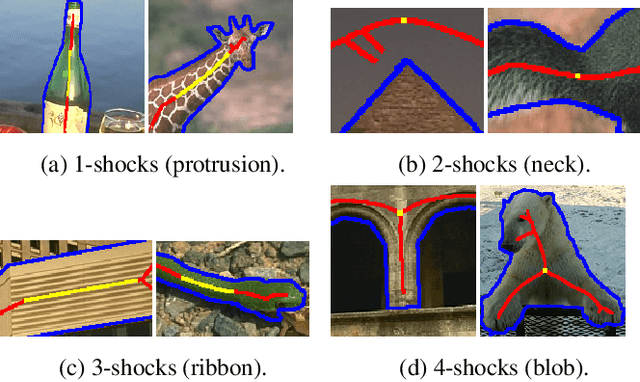
We combine ideas from shock graph theory with more recent appearance-based methods for medial axis extraction from complex natural scenes, improving upon the present best unsupervised method, in terms of efficiency and performance. We make the following specific contributions: i) we extend the shock graph representation to the domain of real images, by generalizing the shock type definitions using local, appearance-based criteria; ii) we then use the rules of a Shock Grammar to guide our search for medial points, drastically reducing run time when compared to other methods, which exhaustively consider all points in the input image;iii) we remove the need for typical post-processing steps including thinning, non-maximum suppression, and grouping, by adhering to the Shock Grammar rules while deriving the medial axis solution; iv) finally, we raise some fundamental concerns with the evaluation scheme used in previous work and propose a more appropriate alternative for assessing the performance of medial axis extraction from scenes. Our experiments on the BMAX500 and SK-LARGE datasets demonstrate the effectiveness of our approach. We outperform the present state-of-the-art, excelling particularly in the high-precision regime, while running an order of magnitude faster and requiring no post-processing.
Automatic Optimization of Hardware Accelerators for Image Processing
Feb 26, 2015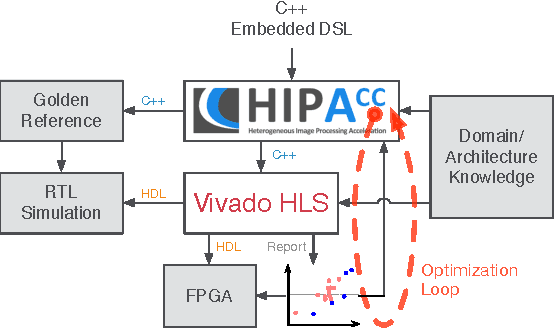
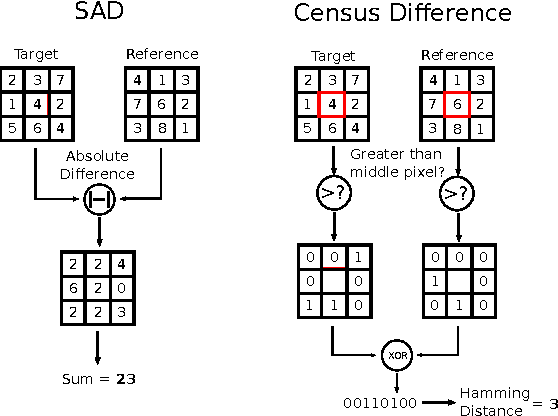
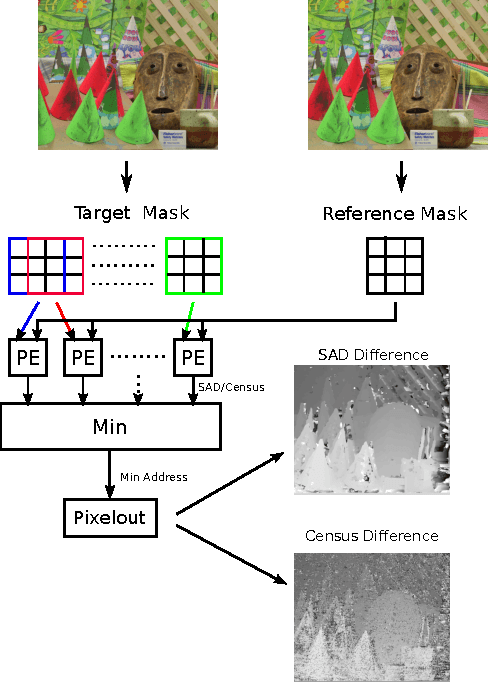
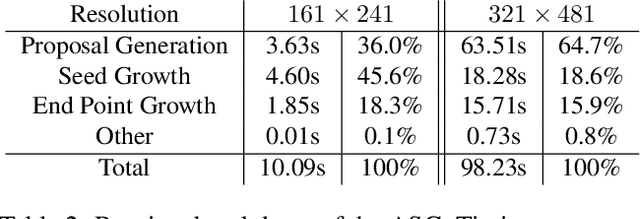
In the domain of image processing, often real-time constraints are required. In particular, in safety-critical applications, such as X-ray computed tomography in medical imaging or advanced driver assistance systems in the automotive domain, timing is of utmost importance. A common approach to maintain real-time capabilities of compute-intensive applications is to offload those computations to dedicated accelerator hardware, such as Field Programmable Gate Arrays (FPGAs). Programming such architectures is a challenging task, with respect to the typical FPGA-specific design criteria: Achievable overall algorithm latency and resource usage of FPGA primitives (BRAM, FF, LUT, and DSP). High-Level