 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Low-Rank Modeling and Its Applications in Image Analysis
Oct 23, 2014
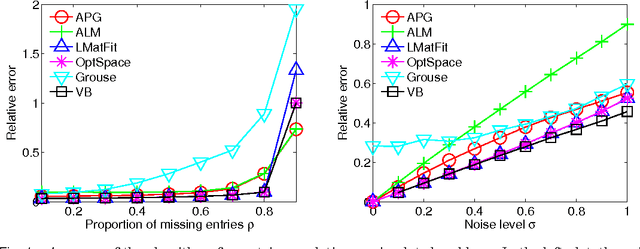
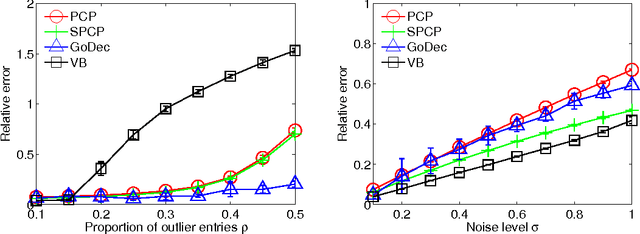
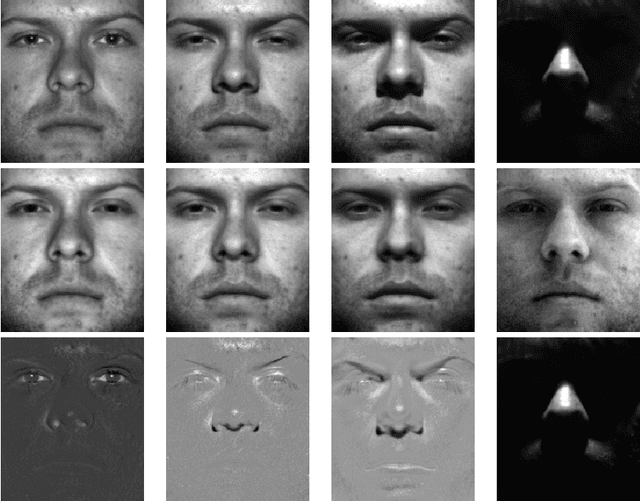

Low-rank modeling generally refers to a class of methods that solve problems by representing variables of interest as low-rank matrices. It has achieved great success in various fields including computer vision, data mining, signal processing and bioinformatics. Recently, much progress has been made in theories, algorithms and applications of low-rank modeling, such as exact low-rank matrix recovery via convex programming and matrix completion applied to collaborative filtering. These advances have brought more and more attentions to this topic. In this paper, we review the recent advance of low-rank modeling, the state-of-the-art algorithms, and related applications in image analysis. We first give an overview to the concept of low-rank modeling and challenging problems in this area. Then, we summarize the models and algorithms for low-rank matrix recovery and illustrate their advantages and limitations with numerical experiments. Next, we introduce a few applications of low-rank modeling in the context of image analysis. Finally, we conclude this paper with some discussions.
Automatic Tag Recommendation for Painting Artworks Using Diachronic Descriptions
Apr 21, 2020

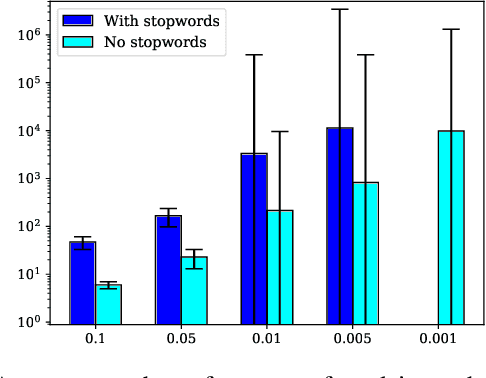
In this paper, we deal with the problem of automatic tag recommendation for painting artworks. Diachronic descriptions containing deviations on the vocabulary used to describe each painting usually occur when the work is done by many experts over time. The objective of this work is to provide a framework that produces a more accurate and homogeneous set of tags for each painting in a large collection. To validate our method we build a model based on a weakly-supervised neural network for over $5{,}300$ paintings with hand-labeled descriptions made by experts for the paintings of the Brazilian painter Candido Portinari. This work takes place with the Portinari Project which started in 1979 intending to recover and catalog the paintings of the Brazilian painter. The Portinari paintings at that time were in private collections and museums spread around the world and thus inaccessible to the public. The descriptions of each painting were made by a large number of collaborators over 40 years as the paintings were recovered and these diachronic descriptions caused deviations on the vocabulary used to describe each painting. Our proposed framework consists of (i) a neural network that receives as input the image of each painting and uses frequent itemsets as possible tags, and (ii) a clustering step in which we group related tags based on the output of the pre-trained classifiers.
