 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bidirectional One-Shot Unsupervised Domain Mapping
Sep 04, 2019
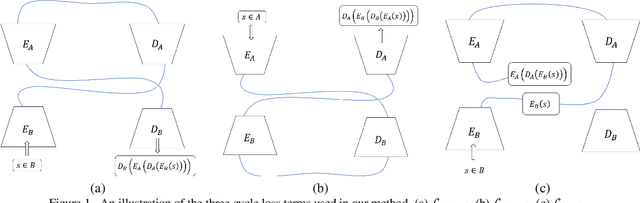

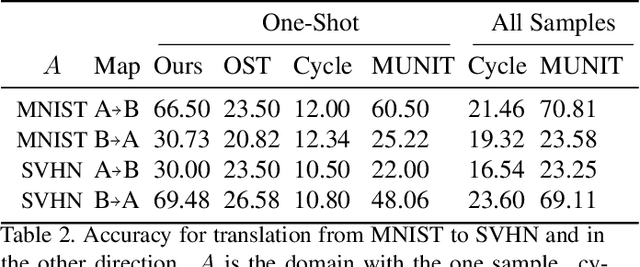

We study the problem of mapping between a domain $A$, in which there is a single training sample and a domain $B$, for which we have a richer training set. The method we present is able to perform this mapping in both directions. For example, we can transfer all MNIST images to the visual domain captured by a single SVHN image and transform the SVHN image to the domain of the MNIST images. Our method is based on employing one encoder and one decoder for each domain, without utilizing weight sharing. The autoencoder of the single sample domain is trained to match both this sample and the latent space of domain $B$. Our results demonstrate convincing mapping between domains, where either the source or the target domain are defined by a single sample, far surpassing existing solutions. Our code is made publicly available at https://github.com/tomercohen11/BiOST
Data augmentation with Möbius transformations
Feb 07, 2020
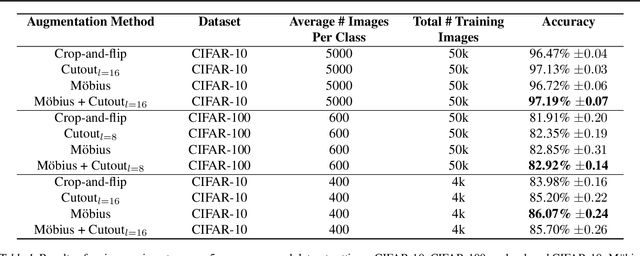

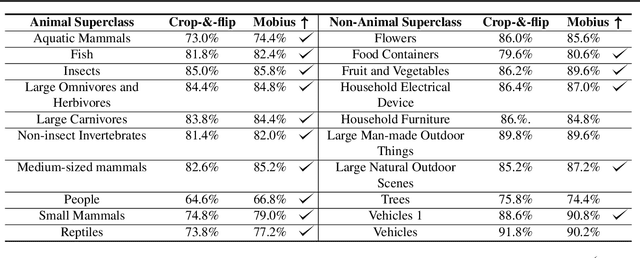
Data augmentation has led to substantial improvements in the performance and generalization of deep models, and remain a highly adaptable method to evolving model architectures and varying amounts of data---in particular, extremely scarce amounts of available training data. In this paper, we present a novel method of applying M\"obius transformations to augment input images during training. M\"obius transformations are bijective conformal maps that generalize image translation to operate over complex inversion in pixel space. As a result, M\"obius transformations can operate on the sample level and preserve data labels. We show that the inclusion of M\"obius transformations during training enables improved generalization over prior sample-level data augmentation techniques such as cutout and standard crop-and-flip transformations, most notably in low data regimes.
