 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WoodFisher: Efficient second-order approximations for model compression
Apr 29, 2020
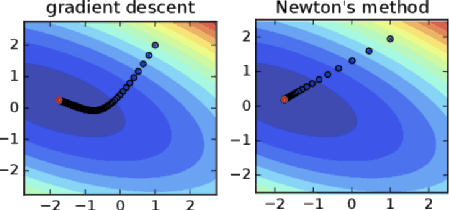
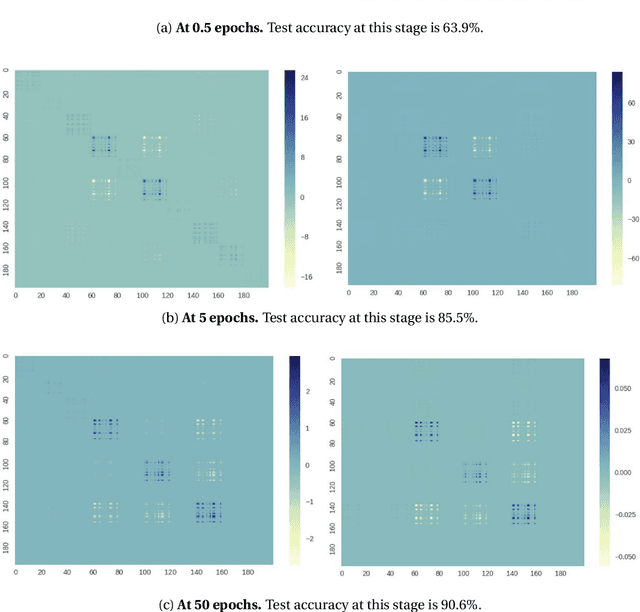
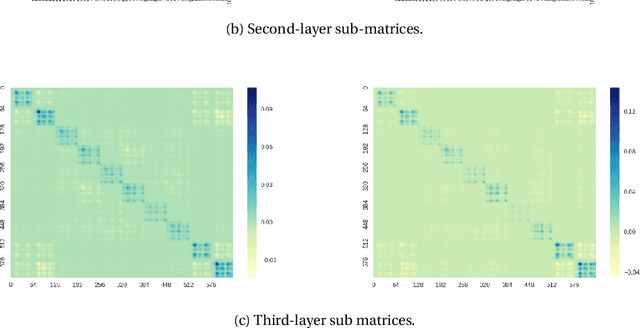
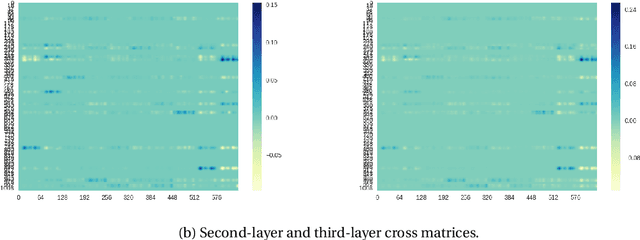
Second-order information, in the form of Hessian- or Inverse-Hessian-vector products, is a fundamental tool for solving optimization problems. Recently, there has been a tremendous amount of work on utilizing this information for the current compute and memory-intensive deep neural networks, usually via coarse-grained approximations (such as diagonal, blockwise, or Kronecker-factorization). However, not much is known about the quality of these approximations. Our work addresses this question, and in particular, we propose a method called `WoodFisher' that leverages the structure of the empirical Fisher information matrix, along with the Woodbury matrix identity, to compute a faithful and efficient estimate of the inverse Hessian. Our main application is to the task of compressing neural networks, where we build on the classical Optimal Brain Damage/Surgeon framework (LeCun et al., 1990; Hassibi and Stork, 1993). We demonstrate that WoodFisher significantly outperforms magnitude pruning (isotropic Hessian), as well as methods that maintain other diagonal estimates. Further, even when gradual pruning is considered, our method results in a gain in test accuracy over the state-of-the-art approaches, for standard image classification datasets such as CIFAR-10, ImageNet. We also propose a variant called `WoodTaylor', which takes into account the first-order gradient term, and can lead to additional improvements. An important advantage of our methods is that they allow us to automatically set the layer-wise pruning thresholds, avoiding the need for any manual tuning or sensitivity analysis.
