 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TMAV: Temporal Motionless Analysis of Video using CNN in MPSoC
Feb 18, 2019

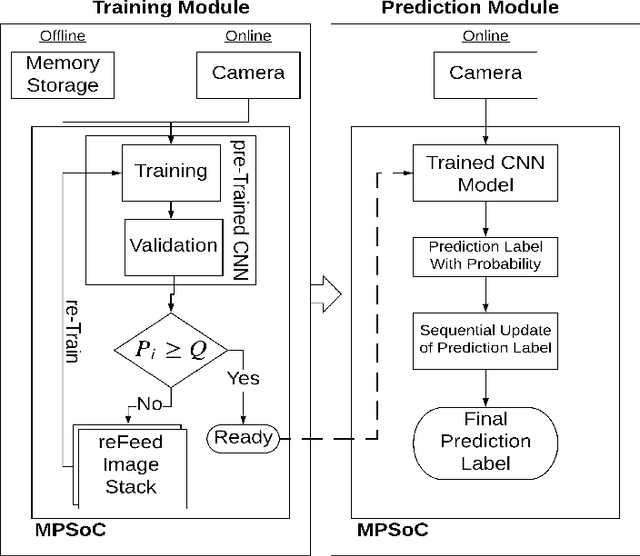
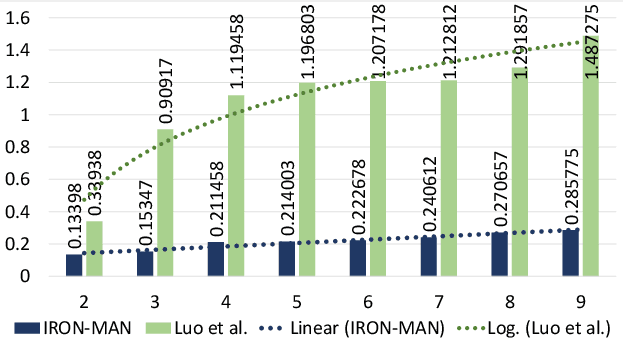
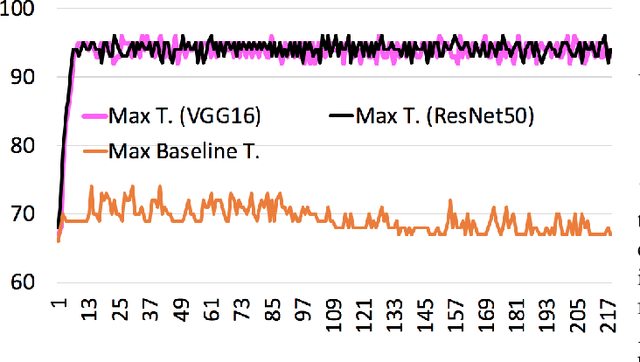
Analyzing video for traffic categorization is an important pillar of Intelligent Transport Systems. However, it is difficult to analyze and predict traffic based on image frames because the representation of each frame may vary significantly within a short time period. This also would inaccurately represent the traffic over a longer period of time such as the case of video. We propose a novel bio-inspired methodology that integrates analysis of the previous image frames of the video to represent the analysis of the current image frame, the same way a human being analyzes the current situation based on past experience. In our proposed methodology, called IRON-MAN (Integrated Rational prediction and Motionless ANalysis), we utilize Bayesian update on top of the individual image frame analysis in the videos and this has resulted in highly accurate prediction of Temporal Motionless Analysis of the Videos (TMAV) for most of the chosen test cases. The proposed approach could be used for TMAV using Convolutional Neural Network (CNN) for applications where the number of objects in an image is the deciding factor for prediction and results also show that our proposed approach outperforms the state-of-the-art for the chosen test case. We also introduce a new metric named, Energy Consumption per Training Image (ECTI). Since, different CNN based models have different training capability and computing resource utilization, some of the models are more suitable for embedded device implementation than the others, and ECTI metric is useful to assess the suitability of using a CNN model in multi-processor systems-on-chips (MPSoCs) with a focus on energy consumption and reliability in terms of lifespan of the embedded device using these MPSoCs.