One-Shot Mutual Affine-Transfer for Photorealistic Stylization
Jul 24, 2019

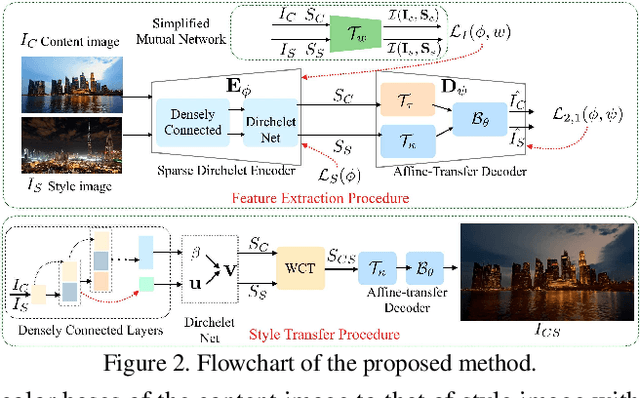
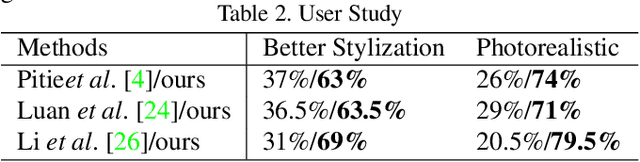
Photorealistic style transfer aims to transfer the style of a reference photo onto a content photo naturally, such that the stylized image looks like a real photo taken by a camera. Existing state-of-the-art methods are prone to spatial structure distortion of the content image and global color inconsistency across different semantic objects, making the results less photorealistic. In this paper, we propose a one-shot mutual Dirichlet network, to address these challenging issues. The essential contribution of the work is the realization of a representation scheme that successfully decouples the spatial structure and color information of images, such that the spatial structure can be well preserved during stylization. This representation is discriminative and context-sensitive with respect to semantic objects. It is extracted with a shared sparse Dirichlet encoder. Moreover, such representation is encouraged to be matched between the content and style images for faithful color transfer. The affine-transfer model is embedded in the decoder of the network to facilitate the color transfer. The strong representative and discriminative power of the proposed network enables one-shot learning given only one content-style image pair. Experimental results demonstrate that the proposed method is able to generate photorealistic photos without spatial distortion or abrupt color changes.
A Robust Variational Model for Positive Image Deconvolution
Oct 08, 2013



In this paper, an iterative method for robust deconvolution with positivity constraints is discussed. It is based on the known variational interpretation of the Richardson-Lucy iterative deconvolution as fixed-point iteration for the minimisation of an information divergence functional under a multiplicative perturbation model. The asymmetric penaliser function involved in this functional is then modified into a robust penaliser, and complemented with a