FourierNet: Compact mask representation for instance segmentation using differentiable shape decoders
Feb 07, 2020
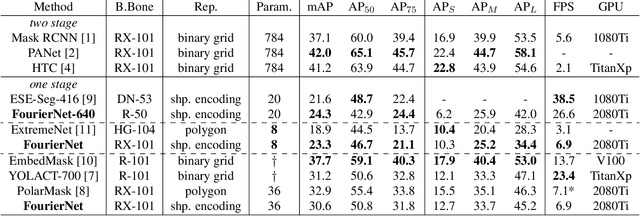
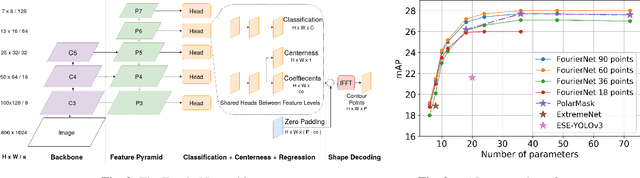
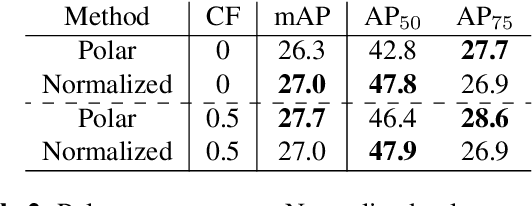
We present FourierNet a single shot, anchor-free, fully convolutional instance segmentation method, which predicts a shape vector that is converted into contour points using a numerical transformation. Compared to previous methods, we introduce a new training technique, where we utilize a differentiable shape decoder, which achieves automatic weight balancing of the shape vector's coefficients. Fourier series was utilized as a shape encoder because of its coefficient interpretability and fast implementation. By using its lower frequencies we were able to retrieve smooth and compact masks. FourierNet shows promising results compared to polygon representation methods, achieving 30.6 mAP on the MS COCO 2017 benchmark. At lower image resolutions, it runs at 26.6 FPS with 24.3 mAP. It achieves 23.3 mAP using just 8 parameters to represent the mask, which is double the amount of parameters to predict a bounding box. Code will be available at: github.com/cogsys-tuebingen/FourierNet.
Deep Semantic Ranking Based Hashing for Multi-Label Image Retrieval
Apr 19, 2015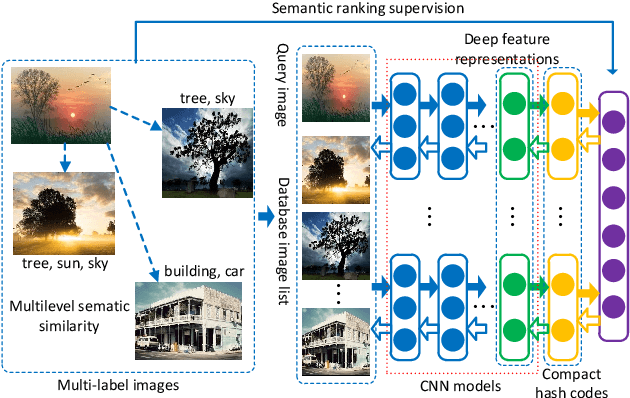
