 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diversified Arbitrary Style Transfer via Deep Feature Perturbation
Sep 18, 2019
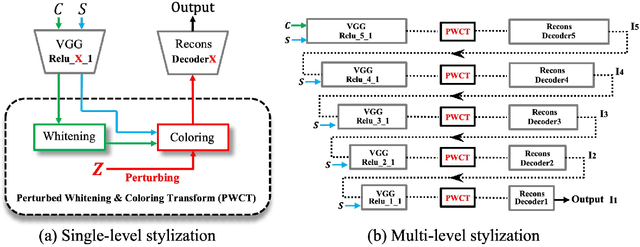

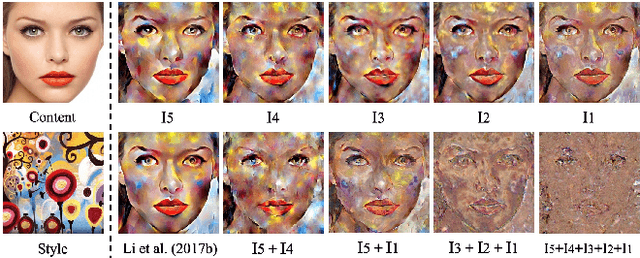
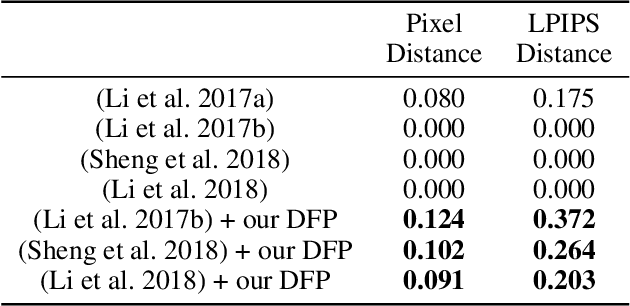
Image style transfer is an underdetermined problem, where a large number of solutions can explain the same constraint (i.e., the content and style). Most current methods always produce visually identical outputs, which lack of diversity. Recently, some methods have introduced an alternative diversity loss to train the feed-forward networks for diverse outputs, but they still suffer from many issues. In this paper, we propose a simple yet effective method for diversified style transfer. Our method can produce diverse outputs for arbitrary styles by incorporating the whitening and coloring transforms (WCT) with a novel deep feature perturbation (DFP) operation, which uses an orthogonal random noise matrix to perturb the deep image features while keeping the original style information unchanged. In addition, our method is learning-free and could be easily integrated into many existing WCT-based methods and empower them to generate diverse results. Experimental results demonstrate that our method can greatly increase the diversity while maintaining the quality of stylization. And several new user studies show that users could obtain more satisfactory results through the diversified approaches based on our method.
Inferring Semantic Information with 3D Neural Scene Representations
Mar 28, 2020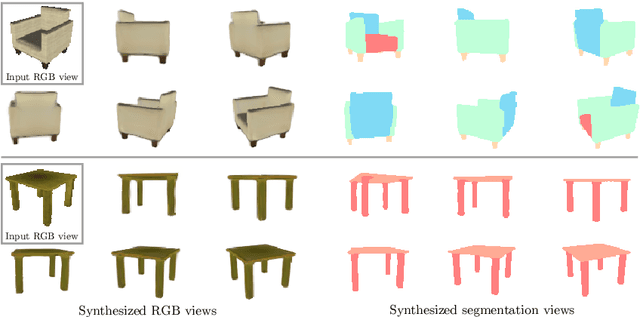

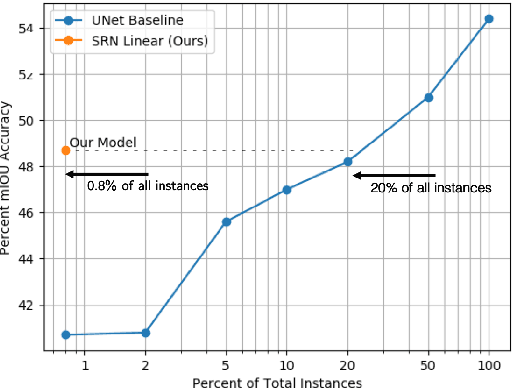
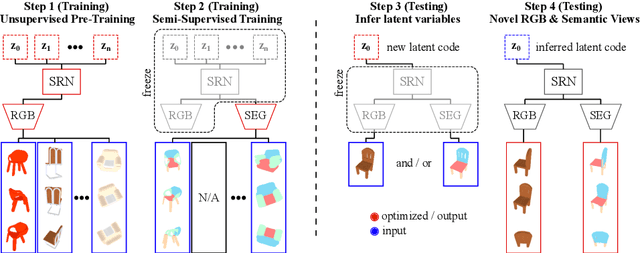
Biological vision infers multi-modal 3D representations that support reasoning about scene properties such as materials, appearance, affordance, and semantics in 3D. These rich representations enable us humans, for example, to acquire new skills, such as the learning of a new semantic class, with extremely limited supervision. Motivated by this ability of biological vision, we demonstrate that 3D-structure-aware representation learning leads to multi-modal representations that