 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A New Randomness Evaluation Method with Applications to Image Shuffling and Encryption
Nov 07, 2012
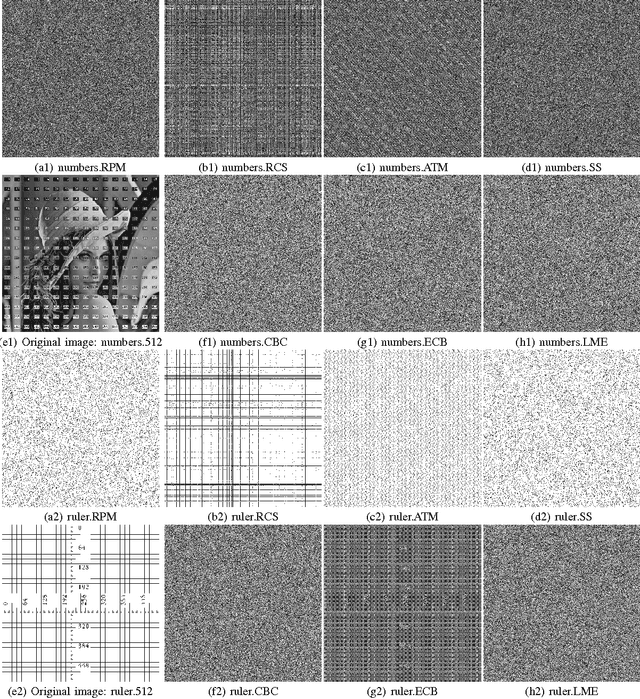
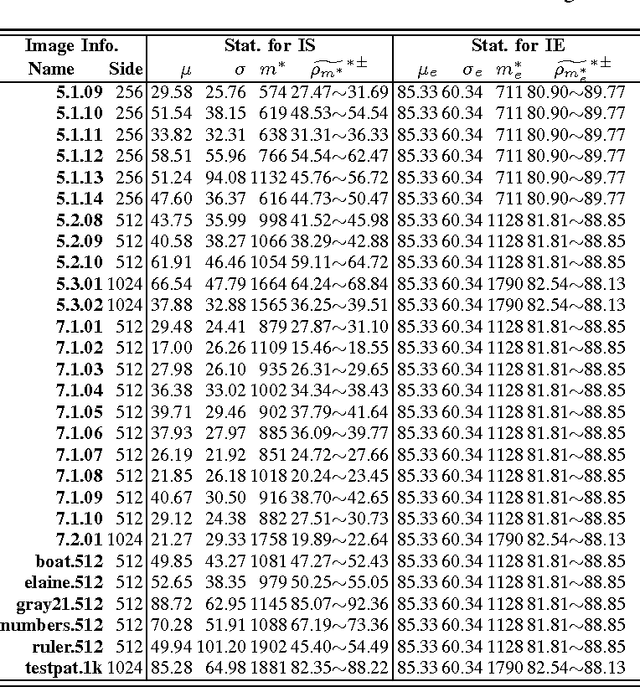
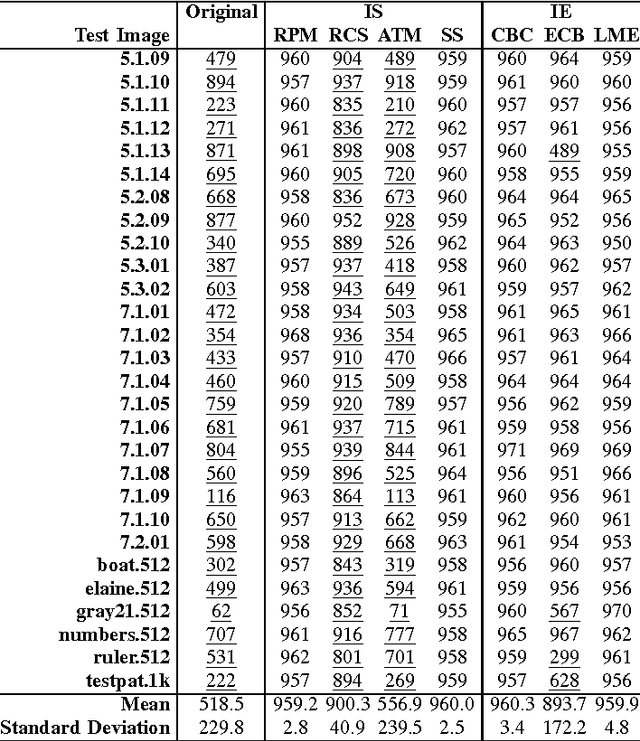
This letter discusses the problem of testing the degree of randomness within an image, particularly for a shuffled or encrypted image. Its key contributions are: 1) a mathematical model of perfectly shuffled images; 2) the derivation of the theoretical distribution of pixel differences; 3) a new $Z$-test based approach to differentiate whether or not a test image is perfectly shuffled; and 4) a randomized algorithm to unbiasedly evaluate the degree of randomness within a given image. Simulation results show that the proposed method is robust and effective in evaluating the degree of randomness within an image, and may often be more suitable for image applications than commonly used testing schemes designed for binary data like NIST 800-22. The developed method may be also useful as a first step in determining whether or not a shuffling or encryption scheme is suitable for a particular cryptographic application.