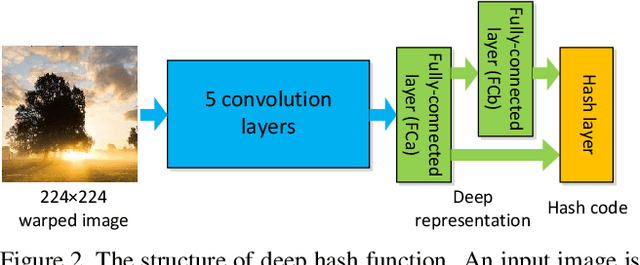
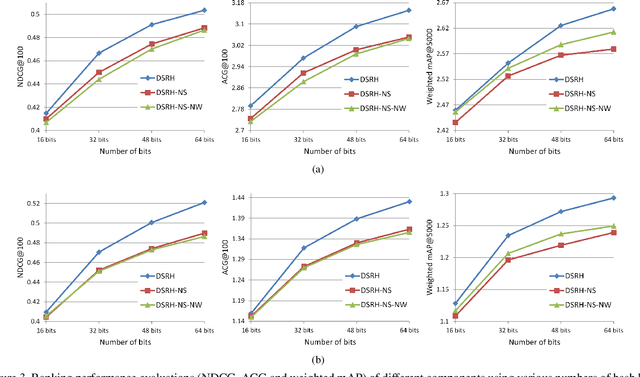
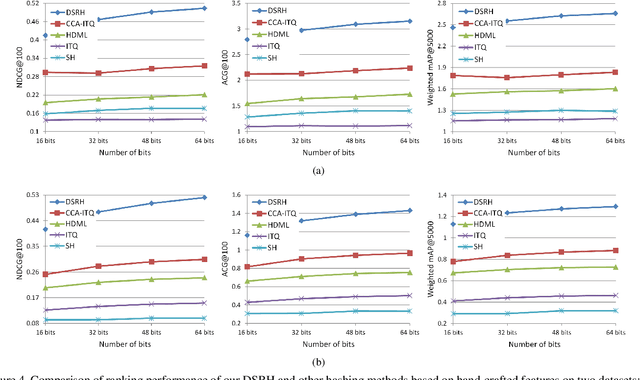
With the rapid growth of web images, hashing has received increasing interests in large scale image retrieval. Research efforts have been devoted to learning compact binary codes that preserve semantic similarity based on labels. However, most of these hashing methods are designed to handle simple binary similarity. The complex multilevel semantic structure of images associated with multiple labels have not yet been well explored. Here we propose a deep semantic ranking based method for learning hash functions that preserve multilevel semantic similarity between multi-label images. In our approach, deep convolutional neural network is incorporated into hash functions to jointly learn feature representations and mappings from them to hash codes, which avoids the limitation of semantic representation power of hand-crafted features. Meanwhile, a ranking list that encodes the multilevel similarity information is employed to guide the learning of such deep hash functions. An effective scheme based on surrogate loss is used to solve the intractable optimization problem of nonsmooth and multivariate ranking measures involved in the learning procedure. Experimental results show the superiority of our proposed approach over several state-of-the-art hashing methods in term of ranking evaluation metrics when tested on multi-label image datasets.
