 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DifAugGAN: A Practical Diffusion-style Data Augmentation for GAN-based Single Image Super-resolution
Nov 30, 2023

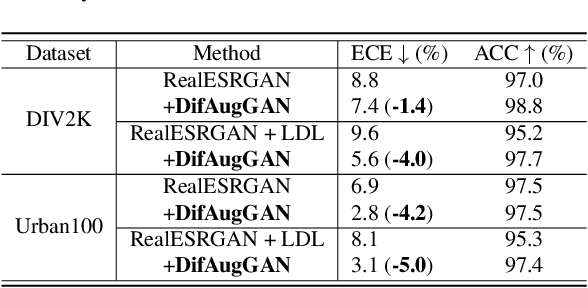
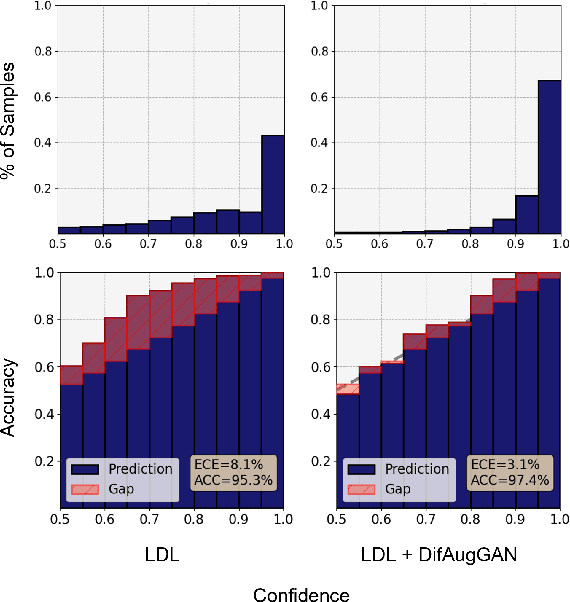
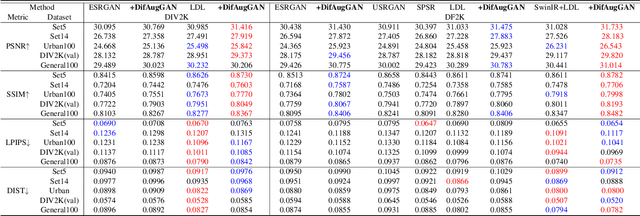
It is well known the adversarial optimization of GAN-based image super-resolution (SR) methods makes the preceding SR model generate unpleasant and undesirable artifacts, leading to large distortion. We attribute the cause of such distortions to the poor calibration of the discriminator, which hampers its ability to provide meaningful feedback to the generator for learning high-quality images. To address this problem, we propose a simple but non-travel diffusion-style data augmentation scheme for current GAN-based SR methods, known as DifAugGAN. It involves adapting the diffusion process in generative diffusion models for improving the calibration of the discriminator during training motivated by the successes of data augmentation schemes in the field to achieve good calibration. Our DifAugGAN can be a Plug-and-Play strategy for current GAN-based SISR methods to improve the calibration of the discriminator and thus improve SR performance. Extensive experimental evaluations demonstrate the superiority of DifAugGAN over state-of-the-art GAN-based SISR methods across both synthetic and real-world datasets, showcasing notable advancements in both qualitative and quantitative results.