Push for Quantization: Deep Fisher Hashing
Aug 31, 2019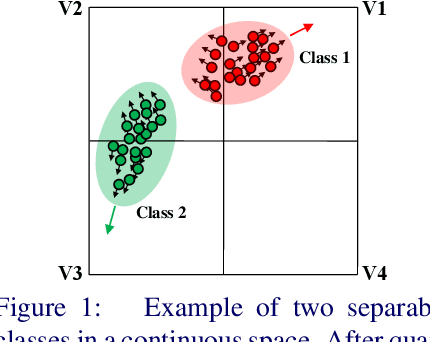
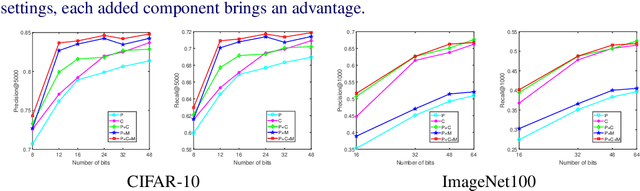
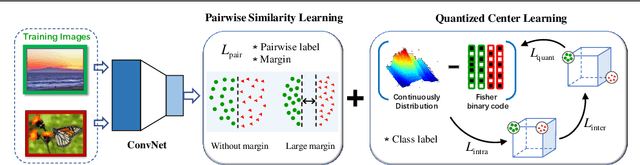
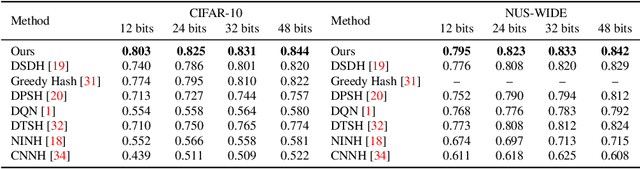
Current massive datasets demand light-weight access for analysis. Discrete hashing methods are thus beneficial because they map high-dimensional data to compact binary codes that are efficient to store and process, while preserving semantic similarity. To optimize powerful deep learning methods for image hashing, gradient-based methods are required. Binary codes, however, are discrete and thus have no continuous derivatives. Relaxing the problem by solving it in a continuous space and then quantizing the solution is not guaranteed to yield separable binary codes. The quantization needs to be included in the optimization. In this paper we push for quantization: We optimize maximum class separability in the binary space. We introduce a margin on distances between dissimilar image pairs as measured in the binary space. In addition to pair-wise distances, we draw inspiration from Fisher's Linear Discriminant Analysis (Fisher LDA) to maximize the binary distances between classes and at the same time minimize the binary distance of images within the same class. Experiments on CIFAR-10, NUS-WIDE and ImageNet100 demonstrate compact codes comparing favorably to the current state of the art.
Face representation by deep learning: a linear encoding in a parameter space?
Oct 22, 2019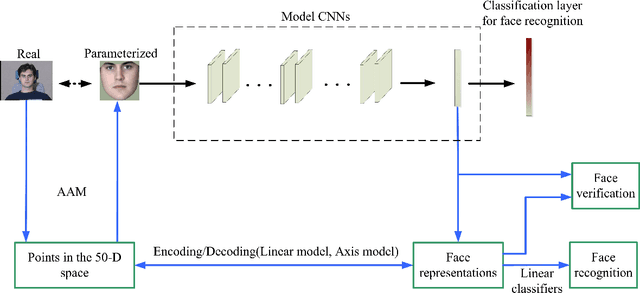
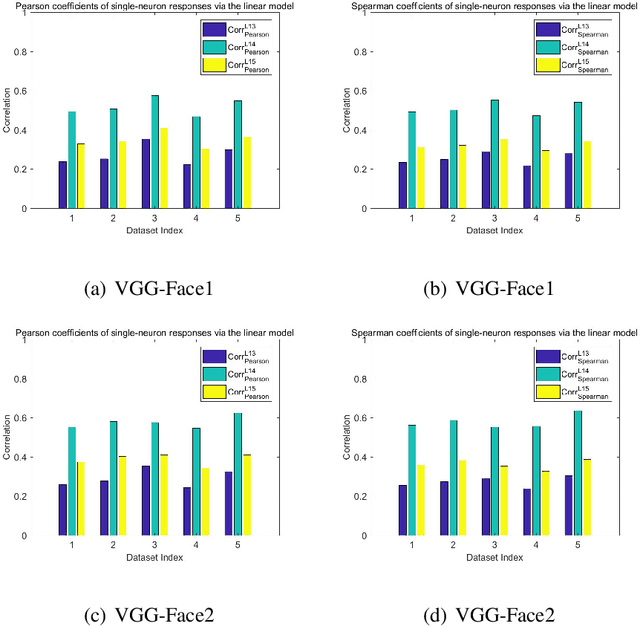
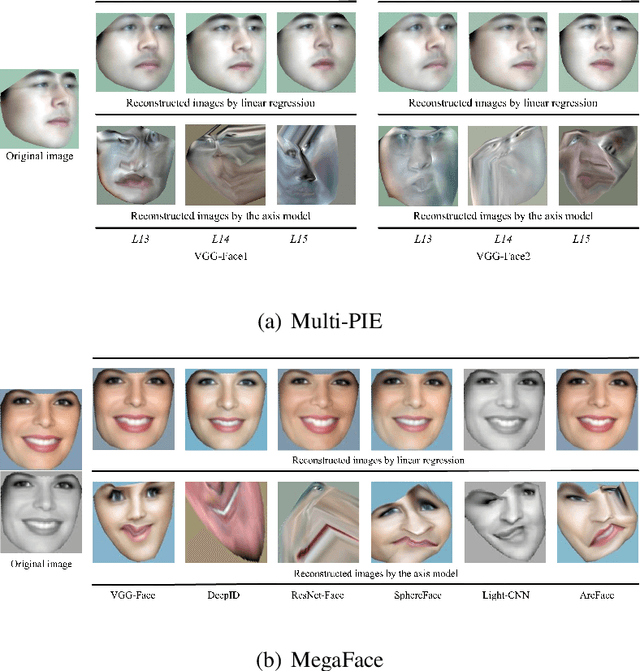
