 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta-learning curiosity algorithms
Mar 11, 2020
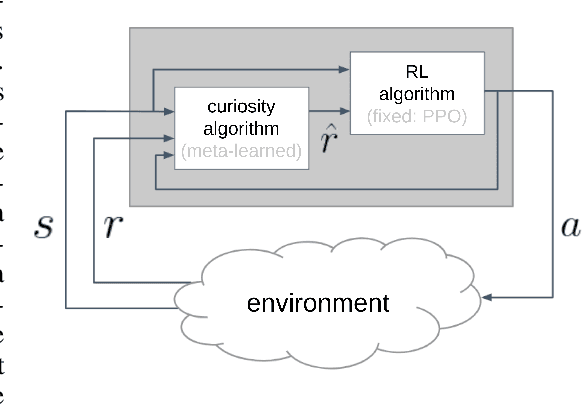
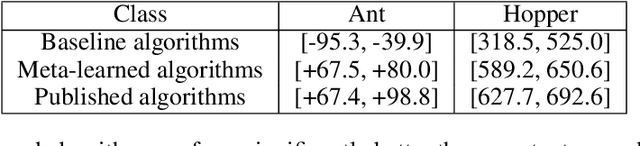
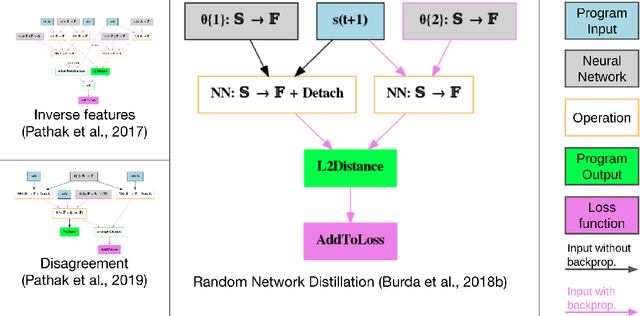
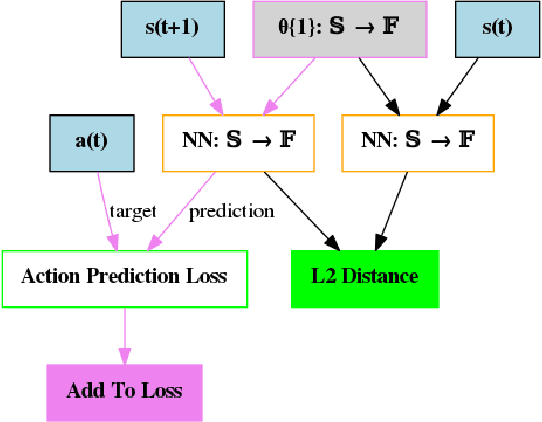
We hypothesize that curiosity is a mechanism found by evolution that encourages meaningful exploration early in an agent's life in order to expose it to experiences that enable it to obtain high rewards over the course of its lifetime. We formulate the problem of generating curious behavior as one of meta-learning: an outer loop will search over a space of curiosity mechanisms that dynamically adapt the agent's reward signal, and an inner loop will perform standard reinforcement learning using the adapted reward signal. However, current meta-RL methods based on transferring neural network weights have only generalized between very similar tasks. To broaden the generalization, we instead propose to meta-learn algorithms: pieces of code similar to those designed by humans in ML papers. Our rich language of programs combines neural networks with other building blocks such as buffers, nearest-neighbor modules and custom loss functions. We demonstrate the effectiveness of the approach empirically, finding two novel curiosity algorithms that perform on par or better than human-designed published curiosity algorithms in domains as disparate as grid navigation with image inputs, acrobot, lunar lander, ant and hopper.
