 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Convolutional Forward and Back-Projection Model for Fan-Beam Geometry
Jul 24, 2019
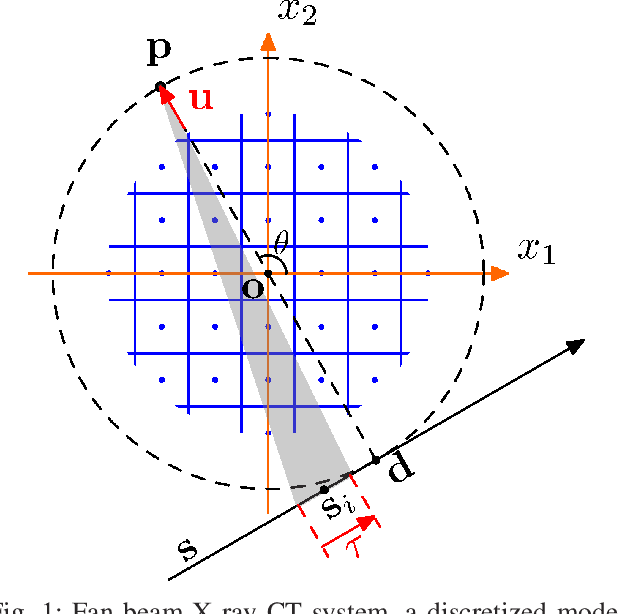
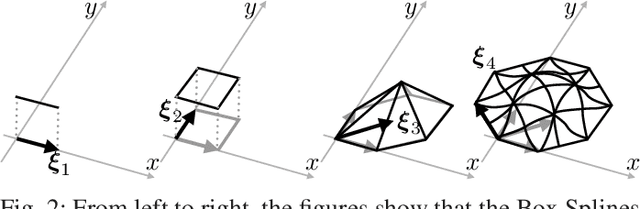
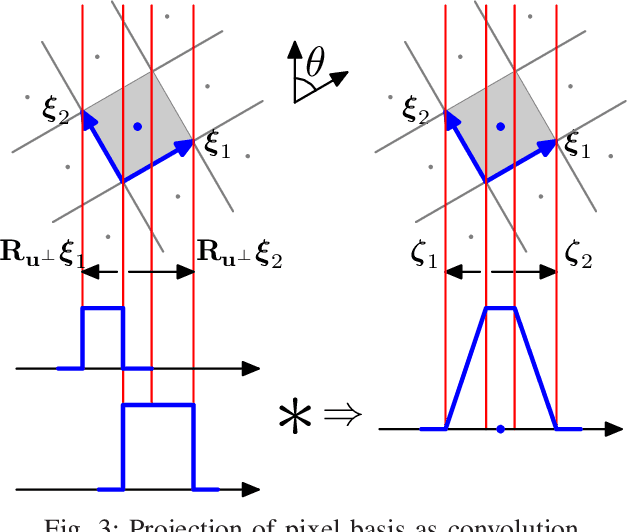
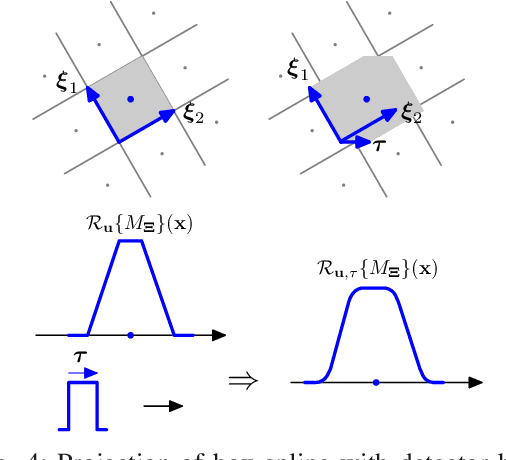
Iterative methods for tomographic image reconstruction have great potential for enabling high quality imaging from low-dose projection data. The computational burden of iterative reconstruction algorithms, however, has been an impediment in their adoption in practical CT reconstruction problems. We present an approach for highly efficient and accurate computation of forward model for image reconstruction in fan-beam geometry in X-ray CT. The efficiency of computations makes this approach suitable for large-scale optimization algorithms with on-the-fly, memory-less, computations of the forward and back-projection. Our experiments demonstrate the improvements in accuracy as well as efficiency of our model, specifically for first-order box splines (i.e., pixel-basis) compared to recently developed methods for this purpose, namely Look-up Table-based Ray Integration (LTRI) and Separable Footprints (SF) in 2-D.
