 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mixup of Feature Maps in a Hidden Layer for Training of Convolutional Neural Network
Jun 24, 2019

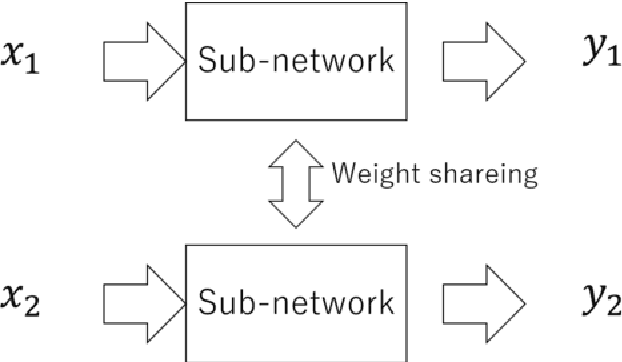
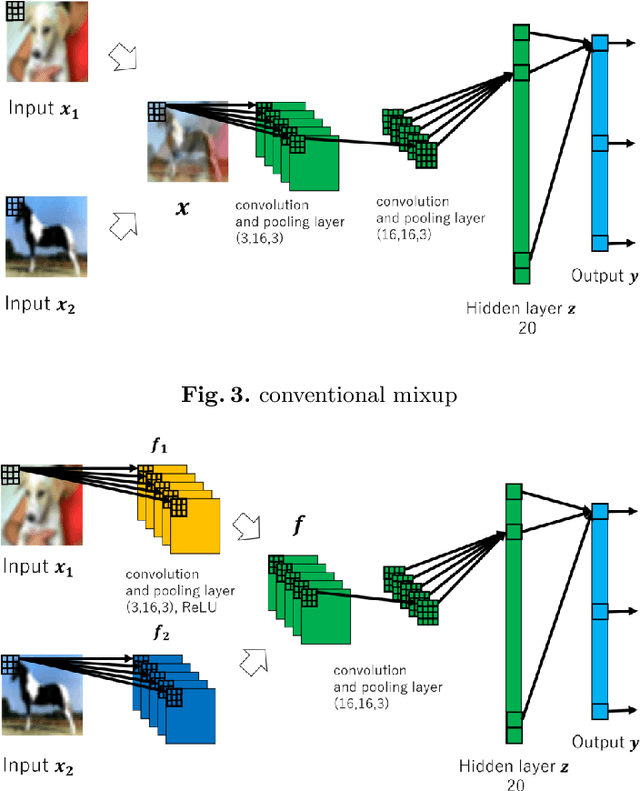
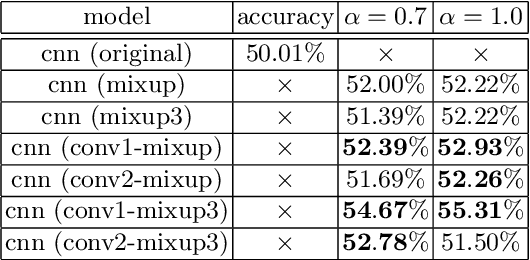
The deep Convolutional Neural Network (CNN) became very popular as a fundamental technique for image classification and objects recognition. To improve the recognition accuracy for the more complex tasks, deeper networks have being introduced. However, the recognition accuracy of the trained deep CNN drastically decreases for the samples which are obtained from the outside regions of the training samples. To improve the generalization ability for such samples, Krizhevsky et al. proposed to generate additional samples through transformations from the existing samples and to make the training samples richer. This method is known as data augmentation. Hongyi Zhang et al. introduced data augmentation method called mixup which achieves state-of-the-art performance in various datasets. Mixup generates new samples by mixing two different training samples. Mixing of the two images is implemented with simple image morphing. In this paper, we propose to apply mixup to the feature maps in a hidden layer. To implement the mixup in the hidden layer we use the Siamese network or the triplet network architecture to mix feature maps. From the experimental comparison, it is observed that the mixup of the feature maps obtained from the first convolution layer is more effective than the original image mixup.
