 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Feb 10, 2020

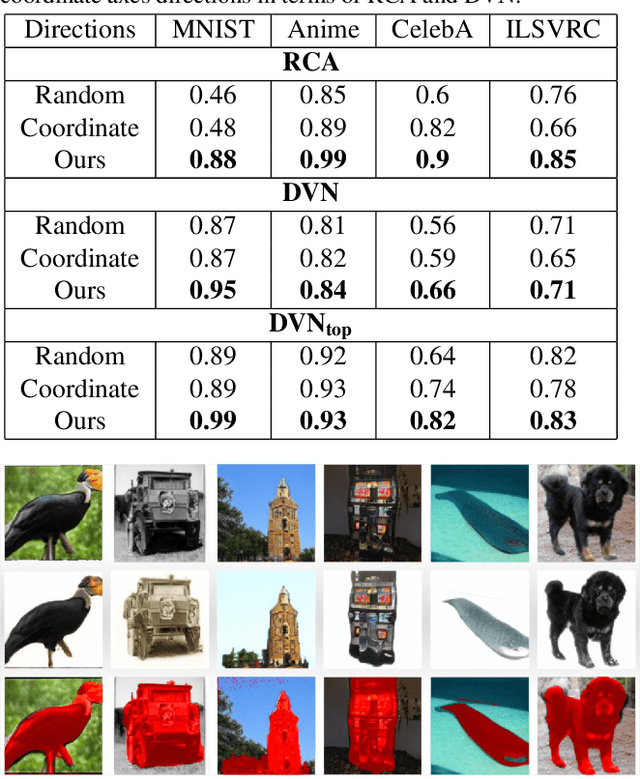


The latent spaces of typical GAN models often have semantically meaningful directions. Moving in these directions corresponds to human-interpretable image transformations, such as zooming or recoloring, enabling a more controllable generation process. However, the discovery of such directions is currently performed in a supervised manner, requiring human labels, pretrained models, or some form of self-supervision. These requirements can severely limit a range of directions existing approaches can discover. In this paper, we introduce an unsupervised method to identify interpretable directions in the latent space of a pretrained GAN model. By a simple model-agnostic procedure, we find directions corresponding to sensible semantic manipulations without any form of (self-)supervision. Furthermore, we reveal several non-trivial findings, which would be difficult to obtain by existing methods, e.g., a direction corresponding to background removal. As an immediate practical benefit of our work, we show how to exploit this finding to achieve a new state-of-the-art for the problem of saliency detection.
Stitching Videos from a Fisheye Lens Camera and a Wide-Angle Lens Camera for Telepresence Robots
Mar 15, 2019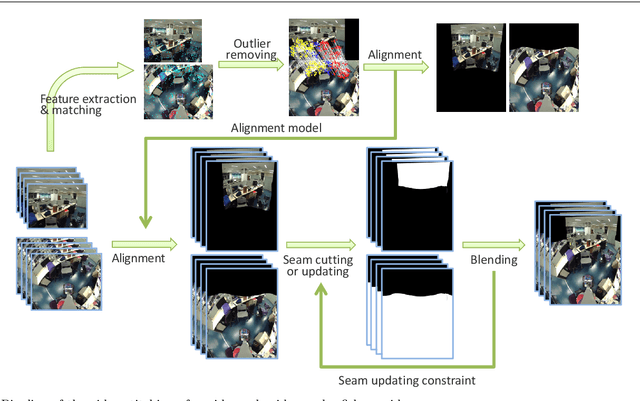
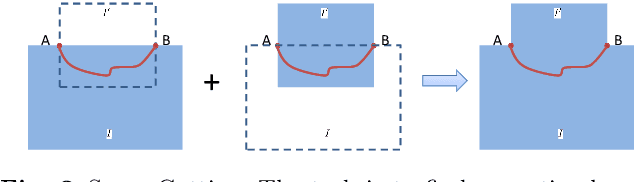

Many telepresence robots are equipped with a forward-facing camera for video communication and a downward-facing camera for navigation. In this paper, we propose to stitch videos from the FF-camera with a wide-angle lens and the DF-camera with a fisheye lens for telepresence robots. We aim at providing more compact and efficient visual feedback for the user interface of telepresence robots with user-friendly interactive experiences. To this end, we present a multi-homography-based video stitching method which stitches videos from a wide-angle camera and a fisheye camera. The method consists of video image alignment, seam cutting, and image blending. We directly align the wide-angle video image and the fisheye video image based on the multi-homography alignment without calibration, distortion correction, and unwarping procedures. Thus, we can obtain a stitched video with shape preservation in the non-overlapping regions and alignment in the overlapping area for telepresence. To alleviate ghosting effects caused by moving objects and/or moving cameras during telepresence robot driving, an optimal seam is found for aligned video composition, and the optimal seam will be updated in subsequent frames, considering spatial and temporal coherence. The final stitched video is created by image blending based on the optimal seam. We conducted a user study to demonstrate the effectiveness of our method and the superiority of telepresence robots with a stitched video as visual feedback.
