 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Super-Resolution of PROBA-V Images Using Convolutional Neural Networks
Jul 03, 2019
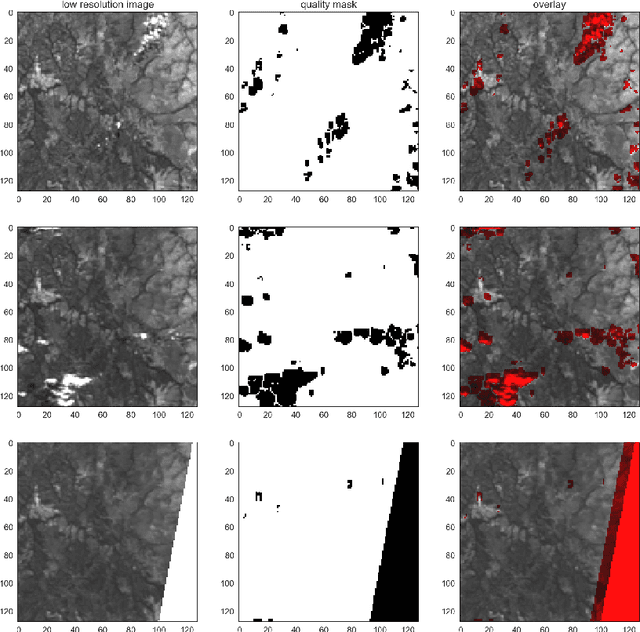
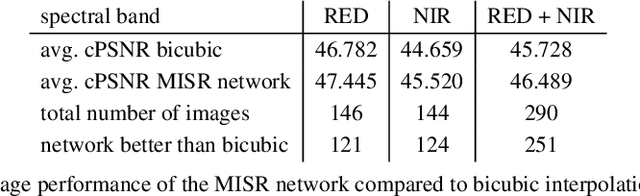
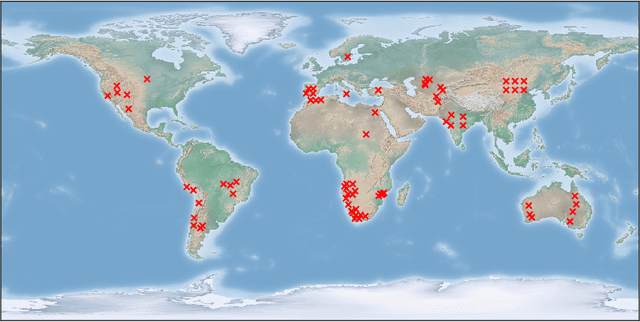
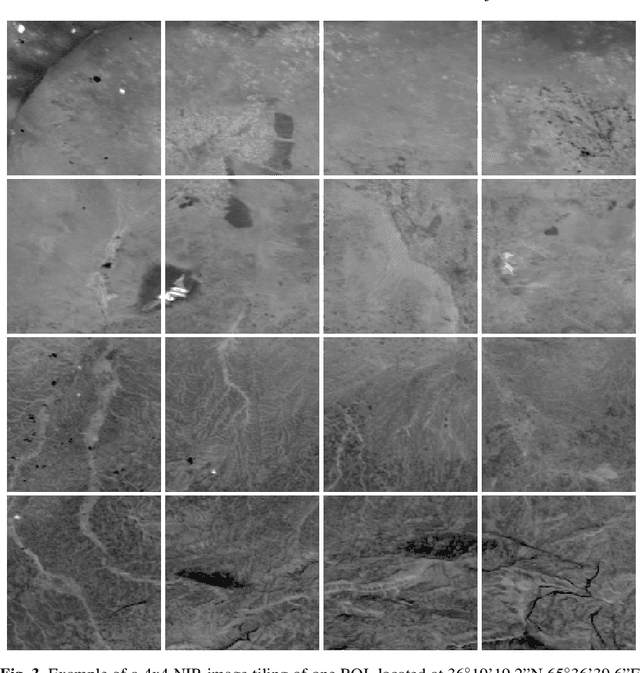
ESA's PROBA-V Earth observation satellite enables us to monitor our planet at a large scale, studying the interaction between vegetation and climate and provides guidance for important decisions on our common global future. However, the interval at which high resolution images are recorded spans over several days, in contrast to the availability of lower resolution images which is often daily. We collect an extensive dataset of both, high and low resolution images taken by PROBA-V instruments during monthly periods to investigate Multi Image Super-resolution, a technique to merge several low resolution images to one image of higher quality. We propose a convolutional neural network that is able to cope with changes in illumination, cloud coverage and landscape features which are challenges introduced by the fact that the different images are taken over successive satellite passages over the same region. Given a bicubic upscaling of low resolution images taken under optimal conditions, we find the Peak Signal to Noise Ratio of the reconstructed image of the network to be higher for a large majority of different scenes. This shows that applied machine learning has the potential to enhance large amounts of previously collected earth observation data during multiple satellite passes.