* 11 pages, 5 figures
Land Use and Land Cover Classification Using Deep Learning Techniques
May 01, 2019
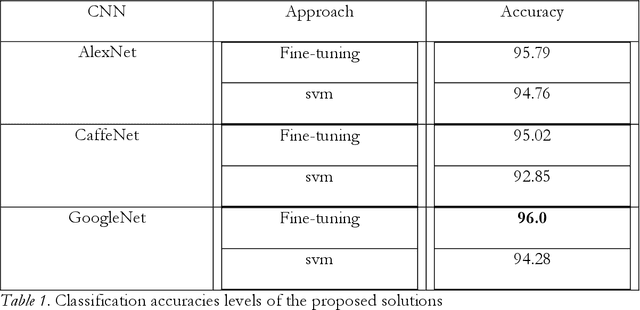
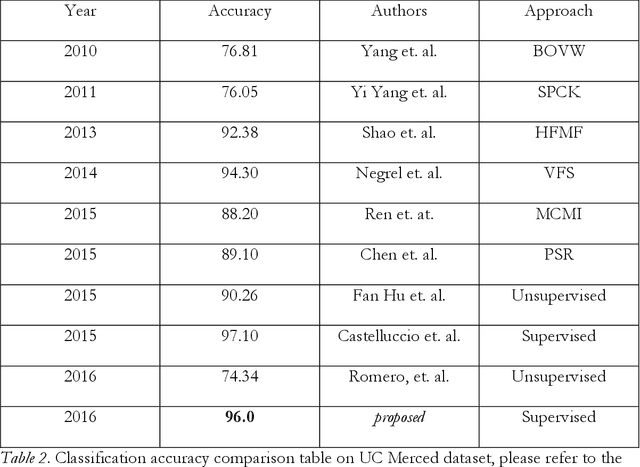
Large datasets of sub-meter aerial imagery represented as orthophoto mosaics are widely available today, and these data sets may hold a great deal of untapped information. This imagery has a potential to locate several types of features; for example, forests, parking lots, airports, residential areas, or freeways in the imagery. However, the appearances of these things vary based on many things including the time that the image is captured, the sensor settings, processing done to rectify the image, and the geographical and cultural context of the region captured by the image. This thesis explores the use of deep convolutional neural networks to classify land use from very high spatial resolution (VHR), orthorectified, visible band multispectral imagery. Recent technological and commercial applications have driven the collection a massive amount of VHR images in the visible red, green, blue (RGB) spectral bands, this work explores the potential for deep learning algorithms to exploit this imagery for automatic land use/ land cover (LULC) classification.
Detecting and Recovering Adversarial Examples: An Input Sensitivity Guided Method