Neural Blind Deconvolution Using Deep Priors
Aug 06, 2019
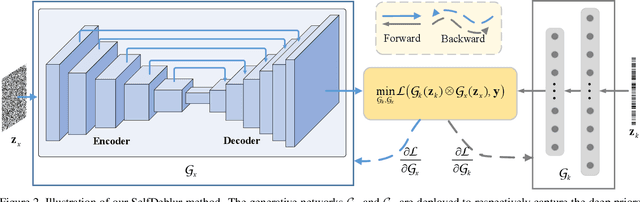


Blind deconvolution is a classical yet challenging low-level vision problem with many real-world applications. Traditional maximum a posterior (MAP) based methods rely heavily on fixed and handcrafted priors that certainly are insufficient in characterizing clean images and blur kernels, and usually adopt specially designed alternating minimization to avoid trivial solution. In contrast, existing deep motion deblurring networks learn from massive training images the mapping to clean image or blur kernel, but are limited in handling various complex and large size blur kernels. To connect MAP and deep models, we in this paper present two generative networks for respectively modeling the deep priors of clean image and blur kernel, and propose an unconstrained neural optimization solution to blind deconvolution. In particular, we adopt an asymmetric Autoencoder with skip connections for generating latent clean image, and a fully-connected network (FCN) for generating blur kernel. Moreover, the SoftMax nonlinearity is applied to the output layer of FCN to meet the non-negative and equality constraints. The process of neural optimization can be explained as a kind of "zero-shot" self-supervised learning of the generative networks, and thus our proposed method is dubbed SelfDeblur. Experimental results show that our SelfDeblur can achieve notable quantitative gains as well as more visually plausible deblurring results in comparison to state-of-the-art blind deconvolution methods on benchmark datasets and real-world blurry images. The source code is available at https://github.com/csdwren/SelfDeblur.
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
Feb 20, 2020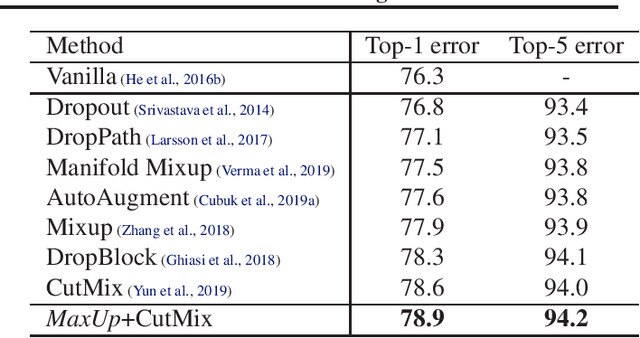
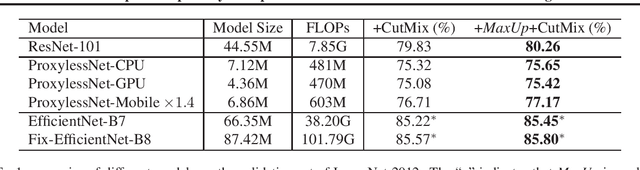
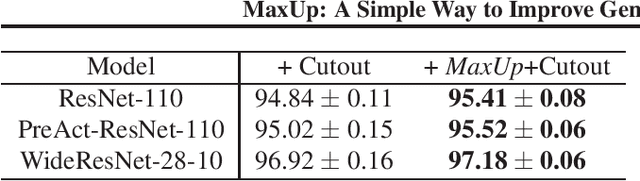

We propose \emph{MaxUp}, an embarrassingly simple, highly effective technique for improving the generalization performance of machine learning models, especially deep neural networks. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, we implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. For example, in the case of Gaussian perturbation, \emph{MaxUp} is asymptotically equivalent to using the gradient norm of the loss as a penalty to encourage smoothness. We test \emph{MaxUp} on a range of tasks, including image classification, language modeling, and adversarial certification, on which \emph{MaxUp} consistently outperforms the existing best baseline methods, without introducing substantial computational overhead. In particular, we improve ImageNet classification from the state-of-the-art top-1 accuracy $85.5\%$ without extra data to $85.8\%$. Code will be released soon.
