 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification
Jul 03, 2019
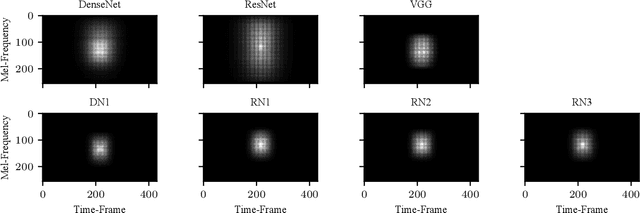
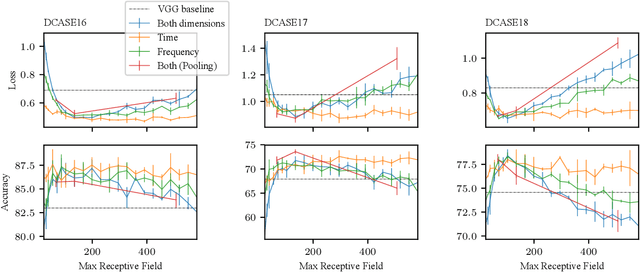
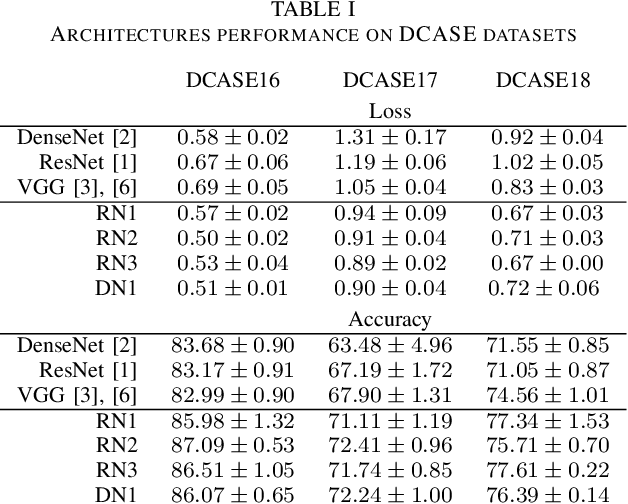

Convolutional Neural Networks (CNNs) have had great success in many machine vision as well as machine audition tasks. Many image recognition network architectures have consequently been adapted for audio processing tasks. However, despite some successes, the performance of many of these did not translate from the image to the audio domain. For example, very deep architectures such as ResNet and DenseNet, which significantly outperform VGG in image recognition, do not perform better in audio processing tasks such as Acoustic Scene Classification (ASC). In this paper, we investigate the reasons why such powerful architectures perform worse in ASC compared to simpler models (e.g., VGG). To this end, we analyse the receptive field (RF) of these CNNs and demonstrate the importance of the RF to the generalization capability of the models. Using our receptive field analysis, we adapt both ResNet and DenseNet, achieving state-of-the-art performance and eventually outperforming the VGG-based models. We introduce systematic ways of adapting the RF in CNNs, and present results on three data sets that show how changing the RF over the time and frequency dimensions affects a model's performance. Our experimental results show that very small or very large RFs can cause performance degradation, but deep models can be made to generalize well by carefully choosing an appropriate RF size within a certain range.