enable 3D semantic segmentation with extremely limited, 2D-only supervision. Building on emerging neural scene representations, which have been developed for modeling the shape and appearance of 3D scenes supervised exclusively by posed 2D images, we are first to demonstrate a representation that jointly encodes shape, appearance, and semantics in a 3D-structure-aware manner. Surprisingly, we find that only a few tens of labeled 2D segmentation masks are required to achieve dense 3D semantic segmentation using a semi-supervised learning strategy. We explore two novel applications for our semantically aware neural scene representation: 3D novel view and semantic label synthesis given only a single input RGB image or 2D label mask, as well as 3D interpolation of appearance and semantics.
Temporal Consistency Objectives Regularize the Learning of Disentangled Representations
Aug 29, 2019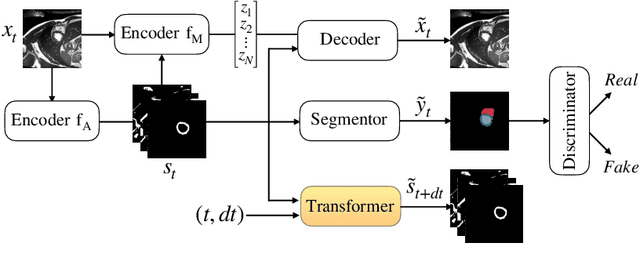
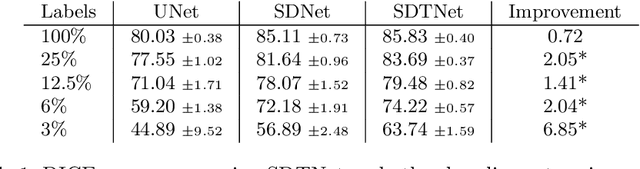


There has been an increasing focus in learning interpretable feature representations, particularly in applications such as medical image analysis that require explainability, whilst relying less on annotated data (since annotations can be tedious and costly). Here we build on recent innovations in style-content representations to learn anatomy, imaging characteristics (appearance) and temporal correlations. By introducing a self-supervised objective of predicting future cardiac phases we improve disentanglement. We propose a temporal transformer architecture that given an image conditioned on phase difference, it predicts a future frame. This forces the anatomical decomposition to be consistent with the temporal cardiac contraction in cine MRI and to have semantic meaning with less need for annotations. We demonstrate that using this regularization, we achieve competitive results and improve semi-supervised segmentation, especially when very few labelled data are available. Specifically, we show Dice increase of up to 19\% and 7\% compared to supervised and semi-supervised approaches respectively on the ACDC dataset. Code is available at: https://github.com/gvalvano/sdtnet .