REAPS: Towards Better Recognition of Fine-grained Images by Region Attending and Part Sequencing
Aug 06, 2019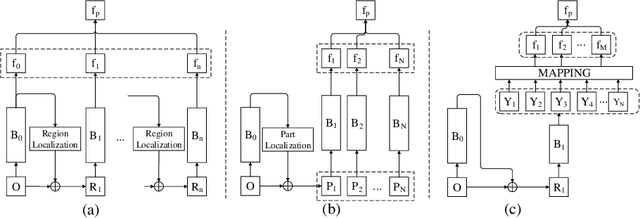
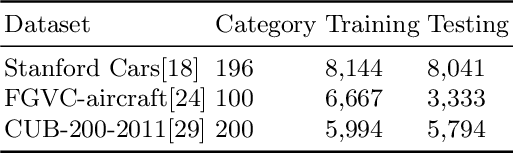

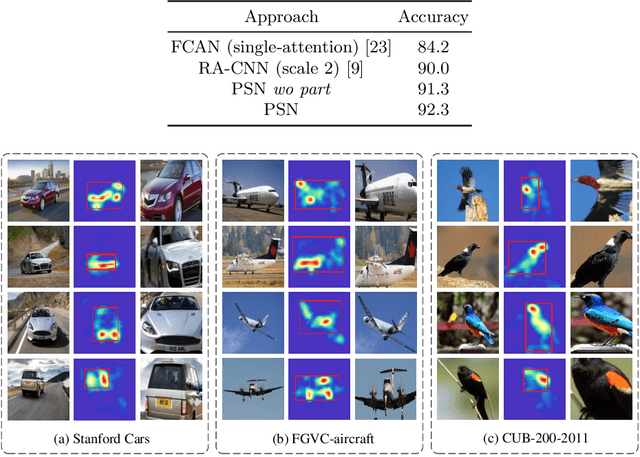
Fine-grained image recognition has been a hot research topic in computer vision due to its various applications. The-state-of-the-art is the part/region-based approaches that first localize discriminative parts/regions, and then learn their fine-grained features. However, these approaches have some inherent drawbacks: 1) the discriminative feature representation of an object is prone to be disturbed by complicated background; 2) it is unreasonable and inflexible to fix the number of salient parts, because the intended parts may be unavailable under certain circumstances due to occlusion or incompleteness, and 3) the spatial correlation among different salient parts has not been thoroughly exploited (if not completely neglected). To overcome these drawbacks, in this paper we propose a new, simple yet robust method by building part sequence model on the attended object region. Concretely, we first try to alleviate the background effect by using a region attention mechanism to generate the attended region from the original image. Then, instead of localizing different salient parts and extracting their features separately, we learn the part representation implicitly by applying a mapping function on the serialized features of the object. Finally, we combine the region attending network and the part sequence learning network into a unified framework that can be trained end-to-end with only image-level labels. Our extensive experiments on three fine-grained benchmarks show that the proposed method achieves the state of the art performance.