Small Object Detection using Context and Attention
Dec 16, 2019
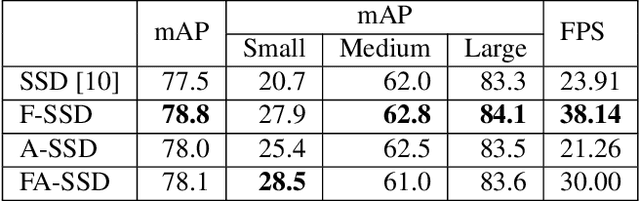

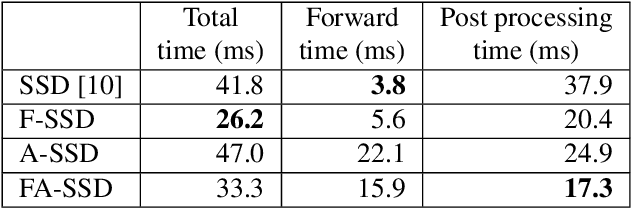
There are many limitations applying object detection algorithm on various environments. Especially detecting small objects is still challenging because they have low resolution and limited information. We propose an object detection method using context for improving accuracy of detecting small objects. The proposed method uses additional features from different layers as context by concatenating multi-scale features. We also propose object detection with attention mechanism which can focus on the object in image, and it can include contextual information from target layer. Experimental results shows that proposed method also has higher accuracy than conventional SSD on detecting small objects. Also, for 300$\times$300 input, we achieved 78.1% Mean Average Precision (mAP) on the PASCAL VOC2007 test set.
CANet: Cross-disease Attention Network for Joint Diabetic Retinopathy and Diabetic Macular Edema Grading
Nov 04, 2019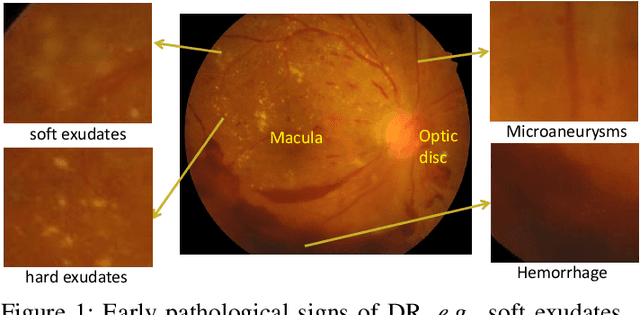
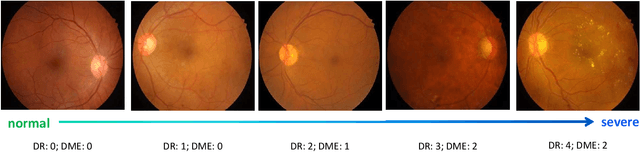
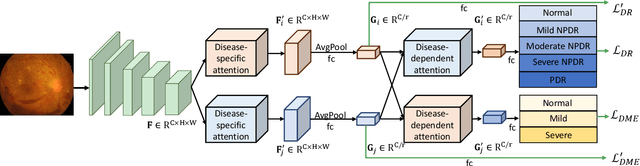
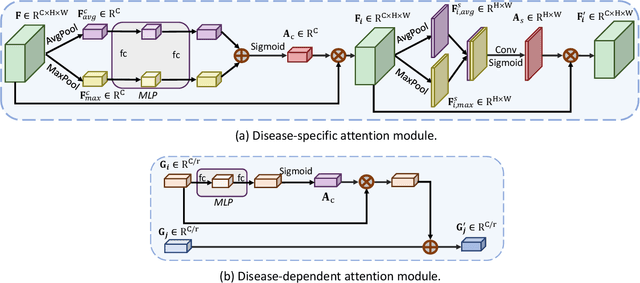
Diabetic retinopathy (DR) and diabetic macular edema (DME) are the leading causes of permanent blindness in the working-age population. Automatic grading of DR and DME helps ophthalmologists design tailored treatments to patients, thus is of vital importance in the clinical practice. However, prior works either grade DR or DME, and ignore the correlation between DR and its complication, i.e., DME. Moreover, the location information, e.g., macula and soft hard exhaust annotations, are widely used as a prior for grading. Such annotations are costly to obtain, hence it is desirable to develop automatic grading methods with only image-level supervision. In this paper, we present a novel cross-disease attention network (CANet) to jointly grade DR and DME by exploring the internal relationship between the diseases with only image-level supervision. Our key contributions include the disease-specific attention module to selectively learn useful features for individual diseases, and the disease-dependent attention module to further capture the internal relationship between the two diseases. We integrate these two attention modules in a deep network to produce disease-specific and disease-dependent features, and to maximize the overall performance jointly for grading DR and DME. We evaluate our network on two public benchmark datasets, i.e., ISBI 2018 IDRiD challenge dataset and Messidor dataset. Our method achieves the best result on the ISBI 2018 IDRiD challenge dataset and outperforms other methods on the Messidor dataset. Our code is publicly available at https://github.com/xmengli999/CANet.