Probing Representations Learned by Multimodal Recurrent and Transformer Models
Aug 29, 2019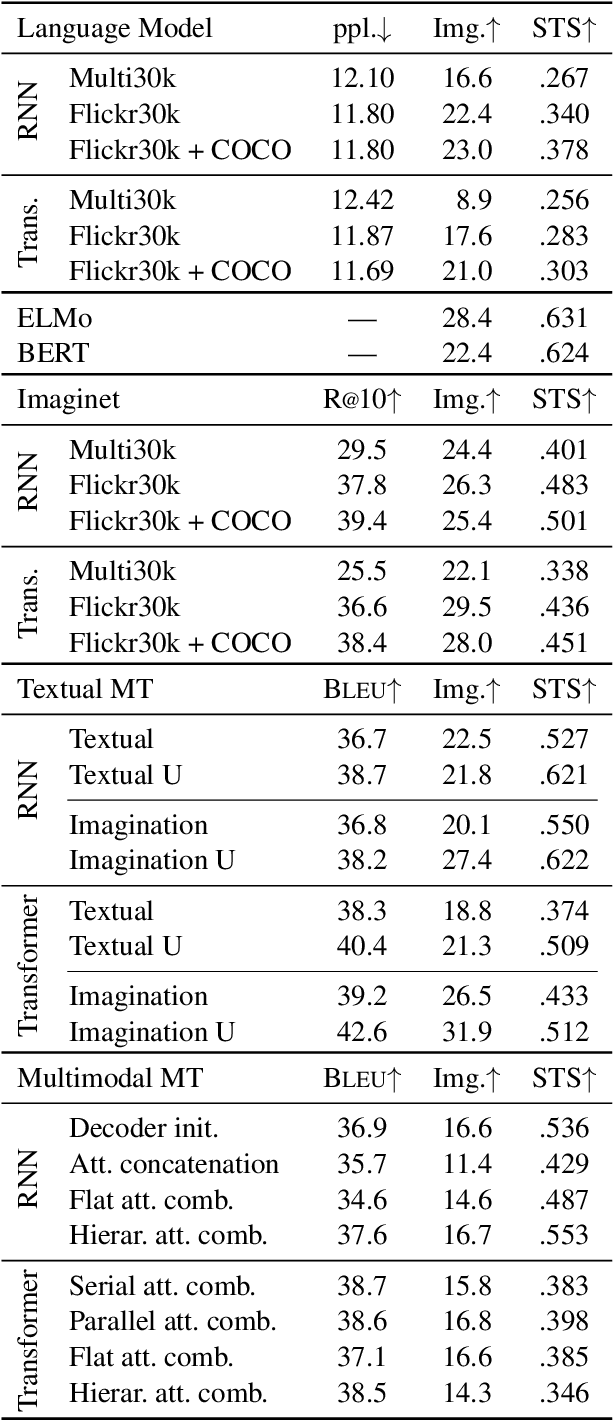

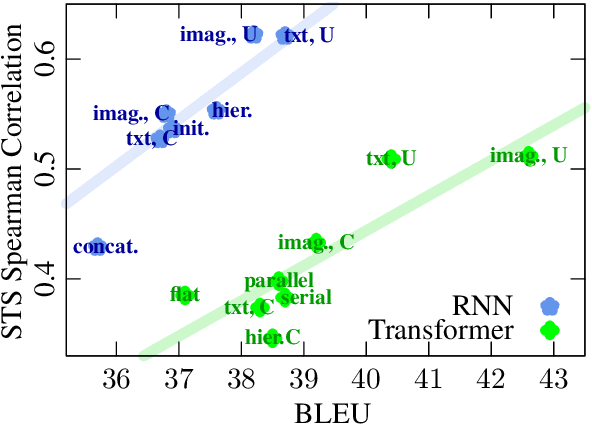

Recent literature shows that large-scale language modeling provides excellent reusable sentence representations with both recurrent and self-attentive architectures. However, there has been less clarity on the commonalities and differences in the representational properties induced by the two architectures. It also has been shown that visual information serves as one of the means for grounding sentence representations. In this paper, we present a meta-study assessing the representational quality of models where the training signal is obtained from different modalities, in particular, language modeling, image features prediction, and both textual and multimodal machine translation. We evaluate textual and visual features of sentence representations obtained using predominant approaches on image retrieval and semantic textual similarity. Our experiments reveal that on moderate-sized datasets, a sentence counterpart in a target language or visual modality provides much stronger training signal for sentence representation than language modeling. Importantly, we observe that while the Transformer models achieve superior machine translation quality, representations from the recurrent neural network based models perform significantly better over tasks focused on semantic relevance.
