 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pola4All: survey of polarimetric applications and an open-source toolkit to analyze polarization
Dec 22, 2023
Polarization information of the light can provide rich cues for computer vision and scene understanding tasks, such as the type of material, pose, and shape of the objects. With the advent of new and cheap polarimetric sensors, this imaging modality is becoming accessible to a wider public for solving problems such as pose estimation, 3D reconstruction, underwater navigation, and depth estimation. However, we observe several limitations regarding the usage of this sensorial modality, as well as a lack of standards and publicly available tools to analyze polarization images. Furthermore, although polarization camera manufacturers usually provide acquisition tools to interface with their cameras, they rarely include processing algorithms that make use of the polarization information. In this paper, we review recent advances in applications that involve polarization imaging, including a comprehensive survey of recent advances on polarization for vision and robotics perception tasks. We also introduce a complete software toolkit that provides common standards to communicate with and process information from most of the existing micro-grid polarization cameras on the market. The toolkit also implements several image processing algorithms for this modality, and it is publicly available on GitHub: https://github.com/vibot-lab/Pola4all_JEI_2023.
Inclusive normalization of face images to passport format
Dec 22, 2023Face recognition has been used more and more in real world applications in recent years. However, when the skin color bias is coupled with intra-personal variations like harsh illumination, the face recognition task is more likely to fail, even during human inspection. Face normalization methods try to deal with such challenges by removing intra-personal variations from an input image while keeping the identity the same. However, most face normalization methods can only remove one or two variations and ignore dataset biases such as skin color bias. The outputs of many face normalization methods are also not realistic to human observers. In this work, a style based face normalization model (StyleFNM) is proposed to remove most intra-personal variations including large changes in pose, bad or harsh illumination, low resolution, blur, facial expressions, and accessories like sunglasses among others. The dataset bias is also dealt with in this paper by controlling a pretrained GAN to generate a balanced dataset of passport-like images. The experimental results show that StyleFNM can generate more realistic outputs and can improve significantly the accuracy and fairness of face recognition systems.
Multi-modal Latent Space Learning for Chain-of-Thought Reasoning in Language Models
Dec 14, 2023
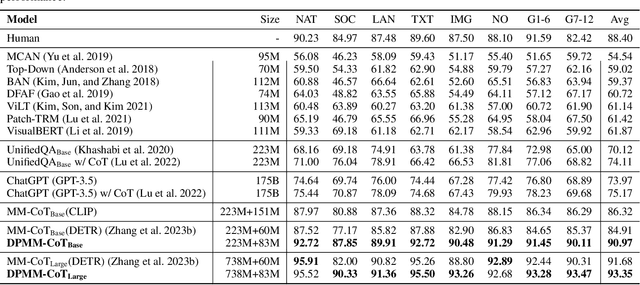
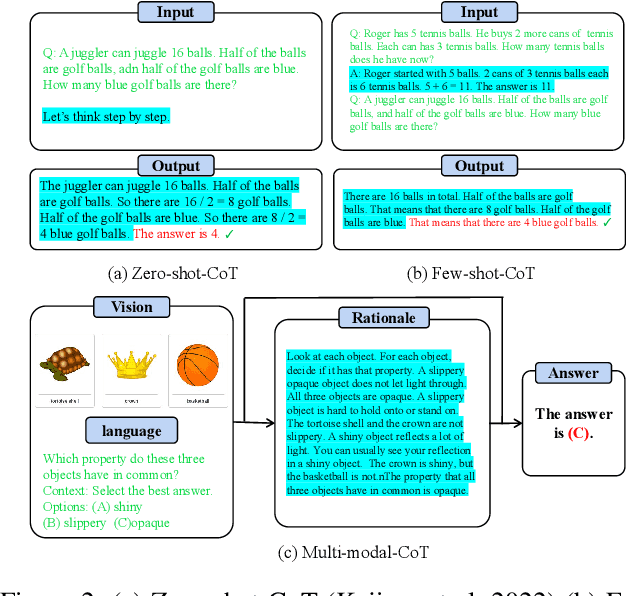
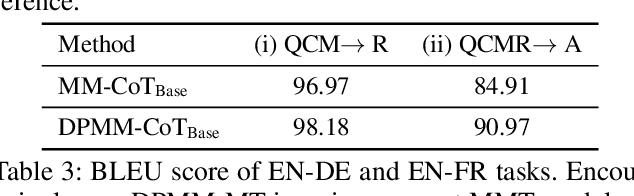
Chain-of-thought (CoT) reasoning has exhibited impressive performance in language models for solving complex tasks and answering questions. However, many real-world questions require multi-modal information, such as text and images. Previous research on multi-modal CoT has primarily focused on extracting fixed image features from off-the-shelf vision models and then fusing them with text using attention mechanisms. This approach has limitations because these vision models were not designed for complex reasoning tasks and do not align well with language thoughts. To overcome this limitation, we introduce a novel approach for multi-modal CoT reasoning that utilizes latent space learning via diffusion processes to generate effective image features that align with language thoughts. Our method fuses image features and text representations at a deep level and improves the complex reasoning ability of multi-modal CoT. We demonstrate the efficacy of our proposed method on multi-modal ScienceQA and machine translation benchmarks, achieving state-of-the-art performance on ScienceQA. Overall, our approach offers a more robust and effective solution for multi-modal reasoning in language models, enhancing their ability to tackle complex real-world problems.