The Effects of Image Pre- and Post-Processing, Wavelet Decomposition, and Local Binary Patterns on U-Nets for Skin Lesion Segmentation
Apr 30, 2018

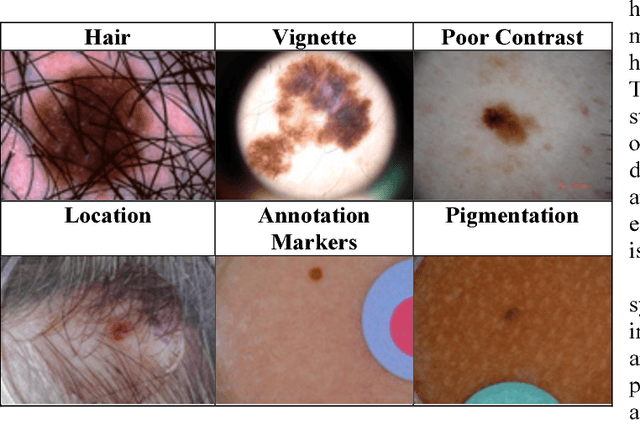

Skin cancer is a widespread, global, and potentially deadly disease, which over the last three decades has afflicted more lives in the USA than all other forms of cancer combined. There have been a lot of promising recent works utilizing deep network architectures, such as FCNs, U-Nets, and ResNets, for developing automated skin lesion segmentation. This paper investigates various pre- and post-processing techniques for improving the performance of U-Nets as measured by the Jaccard Index. The dataset provided as part of the "2017 ISBI Challenges on Skin Lesion Analysis Towards Melanoma Detection" was used for this evaluation and the performance of the finalist competitors was the standard for comparison. The pre-processing techniques employed in the proposed system included contrast enhancement, artifact removal, and vignette correction. More advanced image transformations, such as local binary patterns and wavelet decomposition, were also employed to augment the raw grayscale images used as network input features. While the performance of the proposed system fell short of the winners of the challenge, it was determined that using wavelet decomposition as an early transformation step improved the overall performance of the system over pre- and post-processing steps alone.
SVD Based Image Processing Applications: State of The Art, Contributions and Research Challenges
Nov 29, 2012


Singular Value Decomposition (SVD) has recently emerged as a new paradigm for processing different types of images. SVD is an attractive algebraic transform for image processing applications. The paper proposes an experimental survey for the SVD as an efficient transform in image processing applications. Despite the well-known fact that SVD offers attractive properties in imaging, the exploring of using its properties in various image applications is currently at its infancy. Since the SVD has many attractive properties have not been utilized, this paper contributes in using these generous properties in newly image applications and gives a highly recommendation for more research challenges. In this paper, the SVD properties for images are experimentally presented to be utilized in developing new SVD-based image processing applications. The paper offers survey on the developed SVD based image applications. The paper also proposes some new contributions that were originated from SVD properties analysis in different image processing. The aim of this paper is to provide a better understanding of the SVD in image processing and identify important various applications and open research directions in this increasingly important area; SVD based image processing in the future research.