The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification
Jul 03, 2019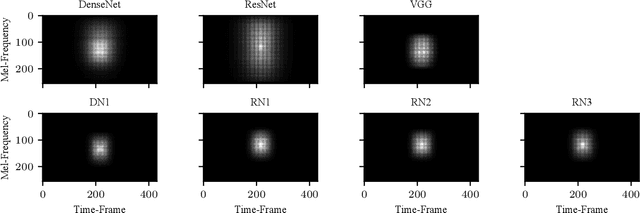
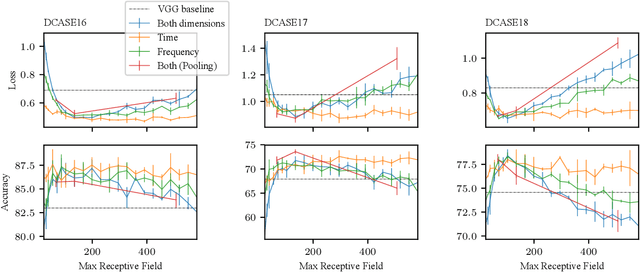
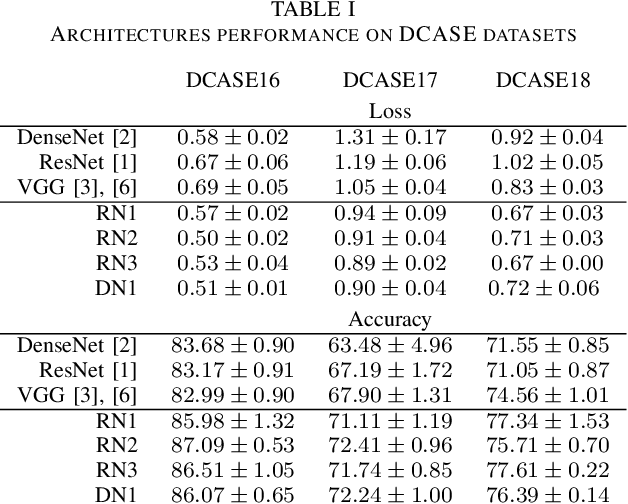

Convolutional Neural Networks (CNNs) have had great success in many machine vision as well as machine audition tasks. Many image recognition network architectures have consequently been adapted for audio processing tasks. However, despite some successes, the performance of many of these did not translate from the image to the audio domain. For example, very deep architectures such as ResNet and DenseNet, which significantly outperform VGG in image recognition, do not perform better in audio processing tasks such as Acoustic Scene Classification (ASC). In this paper, we investigate the reasons why such powerful architectures perform worse in ASC compared to simpler models (e.g., VGG). To this end, we analyse the receptive field (RF) of these CNNs and demonstrate the importance of the RF to the generalization capability of the models. Using our receptive field analysis, we adapt both ResNet and DenseNet, achieving state-of-the-art performance and eventually outperforming the VGG-based models. We introduce systematic ways of adapting the RF in CNNs, and present results on three data sets that show how changing the RF over the time and frequency dimensions affects a model's performance. Our experimental results show that very small or very large RFs can cause performance degradation, but deep models can be made to generalize well by carefully choosing an appropriate RF size within a certain range.
