 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Better Captioning with Sequence-Level Exploration
Mar 08, 2020

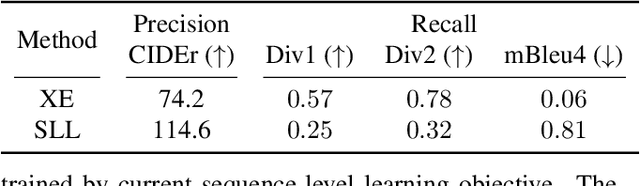

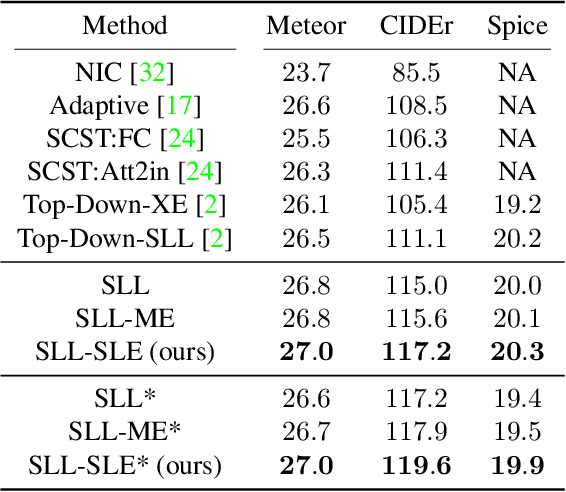
Sequence-level learning objective has been widely used in captioning tasks to achieve the state-of-the-art performance for many models. In this objective, the model is trained by the reward on the quality of its generated captions (sequence-level). In this work, we show the limitation of the current sequence-level learning objective for captioning tasks from both theory and empirical result. In theory, we show that the current objective is equivalent to only optimizing the precision side of the caption set generated by the model and therefore overlooks the recall side. Empirical result shows that the model trained by this objective tends to get lower score on the recall side. We propose to add a sequence-level exploration term to the current objective to boost recall. It guides the model to explore more plausible captions in the training. In this way, the proposed objective takes both the precision and recall sides of generated captions into account. Experiments show the effectiveness of the proposed method on both video and image captioning datasets.
Enhancing high-content imaging for studying microtubule networks at large-scale
Oct 01, 2019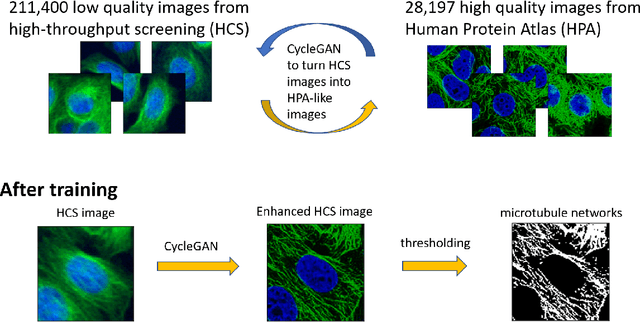
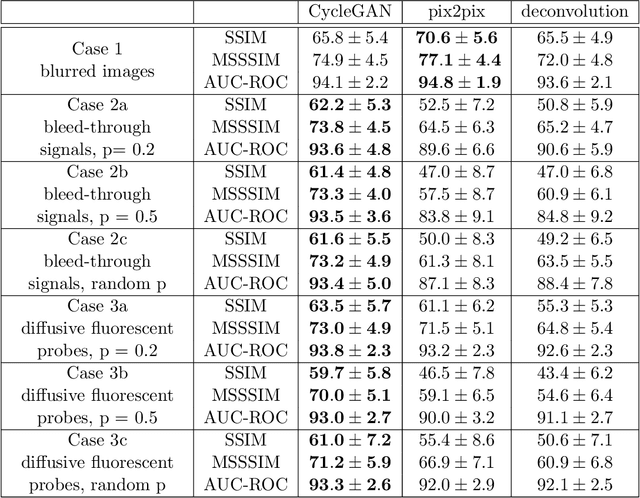
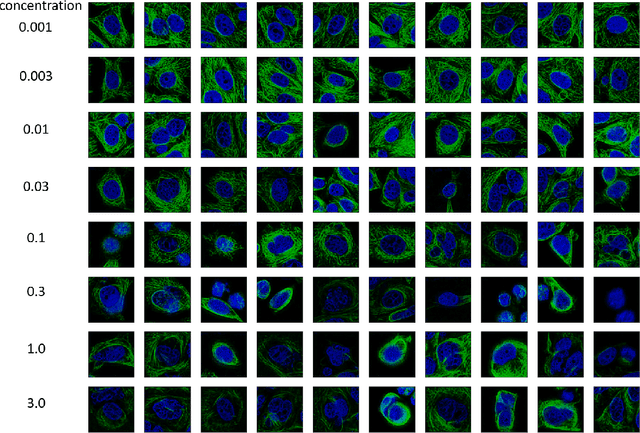
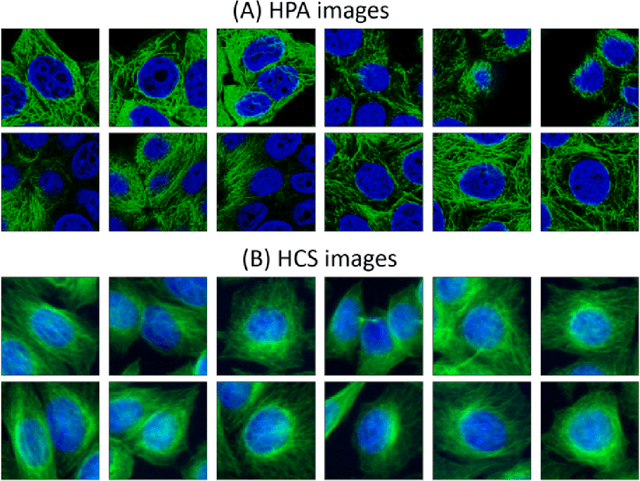
Given the crucial role of microtubules for cell survival, many researchers have found success using microtubule-targeting agents in the search for effective cancer therapeutics. Understanding microtubule responses to targeted interventions requires that the microtubule network within cells can be consistently observed across a large sample of images. However, fluorescence noise sources captured simultaneously with biological signals while using wide-field microscopes can obfuscate fine microtubule structures. Such requirements are particularly challenging for high-throughput imaging, where researchers must make