Bit-Scalable Deep Hashing with Regularized Similarity Learning for Image Retrieval and Person Re-identification
Aug 21, 2015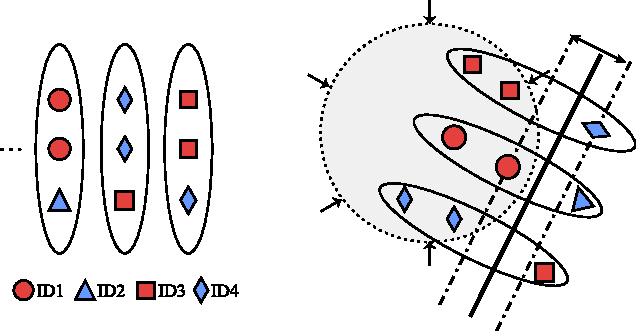
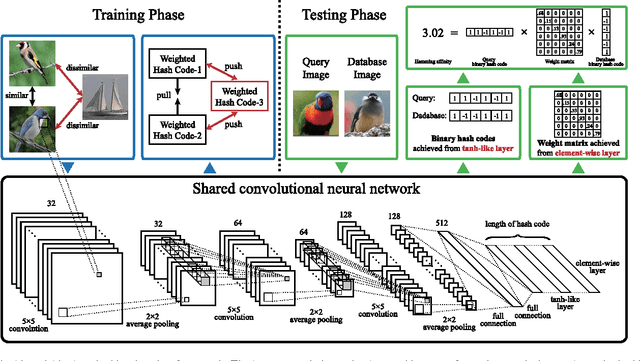

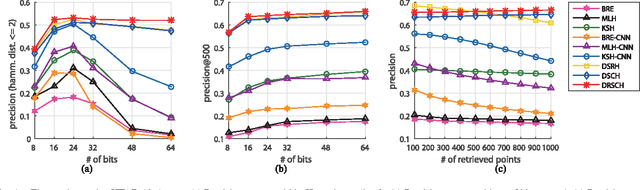
Extracting informative image features and learning effective approximate hashing functions are two crucial steps in image retrieval . Conventional methods often study these two steps separately, e.g., learning hash functions from a predefined hand-crafted feature space. Meanwhile, the bit lengths of output hashing codes are preset in most previous methods, neglecting the significance level of different bits and restricting their practical flexibility. To address these issues, we propose a supervised learning framework to generate compact and bit-scalable hashing codes directly from raw images. We pose hashing learning as a problem of regularized similarity learning. Specifically, we organize the training images into a batch of triplet samples, each sample containing two images with the same label and one with a different label. With these triplet samples, we maximize the margin between matched pairs and mismatched pairs in the Hamming space. In addition, a regularization term is introduced to enforce the adjacency consistency, i.e., images of similar appearances should have similar codes. The deep convolutional neural network is utilized to train the model in an end-to-end fashion, where discriminative image features and hash functions are simultaneously optimized. Furthermore, each bit of our hashing codes is unequally weighted so that we can manipulate the code lengths by truncating the insignificant bits. Our framework outperforms state-of-the-arts on public benchmarks of similar image search and also achieves promising results in the application of person re-identification in surveillance. It is also shown that the generated bit-scalable hashing codes well preserve the discriminative powers with shorter code lengths.