SinSR: Diffusion-Based Image Super-Resolution in a Single Step
Nov 23, 2023
While super-resolution (SR) methods based on diffusion models exhibit promising results, their practical application is hindered by the substantial number of required inference steps. Recent methods utilize degraded images in the initial state, thereby shortening the Markov chain. Nevertheless, these solutions either rely on a precise formulation of the degradation process or still necessitate a relatively lengthy generation path (e.g., 15 iterations). To enhance inference speed, we propose a simple yet effective method for achieving single-step SR generation, named SinSR. Specifically, we first derive a deterministic sampling process from the most recent state-of-the-art (SOTA) method for accelerating diffusion-based SR. This allows the mapping between the input random noise and the generated high-resolution image to be obtained in a reduced and acceptable number of inference steps during training. We show that this deterministic mapping can be distilled into a student model that performs SR within only one inference step. Additionally, we propose a novel consistency-preserving loss to simultaneously leverage the ground-truth image during the distillation process, ensuring that the performance of the student model is not solely bound by the feature manifold of the teacher model, resulting in further performance improvement. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method can achieve comparable or even superior performance compared to both previous SOTA methods and the teacher model, in just one sampling step, resulting in a remarkable up to x10 speedup for inference. Our code will be released at https://github.com/wyf0912/SinSR
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis
Dec 20, 2023In this paper, we introduce Fairy, a minimalist yet robust adaptation of image-editing diffusion models, enhancing them for video editing applications. Our approach centers on the concept of anchor-based cross-frame attention, a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis. Fairy not only addresses limitations of previous models, including memory and processing speed. It also improves temporal consistency through a unique data augmentation strategy. This strategy renders the model equivariant to affine transformations in both source and target images. Remarkably efficient, Fairy generates 120-frame 512x384 videos (4-second duration at 30 FPS) in just 14 seconds, outpacing prior works by at least 44x. A comprehensive user study, involving 1000 generated samples, confirms that our approach delivers superior quality, decisively outperforming established methods.
Improving Image Captioning via Predicting Structured Concepts
Nov 14, 2023Having the difficulty of solving the semantic gap between images and texts for the image captioning task, conventional studies in this area paid some attention to treating semantic concepts as a bridge between the two modalities and improved captioning performance accordingly. Although promising results on concept prediction were obtained, the aforementioned studies normally ignore the relationship among concepts, which relies on not only objects in the image, but also word dependencies in the text, so that offers a considerable potential for improving the process of generating good descriptions. In this paper, we propose a structured concept predictor (SCP) to predict concepts and their structures, then we integrate them into captioning, so as to enhance the contribution of visual signals in this task via concepts and further use their relations to distinguish cross-modal semantics for better description generation. Particularly, we design weighted graph convolutional networks (W-GCN) to depict concept relations driven by word dependencies, and then learns differentiated contributions from these concepts for following decoding process. Therefore, our approach captures potential relations among concepts and discriminatively learns different concepts, so that effectively facilitates image captioning with inherited information across modalities. Extensive experiments and their results demonstrate the effectiveness of our approach as well as each proposed module in this work.
