 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time interactive magnetic resonance (MR) temperature imaging in both aqueous and adipose tissues using cascaded deep neural networks for MR-guided focused ultrasound surgery (MRgFUS)
Aug 29, 2019
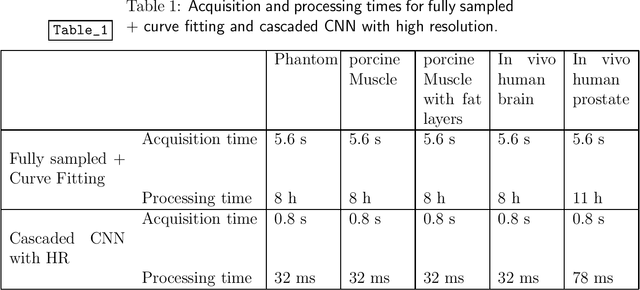
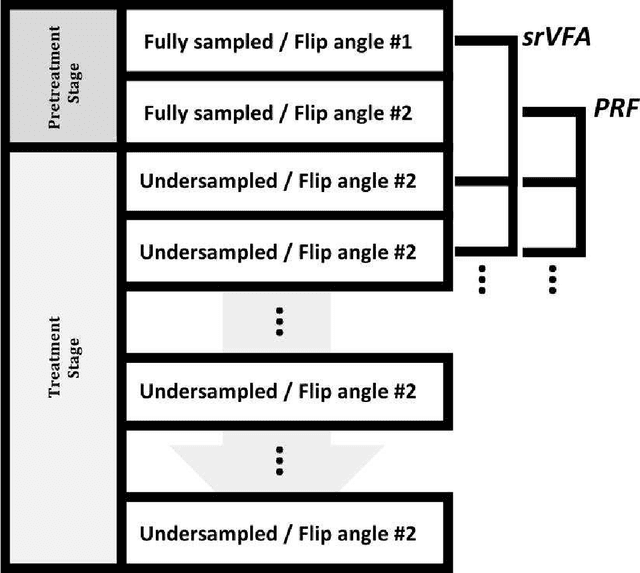
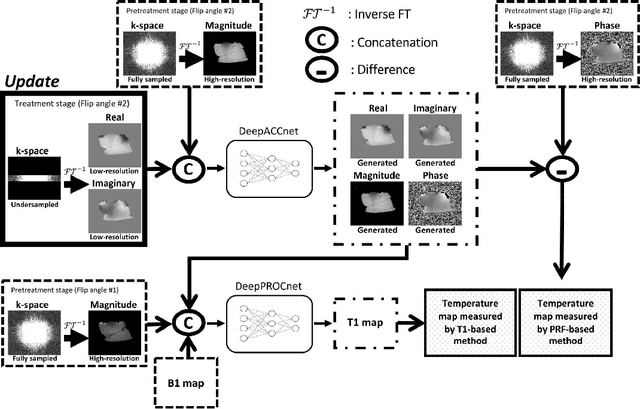
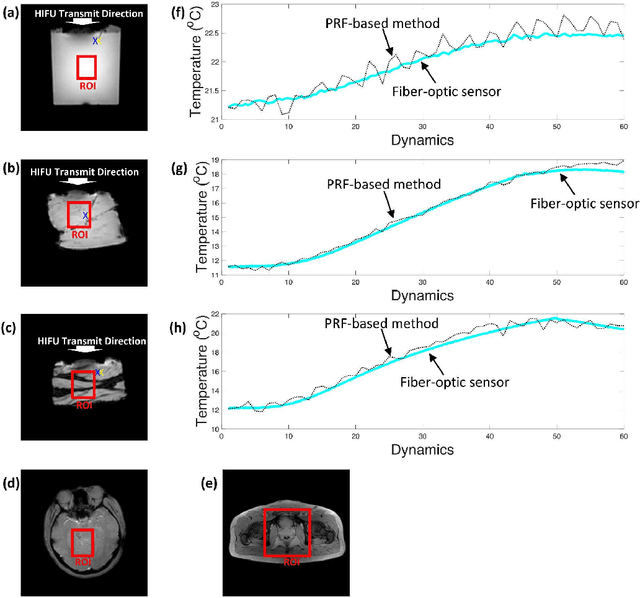
Purpose: To acquire the real-time interactive temperature map for aqueous and adipose tissue, the problems of long acquisition and processing time must be addressed. To overcome these major challenges, this paper proposes a cascaded convolutional neural network (CNN) framework and multi-echo gradient echo (meGRE) with a single reference variable flip angle (srVFA). Methods: To optimize the echo times for each method, MR images are acquired using a meGRE sequence; meGRE images with two flip angles (FAs) and meGRE images with a single FA are acquired during the pretreatment and treatment stages, respectively. These images are then processed and reconstructed by a cascaded CNN, which consists of two CNNs. The first CNN (called DeepACCnet) performs HR complex MR image reconstruction from the LR MR image acquired during the treatment stage, which is improved by the HR magnitude MR image acquired during the pretreatment stage. The second CNN (called DeepPROCnet) copes with T1 mapping. Results: Measurements of temperature and T1 changes obtained by meGRE combined with srVFA and cascaded CNNs were achieved in an agarose gel phantom, ex vivo porcine muscle, and ex vivo porcine muscle with fat layers (heating tests), and in vivo human prostate and brain (non-heating tests). In the