Feb 28, 2020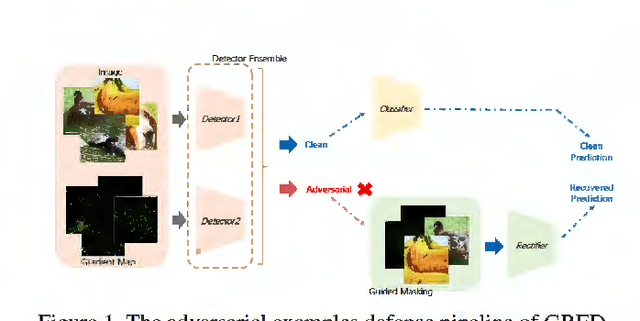
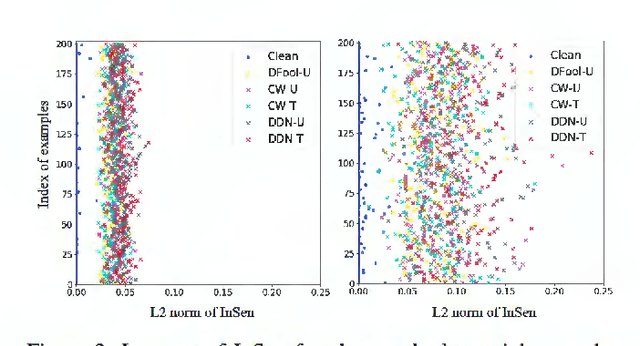
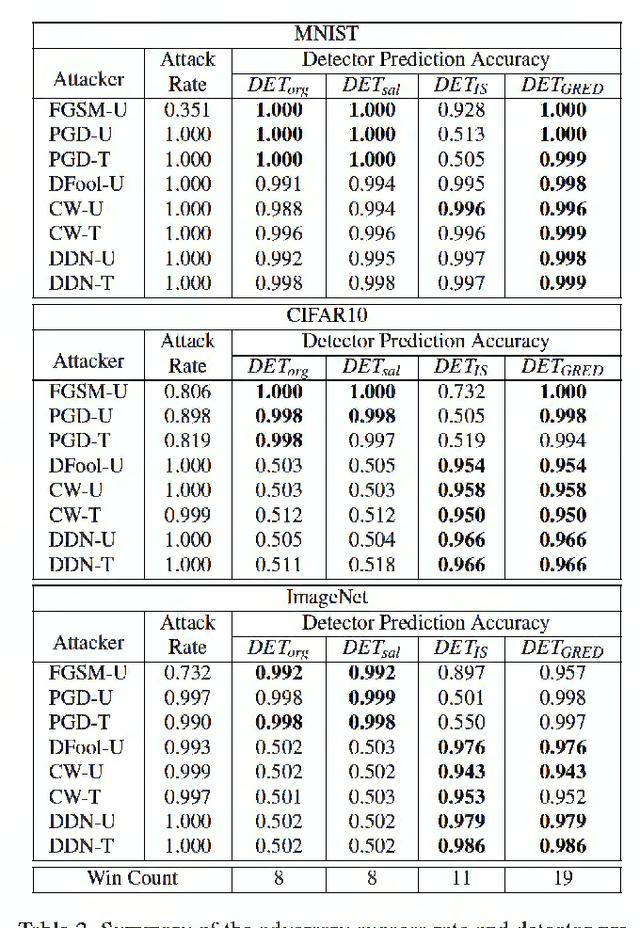
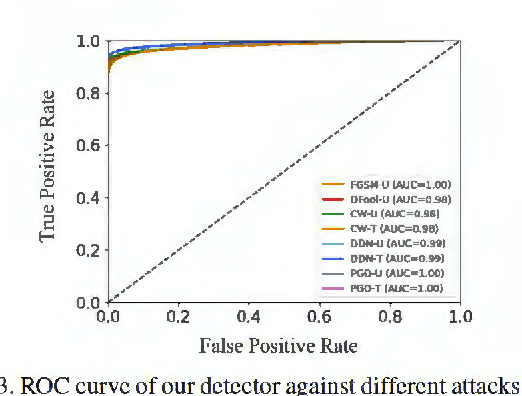
Deep neural networks undergo rapid development and achieve notable success in various tasks, including many security concerned scenarios. However, a considerable amount of works have proved its vulnerability in adversaries. To address this problem, we propose a Guided Robust and Efficient Defensive Model GRED integrating detection and recovery processes together. From the lens of the properties of gradient distribution of adversarial examples, our model detects malicious inputs effectively, as well as recovering the ground-truth label with high accuracy. Compared with commonly used adversarial training methods, our model is more efficient and outperforms state-of-the-art adversarial trained models by a large margin up to 99% on MNIST, 89 % on CIFAR-10 and 87% on ImageNet subsets. When exclusively compared with previous adversarial detection methods, the detector of GRED is robust under all threat settings with a detection rate of over 95% against most of the attacks. It is also demonstrated by empirical assessment that our model could increase attacking cost significantly resulting in either unacceptable time consuming or human perceptible image distortions.
