 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation
Aug 27, 2019
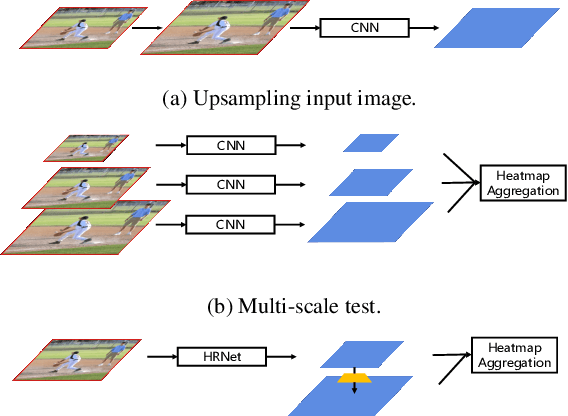
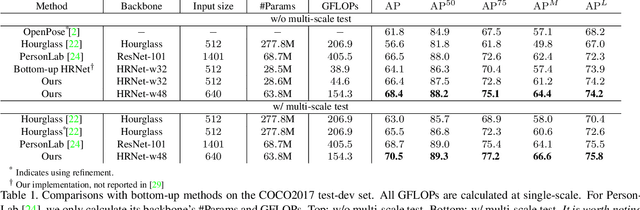
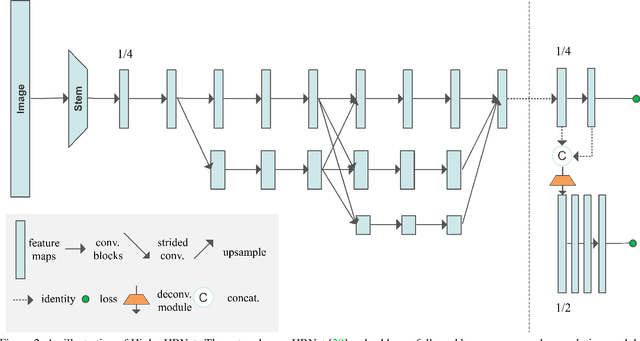
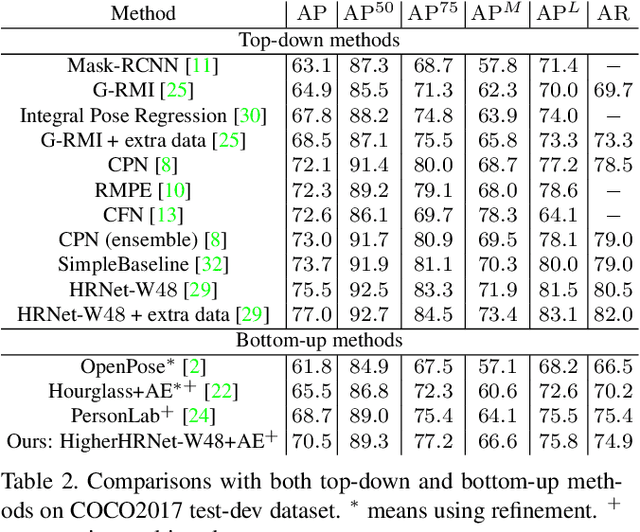
In this paper, we are interested in bottom-up multi-person human pose estimation. A typical bottom-up pipeline consists of two main steps: heatmap prediction and keypoint grouping. We mainly focus on the first step for improving heatmap prediction accuracy. We propose Higher-Resolution Network (HigherHRNet), which is a simple extension of the High-Resolution Network (HRNet). HigherHRNet generates higher-resolution feature maps by deconvolving the high-resolution feature maps outputted by HRNet, which are spatially more accurate for small and medium persons. Then, we build high-quality multi-level features and perform multi-scale pose prediction. The extra computation overhead is marginal and negligible in comparison to existing bottom-up methods that rely on multi-scale image pyramids or large input image size to generate accurate pose heatmaps. HigherHRNet surpasses all existing bottom-up methods on the COCO dataset without using multi-scale test. The code and models will be released.