heating test, the maximum differences between fiber-optic sensor and samples are less than 1 degree Celcius. In all cases, temperature mapping using the cascaded CNN achieved the best results in all cases. The acquisition and processing times for the proposed method are 0.8 s and 32 ms, respectively. Conclusions: Real-time interactive HR MR temperature mapping for simultaneously measuring aqueous and adipose tissue is feasible by combining a cascaded CNN with meGRE and srVFA.
Edge-Based Blur Kernel Estimation Using Sparse Representation and Self-Similarity
Nov 17, 2018

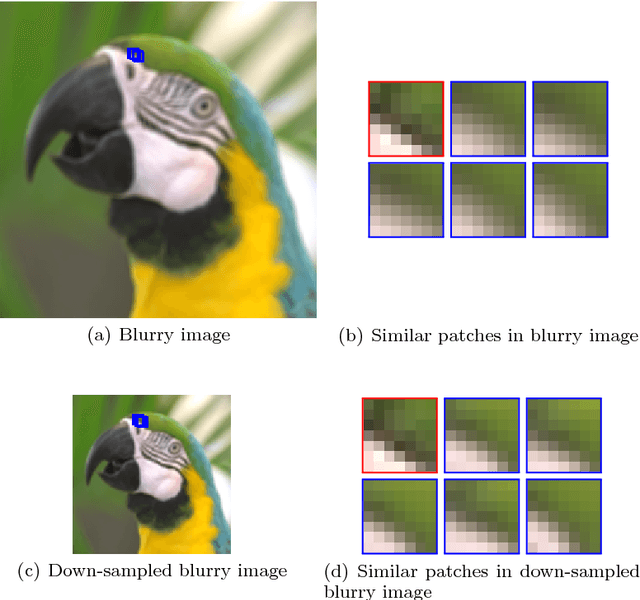

Blind image deconvolution is the problem of recovering the latent image from the only observed blurry image when the blur kernel is unknown. In this paper, we propose an edge-based blur kernel estimation method for blind motion deconvolution. In our previous work, we incorporate both sparse representation and self-similarity of image patches as priors into our blind deconvolution model to regularize the recovery of the latent image. Since almost any natural image has properties of sparsity and multi-scale self-similarity, we construct a sparsity regularizer and a cross-scale non-local regularizer based on our patch priors. It has been observed that our regularizers often favor sharp images over blurry ones only for image patches of the salient edges and thus we define an edge mask to locate salient edges that we want to apply our regularizers. Experimental results on both simulated and real blurry images demonstrate that our method outperforms existing state-of-the-art blind deblurring methods even for handling of very large blurs, thanks to the use of the edge mask.