regulariser. The resulting functional gives rise to a fixed point iteration that we call robust and regularised Richardson-Lucy deconvolution. It achieves an image restoration quality comparable to state-of-the-art robust variational deconvolution with a computational efficiency similar to that of the original Richardson-Lucy method. Experiments on synthetic and real-world image data demonstrate the performance of the proposed method.
Plug-in Factorization for Latent Representation Disentanglement
May 27, 2019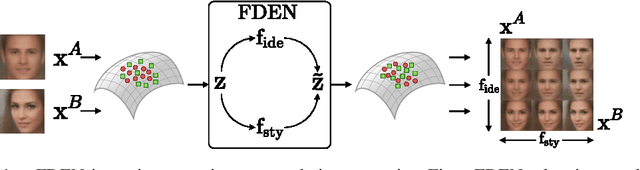
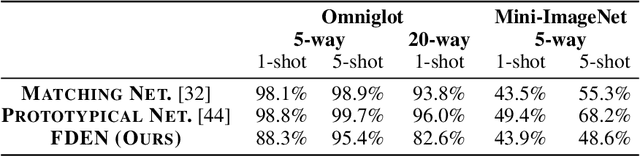
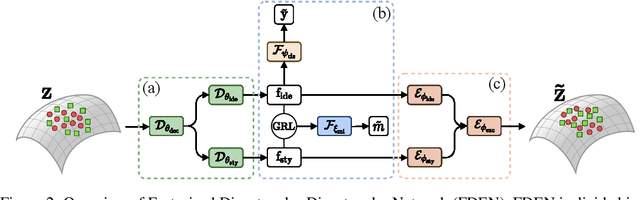
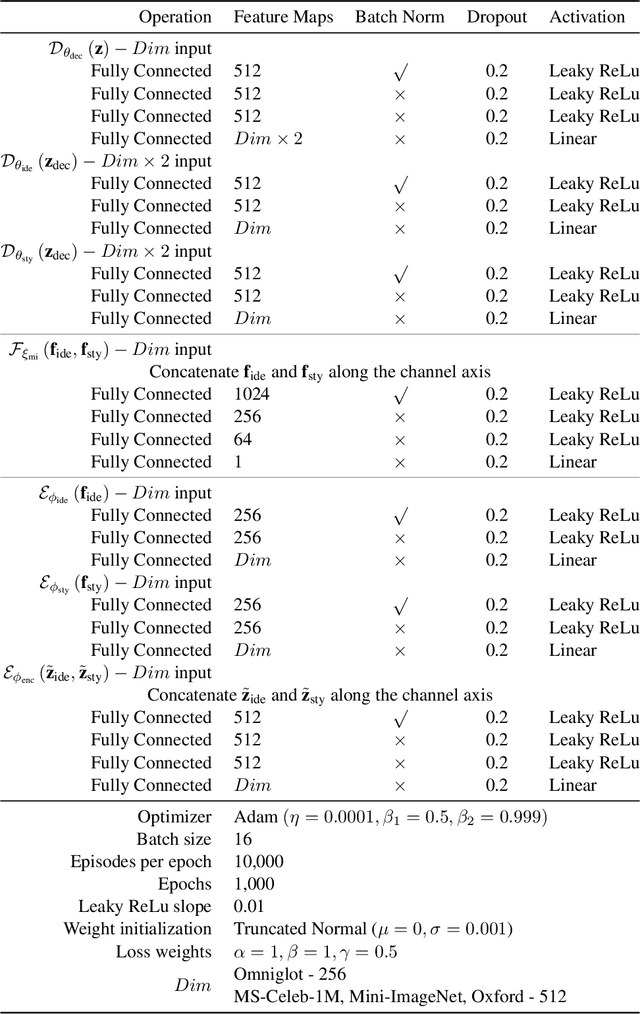
In this work, we propose a Factorized Disentangler-Entangler Network (FDEN) that learns to decompose a latent representation into two mutually independent factors, namely, identity and style. Given a latent representation, the proposed framework draws a set of interpretable factors aligned to identity of an observed data and learns to maximize the independency between these factors. Our work introduces an idea for a plug-in method to disentangle latent representations of already learned deep models with no affect to the model. In doing so, it brings the possibilities of extending state-of-the-art models to solve different tasks and also maintain the performance of its original task. Thus, FDEN is naturally applicable to jointly perform multiple tasks such as few-shot learning and image-to-image translation in a single framework. We show the effectiveness of our work in disentangling a latent representation in two parts. First, to evaluate the alignment of factor to an identity, we perform few-shot learning using only the aligned factor. Then, to evaluate the effectiveness of decomposition of latent representation and to show that plugin method does not affect the deep model in its performance, we perform image-to-image style transfer by mixing factors of different images. These evaluations show, qualitatively and quantitatively, that our proposed framework can indeed disentangle a latent representation.