Improving Learning Effectiveness For Object Detection and Classification in Cluttered Backgrounds
Feb 27, 2020

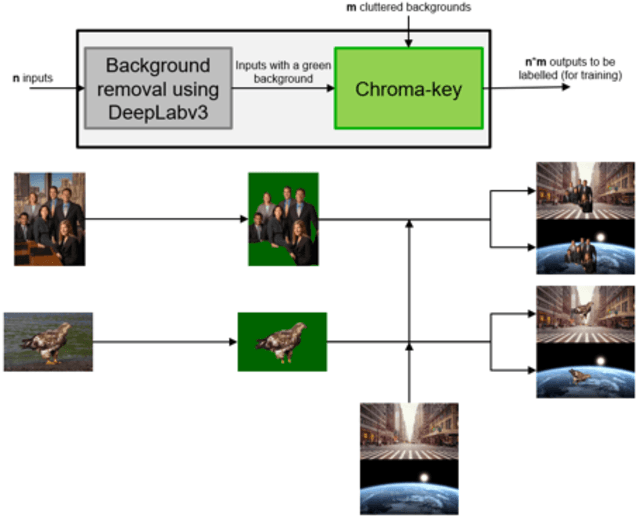
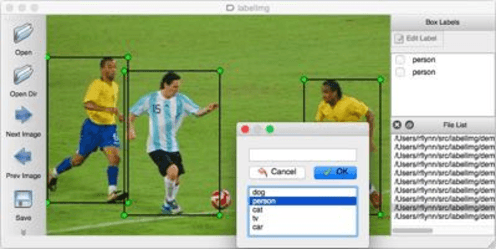
Usually, Neural Networks models are trained with a large dataset of images in homogeneous backgrounds. The issue is that the performance of the network models trained could be significantly degraded in a complex and heterogeneous environment. To mitigate the issue, this paper develops a framework that permits to autonomously generate a training dataset in heterogeneous cluttered backgrounds. It is clear that the learning effectiveness of the proposed framework should be improved in complex and heterogeneous environments, compared with the ones with the typical dataset. In our framework, a state-of-the-art image segmentation technique called DeepLab is used to extract objects of interest from a picture and Chroma-key technique is then used to merge the extracted objects of interest into specific heterogeneous backgrounds. The performance of the proposed framework is investigated through empirical tests and compared with that of the model trained with the COCO dataset. The results show that the proposed framework outperforms the model compared. This implies that the learning effectiveness of the framework developed is superior to the models with the typical dataset.