Self-Supervised Scene De-occlusion
Apr 06, 2020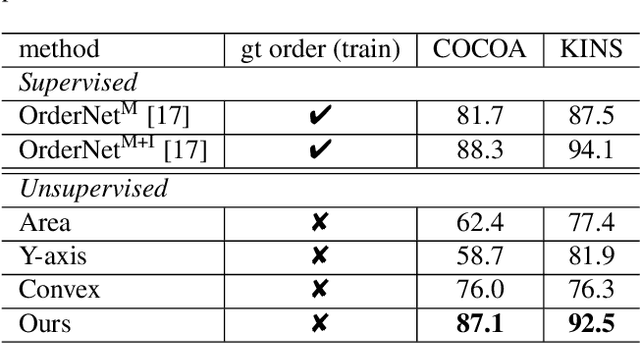
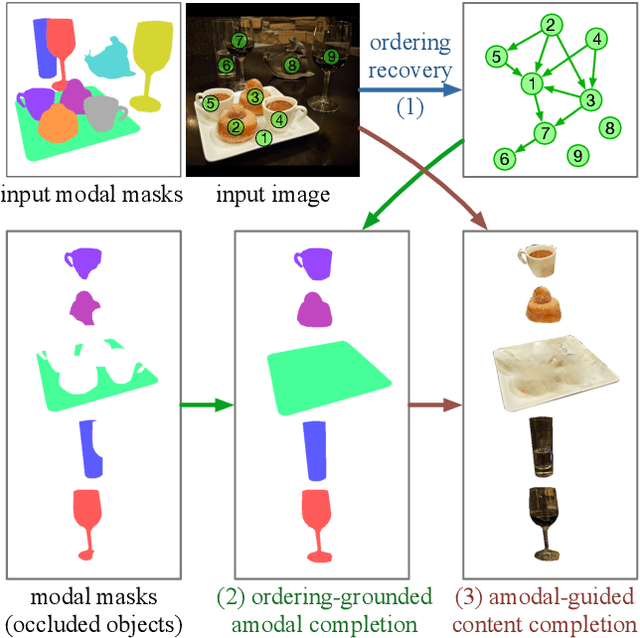
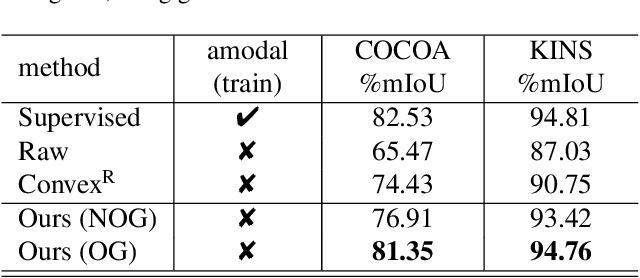
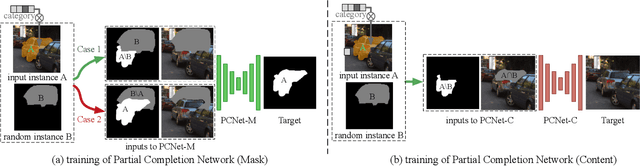
Natural scene understanding is a challenging task, particularly when encountering images of multiple objects that are partially occluded. This obstacle is given rise by varying object ordering and positioning. Existing scene understanding paradigms are able to parse only the visible parts, resulting in incomplete and unstructured scene interpretation. In this paper, we investigate the problem of scene de-occlusion, which aims to recover the underlying occlusion ordering and complete the invisible parts of occluded objects. We make the first attempt to address the problem through a novel and unified framework that recovers hidden scene structures without ordering and amodal annotations as supervisions. This is achieved via Partial Completion Network (PCNet)-mask (M) and -content (C), that learn to recover fractions of object masks and contents, respectively, in a self-supervised manner. Based on PCNet-M and PCNet-C, we devise a novel inference scheme to accomplish scene de-occlusion, via progressive ordering recovery, amodal completion and content completion. Extensive experiments on real-world scenes demonstrate the superior performance of our approach to other alternatives. Remarkably, our approach that is trained in a self-supervised manner achieves comparable results to fully-supervised methods. The proposed scene de-occlusion framework benefits many applications, including high-quality and controllable image manipulation and scene recomposition (see Fig. 1), as well as the conversion of existing modal mask annotations to amodal mask annotations.
Structured Knowledge Representation for Image Retrieval
Jun 30, 2011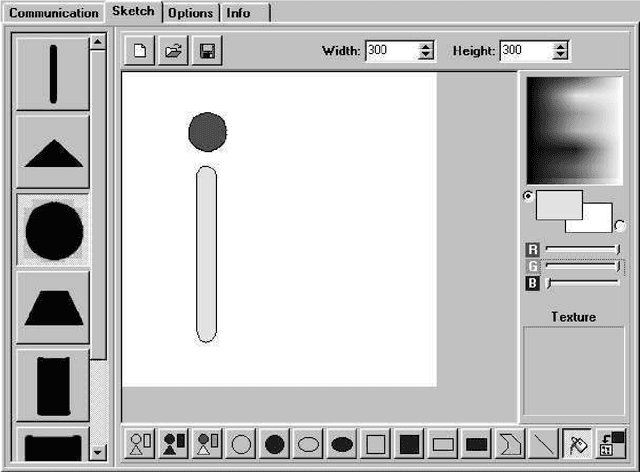
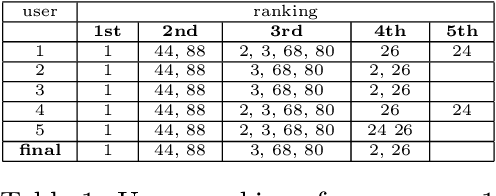
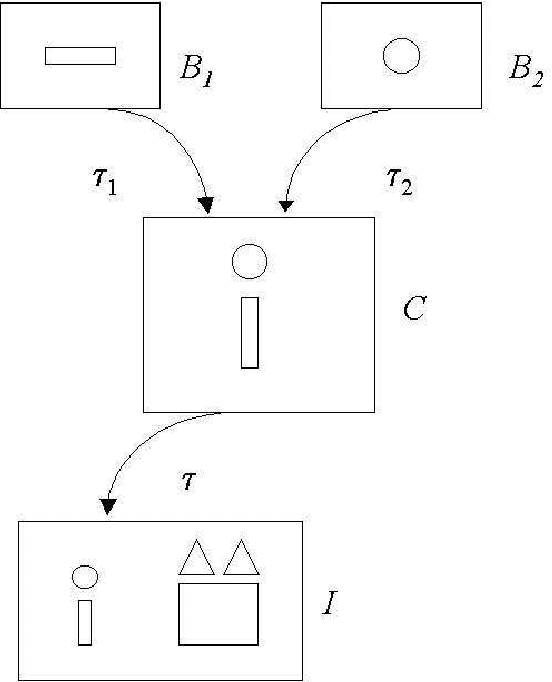
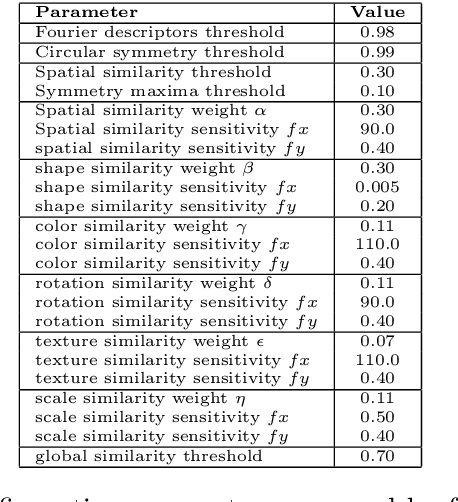