A block coordinate descent optimizer for classification problems exploiting convexity
Jun 17, 2020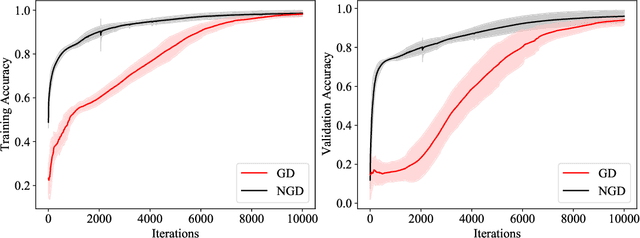
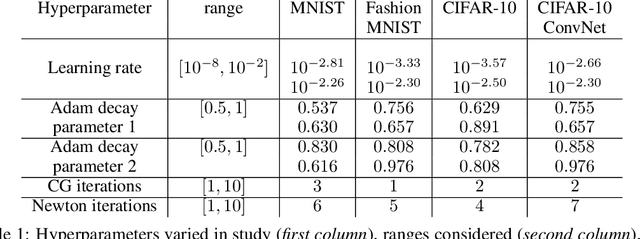
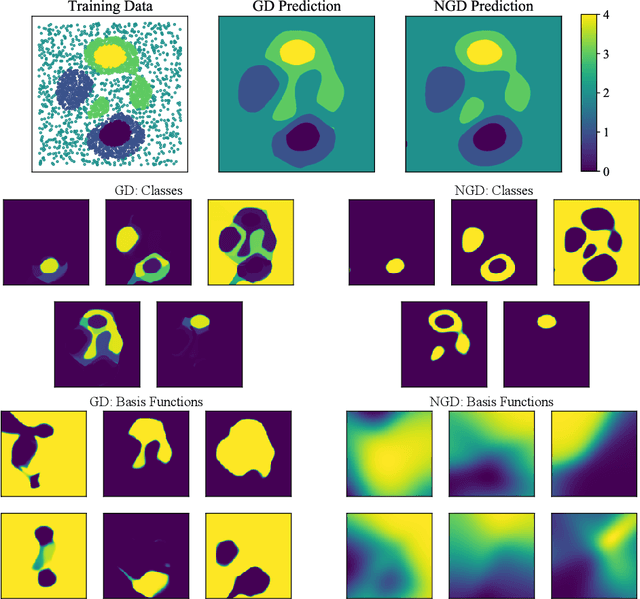
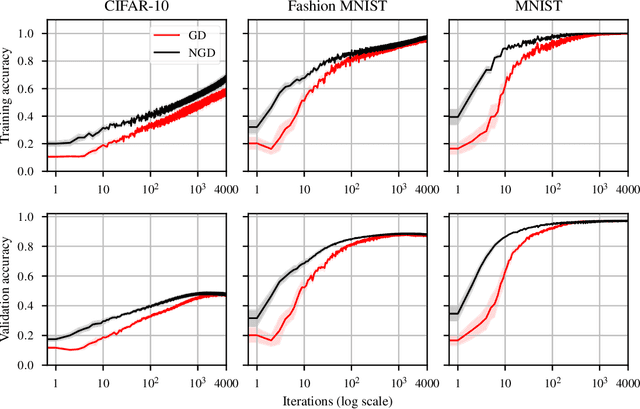
Second-order optimizers hold intriguing potential for deep learning, but suffer from increased cost and sensitivity to the non-convexity of the loss surface as compared to gradient-based approaches. We introduce a coordinate descent method to train deep neural networks for classification tasks that exploits global convexity of the cross-entropy loss in the weights of the linear layer. Our hybrid Newton/Gradient Descent (NGD) method is consistent with the interpretation of hidden layers as providing an adaptive basis and the linear layer as providing an optimal fit of the basis to data. By alternating between a second-order method to find globally optimal parameters for the linear layer and gradient descent to train the hidden layers, we ensure an optimal fit of the adaptive basis to data throughout training. The size of the Hessian in the second-order step scales only with the number weights in the linear layer and not the depth and width of the hidden layers; furthermore, the approach is applicable to arbitrary hidden layer architecture. Previous work applying this adaptive basis perspective to regression problems demonstrated significant improvements in accuracy at reduced training cost, and this work can be viewed as an extension of this approach to classification problems. We first prove that the resulting Hessian matrix is symmetric semi-definite, and that the Newton step realizes a global minimizer. By studying classification of manufactured two-dimensional point cloud data, we demonstrate both an improvement in validation error and a striking qualitative difference in the basis functions encoded in the hidden layer when trained using NGD. Application to image classification benchmarks for both dense and convolutional architectures reveals improved training accuracy, suggesting possible gains of second-order methods over gradient descent.