An Interpretable Deep Learning Approach for Skin Cancer Categorization
Dec 17, 2023Skin cancer is a serious worldwide health issue, precise and early detection is essential for better patient outcomes and effective treatment. In this research, we use modern deep learning methods and explainable artificial intelligence (XAI) approaches to address the problem of skin cancer detection. To categorize skin lesions, we employ four cutting-edge pre-trained models: XceptionNet, EfficientNetV2S, InceptionResNetV2, and EfficientNetV2M. Image augmentation approaches are used to reduce class imbalance and improve the generalization capabilities of our models. Our models decision-making process can be clarified because of the implementation of explainable artificial intelligence (XAI). In the medical field, interpretability is essential to establish credibility and make it easier to implement AI driven diagnostic technologies into clinical workflows. We determined the XceptionNet architecture to be the best performing model, achieving an accuracy of 88.72%. Our study shows how deep learning and explainable artificial intelligence (XAI) can improve skin cancer diagnosis, laying the groundwork for future developments in medical image analysis. These technologies ability to allow for early and accurate detection could enhance patient care, lower healthcare costs, and raise the survival rates for those with skin cancer. Source Code: https://github.com/Faysal-MD/An-Interpretable-Deep-Learning?Approach-for-Skin-Cancer-Categorization-IEEE2023
UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
Nov 17, 2023
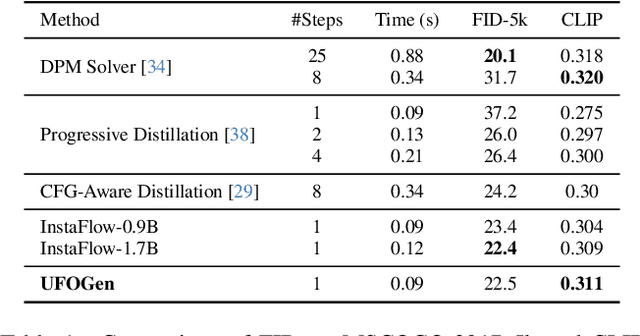
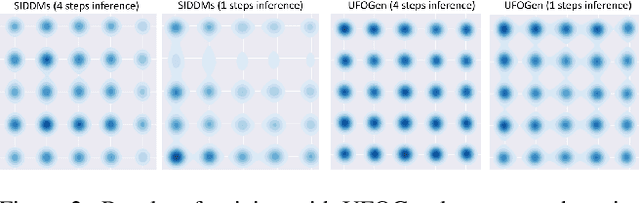
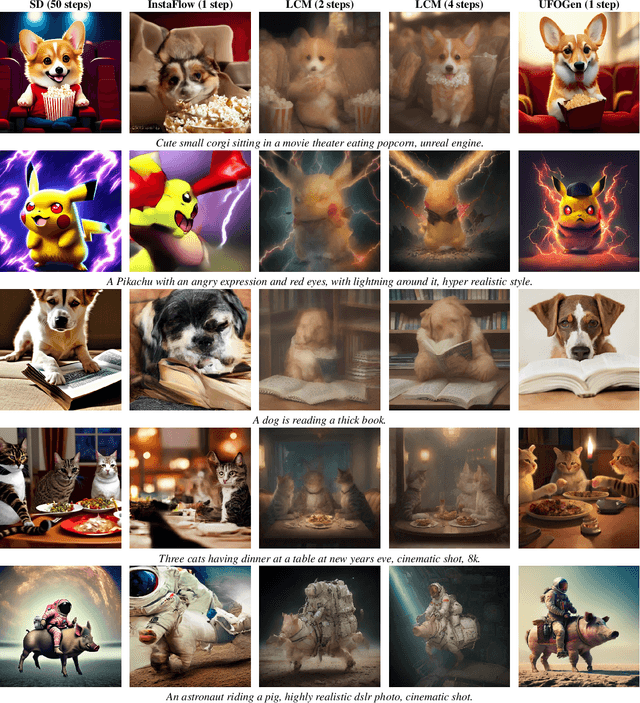
Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image synthesis. In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications. Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models.