Facial Emotion Recognition Using Deep Learning
Oct 19, 2019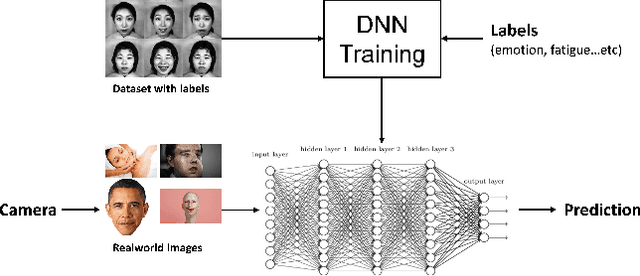
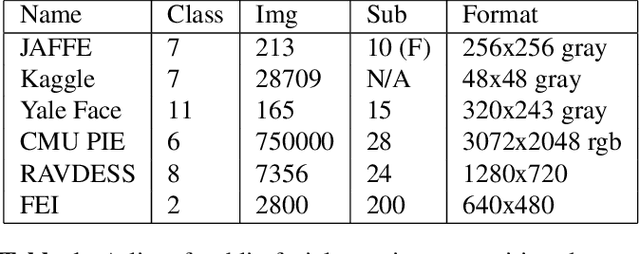
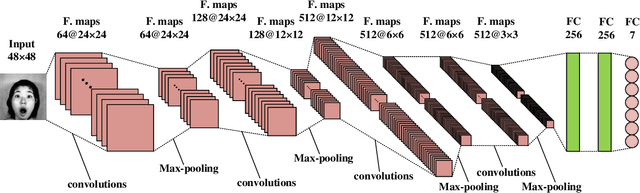
We aim to construct a system that captures real-world facial images through the front camera on a laptop. The system is capable of processing/recognizing the captured image and predict a result in real-time. In this system, we exploit the power of deep learning technique to learn a facial emotion recognition (FER) model based on a set of labeled facial images. Finally, experiments are conducted to evaluate our model using largely used public database.
TensorNetwork for Machine Learning
Jun 07, 2019
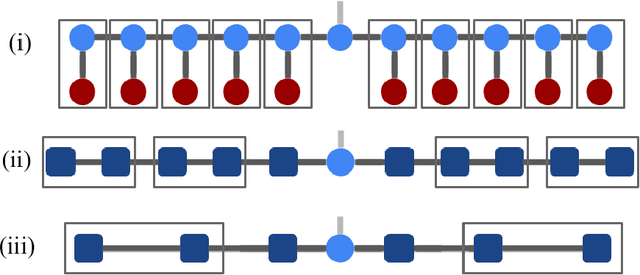
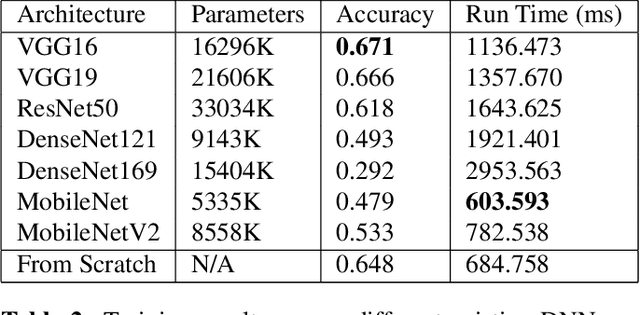
We demonstrate the use of tensor networks for image classification with the TensorNetwork open source library. We explain in detail the encoding of image data into a matrix product state form, and describe how to contract the network in a way that is parallelizable and well-suited to automatic gradients for optimization. Applying the technique to the MNIST and Fashion-MNIST datasets we find out-of-the-box performance of 98% and 88% accuracy, respectively, using the same tensor network architecture. The TensorNetwork library allows us to seamlessly move from CPU to GPU hardware, and we see a factor of more than 10 improvement in computational speed using a GPU.