decisions related to the trade-off between imaging quality and speed. Here, we propose a computational framework to enhance the quality of high-throughput imaging data to achieve fast speed and high quality simultaneously. Using CycleGAN, we learn an image model from low-throughput, high-resolution images to enhance features, such as microtubule networks in high-throughput low-resolution images. We show that CycleGAN is effective in identifying microtubules with 0.93+ AUC-ROC and that these results are robust to different kinds of image noise. We further apply CycleGAN to quantify the changes in microtubule density as a result of the application of drug compounds, and show that the quantified responses correspond well with known drug effects
Adversarial Camouflage: Hiding Physical-World Attacks with Natural Styles
Mar 08, 2020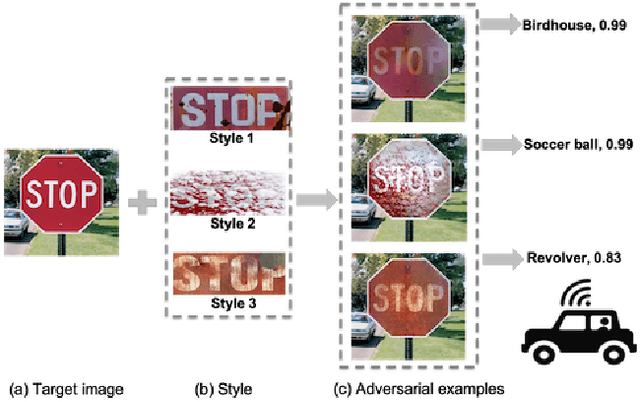
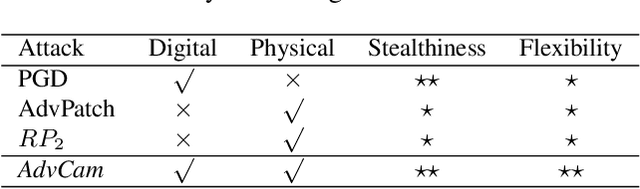

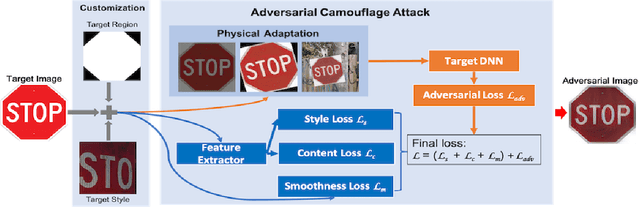
Deep neural networks (DNNs) are known to be vulnerable to adversarial examples. Existing works have mostly focused on either digital adversarial examples created via small and imperceptible perturbations, or physical-world adversarial examples created with large and less realistic distortions that are easily identified by human observers. In this paper, we propose a novel approach, called Adversarial Camouflage (\emph{AdvCam}), to craft and camouflage physical-world adversarial examples into natural styles that appear legitimate to human observers. Specifically, \emph{AdvCam} transfers large adversarial perturbations into customized styles, which are then "hidden" on-target object or off-target background. Experimental evaluation shows that, in both digital and physical-world scenarios, adversarial examples crafted by \emph{AdvCam} are well camouflaged and highly stealthy, while remaining effective in fooling state-of-the-art DNN image classifiers. Hence, \emph{AdvCam} is a flexible approach that can help craft stealthy attacks to evaluate the robustness of DNNs. \emph{AdvCam} can also be used to protect private information from being detected by deep learning systems.