6DoF Object Pose Estimation via Differentiable Proxy Voting Loss
Feb 10, 2020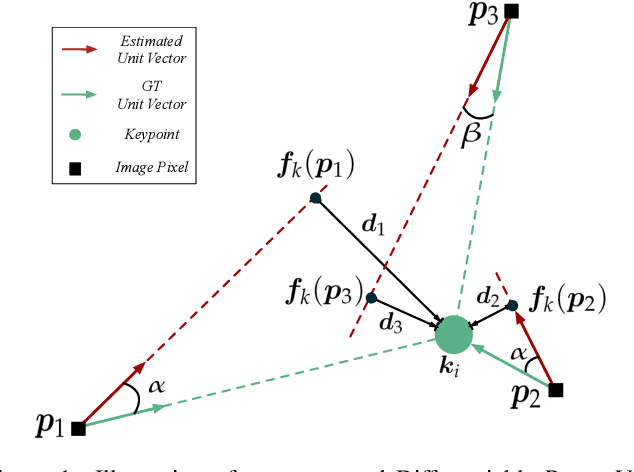
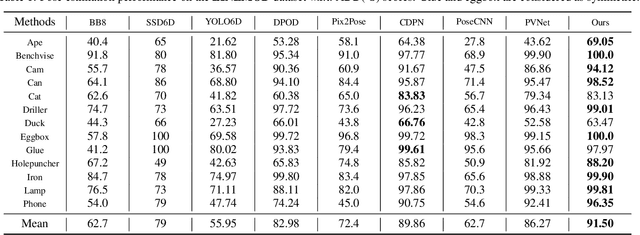
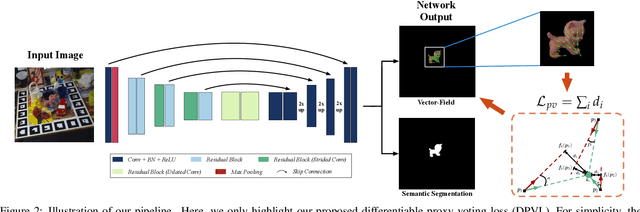
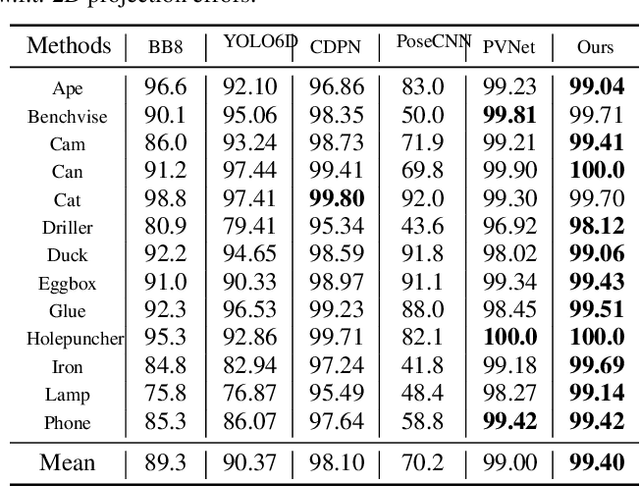
Estimating a 6DOF object pose from a single image is very challenging due to occlusions or textureless appearances. Vector-field based keypoint voting has demonstrated its effectiveness and superiority on tackling those issues. However, direct regression of vector-fields neglects that the distances between pixels and keypoints also affect the deviations of hypotheses dramatically. In other words, small errors in direction vectors may generate severely deviated hypotheses when pixels are far away from a keypoint. In this paper, we aim to reduce such errors by incorporating the distances between pixels and keypoints into our objective. To this end, we develop a simple yet effective differentiable proxy voting loss (DPVL) which mimics the hypothesis selection in the voting procedure. By exploiting our voting loss, we are able to train our network in an end-to-end manner. Experiments on widely used datasets, i.e. LINEMOD and Occlusion LINEMOD, manifest that our DPVL improves pose estimation performance significantly and speeds up the training convergence.
