 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-domain Object Detection through Coarse-to-Fine Feature Adaptation
Mar 23, 2020
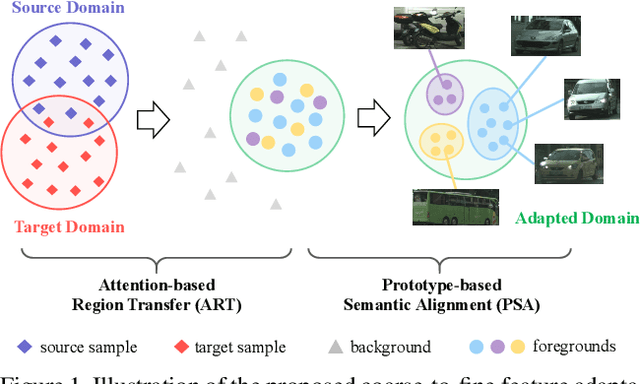
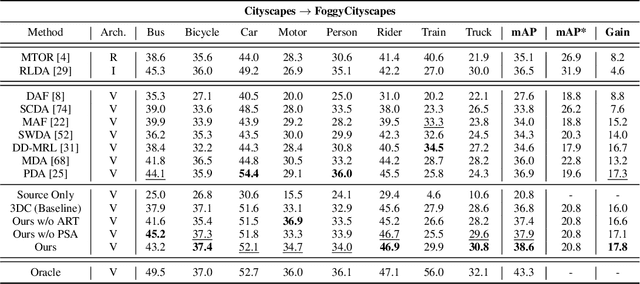
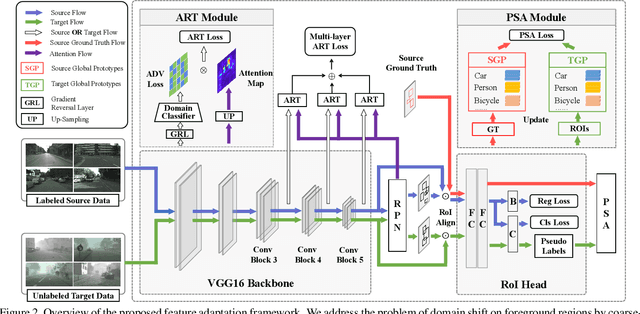
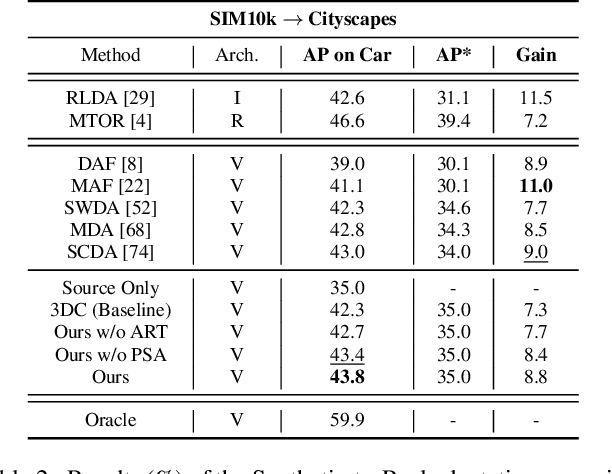
Recent years have witnessed great progress in deep learning based object detection. However, due to the domain shift problem, applying off-the-shelf detectors to an unseen domain leads to significant performance drop. To address such an issue, this paper proposes a novel coarse-to-fine feature adaptation approach to cross-domain object detection. At the coarse-grained stage, different from the rough image-level or instance-level feature alignment used in the literature, foreground regions are extracted by adopting the attention mechanism, and aligned according to their marginal distributions via multi-layer adversarial learning in the common feature space. At the fine-grained stage, we conduct conditional distribution alignment of foregrounds by minimizing the distance of global prototypes with the same category but from different domains. Thanks to this coarse-to-fine feature adaptation, domain knowledge in foreground regions can be effectively transferred. Extensive experiments are carried out in various cross-domain detection scenarios. The results are state-of-the-art, which demonstrate the broad applicability and effectiveness of the proposed approach.