TGGLines: A Robust Topological Graph Guided Line Segment Detector for Low Quality Binary Images
Feb 27, 2020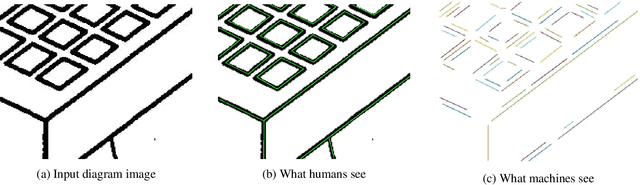
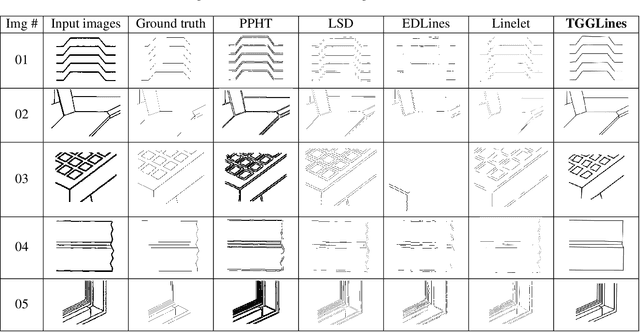

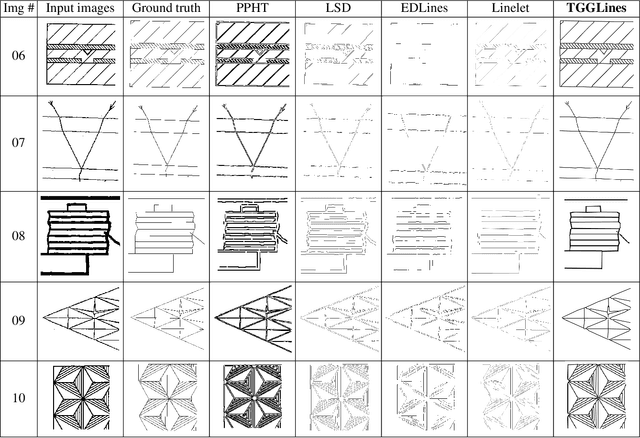
Line segment detection is an essential task in computer vision and image analysis, as it is the critical foundation for advanced tasks such as shape modeling and road lane line detection for autonomous driving. We present a robust topological graph guided approach for line segment detection in low quality binary images (hence, we call it TGGLines). Due to the graph-guided approach, TGGLines not only detects line segments, but also organizes the segments with a line segment connectivity graph, which means the topological relationships (e.g., intersection, an isolated line segment) of the detected line segments are captured and stored; whereas other line detectors only retain a collection of loose line segments. Our empirical results show that the TGGLines detector visually and quantitatively outperforms state-of-the-art line segment detection methods. In addition, our TGGLines approach has the following two competitive advantages: (1) our method only requires one parameter and it is adaptive, whereas almost all other line segment detection methods require multiple (non-adaptive) parameters, and (2) the line segments detected by TGGLines are organized by a line segment connectivity graph.
Improved low-count quantitative PET reconstruction with a variational neural network
Jun 05, 2019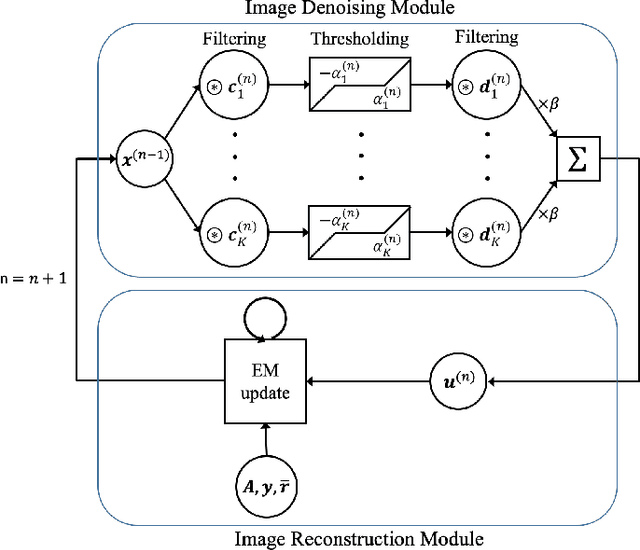
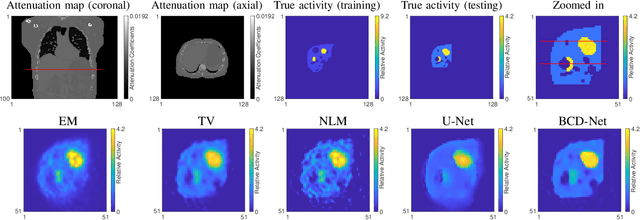
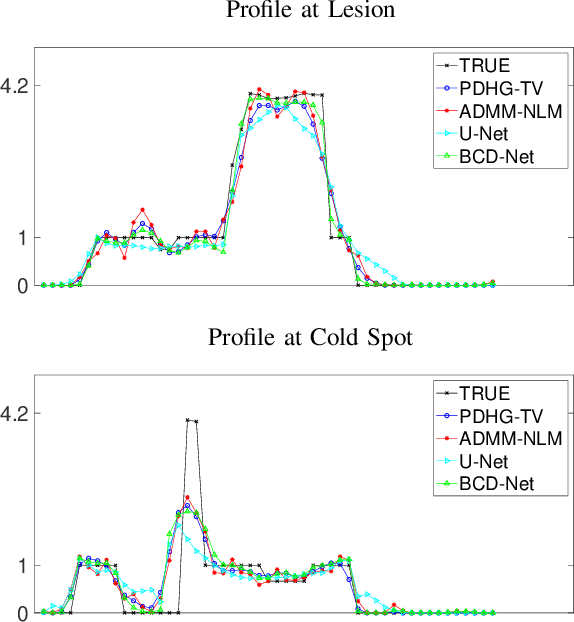

Image reconstruction in low-count PET is particularly challenging because gammas from natural radioactivity in Lu-based crystals cause high random fractions that lower the measurement signal-to-noise-ratio (SNR). In model-based image reconstruction (MBIR), using more iterations of an unregularized method may increase the noise, so incorporating regularization into the image reconstruction is desirable to control