Learnable Bernoulli Dropout for Bayesian Deep Learning
Feb 12, 2020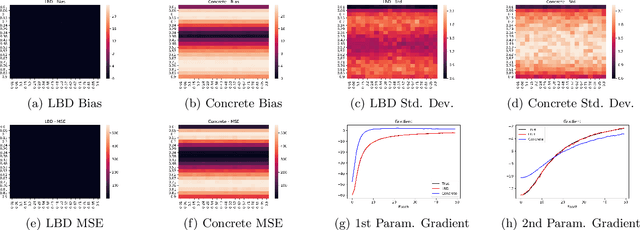
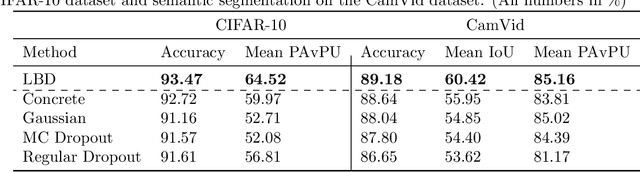
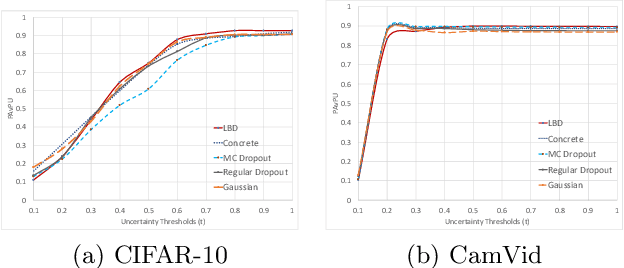
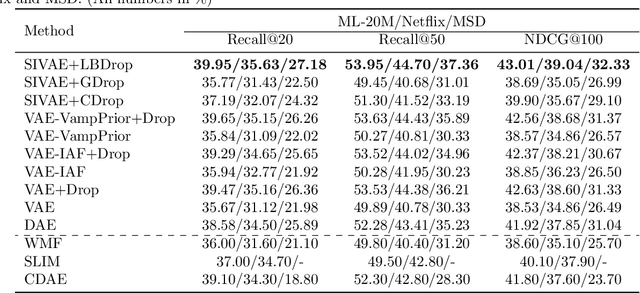
In this work, we propose learnable Bernoulli dropout (LBD), a new model-agnostic dropout scheme that considers the dropout rates as parameters jointly optimized with other model parameters. By probabilistic modeling of Bernoulli dropout, our method enables more robust prediction and uncertainty quantification in deep models. Especially, when combined with variational auto-encoders (VAEs), LBD enables flexible semi-implicit posterior representations, leading to new semi-implicit VAE~(SIVAE) models. We solve the optimization for training with respect to the dropout parameters using Augment-REINFORCE-Merge (ARM), an unbiased and low-variance gradient estimator. Our experiments on a range of tasks show the superior performance of our approach compared with other commonly used dropout schemes. Overall, LBD leads to improved accuracy and uncertainty estimates in image classification and semantic segmentation. Moreover, using SIVAE, we can achieve state-of-the-art performance on collaborative filtering for implicit feedback on several public datasets.
Per-pixel Classification Rebar Exposures in Bridge Eye-inspection
Apr 22, 2020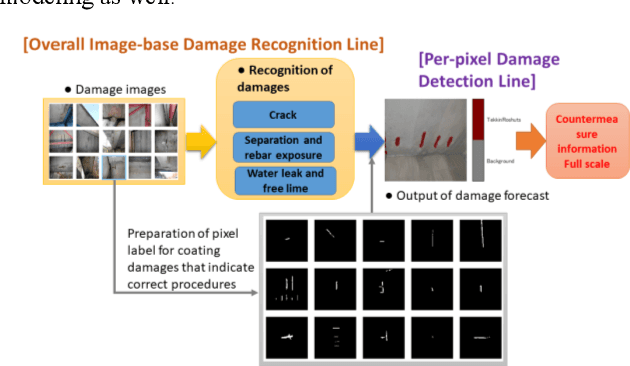
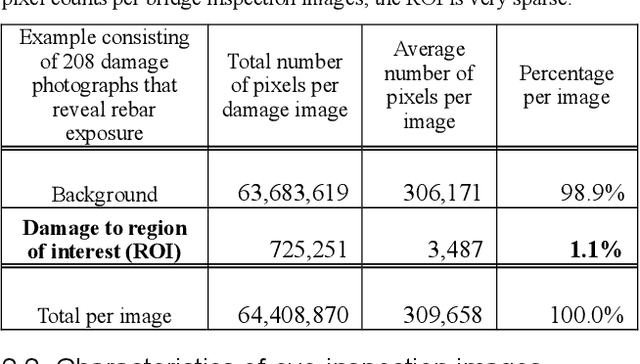