Deep Semantic Ranking Based Hashing for Multi-Label Image Retrieval
Apr 19, 2015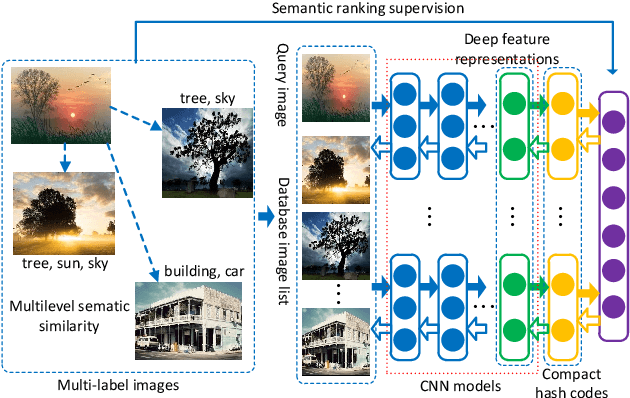
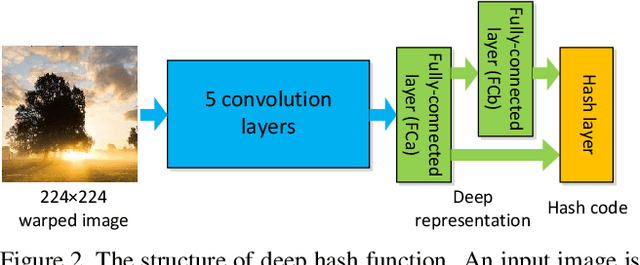
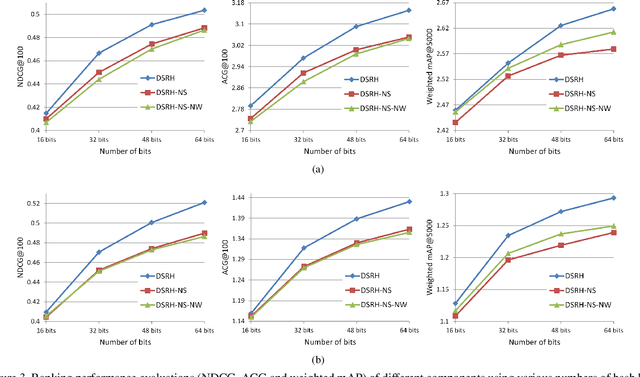
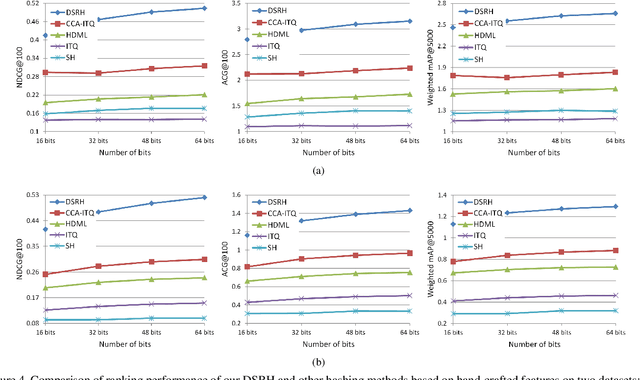
With the rapid growth of web images, hashing has received increasing interests in large scale image retrieval. Research efforts have been devoted to learning compact binary codes that preserve semantic similarity based on labels. However, most of these hashing methods are designed to handle simple binary similarity. The complex multilevel semantic structure of images associated with multiple labels have not yet been well explored. Here we propose a deep semantic ranking based method for learning hash functions that preserve multilevel semantic similarity between multi-label images. In our approach, deep convolutional neural network is incorporated into hash functions to jointly learn feature representations and mappings from them to hash codes, which avoids the limitation of semantic representation power of hand-crafted features. Meanwhile, a ranking list that encodes the multilevel similarity information is employed to guide the learning of such deep hash functions. An effective scheme based on surrogate loss is used to solve the intractable optimization problem of nonsmooth and multivariate ranking measures involved in the learning procedure. Experimental results show the superiority of our proposed approach over several state-of-the-art hashing methods in term of ranking evaluation metrics when tested on multi-label image datasets.