Recently, Convolutional Neural Networks (CNNs) have achieved tremendous performances on face recognition, and one popular perspective regarding CNNs' success is that CNNs could learn discriminative face representations from face images with complex image feature encoding. However, it is still unclear what is the intrinsic mechanism of face representation in CNNs. In this work, we investigate this problem by formulating face images as points in a shape-appearance parameter space, and our results demonstrate that: (i) The encoding and decoding of the neuron responses (representations) to face images in CNNs could be achieved under a linear model in the parameter space, in agreement with the recent discovery in primate IT face neurons, but different from the aforementioned perspective on CNNs' face representation with complex image feature encoding; (ii) The linear model for face encoding and decoding in the parameter space could achieve close or even better performances on face recognition and verification than state-of-the-art CNNs, which might provide new lights on the design strategies for face recognition systems; (iii) The neuron responses to face images in CNNs could not be adequately modelled by the axis model, a model recently proposed on face modelling in primate IT cortex. All these results might shed some lights on the often complained blackbox nature behind CNNs' tremendous performances on face recognition.
Robustness Of Saak Transform Against Adversarial Attacks
Feb 07, 2019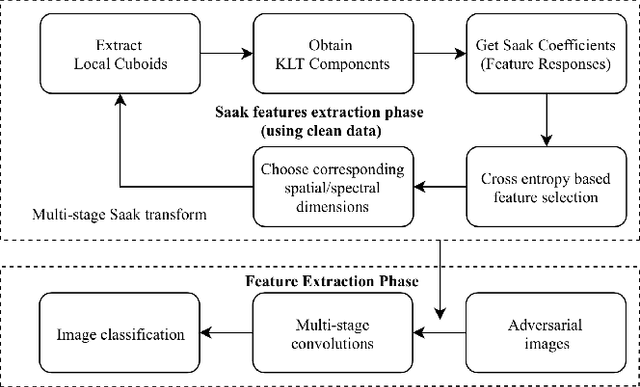
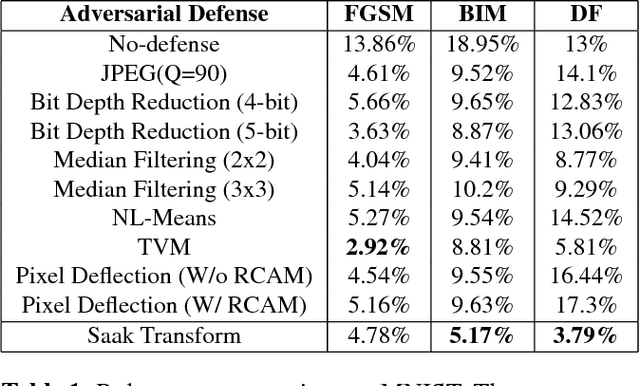
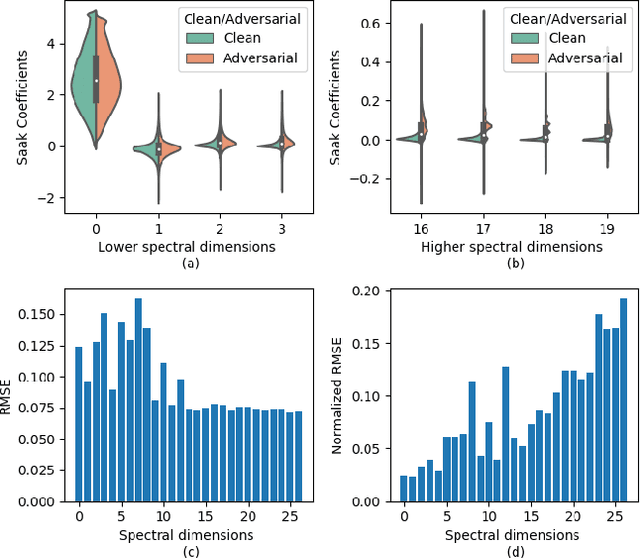
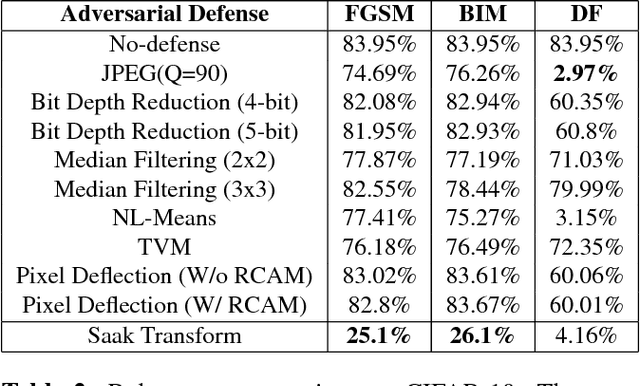