A New Randomness Evaluation Method with Applications to Image Shuffling and Encryption
Nov 07, 2012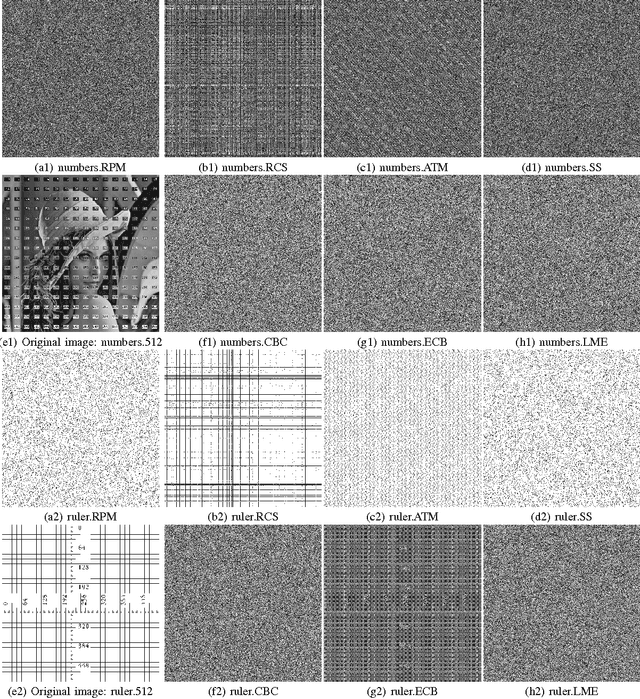
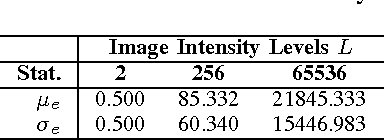
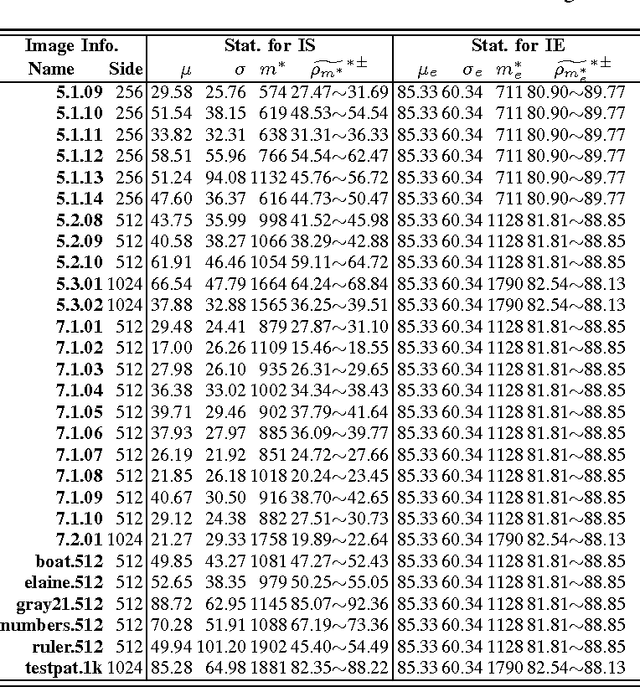
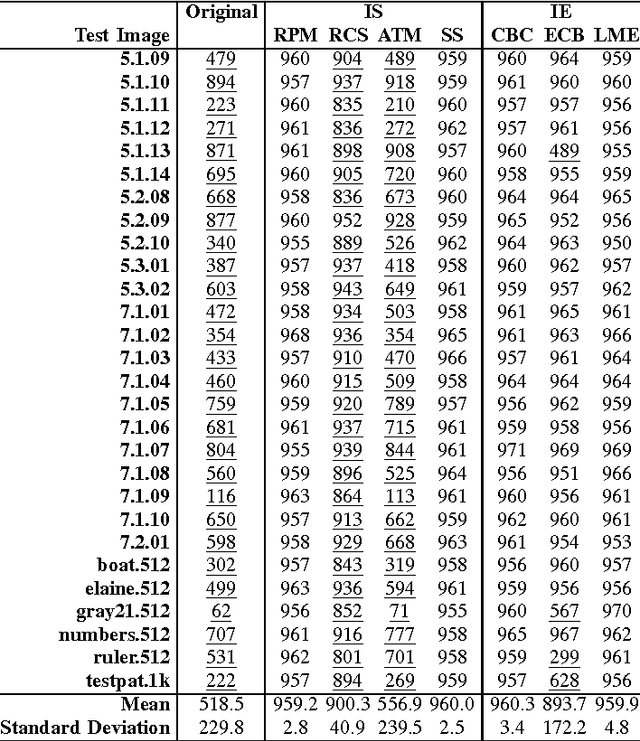
This letter discusses the problem of testing the degree of randomness within an image, particularly for a shuffled or encrypted image. Its key contributions are: 1) a mathematical model of perfectly shuffled images; 2) the derivation of the theoretical distribution of pixel differences; 3) a new $Z$-test based approach to differentiate whether or not a test image is perfectly shuffled; and 4) a randomized algorithm to unbiasedly evaluate the degree of randomness within a given image. Simulation results show that the proposed method is robust and effective in evaluating the degree of randomness within an image, and may often be more suitable for image applications than commonly used testing schemes designed for binary data like NIST 800-22. The developed method may be also useful as a first step in determining whether or not a shuffling or encryption scheme is suitable for a particular cryptographic application.
