 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging Big Data Analytics in Healthcare Enhancement: Trends, Challenges and Opportunities
Apr 05, 2020
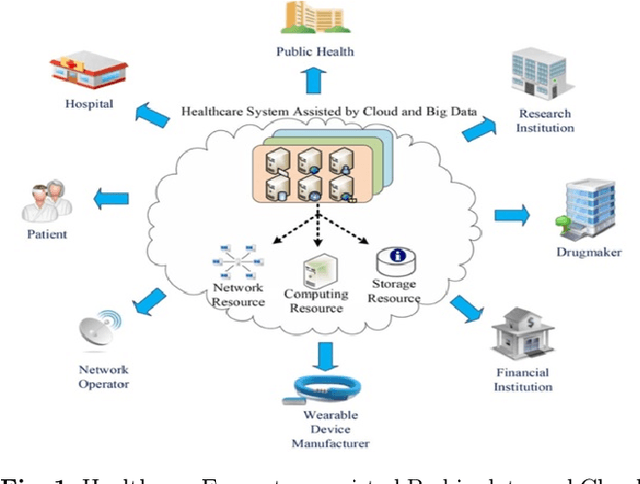
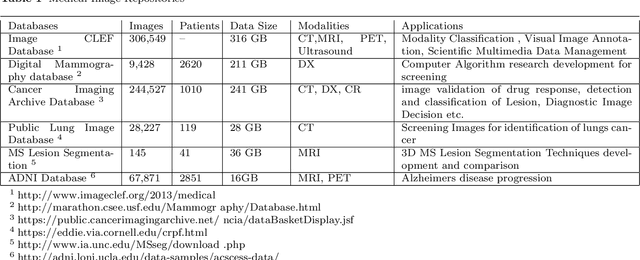
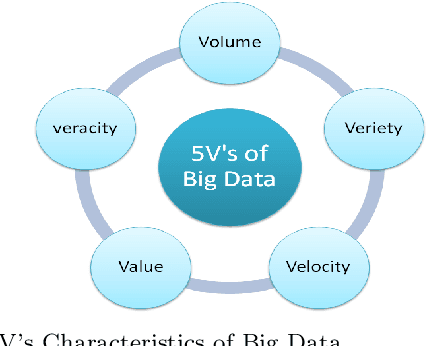
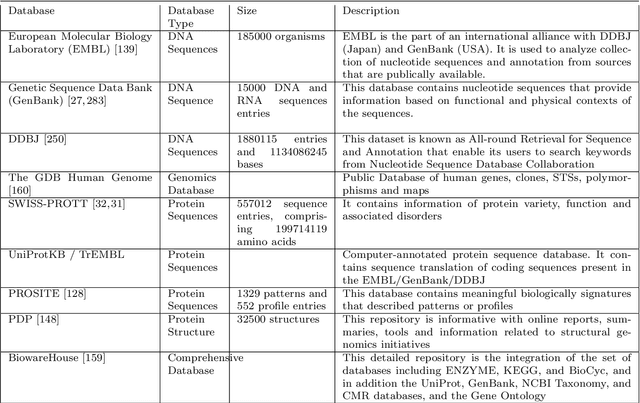
Clinicians decisions are becoming more and more evidence-based meaning in no other field the big data analytics so promising as in healthcare. Due to the sheer size and availability of healthcare data, big data analytics has revolutionized this industry and promises us a world of opportunities. It promises us the power of early detection, prediction, prevention and helps us to improve the quality of life. Researchers and clinicians are working to inhibit big data from having a positive impact on health in the future. Different tools and techniques are being used to analyze, process, accumulate, assimilate and manage large amount of healthcare data either in structured or unstructured form. In this paper, we would like to address the need of big data analytics in healthcare: why and how can it help to improve life?. We present the emerging landscape of big data and analytical techniques in the five sub-disciplines of healthcare i.e.medical image analysis and imaging informatics, bioinformatics, clinical informatics, public health informatics and medical signal analytics. We presents different architectures, advantages and repositories of each discipline that draws an integrated depiction of how distinct healthcare activities are accomplished in the pipeline to facilitate individual patients from multiple perspectives. Finally the paper ends with the notable applications and challenges in adoption of big data analytics in healthcare.