the noise. New regularization methods based on learned convolutional operators are emerging in MBIR. We modify the architecture of a variational neural network, BCD-Net, for PET MBIR, and demonstrate the efficacy of the trained BCD-Net using XCAT phantom data that simulates the low true coincidence count-rates with high random fractions typical for Y-90 PET patient imaging after Y-90 microsphere radioembolization. Numerical results show that the proposed BCD-Net significantly improves PET reconstruction performance compared to MBIR methods using non-trained regularizers, total variation (TV) and non-local means (NLM), and a non-MBIR method using a single forward pass deep neural network, U-Net. BCD-Net improved activity recovery for a hot sphere significantly and reduced noise, whereas non-trained regularizers had a trade-off between noise and quantification. BCD-Net improved CNR and RMSE by 43.4% (85.7%) and 12.9% (29.1%) compared to TV (NLM) regularized MBIR. Moreover, whereas the image reconstruction results show that the non-MBIR U-Net over-fits the training data, BCD-Net successfully generalizes to data that differs from training data. Improvements were also demonstrated for the clinically relevant phantom measurement data where we used training and testing datasets having very different activity distribution and count-level.
Forecasting Mobile Traffic with Spatiotemporal correlation using Deep Regression
Jul 25, 2019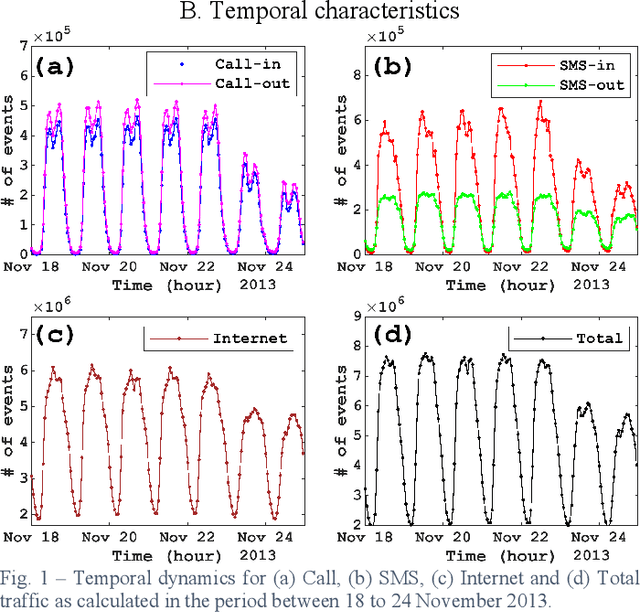
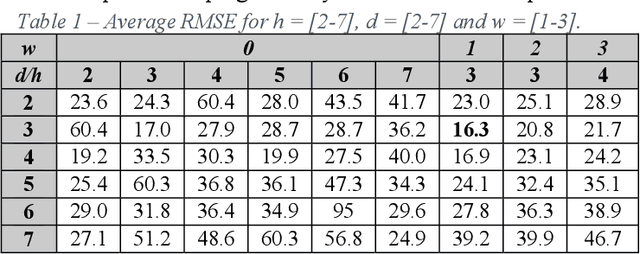
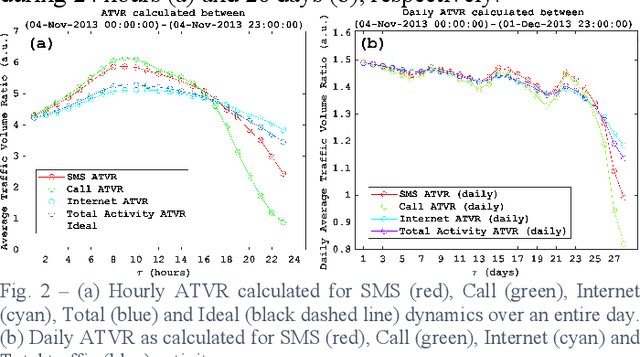
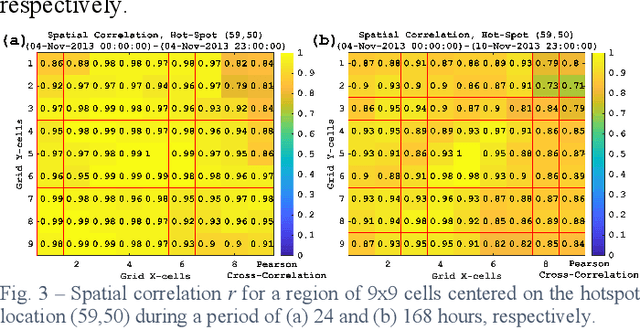
The concept of mobility prediction represents one of the key enablers for an efficient management of future cellular networks, which tend to be progressively more elaborate and dense due to the aggregation of multiple technologies. In this letter we aim to investigate the problem of cellular traffic prediction over a metropolitan area and propose a deep regression (DR) approach to model its complex spatio-temporal dynamics. DR is instrumental in capturing multi-scale