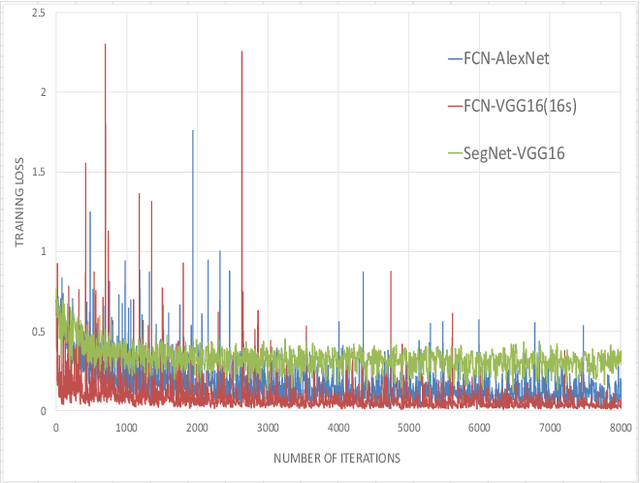
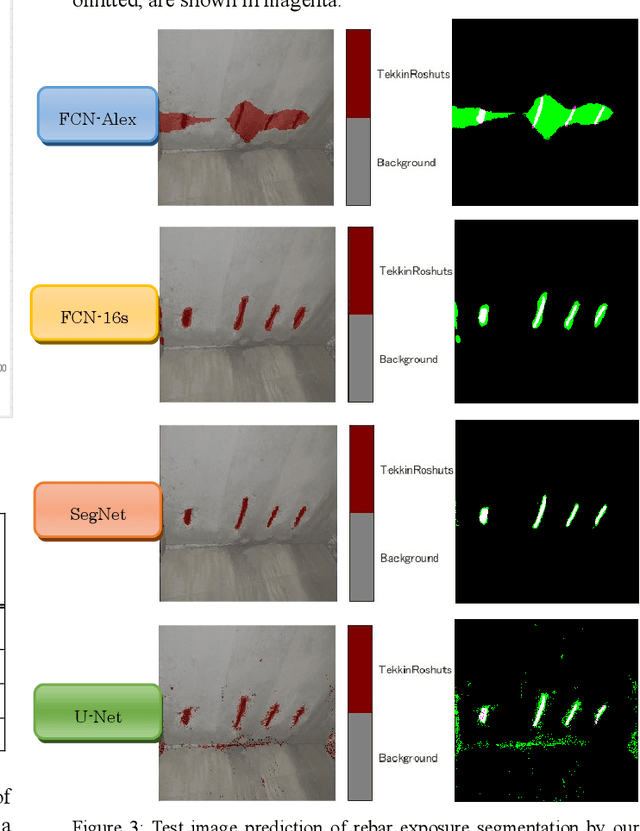
Efficient inspection and accurate diagnosis are required for civil infrastructures with 50 years since completion. Especially in municipalities, the shortage of technical staff and budget constraints on repair expenses have become a critical problem. If we can detect damaged photos automatically per-pixels from the record of the inspection record in addition to the 5-step judgment and countermeasure classification of eye-inspection vision, then it is possible that countermeasure information can be provided more flexibly, whether we need to repair and how large the expose of damage interest. A piece of damage photo is often sparse as long as it is not zoomed around damage, exactly the range where the detection target is photographed, is at most only 1%. Generally speaking, rebar exposure is frequently occurred, and there are many opportunities to judge repair measure. In this paper, we propose three damage detection methods of transfer learning which enables semantic segmentation in an image with low pixels using damaged photos of human eye-inspection. Also, we tried to create a deep convolutional network from scratch with the preprocessing that random crops with rotations are generated. In fact, we show the results applied this method using the 208 rebar exposed images on the 106 real-world bridges. Finally, future tasks of damage detection modeling are mentioned.