Image classification is vulnerable to adversarial attacks. This work investigates the robustness of Saak transform against adversarial attacks towards high performance image classification. We develop a complete image classification system based on multi-stage Saak transform. In the Saak transform domain, clean and adversarial images demonstrate different distributions at different spectral dimensions. Selection of the spectral dimensions at every stage can be viewed as an automatic denoising process. Motivated by this observation, we carefully design strategies of feature extraction, representation and classification that increase adversarial robustness. The performances with well-known datasets and attacks are demonstrated by extensive experimental evaluations.
Using panoramic videos for multi-person localization and tracking in a 3D panoramic coordinate
Dec 05, 2019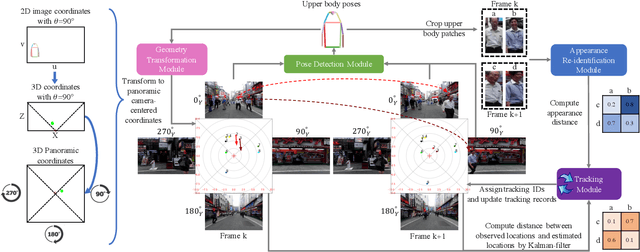
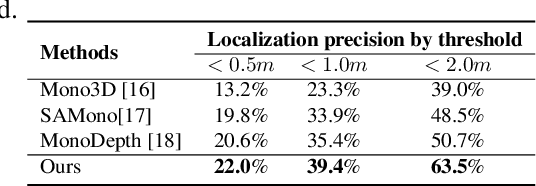
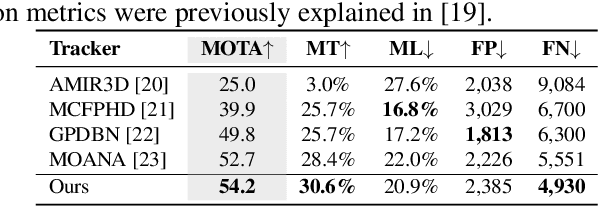
This work proposes a new human-related video processing task named 3D panoramic multi-person localization and tracking. With a benchmark dataset and a simple yet effective solution, it establishes a new paradigm for multi-person tracking systems and related applications. Unlike existing methods that can only work on a 2D coordinate or a narrow-angle-view 3D coordinate, our proposal can maximally explore the 3D trajectory information of tracking targets. This is approached by applying camera geometry to transform human locations from 2D panoramic image coordinates to a 3D panoramic camera coordinate, and then by applying a tracking algorithm that associates human appearance and 3D trajectory together.
