 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Multi-pose Guided Virtual Try-on Network
Feb 28, 2019

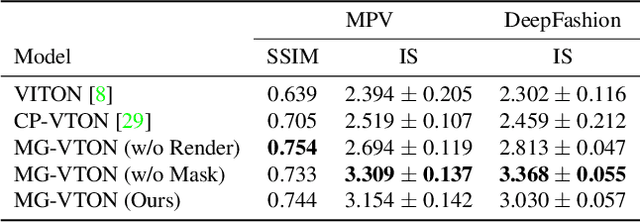
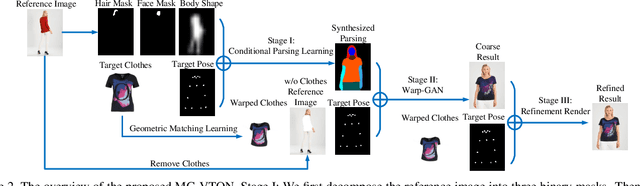

Virtual try-on system under arbitrary human poses has huge application potential, yet raises quite a lot of challenges, e.g. self-occlusions, heavy misalignment among diverse poses, and diverse clothes textures. Existing methods aim at fitting new clothes into a person can only transfer clothes on the fixed human pose, but still show unsatisfactory performances which often fail to preserve the identity, lose the texture details, and decrease the diversity of poses. In this paper, we make the first attempt towards multi-pose guided virtual try-on system, which enables transfer clothes on a person image under diverse poses. Given an input person image, a desired clothes image, and a desired pose, the proposed Multi-pose Guided Virtual Try-on Network (MG-VTON) can generate a new person image after fitting the desired clothes into the input image and manipulating human poses. Our MG-VTON is constructed in three stages: 1) a desired human parsing map of the target image is synthesized to match both the desired pose and the desired clothes shape; 2) a deep Warping Generative Adversarial Network (Warp-GAN) warps the desired clothes appearance into the synthesized human parsing map and alleviates the misalignment problem between the input human pose and desired human pose; 3) a refinement render utilizing multi-pose composition masks recovers the texture details of clothes and removes some artifacts. Extensive experiments on well-known datasets and our newly collected largest virtual try-on benchmark demonstrate that our MG-VTON significantly outperforms all state-of-the-art methods both qualitatively and quantitatively with promising multi-pose virtual try-on performances.
A deep learning-based framework for segmenting invisible clinical target volumes with estimated uncertainties for post-operative prostate cancer radiotherapy
Apr 28, 2020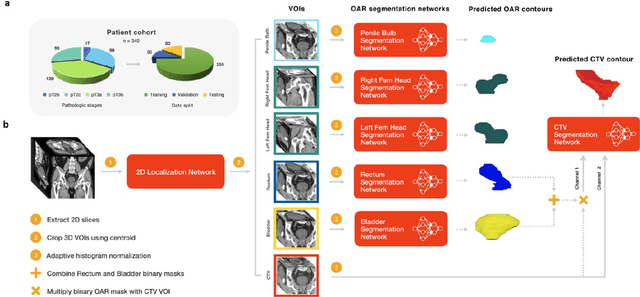
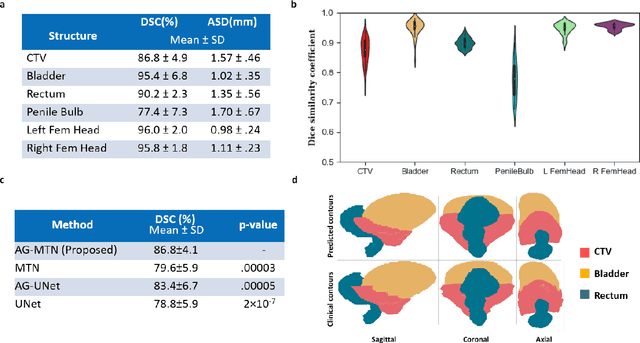
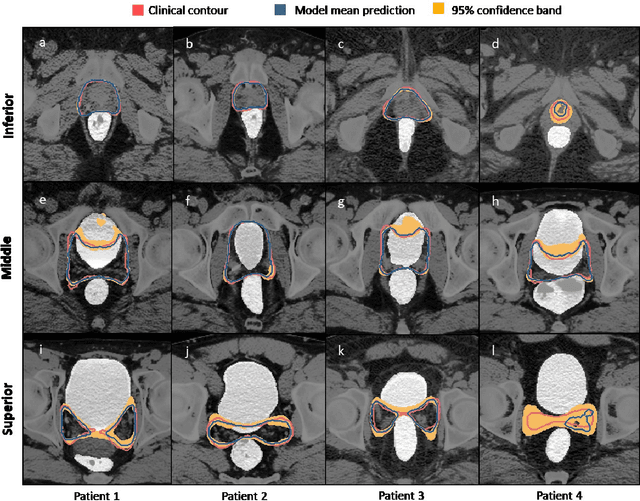
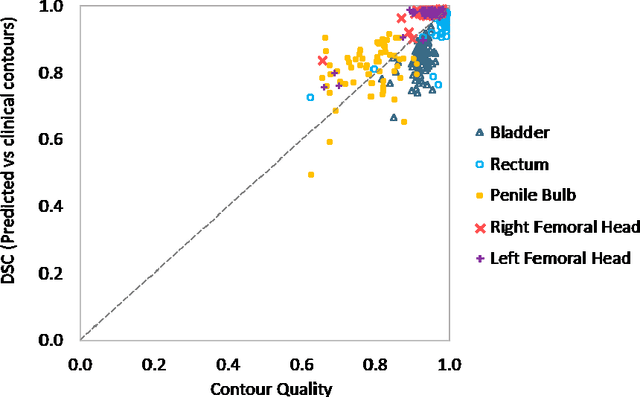