Rotation-Agnostic Image Representation Learning for Digital Pathology
Nov 14, 2023This paper addresses complex challenges in histopathological image analysis through three key contributions. Firstly, it introduces a fast patch selection method, FPS, for whole-slide image (WSI) analysis, significantly reducing computational cost while maintaining accuracy. Secondly, it presents PathDino, a lightweight histopathology feature extractor with a minimal configuration of five Transformer blocks and only 9 million parameters, markedly fewer than alternatives. Thirdly, it introduces a rotation-agnostic representation learning paradigm using self-supervised learning, effectively mitigating overfitting. We also show that our compact model outperforms existing state-of-the-art histopathology-specific vision transformers on 12 diverse datasets, including both internal datasets spanning four sites (breast, liver, skin, and colorectal) and seven public datasets (PANDA, CAMELYON16, BRACS, DigestPath, Kather, PanNuke, and WSSS4LUAD). Notably, even with a training dataset of 6 million histopathology patches from The Cancer Genome Atlas (TCGA), our approach demonstrates an average 8.5% improvement in patch-level majority vote performance. These contributions provide a robust framework for enhancing image analysis in digital pathology, rigorously validated through extensive evaluation. Project Page: https://rhazeslab.github.io/PathDino-Page/
Stable diffusion for Data Augmentation in COCO and Weed Datasets
Dec 11, 2023Generative models have increasingly impacted relative tasks, from computer vision to interior design and other fields. Stable diffusion is an outstanding diffusion model that paves the way for producing high-resolution images with thorough details from text prompts or reference images. It will be an interesting topic about gaining improvements for small datasets with image-sparse categories. This study utilized seven common categories and three widespread weed species to evaluate the efficiency of a stable diffusion model. In detail, Stable diffusion was used to generate synthetic images belonging to these classes; three techniques (i.e., Image-to-image translation, Dreambooth, and ControlNet) based on stable diffusion were leveraged for image generation with different focuses. Then, classification and detection tasks were conducted based on these synthetic images, whose performance was compared to the models trained on original images. Promising results have been achieved in some classes. This seminal study may expedite the adaption of stable diffusion models to different fields.
Diffusing More Objects for Semi-Supervised Domain Adaptation with Less Labeling
Dec 19, 2023For object detection, it is possible to view the prediction of bounding boxes as a reverse diffusion process. Using a diffusion model, the random bounding boxes are iteratively refined in a denoising step, conditioned on the image. We propose a stochastic accumulator function that starts each run with random bounding boxes and combines the slightly different predictions. We empirically verify that this improves detection performance. The improved detections are leveraged on unlabelled images as weighted pseudo-labels for semi-supervised learning. We evaluate the method on a challenging out-of-domain test set. Our method brings significant improvements and is on par with human-selected pseudo-labels, while not requiring any human involvement.
C-NERF: Representing Scene Changes as Directional Consistency Difference-based NeRF
Dec 23, 2023In this work, we aim to detect the changes caused by object variations in a scene represented by the neural radiance fields (NeRFs). Given an arbitrary view and two sets of scene images captured at different timestamps, we can predict the scene changes in that view, which has significant potential applications in scene monitoring and measuring. We conducted preliminary studies and found that such an exciting task cannot be easily achieved by utilizing existing NeRFs and 2D change detection methods with many false or missing detections. The main reason is that the 2D change detection is based on the pixel appearance difference between spatial-aligned image pairs and neglects the stereo information in the NeRF. To address the limitations, we propose the C-NERF to represent scene changes as directional consistency difference-based NeRF, which mainly contains three modules. We first perform the spatial alignment of two NeRFs captured before and after changes. Then, we identify the change points based on the direction-consistent constraint; that is, real change points have similar change representations across view directions, but fake change points do not. Finally, we design the change map rendering process based on the built NeRFs and can generate the change map of an arbitrarily specified view direction. To validate the effectiveness, we build a new dataset containing ten scenes covering diverse scenarios with different changing objects. Our approach surpasses state-of-the-art 2D change detection and NeRF-based methods by a significant margin.