Robust Unsupervised Flexible Auto-weighted Local-Coordinate Concept Factorization for Image Clustering
May 25, 2019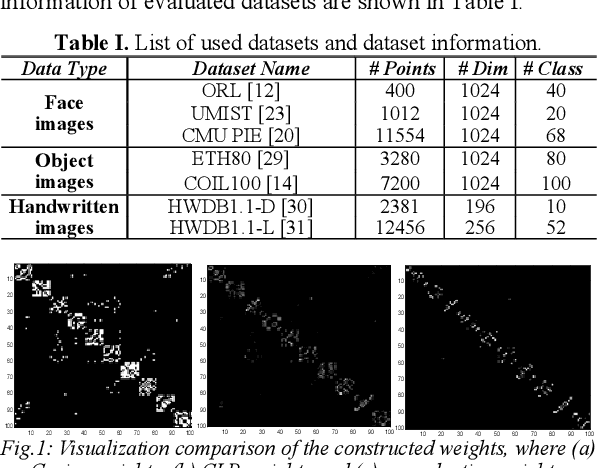
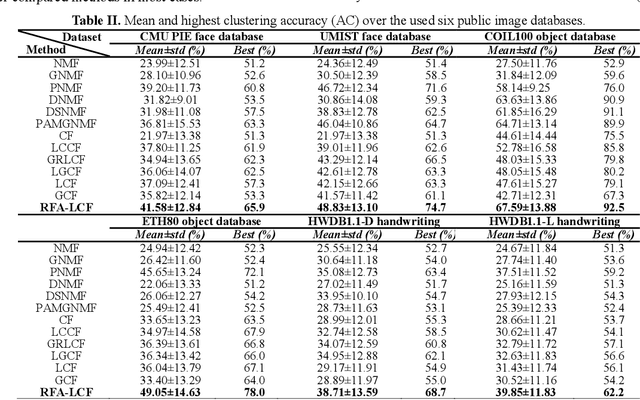
We investigate the high-dimensional data clustering problem by proposing a novel and unsupervised representation learning model called Robust Flexible Auto-weighted Local-coordinate Concept Factorization (RFA-LCF). RFA-LCF integrates the robust flexible CF, robust sparse local-coordinate coding and the adaptive reconstruction weighting learning into a unified model. The adaptive weighting is driven by including the joint manifold preserving constraints on the recovered clean data, basis concepts and new representation. Specifically, our RFA-LCF uses a L2,1-norm based flexible residue to encode the mismatch between clean data and its reconstruction, and also applies the robust adaptive sparse local-coordinate coding to represent the data using a few nearby basis concepts, which can make the factorization more accurate and robust to noise. The robust flexible factorization is also performed in the recovered clean data space for enhancing representations. RFA-LCF also considers preserving the local manifold structures of clean data space, basis concept space and the new coordinate space jointly in an adaptive manner way. Extensive comparisons show that RFA-LCF can deliver enhanced clustering results.
Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
Dec 05, 2019

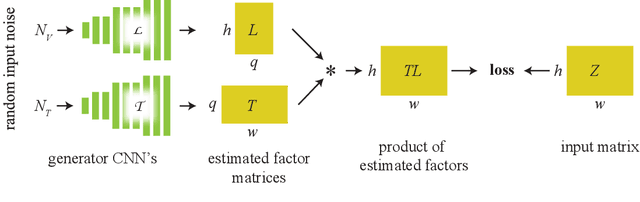

We recover a video of the motion taking place in a hidden scene by observing changes in indirect illumination in a nearby uncalibrated visible region. We solve this problem by factoring the observed video into a matrix product between the unknown hidden scene video and an unknown light transport matrix. This task is extremely ill-posed, as any non-negative factorization will satisfy the data. Inspired by recent work on the Deep Image Prior, we parameterize the factor matrices using randomly initialized convolutional neural networks trained in a one-off manner, and show that this results in decompositions that reflect the true motion in the hidden scene.
