 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predicting Actions to Help Predict Translations
Aug 18, 2019

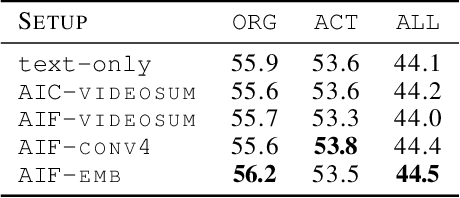


We address the task of text translation on the How2 dataset using a state of the art transformer-based multimodal approach. The question we ask ourselves is whether visual features can support the translation process, in particular, given that this is a dataset extracted from videos, we focus on the translation of actions, which we believe are poorly captured in current static image-text datasets currently used for multimodal translation. For that purpose, we extract different types of action features from the videos and carefully investigate how helpful this visual information is by testing whether it can increase translation quality when used in conjunction with (i) the original text and (ii) the original text where action-related words (or all verbs) are masked out. The latter is a simulation that helps us assess the utility of the image in cases where the text does not provide enough context about the action, or in the presence of noise in the input text.
Towards Multi-pose Guided Virtual Try-on Network
Feb 28, 2019
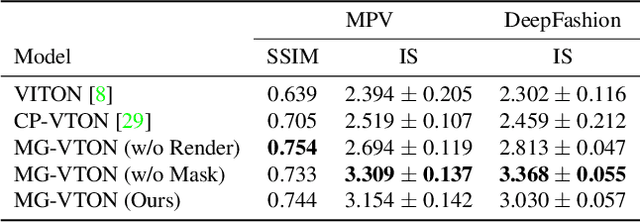
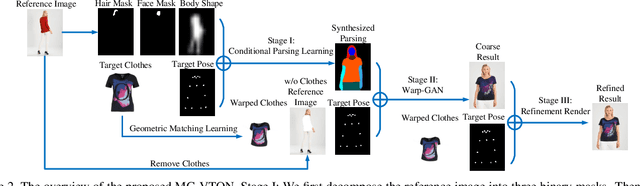

Virtual try-on system under arbitrary human poses has huge application potential, yet raises quite a lot of challenges, e.g. self-occlusions, heavy misalignment among diverse poses, and diverse clothes textures. Existing methods aim at fitting new clothes into a person can only transfer clothes on the fixed human pose, but still show unsatisfactory performances which often fail to preserve the identity, lose the texture details, and decrease the diversity of poses. In this paper, we make the first attempt towards multi-pose guided virtual try-on system, which enables transfer clothes on a person image under diverse poses. Given an input person image, a desired clothes image, and a desired pose, the proposed Multi-pose Guided Virtual Try-on Network (MG-VTON) can generate a new person image after fitting the desired clothes into the input image and manipulating human poses. Our MG-VTON is constructed in three stages: 1) a desired human parsing map of the target image is synthesized to match both the desired pose and the desired clothes shape; 2) a deep Warping Generative Adversarial Network (Warp-GAN) warps the desired clothes appearance into the synthesized human parsing map and alleviates the misalignment problem between the input human pose and desired human pose; 3) a refinement render utilizing multi-pose composition masks recovers the texture details of clothes and removes some artifacts. Extensive experiments on well-known datasets and our newly collected largest virtual try-on benchmark demonstrate that our MG-VTON significantly outperforms all state-of-the-art methods both qualitatively and quantitatively with promising multi-pose virtual try-on performances.