Bit-Scalable Deep Hashing with Regularized Similarity Learning for Image Retrieval and Person Re-identification
Aug 21, 2015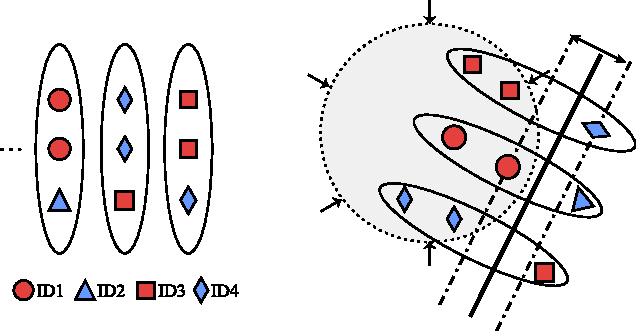
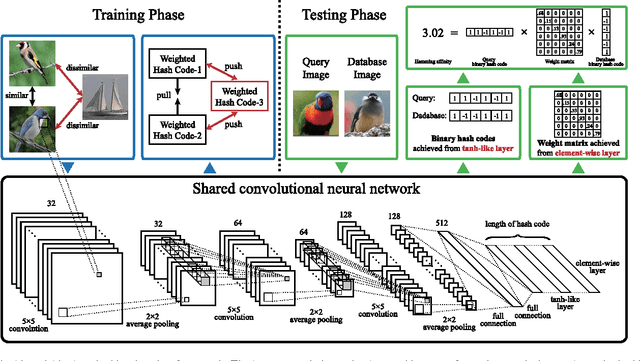

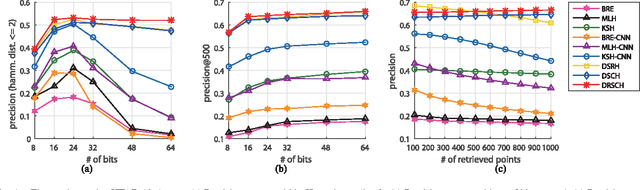
Extracting informative image features and learning effective approximate hashing functions are two crucial steps in image retrieval . Conventional methods often study these two steps separately, e.g., learning hash functions from a predefined hand-crafted feature space. Meanwhile, the bit lengths of output hashing codes are preset in most previous methods, neglecting the significance level of different bits and restricting their practical flexibility. To address these issues, we propose a supervised learning framework to generate compact and bit-scalable hashing codes directly from raw images. We pose hashing learning as a problem of regularized similarity learning. Specifically, we organize the training images into a batch of triplet samples, each sample containing two images with the same label and one with a different label. With these triplet samples, we maximize the margin between matched pairs and mismatched pairs in the Hamming space. In addition, a regularization term is introduced to enforce the adjacency consistency, i.e., images of similar appearances should have similar codes. The deep convolutional neural network is utilized to train the model in an end-to-end fashion, where discriminative image features and hash functions are simultaneously optimized. Furthermore, each bit of our hashing codes is unequally weighted so that we can manipulate the code lengths by truncating the insignificant bits. Our framework outperforms state-of-the-arts on public benchmarks of similar image search and also achieves promising results in the application of person re-identification in surveillance. It is also shown that the generated bit-scalable hashing codes well preserve the discriminative powers with shorter code lengths.