Learning to Detect Head Movement in Unconstrained Remote Gaze Estimation in the Wild
Apr 07, 2020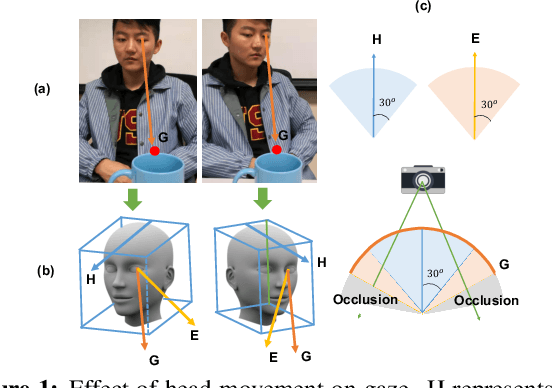
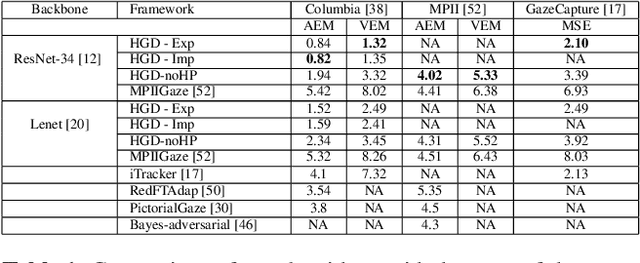
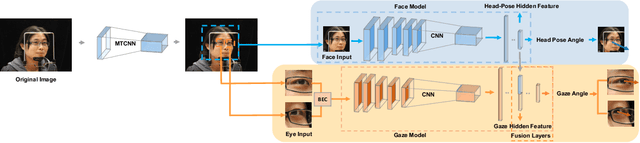
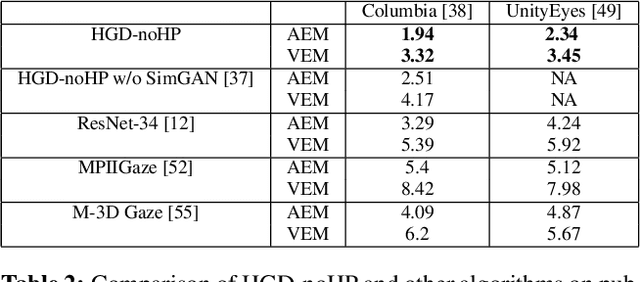
Unconstrained remote gaze estimation remains challenging mostly due to its vulnerability to the large variability in head-pose. Prior solutions struggle to maintain reliable accuracy in unconstrained remote gaze tracking. Among them, appearance-based solutions demonstrate tremendous potential in improving gaze accuracy. However, existing works still suffer from head movement and are not robust enough to handle real-world scenarios. Especially most of them study gaze estimation under controlled scenarios where the collected datasets often cover limited ranges of both head-pose and gaze which introduces further bias. In this paper, we propose novel end-to-end appearance-based gaze estimation methods that could more robustly incorporate different levels of head-pose representations into gaze estimation. Our method could generalize to real-world scenarios with low image quality, different lightings and scenarios where direct head-pose information is not available. To better demonstrate the advantage of our methods, we further propose a new benchmark dataset with the most rich distribution of head-gaze combination reflecting real-world scenarios. Extensive evaluations on several public datasets and our own dataset demonstrate that our method consistently outperforms the state-of-the-art by a significant margin.