A New Technique of Camera Calibration: A Geometric Approach Based on Principal Lines
Aug 18, 2019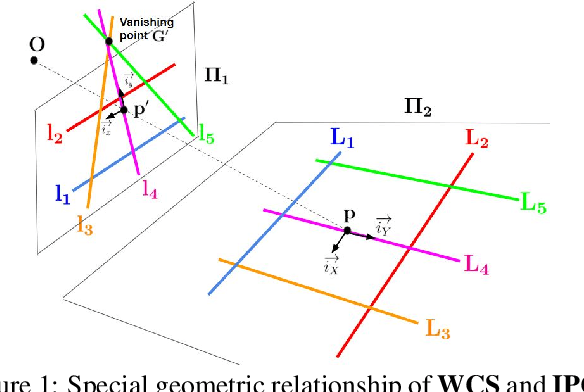
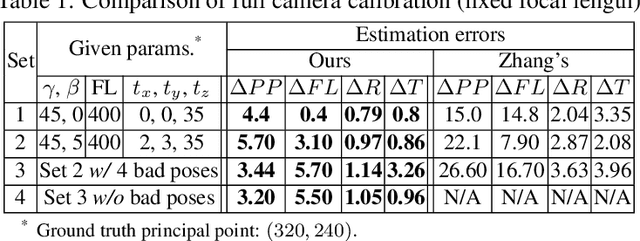
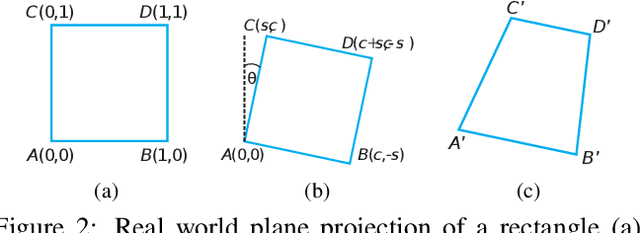
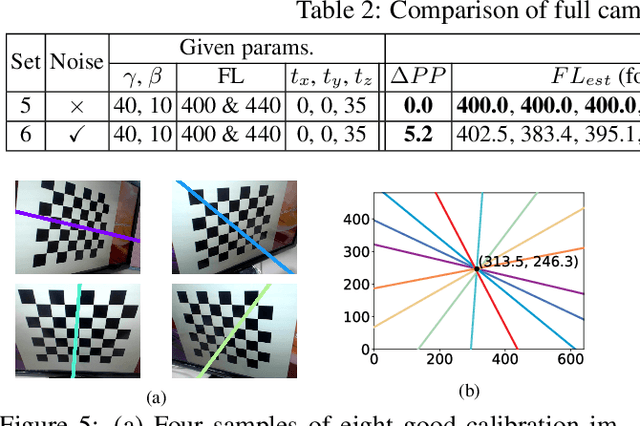
Camera calibration is a crucial prerequisite in many applications of computer vision. In this paper, a new, geometry-based camera calibration technique is proposed, which resolves two main issues associated with the widely used Zhang's method: (i) the lack of guidelines to avoid outliers in the computation and (ii) the assumption of fixed camera focal length. The proposed approach is based on the closed-form solution of principal lines (PLs), with their intersection being the principal point while each PL can concisely represent relative orientation/position (up to one degree of freedom for both) between a special pair of coordinate systems of image plane and calibration pattern. With such analytically tractable image features, computations associated with the calibration are greatly simplified, while the guidelines in (i) can be established intuitively. Experimental results for synthetic and real data show that the proposed approach does compare favorably with Zhang's method, in terms of correctness, robustness, and flexibility, and addresses issues (i) and (ii) satisfactorily.
Incremental Learning Techniques for Semantic Segmentation
Aug 08, 2019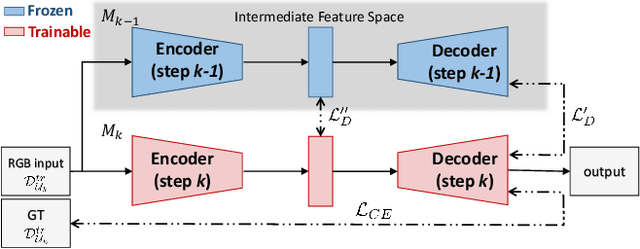
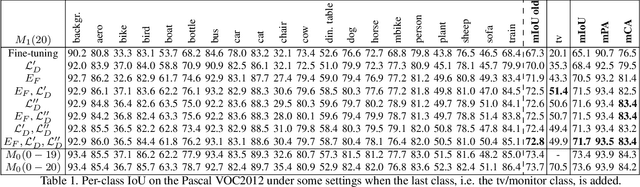
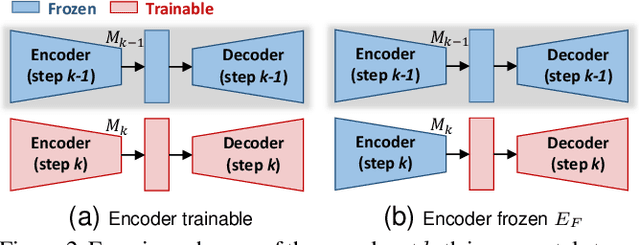
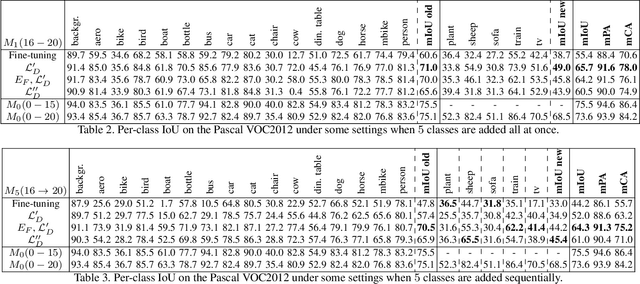
Deep learning architectures exhibit a critical drop of performance due to catastrophic forgetting when they are required to incrementally learn new tasks. Contemporary incremental learning frameworks focus on image classification and object detection while in this work we formally introduce the incremental learning problem for semantic segmentation in which a pixel-wise labeling is considered. To tackle this task we propose to distill the knowledge of the previous model to retain the information about previously learned classes, whilst updating the current model to learn the new ones. We propose various approaches working both on the output logits and on intermediate features. In opposition to some recent frameworks, we do not store any image from previously learned classes and only the last model is needed to preserve high accuracy on these classes. The experimental evaluation on the Pascal VOC2012 dataset shows the effectiveness of the proposed approaches.