Domain Adaptive Transfer Attack (DATA)-based Segmentation Networks for Building Extraction from Aerial Images
Apr 29, 2020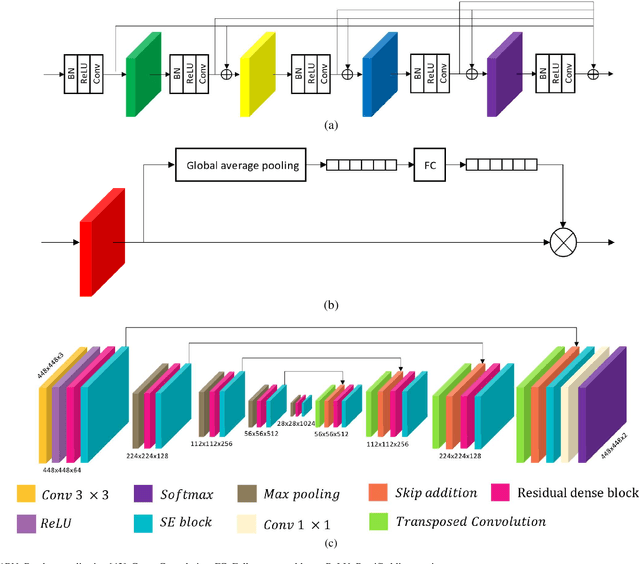



Semantic segmentation models based on convolutional neural networks (CNNs) have gained much attention in relation to remote sensing and have achieved remarkable performance for the extraction of buildings from high-resolution aerial images. However, the issue of limited generalization for unseen images remains. When there is a domain gap between the training and test datasets, CNN-based segmentation models trained by a training dataset fail to segment buildings for the test dataset. In this paper, we propose segmentation networks based on a domain adaptive transfer attack (DATA) scheme for building extraction from aerial images. The proposed system combines the domain transfer and adversarial attack concepts. Based on the DATA scheme, the distribution of the input images can be shifted to that of the target images while turning images into adversarial examples against a target network. Defending adversarial examples adapted to the target domain can overcome the performance degradation due to the domain gap and increase the robustness of the segmentation model. Cross-dataset experiments and the ablation study are conducted for the three different datasets: the Inria aerial image labeling dataset, the Massachusetts building dataset, and the WHU East Asia dataset. Compared to the performance of the segmentation network without the DATA scheme, the proposed method shows improvements in the overall IoU. Moreover, it is verified that the proposed method outperforms even when compared to feature adaptation (FA) and output space adaptation (OSA).
Pose Estimation for Texture-less Shiny Objects in a Single RGB Image Using Synthetic Training Data
Sep 23, 2019
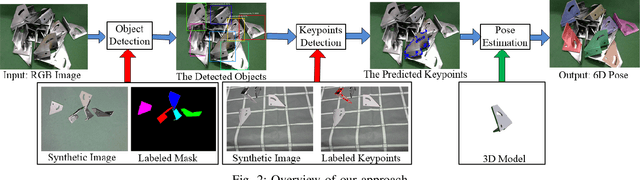


In the industrial domain, the pose estimation of multiple texture-less shiny parts is a valuable but challenging task. In this particular scenario, it is impractical to utilize keypoints or other texture information because most of them are not actual features of the target but the reflections of surroundings. Moreover, the similarity of color also poses a challenge in segmentation. In this article, we propose to divide the pose estimation process into three stages: object detection, features detection and pose optimization. A convolutional neural network was utilized to perform object detection. Concerning the reliability of surface texture, we leveraged the contour information for estimating pose. Since conventional contour-based methods are inapplicable to clustered metal parts due to the difficulties in segmentation, we use the dense discrete points along the metal part edges as semantic keypoints for contour detection. Afterward, we exploit both keypoint information and CAD model to calculate the 6D pose of each object in view. A typical implementation of deep learning methods not only requires a large amount of training data, but also relies on intensive human labor for labeling the datasets. Therefore, we propose an approach to generate datasets and label them automatically. Despite not using any real-world photos for training, a series of experiments showed that the algorithm built on synthetic data perform well in the real environment.