A Real-Time Deep Network for Crowd Counting
Feb 16, 2020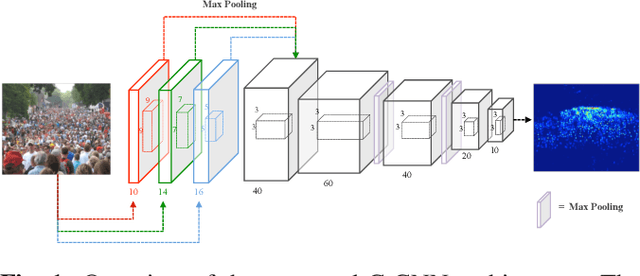
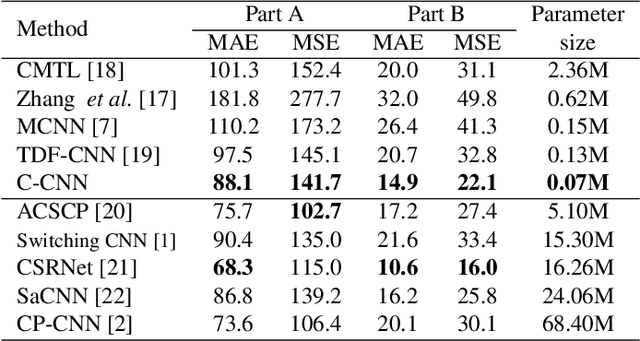
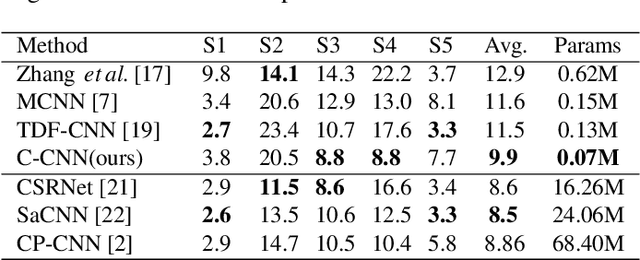

Automatic analysis of highly crowded people has attracted extensive attention from computer vision research. Previous approaches for crowd counting have already achieved promising performance across various benchmarks. However, to deal with the real situation, we hope the model run as fast as possible while keeping accuracy. In this paper, we propose a compact convolutional neural network for crowd counting which learns a more efficient model with a small number of parameters. With three parallel filters executing the convolutional operation on the input image simultaneously at the front of the network, our model could achieve nearly real-time speed and save more computing resources. Experiments on two benchmarks show that our proposed method not only takes a balance between performance and efficiency which is more suitable for actual scenes but also is superior to existing light-weight models in speed.
Extracting dispersion curves from ambient noise correlations using deep learning
Feb 05, 2020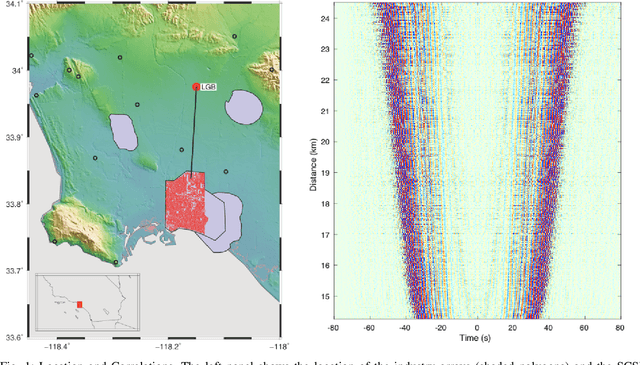
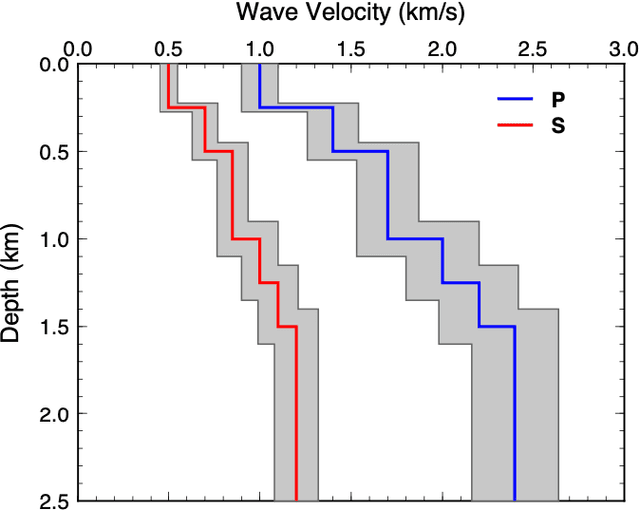
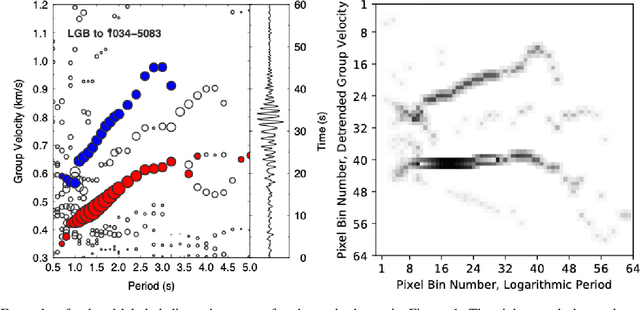
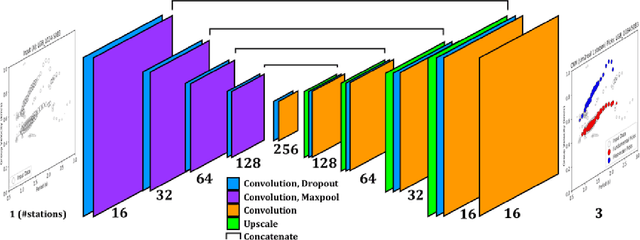
We present a machine-learning approach to classifying the phases of surface wave dispersion curves. Standard FTAN analysis of surfaces observed on an array of receivers is converted to an image, of which, each pixel is classified as fundamental mode, first overtone, or noise. We use a convolutional neural network (U-net) architecture with a supervised learning objective and incorporate transfer learning. The training is initially performed with synthetic data to learn coarse structure, followed by fine-tuning of the network using approximately 10% of the real data based on human classification. The results show that the machine classification is nearly identical to the human picked phases. Expanding the method to process multiple images at once did not improve the performance. The developed technique will faciliate automated processing of large dispersion curve datasets.