A Bayes-Optimal View on Adversarial Examples
Feb 20, 2020
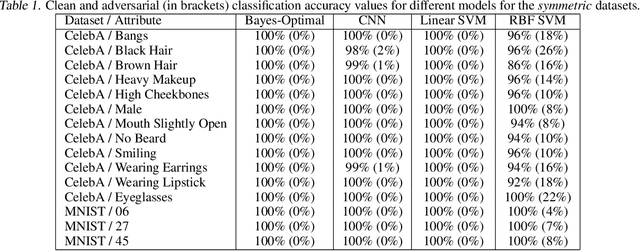

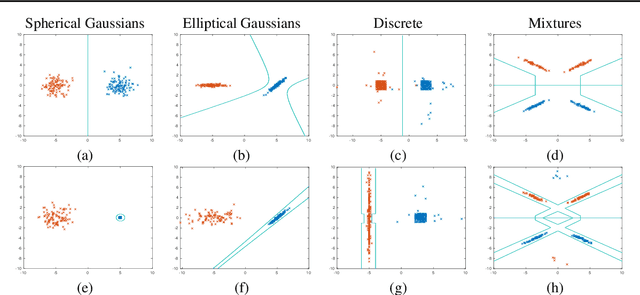
The ability to fool modern CNN classifiers with tiny perturbations of the input has lead to the development of a large number of candidate defenses and often conflicting explanations. In this paper, we argue for examining adversarial examples from the perspective of Bayes-Optimal classification. We construct realistic image datasets for which the Bayes-Optimal classifier can be efficiently computed and derive analytic conditions on the distributions so that the optimal classifier is either robust or vulnerable. By training different classifiers on these datasets (for which the "gold standard" optimal classifiers are known), we can disentangle the possible sources of vulnerability and avoid the accuracy-robustness tradeoff that may occur in commonly used datasets. Our results show that even when the optimal classifier is robust, standard CNN training consistently learns a vulnerable classifier. At the same time, for exactly the same training data, RBF SVMs consistently learn a robust classifier. The same trend is observed in experiments with real images.
A Convolutional Neural Network into graph space
Feb 20, 2020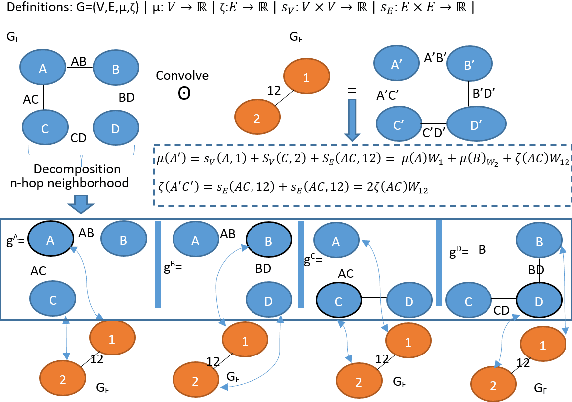

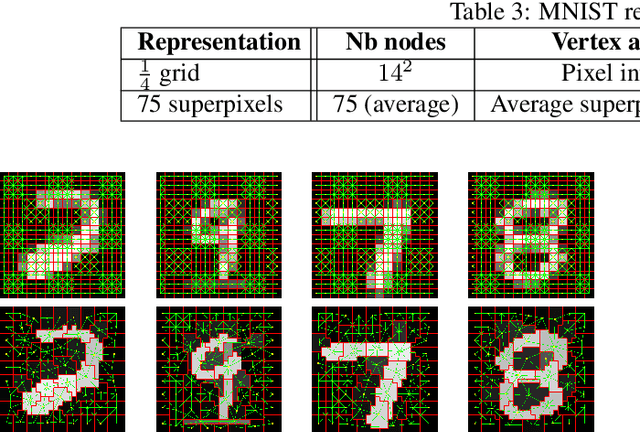
Convolutional neural networks (CNNs), in a few decades, have outperformed the existing state of the art methods in classification context. However, in the way they were formalised, CNNs are bound to operate on euclidean spaces. Indeed, convolution is a signal operation that are defined on euclidean spaces. This has restricted deep learning main use to euclidean-defined data such as sound or image. And yet, numerous computer application fields (among which network analysis, computational social science, chemo-informatics or computer graphics) induce non-euclideanly defined data such as graphs, networks or manifolds. In this paper we propose a new convolution neural network architecture, defined directly into graph space. Convolution and pooling operators are defined in graph domain. We show its usability in a back-propagation context. Experimental results show that our model performance is at state of the art level on simple tasks. It shows robustness with respect to graph domain changes and improvement with respect to other euclidean and non-euclidean convolutional architectures.