Meat adulteration detection through digital image analysis of histological cuts using LBP
Nov 07, 2016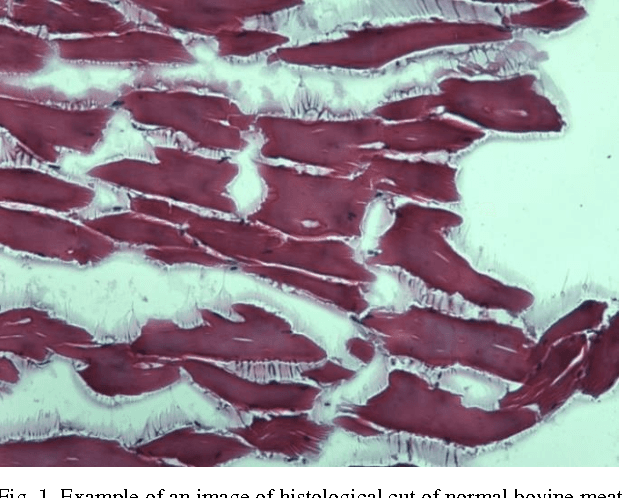
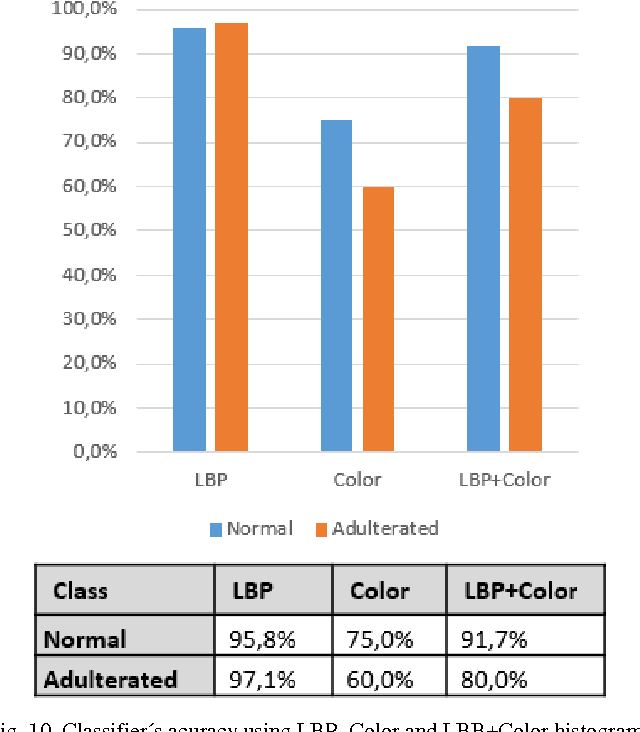
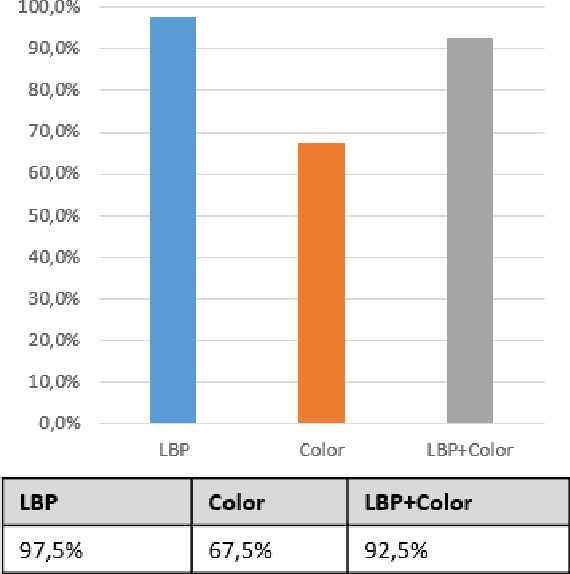
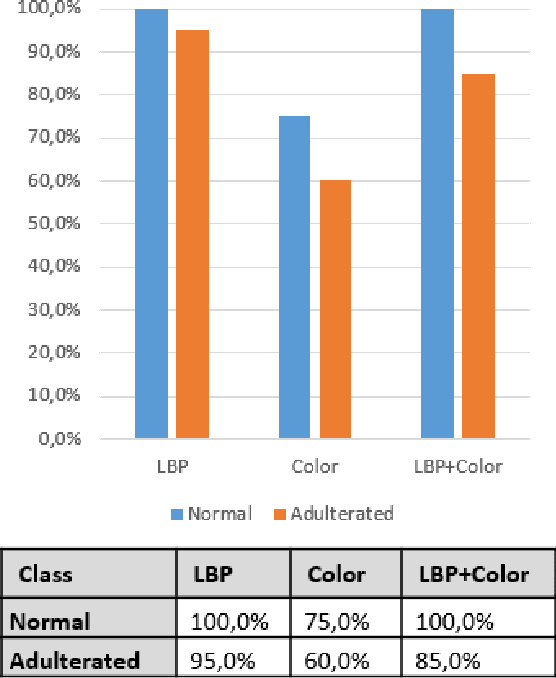
Food fraud has been an area of great concern due to its risk to public health, reduction of food quality or nutritional value and for its economic consequences. For this reason, it's been object of regulation in many countries (e.g. [1], [2]). One type of food that has been frequently object of fraud through the addition of water or an aqueous solution is bovine meat. The traditional methods used to detect this kind of fraud are expensive, time-consuming and depend on physicochemical analysis that require complex laboratory techniques, specific for each added substance. In this paper, based on digital images of histological cuts of adulterated and not-adulterated (normal) bovine meat, we evaluate the of digital image analysis methods to identify the aforementioned kind of fraud, with focus on the Local Binary Pattern (LBP) algorithm.
On the String Kernel Pre-Image Problem with Applications in Drug Discovery
Dec 04, 2014The pre-image problem has to be solved during inference by most structured output predictors. For string kernels, this problem corresponds to finding the string associated to a given input. An algorithm capable of solving or finding good approximations to this problem would have many applications in computational biology and other fields. This work uses a recent result on combinatorial optimization of linear predictors based on string kernels to develop, for the pre-image, a low complexity upper bound valid for many string kernels. This upper bound is used with success in a branch and bound searching algorithm. Applications and results in the discovery of druggable peptides are presented and discussed.