Statistical models and regularization strategies in statistical image reconstruction of low-dose X-ray CT: a survey
May 14, 2015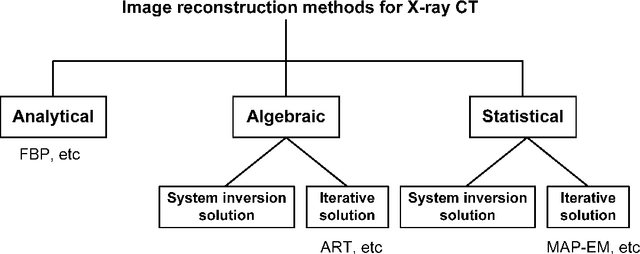

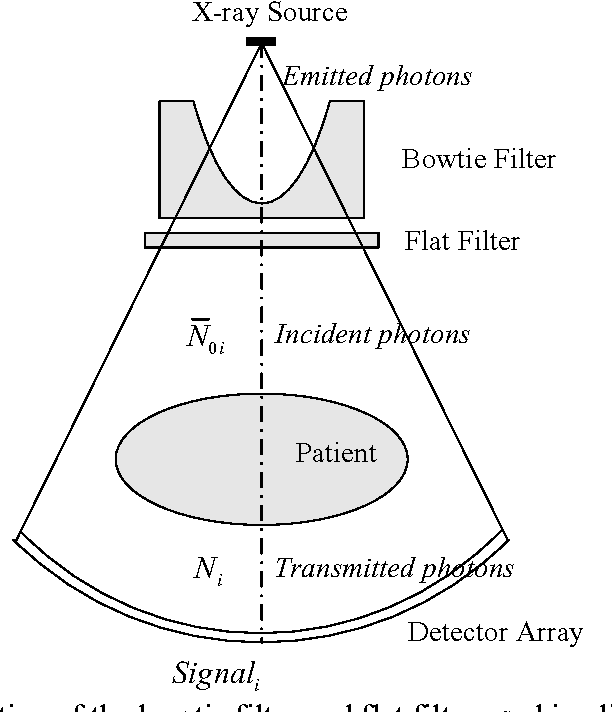

Statistical image reconstruction (SIR) methods have shown potential to substantially improve the image quality of low-dose X-ray computed tomography (CT) as compared to the conventional filtered back-projection (FBP) method for various clinical tasks. According to the maximum a posterior (MAP) estimation, the SIR methods can be typically formulated by an objective function consisting of two terms: (1) data-fidelity (or equivalently, data-fitting or data-mismatch) term modeling the statistics of projection measurements, and (2) regularization (or equivalently, prior or penalty) term reflecting prior knowledge or expectation on the characteristics of the image to be reconstructed. Existing SIR methods for low-dose CT can be divided into two groups: (1) those that use calibrated transmitted photon counts (before log-transform) with penalized maximum likelihood (pML) criterion, and (2) those that use calibrated line-integrals (after log-transform) with penalized weighted least-squares (PWLS) criterion. Accurate statistical modeling of the projection measurements is a prerequisite for SIR, while the regularization term in the objective function also plays a critical role for successful image reconstruction. This paper reviews several statistical models on CT projection measurements and various regularization strategies incorporating prior knowledge or expected properties of the image to be reconstructed, which together formulate the objective function of the SIR methods for low-dose X-ray CT.
Exploit fully automatic low-level segmented PET data for training high-level deep learning algorithms for the corresponding CT data
Mar 07, 2019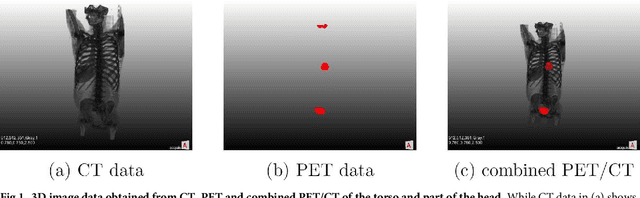
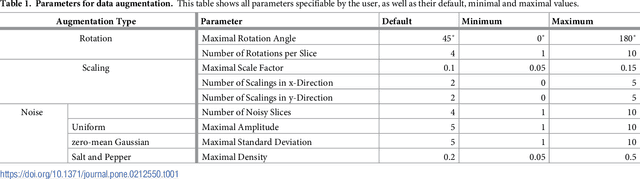
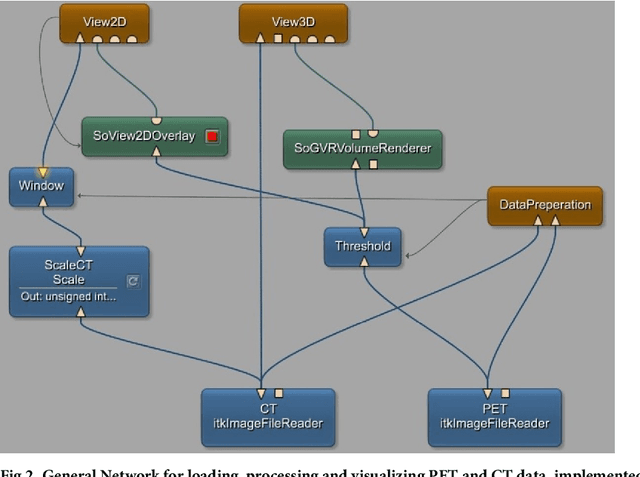
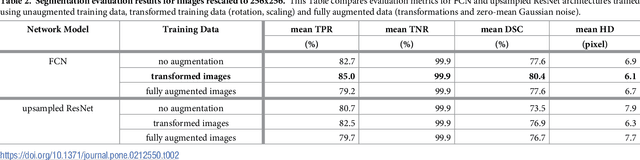
We present an approach for fully automatic urinary bladder segmentation in CT images with artificial neural networks in this study. Automatic medical image analysis has become an invaluable tool in the different treatment stages of diseases. Especially medical image segmentation plays a vital role, since segmentation is often the initial step in an image analysis pipeline. Since deep neural networks have made a large impact on the field of