Synthesis (HLS) dramatically simplifies this task by enabling the description of algorithms in well-known higher languages (C/C++) and its automatic synthesis that can be accomplished by HLS tools. However, algorithm developers still need expert knowledge about the target architecture, in order to achieve satisfying results. Therefore, in previous work, we have shown that elevating the description of image algorithms to an even higher abstraction level, by using a Domain-Specific Language (DSL), can significantly cut down the complexity for designing such algorithms for FPGAs. To give the developer even more control over the common trade-off, latency vs. resource usage, we will present an automatic optimization process where these criteria are analyzed and fed back to the DSL compiler, in order to generate code that is closer to the desired design specifications. Finally, we generate code for stereo block matching algorithms and compare it with handwritten implementations to quantify the quality of our results.
Learning Similarity Metrics for Numerical Simulations
Feb 18, 2020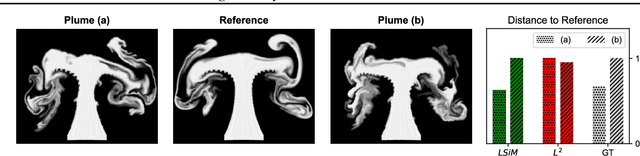
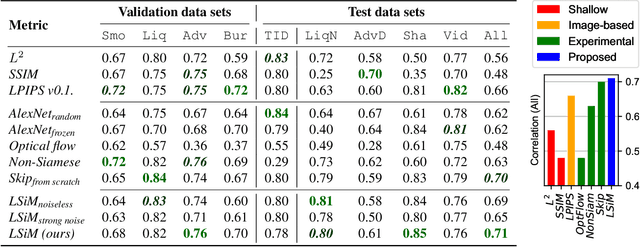
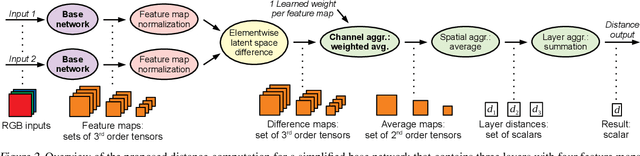
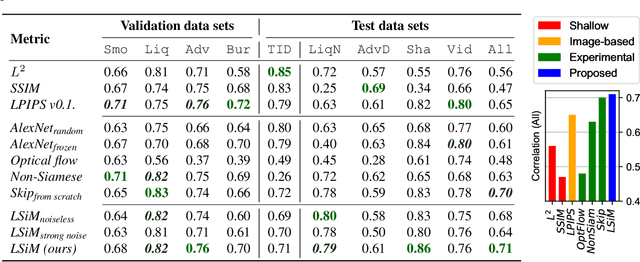
We propose a neural network-based approach that computes a stable and generalizing metric (LSiM), to compare field data from a variety of numerical simulation sources. Our method employs a Siamese network architecture that is motivated by the mathematical properties of a metric. We leverage a controllable data generation setup with partial differential equation (PDE) solvers to create increasingly different outputs from a reference simulation in a controlled environment. A central component of our learned metric is a specialized loss function that introduces knowledge about the correlation between single data samples into the training process. To demonstrate that the proposed approach outperforms existing simple metrics for vector spaces and other learned, image-based metrics, we evaluate the different methods on a large range of test data. Additionally, we analyze benefits for generalization and the impact of an adjustable training data difficulty. The robustness of LSiM is demonstrated via an evaluation on three real-world data sets.