We propose a structured approach to the problem of retrieval of images by content and present a description logic that has been devised for the semantic indexing and retrieval of images containing complex objects. As other approaches do, we start from low-level features extracted with image analysis to detect and characterize regions in an image. However, in contrast with feature-based approaches, we provide a syntax to describe segmented regions as basic objects and complex objects as compositions of basic ones. Then we introduce a companion extensional semantics for defining reasoning services, such as retrieval, classification, and subsumption. These services can be used for both exact and approximate matching, using similarity measures. Using our logical approach as a formal specification, we implemented a complete client-server image retrieval system, which allows a user to pose both queries by sketch and queries by example. A set of experiments has been carried out on a testbed of images to assess the retrieval capabilities of the system in comparison with expert users ranking. Results are presented adopting a well-established measure of quality borrowed from textual information retrieval.
Enhancing Flood Impact Analysis using Interactive Retrieval of Social Media Images
Aug 09, 2019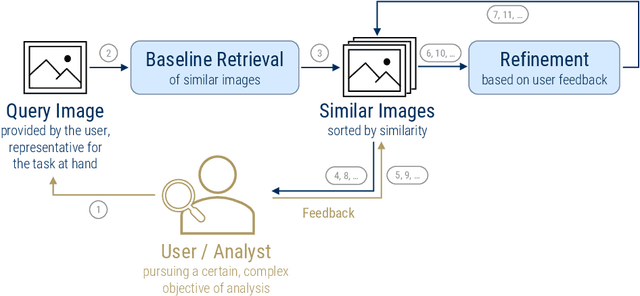
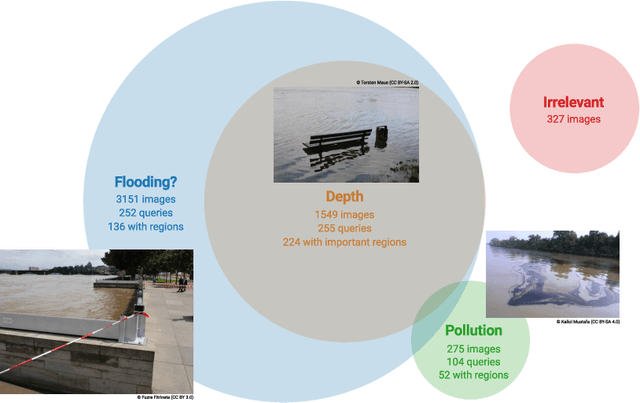

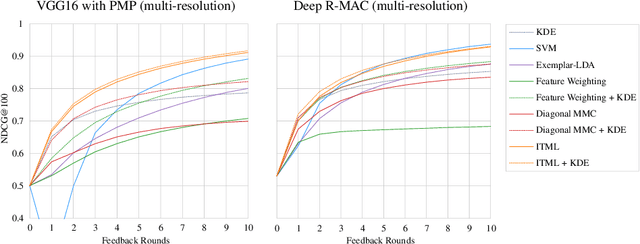
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to a coarse distribution of sensors or sensor failures. This limitation could be alleviated by leveraging information contained in images of the event posted on social media platforms, so-called "Volunteered Geographic Information (VGI)". To save the analyst from the need to inspect all images posted online manually, we propose to use content-based image retrieval with the possibility of relevance feedback for retrieving only relevant images of the event to be analyzed. To evaluate this approach, we introduce a new dataset of 3,710 flood images, annotated by domain experts regarding their relevance with respect to three tasks (determining the flooded area, inundation depth, water pollution). We compare several image features and relevance feedback methods on that dataset, mixed with 97,085 distractor images, and are able to improve the precision among the top 100 retrieval results from 55% with the baseline retrieval to 87% after 5 rounds of feedback.