Video from Stills: Lensless Imaging with Rolling Shutter
May 30, 2019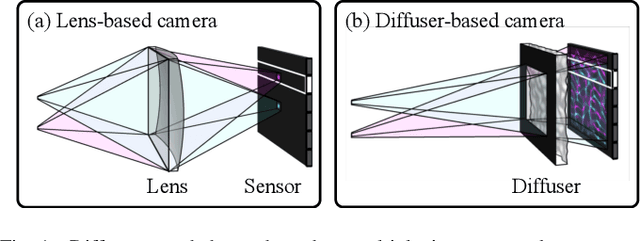

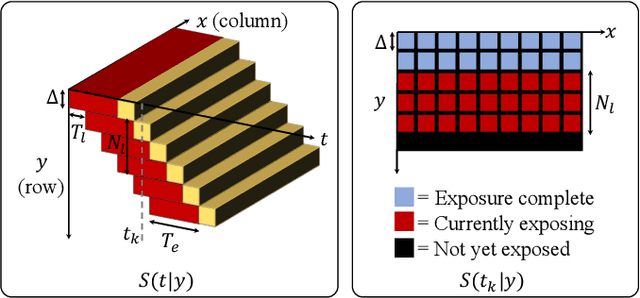
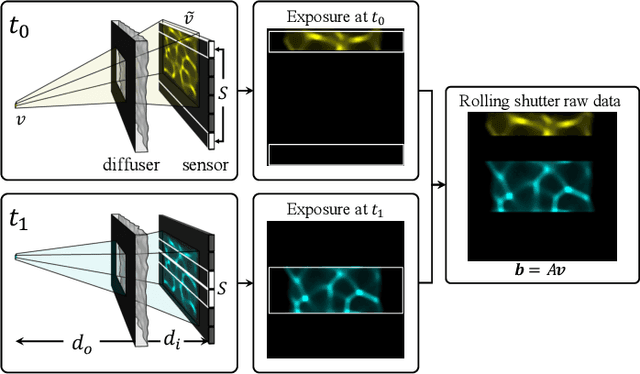
Because image sensor chips have a finite bandwidth with which to read out pixels, recording video typically requires a trade-off between frame rate and pixel count. Compressed sensing techniques can circumvent this trade-off by assuming that the image is compressible. Here, we propose using multiplexing optics to spatially compress the scene, enabling information about the whole scene to be sampled from a row of sensor pixels, which can be read off quickly via a rolling shutter CMOS sensor. Conveniently, such multiplexing can be achieved with a simple lensless, diffuser-based imaging system. Using sparse recovery methods, we are able to recover 140 video frames at over 4,500 frames per second, all from a single captured image with a rolling shutter sensor. Our proof-of-concept system uses easily-fabricated diffusers paired with an off-the-shelf sensor. The resulting prototype enables compressive encoding of high frame rate video into a single rolling shutter exposure, and exceeds the sampling-limited performance of an equivalent global shutter system for sufficiently sparse objects.
Enhancing high-content imaging for studying microtubule networks at large-scale
Oct 01, 2019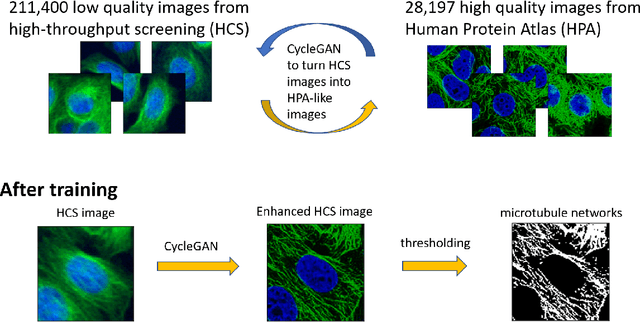
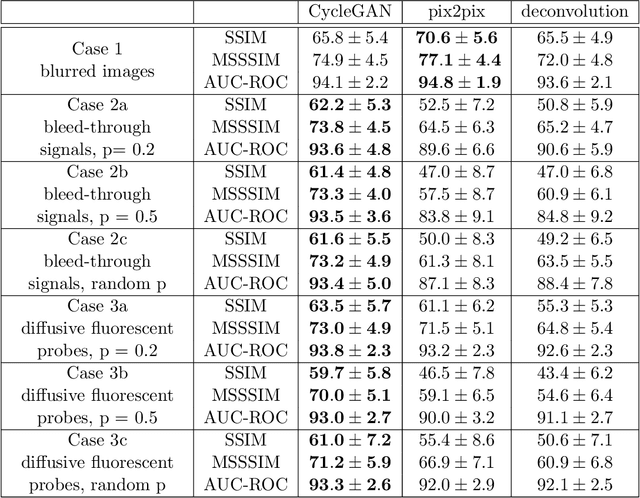
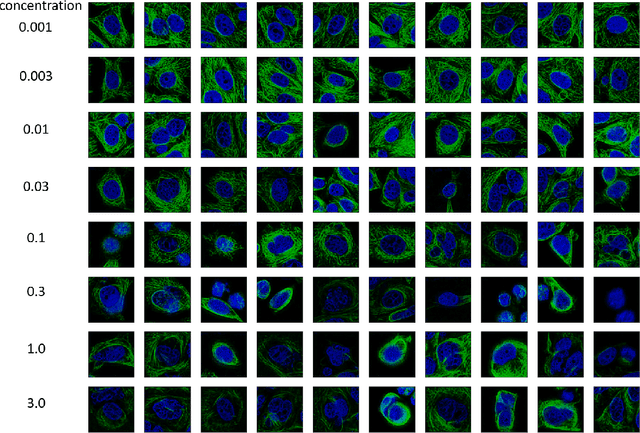
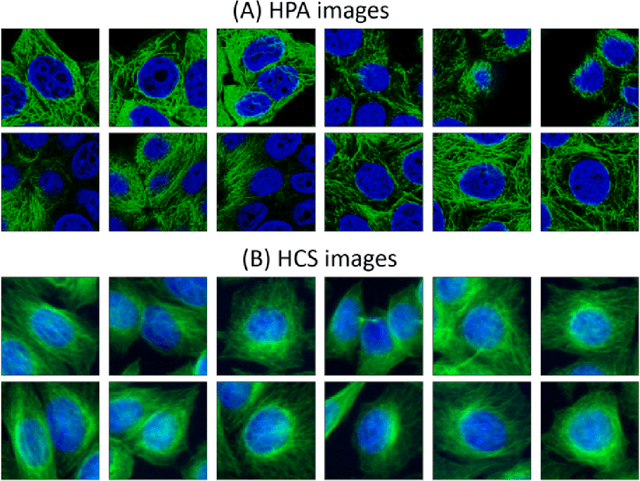
Given the crucial role of microtubules for cell survival, many researchers have found success using microtubule-targeting agents in the search for effective cancer therapeutics. Understanding microtubule responses to targeted interventions requires that the microtubule network within cells can be consistently observed across a large sample of images. However, fluorescence noise sources captured simultaneously with biological signals while using wide-field microscopes can obfuscate fine microtubule structures. Such requirements are