Imbalanced Data Learning by Minority Class Augmentation using Capsule Adversarial Networks
Apr 08, 2020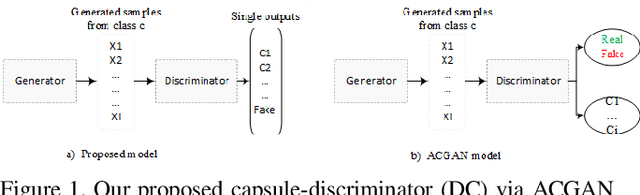

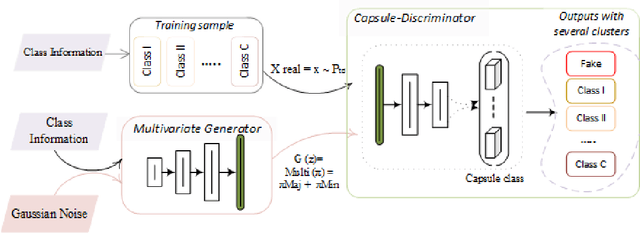
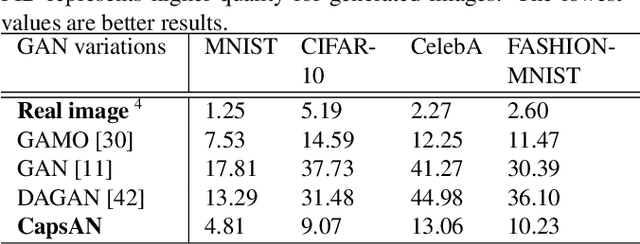
The fact that image datasets are often imbalanced poses an intense challenge for deep learning techniques. In this paper, we propose a method to restore the balance in imbalanced images, by coalescing two concurrent methods, generative adversarial networks (GANs) and capsule network. In our model, generative and discriminative networks play a novel competitive game, in which the generator generates samples towards specific classes from multivariate probabilities distribution. The discriminator of our model is designed in a way that while recognizing the real and fake samples, it is also requires to assign classes to the inputs. Since GAN approaches require fully observed data during training, when the training samples are imbalanced, the approaches might generate similar samples which leading to data overfitting. This problem is addressed by providing all the available information from both the class components jointly in the adversarial training. It improves learning from imbalanced data by incorporating the majority distribution structure in the generation of new minority samples. Furthermore, the generator is trained with feature matching loss function to improve the training convergence. In addition, prevents generation of outliers and does not affect majority class space. The evaluations show the effectiveness of our proposed methodology; in particular, the coalescing of capsule-GAN is effective at recognizing highly overlapping classes with much fewer parameters compared with the convolutional-GAN.