ProtoArgNet: Interpretable Image Classification with Super-Prototypes and Argumentation [Technical Report]
Nov 26, 2023We propose ProtoArgNet, a novel interpretable deep neural architecture for image classification in the spirit of prototypical-part-learning as found, e.g. in ProtoPNet. While earlier approaches associate every class with multiple prototypical-parts, ProtoArgNet uses super-prototypes that combine prototypical-parts into single prototypical class representations. Furthermore, while earlier approaches use interpretable classification layers, e.g. logistic regression in ProtoPNet, ProtoArgNet improves accuracy with multi-layer perceptrons while relying upon an interpretable reading thereof based on a form of argumentation. ProtoArgNet is customisable to user cognitive requirements by a process of sparsification of the multi-layer perceptron/argumentation component. Also, as opposed to other prototypical-part-learning approaches, ProtoArgNet can recognise spatial relations between different prototypical-parts that are from different regions in images, similar to how CNNs capture relations between patterns recognized in earlier layers.
DifAugGAN: A Practical Diffusion-style Data Augmentation for GAN-based Single Image Super-resolution
Nov 30, 2023
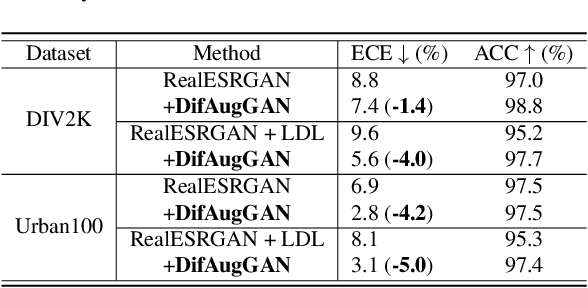
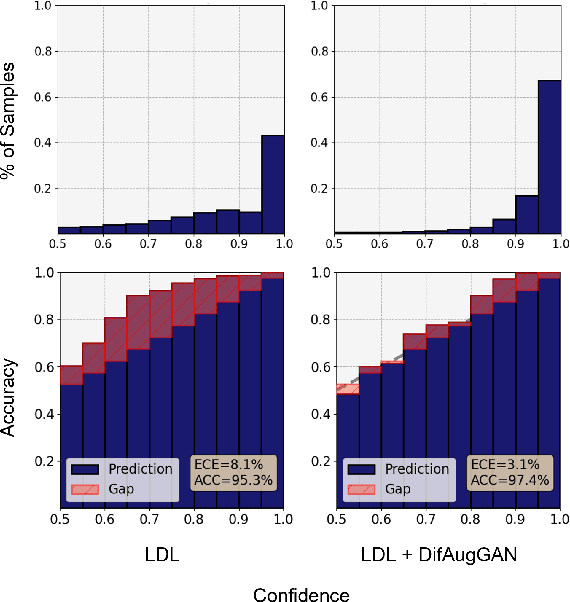
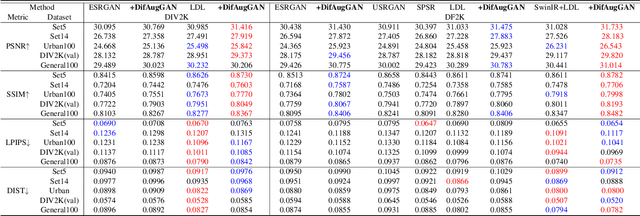
It is well known the adversarial optimization of GAN-based image super-resolution (SR) methods makes the preceding SR model generate unpleasant and undesirable artifacts, leading to large distortion. We attribute the cause of such distortions to the poor calibration of the discriminator, which hampers its ability to provide meaningful feedback to the generator for learning high-quality images. To address this problem, we propose a simple but non-travel diffusion-style data augmentation scheme for current GAN-based SR methods, known as DifAugGAN. It involves adapting the diffusion process in generative diffusion models for improving the calibration of the discriminator during training motivated by the successes of data augmentation schemes in the field to achieve good calibration. Our DifAugGAN can be a Plug-and-Play strategy for current GAN-based SISR methods to improve the calibration of the discriminator and thus improve SR performance. Extensive experimental evaluations demonstrate the superiority of DifAugGAN over state-of-the-art GAN-based SISR methods across both synthetic and real-world datasets, showcasing notable advancements in both qualitative and quantitative results.