particularly challenging for high-throughput imaging, where researchers must make decisions related to the trade-off between imaging quality and speed. Here, we propose a computational framework to enhance the quality of high-throughput imaging data to achieve fast speed and high quality simultaneously. Using CycleGAN, we learn an image model from low-throughput, high-resolution images to enhance features, such as microtubule networks in high-throughput low-resolution images. We show that CycleGAN is effective in identifying microtubules with 0.93+ AUC-ROC and that these results are robust to different kinds of image noise. We further apply CycleGAN to quantify the changes in microtubule density as a result of the application of drug compounds, and show that the quantified responses correspond well with known drug effects
Target-Independent Domain Adaptation for WBC Classification using Generative Latent Search
May 11, 2020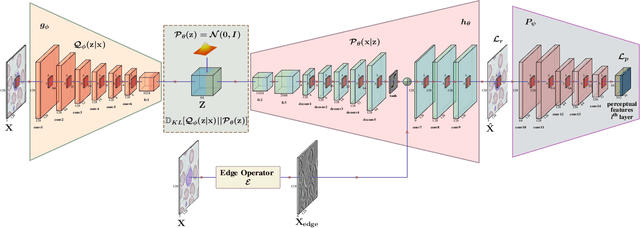
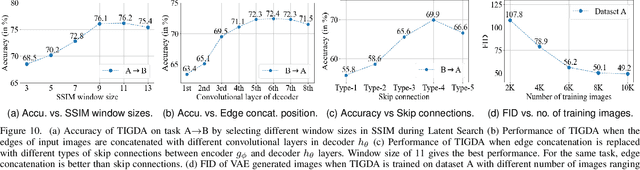
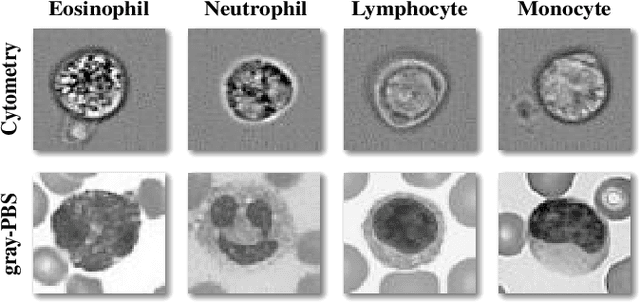
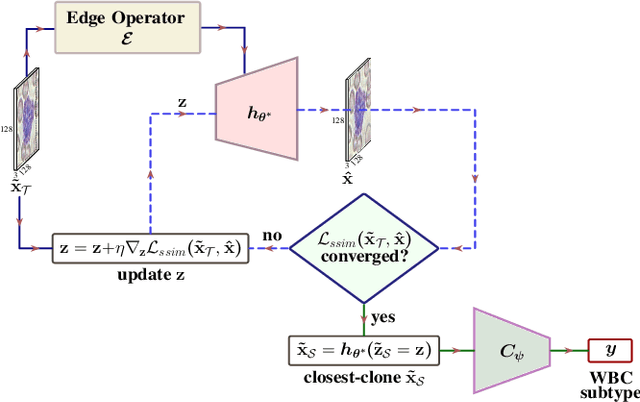
Automating the classification of camera-obtained microscopic images of White Blood Cells (WBCs) and related cell subtypes has assumed importance since it aids the laborious manual process of review and diagnosis. Several State-Of-The-Art (SOTA) methods developed using Deep Convolutional Neural Networks suffer from the problem of domain shift - severe performance degradation when they are tested on data (target) obtained in a setting different from that of the training (source). The change in the target data might be caused by factors such as differences in camera/microscope types, lenses, lighting-conditions etc. This problem can potentially be solved using Unsupervised Domain Adaptation (UDA) techniques albeit standard algorithms presuppose the existence of a sufficient amount of unlabelled target data which is not always the case with medical images. In this paper, we propose a method for UDA that is devoid of the need for target data. Given a test image from the target