Image Super-Resolution via Dual-Dictionary Learning And Sparse Representation
Aug 18, 2012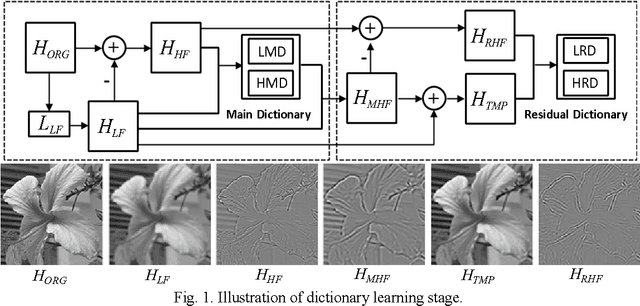
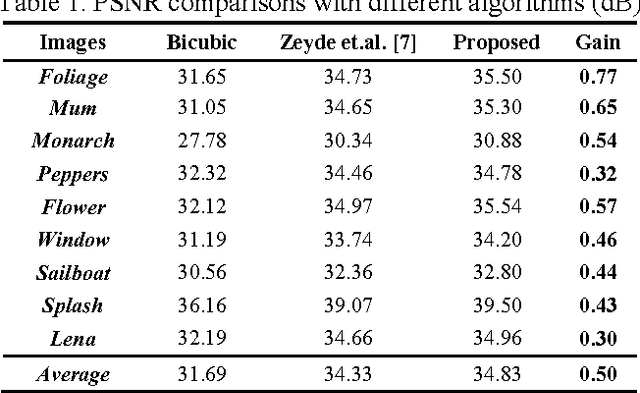
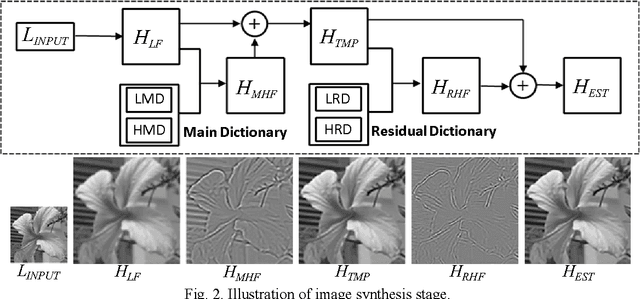
Learning-based image super-resolution aims to reconstruct high-frequency (HF) details from the prior model trained by a set of high- and low-resolution image patches. In this paper, HF to be estimated is considered as a combination of two components: main high-frequency (MHF) and residual high-frequency (RHF), and we propose a novel image super-resolution method via dual-dictionary learning and sparse representation, which consists of the main dictionary learning and the residual dictionary learning, to recover MHF and RHF respectively. Extensive experimental results on test images validate that by employing the proposed two-layer progressive scheme, more image details can be recovered and much better results can be achieved than the state-of-the-art algorithms in terms of both PSNR and visual perception.
Reduced Dilation-Erosion Perceptron for Binary Classification
Apr 14, 2020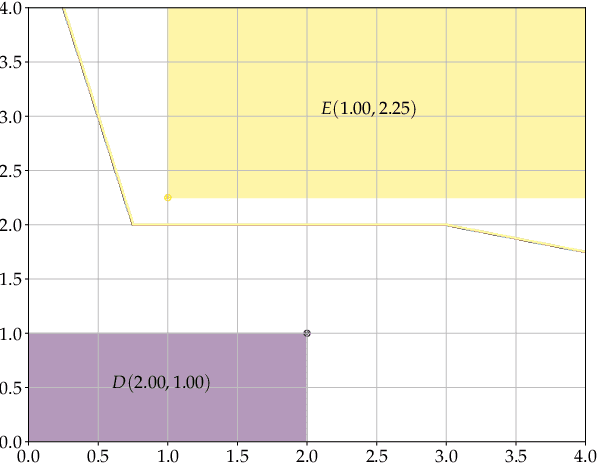
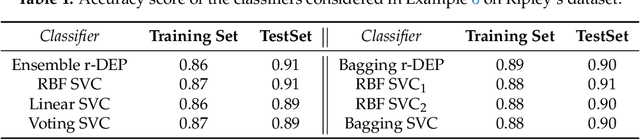
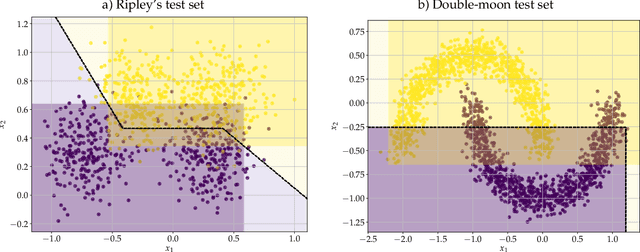

Dilation and erosion are two elementary operations from mathematical morphology, a non-linear lattice computing methodology widely used for image processing and analysis. The dilation-erosion perceptron (DEP) is a morphological neural network obtained by a convex combination of a dilation and an erosion followed by the application of a hard-limiter function for binary classification tasks. A DEP classifier can be trained using a convex-concave procedure along with the minimization of the hinge loss function. As a lattice computing model, the DEP classifier assumes the feature and class spaces are partially ordered sets. In many practical situations, however, there is no natural ordering for the feature patterns. Using concepts from multi-valued mathematical morphology, this paper introduces the reduced dilation-erosion (r-DEP) classifier. An r-DEP classifier is obtained by endowing the feature space with an appropriate reduced ordering. Such reduced ordering can be determined using two approaches: One based on an ensemble of support vector classifiers (SVCs) with different kernels and the other based on a bagging of similar SVCs trained using different samples of the training set. Using several binary classification datasets from the OpenML repository, the ensemble and bagging r-DEP classifiers yielded in mean higher balanced accuracy scores than the linear, polynomial, and radial basis function (RBF) SVCs as well as their ensemble and a bagging of RBF SVCs.