image processing in the past years, we use two different deep learning architectures to segment the urinary bladder. Both of these architectures are based on pre-trained classification networks that are adapted to perform semantic segmentation. Since deep neural networks require a large amount of training data, specifically images and corresponding ground truth labels, we furthermore propose a method to generate such a suitable training data set from Positron Emission Tomography/Computed Tomography image data. This is done by applying thresholding to the Positron Emission Tomography data for obtaining a ground truth and by utilizing data augmentation to enlarge the dataset. In this study, we discuss the influence of data augmentation on the segmentation results, and compare and evaluate the proposed architectures in terms of qualitative and quantitative segmentation performance. The results presented in this study allow concluding that deep neural networks can be considered a promising approach to segment the urinary bladder in CT images.
* 20 pages
Learning View and Target Invariant Visual Servoing for Navigation
Mar 04, 2020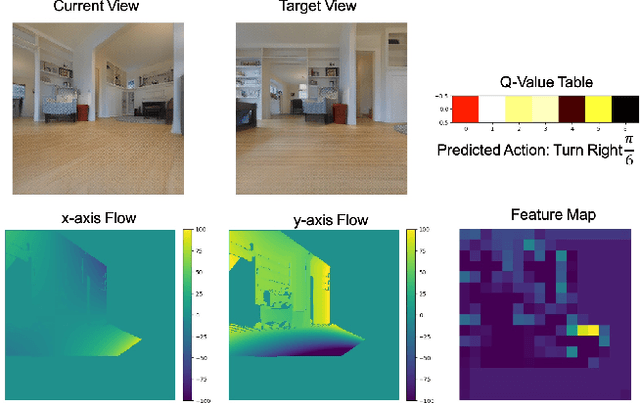
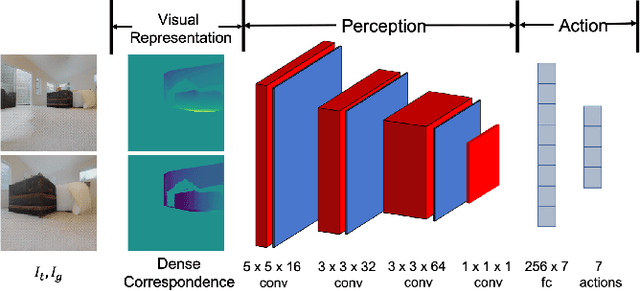
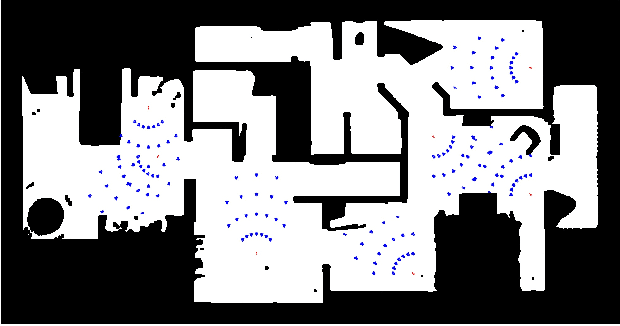

The advances in deep reinforcement learning recently revived interest in data-driven learning based approaches to navigation. In this paper we propose to learn viewpoint invariant and target invariant visual servoing for local mobile robot navigation; given an initial view and the goal view or an image of a target, we train deep convolutional network controller to reach the desired goal. We present a new architecture for this task which rests on the ability of establishing correspondences between the initial and goal view and novel reward structure motivated by the traditional feedback control error. The advantage of the proposed model is that it does not require calibration and depth information and achieves robust visual servoing in a variety of environments and targets without any parameter fine tuning. We present comprehensive evaluation of the approach and comparison with other deep learning architectures as well as classical visual servoing methods in visually realistic simulation environment. The presented model overcomes the brittleness of classical visual servoing based methods and achieves significantly higher generalization capability compared to the previous learning approaches.