Real-time texturing for 6D object instance detection from RGB Images
Dec 13, 2019
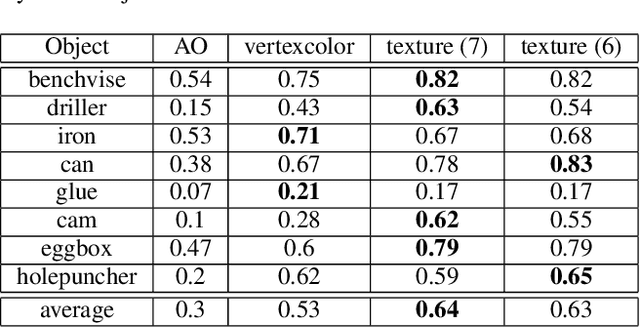

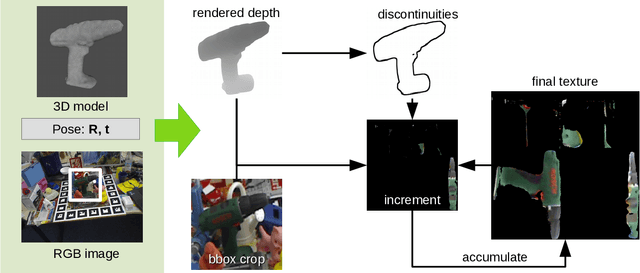
For objected detection, the availability of color cues strongly influences detection rates and is even a prerequisite for many methods. However, when training on synthetic CAD data, this information is not available. We therefore present a method for generating a texture-map from image sequences in real-time. The method relies on 6 degree-of-freedom poses and a 3D-model being available. In contrast to previous works this allows interleaving detection and texturing for upgrading the detector on-the-fly. Our evaluation shows that the acquired texture-map significantly improves detection rates using the LINEMOD detector on RGB images only. Additionally, we use the texture-map to differentiate instances of the same object by surface color.
One-Shot Informed Robotic Visual Search in the Wild
Mar 22, 2020
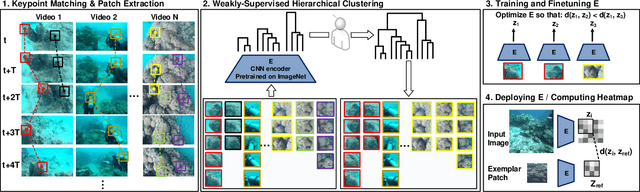


We consider the task of underwater robot navigation for the purpose of collecting scientifically-relevant video data for environmental monitoring. The majority of field robots that currently perform monitoring tasks in unstructured natural environments navigate via path-tracking a pre-specified sequence of waypoints. Although this navigation method is often necessary, it is limiting because the robot does not have a model of what the scientist deems to be relevant visual observations. Thus, the robot can neither visually search for particular types of objects, nor focus its attention on parts of the scene that might be more relevant than the pre-specified waypoints and viewpoints. In this paper we propose a method that enables informed visual navigation via a learned visual similarity operator that guides the robot's visual search towards parts of the scene that look like an exemplar image, which is given by the user as a high-level specification for data collection. We propose and evaluate a weakly-supervised video representation learning method that outperforms ImageNet embeddings for similarity tasks in the underwater domain. We also demonstrate the deployment of this similarity operator during informed visual navigation in collaborative environmental monitoring scenarios, in large-scale field trials, where the robot and a human scientist jointly search for relevant visual content.