Weak Supervision in Convolutional Neural Network for Semantic Segmentation of Diffuse Lung Diseases Using Partially Annotated Dataset
Feb 27, 2020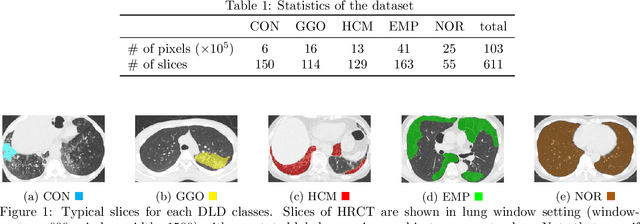
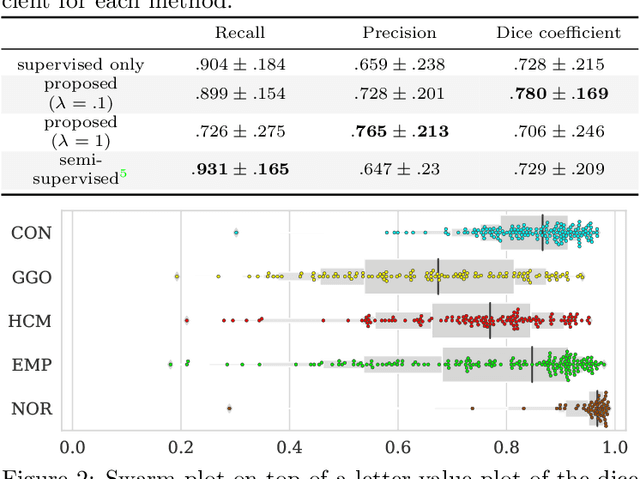
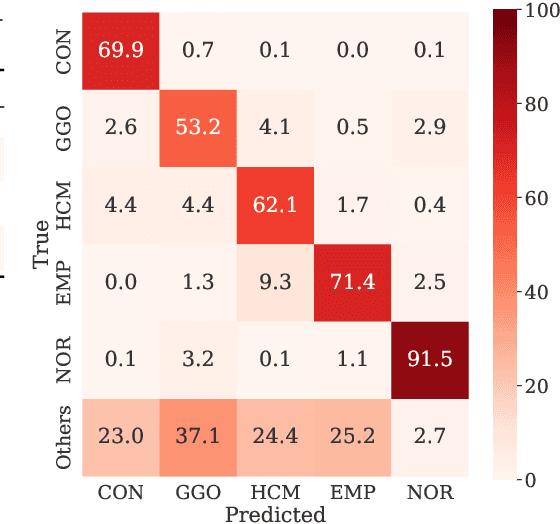
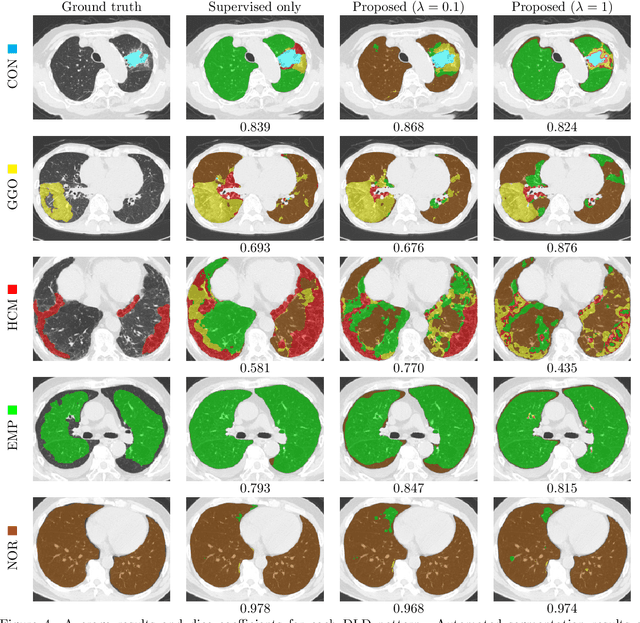
Computer-aided diagnosis system for diffuse lung diseases (DLDs) is necessary for the objective assessment of the lung diseases. In this paper, we develop semantic segmentation model for 5 kinds of DLDs. DLDs considered in this work are consolidation, ground glass opacity, honeycombing, emphysema, and normal. Convolutional neural network (CNN) is one of the most promising technique for semantic segmentation among machine learning algorithms. While creating annotated dataset for semantic segmentation is laborious and time consuming, creating partially annotated dataset, in which only one chosen class is annotated for each image, is easier since annotators only need to focus on one class at a time during the annotation task. In this paper, we propose a new weak supervision technique that effectively utilizes partially annotated dataset. The experiments using partially annotated dataset composed 372 CT images demonstrated that our proposed technique significantly improved segmentation accuracy.
