 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VILA: On Pre-training for Visual Language Models
Dec 14, 2023
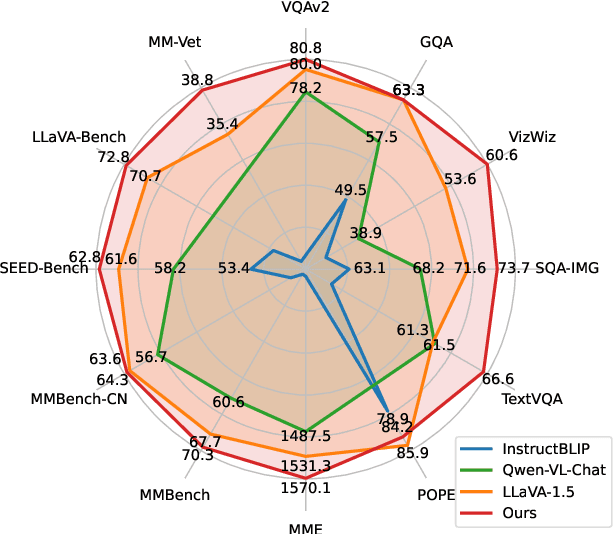
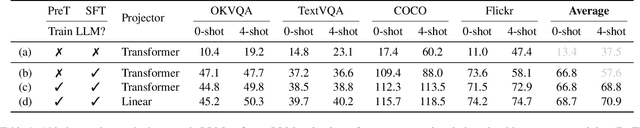
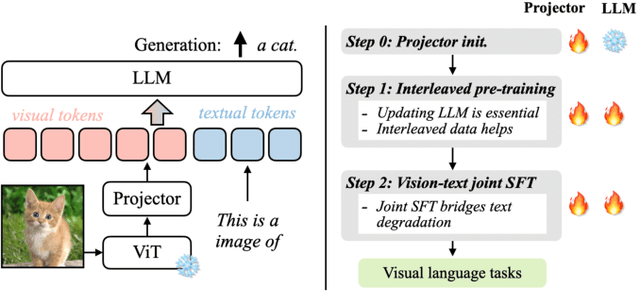

Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
Exploring the Naturalness of AI-Generated Images
Dec 14, 2023The proliferation of Artificial Intelligence-Generated Images (AGIs) has greatly expanded the Image Naturalness Assessment (INA) problem. Different from early definitions that mainly focus on tone-mapped images with limited distortions (e.g., exposure, contrast, and color reproduction), INA on AI-generated images is especially challenging as it has more diverse contents and could be affected by factors from multiple perspectives, including low-level technical distortions and high-level rationality distortions. In this paper, we take the first step to benchmark and assess the visual naturalness of AI-generated images. First, we construct the AI-Generated Image Naturalness (AGIN) database by conducting a large-scale subjective study to collect human opinions on the overall naturalness as well as perceptions from technical and rationality perspectives. AGIN verifies that naturalness is universally and disparately affected by both technical and rationality distortions. Second, we propose the Joint Objective Image Naturalness evaluaTor (JOINT), to automatically learn the naturalness of AGIs that aligns human ratings. Specifically, JOINT imitates human reasoning in naturalness evaluation by jointly learning both technical and rationality perspectives. Experimental results show our proposed JOINT significantly surpasses baselines for providing more subjectively consistent results on naturalness assessment. Our database and code will be released in https://github.com/zijianchen98/AGIN.