In post-operative radiotherapy for prostate cancer, the cancerous prostate gland has been surgically removed, so the clinical target volume (CTV) to be irradiated encompasses the microscopic spread of tumor cells, which cannot be visualized in typical clinical images such as computed tomography or magnetic resonance imaging. In current clinical practice, physicians segment CTVs manually based on their relationship with nearby organs and other clinical information, per clinical guidelines. Automating post-operative prostate CTV segmentation with traditional image segmentation methods has been a major challenge. Here, we propose a deep learning model to overcome this problem by segmenting nearby organs first, then using their relationship with the CTV to assist CTV segmentation. The model proposed is trained using labels clinically approved and used for patient treatment, which are subject to relatively large inter-physician variations due to the absence of a visual ground truth. The model achieves an average Dice similarity coefficient (DSC) of 0.87 on a holdout dataset of 50 patients, much better than established methods, such as atlas-based methods (DSC<0.7). The uncertainties associated with automatically segmented CTV contours are also estimated to help physicians inspect and revise the contours, especially in areas with large inter-physician variations. We also use a 4-point grading system to show that the clinical quality of the automatically segmented CTV contours is equal to that of approved clinical contours manually drawn by physicians.
Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
Apr 02, 2020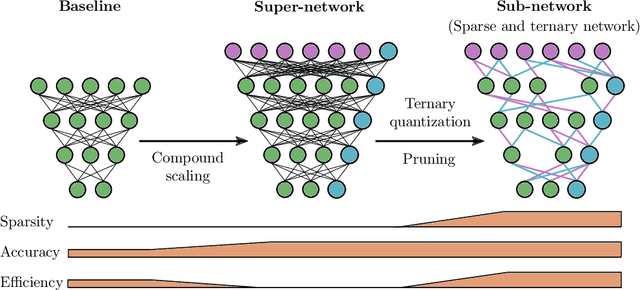
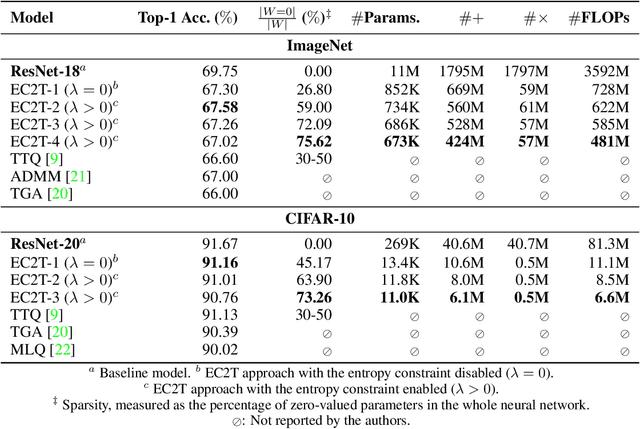
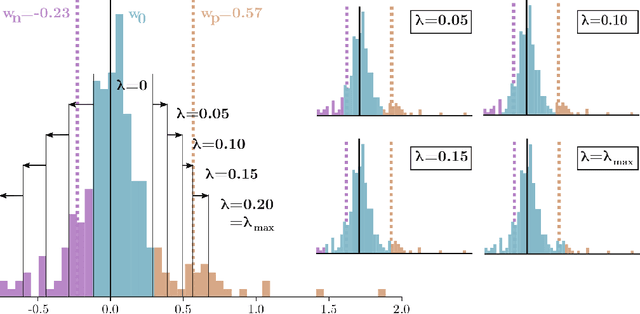
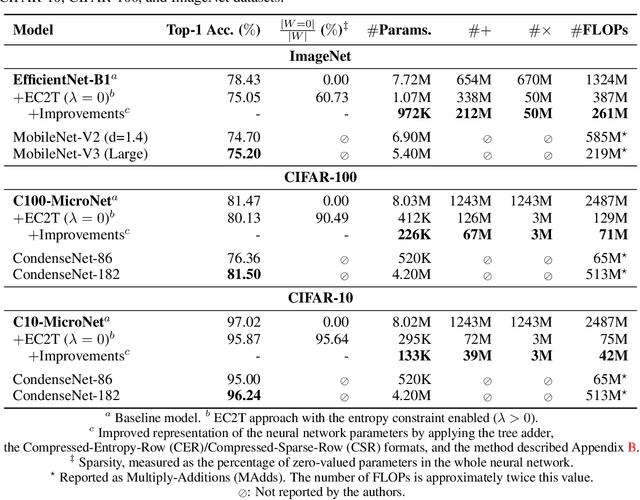
Deep neural networks (DNN) have shown remarkable success in a variety of machine learning applications. The capacity of these models (i.e., number of parameters), endows them with expressive power and allows them to reach the desired performance. In recent years, there is an increasing interest in deploying DNNs to resource-constrained devices (i.e., mobile devices) with limited energy, memory, and computational budget. To address this problem, we propose Entropy-Constrained Trained Ternarization (EC2T), a general framework to create sparse and ternary neural networks which are efficient in terms of storage (e.g., at most two binary-masks and two full-precision values are required to save a weight matrix) and computation (e.g., MAC operations are reduced to a few accumulations plus two multiplications). This approach consists of two steps. First, a super-network is created by scaling the dimensions of a pre-trained model (i.e., its width and