Benchmarking Adversarial Robustness
Dec 26, 2019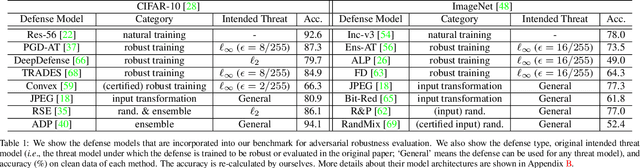
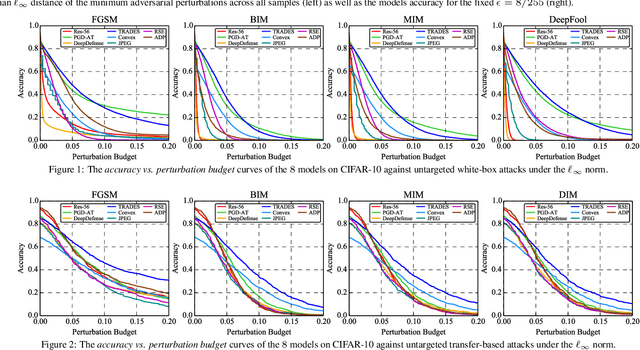
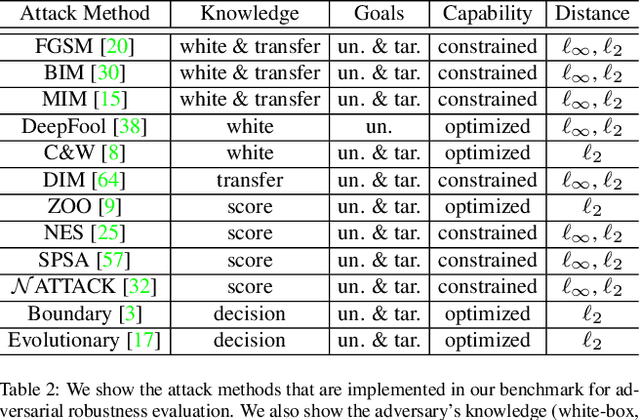
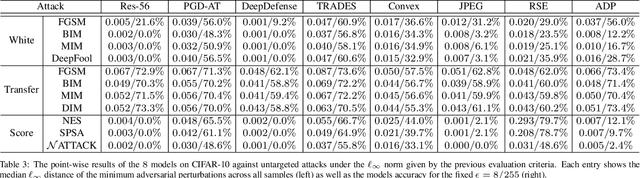
Deep neural networks are vulnerable to adversarial examples, which becomes one of the most important research problems in the development of deep learning. While a lot of efforts have been made in recent years, it is of great significance to perform correct and complete evaluations of the adversarial attack and defense algorithms. In this paper, we establish a comprehensive, rigorous, and coherent benchmark to evaluate adversarial robustness on image classification tasks. After briefly reviewing plenty of representative attack and defense methods, we perform large-scale experiments with two robustness curves as the fair-minded evaluation criteria to fully understand the performance of these methods. Based on the evaluation results, we draw several important findings and provide insights for future research.