Block Randomized Optimization for Adaptive Hypergraph Learning
Aug 22, 2019
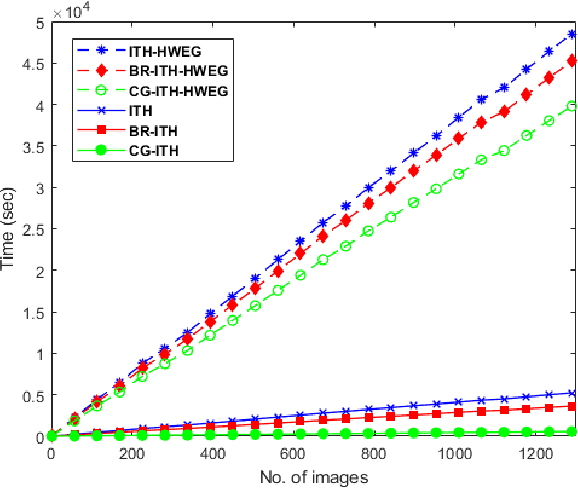
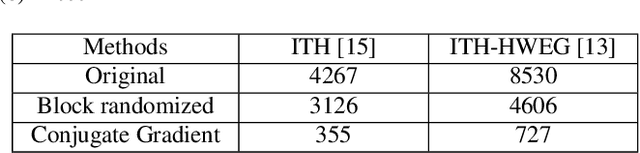
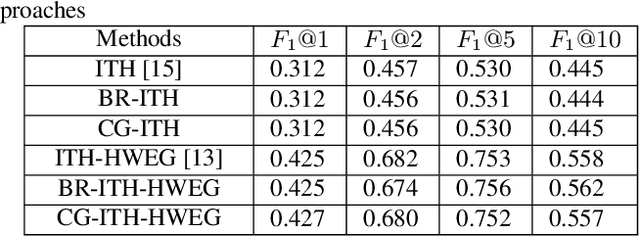
The high-order relations between the content in social media sharing platforms are frequently modeled by a hypergraph. Either hypergraph Laplacian matrix or the adjacency matrix is a big matrix. Randomized algorithms are used for low-rank factorizations in order to approximately decompose and eventually invert such big matrices fast. Here, block randomized Singular Value Decomposition (SVD) via subspace iteration is integrated within adaptive hypergraph weight estimation for image tagging, as a first approach. Specifically, creating low-rank submatrices along the main diagonal by tessellation permits fast matrix inversions via randomized SVD. Moreover, a second approach is proposed for solving the linear system in the optimization problem of hypergraph learning by employing the conjugate gradient method. Both proposed approaches achieve high accuracy in image tagging measured by F1 score and succeed to reduce the computational requirements of adaptive hypergraph weight estimation.