Enhancing Neural Training via a Correlated Dynamics Model
Dec 20, 2023As neural networks grow in scale, their training becomes both computationally demanding and rich in dynamics. Amidst the flourishing interest in these training dynamics, we present a novel observation: Parameters during training exhibit intrinsic correlations over time. Capitalizing on this, we introduce Correlation Mode Decomposition (CMD). This algorithm clusters the parameter space into groups, termed modes, that display synchronized behavior across epochs. This enables CMD to efficiently represent the training dynamics of complex networks, like ResNets and Transformers, using only a few modes. Moreover, test set generalization is enhanced. We introduce an efficient CMD variant, designed to run concurrently with training. Our experiments indicate that CMD surpasses the state-of-the-art method for compactly modeled dynamics on image classification. Our modeling can improve training efficiency and lower communication overhead, as shown by our preliminary experiments in the context of federated learning.
VILA: On Pre-training for Visual Language Models
Dec 14, 2023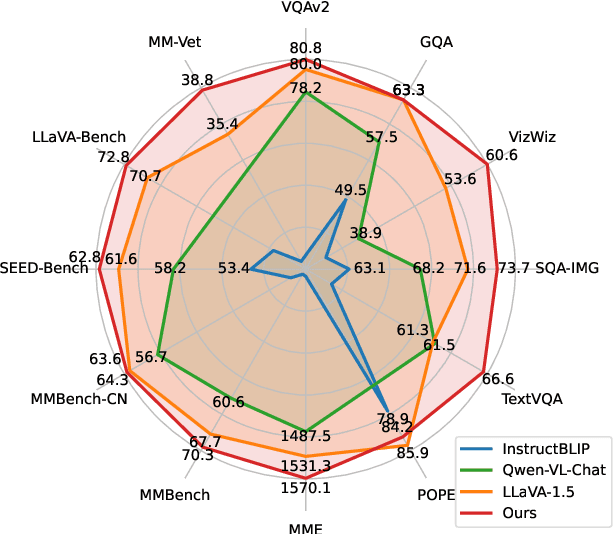
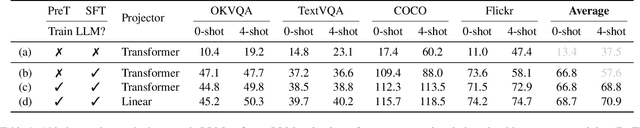
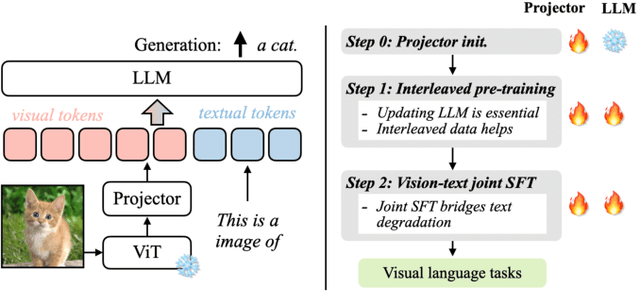

Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
Exploring the Naturalness of AI-Generated Images
Dec 14, 2023The proliferation of Artificial Intelligence-Generated Images (AGIs) has greatly expanded the Image Naturalness Assessment (INA) problem. Different from early definitions that mainly focus on tone-mapped images with limited distortions (e.g., exposure, contrast, and color reproduction), INA on AI-generated images is especially challenging as it has more diverse contents and could be affected by factors from multiple perspectives, including low-level technical distortions and high-level rationality distortions. In this paper, we take the first step to benchmark and assess the visual naturalness of AI-generated images. First, we construct the AI-Generated Image Naturalness (AGIN) database by conducting a large-scale subjective study to collect human opinions on the overall naturalness as well as perceptions from technical and rationality perspectives. AGIN verifies that naturalness is universally and disparately affected by both technical and rationality distortions. Second, we propose the Joint Objective Image Naturalness evaluaTor (JOINT), to automatically learn the naturalness of AGIs that aligns human ratings. Specifically, JOINT imitates human reasoning in naturalness evaluation by jointly learning both technical and rationality perspectives. Experimental results show our proposed JOINT significantly surpasses baselines for providing more subjectively consistent results on naturalness assessment. Our database and code will be released in https://github.com/zijianchen98/AGIN.