Fisher Vectors Derived from Hybrid Gaussian-Laplacian Mixture Models for Image Annotation
Jan 24, 2015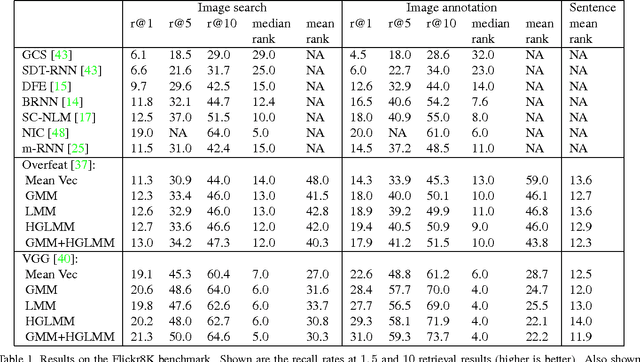

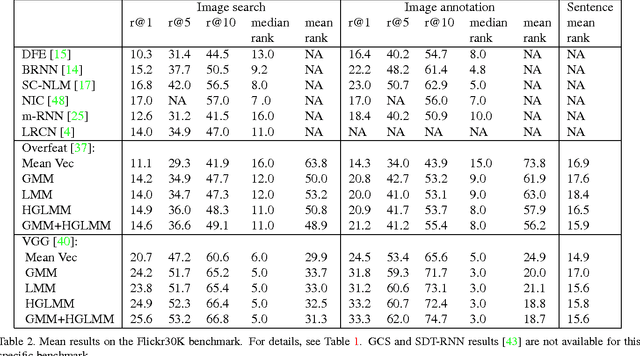
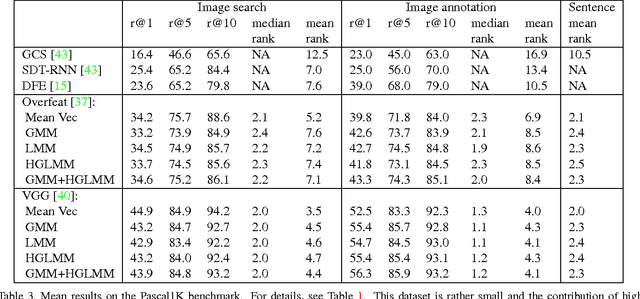
In the traditional object recognition pipeline, descriptors are densely sampled over an image, pooled into a high dimensional non-linear representation and then passed to a classifier. In recent years, Fisher Vectors have proven empirically to be the leading representation for a large variety of applications. The Fisher Vector is typically taken as the gradients of the log-likelihood of descriptors, with respect to the parameters of a Gaussian Mixture Model (GMM). Motivated by the assumption that different distributions should be applied for different datasets, we present two other Mixture Models and derive their Expectation-Maximization and Fisher Vector expressions. The first is a Laplacian Mixture Model (LMM), which is based on the Laplacian distribution. The second Mixture Model presented is a Hybrid Gaussian-Laplacian Mixture Model (HGLMM) which is based on a weighted geometric mean of the Gaussian and Laplacian distribution. An interesting property of the Expectation-Maximization algorithm for the latter is that in the maximization step, each dimension in each component is chosen to be either a Gaussian or a Laplacian. Finally, by using the new Fisher Vectors derived from HGLMMs, we achieve state-of-the-art results for both the image annotation and the image search by a sentence tasks.