depth). Subsequently, this super-network is simultaneously pruned (using an entropy constraint) and quantized (that is, ternary values are assigned layer-wise) in a training process, resulting in a sparse and ternary network representation. We validate the proposed approach in CIFAR-10, CIFAR-100, and ImageNet datasets, showing its effectiveness in image classification tasks.
The Skincare project, an interactive deep learning system for differential diagnosis of malignant skin lesions. Technical Report
May 19, 2020

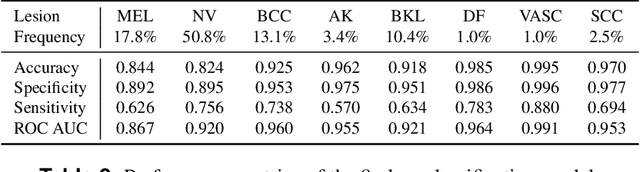
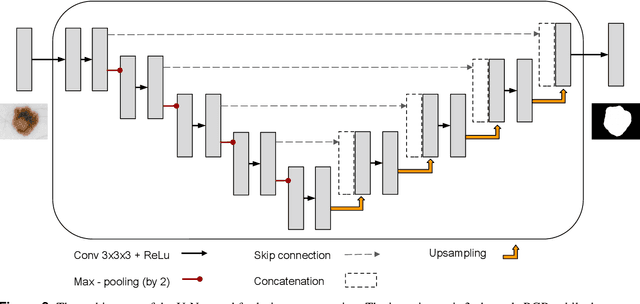
A shortage of dermatologists causes long wait times for patients who seek dermatologic care. In addition, the diagnostic accuracy of general practitioners has been reported to be lower than the accuracy of artificial intelligence software. This article describes the Skincare project (H2020, EIT Digital). Contributions include enabling technology for clinical decision support based on interactive machine learning (IML), a reference architecture towards a Digital European Healthcare Infrastructure (also cf. EIT MCPS), technical components for aggregating digitised patient information, and the integration of decision support technology into clinical test-bed environments. However, the main contribution is a diagnostic and decision support system in dermatology for patients and doctors, an interactive deep learning system for differential diagnosis of malignant skin lesions. In this article, we describe its functionalities and the user interfaces to facilitate machine learning from human input. The baseline deep learning system, which delivers state-of-the-art results and the potential to augment general practitioners and even dermatologists, was developed and validated using de-identified cases from a dermatology image data base (ISIC), which has about 20000 cases for development and validation, provided by board-certified dermatologists defining the reference standard for every case. ISIC allows for differential diagnosis, a ranked list of eight diagnoses, that is used to plan treatments in the common setting of diagnostic ambiguity. We give an overall description of the outcome of the Skincare project, and we focus on the steps to support communication and coordination between humans and machine in IML. This is an integral part of the development of future cognitive assistants in the medical domain, and we describe the necessary intelligent user interfaces.