ECG-DelNet: Delineation of Ambulatory Electrocardiograms with Mixed Quality Labeling Using Neural Networks
May 11, 2020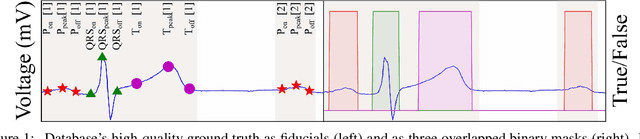
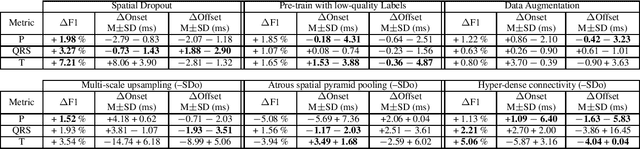
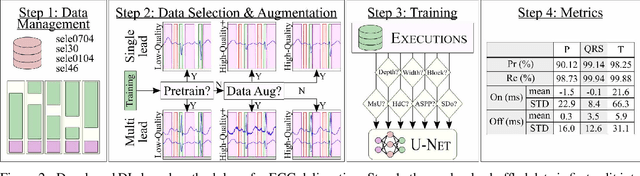
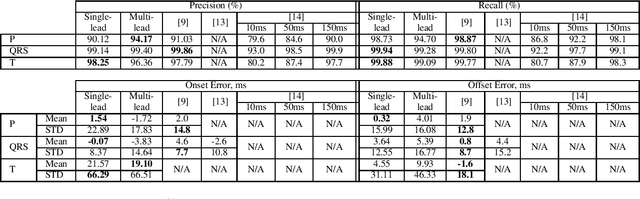
Electrocardiogram (ECG) detection and delineation are key steps for numerous tasks in clinical practice, as ECG is the most performed non-invasive test for assessing cardiac condition. State-of-the-art algorithms employ digital signal processing (DSP), which require laborious rule adaptation to new morphologies. In contrast, deep learning (DL) algorithms, especially for classification, are gaining weight in academic and industrial settings. However, the lack of model explainability and small databases hinder their applicability. We demonstrate DL can be successfully applied to low interpretative tasks by embedding ECG detection and delineation onto a segmentation framework. For this purpose, we adapted and validated the most used neural network architecture for image segmentation, the U-Net, to one-dimensional data. The model was trained using PhysioNet's QT database, comprised of 105 ambulatory ECG recordings, for single- and multi-lead scenarios. To alleviate data scarcity, data regularization techniques such as pre-training with low-quality data labels, performing ECG-based data augmentation and applying strong model regularizers to the architecture were attempted. Other variations in the model's capacity (U-Net's depth and width), alongside the application of state-of-the-art additions, were evaluated. These variations were exhaustively validated in a 5-fold cross-validation manner. The best performing configuration