DeepSD: Generating High Resolution Climate Change Projections through Single Image Super-Resolution
Mar 09, 2017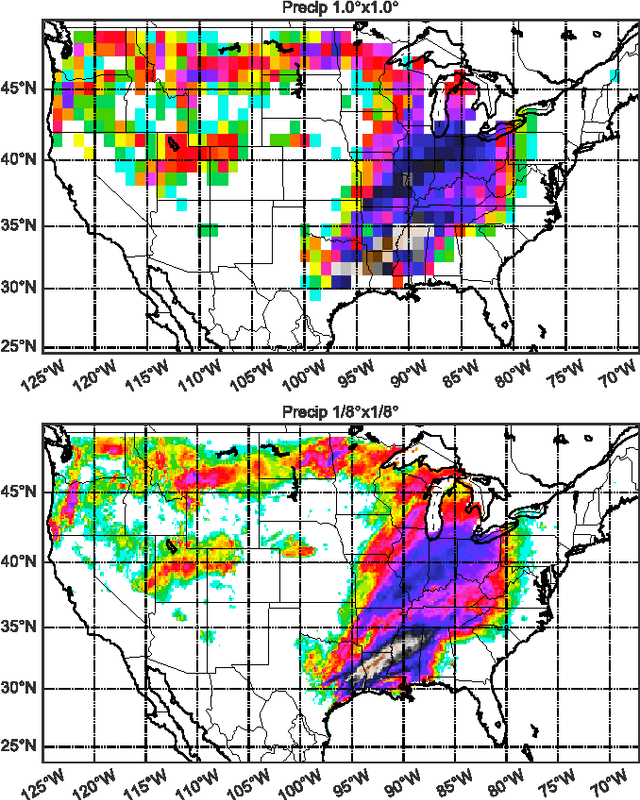
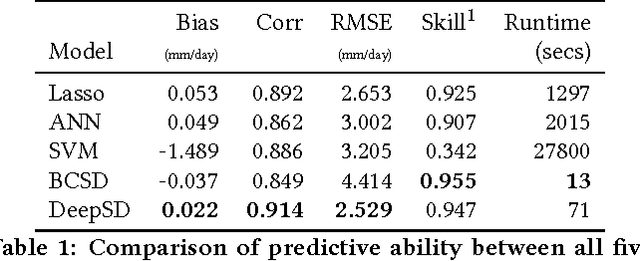

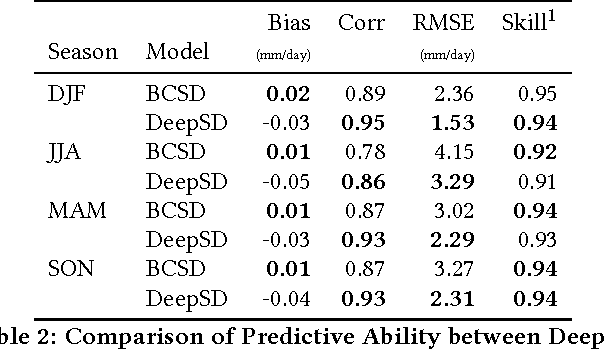
The impacts of climate change are felt by most critical systems, such as infrastructure, ecological systems, and power-plants. However, contemporary Earth System Models (ESM) are run at spatial resolutions too coarse for assessing effects this localized. Local scale projections can be obtained using statistical downscaling, a technique which uses historical climate observations to learn a low-resolution to high-resolution mapping. Depending on statistical modeling choices, downscaled projections have been shown to vary significantly terms of accuracy and reliability. The spatio-temporal nature of the climate system motivates the adaptation of super-resolution image processing techniques to statistical downscaling. In our work, we present DeepSD, a generalized stacked super resolution convolutional neural network (SRCNN) framework for statistical downscaling of climate variables. DeepSD augments SRCNN with multi-scale input channels to maximize predictability in statistical downscaling. We provide a comparison with Bias Correction Spatial Disaggregation as well as three Automated-Statistical Downscaling approaches in downscaling daily precipitation from 1 degree (~100km) to 1/8 degrees (~12.5km) over the Continental United States. Furthermore, a framework using the NASA Earth Exchange (NEX) platform is discussed for downscaling more than 20 ESM models with multiple emission scenarios.