Learning monocular depth estimation infusing traditional stereo knowledge
Apr 08, 2019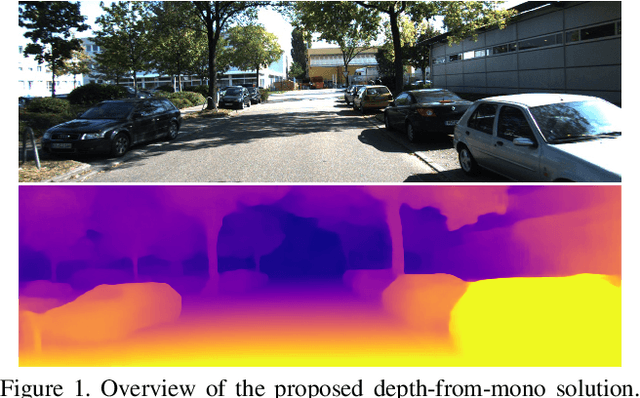
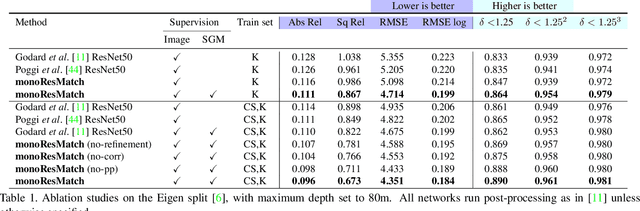
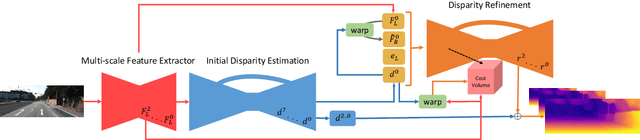
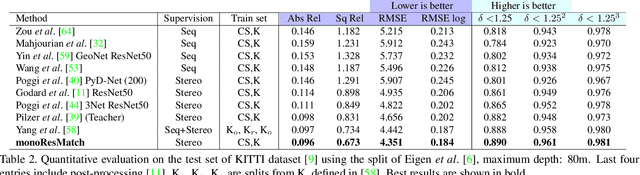
Depth estimation from a single image represents a fascinating, yet challenging problem with countless applications. Recent works proved that this task could be learned without direct supervision from ground truth labels leveraging image synthesis on sequences or stereo pairs. Focusing on this second case, in this paper we leverage stereo matching in order to improve monocular depth estimation. To this aim we propose monoResMatch, a novel deep architecture designed to infer depth from a single input image by synthesizing features from a different point of view, horizontally aligned with the input image, performing stereo matching between the two cues. In contrast to previous works sharing this rationale, our network is the first trained end-to-end from scratch. Moreover, we show how obtaining proxy ground truth annotation through traditional stereo algorithms, such as Semi-Global Matching, enables more accurate monocular depth estimation still countering the need for expensive depth labels by keeping a self-supervised approach. Exhaustive experimental results prove how the synergy between i) the proposed monoResMatch architecture and ii) proxy-supervision attains state-of-the-art for self-supervised monocular depth estimation. The code is publicly available at https://github.com/fabiotosi92/monoResMatch-Tensorflow.
Auto-Embedding Generative Adversarial Networks for High Resolution Image Synthesis
Mar 29, 2019

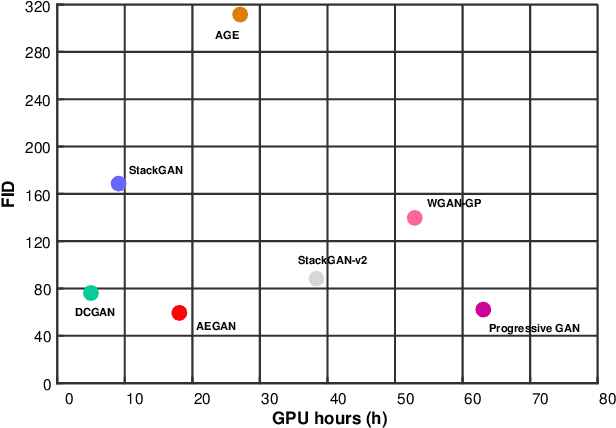
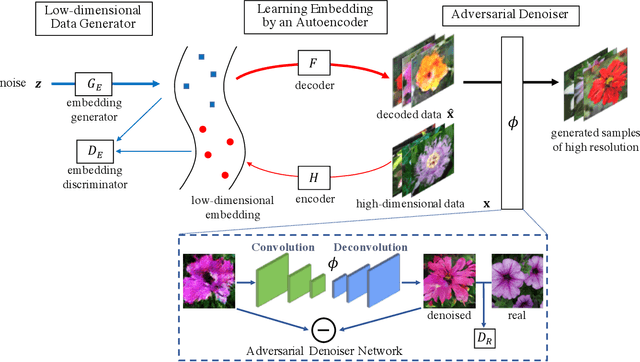
Generating images via the generative adversarial network (GAN) has attracted much attention recently. However, most of the existing GAN-based methods can only produce low-resolution images of limited quality. Directly generating high-resolution images using GANs is nontrivial, and often produces problematic images with incomplete objects. To address this issue, we develop a novel GAN called Auto-Embedding Generative Adversarial Network (AEGAN), which simultaneously encodes the global structure features and captures the fine-grained