Knowledge Distillation for Brain Tumor Segmentation
Feb 10, 2020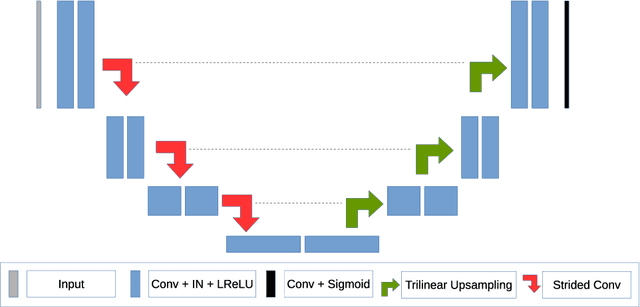
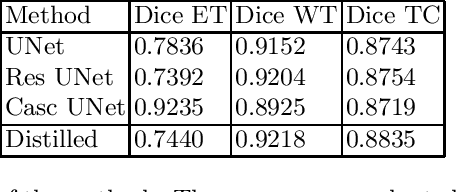
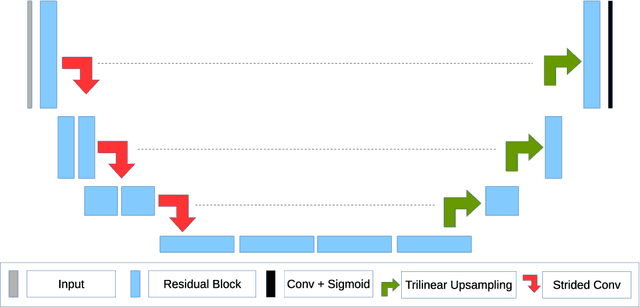
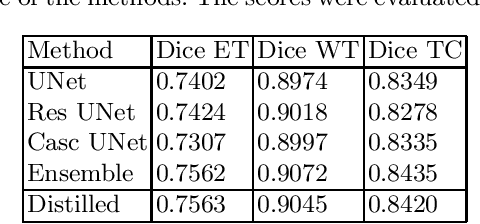
The segmentation of brain tumors in multimodal MRIs is one of the most challenging tasks in medical image analysis. The recent state of the art algorithms solving this task is based on machine learning approaches and deep learning in particular. The amount of data used for training such models and its variability is a keystone for building an algorithm with high representation power. In this paper, we study the relationship between the performance of the model and the amount of data employed during the training process. On the example of brain tumor segmentation challenge, we compare the model trained with labeled data provided by challenge organizers, and the same model trained in omni-supervised manner using additional unlabeled data annotated with the ensemble of heterogeneous models. As a result, a single model trained with additional data achieves performance close to the ensemble of multiple models and outperforms individual methods.