Context-Aware Domain Adaptation in Semantic Segmentation
Mar 09, 2020
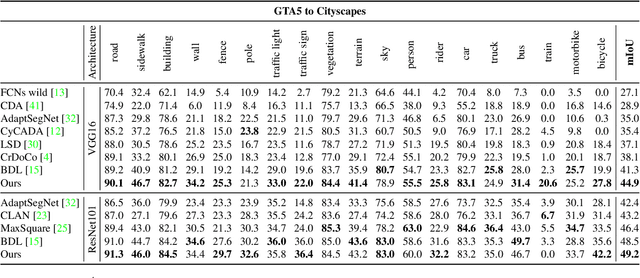
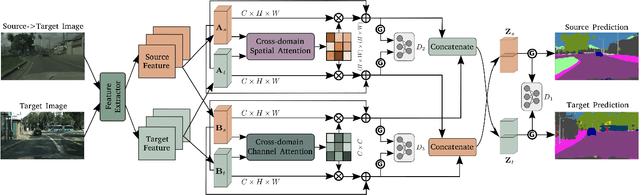
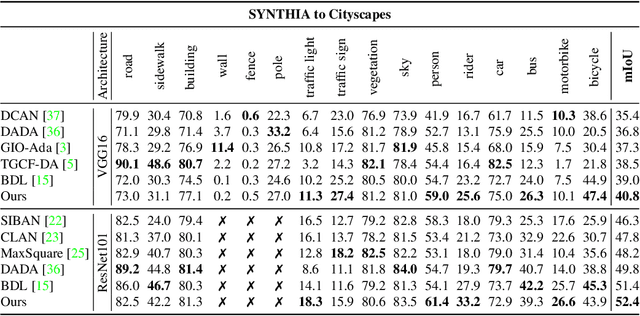
In this paper, we consider the problem of unsupervised domain adaptation in the semantic segmentation. There are two primary issues in this field, i.e., what and how to transfer domain knowledge across two domains. Existing methods mainly focus on adapting domain-invariant features (what to transfer) through adversarial learning (how to transfer). Context dependency is essential for semantic segmentation, however, its transferability is still not well understood. Furthermore, how to transfer contextual information across two domains remains unexplored. Motivated by this, we propose a cross-attention mechanism based on self-attention to capture context dependencies between two domains and adapt transferable context. To achieve this goal, we design two cross-domain attention modules to adapt context dependencies from both spatial and channel views. Specifically, the spatial attention module captures local feature dependencies between each position in the source and target image. The channel attention module models semantic dependencies between each pair of cross-domain channel maps. To adapt context dependencies, we further selectively aggregate the context information from two domains. The superiority of our method over existing state-of-the-art methods is empirically proved on "GTA5 to Cityscapes" and "SYNTHIA to Cityscapes".
Augmented Semantic Signatures of Airborne LiDAR Point Clouds for Determining Change in Time-varying Data
Apr 29, 2020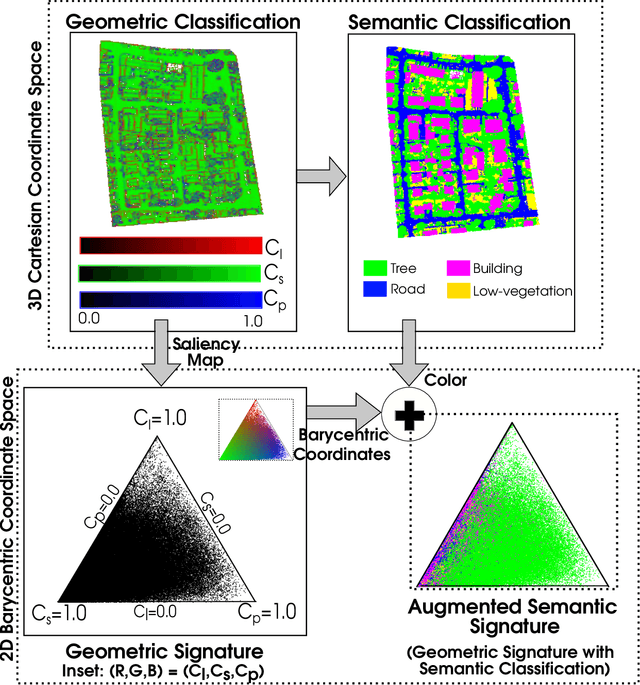
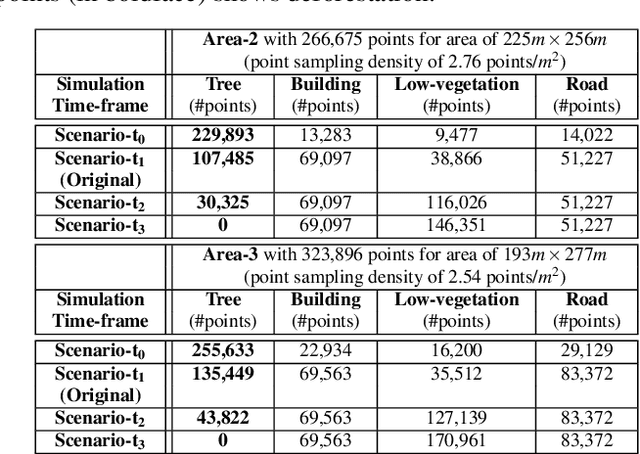
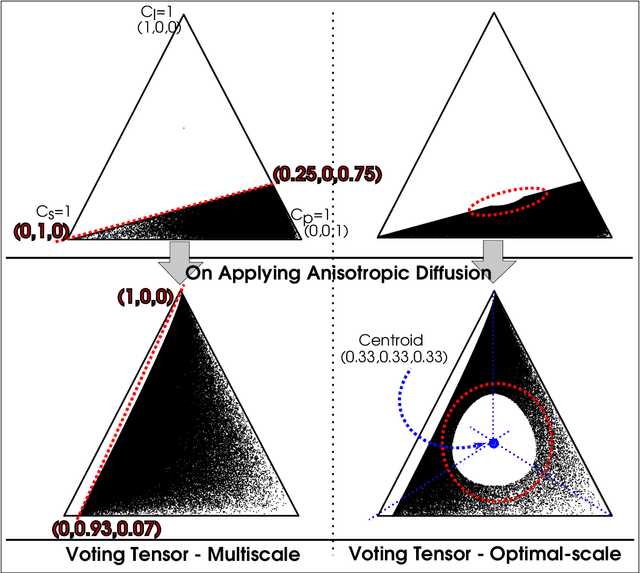
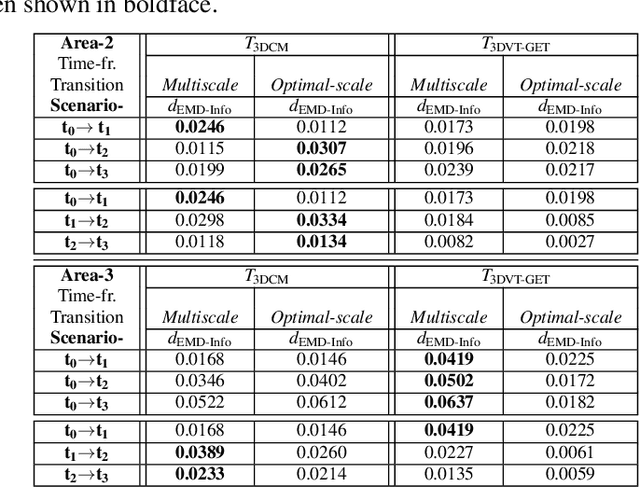
LiDAR point clouds provide rich geometric information, which is particularly useful for the analysis of complex scenes of urban regions. Finding structural and semantic differences between two different three-dimensional point clouds, say, of the same region but acquired at different time instances is an important problem. Usually, the data capture has inconsistencies when taken at different time instances, e.g., sampling densities, and the orientation of the flight path. Hence, change detection involves computationally