GEVO: GPU Code Optimization using EvolutionaryComputation
Apr 17, 2020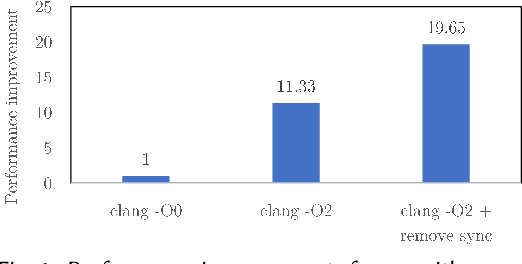
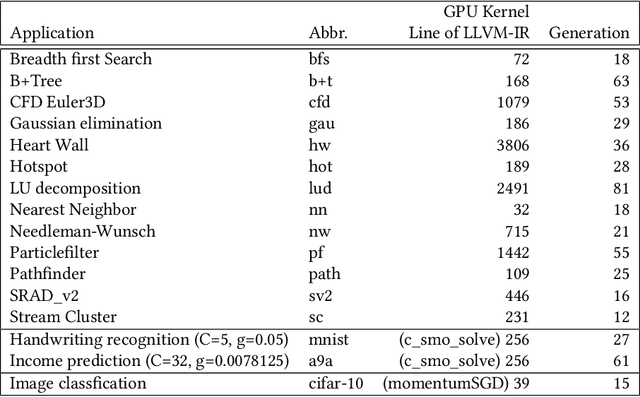
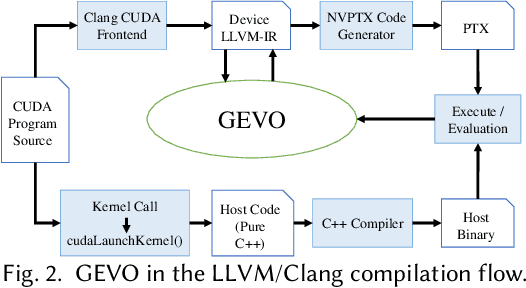
GPUs are a key enabler of the revolution in machine learning and high performance computing, functioning as de facto co-processors to accelerate large-scale computation. As the programming stack and tool support have matured, GPUs have also become accessible to programmers, who may lack detailed knowledge of the underlying architecture and fail to fully leverage the GPU's computation power. GEVO (Gpu optimization using EVOlutionary computation) is a tool for automatically discovering optimization opportunities and tuning the performance of GPU kernels in the LLVM representation. GEVO uses population-based search to find edits to GPU code compiled to LLVM-IR and improves performance on desired criteria while retaining required functionality. We demonstrate that GEVO improves the execution time of the GPU programs in the Rodinia benchmark suite and the machine learning models, SVM and ResNet18, on NVIDIA Tesla P100. For the Rodinia benchmarks, GEVO improves GPU kernel runtime performance by an average of 49.48% and by as much as 412% over the fully compiler-optimized baseline. If kernel output accuracy is relaxed to tolerate up to 1% error, GEVO can find kernel variants that outperform the baseline version by an average of 51.08%. For the machine learning workloads, GEVO achieves kernel performance improvement for SVM on the MNIST handwriting recognition (3.24X) and the a9a income prediction (2.93X) datasets with no loss of model accuracy. GEVO achieves 1.79X kernel performance improvement on image classification using ResNet18/CIFAR-10, with less than 1% model accuracy reduction.