Object-Oriented Video Captioning with Temporal Graph and Prior Knowledge Building
Mar 08, 2020

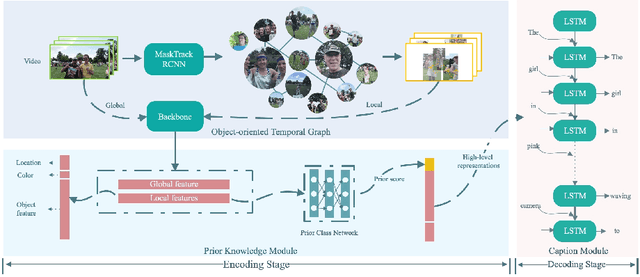

Traditional video captioning requests a holistic description of the video, yet the detailed descriptions of the specific objects may not be available. Besides, most methods adopt frame-level inter-object features and ambiguous descriptions during training, which is difficult for learning the vision-language relationships. Without associating the transition trajectories, these image-based methods cannot understand the activities with visual features. We propose a novel task, named object-oriented video captioning, which focuses on understanding the videos in object-level. We re-annotate the object-sentence pairs for more effective cross-modal learning. Thereafter, we design the video-based object-oriented video captioning (OVC)-Net to reliably analyze the activities along time with only visual features and capture the vision-language connections under small datasets stably. To demonstrate the effectiveness, we evaluate the method on the new dataset and compare it with the state-of-the-arts for video captioning. From the experimental results, the OVC-Net exhibits the ability of precisely describing the concurrent objects and their activities in details.
Increasing the Inference and Learning Speed of Tsetlin Machines with Clause Indexing
Apr 07, 2020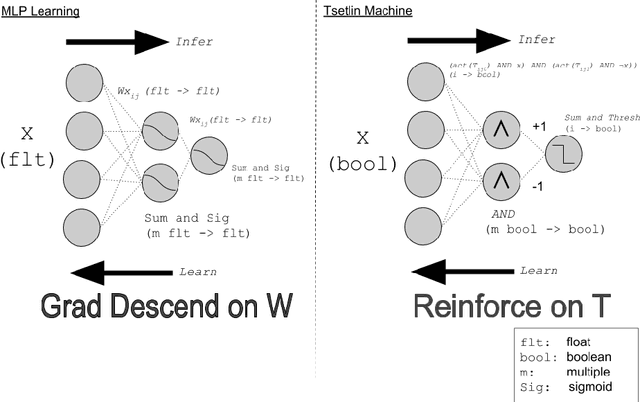
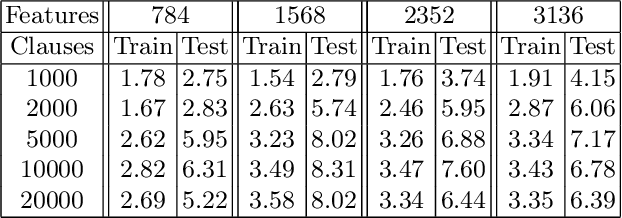
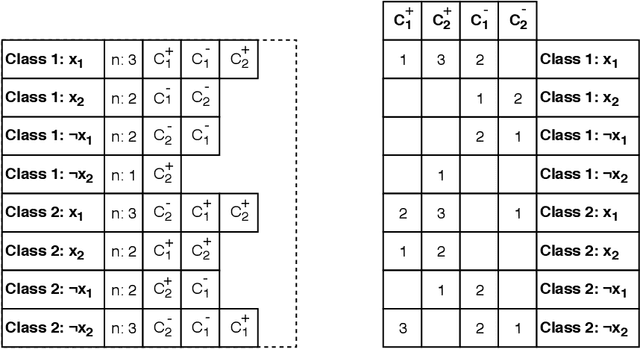
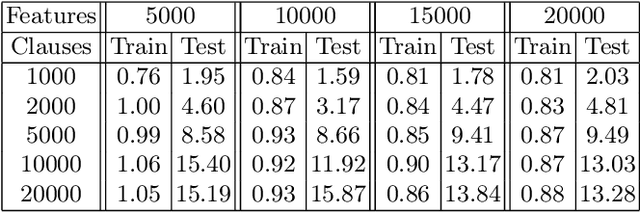
The Tsetlin Machine (TM) is a machine learning algorithm founded on the classical Tsetlin Automaton (TA) and game theory. It further leverages frequent pattern mining and resource allocation principles to extract common patterns in the data, rather than relying on minimizing output error, which is prone to overfitting. Unlike the intertwined nature of pattern representation in neural networks, a TM decomposes problems into self-contained patterns, represented as conjunctive clauses. The clause outputs, in turn, are combined into a classification decision through summation and thresholding, akin to a logistic regression function, however, with binary weights and a unit step output function. In this paper, we exploit this hierarchical structure by introducing a novel algorithm that avoids evaluating the clauses exhaustively. Instead we use a simple look-up table that indexes the clauses on the features that falsify them. In this manner, we can quickly evaluate a large number of clauses through falsification, simply by iterating through the features and using the look-up table to eliminate those clauses that are falsified. The look-up table is further structured so that it facilitates constant time updating, thus supporting use also during learning. We report up to 15 times faster classification and three times faster learning on MNIST and Fashion-MNIST image classification, and IMDb sentiment analysis.