Ada-LISTA: Learned Solvers Adaptive to Varying Models
Jan 23, 2020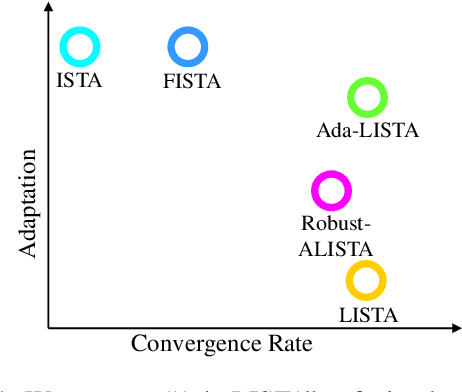


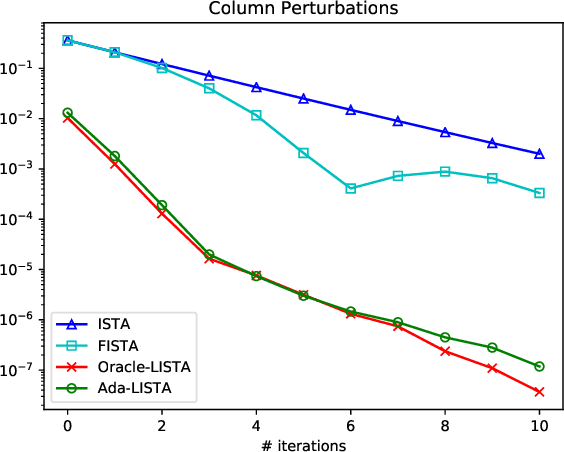
Neural networks that are based on unfolding of an iterative solver, such as LISTA (learned iterative soft threshold algorithm), are widely used due to their accelerated performance. Nevertheless, as opposed to non-learned solvers, these networks are trained on a certain dictionary, and therefore they are inapplicable for varying model scenarios. This work introduces an adaptive learned solver, termed Ada-LISTA, which receives pairs of signals and their corresponding dictionaries as inputs, and learns a universal architecture to serve them all. We prove that this scheme is guaranteed to solve sparse coding in linear rate for varying models, including dictionary perturbations and permutations. We also provide an extensive numerical study demonstrating its practical adaptation capabilities. Finally, we deploy Ada-LISTA to natural image inpainting, where the patch-masks vary spatially, thus requiring such an adaptation.
Occluded Prohibited Items Detection: An X-ray Security Inspection Benchmark and De-occlusion Attention Module
May 26, 2020
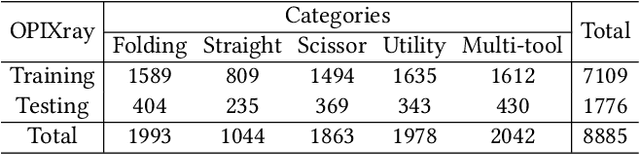
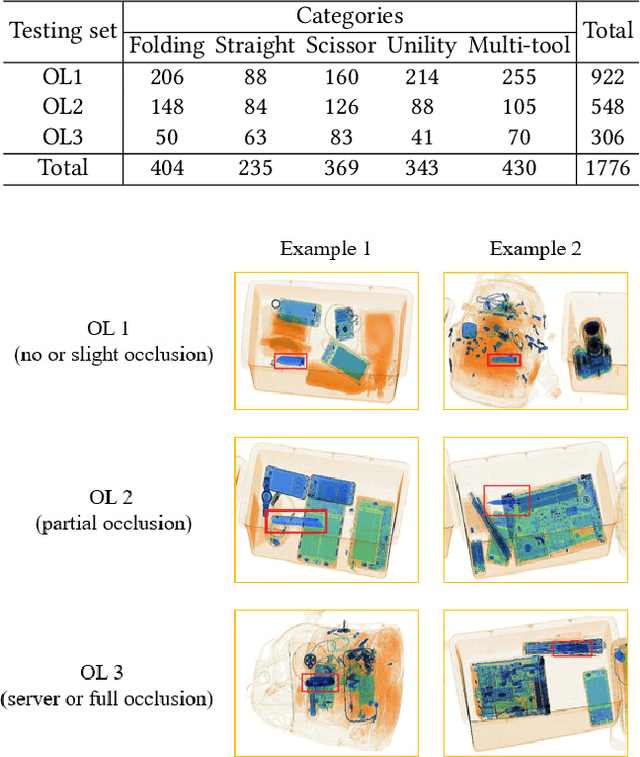
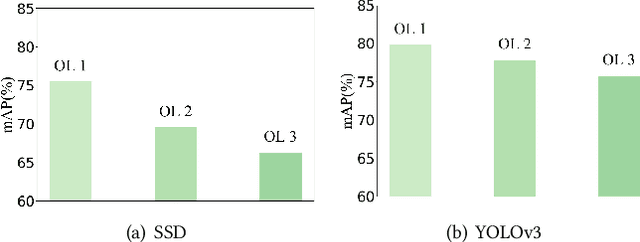
Security inspection often deals with a piece of baggage or suitcase where objects are heavily overlapped with each other, resulting in an unsatisfactory performance for prohibited items detection in X-ray images. In the literature, there have been rare studies and datasets touching this important topic. In this work, we contribute the first high-quality object detection dataset for security inspection, named Occluded Prohibited Items X-ray (OPIXray) image benchmark. OPIXray focused on the widely-occurred prohibited item "cutter", annotated manually by professional inspectors from the international airport. The test set is further divided into three occlusion levels to better understand the performance of detectors. Furthermore, to deal with the occlusion in X-ray images detection, we propose the De-occlusion Attention Module (DOAM), a plug-and-play module that can be easily inserted into and thus promote most popular detectors. Despite the heavy occlusion in X-ray imaging, shape appearance of objects can be preserved well, and meanwhile different materials visually appear with different colors and textures. Motivated by these observations, our DOAM simultaneously leverages the different appearance information of the prohibited item to generate the attention map, which helps refine feature maps for the general detectors. We comprehensively evaluate our module on the OPIXray dataset, and demonstrate that our module can consistently improve the performance of the state-of-the-art detection methods such as SSD, FCOS, etc, and significantly outperforms several widely-used attention mechanisms. In particular, the advantages of DOAM are more significant in the scenarios with higher levels of occlusion, which demonstrates its potential application in real-world inspections. The OPIXray benchmark and our model are released at https://github.com/OPIXray-author/OPIXray.
A Comparative Study of Computational Aesthetics
Nov 19, 2018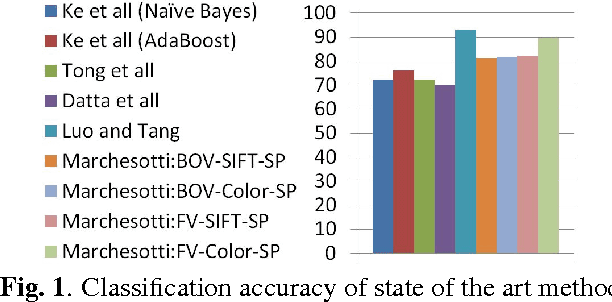
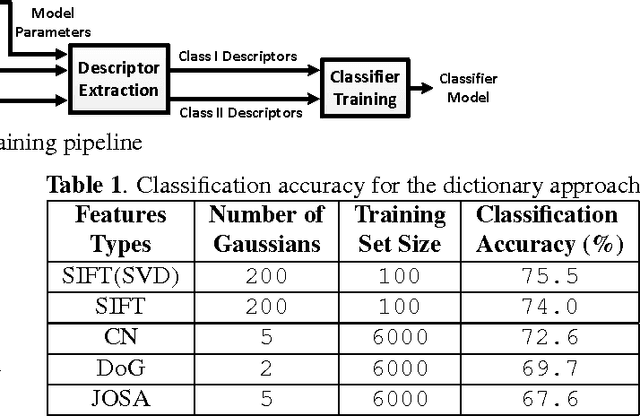
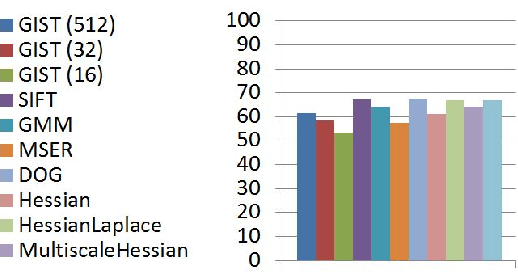
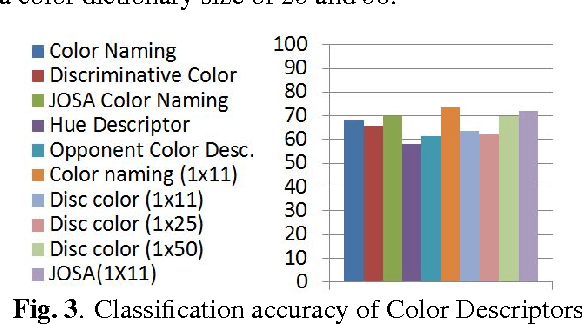
Objective metrics model image quality by quantifying image degradations or estimating perceived image quality. However, image quality metrics do not model what makes an image more appealing or beautiful. In order to quantify the aesthetics of an image, we need to take it one step further and model the perception of aesthetics. In this paper, we examine computational aesthetics models that use hand-crafted, generic and hybrid descriptors. We show that generic descriptors can perform as well as state of the art hand-crafted aesthetics models that use global features. However, neither generic nor hand-crafted features is sufficient to model aesthetics when we only use global features without considering spatial composition or distribution. We also follow a visual dictionary approach similar to state of the art methods and show that it performs poorly without the spatial pyramid step.