Neural Mesh Refiner for 6-DoF Pose Estimation
Mar 18, 2020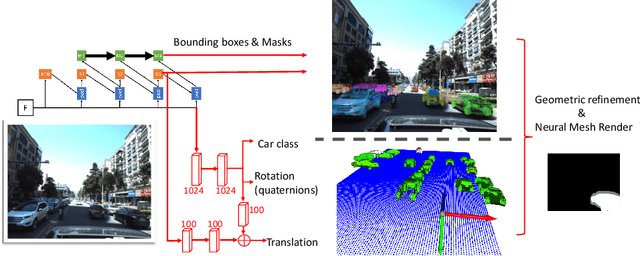
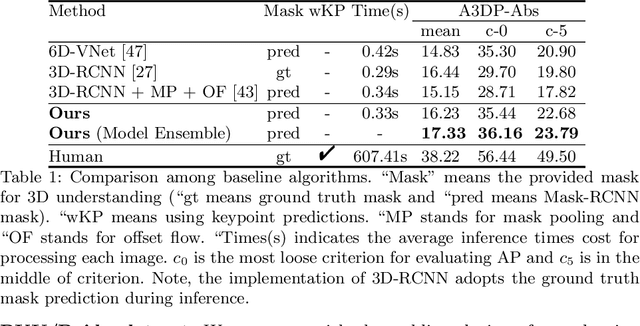
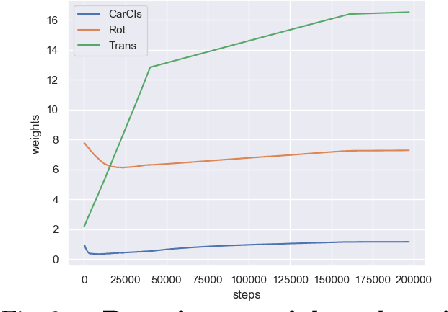
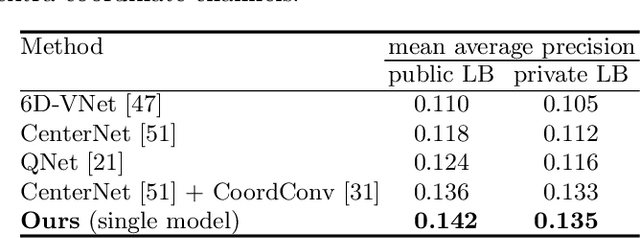
How can we effectively utilise the 2D monocular image information for recovering the 6D pose (6-DoF) of the visual objects? Deep learning has shown to be effective for robust and real-time monocular pose estimation. Oftentimes, the network learns to regress the 6-DoF pose using a naive loss function. However, due to a lack of geometrical scene understanding from the directly regressed pose estimation, there are misalignments between the rendered mesh from the 3D object and the 2D instance segmentation result, e.g., bounding boxes and masks prediction. This paper bridges the gap between 2D mask generation and 3D location prediction via a differentiable neural mesh renderer. We utilise the overlay between the accurate mask prediction and less accurate mesh prediction to iteratively optimise the direct regressed 6D pose information with a focus on translation estimation. By leveraging geometry, we demonstrate that our technique significantly improves direct regression performance on the difficult task of translation estimation and achieve the state of the art results on Peking University/Baidu - Autonomous Driving dataset and the ApolloScape 3D Car Instance dataset. The code can be found at \url{https://bit.ly/2IRihfU}.
Learning to Match Templates for Unseen Instance Detection
Nov 26, 2019



Detecting objects in images is a quintessential problem in computer vision. Much of the focus in the literature has been on the problem of identifying the bounding box of a particular type of objects in an image. Yet, in many contexts such as robotics and augmented reality, it is more important to find a specific object instance---a unique toy or a custom industrial part for example---rather than a generic object class. Here, applications can require a rapid shift from one object instance to another, thus requiring fast turnaround which affords little-to-no training time. In this context, we propose a method for detecting objects that are unknown at training time. Our approach frames the problem as one of learned template matching, where a network is trained to match the template of an object in an image. The template is obtained by rendering a textured 3D model of the object. At test time, we provide a novel 3D object, and the network is able to successfully detect it, even under significant occlusion. Our method offers an improvement of almost 30 mAP over the previous template matching methods on the challenging Occluded Linemod (overall mAP of 50.7). With no access to the objects at training time, our method still yields detection results that are on par with existing ones that are allowed to train on the objects. By reviving this research direction in the context of more powerful, deep feature extractors, our work sets the stage for more development in the area of unseen object instance detection.