* 14 pages, 5 figures, Advances in Neural Information Processing Systems 2019
EMPIR: Ensembles of Mixed Precision Deep Networks for Increased Robustness against Adversarial Attacks
Apr 21, 2020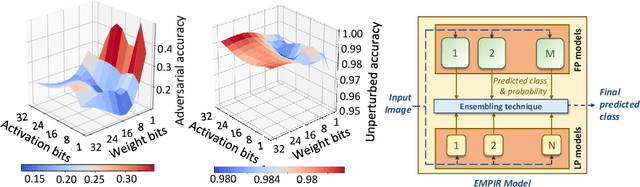

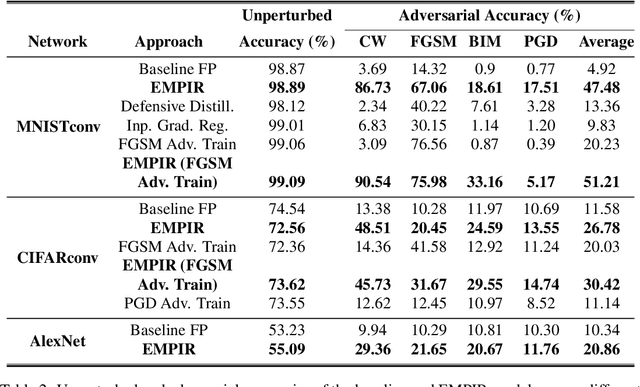
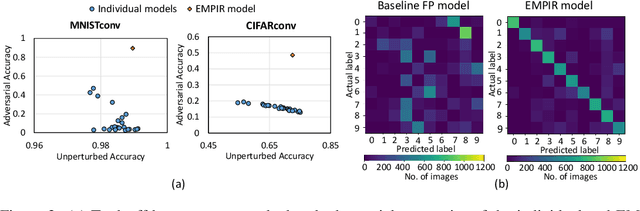
Ensuring robustness of Deep Neural Networks (DNNs) is crucial to their adoption in safety-critical applications such as self-driving cars, drones, and healthcare. Notably, DNNs are vulnerable to adversarial attacks in which small input perturbations can produce catastrophic misclassifications. In this work, we propose EMPIR, ensembles of quantized DNN models with different numerical precisions, as a new approach to increase robustness against adversarial attacks. EMPIR is based on the observation that quantized neural networks often demonstrate much higher robustness to adversarial attacks than full precision networks, but at the cost of a substantial loss in accuracy on the original (unperturbed) inputs. EMPIR overcomes this limitation to achieve the 'best of both worlds', i.e., the higher unperturbed accuracies of the full precision models combined with the higher robustness of the low precision models, by composing them in an ensemble. Further, as low precision DNN models have significantly lower computational and storage requirements than full precision models, EMPIR models only incur modest compute and memory overheads compared to a single full-precision model (<25% in our evaluations). We evaluate EMPIR across a suite of DNNs for 3 different image recognition tasks (MNIST, CIFAR-10 and ImageNet) and under 4 different adversarial attacks. Our results indicate that EMPIR boosts the average adversarial accuracies by 42.6%, 15.2% and 10.5% for the DNN models trained on the MNIST, CIFAR-10 and ImageNet datasets respectively, when compared to single full-precision models, without sacrificing accuracy on the unperturbed inputs.