$Π-$nets: Deep Polynomial Neural Networks
Mar 08, 2020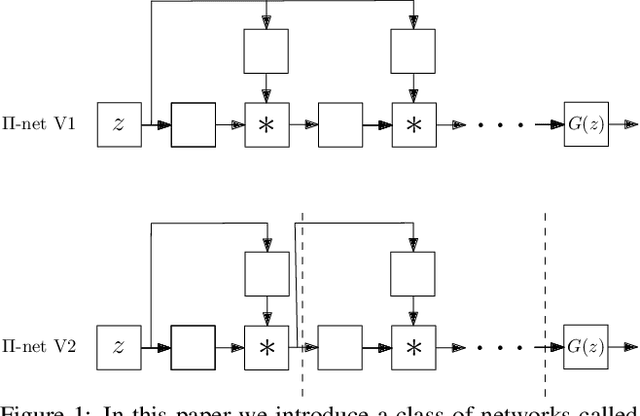
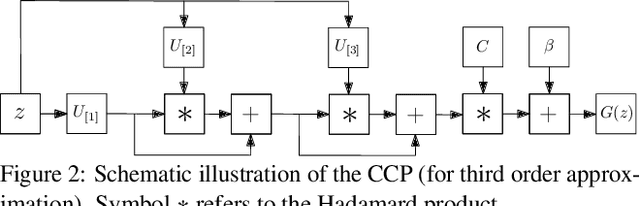
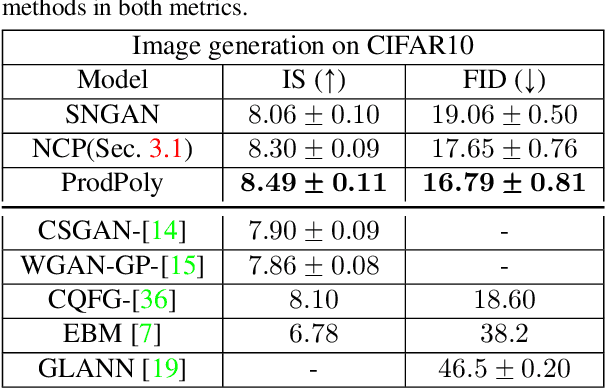
Deep Convolutional Neural Networks (DCNNs) is currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. $\Pi$-Nets can be implemented using special kind of skip connections and their parameters can be represented via high-order tensors. We empirically demonstrate that $\Pi$-Nets have better representation power than standard DCNNs and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in challenging tasks, such as image generation. Lastly, our framework elucidates why recent generative models, such as StyleGAN, improve upon their predecessors, e.g., ProGAN.