expensive registration and segmentation. We are interested in capturing the relative differences in the geometric uncertainty and semantic content of the point cloud without the registration process. Hence, we propose an orientation-invariant geometric signature of the point cloud, which integrates its probabilistic geometric and semantic classifications. We study different properties of the geometric signature, which are image-based encoding of geometric uncertainty and semantic content. We explore different metrics to determine differences between these signatures, which in turn compare point clouds without performing point-to-point registration. We have observed that a point cloud with four semantic classes, namely, buildings, trees, road, and low-vegetation, that the tree class shows a characteristic pattern. Thus, we use a case study of airborne LiDAR point clouds where the visual and the quantitative comparisons of the geometric signatures of point clouds are useful in demonstrating changes during a thematic event, such as progressive deforestation, in the topography of an urban region. Our results show that the differences in the signatures corroborate with the geometric and semantic differences of the point clouds.
A Little Fog for a Large Turn
Jan 16, 2020
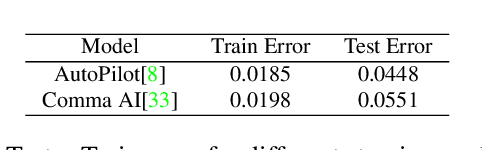
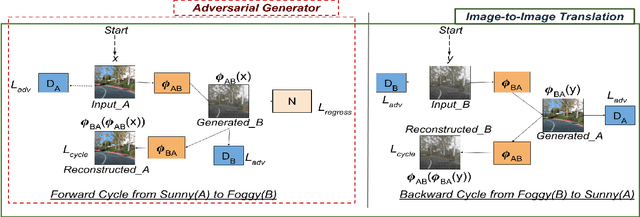

Small, carefully crafted perturbations called adversarial perturbations can easily fool neural networks. However, these perturbations are largely additive and not naturally found. We turn our attention to the field of Autonomous navigation wherein adverse weather conditions such as fog have a drastic effect on the predictions of these systems. These weather conditions are capable of acting like natural adversaries that can help in testing models. To this end, we introduce a general notion of adversarial perturbations, which can be created using generative models and provide a methodology inspired by Cycle-Consistent Generative Adversarial Networks to generate adversarial weather conditions for a given image. Our formulation and results show that these images provide a suitable testbed for steering models used in Autonomous navigation models. Our work also presents a more natural and general definition of Adversarial perturbations based on Perceptual Similarity.