Holistic Evaluation of Text-To-Image Models
Nov 07, 2023The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/v1.1.0 and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase.
Segment Anything Model with Uncertainty Rectification for Auto-Prompting Medical Image Segmentation
Nov 17, 2023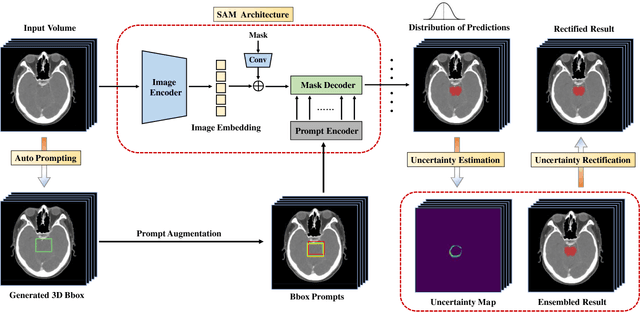
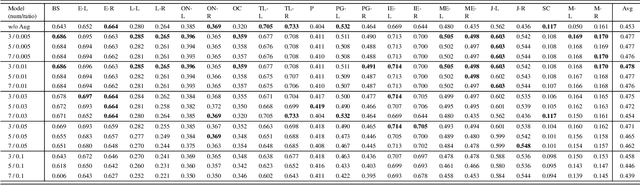
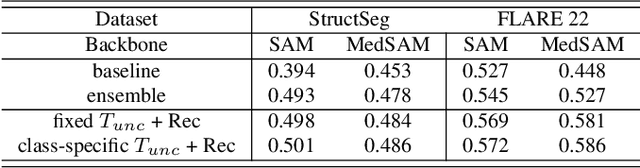
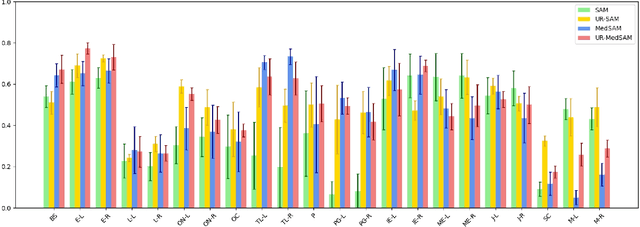
The introduction of the Segment Anything Model (SAM) has marked a significant advancement in prompt-driven image segmentation. However, SAM's application to medical image segmentation requires manual prompting of target structures to obtain acceptable performance, which is still labor-intensive. Despite attempts of auto-prompting to turn SAM into a fully automatic manner, it still exhibits subpar performance and lacks of reliability in the field of medical imaging. In this paper, we propose UR-SAM, an uncertainty rectified SAM framework to enhance the robustness and reliability for auto-prompting medical image segmentation. Our method incorporates a prompt augmentation module to estimate the distribution of predictions and generate uncertainty maps, and an uncertainty-based rectification module to further enhance the performance of SAM. Extensive experiments on two public 3D medical datasets covering the segmentation of 35 organs demonstrate that without supplementary training or fine-tuning, our method further improves the segmentation performance with up to 10.7 % and 13.8 % in dice similarity coefficient, demonstrating efficiency and broad capabilities for medical image segmentation without manual prompting.