Arbitrary Scale Super-Resolution for Brain MRI Images
Apr 05, 2020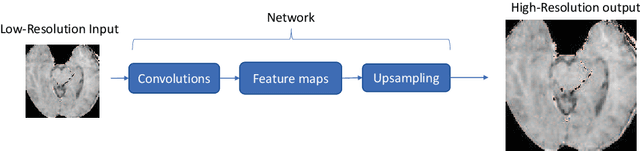

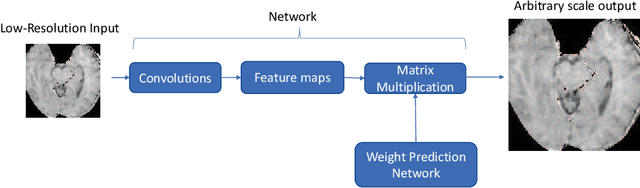
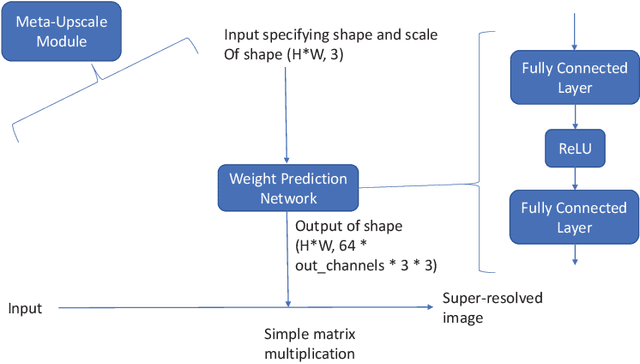
Recent attempts at Super-Resolution for medical images used deep learning techniques such as Generative Adversarial Networks (GANs) to achieve perceptually realistic single image Super-Resolution. Yet, they are constrained by their inability to generalise to different scale factors. This involves high storage and energy costs as every integer scale factor involves a separate neural network. A recent paper has proposed a novel meta-learning technique that uses a Weight Prediction Network to enable Super-Resolution on arbitrary scale factors using only a single neural network. In this paper, we propose a new network that combines that technique with SRGAN, a state-of-the-art GAN-based architecture, to achieve arbitrary scale, high fidelity Super-Resolution for medical images. By using this network to perform arbitrary scale magnifications on images from the Multimodal Brain Tumor Segmentation Challenge (BraTS) dataset, we demonstrate that it is able to outperform traditional interpolation methods by up to 20$\%$ on SSIM scores whilst retaining generalisability on brain MRI images. We show that performance across scales is not compromised, and that it is able to achieve competitive results with other state-of-the-art methods such as EDSR whilst being fifty times smaller than them. Combining efficiency, performance, and generalisability, this can hopefully become a new foundation for tackling Super-Resolution on medical images.
A fast and memory-efficient algorithm for smooth interpolation of polyrigid transformations: application to human joint tracking
Apr 28, 2020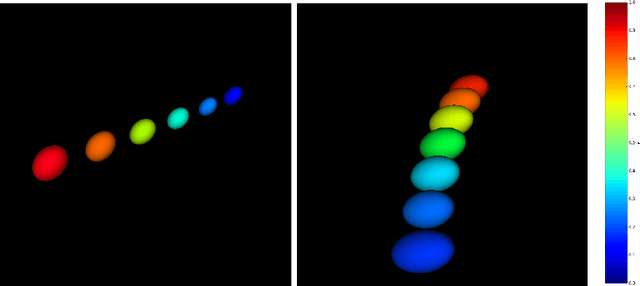

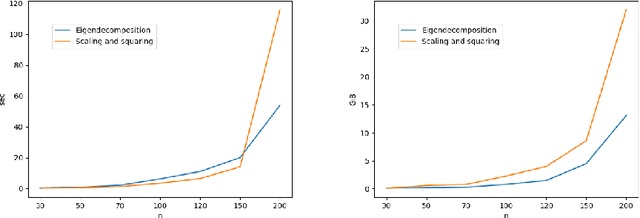
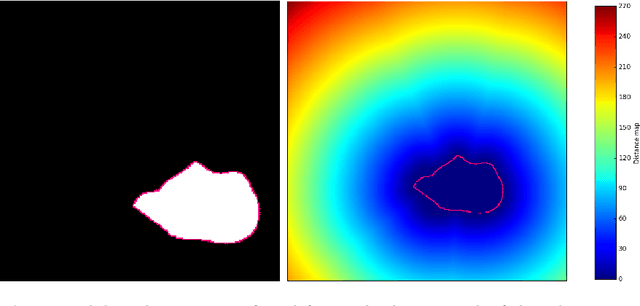
The log Euclidean polyrigid registration framework provides a way to smoothly estimate and interpolate poly-rigid/affine transformations for which the invertibility is guaranteed. This powerful and flexible mathematical framework is currently being used to track the human joint dynamics by first imposing bone rigidity constraints in order to synthetize the spatio-temporal joint deformations later. However, since no closed-form exists, then a computationally expensive integration of ordinary differential equations (ODEs) is required to perform image registration using this framework. To tackle this problem, the exponential map for solving these ODEs is computed using the scaling and squaring method in the literature. In this paper, we propose an algorithm