XtarNet: Learning to Extract Task-Adaptive Representation for Incremental Few-Shot Learning
Mar 19, 2020



Learning novel concepts while preserving prior knowledge is a long-standing challenge in machine learning. The challenge gets greater when a novel task is given with only a few labeled examples, a problem known as incremental few-shot learning. We propose XtarNet, which learns to extract task-adaptive representation (TAR) for facilitating incremental few-shot learning. The method utilizes a backbone network pretrained on a set of base categories while also employing additional modules that are meta-trained across episodes. Given a new task, the novel feature extracted from the meta-trained modules is mixed with the base feature obtained from the pretrained model. The process of combining two different features provides TAR and is also controlled by meta-trained modules. The TAR contains effective information for classifying both novel and base categories. The base and novel classifiers quickly adapt to a given task by utilizing the TAR. Experiments on standard image datasets indicate that XtarNet achieves state-of-the-art incremental few-shot learning performance. The concept of TAR can also be used in conjunction with existing incremental few-shot learning methods; extensive simulation results in fact show that applying TAR enhances the known methods significantly.
Face Quality Estimation and Its Correlation to Demographic and Non-Demographic Bias in Face Recognition
Apr 02, 2020
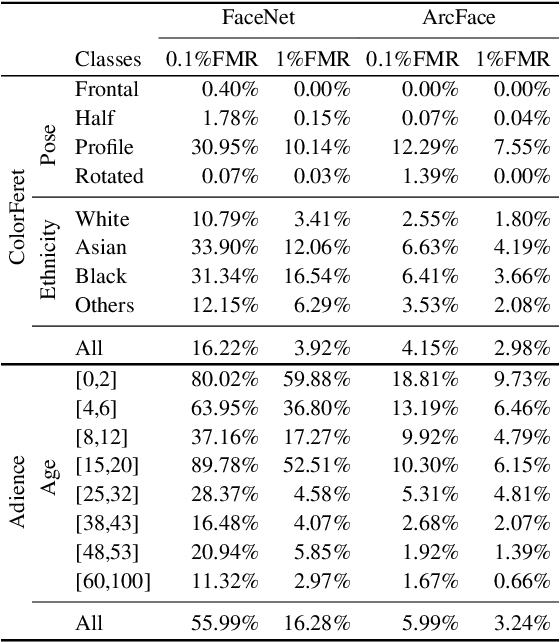
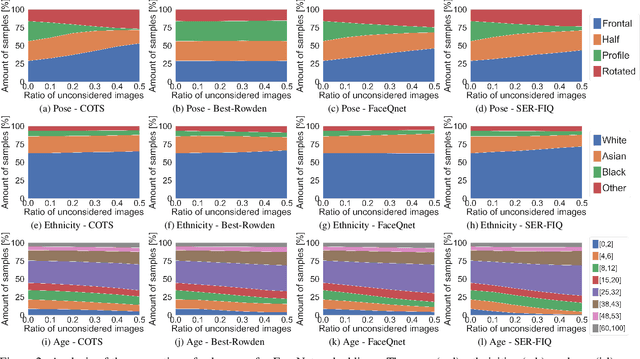
Face quality assessment aims at estimating the utility of a face image for the purpose of recognition. It is a key factor to achieve high face recognition performances. Currently, the high performance of these face recognition systems come with the cost of a strong bias against demographic and non-demographic sub-groups. Recent work has shown that face quality assessment algorithms should adapt to the deployed face recognition system, in order to achieve highly accurate and robust quality estimations. However, this could lead to a bias transfer towards the face quality assessment leading to discriminatory effects e.g. during enrolment. In this work, we present an in-depth analysis of the correlation between bias in face recognition and face quality assessment. Experiments were conducted on two publicly available datasets captured under controlled and uncontrolled circumstances with two popular face embeddings. We evaluated four state-of-the-art solutions for face quality assessment towards biases to pose, ethnicity, and age. The experiments showed that the face quality assessment solutions assign significantly lower quality values towards subgroups affected by the recognition bias demonstrating that these approaches are biased as well. This raises ethical questions towards fairness and discrimination which future works have to address.