Distilling Knowledge from Refinement in Multiple Instance Detection Networks
Apr 23, 2020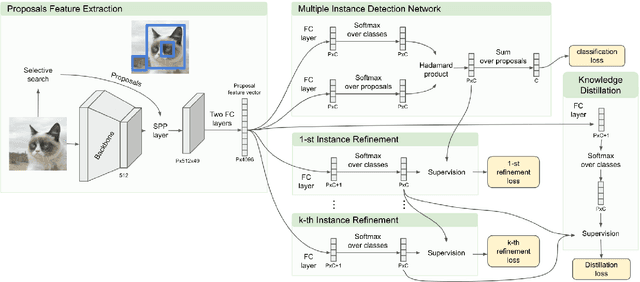
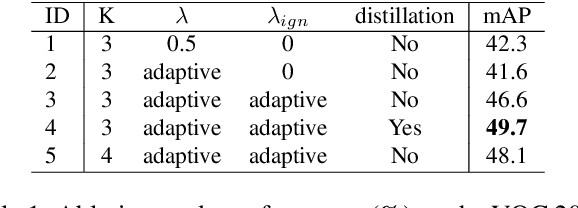
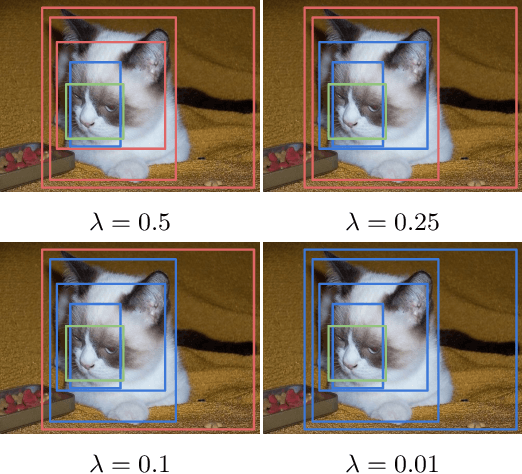
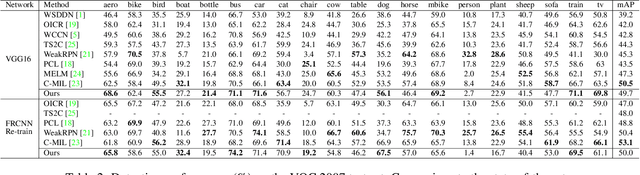
Weakly supervised object detection (WSOD) aims to tackle the object detection problem using only labeled image categories as supervision. A common approach used in WSOD to deal with the lack of localization information is Multiple Instance Learning, and in recent years methods started adopting Multiple Instance Detection Networks (MIDN), which allows training in an end-to-end fashion. In general, these methods work by selecting the best instance from a pool of candidates and then aggregating other instances based on similarity. In this work, we claim that carefully selecting the aggregation criteria can considerably improve the accuracy of the learned detector. We start by proposing an additional refinement step to an existing approach (OICR), which we call refinement knowledge distillation. Then, we present an adaptive supervision aggregation function that dynamically changes the aggregation criteria for selecting boxes related to one of the ground-truth classes, background, or even ignored during the generation of each refinement module supervision. Experiments in Pascal VOC 2007 demonstrate that our Knowledge Distillation and smooth aggregation function significantly improves the performance of OICR in the weakly supervised object detection and weakly supervised object localization tasks. These improvements make the Boosted-OICR competitive again versus other state-of-the-art approaches.