FourierNet: Compact mask representation for instance segmentation using differentiable shape decoders
Feb 07, 2020
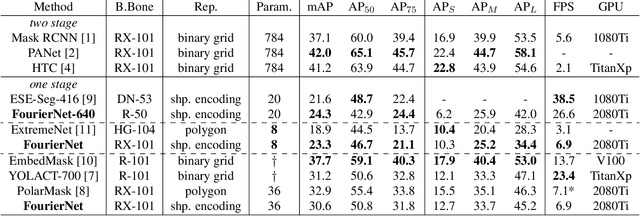
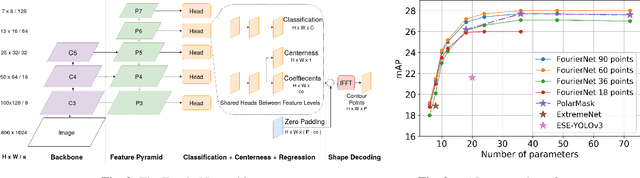
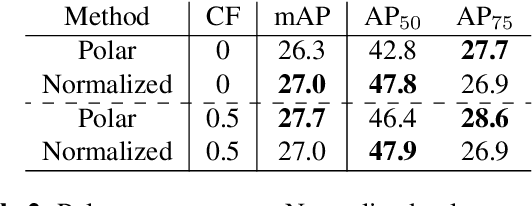
We present FourierNet a single shot, anchor-free, fully convolutional instance segmentation method, which predicts a shape vector that is converted into contour points using a numerical transformation. Compared to previous methods, we introduce a new training technique, where we utilize a differentiable shape decoder, which achieves automatic weight balancing of the shape vector's coefficients. Fourier series was utilized as a shape encoder because of its coefficient interpretability and fast implementation. By using its lower frequencies we were able to retrieve smooth and compact masks. FourierNet shows promising results compared to polygon representation methods, achieving 30.6 mAP on the MS COCO 2017 benchmark. At lower image resolutions, it runs at 26.6 FPS with 24.3 mAP. It achieves 23.3 mAP using just 8 parameters to represent the mask, which is double the amount of parameters to predict a bounding box. Code will be available at: github.com/cogsys-tuebingen/FourierNet.
OPFython: A Python-Inspired Optimum-Path Forest Classifier
Jan 28, 2020
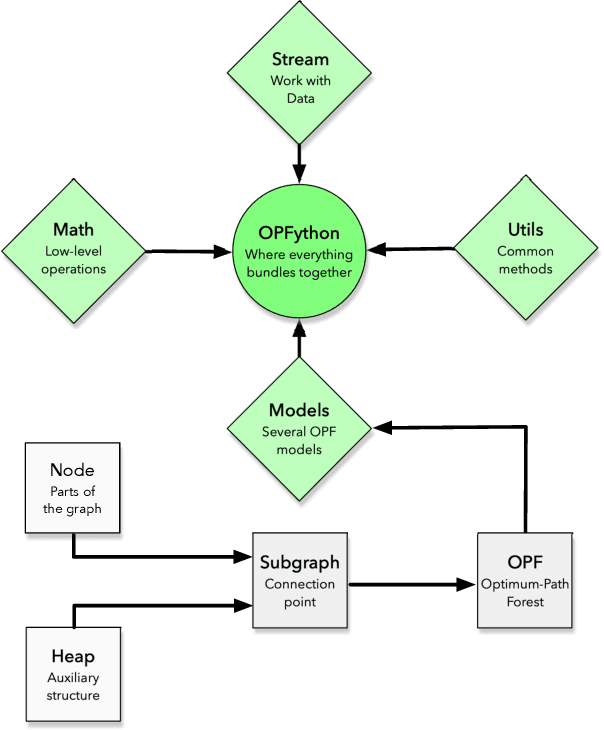
Machine learning techniques have been paramount throughout the last years, being applied in a wide range of tasks, such as classification, object recognition, person identification, image segmentation, among others. Nevertheless, conventional classification algorithms, e.g., Logistic Regression, Decision Trees, Bayesian classifiers, might lack complexity and diversity, not being suitable when dealing with real-world data. A recent graph-inspired classifier, known as the Optimum-Path Forest, has proven to be a state-of-the-art technique, comparable to Support Vector Machines and even surpassing it in some tasks. In this paper, we propose a Python-based Optimum-Path Forest framework, denoted as OPFython, where all of its functions and classes are based upon the original C language implementation. Additionally, as OPFython is a Python-based library, it provides a more friendly environment and a faster prototyping workspace than the C language.
Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm
Apr 17, 2020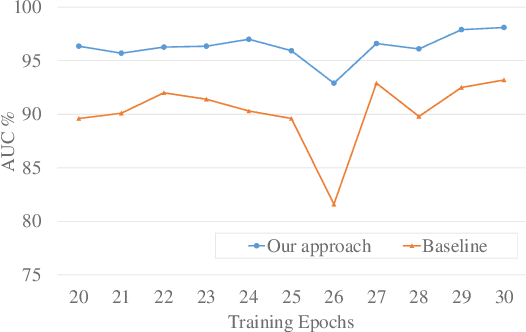

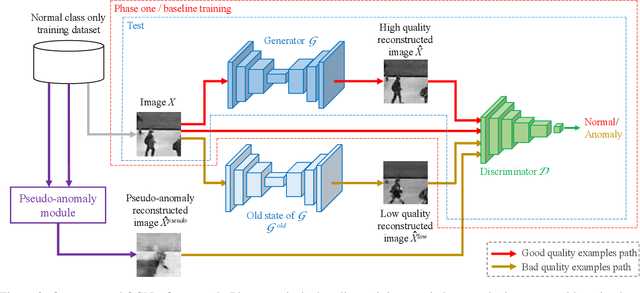

A popular method for anomaly detection is to use the generator of an adversarial network to formulate anomaly scores over reconstruction loss of input. Due to the rare occurrence of anomalies, optimizing such networks can be a cumbersome task. Another possible approach is to use both generator and discriminator for anomaly detection. However, attributed to the involvement of adversarial training, this model is often unstable in a way that the performance fluctuates drastically with each training step. In this study, we propose a framework that effectively generates stable results across a wide range of training steps and allows us to use both the generator and the discriminator of an adversarial model for efficient and robust anomaly detection. Our approach transforms the fundamental role of a discriminator from identifying real and fake data to distinguishing between good and bad quality reconstructions. To this end, we prepare training examples for the good quality reconstruction by employing the current generator, whereas poor quality examples are obtained by utilizing an old state of the same generator. This way, the discriminator learns to detect subtle distortions that often appear in reconstructions of the anomaly inputs. Extensive experiments performed on Caltech-256 and MNIST image datasets for novelty detection show superior results. Furthermore, on UCSD Ped2 video dataset for anomaly detection, our model achieves a frame-level AUC of 98.1%, surpassing recent state-of-the-art methods.