and multi-domain dependences of mobile data by solving an image-to-image regression problem. A parametric relationship between input and expected output is defined and grid search is put in place to isolate and optimize performance. Experimental results confirm that the proposed method achieves a lower prediction error against stateof-the-art algorithms. We validate forecasting performance and stability by using a large public dataset of a European Provider.
Federated Generative Adversarial Learning
May 24, 2020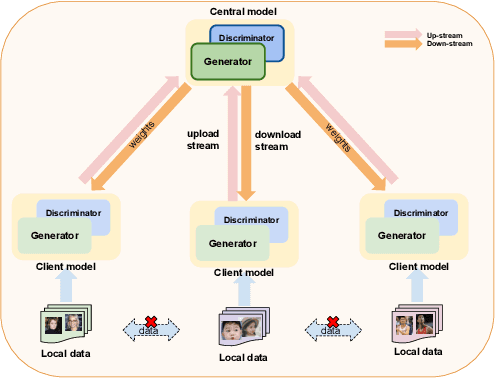
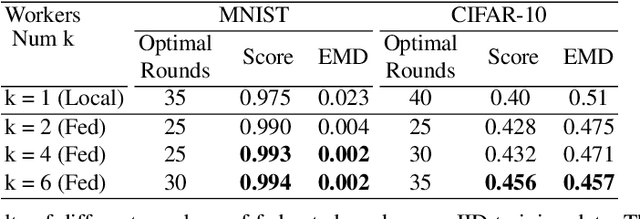
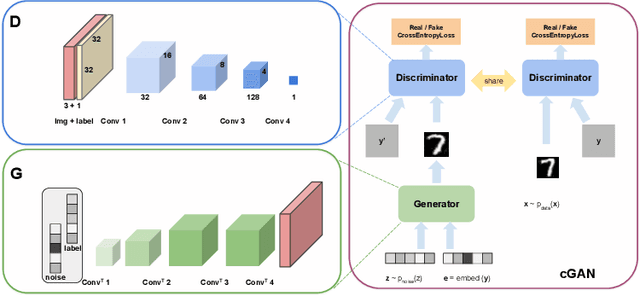
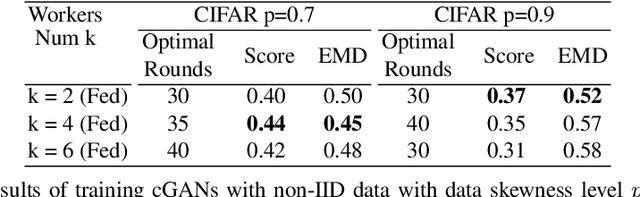
This work studies training generative adversarial networks under the federated learning setting. Generative adversarial networks (GANs) have achieved advancement in various real-world applications, such as image editing, style transfer, scene generations, etc. However, like other deep learning models, GANs are also suffering from data limitation problems in real cases. To boost the performance of GANs in target tasks, collecting images as many as possible from different sources becomes not only important but also essential. For example, to build a robust and accurate bio-metric verification system, huge amounts of images might be collected from surveillance cameras, and/or uploaded from cellphones by users accepting agreements. In an ideal case, utilize all those data uploaded from public and private devices for model training is straightforward. Unfortunately, in the real scenarios, this is hard due to a few reasons. At first, some data face the serious concern of leakage, and therefore it is prohibitive to upload them to a third-party server for model training; at second, the images collected by different kinds of devices, probably have distinctive biases due to various factors, $\textit{e.g.