Image Super-Resolution via Dual-Dictionary Learning And Sparse Representation
Aug 18, 2012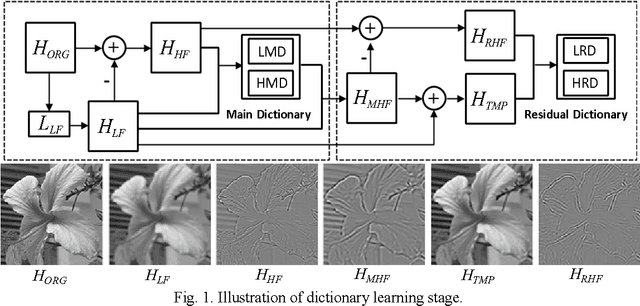
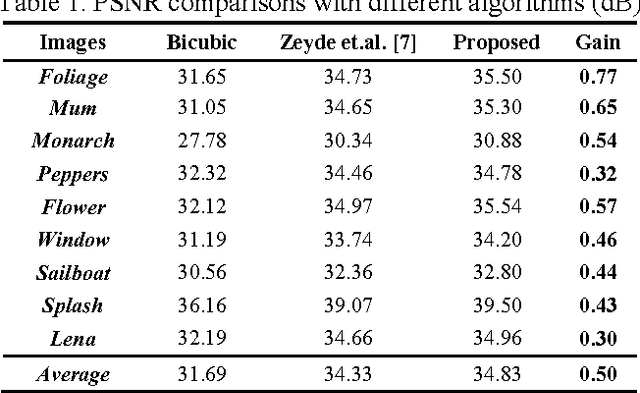
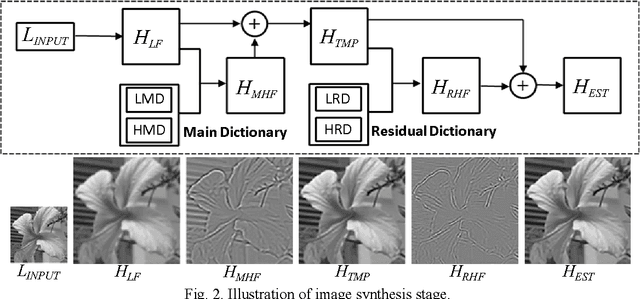
Learning-based image super-resolution aims to reconstruct high-frequency (HF) details from the prior model trained by a set of high- and low-resolution image patches. In this paper, HF to be estimated is considered as a combination of two components: main high-frequency (MHF) and residual high-frequency (RHF), and we propose a novel image super-resolution method via dual-dictionary learning and sparse representation, which consists of the main dictionary learning and the residual dictionary learning, to recover MHF and RHF respectively. Extensive experimental results on test images validate that by employing the proposed two-layer progressive scheme, more image details can be recovered and much better results can be achieved than the state-of-the-art algorithms in terms of both PSNR and visual perception.
The Effects of Image Pre- and Post-Processing, Wavelet Decomposition, and Local Binary Patterns on U-Nets for Skin Lesion Segmentation
Apr 30, 2018

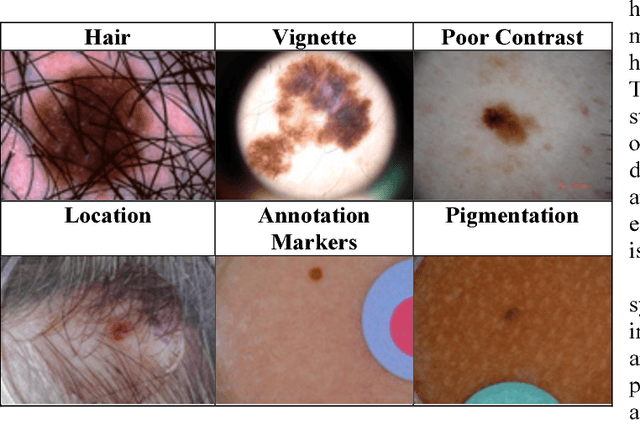

Skin cancer is a widespread, global, and potentially deadly disease, which over the last three decades has afflicted more lives in the USA than all other forms of cancer combined. There have been a lot of promising recent works utilizing deep network architectures, such as FCNs, U-Nets, and ResNets, for developing automated skin lesion segmentation. This paper investigates various pre- and post-processing techniques for improving the performance of U-Nets as measured by the Jaccard Index. The dataset provided as part of the "2017 ISBI Challenges on Skin Lesion Analysis Towards Melanoma Detection" was used for this evaluation and the performance of the finalist competitors was the standard for comparison. The pre-processing techniques employed in the proposed system included contrast enhancement, artifact removal, and vignette correction. More advanced image transformations, such as local binary patterns and wavelet decomposition, were also employed to augment the raw grayscale images used as network input features. While the performance of the proposed system fell short of the winners of the challenge, it was determined that using wavelet decomposition as an early transformation step improved the overall performance of the system over pre- and post-processing steps alone.