Improving Image Clustering using Sparse Text and the Wisdom of the Crowds
May 08, 2014

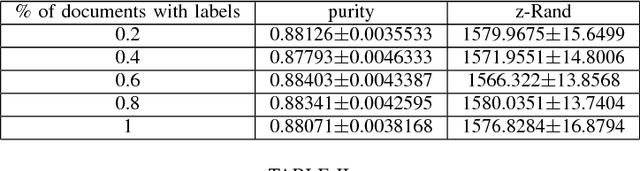
We propose a method to improve image clustering using sparse text and the wisdom of the crowds. In particular, we present a method to fuse two different kinds of document features, image and text features, and use a common dictionary or "wisdom of the crowds" as the connection between the two different kinds of documents. With the proposed fusion matrix, we use topic modeling via non-negative matrix factorization to cluster documents.
Get Rid of Suspended Animation Problem: Deep Diffusive Neural Network on Graph Semi-Supervised Classification
Jan 22, 2020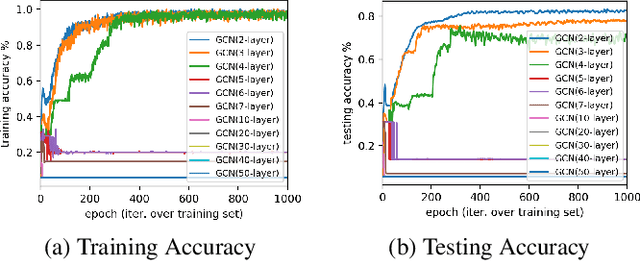
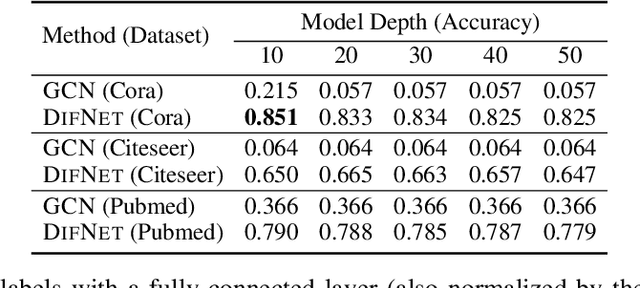
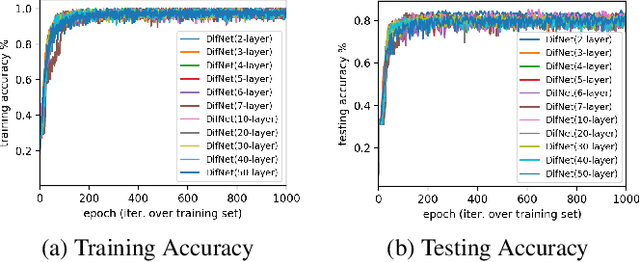
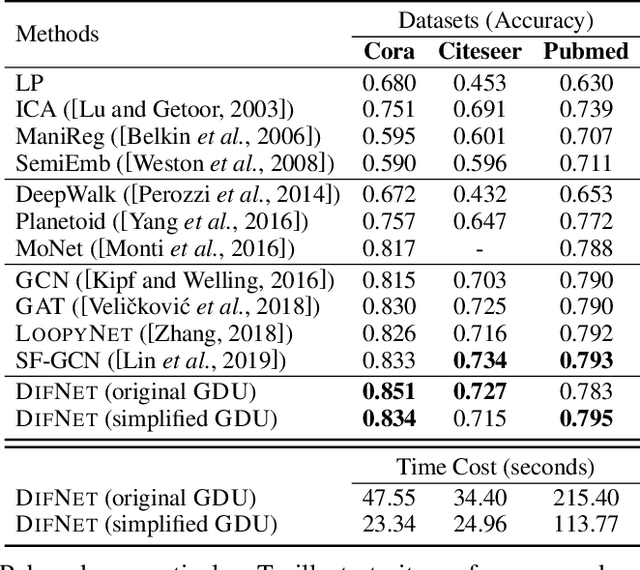
Existing graph neural networks may suffer from the "suspended animation problem" when the model architecture goes deep. Meanwhile, for some graph learning scenarios, e.g., nodes with text/image attributes or graphs with long-distance node correlations, deep graph neural networks will be necessary for effective graph representation learning. In this paper, we propose a new graph neural network, namely DIFNET (Graph Diffusive Neural Network), for graph representation learning and node classification. DIFNET utilizes both neural gates and graph residual learning for node hidden state modeling, and includes an attention mechanism for node neighborhood information diffusion. Extensive experiments will be done in this paper to compare DIFNET against several state-of-the-art graph neural network models. The experimental results can illustrate both the learning performance advantages and effectiveness of DIFNET, especially in addressing the "suspended animation problem".