Brain-optimized inference improves reconstructions of fMRI brain activity
Dec 12, 2023The release of large datasets and developments in AI have led to dramatic improvements in decoding methods that reconstruct seen images from human brain activity. We evaluate the prospect of further improving recent decoding methods by optimizing for consistency between reconstructions and brain activity during inference. We sample seed reconstructions from a base decoding method, then iteratively refine these reconstructions using a brain-optimized encoding model that maps images to brain activity. At each iteration, we sample a small library of images from an image distribution (a diffusion model) conditioned on a seed reconstruction from the previous iteration. We select those that best approximate the measured brain activity when passed through our encoding model, and use these images for structural guidance during the generation of the small library in the next iteration. We reduce the stochasticity of the image distribution at each iteration, and stop when a criterion on the "width" of the image distribution is met. We show that when this process is applied to recent decoding methods, it outperforms the base decoding method as measured by human raters, a variety of image feature metrics, and alignment to brain activity. These results demonstrate that reconstruction quality can be significantly improved by explicitly aligning decoding distributions to brain activity distributions, even when the seed reconstruction is output from a state-of-the-art decoding algorithm. Interestingly, the rate of refinement varies systematically across visual cortex, with earlier visual areas generally converging more slowly and preferring narrower image distributions, relative to higher-level brain areas. Brain-optimized inference thus offers a succinct and novel method for improving reconstructions and exploring the diversity of representations across visual brain areas.
VLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering
Dec 13, 2023In this work, we propose an efficient Video-Language Alignment via Frame-Prompting and Distilling (VLAP) network. Our VLAP model addresses both efficient frame sampling and effective cross-modal alignment in a unified way. In our VLAP network, we design a new learnable question-aware Frame-Prompter together with a new cross-modal distillation (QFormer-Distiller) module. Pre-trained large image-language models have shown promising results on problems such as visual question answering. However, how to efficiently and effectively sample image frames when adapting pre-trained large image-language model to video-language alignment is still the major challenge. Compared with prior work, our VLAP model demonstrates the capability of selecting key frames with critical contents, thus improving the video-language alignment accuracy while reducing the inference latency (+3.3% on NExT-QA Temporal with 3.0X speed up). Overall, our VLAP network outperforms (e.g. +4.6% on STAR Interaction and +2.2% on STAR average with 3.0X speed up, ours 2-frames out-perform SeViLA 4-frames on VLEP with 4.2X speed up) the state-of-the-art methods on the video question-answering benchmarks.
Diffusing More Objects for Semi-Supervised Domain Adaptation with Less Labeling
Dec 19, 2023For object detection, it is possible to view the prediction of bounding boxes as a reverse diffusion process. Using a diffusion model, the random bounding boxes are iteratively refined in a denoising step, conditioned on the image. We propose a stochastic accumulator function that starts each run with random bounding boxes and combines the slightly different predictions. We empirically verify that this improves detection performance. The improved detections are leveraged on unlabelled images as weighted pseudo-labels for semi-supervised learning. We evaluate the method on a challenging out-of-domain test set. Our method brings significant improvements and is on par with human-selected pseudo-labels, while not requiring any human involvement.
Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation
Dec 15, 2023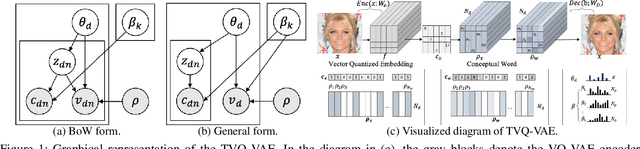
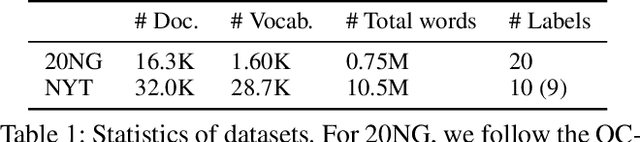


This paper introduces a novel approach for topic modeling utilizing latent codebooks from Vector-Quantized Variational Auto-Encoder~(VQ-VAE), discretely encapsulating the rich information of the pre-trained embeddings such as the pre-trained language model. From the novel interpretation of the latent codebooks and embeddings as conceptual bag-of-words, we propose a new generative topic model called Topic-VQ-VAE~(TVQ-VAE) which inversely generates the original documents related to the respective latent codebook. The TVQ-VAE can visualize the topics with various generative distributions including the traditional BoW distribution and the autoregressive image generation. Our experimental results on document analysis and image generation demonstrate that TVQ-VAE effectively captures the topic context which reveals the underlying structures of the dataset and supports flexible forms of document generation. Official implementation of the proposed TVQ-VAE is available at https://github.com/clovaai/TVQ-VAE.