Detecting Lane and Road Markings at A Distance with Perspective Transformer Layers
Mar 19, 2020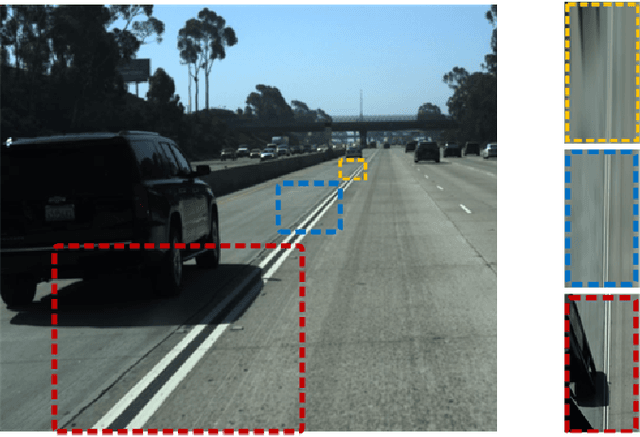

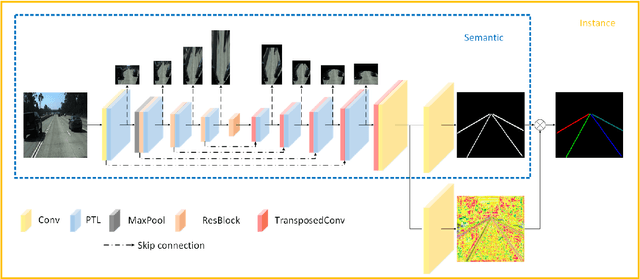
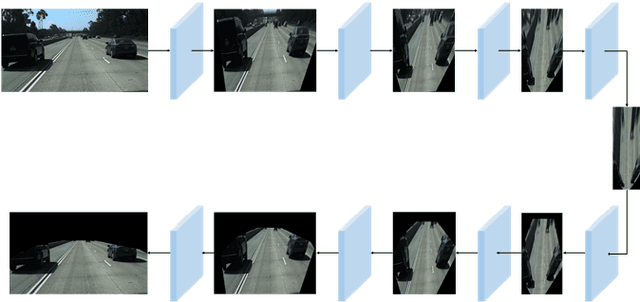
Accurate detection of lane and road markings is a task of great importance for intelligent vehicles. In existing approaches, the detection accuracy often degrades with the increasing distance. This is due to the fact that distant lane and road markings occupy a small number of pixels in the image, and scales of lane and road markings are inconsistent at various distances and perspectives. The Inverse Perspective Mapping (IPM) can be used to eliminate the perspective distortion, but the inherent interpolation can lead to artifacts especially around distant lane and road markings and thus has a negative impact on the accuracy of lane marking detection and segmentation. To solve this problem, we adopt the Encoder-Decoder architecture in Fully Convolutional Networks and leverage the idea of Spatial Transformer Networks to introduce a novel semantic segmentation neural network. This approach decomposes the IPM process into multiple consecutive differentiable homographic transform layers, which are called "Perspective Transformer Layers". Furthermore, the interpolated feature map is refined by subsequent convolutional layers thus reducing the artifacts and improving the accuracy. The effectiveness of the proposed method in lane marking detection is validated on two public datasets: TuSimple and ApolloScape
Learning Furniture Compatibility with Graph Neural Networks
Apr 15, 2020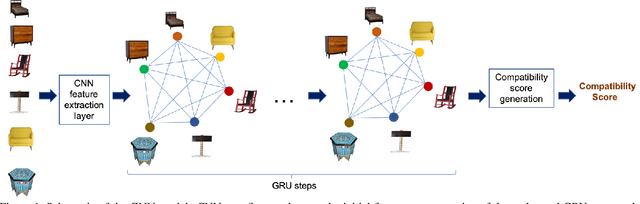
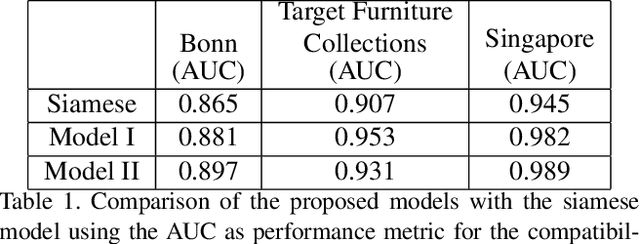

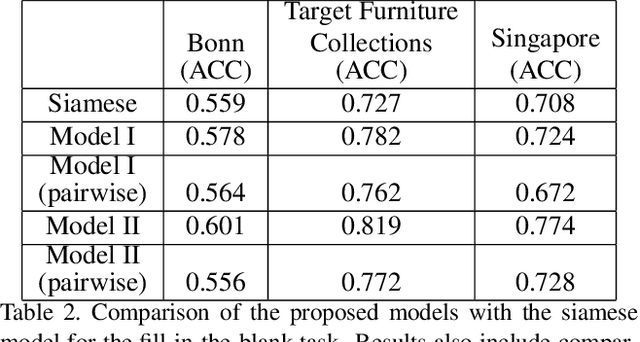
We propose a graph neural network (GNN) approach to the problem of predicting the stylistic compatibility of a set of furniture items from images. While most existing results are based on siamese networks which evaluate pairwise compatibility between items, the proposed GNN architecture exploits relational information among groups of items. We present two GNN models, both of which comprise a deep CNN that extracts a feature representation for each image, a gated recurrent unit (GRU) network that models interactions between the