* 8 pages, 3 figures, 4 tables
Regularizing activations in neural networks via distribution matching with the Wasserstein metric
Feb 13, 2020
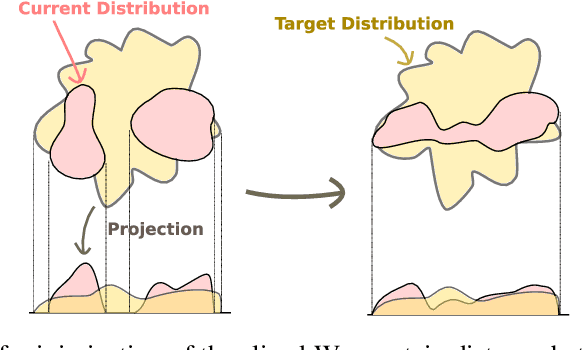

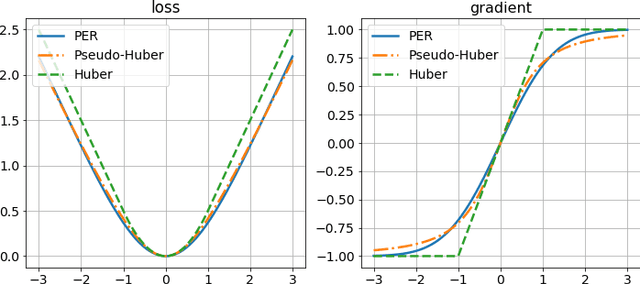
Regularization and normalization have become indispensable components in training deep neural networks, resulting in faster training and improved generalization performance. We propose the projected error function regularization loss (PER) that encourages activations to follow the standard normal distribution. PER randomly projects activations onto one-dimensional space and computes the regularization loss in the projected space. PER is similar to the Pseudo-Huber loss in the projected space, thus taking advantage of both $L^1$ and $L^2$ regularization losses. Besides, PER can capture the interaction between hidden units by projection vector drawn from a unit sphere. By doing so, PER minimizes the upper bound of the Wasserstein distance of order one between an empirical distribution of activations and the standard normal distribution. To the best of the authors' knowledge, this is the first work to regularize activations via distribution matching in the probability distribution space. We evaluate the proposed method on the image classification task and the word-level language modeling task.