* 6 pages, 5 figures, 1 table
WW-Nets: Dual Neural Networks for Object Detection
May 15, 2020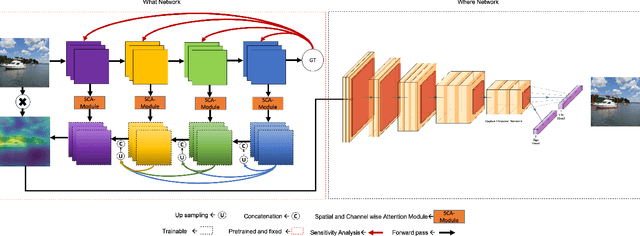

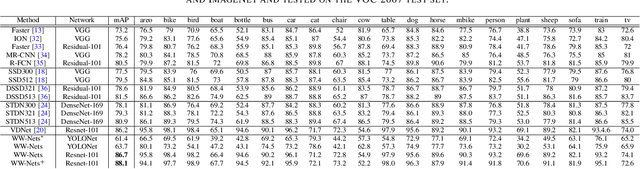
We propose a new deep convolutional neural network framework that uses object location knowledge implicit in network connection weights to guide selective attention in object detection tasks. Our approach is called What-Where Nets (WW-Nets), and it is inspired by the structure of human visual pathways. In the brain, vision incorporates two separate streams, one in the temporal lobe and the other in the parietal lobe, called the ventral stream and the dorsal stream, respectively. The ventral pathway from primary visual cortex is dominated by "what" information, while the dorsal pathway is dominated by "where" information. Inspired by this structure, we have proposed an object detection framework involving the integration of a "What Network" and a "Where Network". The aim of the What Network is to provide selective attention to the relevant parts of the input image. The Where Network uses this information to locate and classify objects of interest. In this paper, we compare this approach to state-of-the-art algorithms on the PASCAL VOC 2007 and 2012 and COCO object detection challenge datasets. Also, we compare out approach to human "ground-truth" attention. We report the results of an eye-tracking experiment on human subjects using images from PASCAL VOC 2007, and we demonstrate