Spatio-spectral deep learning methods for in-vivo hyperspectral laryngeal cancer detection
Apr 21, 2020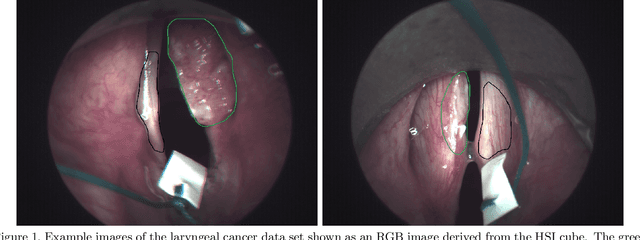

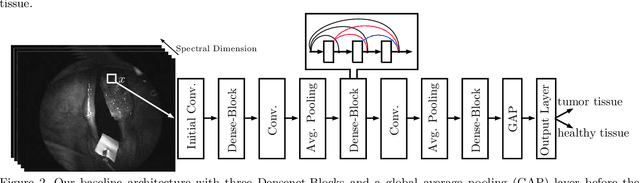
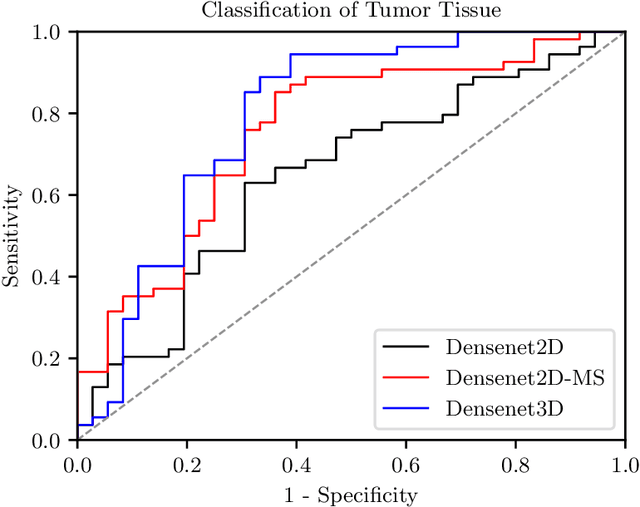
Early detection of head and neck tumors is crucial for patient survival. Often, diagnoses are made based on endoscopic examination of the larynx followed by biopsy and histological analysis, leading to a high inter-observer variability due to subjective assessment. In this regard, early non-invasive diagnostics independent of the clinician would be a valuable tool. A recent study has shown that hyperspectral imaging (HSI) can be used for non-invasive detection of head and neck tumors, as precancerous or cancerous lesions show specific spectral signatures that distinguish them from healthy tissue. However, HSI data processing is challenging due to high spectral variations, various image interferences, and the high dimensionality of the data. Therefore, performance of automatic HSI analysis has been limited and so far, mostly ex-vivo studies have been presented with deep learning. In this work, we analyze deep learning techniques for in-vivo hyperspectral laryngeal cancer detection. For this purpose we design and evaluate convolutional neural networks (CNNs) with 2D spatial or 3D spatio-spectral convolutions combined with a state-of-the-art Densenet architecture. For evaluation, we use an in-vivo data set with HSI of the oral cavity or oropharynx. Overall, we present multiple deep learning techniques for in-vivo laryngeal cancer detection based on HSI and we show that jointly learning from the spatial and spectral domain improves classification accuracy notably. Our 3D spatio-spectral Densenet achieves an average accuracy of 81%.