data, we obtain its 'closest-clone' from the source data that is used as a proxy in the classifier. We prove the existence of such a clone given that infinite number of data points can be sampled from the source distribution. We propose a method in which a latent-variable generative model based on variational inference is used to simultaneously sample and find the 'closest-clone' from the source distribution through an optimization procedure in the latent space. We demonstrate the efficacy of the proposed method over several SOTA UDA methods for WBC classification on datasets captured using different imaging modalities under multiple settings.
A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities
May 30, 2019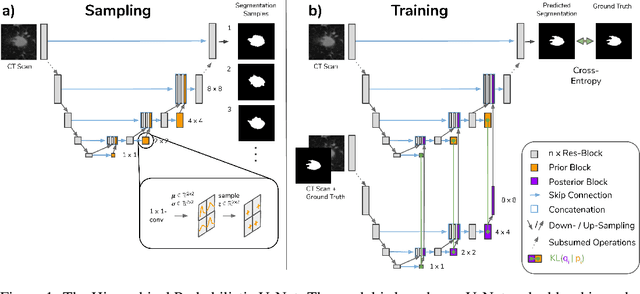
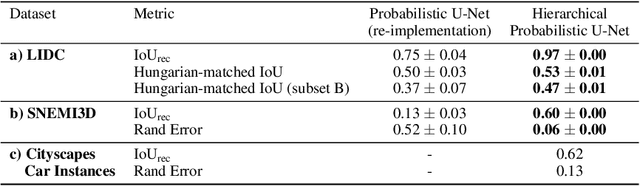
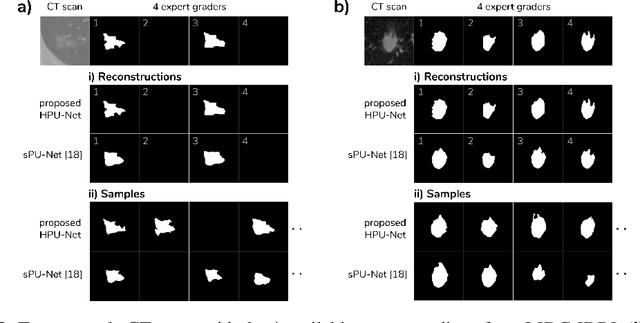

Medical imaging only indirectly measures the molecular identity of the tissue within each voxel, which often produces only ambiguous image evidence for target measures of interest, like semantic segmentation. This diversity and the variations of plausible interpretations are often specific to given image regions and may thus manifest on various scales, spanning all the way from the pixel to the image level. In order to learn a flexible distribution that can account for multiple scales of variations, we propose the Hierarchical Probabilistic U-Net, a segmentation network with a conditional variational auto-encoder (cVAE) that uses a hierarchical latent space decomposition. We show that this model formulation enables sampling and reconstruction of segmenations with high fidelity, i.e. with finely resolved detail, while providing the flexibility to learn complex structured distributions across scales. We demonstrate these abilities on the task of segmenting ambiguous medical scans as well as on instance segmentation of neurobiological and natural images. Our model automatically separates independent factors across scales, an inductive bias that we deem beneficial in structured output prediction tasks beyond segmentation.