UniformAugment: A Search-free Probabilistic Data Augmentation Approach
Mar 31, 2020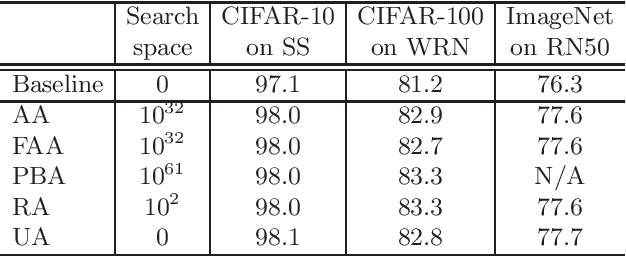
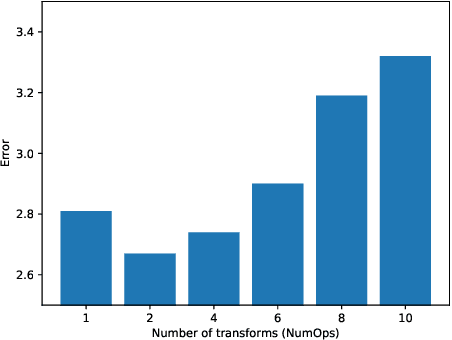
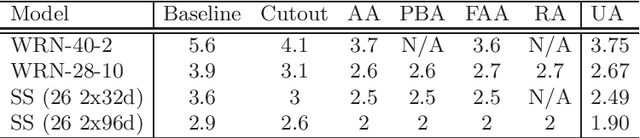

Augmenting training datasets has been shown to improve the learning effectiveness for several computer vision tasks. A good augmentation produces an augmented dataset that adds variability while retaining the statistical properties of the original dataset. Some techniques, such as AutoAugment and Fast AutoAugment, have introduced a search phase to find a set of suitable augmentation policies for a given model and dataset. This comes at the cost of great computational overhead, adding up to several thousand GPU hours. More recently RandAugment was proposed to substantially speedup the search phase by approximating the search space by a couple of hyperparameters, but still incurring non-negligible cost for tuning those. In this paper we show that, under the assumption that the augmentation space is approximately distribution invariant, a uniform sampling over the continuous space of augmentation transformations is sufficient to train highly effective models. Based on that result we propose UniformAugment, an automated data augmentation approach that completely avoids a search phase. In addition to discussing the theoretical underpinning supporting our approach, we also use the standard datasets, as well as established models for image classification, to show that UniformAugment's effectiveness is comparable to the aforementioned methods, while still being highly efficient by virtue of not requiring any search.
CMRNet: Camera to LiDAR-Map Registration
Jul 17, 2019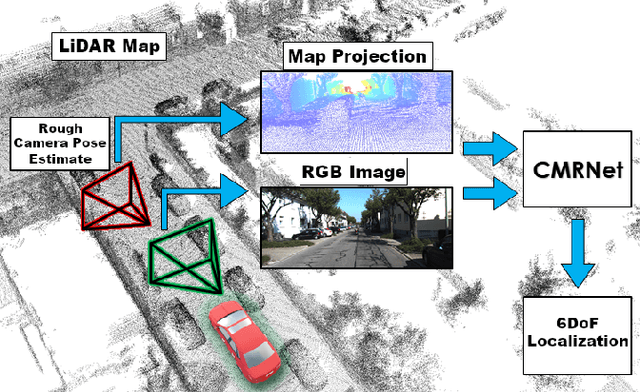


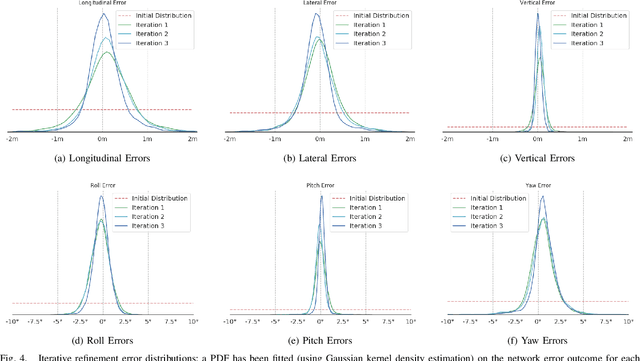
In this paper we present CMRNet, a realtime approach based on a Convolutional Neural Network to localize an RGB image of a scene in a map built from LiDAR data. Our network is not trained in the working area, i.e. CMRNet does not learn the map. Instead it learns to match an image to the map. We validate our approach on the KITTI dataset, processing each frame independently without any tracking procedure. CMRNet achieves 0.27m and 1.07deg median localization accuracy on the sequence 00 of the odometry dataset, starting from a rough pose estimate displaced up to 3.5m and 17deg. To the best of our knowledge this is the first CNN-based approach that learns to match images from a monocular camera to a given, preexisting 3D LiDAR-map.