}$, collector preferences, geo-location differences, which is also known as "domain shift". To handle those problems, we propose a novel generative learning scheme utilizing a federated learning framework. Following the configuration of federated learning, we conduct model training and aggregation on one center and a group of clients. Specifically, our method learns the distributed generative models in clients, while the models trained in each client are fused into one unified and versatile model in the center. We perform extensive experiments to compare different federation strategies, and empirically examine the effectiveness of federation under different levels of parallelism and data skewness.
Monocular Depth Estimation Based On Deep Learning: An Overview
Mar 14, 2020
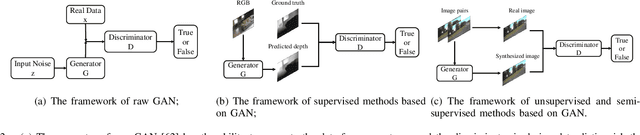
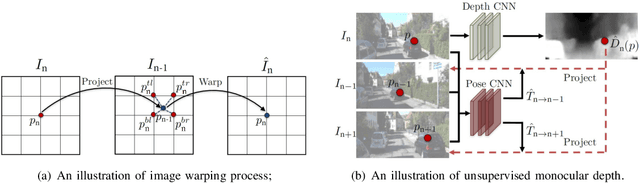
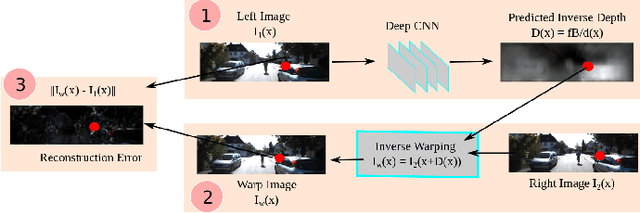
Depth information is important for autonomous systems to perceive environments and estimate their own state. Traditional depth estimation methods, like structure from motion and stereo vision matching, are built on feature correspondences of multiple viewpoints. Meanwhile, the predicted depth maps are sparse. Inferring depth information from a single image (monocular depth estimation) is an ill-posed problem. With the rapid development of deep neural networks, monocular depth estimation based on deep learning has been widely studied recently and achieved promising performance in accuracy. Meanwhile, dense depth maps are estimated from single images by deep neural networks in an end-to-end manner. In order to improve the accuracy of depth estimation, different kinds of network frameworks, loss functions and training strategies are proposed subsequently. Therefore, we survey the current monocular depth estimation methods based on deep learning in this review. Initially, we conclude several widely used datasets and evaluation indicators in deep learning-based depth estimation. Furthermore, we review some representative existing methods according to different training manners: supervised, unsupervised and semi-supervised. Finally, we discuss the challenges and provide some ideas for future researches in monocular depth estimation.