Unsupervised Domain Adaptation by Optical Flow Augmentation in Semantic Segmentation
Nov 20, 2019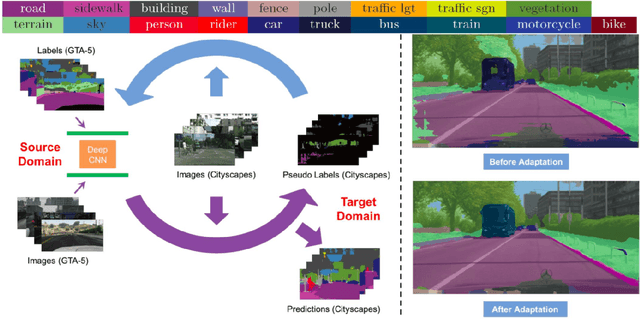
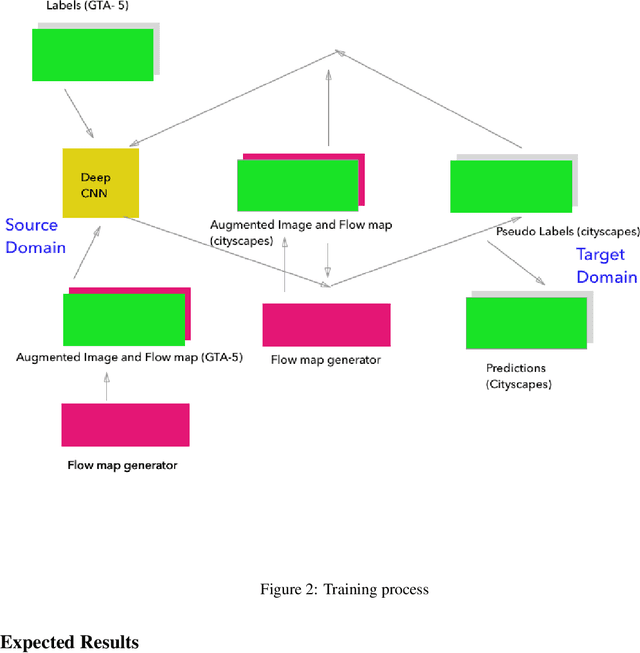
It is expensive to generate real-life image labels and there is a domain gap between real-life and simulated images, hence a model trained on the latter cannot adapt to the former. Solving this can totally eliminate the need for labeling real-life datasets completely. Class balanced self-training is one of the existing techniques that attempt to reduce the domain gap. Moreover, augmenting RGB with flow maps has improved performance in simple semantic segmentation and geometry is preserved across domains. Hence, by augmenting images with dense optical flow map, domain adaptation in semantic segmentation can be improved.
Push and Drag: An Active Obstacle Separation Method for Fruit Harvesting Robots
Apr 20, 2020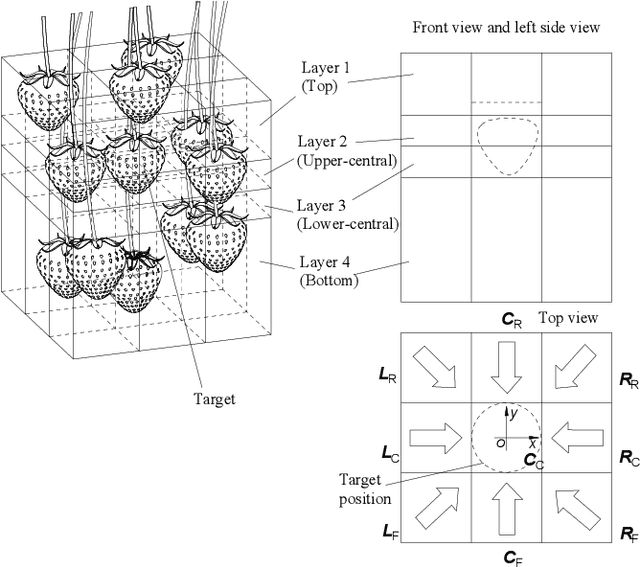
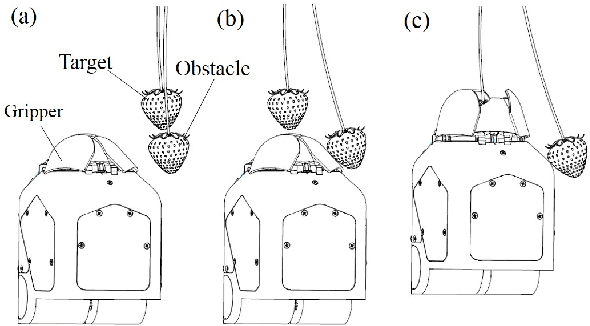
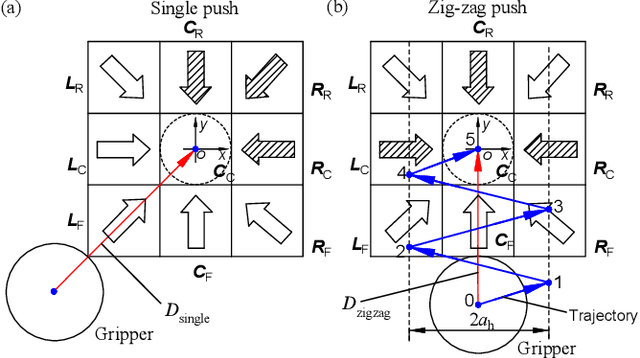
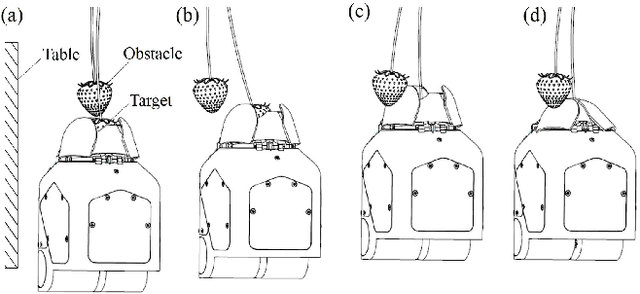
Selectively picking a target fruit surrounded by obstacles is one of the major challenges for fruit harvesting robots. Different from traditional obstacle avoidance methods, this paper presents an active obstacle separation strategy that combines push and drag motions. The separation motion and trajectory are generated based on the 3D visual perception of the obstacle information around the target. A linear push is used to clear the obstacles from the area below the target, while a zig-zag push that contains several linear motions is proposed to push aside more dense obstacles. The zig-zag push can generate multi-directional pushes and the side-to-side motion can break the static contact force between the target and obstacles, thus helping the gripper to receive a target in more complex situations. Moreover, we propose a novel drag operation to address the issue of mis-capturing obstacles