Machine Vision for Improved Human-Robot Cooperation in Adverse Underwater Conditions
Oct 29, 2019
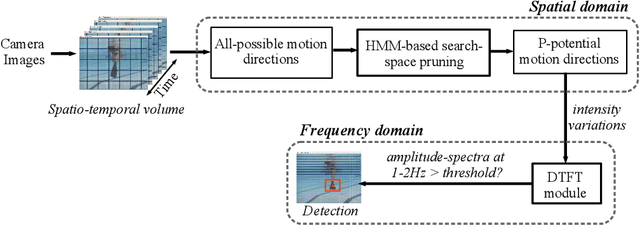
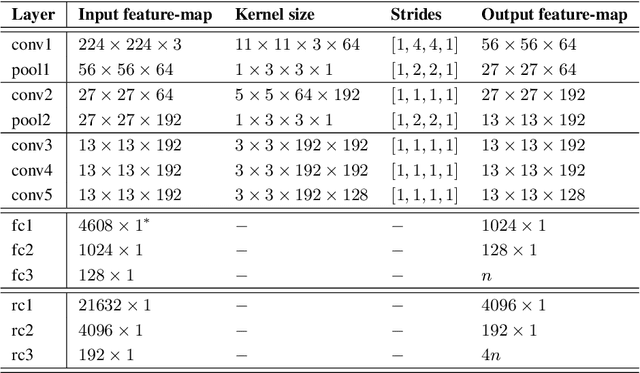
Visually-guided underwater robots are widely used in numerous autonomous exploration and surveillance applications alongside humans for cooperative task execution. However, underwater visual perception is challenging due to marine artifacts such as poor visibility, lighting variation, scattering, etc. Additionally, chromatic distortions and scarcity of salient visual features make it harder for an underwater robot to visually interpret its surroundings to effectively assist its companion diver during an underwater mission. In this paper, we delineate our attempts to address these challenges by designing novel and improved vision-based solutions. Specifically, we present robust methodologies for autonomous diver following, human-robot communication, automatic image enhancement, and image super-resolution. We depict their algorithmic details and describe relevant design choices to meet the real-time operating constraints on single-board embedded machines. Moreover, through extensive simulation and field experiments, we demonstrate how an autonomous robot can exploit these solutions to understand human motion and hand gesture-based instructions even in adverse visual conditions. As an immediate next step, we want to focus on relative pose estimation and visual attention modeling of an underwater robot based on its companion humans' body-pose and temporal activity recognition. We believe that these autonomous capabilities will facilitate a faster and better interpretation of visual scenes and enable more effective underwater human-robot cooperation.
Child Face Age-Progression via Deep Feature Aging
Mar 17, 2020


Given a gallery of face images of missing children, state-of-the-art face recognition systems fall short in identifying a child (probe) recovered at a later age. We propose a feature aging module that can age-progress deep face features output by a face matcher. In addition, the feature aging module guides age-progression in the image space such that synthesized aged faces can be utilized to enhance longitudinal face recognition performance of any face matcher without requiring any explicit training. For time lapses larger than 10 years (the missing child is found after 10 or more years), the proposed age-progression module improves the closed-set identification accuracy of FaceNet from 16.53% to 21.44% and CosFace from 60.72% to 66.12% on a child celebrity dataset, namely ITWCC. The proposed method also outperforms state-of-the-art approaches with a rank-1 identification rate of 95.91%, compared to 94.91%, on a public aging dataset, FG-NET, and 99.58%, compared to 99.50%, on CACD-VS. These results suggest that aging face features enhances the ability to identify young children who are possible victims of child trafficking or abduction.