Color image quality assessment measure using multivariate generalized Gaussian distribution
Nov 29, 2014
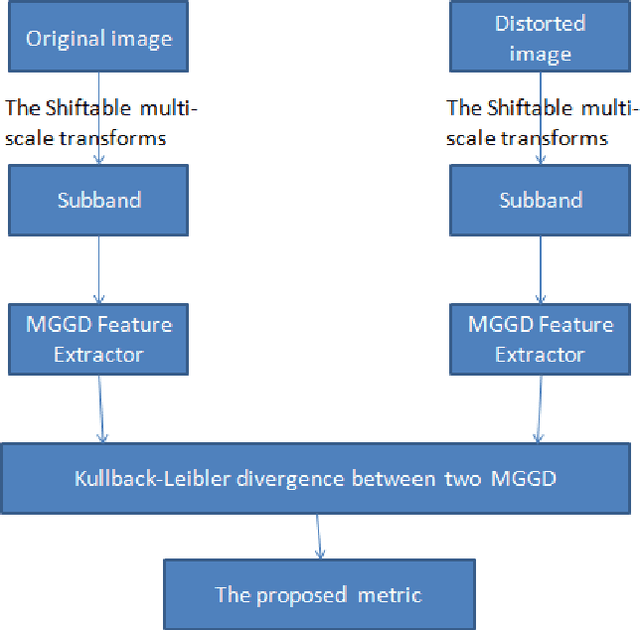

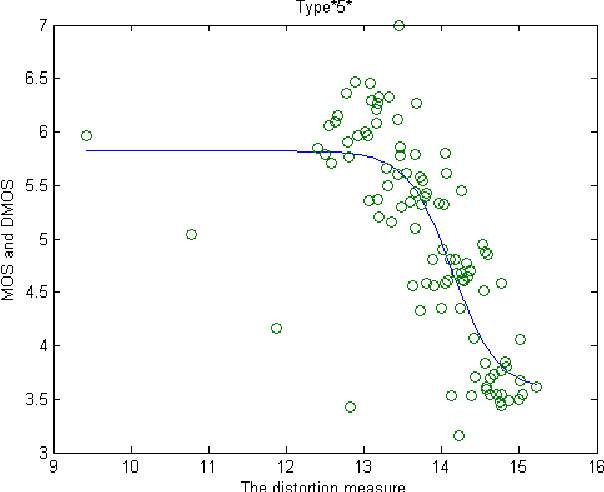
This paper deals with color image quality assessment in the reduced-reference framework based on natural scenes statistics. In this context, we propose to model the statistics of the steerable pyramid coefficients by a Multivariate Generalized Gaussian distribution (MGGD). This model allows taking into account the high correlation between the components of the RGB color space. For each selected scale and orientation, we extract a parameter matrix from the three color components subbands. In order to quantify the visual degradation, we use a closed-form of Kullback-Leibler Divergence (KLD) between two MGGDs. Using "TID 2008" benchmark, the proposed measure has been compared with the most influential methods according to the FRTV1 VQEG framework. Results demonstrates its effectiveness for a great variety of distortion type. Among other benefits this measure uses only very little information about the original image.
Unconstrained Biometric Recognition: Summary of Recent SOCIA Lab. Research
Jan 27, 2020
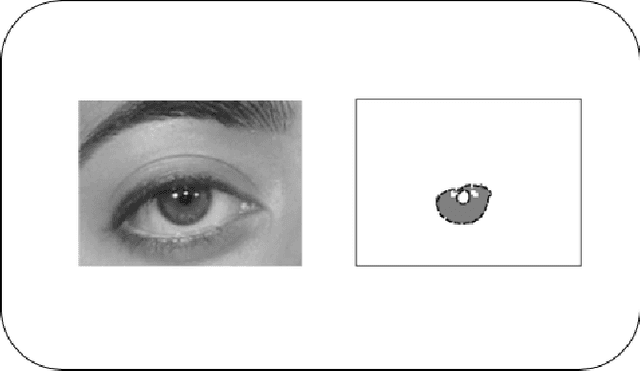
The development of biometric recognition solutions able to work in visual surveillance conditions, i.e., in unconstrained data acquisition conditions and under covert protocols has been motivating growing efforts from the research community. Among the various laboratories, schools and research institutes concerned about this problem, the SOCIA: Soft Computing and Image Analysis Lab., of the University of Beira Interior, Portugal, has been among the most active in pursuing disruptive solutions for obtaining such extremely ambitious kind of automata. This report summarises the research works published by elements of the SOCIA Lab. in the last decade in the scope of biometric recognition in unconstrained conditions. The idea is that it can be used as basis for someone wishing to entering in this research topic.