Decentralized SGD with Over-the-Air Computation
Mar 06, 2020
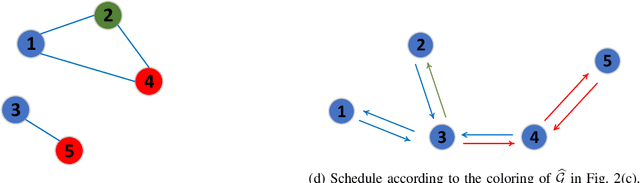
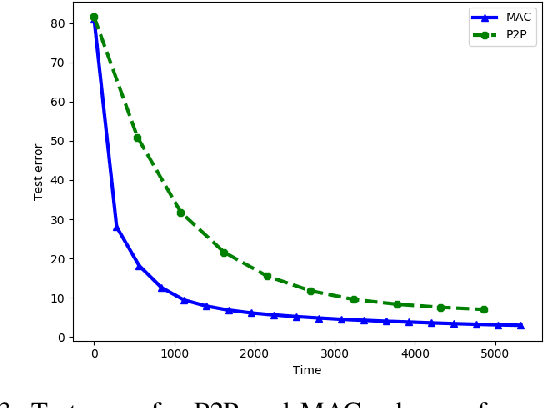
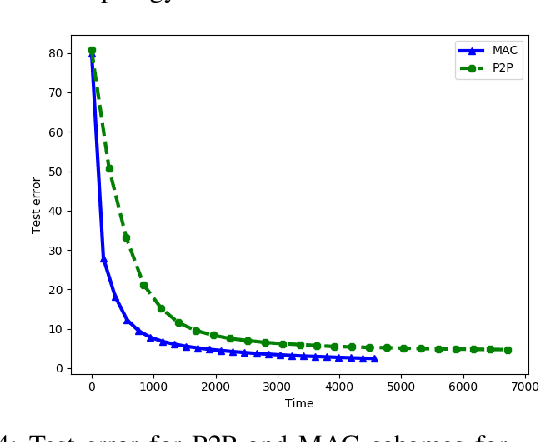
We study the performance of decentralized stochastic gradient descent (DSGD) in a wireless network, where the nodes collaboratively optimize an objective function using their local datasets. Unlike the conventional setting, where the nodes communicate over error-free orthogonal communication links, we assume that transmissions are prone to additive noise and interference.We first consider a point-to-point (P2P) transmission strategy, termed the OAC-P2P scheme, in which the node pairs are scheduled in an orthogonal fashion to minimize interference. Since in the DSGD framework, each node requires a linear combination of the neighboring models at the consensus step, we then propose the OAC-MAC scheme, which utilizes the signal superposition property of the wireless medium to achieve over-the-air computation (OAC). For both schemes, we cast the scheduling problem as a graph coloring problem. We numerically evaluate the performance of these two schemes for the MNIST image classification task under various network conditions. We show that the OAC-MAC scheme attains better convergence performance with a fewer communication rounds.