A CNN-RNN Architecture for Multi-Label Weather Recognition
Apr 24, 2019


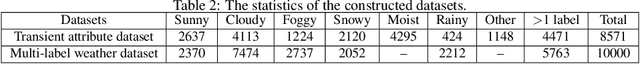
Weather Recognition plays an important role in our daily lives and many computer vision applications. However, recognizing the weather conditions from a single image remains challenging and has not been studied thoroughly. Generally, most previous works treat weather recognition as a single-label classification task, namely, determining whether an image belongs to a specific weather class or not. This treatment is not always appropriate, since more than one weather conditions may appear simultaneously in a single image. To address this problem, we make the first attempt to view weather recognition as a multi-label classification task, i.e., assigning an image more than one labels according to the displayed weather conditions. Specifically, a CNN-RNN based multi-label classification approach is proposed in this paper. The convolutional neural network (CNN) is extended with a channel-wise attention model to extract the most correlated visual features. The Recurrent Neural Network (RNN) further processes the features and excavates the dependencies among weather classes. Finally, the weather labels are predicted step by step. Besides, we construct two datasets for the weather recognition task and explore the relationships among different weather conditions. Experimental results demonstrate the superiority and effectiveness of the proposed approach. The new constructed datasets will be available at https://github.com/wzgwzg/Multi-Label-Weather-Recognition.
Dense-Caption Matching and Frame-Selection Gating for Temporal Localization in VideoQA
May 13, 2020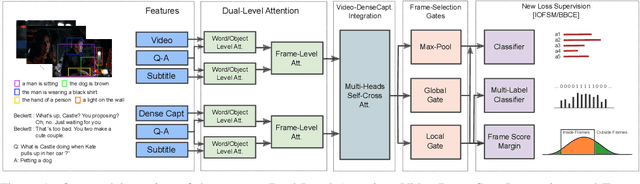
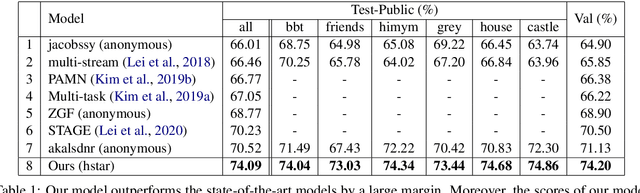
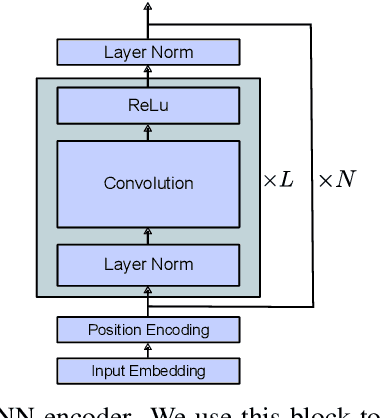
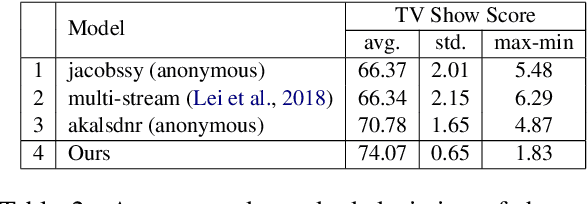
Videos convey rich information. Dynamic spatio-temporal relationships between people/objects, and diverse multimodal events are present in a video clip. Hence, it is important to develop automated models that can accurately extract such information from videos. Answering questions on videos is one of the tasks which can evaluate such AI abilities. In this paper, we propose a video question answering model which effectively integrates multi-modal input sources and finds the temporally relevant information to answer questions. Specifically, we first employ dense image captions to help identify objects and their detailed salient regions and actions, and hence give the model useful extra information (in explicit textual format to allow easier matching) for answering questions. Moreover, our model is also comprised of dual-level attention (word/object and frame level), multi-head self/cross-integration for different sources (video and dense captions), and gates which pass more relevant information to the classifier. Finally, we also cast the frame selection problem as a multi-label classification task and introduce two loss functions, In-andOut Frame Score Margin (IOFSM) and Balanced Binary Cross-Entropy (BBCE), to better supervise the model with human importance annotations. We evaluate our model on the challenging TVQA dataset, where each of our model components provides significant gains, and our overall model outperforms the state-of-the-art by a large margin (74.09% versus 70.52%). We also present several word, object, and frame level visualization studies. Our code is publicly available at: https://github.com/hyounghk/VideoQADenseCapFrameGate-ACL2020