CorGAN: Correlation-Capturing Convolutional Generative Adversarial Networks for Generating Synthetic Healthcare Records
Mar 04, 2020
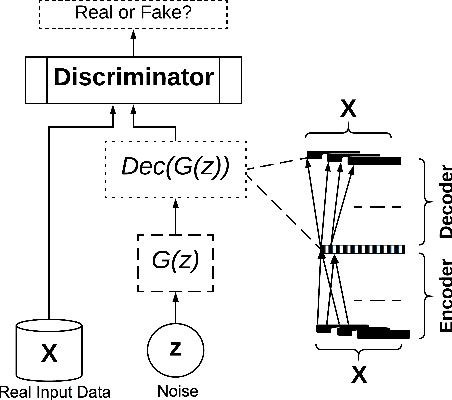


Deep learning models have demonstrated high-quality performance in areas such as image classification and speech processing. However, creating a deep learning model using electronic health record (EHR) data, requires addressing particular privacy challenges that are unique to researchers in this domain. This matter focuses attention on generating realistic synthetic data while ensuring privacy. In this paper, we propose a novel framework called correlation-capturing Generative Adversarial Network (CorGAN), to generate synthetic healthcare records. In CorGAN we utilize Convolutional Neural Networks to capture the correlations between adjacent medical features in the data representation space by combining Convolutional Generative Adversarial Networks and Convolutional Autoencoders. To demonstrate the model fidelity, we show that CorGAN generates synthetic data with performance similar to that of real data in various Machine Learning settings such as classification and prediction. We also give a privacy assessment and report on statistical analysis regarding realistic characteristics of the synthetic data. The software of this work is open-source and is available at: https://github.com/astorfi/cor-gan.
Learning Not to Learn in the Presence of Noisy Labels
Feb 16, 2020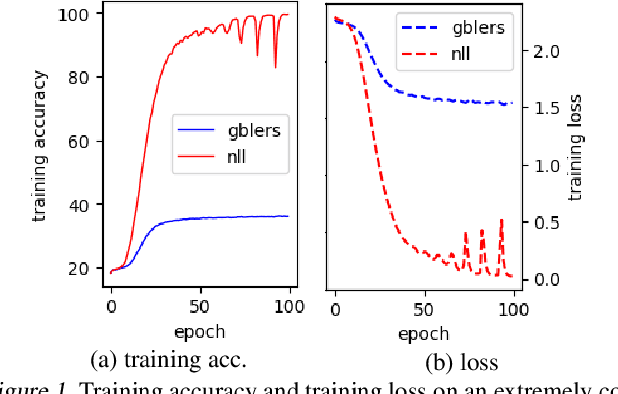

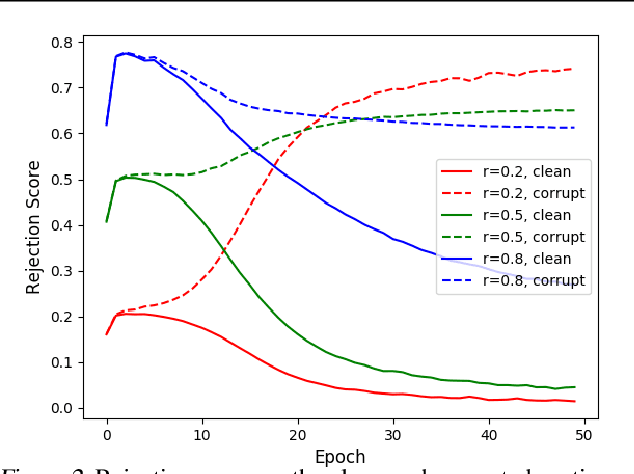
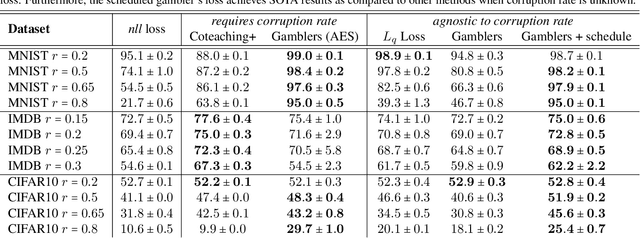
Learning in the presence of label noise is a challenging yet important task: it is crucial to design models that are robust in the presence of mislabeled datasets. In this paper, we discover that a new class of loss functions called the gambler's loss provides strong robustness to label noise across various levels of corruption. We show that training with this loss function encourages the model to "abstain" from learning on the data points with noisy labels, resulting in a simple and effective method to improve robustness and generalization. In addition, we propose