located above the target, in which the gripper drags the target to a place with fewer obstacles and then pushes back to move the obstacles aside for further detachment. Furthermore, an image processing pipeline consisting of color thresholding, object detection using deep learning and point cloud operation, is developed to implement the proposed method on a harvesting robot. Field tests show that the proposed method can improve the picking performance substantially. This method helps to enable complex clusters of fruits to be harvested with a higher success rate than conventional methods.
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
Mar 11, 2020
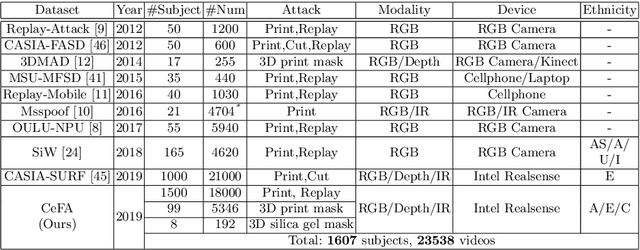
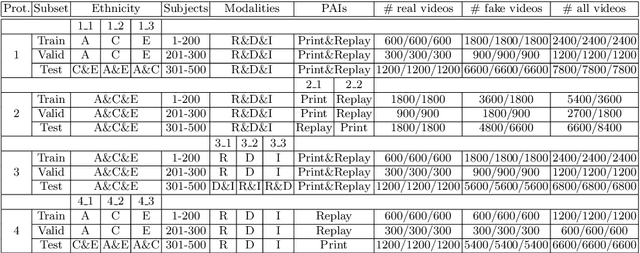
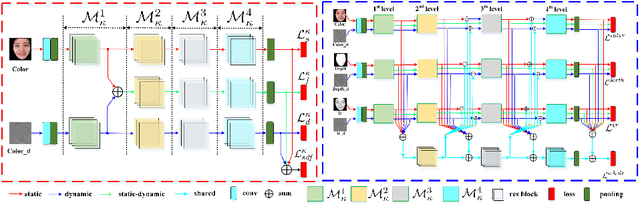
Ethnic bias has proven to negatively affect the performance of face recognition systems, and it remains an open research problem in face anti-spoofing. In order to study the ethnic bias for face anti-spoofing, we introduce the largest up to date CASIA-SURF Cross-ethnicity Face Anti-spoofing (CeFA) dataset (briefly named CeFA), covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, and 2D plus 3D attack types. Four protocols are introduced to measure the affect under varied evaluation conditions, such as cross-ethnicity, unknown spoofs or both of them. To the best of our knowledge, CeFA is the first dataset including explicit ethnic labels in current published/released datasets for face anti-spoofing. Then, we propose a novel multi-modal fusion method as a strong baseline to alleviate these bias, namely, the static-dynamic fusion mechanism applied in each modality (i.e., RGB, Depth and infrared image). Later, a partially shared fusion strategy is proposed to learn complementary information from multiple modalities. Extensive experiments demonstrate that the proposed method achieves state-of-the-art results on the CASIA-SURF, OULU-NPU, SiW and the CeFA dataset.