Multiscale Vision Transformer With Deep Clustering-Guided Refinement for Weakly Supervised Object Localization
Dec 15, 2023This work addresses the task of weakly-supervised object localization. The goal is to learn object localization using only image-level class labels, which are much easier to obtain compared to bounding box annotations. This task is important because it reduces the need for labor-intensive ground-truth annotations. However, methods for object localization trained using weak supervision often suffer from limited accuracy in localization. To address this challenge and enhance localization accuracy, we propose a multiscale object localization transformer (MOLT). It comprises multiple object localization transformers that extract patch embeddings across various scales. Moreover, we introduce a deep clustering-guided refinement method that further enhances localization accuracy by utilizing separately extracted image segments. These segments are obtained by clustering pixels using convolutional neural networks. Finally, we demonstrate the effectiveness of our proposed method by conducting experiments on the publicly available ILSVRC-2012 dataset.
* 5 pages
Enhancing Neural Training via a Correlated Dynamics Model
Dec 20, 2023As neural networks grow in scale, their training becomes both computationally demanding and rich in dynamics. Amidst the flourishing interest in these training dynamics, we present a novel observation: Parameters during training exhibit intrinsic correlations over time. Capitalizing on this, we introduce Correlation Mode Decomposition (CMD). This algorithm clusters the parameter space into groups, termed modes, that display synchronized behavior across epochs. This enables CMD to efficiently represent the training dynamics of complex networks, like ResNets and Transformers, using only a few modes. Moreover, test set generalization is enhanced. We introduce an efficient CMD variant, designed to run concurrently with training. Our experiments indicate that CMD surpasses the state-of-the-art method for compactly modeled dynamics on image classification. Our modeling can improve training efficiency and lower communication overhead, as shown by our preliminary experiments in the context of federated learning.
On the Quantification of Image Reconstruction Uncertainty without Training Data
Nov 16, 2023Computational imaging plays a pivotal role in determining hidden information from sparse measurements. A robust inverse solver is crucial to fully characterize the uncertainty induced by these measurements, as it allows for the estimation of the complete posterior of unrecoverable targets. This, in turn, facilitates a probabilistic interpretation of observational data for decision-making. In this study, we propose a deep variational framework that leverages a deep generative model to learn an approximate posterior distribution to effectively quantify image reconstruction uncertainty without the need for training data. We parameterize the target posterior using a flow-based model and minimize their Kullback-Leibler (KL) divergence to achieve accurate uncertainty estimation. To bolster stability, we introduce a robust flow-based model with bi-directional regularization and enhance expressivity through gradient boosting. Additionally, we incorporate a space-filling design to achieve substantial variance reduction on both latent prior space and target posterior space. We validate our method on several benchmark tasks and two real-world applications, namely fastMRI and black hole image reconstruction. Our results indicate that our method provides reliable and high-quality image reconstruction with robust uncertainty estimation.
Enhancing Instance-Level Image Classification with Set-Level Labels
Nov 09, 2023Instance-level image classification tasks have traditionally relied on single-instance labels to train models, e.g., few-shot learning and transfer learning. However, set-level coarse-grained labels that capture relationships among instances can provide richer information in real-world scenarios. In this paper, we present a novel approach to enhance instance-level image classification by leveraging set-level labels. We provide a theoretical analysis of the proposed method, including recognition conditions for fast excess risk rate, shedding light on the theoretical foundations of our approach. We conducted experiments on two distinct categories of datasets: natural image datasets and histopathology image datasets. Our experimental results demonstrate the effectiveness of our approach, showcasing improved classification performance compared to traditional single-instance label-based methods. Notably, our algorithm achieves 13% improvement in classification accuracy compared to the strongest baseline on the histopathology image classification benchmarks. Importantly, our experimental findings align with the theoretical analysis, reinforcing the robustness and reliability of our proposed method. This work bridges the gap between instance-level and set-level image classification, offering a promising avenue for advancing the capabilities of image classification models with set-level coarse-grained labels.