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Feb 10, 2020
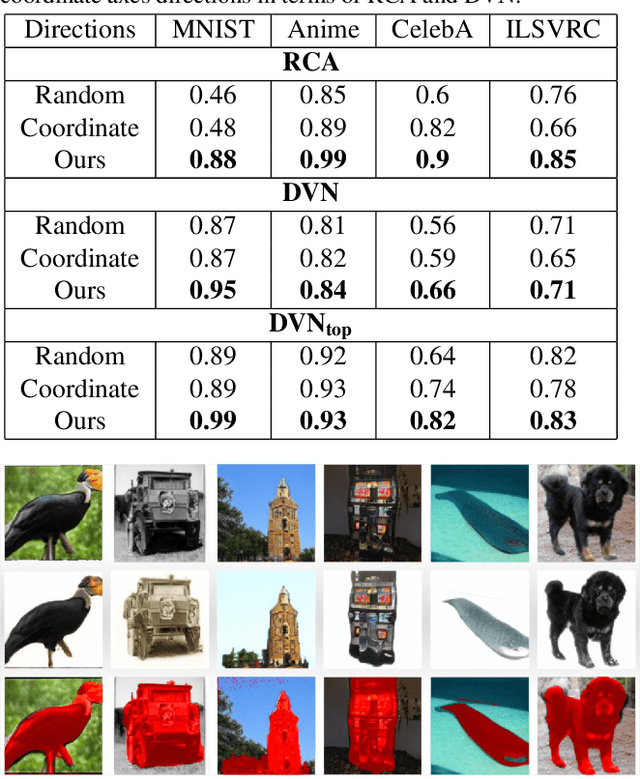


The latent spaces of typical GAN models often have semantically meaningful directions. Moving in these directions corresponds to human-interpretable image transformations, such as zooming or recoloring, enabling a more controllable generation process. However, the discovery of such directions is currently performed in a supervised manner, requiring human labels, pretrained models, or some form of self-supervision. These requirements can severely limit a range of directions existing approaches can discover. In this paper, we introduce an unsupervised method to identify interpretable directions in the latent space of a pretrained GAN model. By a simple model-agnostic procedure, we find directions corresponding to sensible semantic manipulations without any form of (self-)supervision. Furthermore, we reveal several non-trivial findings, which would be difficult to obtain by existing methods, e.g., a direction corresponding to background removal. As an immediate practical benefit of our work, we show how to exploit this finding to achieve a new state-of-the-art for the problem of saliency detection.