using a matrix diagonalization based method for smooth interpolation of homogeneous polyrigid transformations of human joints during motion. The use of this alternative computational approach to integrate ODEs is well motivated by the fact that bone rigid transformations satisfy the mechanical constraints of human joint motion, which provide conditions that guarantee the diagonalizability of local bone transformations and consequently of the resulting joint transformations. In a comparison with the scaling and squaring method, we discuss the usefulness of the matrix eigendecomposition technique which reduces significantly the computational burden associated with the computation of matrix exponential over a dense regular grid. Finally, we have applied the method to enhance the temporal resolution of dynamic MRI sequences of the ankle joint. To conclude, numerical experiments show that the eigendecomposition method is more capable of balancing the trade-off between accuracy, computation time, and memory requirements.
Disentangling Pose from Appearance in Monochrome Hand Images
Apr 16, 2019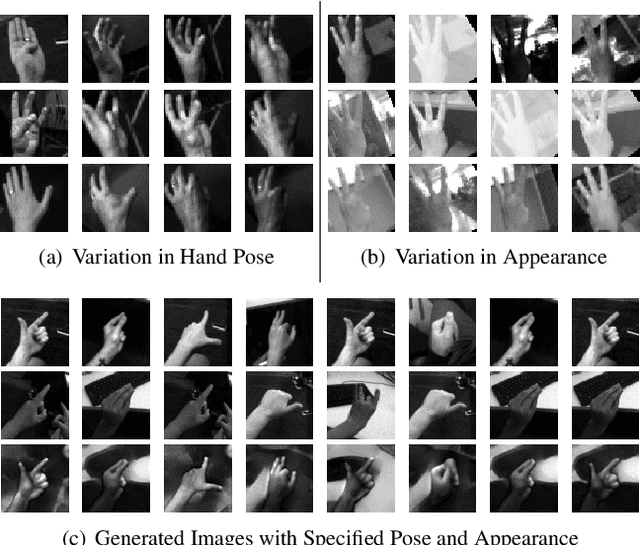

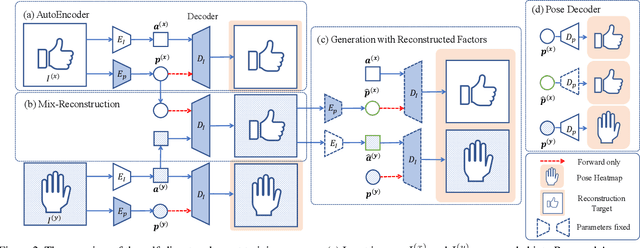

Hand pose estimation from the monocular 2D image is challenging due to the variation in lighting, appearance, and background. While some success has been achieved using deep neural networks, they typically require collecting a large dataset that adequately samples all the axes of variation of hand images. It would, therefore, be useful to find a representation of hand pose which is independent of the image appearance~(like hand texture, lighting, background), so that we can synthesize unseen images by mixing pose-appearance combinations. In this paper, we present a novel technique that disentangles the representation of pose from a complementary appearance factor in 2D monochrome images. We supervise this disentanglement process using a network that learns to generate images of hand using specified pose+appearance features. Unlike previous work, we do not require image pairs with a matching pose; instead, we use the pose annotations already available and introduce a novel use of cycle consistency to ensure orthogonality between the factors. Experimental results show that our self-disentanglement scheme successfully decomposes the hand image into the pose and its complementary appearance features of comparable quality as the method using paired data. Additionally, training the model with extra synthesized images with unseen hand-appearance combinations by re-mixing pose and appearance factors from different images can improve the 2D pose estimation performance.