Temporal Spike Sequence Learning via Backpropagation for Deep Spiking Neural Networks
Feb 24, 2020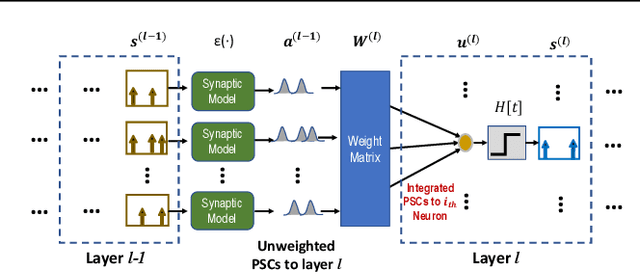

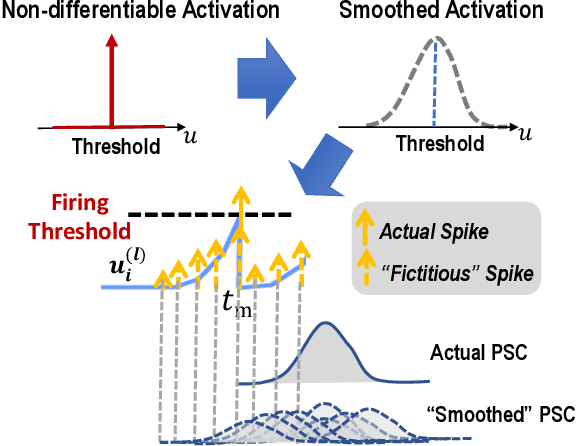

Spiking neural networks (SNNs) are well suited for spatio-temporal learning and implementations on energy-efficient event-driven neuromorphic processors. However, existing SNNs error backpropagation (BP) track methods lack proper handling of spiking discontinuities and suffer from low performance compared to BP methods for traditional artificial neural networks. In addition, a large number of time steps are typically required for SNNs to achieve decent performance, leading to high latency and rendering spike-based computation unscalable to deep architectures. We present a novel Temporal Spike Sequence Learning Backpropagation (TSSL-BP) method for training deep SNNs, which breaks down error backpropagation across two types of inter-neuron and intra-neuron dependencies. It considers the all-or-none characteristics of firing activities, capturing inter-neuron dependencies through presynaptic firing times, and internal evolution of each neuronal state through time capturing intra-neuron dependencies. For various image classification datasets, TSSL-BP efficiently trains deep SNNs within a short temporal time window of a few steps with improved accuracy and runtime efficiency including achieving more than 2% accuracy improvement over the previously reported SNN work on CIFAR10.