interesting relationships between human overt attention and information processing in our WW-Nets. Finally, we provide evidence that our proposed method performs favorably in comparison to other object detection approaches, often by a large margin. The code and the eye-tracking ground-truth dataset can be found at: https://github.com/mkebrahimpour.
Pix2Vex: Image-to-Geometry Reconstruction using a Smooth Differentiable Renderer
Mar 26, 2019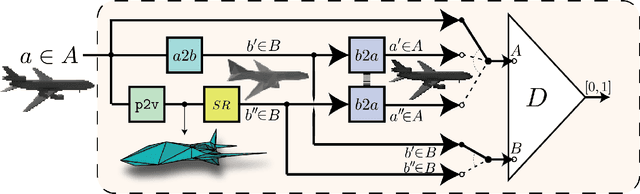
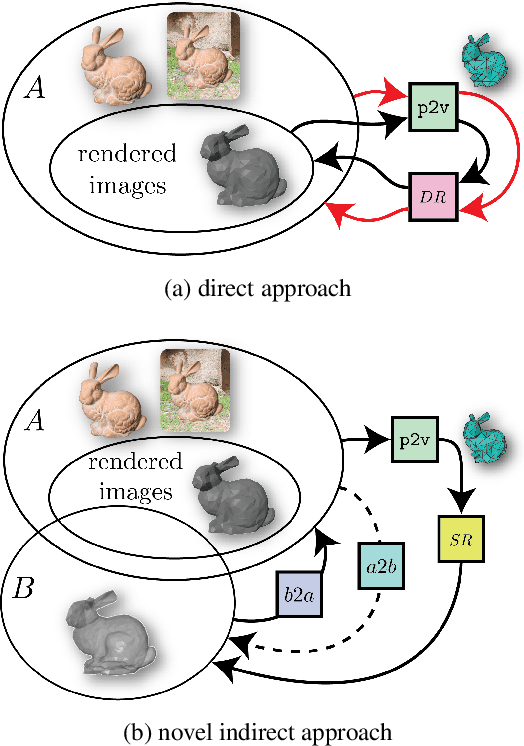
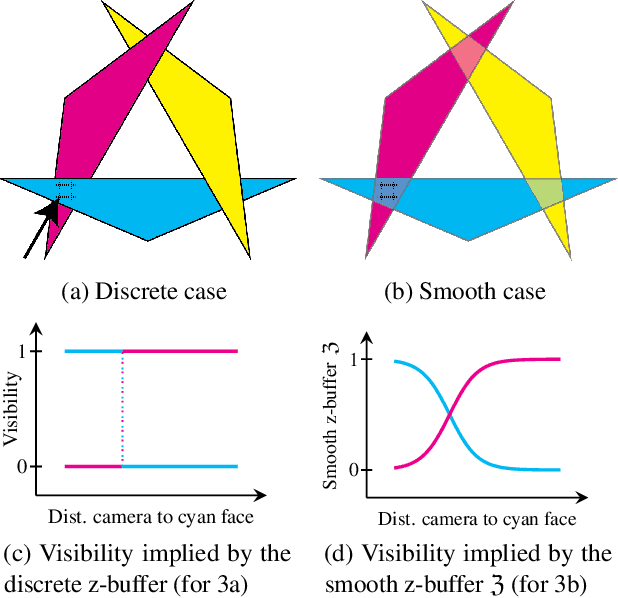
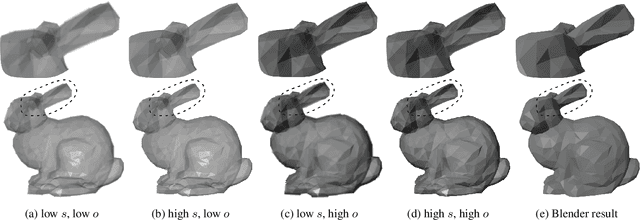
We present a novel approach to 3D object reconstruction from its 2D projections. Our unique, GAN-inspired system employs a novel $C^\infty$ smooth differentiable renderer. Unlike the state-of-the-art, our renderer does not display any discontinuities at occlusions and dis-occlusions, facilitating training without 3D supervision and only minimal 2D supervision. Through domain adaptation and a novel training scheme, our network, the Reconstructive Adversarial Network (RAN), is able to train on different types of images. In contrast, previous work can only train on images of a similar appearance to those rendered by a differentiable renderer. We validate our reconstruction method through three shape classes from ShapeNet, and demonstrate that our method is robust to perturbations in view directions, different lighting conditions, and levels of texture details.