reached precisions of 90.12%, 99.14% and 98.25% and recalls of 98.73%, 99.94% and 99.88% for the P, QRS and T waves, respectively, on par with DSP-based approaches. Despite being a data-hungry technique trained on a small dataset, DL-based approaches demonstrate to be a viable alternative to traditional DSP-based ECG processing techniques.
Robust Full-FoV Depth Estimation in Tele-wide Camera System
Oct 18, 2019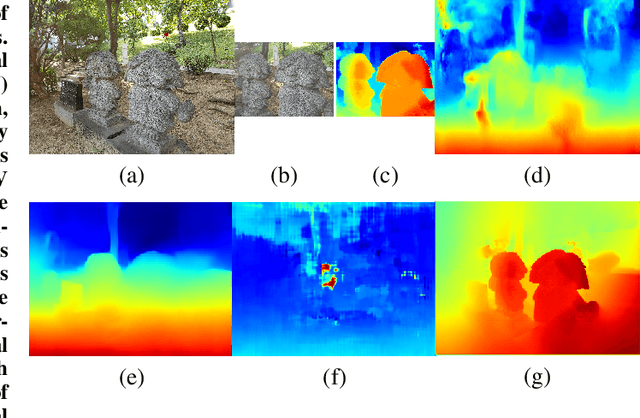
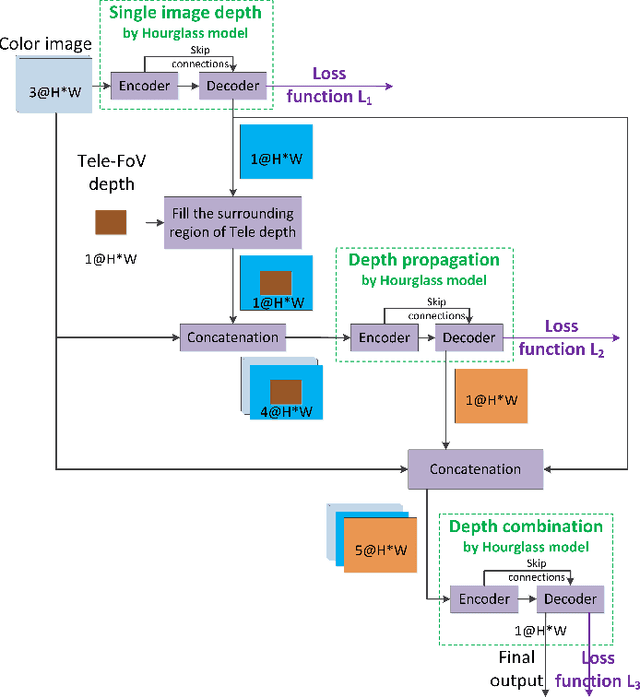
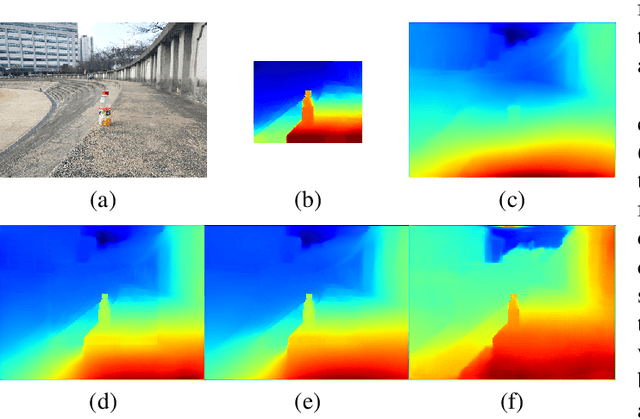
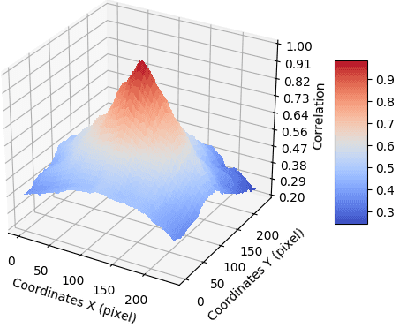
Tele-wide camera system with different Field of View (FoV) lenses becomes very popular in recent mobile devices. Usually it is difficult to obtain full-FoV depth based on traditional stereo-matching methods. Pure Deep Neural Network (DNN) based depth estimation methods can obtain full-FoV depth, but have low robustness for scenarios which are not covered by training dataset. In this paper, to address the above problems we propose a hierarchical hourglass network for robust full-FoV depth estimation in tele-wide camera system, which combines the robustness of traditional stereo-matching methods with the accuracy of DNN. More specifically, the proposed network comprises three major modules: single image depth prediction module infers initial depth from input color image, depth propagation module propagates traditional stereo-matching tele-FoV depth to surrounding regions, and depth combination module fuses the initial depth with the propagated depth to generate final output. Each of these modules employs an hourglass model, which is a kind of encoder-decoder structure with skip connections. Experimental results compared with state-of-the-art depth estimation methods demonstrate that our method not only produces robust and better subjective depth quality on wild test images, but also obtains better quantitative results on standard datasets.