Improving Self-Supervised Single View Depth Estimation by Masking Occlusion
Aug 29, 2019


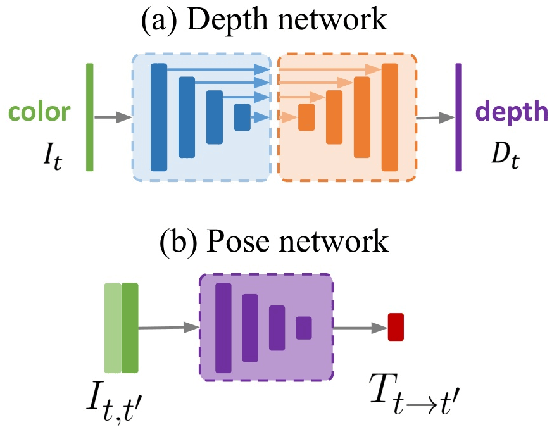
Single view depth estimation models can be trained from video footage using a self-supervised end-to-end approach with view synthesis as the supervisory signal. This is achieved with a framework that predicts depth and camera motion, with a loss based on reconstructing a target video frame from temporally adjacent frames. In this context, occlusion relates to parts of a scene that can be observed in the target frame but not in a frame used for image reconstruction. Since the image reconstruction is based on sampling from the adjacent frame, and occluded areas by definition cannot be sampled, reconstructed occluded areas corrupt to the supervisory signal. In previous work arXiv:1806.01260 occlusion is handled based on reconstruction error; at each pixel location, only the reconstruction with the lowest error is included in the loss. The current study aims to determine whether performance improvements of depth estimation models can be gained by during training only ignoring those regions that are affected by occlusion. In this work we introduce occlusion mask, a mask that during training can be used to specifically ignore regions that cannot be reconstructed due to occlusions. Occlusion mask is based entirely on predicted depth information. We introduce two novel loss formulations which incorporate the occlusion mask. The method and implementation of arXiv:1806.01260 serves as the foundation for our modifications as well as the baseline in our experiments. We demonstrate that (i) incorporating occlusion mask in the loss function improves the performance of single image depth prediction models on the KITTI benchmark. (ii) loss functions that select from reconstructions based on error are able to ignore some of the reprojection error caused by object motion.
Additive Angular Margin for Few Shot Learning to Classify Clinical Endoscopy Images
Mar 23, 2020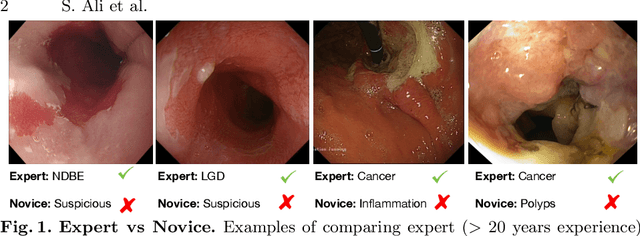
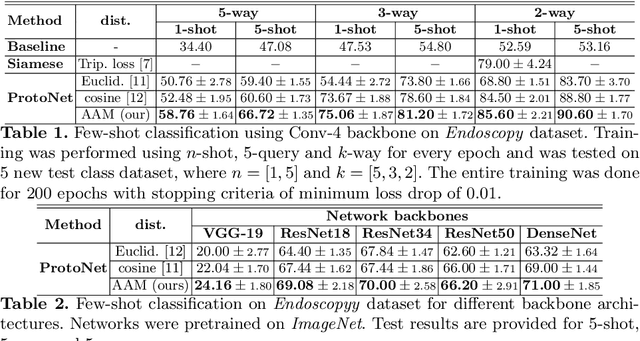
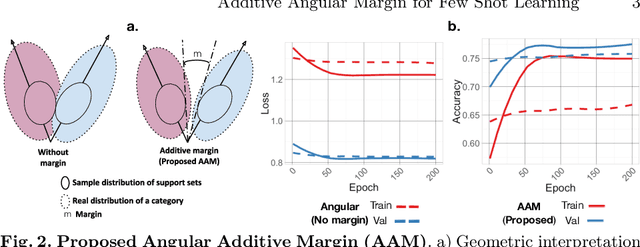
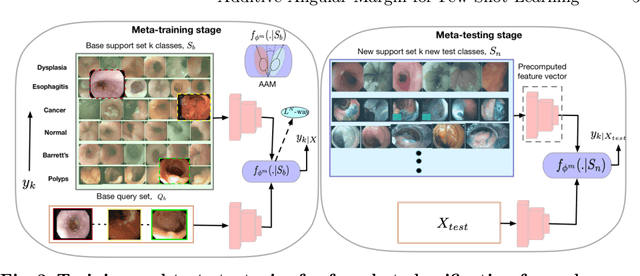