On Feature Normalization and Data Augmentation
Feb 25, 2020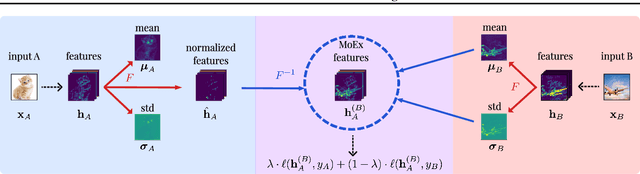
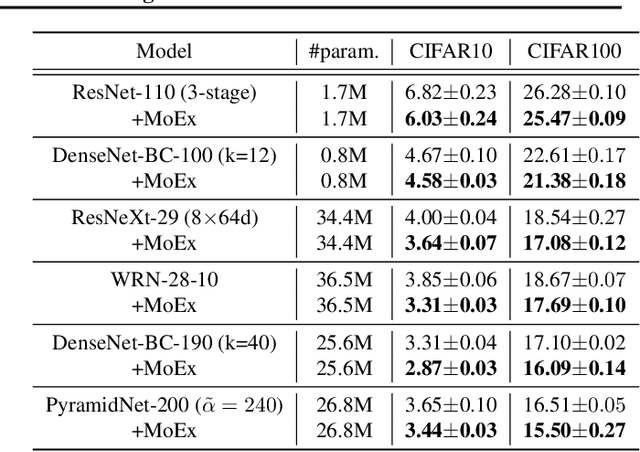
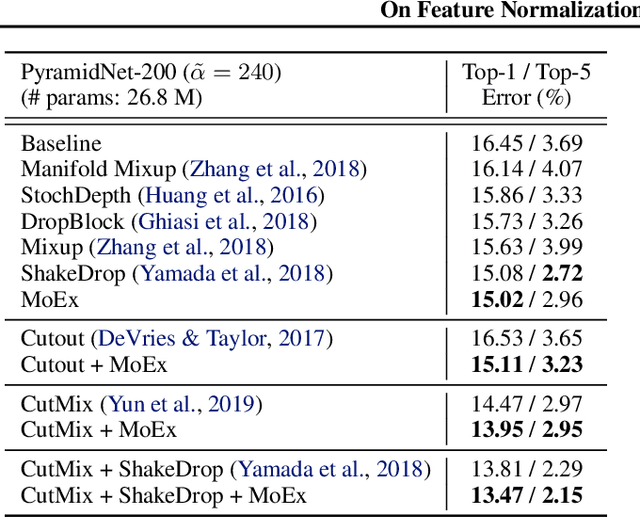
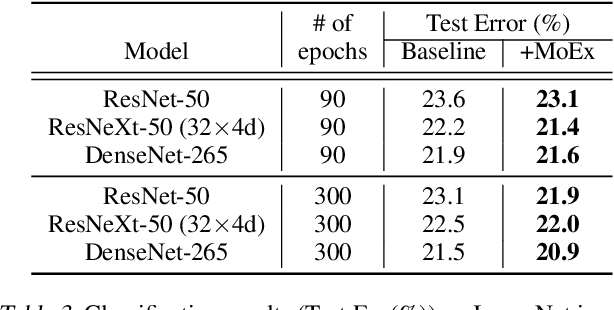
Modern neural network training relies heavily on data augmentation for improved generalization. After the initial success of label-preserving augmentations, there has been a recent surge of interest in label-perturbing approaches, which combine features and labels across training samples to smooth the learned decision surface. In this paper, we propose a new augmentation method that leverages the first and second moments extracted and re-injected by feature normalization. We replace the moments of the learned features of one training image by those of another, and also interpolate the target labels. As our approach is fast, operates entirely in feature space, and mixes different signals than prior methods, one can effectively combine it with existing augmentation methods. We demonstrate its efficacy across benchmark data sets in computer vision, speech, and natural language processing, where it consistently improves the generalization performance of highly competitive baseline networks.