furniture items in a set, and an aggregation function that calculates the compatibility score. In the first model, a generalized contrastive loss function that promotes the generation of clustered embeddings for items belonging to the same furniture set is introduced. Also, in the first model, the edge function between nodes in the GRU and the aggregation function are fixed in order to limit model complexity and allow training on smaller datasets; in the second model, the edge function and aggregation function are learned directly from the data. We demonstrate state-of-the art accuracy for compatibility prediction and "fill in the blank" tasks on the Bonn and Singapore furniture datasets. We further introduce a new dataset, called the Target Furniture Collections dataset, which contains over 6000 furniture items that have been hand-curated by stylists to make up 1632 compatible sets. We also demonstrate superior prediction accuracy on this dataset.
Vector Learning for Cross Domain Representations
Sep 27, 2018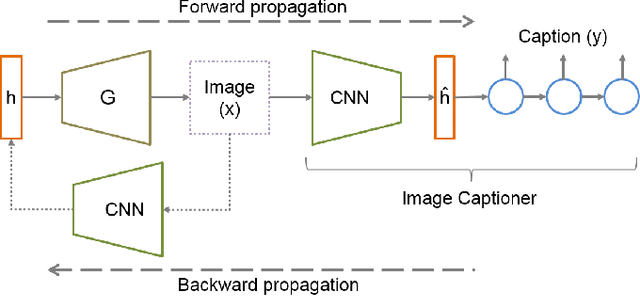
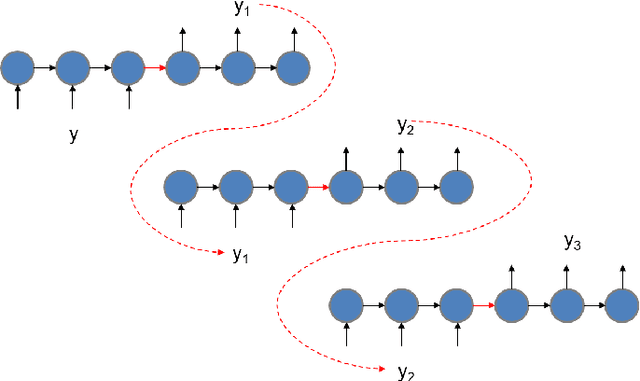


Recently, generative adversarial networks have gained a lot of popularity for image generation tasks. However, such models are associated with complex learning mechanisms and demand very large relevant datasets. This work borrows concepts from image and video captioning models to form an image generative framework. The model is trained in a similar fashion as recurrent captioning model and uses the learned weights for image generation. This is done in an inverse direction, where the input is a caption and the output is an image. The vector representation of the sentence and frames are extracted from an encoder-decoder model which is initially trained on similar sentence and image pairs. Our model conditions image generation on a natural language caption. We leverage a sequence-to-sequence model to generate synthetic captions that have the same meaning for having a robust image generation. One key advantage of our method is that the traditional image captioning datasets can be used for synthetic sentence paraphrases. Results indicate that images generated through multiple captions are better at capturing the semantic meaning of the family of captions.