A Unified View of Label Shift Estimation
Mar 17, 2020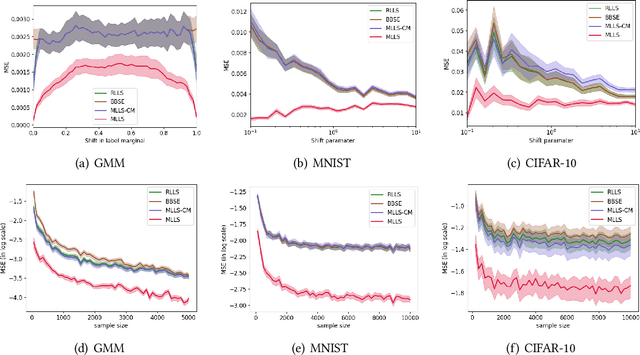
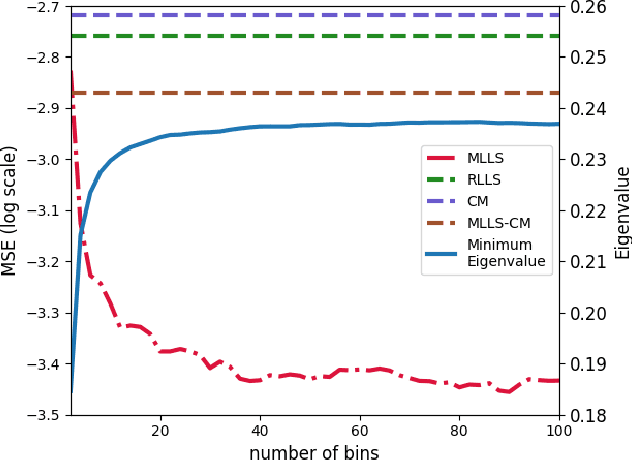
Label shift describes the setting where although the label distribution might change between the source and target domains, the class-conditional probabilities (of data given a label) do not. There are two dominant approaches for estimating the label marginal. BBSE, a moment-matching approach based on confusion matrices, is provably consistent and provides interpretable error bounds. However, a maximum likelihood estimation approach, which we call MLLS, dominates empirically. In this paper, we present a unified view of the two methods and the first theoretical characterization of the likelihood-based estimator. Our contributions include (i) conditions for consistency of MLLS, which include calibration of the classifier and a confusion matrix invertibility condition that BBSE also requires; (ii) a unified view of the methods, casting the confusion matrix as roughly equivalent to MLLS for a particular choice of calibration method; and (iii) a decomposition of MLLS's finite-sample error into terms reflecting the impacts of miscalibration and estimation error. Our analysis attributes BBSE's statistical inefficiency to a loss of information due to coarse calibration. We support our findings with experiments on both synthetic data and the MNIST and CIFAR10 image recognition datasets.
State-of-the-Art in Retinal Optical Coherence Tomography Image Analysis
Nov 17, 2014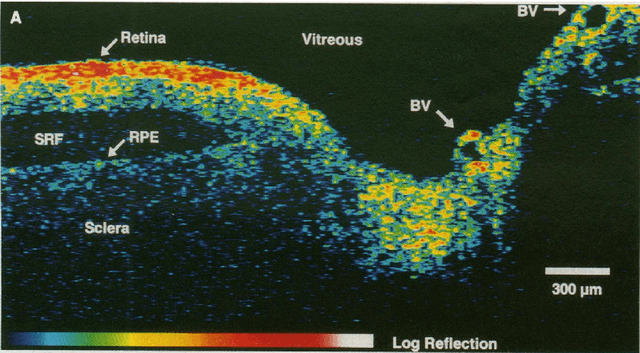
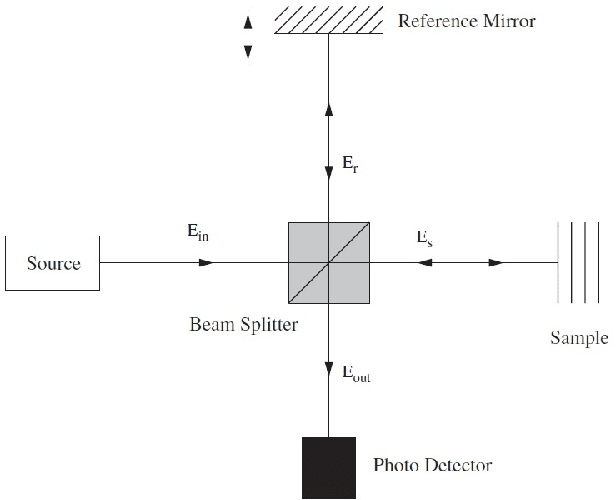

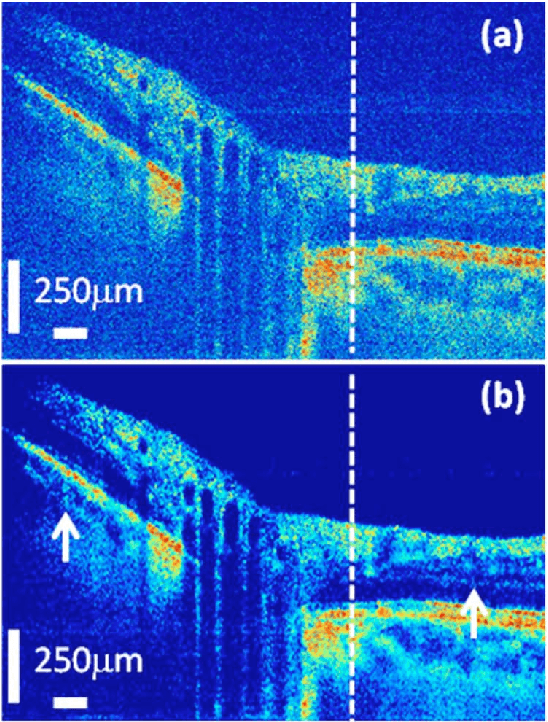
Optical Coherence Tomography (OCT) is one of the most emerging imaging modalities that has been used widely in the field of biomedical imaging. From its emergence in 1990's, plenty of hardware and software improvements have been made. Its applications range from ophthalmology to dermatology to coronary imaging etc. Here, the focus is on applications of OCT in ophthalmology and retinal imaging. OCT is able to non-invasively produce cross-sectional volume images of the tissues which are further used for analysis of the tissue structure and its