Image Acquisition in an Underwater Vision System with NIR and VIS Illumination
Feb 05, 2014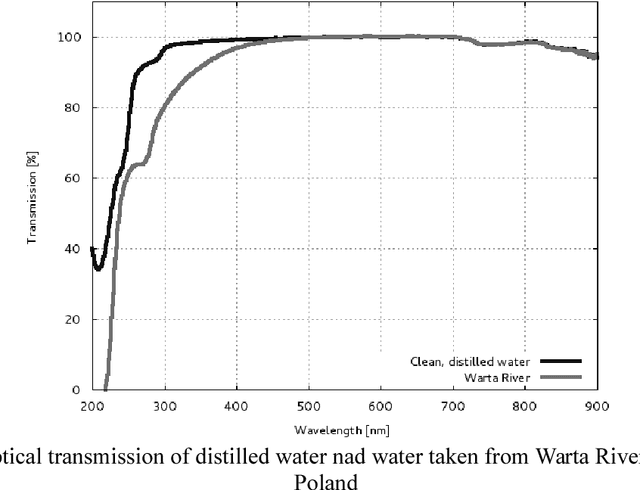
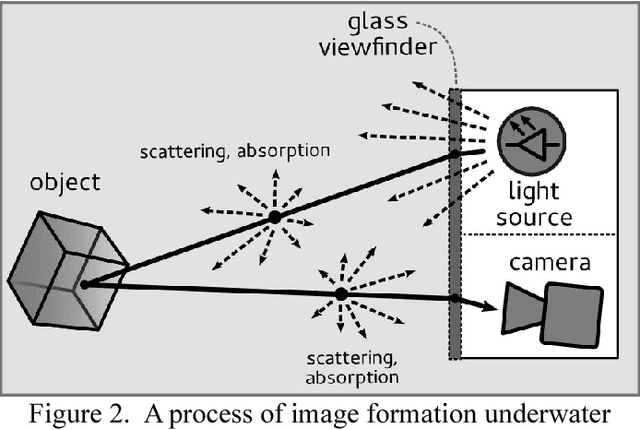
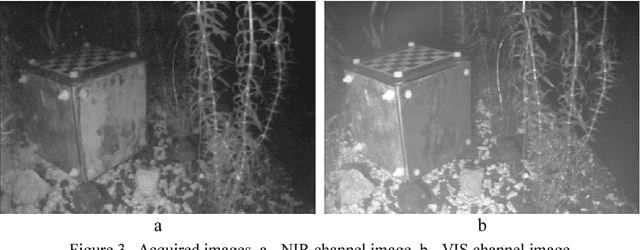
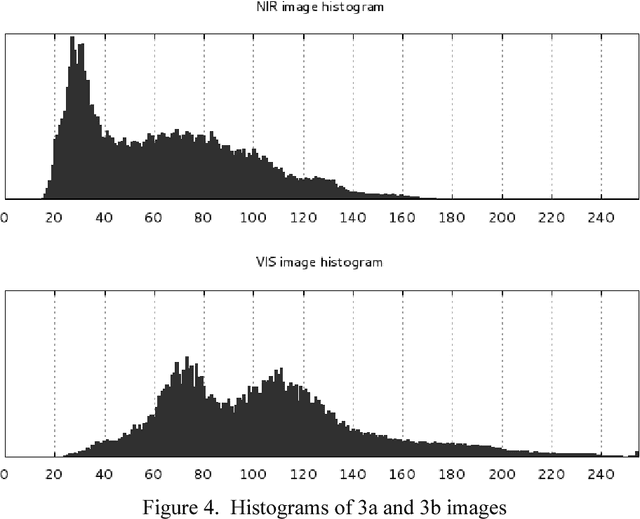
The paper describes the image acquisition system able to capture images in two separated bands of light, used to underwater autonomous navigation. The channels are: the visible light spectrum and near infrared spectrum. The characteristics of natural, underwater environment were also described together with the process of the underwater image creation. The results of an experiment with comparison of selected images acquired in these channels are discussed.