Neuron Linear Transformation: Modeling the Domain Shift for Crowd Counting
Apr 05, 2020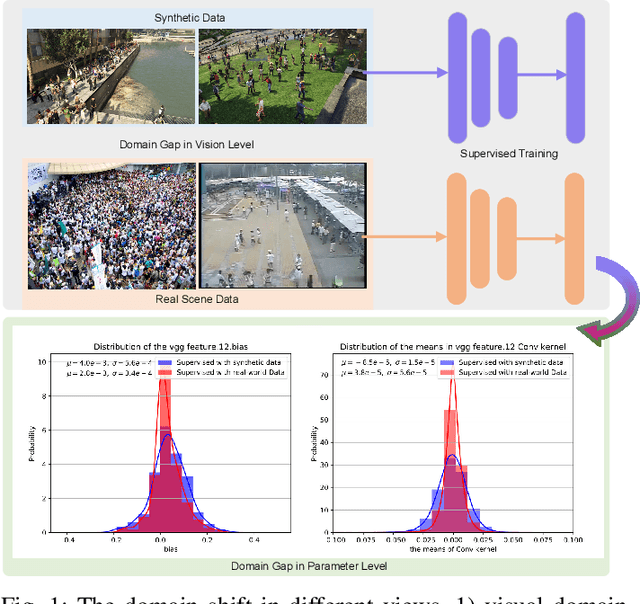
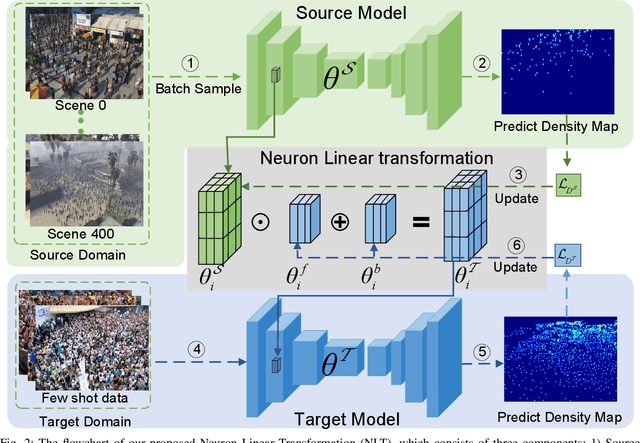
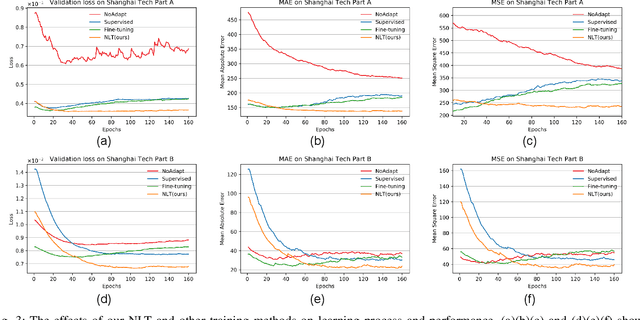
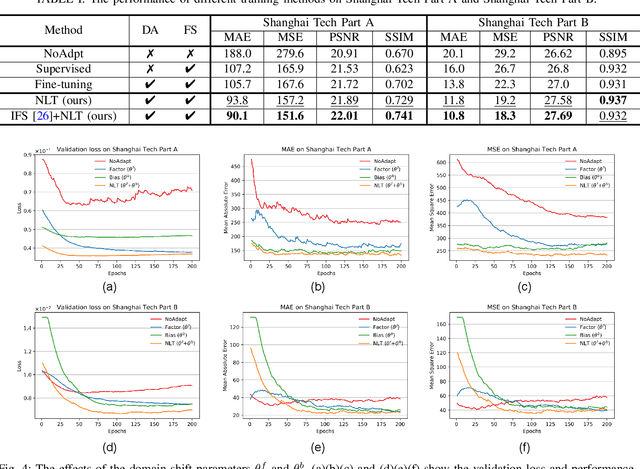
Cross-domain crowd counting (CDCC) is a hot topic due to its importance in public safety. The purpose of CDCC is to reduce the domain shift between the source and target domain. Recently, typical methods attempt to extract domain-invariant features via image translation and adversarial learning. When it comes to specific tasks, we find that the final manifestation of the task gap is in the parameters of the model, and the domain shift can be represented apparently by the differences in model weights. To describe the domain gap directly at the parameter-level, we propose a Neuron Linear Transformation (NLT) method, where NLT is exploited to learn the shift at neuron-level and then transfer the source model to the target model. Specifically, for a specific neuron of a source model, NLT exploits few labeled target data to learn a group of parameters, which updates the target neuron via a linear transformation. Extensive experiments and analysis on six real-world datasets validate that NLT achieves top performance compared with other domain adaptation methods. An ablation study also shows that the NLT is robust and more effective compare with supervised and fine-tune training. Furthermore, we will release the code after the paper is accepted.