Radioactive data: tracing through training
Feb 03, 2020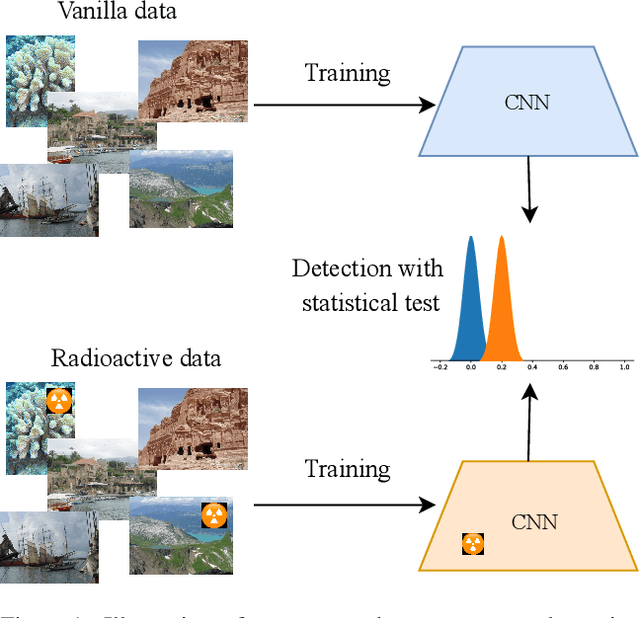
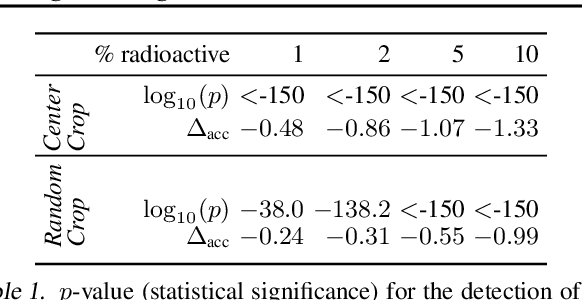
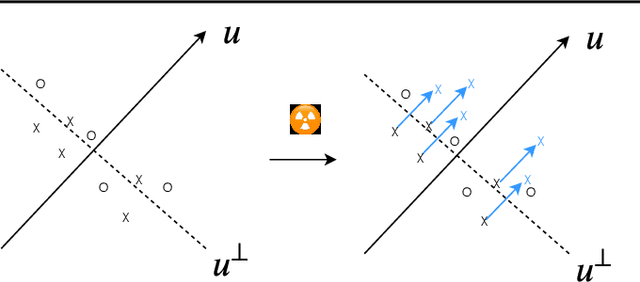
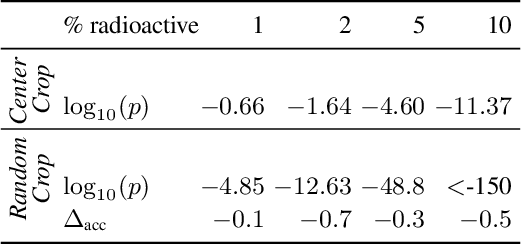
We want to detect whether a particular image dataset has been used to train a model. We propose a new technique, \emph{radioactive data}, that makes imperceptible changes to this dataset such that any model trained on it will bear an identifiable mark. The mark is robust to strong variations such as different architectures or optimization methods. Given a trained model, our technique detects the use of radioactive data and provides a level of confidence (p-value). Our experiments on large-scale benchmarks (Imagenet), using standard architectures (Resnet-18, VGG-16, Densenet-121) and training procedures, show that we can detect usage of radioactive data with high confidence (p<10^-4) even when only 1% of the data used to trained our model is radioactive. Our method is robust to data augmentation and the stochasticity of deep network optimization. As a result, it offers a much higher signal-to-noise ratio than data poisoning and backdoor methods.