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Feb 18, 2020
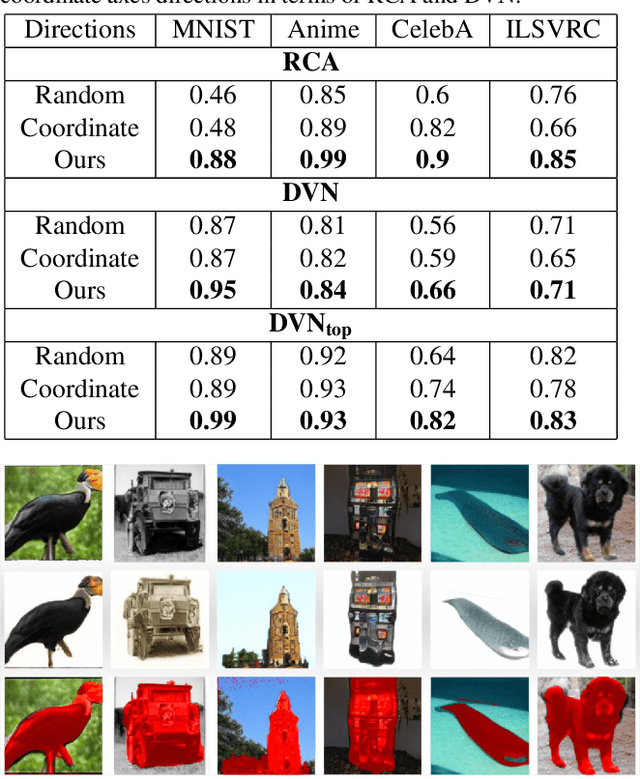


The latent spaces of typical GAN models often have semantically meaningful directions. Moving in these directions corresponds to human-interpretable image transformations, such as zooming or recoloring, enabling a more controllable generation process. However, the discovery of such directions is currently performed in a supervised manner, requiring human labels, pretrained models, or some form of self-supervision. These requirements can severely limit a range of directions existing approaches can discover. In this paper, we introduce an unsupervised method to identify interpretable directions in the latent space of a pretrained GAN model. By a simple model-agnostic procedure, we find directions corresponding to sensible semantic manipulations without any form of (self-)supervision. Furthermore, we reveal several non-trivial findings, which would be difficult to obtain by existing methods, e.g., a direction corresponding to background removal. As an immediate practical benefit of our work, we show how to exploit this finding to achieve a new state-of-the-art for the problem of saliency detection.
Weakly Supervised Instance Segmentation by Deep Multi-Task Community Learning
Jan 30, 2020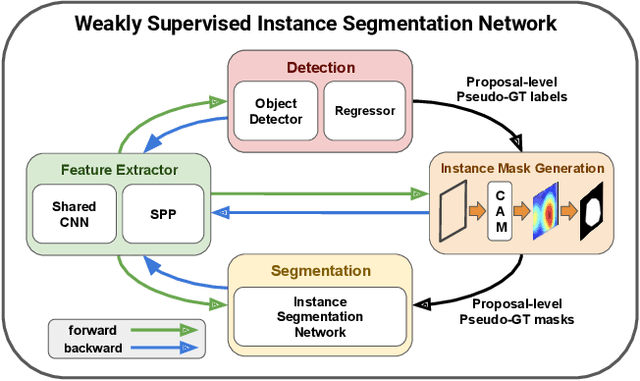
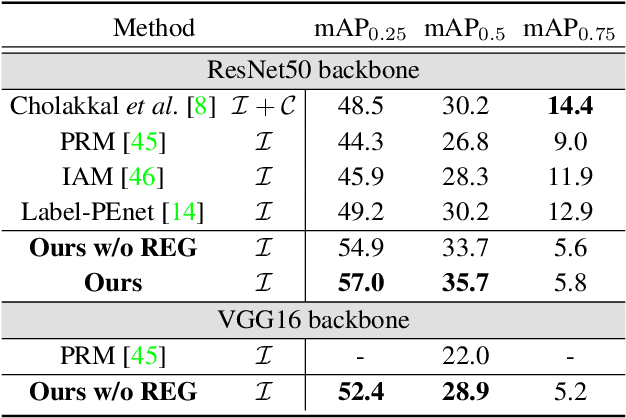
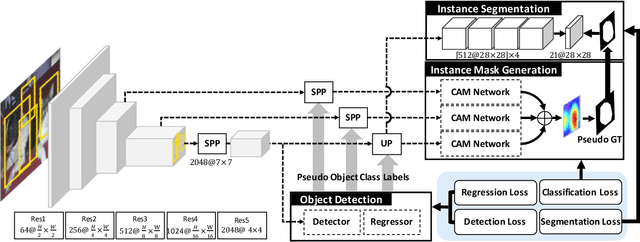
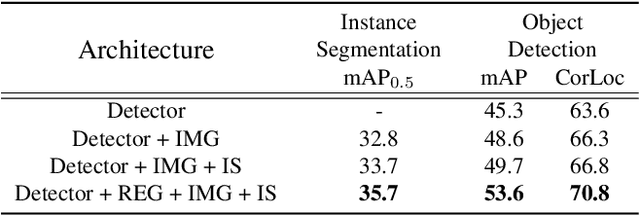
We present an object segmentation algorithm based on community learning for multiple tasks under the supervision of image-level class labels only, where individual instances of the same class are identified and segmented separately. This problem is formulated as a combination of weakly supervised object detection and semantic segmentation and is addressed by designing a unified deep neural network architecture, which has a positive feedback loop of object detection with bounding box regression, instance mask generation, instance segmentation, and feature extraction. Each component of the network makes active interactions with others to improve accuracy, and the end-to-end trainability of our model makes our results more reproducible. The proposed algorithm achieves competitive accuracy in the weakly supervised setting without any external components such as Fast R-CNN and Mask R-CNN on the standard benchmark dataset.