Model Agnostic Defence against Backdoor Attacks in Machine Learning
Aug 06, 2019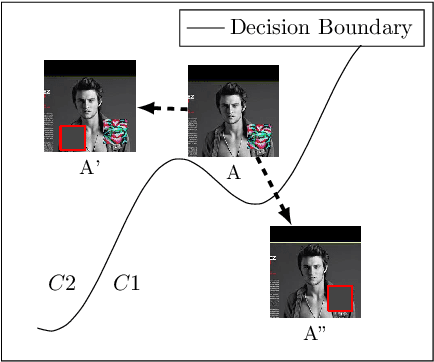
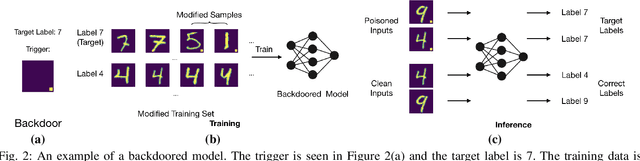

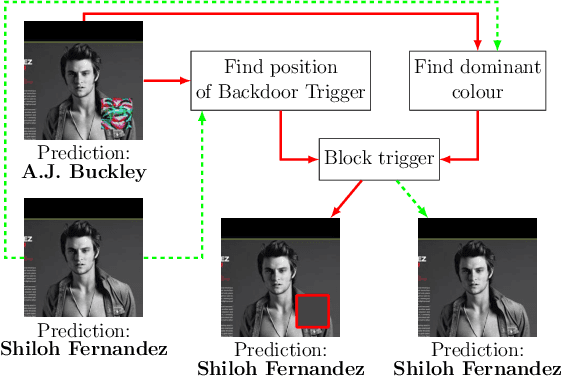
Machine Learning (ML) has automated a multitude of our day-to-day decision making domains such as education, employment and driving automation. The continued success of ML largely depends on our ability to trust the model we are using. Recently, a new class of attacks called Backdoor Attacks have been developed. These attacks undermine the user's trust in ML models. In this work, we present NEO, a model agnostic framework to detect and mitigate such backdoor attacks in image classification ML models. For a given image classification model, our approach analyses the inputs it receives and determines if the model is backdoored. In addition to this feature, we also mitigate these attacks by determining the correct predictions of the poisoned images. An appealing feature of NEO is that it can, for the first time, isolate and reconstruct the backdoor trigger. NEO is also the first defence methodology, to the best of our knowledge that is completely blackbox. We have implemented NEO and evaluated it against three state of the art poisoned models. These models include highly critical applications such as traffic sign detection (USTS) and facial detection. In our evaluation, we show that NEO can detect $\approx$88\% of the poisoned inputs on average and it is as fast as 4.4 ms per input image. We also reconstruct the poisoned input for the user to effectively test their systems.
Fusion of Image Segmentation Algorithms using Consensus Clustering
Feb 18, 2015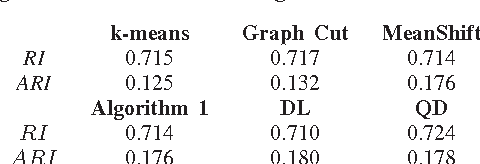

A new segmentation fusion method is proposed that ensembles the output of several segmentation algorithms applied on a remotely sensed image. The candidate segmentation sets are processed to achieve a consensus segmentation using a stochastic optimization algorithm based on the Filtered Stochastic BOEM (Best One Element Move) method. For this purpose, Filtered Stochastic BOEM is reformulated as a segmentation fusion problem by designing a new distance learning approach. The proposed algorithm also embeds the computation of the optimum number of clusters into the segmentation fusion problem.
* A version of the manuscript was published in ICIP 2013
DiagNet: towards a generic, Internet-scale root cause analysis solution
Apr 07, 2020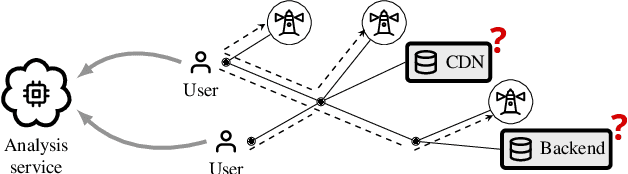
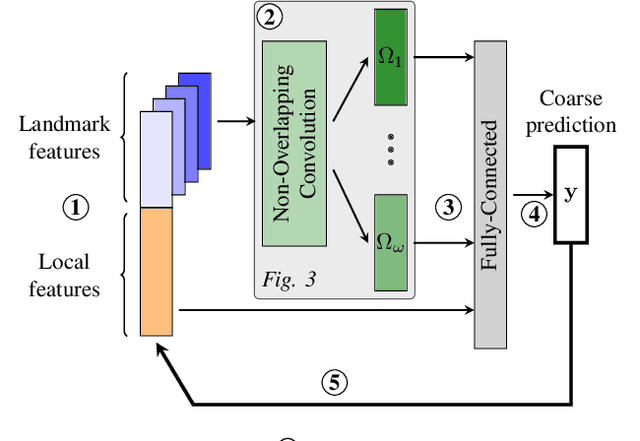