Multi-Task Learning from Videos via Efficient Inter-Frame Attention
Feb 18, 2020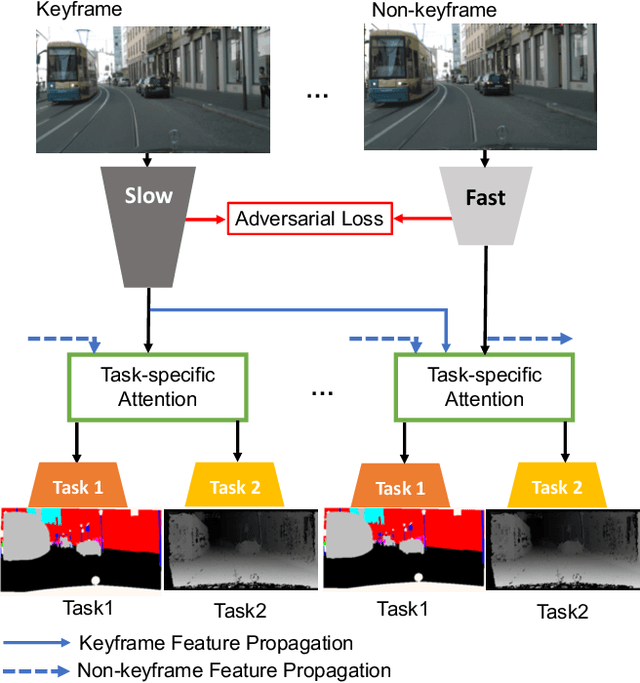
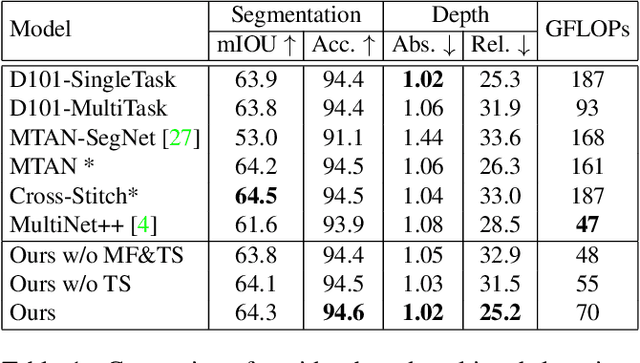
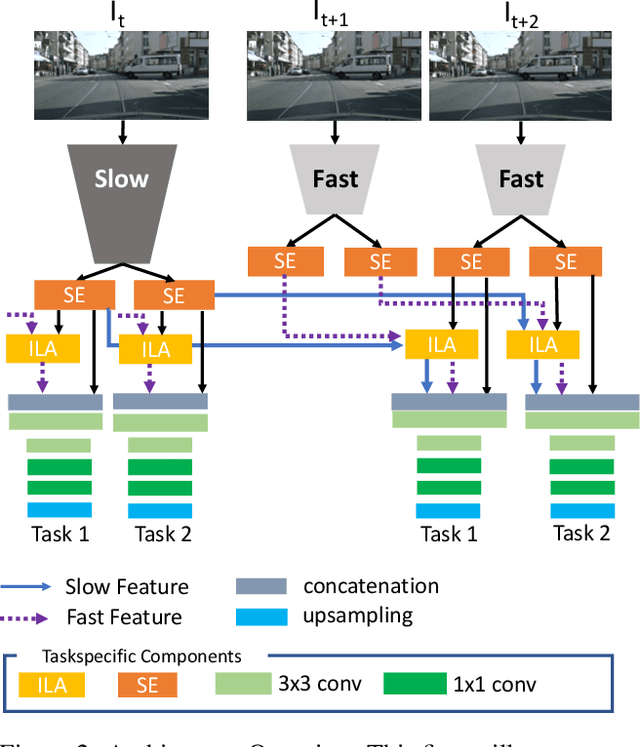
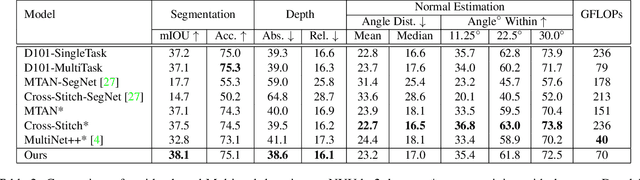
Prior work in multi-task learning has mainly focused on predictions on a single image. In this work, we present a new approach for multi-task learning from videos. Our approach contains a novel inter-frame attention module which allows learning of task-specific attention across frames. We embed the attention module in a "slow-fast" architecture, where the slower network runs on sparsely sampled keyframes and the lightweight shallow network runs on non-key frames at a high frame rate. We further propose an effective adversarial learning strategy to encourage the slow and fast network to learn similar features. The proposed architecture ensures low-latency multi-task learning while maintaining high quality prediction. Experiments show competitive accuracy compared to state-of-the-art on two multi-task learning benchmarks while reducing the number of floating point operations (FLOPs) by 70%. Meanwhile, our attention based feature propagation outperforms other feature propagation methods in accuracy by up to 90% reduction of FLOPs.