details. In our network, we use an autoencoder to learn the intrinsic high-level structure of real images and design a novel denoiser network to provide photo-realistic details for the generated images. In the experiments, we are able to produce 512x512 images of promising quality directly from the input noise. The resultant images exhibit better perceptual photo-realism, i.e., with sharper structure and richer details, than other baselines on several datasets, including Oxford-102 Flowers, Caltech-UCSD Birds (CUB), High-Quality Large-scale CelebFaces Attributes (CelebA-HQ), Large-scale Scene Understanding (LSUN) and ImageNet.
Multi-component Image Translation for Deep Domain Generalization
Dec 21, 2018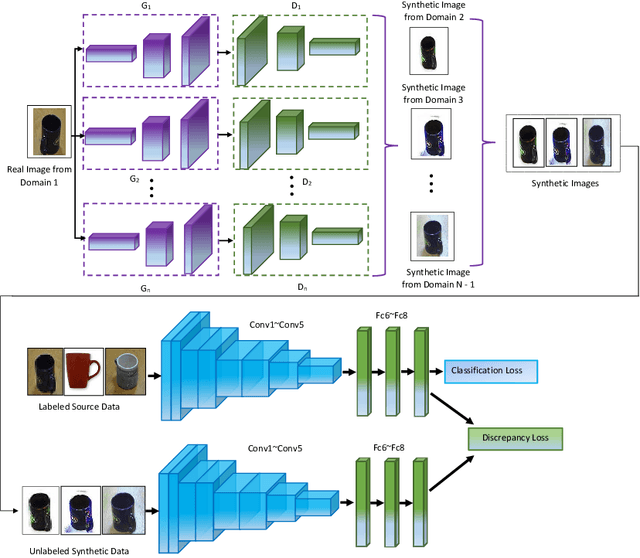
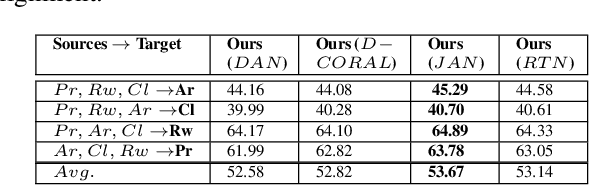
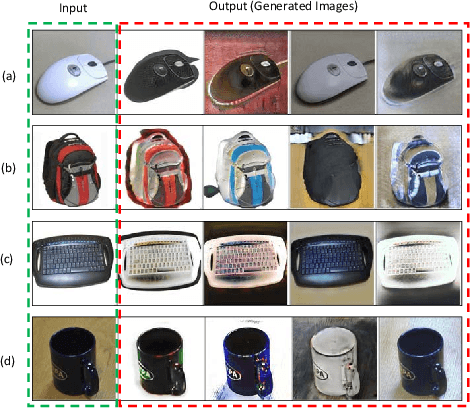
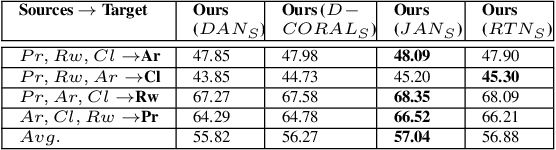
Domain adaption (DA) and domain generalization (DG) are two closely related methods which are both concerned with the task of assigning labels to an unlabeled data set. The only dissimilarity between these approaches is that DA can access the target data during the training phase, while the target data is totally unseen during the training phase in DG. The task of DG is challenging as we have no earlier knowledge of the target samples. If DA methods are applied directly to DG by a simple exclusion of the target data from training, poor performance will result for a given task. In this paper, we tackle the domain generalization challenge in two ways. In our first approach, we propose a novel deep domain generalization architecture utilizing synthetic data generated by a Generative Adversarial Network (GAN). The discrepancy between the generated images and synthetic images is minimized using existing domain discrepancy metrics such as maximum mean discrepancy or correlation alignment. In our second approach, we introduce a protocol for applying DA methods to a DG scenario by excluding the target data from the training phase, splitting the source data to training and validation parts, and treating the validation data as target data for DA. We conduct extensive experiments on four cross-domain benchmark datasets. Experimental results signify our proposed model outperforms the current state-of-the-art methods for DG.