two practical extensions of the method: 1) an analytical early stopping criterion to approximately stop training before the memorization of noisy labels, as well as 2) a heuristic for setting hyperparameters which do not require knowledge of the noise corruption rate. We demonstrate the effectiveness of our method by achieving strong results across three image and text classification tasks as compared to existing baselines.
Domain Adaptive Transfer Attack (DATA)-based Segmentation Networks for Building Extraction from Aerial Images
Apr 29, 2020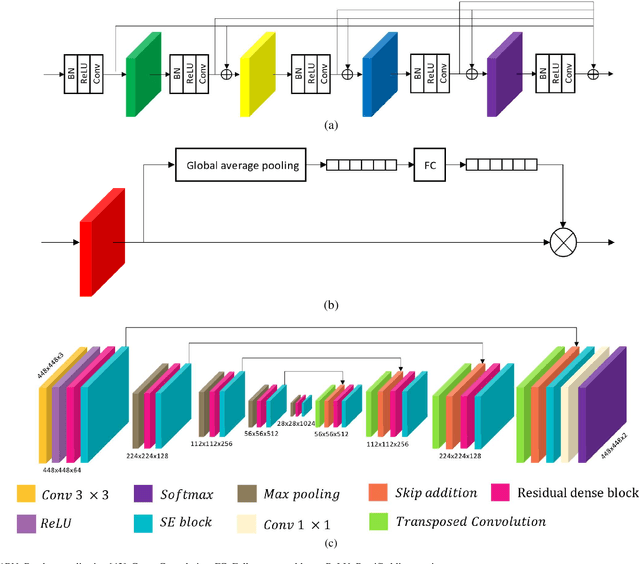



Semantic segmentation models based on convolutional neural networks (CNNs) have gained much attention in relation to remote sensing and have achieved remarkable performance for the extraction of buildings from high-resolution aerial images. However, the issue of limited generalization for unseen images remains. When there is a domain gap between the training and test datasets, CNN-based segmentation models trained by a training dataset fail to segment buildings for the test dataset. In this paper, we propose segmentation networks based on a domain adaptive transfer attack (DATA) scheme for building extraction from aerial images. The proposed system combines the domain transfer and adversarial attack concepts. Based on the DATA scheme, the distribution of the input images can be shifted to that of the target images while turning images into adversarial examples against a target network. Defending adversarial examples adapted to the target domain can overcome the performance degradation due to the domain gap and increase the robustness of the segmentation model. Cross-dataset experiments and the ablation study are conducted for the three different datasets: the Inria aerial image labeling dataset, the Massachusetts building dataset, and the WHU East Asia dataset. Compared to the performance of the segmentation network without the DATA scheme, the proposed method shows improvements in the overall IoU. Moreover, it is verified that the proposed method outperforms even when compared to feature adaptation (FA) and output space adaptation (OSA).