Selective Style Transfer for Text
Jun 04, 2019

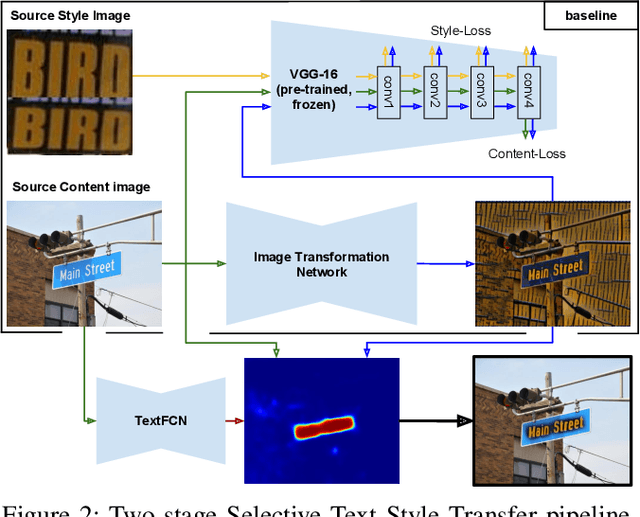
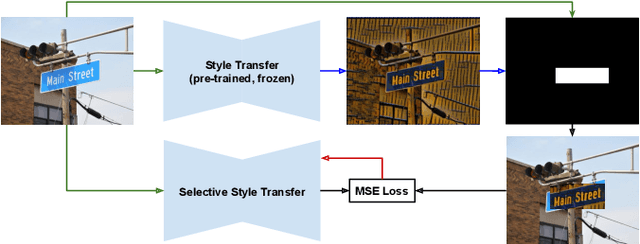
This paper explores the possibilities of image style transfer applied to text maintaining the original transcriptions. Results on different text domains (scene text, machine printed text and handwritten text) and cross modal results demonstrate that this is feasible, and open different research lines. Furthermore, two architectures for selective style transfer, which means transferring style to only desired image pixels, are proposed. Finally, scene text selective style transfer is evaluated as a data augmentation technique to expand scene text detection datasets, resulting in a boost of text detectors performance. Our implementation of the described models is publicly available.
Anisotropic Convolutional Networks for 3D Semantic Scene Completion
Apr 05, 2020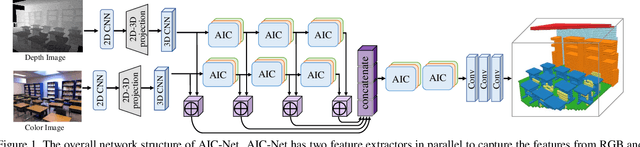
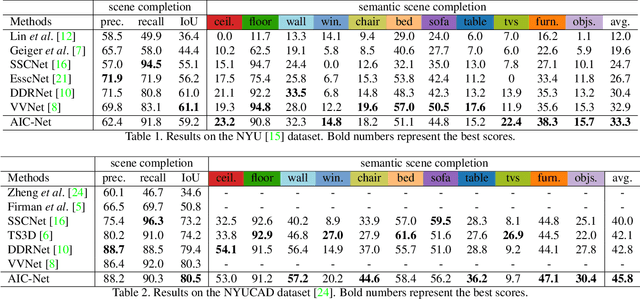
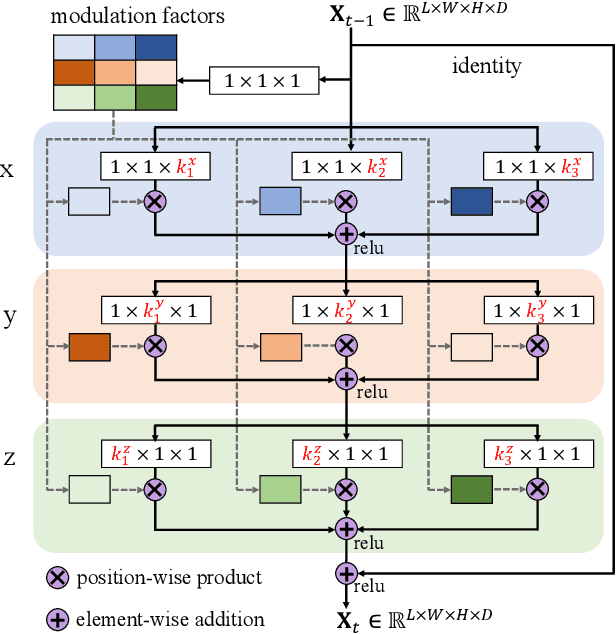
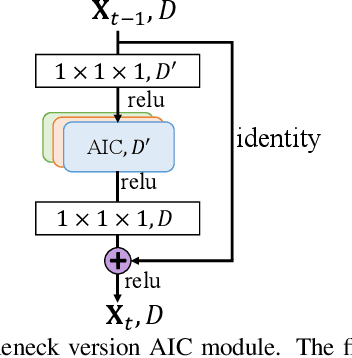
As a voxel-wise labeling task, semantic scene completion (SSC) tries to simultaneously infer the occupancy and semantic labels for a scene from a single depth and/or RGB image. The key challenge for SSC is how to effectively take advantage of the 3D context to model various objects or stuffs with severe variations in shapes, layouts and visibility. To handle such variations, we propose a novel module called anisotropic convolution, which properties with flexibility and power impossible for the competing methods such as standard 3D convolution and some of its variations. In contrast to the standard 3D convolution that is limited to a fixed 3D receptive field, our module is capable of modeling