Statistical models and regularization strategies in statistical image reconstruction of low-dose X-ray CT: a survey
May 14, 2015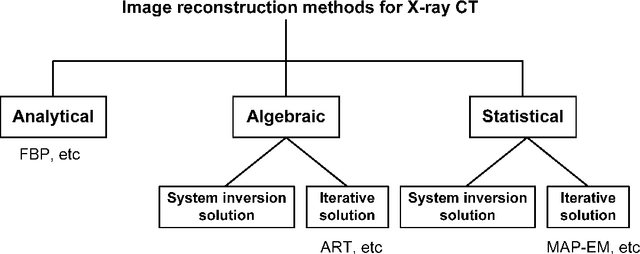

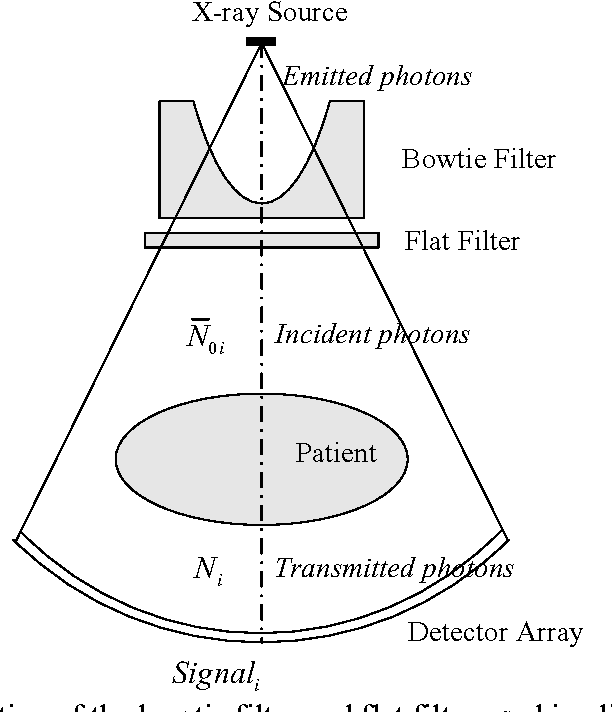

Statistical image reconstruction (SIR) methods have shown potential to substantially improve the image quality of low-dose X-ray computed tomography (CT) as compared to the conventional filtered back-projection (FBP) method for various clinical tasks. According to the maximum a posterior (MAP) estimation, the SIR methods can be typically formulated by an objective function consisting of two terms: (1) data-fidelity (or equivalently, data-fitting or data-mismatch) term modeling the statistics of projection measurements, and (2) regularization (or equivalently, prior or penalty) term reflecting prior knowledge or expectation on the characteristics of the image to be reconstructed. Existing SIR methods for low-dose CT can be divided into two groups: (1) those that use calibrated transmitted photon counts (before log-transform) with penalized maximum likelihood (pML) criterion, and (2) those that use calibrated line-integrals (after log-transform) with penalized weighted least-squares (PWLS) criterion. Accurate statistical modeling of the projection measurements is a prerequisite for SIR, while the regularization term in the objective function also plays a critical role for successful image reconstruction. This paper reviews several statistical models on CT projection measurements and various regularization strategies incorporating prior knowledge or expected properties of the image to be reconstructed, which together formulate the objective function of the SIR methods for low-dose X-ray CT.