GEVO: GPU Code Optimization using Evolutionary Computation
Apr 27, 2020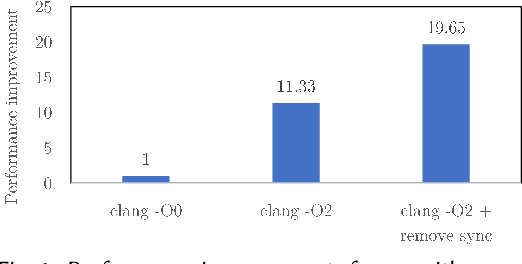
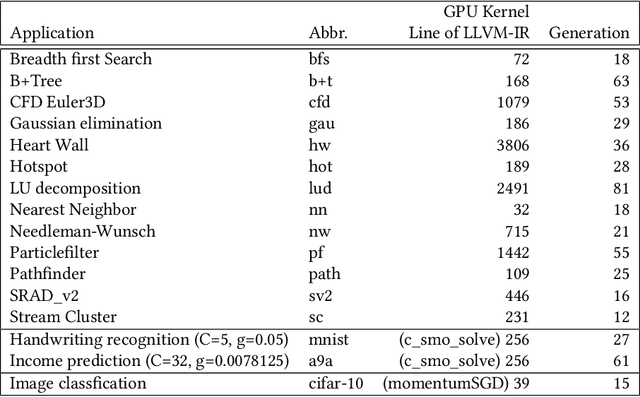
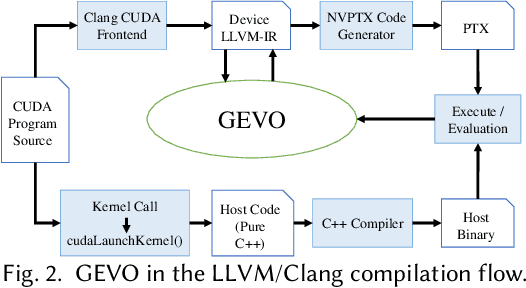
GPUs are a key enabler of the revolution in machine learning and high performance computing, functioning as de facto co-processors to accelerate large-scale computation. As the programming stack and tool support have matured, GPUs have also become accessible to programmers, who may lack detailed knowledge of the underlying architecture and fail to fully leverage the GPU's computation power. GEVO (Gpu optimization using EVOlutionary computation) is a tool for automatically discovering optimization opportunities and tuning the performance of GPU kernels in the LLVM representation. GEVO uses population-based search to find edits to GPU code compiled to LLVM-IR and improves performance on desired criteria while retaining required functionality. We demonstrate that GEVO improves the execution time of the GPU programs in the Rodinia benchmark suite and the machine learning models, SVM and ResNet18, on NVIDIA Tesla P100. For the Rodinia benchmarks, GEVO improves GPU kernel runtime performance by an average of 49.48% and by as much as 412% over the fully compiler-optimized baseline. If kernel output accuracy is relaxed to tolerate up to 1% error, GEVO can find kernel variants that outperform the baseline version by an average of 51.08%. For the machine learning workloads, GEVO achieves kernel performance improvement for SVM on the MNIST handwriting recognition (3.24X) and the a9a income prediction (2.93X) datasets with no loss of model accuracy. GEVO achieves 1.79X kernel performance improvement on image classification using ResNet18/CIFAR-10, with less than 1% model accuracy reduction.