Adaptive Neuron-wise Discriminant Criterion and Adaptive Center Loss at Hidden Layer for Deep Convolutional Neural Network
Apr 17, 2020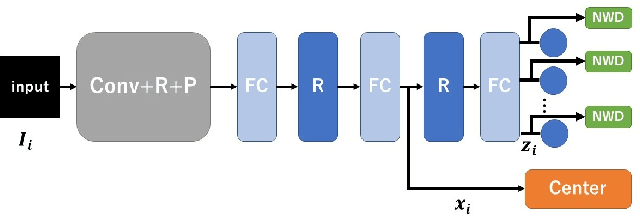
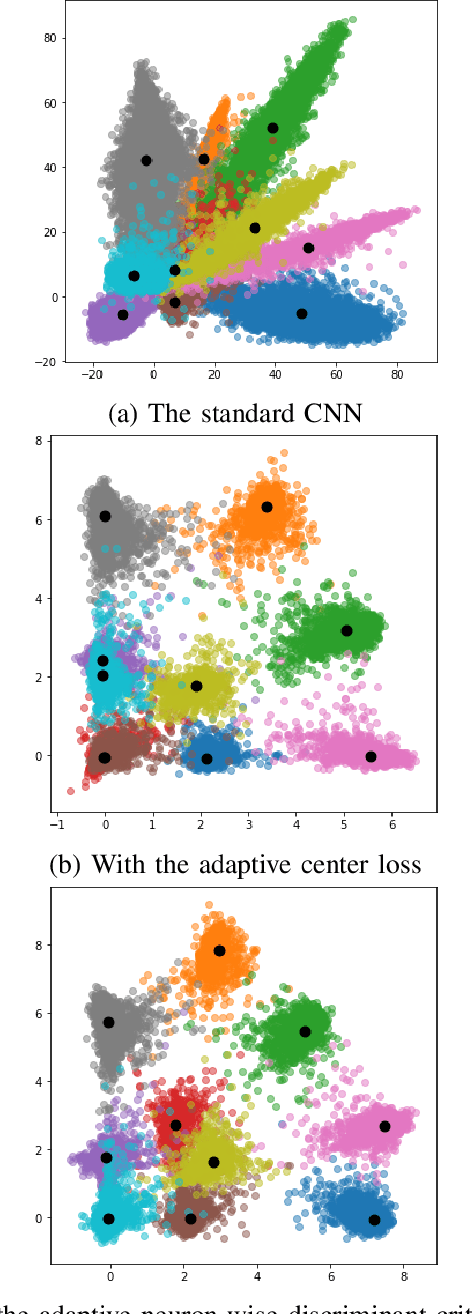
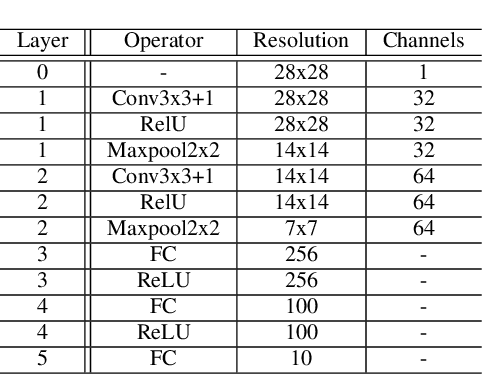
A deep convolutional neural network (CNN) has been widely used in image classification and gives better classification accuracy than the other techniques. The softmax cross-entropy loss function is often used for classification tasks. There are some works to introduce the additional terms in the objective function for training to make the features of the output layer more discriminative. The neuron-wise discriminant criterion makes the input feature of each neuron in the output layer discriminative by introducing the discriminant criterion to each of the features. Similarly, the center loss was introduced to the features before the softmax activation function for face recognition to make the deep features discriminative. The ReLU function is often used for the network as an active function in the hidden layers of the CNN. However, it is observed that the deep features trained by using the ReLU function are not discriminative enough and show elongated shapes. In this paper, we propose to use the neuron-wise discriminant criterion at the output layer and the center-loss at the hidden layer. Also, we introduce the online computation of the means of each class with the exponential forgetting. We named them adaptive neuron-wise