Learning View and Target Invariant Visual Servoing for Navigation
Mar 04, 2020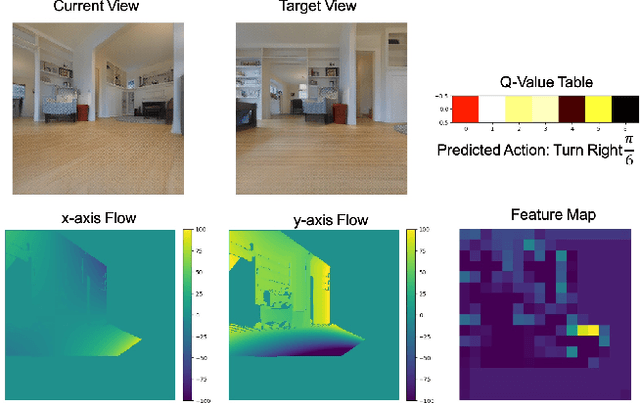
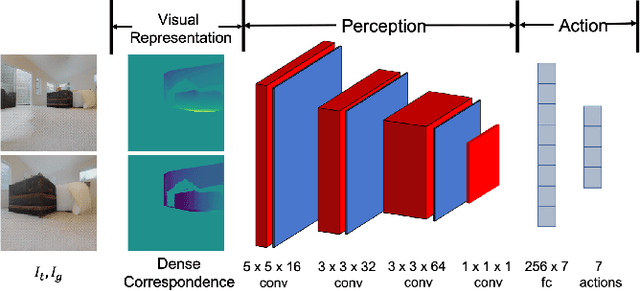
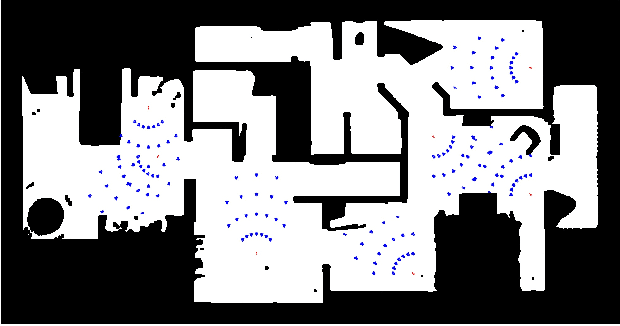

The advances in deep reinforcement learning recently revived interest in data-driven learning based approaches to navigation. In this paper we propose to learn viewpoint invariant and target invariant visual servoing for local mobile robot navigation; given an initial view and the goal view or an image of a target, we train deep convolutional network controller to reach the desired goal. We present a new architecture for this task which rests on the ability of establishing correspondences between the initial and goal view and novel reward structure motivated by the traditional feedback control error. The advantage of the proposed model is that it does not require calibration and depth information and achieves robust visual servoing in a variety of environments and targets without any parameter fine tuning. We present comprehensive evaluation of the approach and comparison with other deep learning architectures as well as classical visual servoing methods in visually realistic simulation environment. The presented model overcomes the brittleness of classical visual servoing based methods and achieves significantly higher generalization capability compared to the previous learning approaches.
CorGAN: Correlation-Capturing Convolutional Generative Adversarial Networks for Generating Synthetic Healthcare Records
Mar 04, 2020
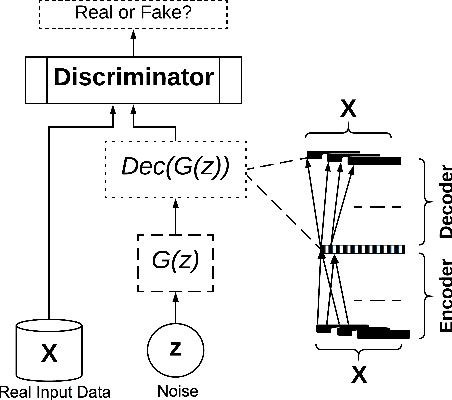


Deep learning models have demonstrated high-quality performance in areas such as image classification and speech processing. However, creating a deep learning model using electronic health record (EHR) data, requires addressing particular privacy challenges that are unique to researchers in this domain. This matter focuses attention on generating realistic synthetic data while ensuring privacy. In this paper, we propose a novel framework called correlation-capturing Generative Adversarial Network (CorGAN), to generate synthetic healthcare records. In CorGAN we utilize Convolutional Neural Networks to capture the correlations between adjacent medical features in the data representation space by combining Convolutional Generative Adversarial Networks and Convolutional Autoencoders. To demonstrate the model fidelity, we show that CorGAN generates synthetic data with performance similar to that of real data in various Machine Learning settings such as classification and prediction. We also give a privacy assessment and report on statistical analysis regarding realistic characteristics of the synthetic data. The software of this work is open-source and is available at: https://github.com/astorfi/cor-gan.