properties. Due to the underlying physics, OCT images usually suffer from a granular pattern, called speckle noise, which restricts the process of interpretation, hence requiring specialized noise reduction techniques to remove the noise while preserving image details. Also, given the fact that OCT images are in the $\mu m$ -level, further analysis in needed to distinguish between the different structures in the imaged volume. Therefore the use of different segmentation techniques are of high importance. The movement of the tissue under imaging or the progression of disease in the tissue also imposes further implications both on the quality and the proper interpretation of the acquired images. Thus, use of image registration techniques can be very helpful. In this work, an overview of such image analysis techniques will be given.
KPNet: Towards Minimal Face Detector
Mar 17, 2020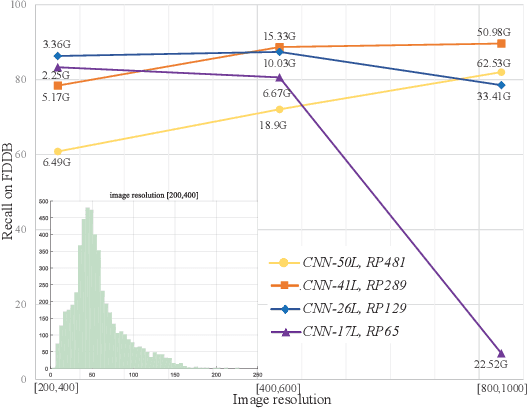

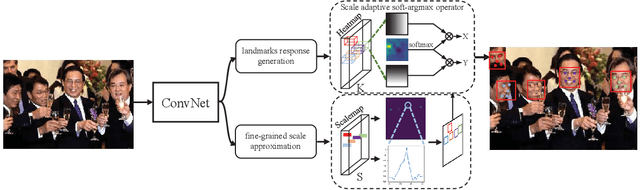
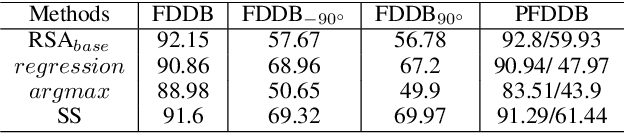
The small receptive field and capacity of minimal neural networks limit their performance when using them to be the backbone of detectors. In this work, we find that the appearance feature of a generic face is discriminative enough for a tiny and shallow neural network to verify from the background. And the essential barriers behind us are 1) the vague definition of the face bounding box and 2) tricky design of anchor-boxes or receptive field. Unlike most top-down methods for joint face detection and alignment, the proposed KPNet detects small facial keypoints instead of the whole face by in a bottom-up manner. It first predicts the facial landmarks from a low-resolution image via the well-designed fine-grained scale approximation and scale adaptive soft-argmax operator. Finally, the precise face bounding boxes, no matter how we define it, can be inferred from the keypoints. Without any complex head architecture or meticulous network designing, the KPNet achieves state-of-the-art accuracy on generic face detection and alignment benchmarks with only $\sim1M$ parameters, which runs at 1000fps on GPU and is easy to perform real-time on most modern front-end chips.