A CNN-RNN Architecture for Multi-Label Weather Recognition
Apr 24, 2019


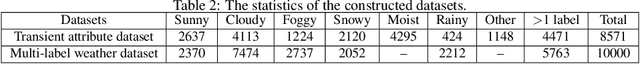
Weather Recognition plays an important role in our daily lives and many computer vision applications. However, recognizing the weather conditions from a single image remains challenging and has not been studied thoroughly. Generally, most previous works treat weather recognition as a single-label classification task, namely, determining whether an image belongs to a specific weather class or not. This treatment is not always appropriate, since more than one weather conditions may appear simultaneously in a single image. To address this problem, we make the first attempt to view weather recognition as a multi-label classification task, i.e., assigning an image more than one labels according to the displayed weather conditions. Specifically, a CNN-RNN based multi-label classification approach is proposed in this paper. The convolutional neural network (CNN) is extended with a channel-wise attention model to extract the most correlated visual features. The Recurrent Neural Network (RNN) further processes the features and excavates the dependencies among weather classes. Finally, the weather labels are predicted step by step. Besides, we construct two datasets for the weather recognition task and explore the relationships among different weather conditions. Experimental results demonstrate the superiority and effectiveness of the proposed approach. The new constructed datasets will be available at https://github.com/wzgwzg/Multi-Label-Weather-Recognition.
Softmax Splatting for Video Frame Interpolation
Mar 11, 2020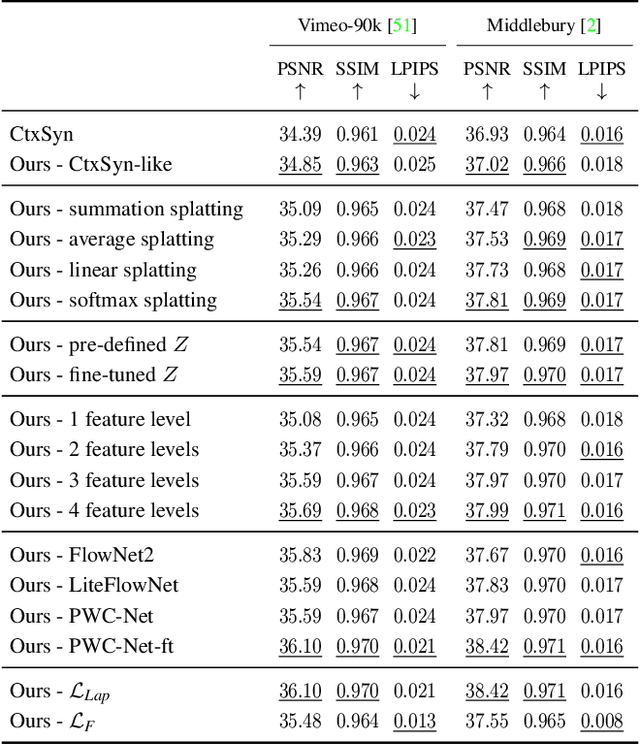
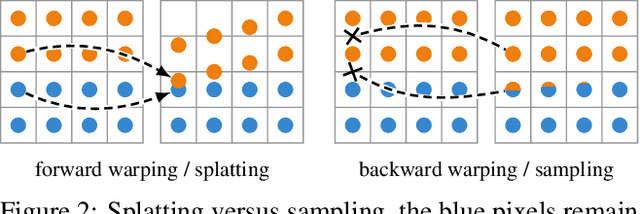
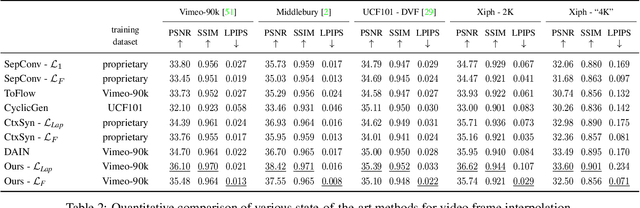