ViCo: Word Embeddings from Visual Co-occurrences
Aug 22, 2019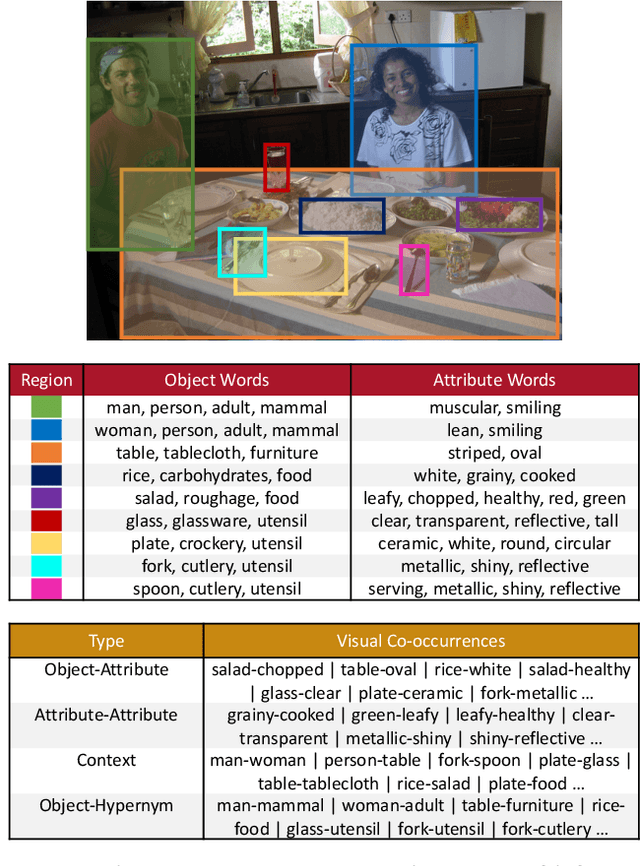
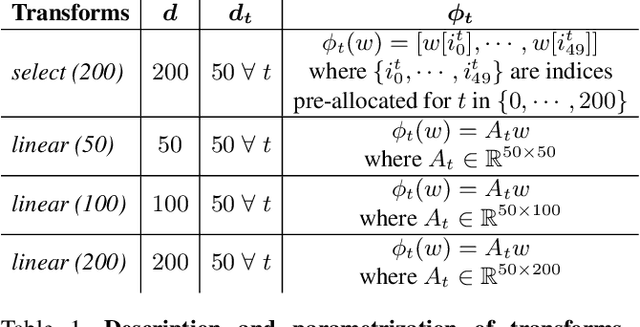
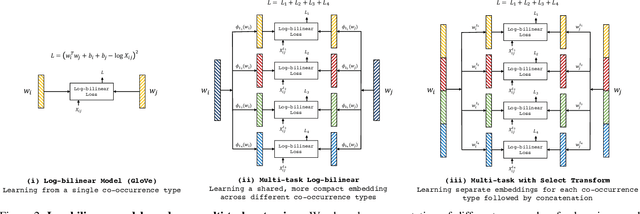
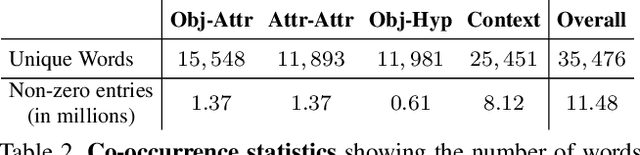
We propose to learn word embeddings from visual co-occurrences. Two words co-occur visually if both words apply to the same image or image region. Specifically, we extract four types of visual co-occurrences between object and attribute words from large-scale, textually-annotated visual databases like VisualGenome and ImageNet. We then train a multi-task log-bilinear model that compactly encodes word "meanings" represented by each co-occurrence type into a single visual word-vector. Through unsupervised clustering, supervised partitioning, and a zero-shot-like generalization analysis we show that our word embeddings complement text-only embeddings like GloVe by better representing similarities and differences between visual concepts that are difficult to obtain from text corpora alone. We further evaluate our embeddings on five downstream applications, four of which are vision-language tasks. Augmenting GloVe with our embeddings yields gains on all tasks. We also find that random embeddings perform comparably to learned embeddings on all supervised vision-language tasks, contrary to conventional wisdom.