the dimensional anisotropy voxel-wisely. The basic idea is to enable anisotropic 3D receptive field by decomposing a 3D convolution into three consecutive 1D convolutions, and the kernel size for each such 1D convolution is adaptively determined on the fly. By stacking multiple such anisotropic convolution modules, the voxel-wise modeling capability can be further enhanced while maintaining a controllable amount of model parameters. Extensive experiments on two SSC benchmarks, NYU-Depth-v2 and NYUCAD, show the superior performance of the proposed method. Our code is available at https://waterljwant.github.io/SSC/
A Comparative Study of Computational Aesthetics
Nov 19, 2018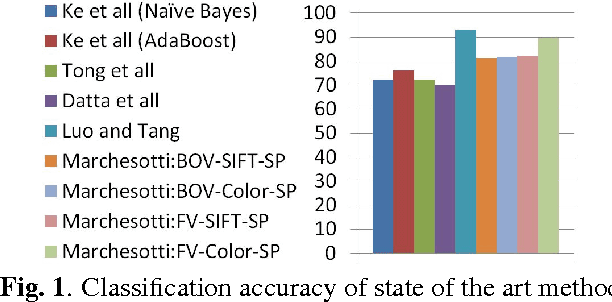
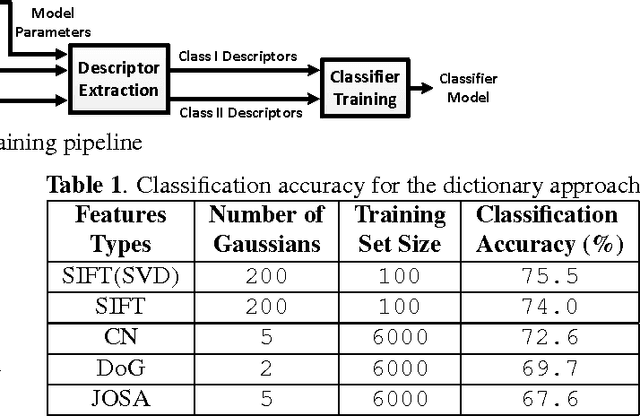
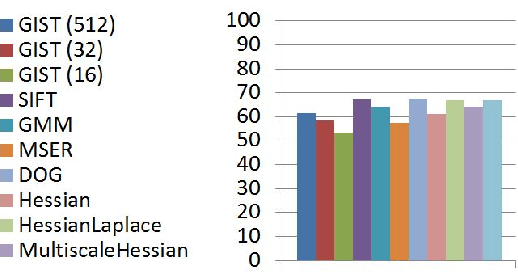
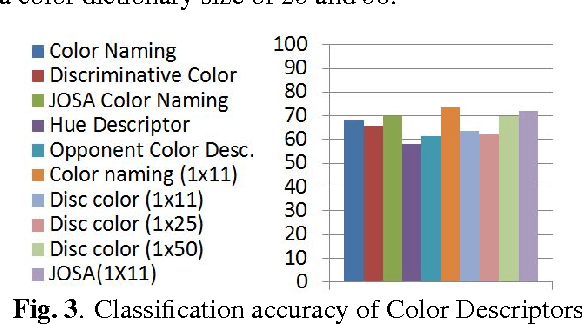
Objective metrics model image quality by quantifying image degradations or estimating perceived image quality. However, image quality metrics do not model what makes an image more appealing or beautiful. In order to quantify the aesthetics of an image, we need to take it one step further and model the perception of aesthetics. In this paper, we examine computational aesthetics models that use hand-crafted, generic and hybrid descriptors. We show that generic descriptors can perform as well as state of the art hand-crafted aesthetics models that use global features. However, neither generic nor hand-crafted features is sufficient to model aesthetics when we only use global features without considering spatial composition or distribution. We also follow a visual dictionary approach similar to state of the art methods and show that it performs poorly without the spatial pyramid step.
* 6 pages, 5 figures, 1 table