Improving Learning Effectiveness For Object Detection and Classification in Cluttered Backgrounds
Feb 27, 2020

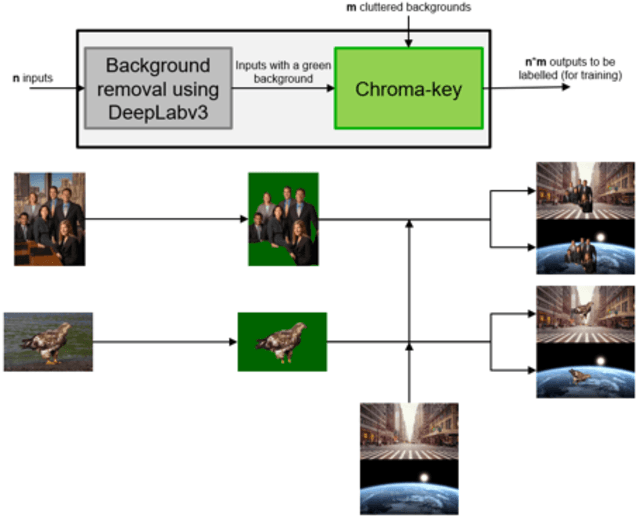
Usually, Neural Networks models are trained with a large dataset of images in homogeneous backgrounds. The issue is that the performance of the network models trained could be significantly degraded in a complex and heterogeneous environment. To mitigate the issue, this paper develops a framework that permits to autonomously generate a training dataset in heterogeneous cluttered backgrounds. It is clear that the learning effectiveness of the proposed framework should be improved in complex and heterogeneous environments, compared with the ones with the typical dataset. In our framework, a state-of-the-art image segmentation technique called DeepLab is used to extract objects of interest from a picture and Chroma-key technique is then used to merge the extracted objects of interest into specific heterogeneous backgrounds. The performance of the proposed framework is investigated through empirical tests and compared with that of the model trained with the COCO dataset. The results show that the proposed framework outperforms the model compared. This implies that the learning effectiveness of the framework developed is superior to the models with the typical dataset.
Federated Generative Adversarial Learning
May 24, 2020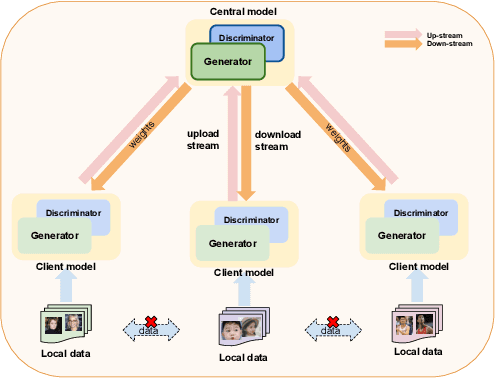
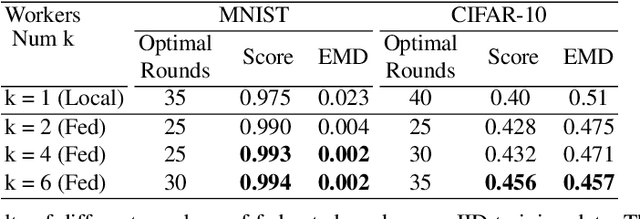
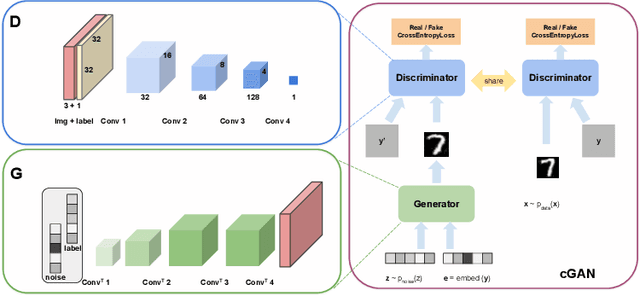
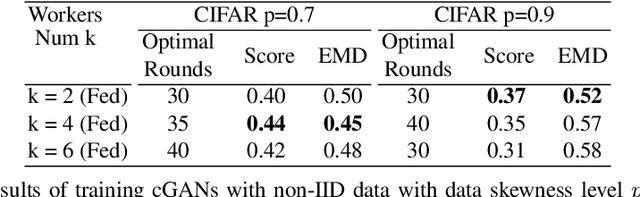
This work studies training generative adversarial networks under the federated learning setting. Generative adversarial networks (GANs) have achieved advancement in various real-world applications, such as image editing, style transfer, scene generations, etc. However, like other deep learning models, GANs are also suffering from data limitation problems in real cases. To boost the performance of GANs in target tasks, collecting images as many as possible from different sources becomes not only important but also essential. For example, to build a robust and accurate bio-metric verification system, huge amounts of images might be collected from surveillance cameras, and/or uploaded from cellphones by users accepting agreements. In an ideal case, utilize all those data uploaded from public and private devices for model training is straightforward. Unfortunately, in the real scenarios, this is hard due to a few reasons. At first, some data face the serious concern of leakage, and therefore it is prohibitive to upload them to a third-party server for model training; at second, the images collected by different kinds of devices, probably have distinctive biases due to various factors, $\textit{e.g.}$, collector preferences, geo-location differences, which is also known as "domain shift". To handle those problems, we propose a novel generative learning scheme utilizing a federated learning framework. Following the configuration of federated learning, we conduct model training and aggregation on one center and a group of clients. Specifically, our method learns the distributed generative models in clients, while the models trained in each client are fused into one unified and versatile model in the center. We perform extensive experiments to compare different federation strategies, and empirically examine the effectiveness of federation under different levels of parallelism and data skewness.