Differentiable image sampling in the form of backward warping has seen broad adoption in tasks like depth estimation and optical flow prediction. In contrast, how to perform forward warping has seen less attention, partly due to additional challenges such as resolving the conflict of mapping multiple pixels to the same target location in a differentiable way. We propose softmax splatting to address this paradigm shift and show its effectiveness on the application of frame interpolation. Specifically, given two input frames, we forward-warp the frames and their feature pyramid representations based on an optical flow estimate using softmax splatting. In doing so, the softmax splatting seamlessly handles cases where multiple source pixels map to the same target location. We then use a synthesis network to predict the interpolation result from the warped representations. Our softmax splatting allows us to not only interpolate frames at an arbitrary time but also to fine tune the feature pyramid and the optical flow. We show that our synthesis approach, empowered by softmax splatting, achieves new state-of-the-art results for video frame interpolation.
Towards Graph Representation Learning in Emergent Communication
Jan 24, 2020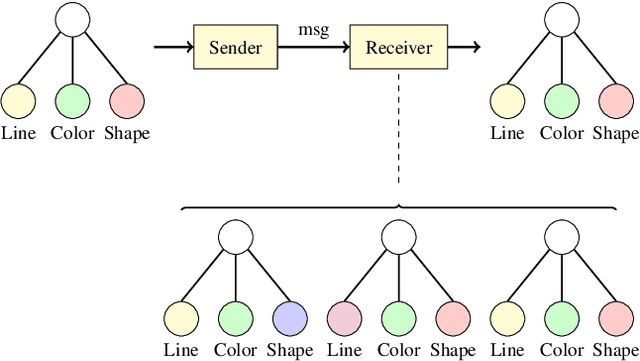

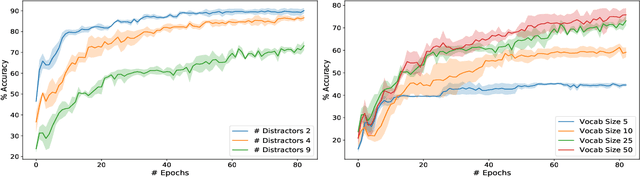
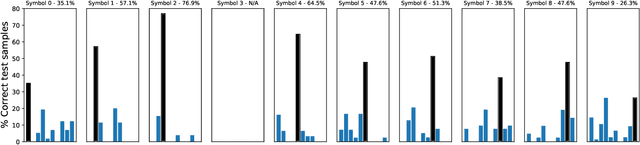
Recent findings in neuroscience suggest that the human brain represents information in a geometric structure (for instance, through conceptual spaces). In order to communicate, we flatten the complex representation of entities and their attributes into a single word or a sentence. In this paper we use graph convolutional networks to support the evolution of language and cooperation in multi-agent systems. Motivated by an image-based referential game, we propose a graph referential game with varying degrees of complexity, and we provide strong baseline models that exhibit desirable properties in terms of language emergence and cooperation. We show that the emerged communication protocol is robust, that the agents uncover the true factors of variation in the game, and that they learn to generalize beyond the samples encountered during training.