Disaster Feature Classification on Aerial Photography to Explain Typhoon Damaged Region using Grad-CAM
Apr 21, 2020
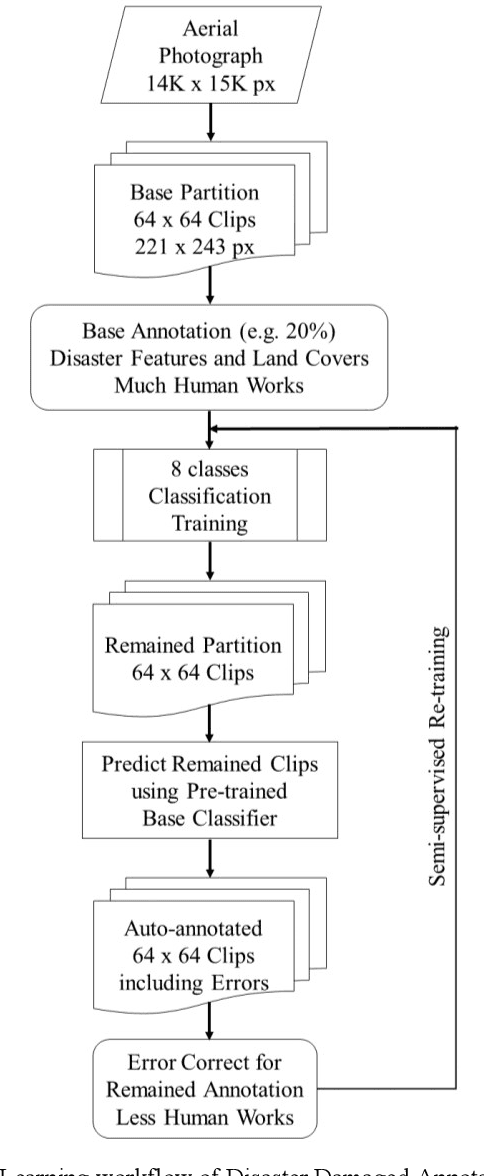
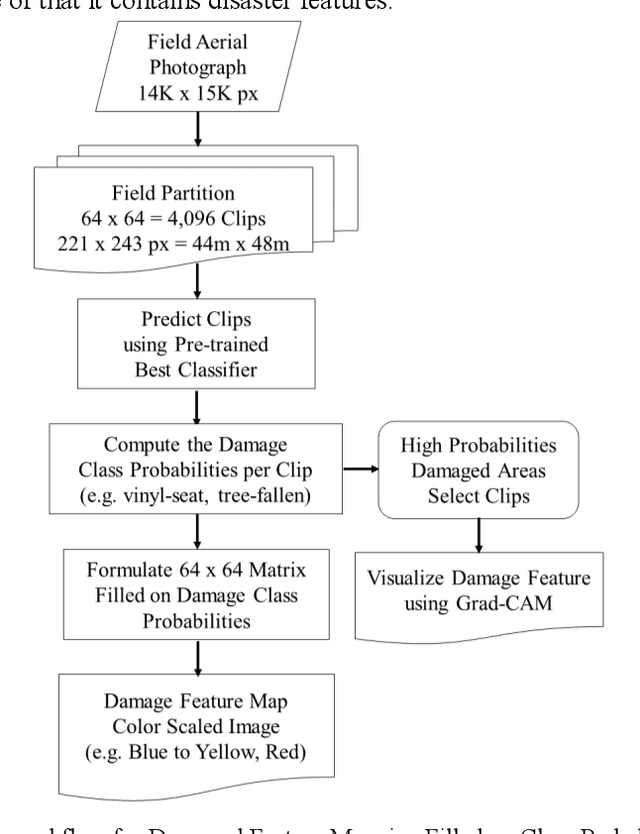
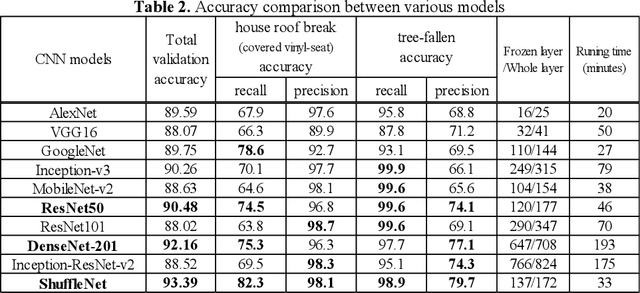
Recent years, typhoon damages has become social problem owing to climate change. Especially, 9 September 2019, Typhoon Faxai passed on the south Chiba prefecture in Japan, whose damages included with electric and water provision stop and house roof break because of strong wind recorded on the maximum 45 meter per second. A large amount of tree fell down, and the neighbor electric poles also fell down at the same time. These disaster features have caused that it took eighteen days for recovery longer than past ones. Initial responses are important for faster recovery. As long as we can, aerial survey for global screening of devastated region would be required for decision support to respond where to recover ahead. This paper proposes a practical method to visualize the damaged areas focused on the typhoon disaster features using aerial photography. This method can classify eight classes which contains land covers without damages and areas with disaster, where an aerial photograph is partitioned into 4,096 grids that is 64 by 64, with each unit image of 48 meter square. Using target feature class probabilities, we can visualize disaster features map to scale the color range from blue to red or yellow. Furthermore, we can realize disaster feature mapping on each unit grid images to compute the convolutional activation map using Grad-CAM based on deep neural network layers for classification. This paper demonstrates case studies applied to aerial photographs recorded at the south Chiba prefecture in Japan after typhoon disaster.