ECG-DelNet: Delineation of Ambulatory Electrocardiograms with Mixed Quality Labeling Using Neural Networks
May 11, 2020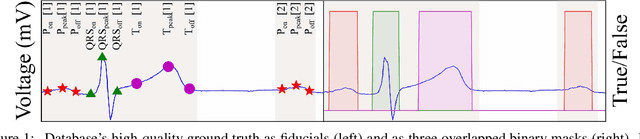
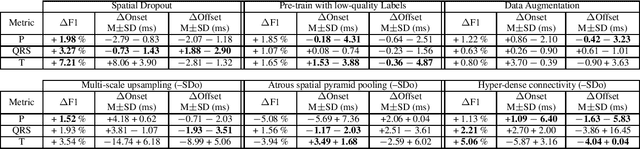
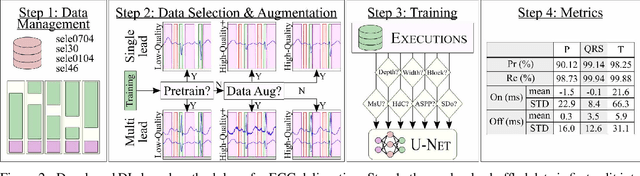
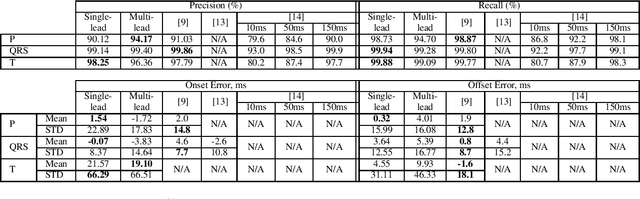
Electrocardiogram (ECG) detection and delineation are key steps for numerous tasks in clinical practice, as ECG is the most performed non-invasive test for assessing cardiac condition. State-of-the-art algorithms employ digital signal processing (DSP), which require laborious rule adaptation to new morphologies. In contrast, deep learning (DL) algorithms, especially for classification, are gaining weight in academic and industrial settings. However, the lack of model explainability and small databases hinder their applicability. We demonstrate DL can be successfully applied to low interpretative tasks by embedding ECG detection and delineation onto a segmentation framework. For this purpose, we adapted and validated the most used neural network architecture for image segmentation, the U-Net, to one-dimensional data. The model was trained using PhysioNet's QT database, comprised of 105 ambulatory ECG recordings, for single- and multi-lead scenarios. To alleviate data scarcity, data regularization techniques such as pre-training with low-quality data labels, performing ECG-based data augmentation and applying strong model regularizers to the architecture were attempted. Other variations in the model's capacity (U-Net's depth and width), alongside the application of state-of-the-art additions, were evaluated. These variations were exhaustively validated in a 5-fold cross-validation manner. The best performing configuration reached precisions of 90.12%, 99.14% and 98.25% and recalls of 98.73%, 99.94% and 99.88% for the P, QRS and T waves, respectively, on par with DSP-based approaches. Despite being a data-hungry technique trained on a small dataset, DL-based approaches demonstrate to be a viable alternative to traditional DSP-based ECG processing techniques.