TGGLines: A Robust Topological Graph Guided Line Segment Detector for Low Quality Binary Images
Feb 27, 2020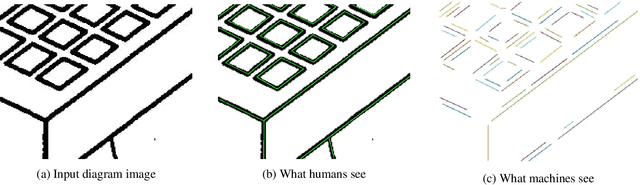
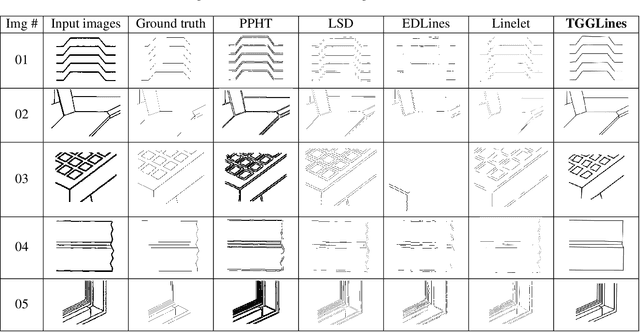

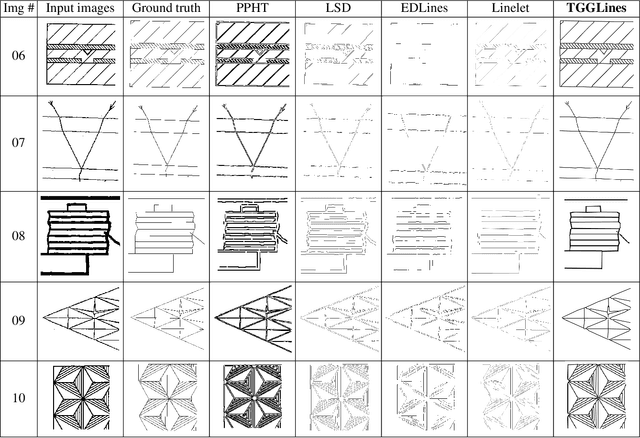
Line segment detection is an essential task in computer vision and image analysis, as it is the critical foundation for advanced tasks such as shape modeling and road lane line detection for autonomous driving. We present a robust topological graph guided approach for line segment detection in low quality binary images (hence, we call it TGGLines). Due to the graph-guided approach, TGGLines not only detects line segments, but also organizes the segments with a line segment connectivity graph, which means the topological relationships (e.g., intersection, an isolated line segment) of the detected line segments are captured and stored; whereas other line detectors only retain a collection of loose line segments. Our empirical results show that the TGGLines detector visually and quantitatively outperforms state-of-the-art line segment detection methods. In addition, our TGGLines approach has the following two competitive advantages: (1) our method only requires one parameter and it is adaptive, whereas almost all other line segment detection methods require multiple (non-adaptive) parameters, and (2) the line segments detected by TGGLines are organized by a line segment connectivity graph.