discriminant criterion and adaptive center loss, respectively. The effectiveness of the integration of the adaptive neuron-wise discriminant criterion and the adaptive center loss is shown by the experiments with MNSIT, FashionMNIST, CIFAR10, CIFAR100, and STL10. Source code is at https://github.com/i13abe/Adaptive-discriminant-and-center
Dense RepPoints: Representing Visual Objects with Dense Point Sets
Dec 24, 2019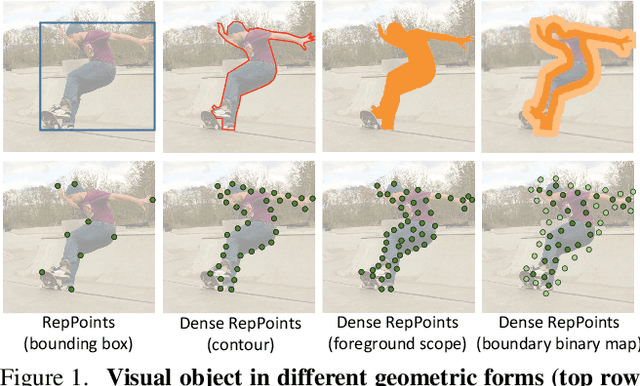
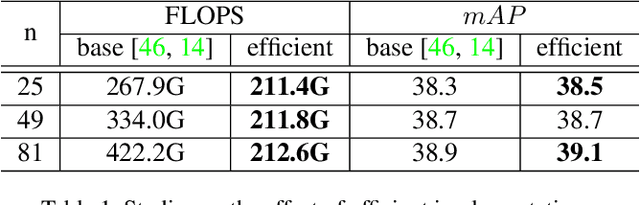
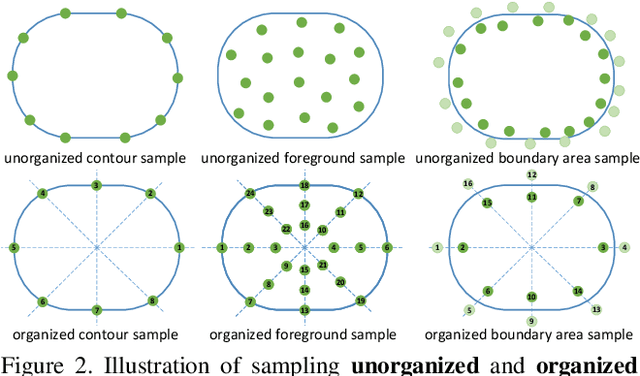
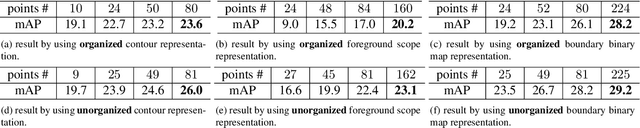
We present an object representation, called \textbf{Dense RepPoints}, for flexible and detailed modeling of object appearance and geometry. In contrast to the coarse geometric localization and feature extraction of bounding boxes, Dense RepPoints adaptively distributes a dense set of points to semantically and geometrically significant positions on an object, providing informative cues for object analysis. Techniques are developed to address challenges related to supervised training for dense point sets from image segments annotations and making this extensive representation computationally practical. In addition, the versatility of this representation is exploited to model object structure over multiple levels of granularity. Dense RepPoints significantly improves performance on geometrically-oriented visual understanding tasks, including a $1.6$ AP gain in object detection on the challenging COCO benchmark.