Endoscopy is a widely used imaging modality to diagnose and treat diseases in hollow organs as for example the gastrointestinal tract, the kidney and the liver. However, due to varied modalities and use of different imaging protocols at various clinical centers impose significant challenges when generalising deep learning models. Moreover, the assembly of large datasets from different clinical centers can introduce a huge label bias that renders any learnt model unusable. Also, when using new modality or presence of images with rare patterns, a bulk amount of similar image data and their corresponding labels are required for training these models. In this work, we propose to use a few-shot learning approach that requires less training data and can be used to predict label classes of test samples from an unseen dataset. We propose a novel additive angular margin metric in the framework of prototypical network in few-shot learning setting. We compare our approach to the several established methods on a large cohort of multi-center, multi-organ, and multi-modal endoscopy data. The proposed algorithm outperforms existing state-of-the-art methods.
Key Points Estimation and Point Instance Segmentation Approach for Lane Detection
Feb 18, 2020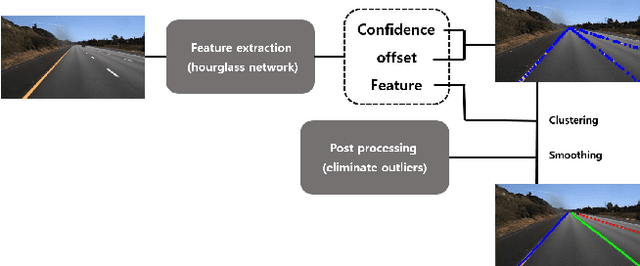
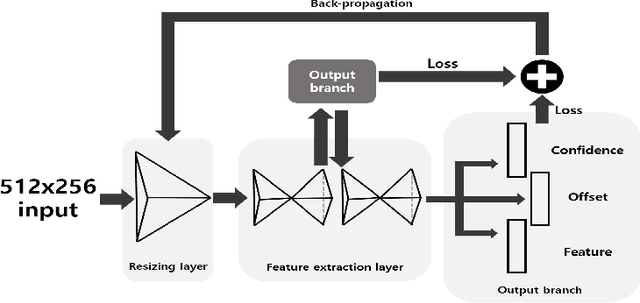
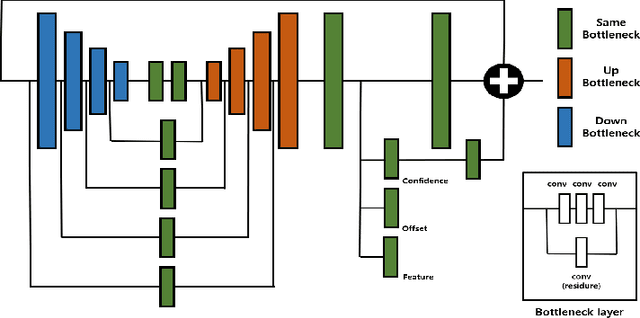

State-of-the-art lane detection methods achieve successful performance. Despite their advantages, these methods have critical deficiencies such as the limited number of detectable lanes and high false positive. In especial, high false positive can cause wrong and dangerous control. In this paper, we propose a novel lane detection method for the arbitrary number of lanes using the deep learning method, which has the lower number of false positives than other recent lane detection methods. The architecture of the proposed method has the shared feature extraction layers and several branches for detection and embedding to cluster lanes. The proposed method can generate exact points on the lanes, and we cast a clustering problem for the generated points as a point cloud instance segmentation problem. The proposed method is more compact because it generates fewer points than the original image pixel size. Our proposed post processing method eliminates outliers successfully and increases the performance notably. Whole proposed framework achieves competitive results on the tuSimple dataset.