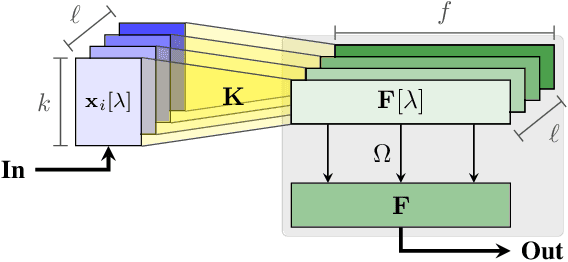
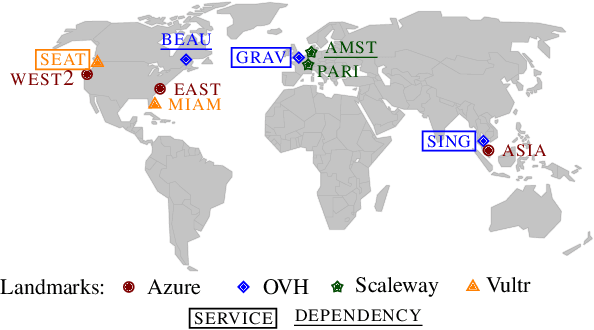
Diagnosing problems in Internet-scale services remains particularly difficult and costly for both content providers and ISPs. Because the Internet is decentralized, the cause of such problems might lie anywhere between an end-user's device and the service datacenters. Further, the set of possible problems and causes is not known in advance, making it impossible in practice to train a classifier with all combinations of problems, causes and locations. In this paper, we explore how different machine learning techniques can be used for Internet-scale root cause analysis using measurements taken from end-user devices. We show how to build generic models that (i) are agnostic to the underlying network topology, (ii) do not require to define the full set of possible causes during training, and (iii) can be quickly adapted to diagnose new services. Our solution, DiagNet, adapts concepts from image processing research to handle network and system metrics. We evaluate DiagNet with a multi-cloud deployment of online services with injected faults and emulated clients with automated browsers. We demonstrate promising root cause analysis capabilities, with a recall of 73.9% including causes only being introduced at inference time.
Incorporating Near-Infrared Information into Semantic Image Segmentation
Jun 24, 2014
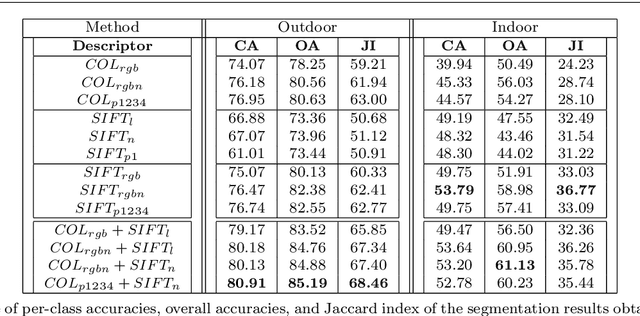

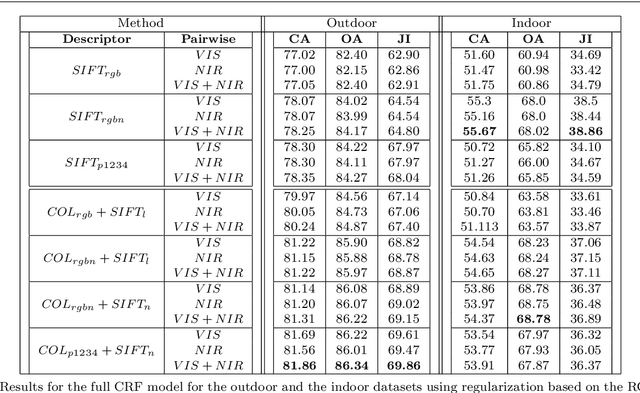
Recent progress in computational photography has shown that we can acquire near-infrared (NIR) information in addition to the normal visible (RGB) band, with only slight modifications to standard digital cameras. Due to the proximity of the NIR band to visible radiation, NIR images share many properties with visible images. However, as a result of the material dependent reflection in the NIR part of the spectrum, such images reveal different characteristics of the scene. We investigate how to effectively exploit these differences to improve performance on the semantic image segmentation task. Based on a state-of-the-art segmentation framework and a novel manually segmented image database (both indoor and outdoor scenes) that contain 4-channel images (RGB+NIR), we study how to best incorporate the specific characteristics of the NIR response. We show that adding NIR leads to improved performance for classes that correspond to a specific type of material in both outdoor and indoor scenes. We also discuss the results with respect to the physical properties of the NIR response.