Remote measurement of sea ice dynamics with regularized optimal transport
May 02, 2019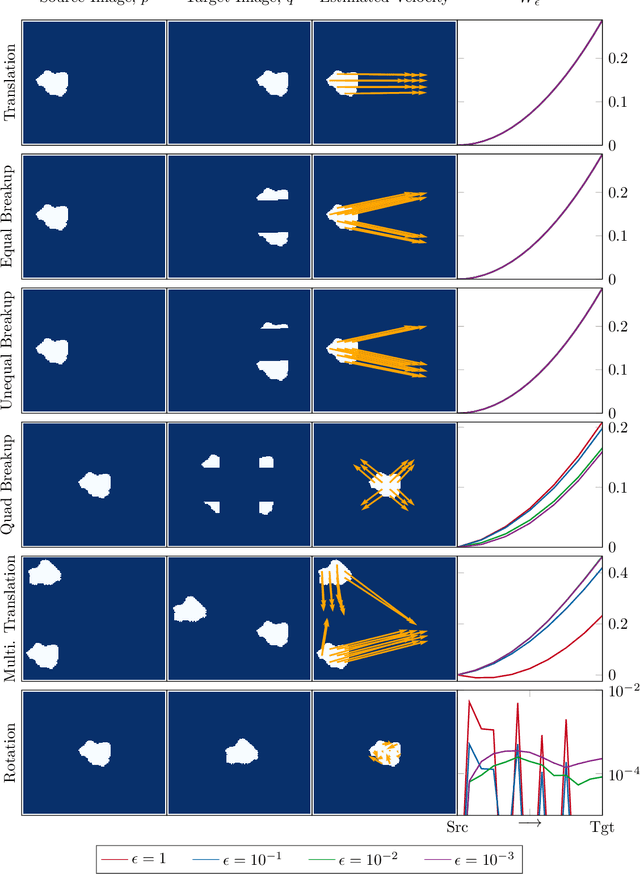
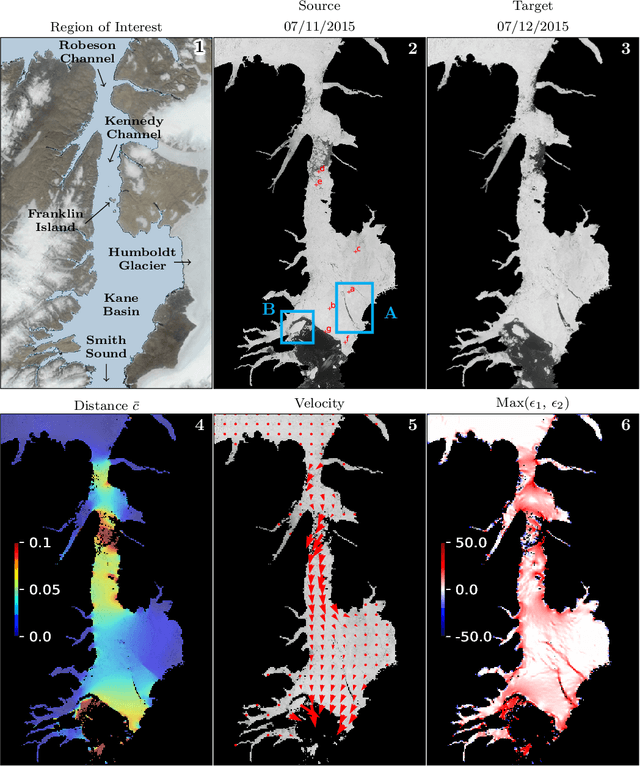

As Arctic conditions rapidly change, human activity in the Arctic will continue to increase and so will the need for high-resolution observations of sea ice. While satellite imagery can provide high spatial resolution, it is temporally sparse and significant ice deformation can occur between observations. This makes it difficult to apply feature tracking or image correlation techniques that require persistent features to exist between images. With this in mind, we propose a technique based on optimal transport, which is commonly used to measure differences between probability distributions. When little ice enters or leaves the image scene, we show that regularized optimal transport can be used to quantitatively estimate ice deformation. We discuss the motivation for our approach and describe efficient computational implementations. Results are provided on a combination of synthetic and MODIS imagery to demonstrate the ability of our approach to estimate dynamics properties at the original image resolution.
Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances
Oct 04, 2019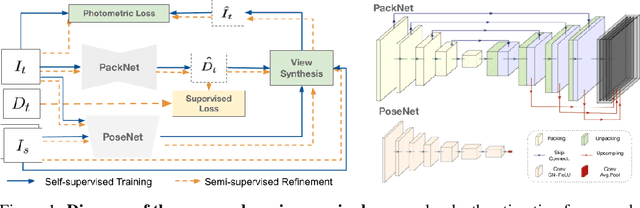
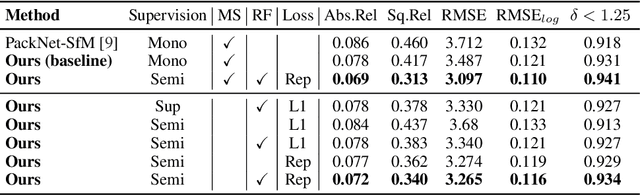
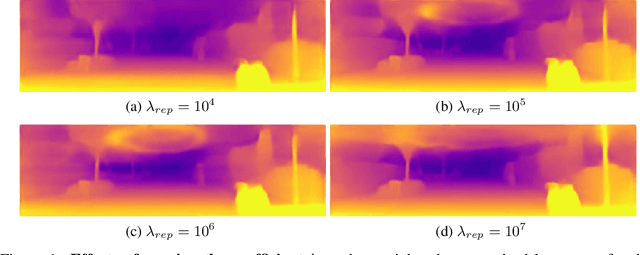
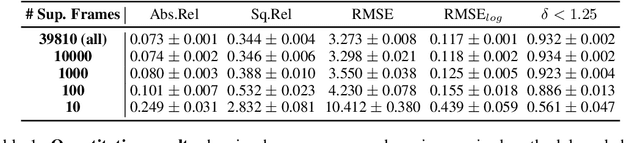
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art.