 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neuropsychiatric Disease Classification Using Functional Connectomics -- Results of the Connectomics in NeuroImaging Transfer Learning Challenge
Jun 05, 2020
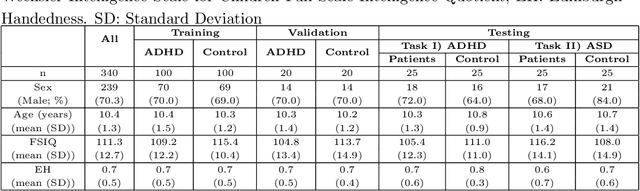
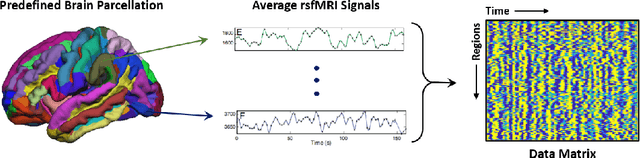
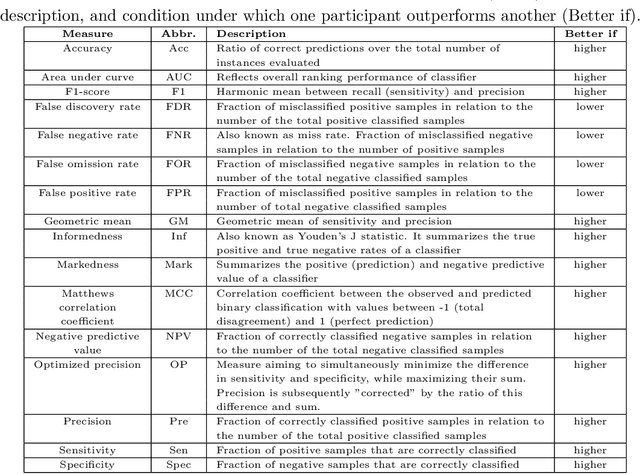
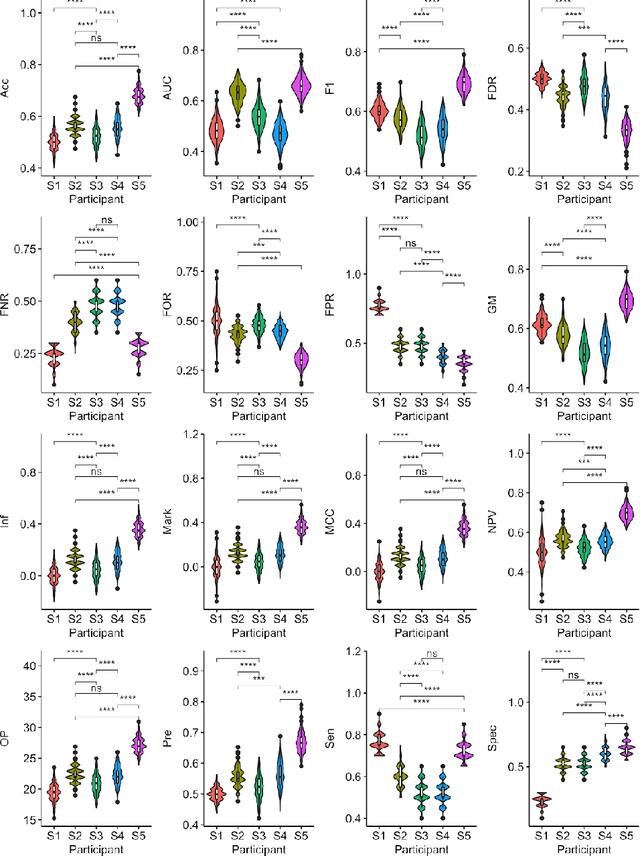
Large, open-source consortium datasets have spurred the development of new and increasingly powerful machine learning approaches in brain connectomics. However, one key question remains: are we capturing biologically relevant and generalizable information about the brain, or are we simply overfitting to the data? To answer this, we organized a scientific challenge, the Connectomics in NeuroImaging Transfer Learning Challenge (CNI-TLC), held in conjunction with MICCAI 2019. CNI-TLC included two classification tasks: (1) diagnosis of Attention-Deficit/Hyperactivity Disorder (ADHD) within a pre-adolescent cohort; and (2) transference of the ADHD model to a related cohort of Autism Spectrum Disorder (ASD) patients with an ADHD comorbidity. In total, 240 resting-state fMRI time series averaged according to three standard parcellation atlases, along with clinical diagnosis, were released for training and validation (120 neurotypical controls and 120 ADHD). We also provided demographic information of age, sex, IQ, and handedness. A second set of 100 subjects (50 neurotypical controls, 25 ADHD, and 25 ASD with ADHD comorbidity) was used for testing. Models were submitted in a standardized format as Docker images through ChRIS, an open-source image analysis platform. Utilizing an inclusive approach, we ranked the methods based on 16 different metrics. The final rank was calculated using the rank product for each participant across all measures. Furthermore, we assessed the calibration curves of each method. Five participants submitted their model for evaluation, with one outperforming all other methods in both ADHD and ASD classification. However, further improvements are needed to reach the clinical translation of functional connectomics. We are keeping the CNI-TLC open as a publicly available resource for developing and validating new classification methodologies in the field of connectomics.
A CNN-RNN Architecture for Multi-Label Weather Recognition
Apr 24, 2019


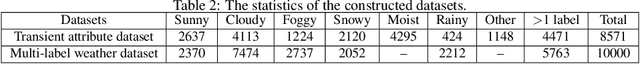
Weather Recognition plays an important role in our daily lives and many computer vision applications. However, recognizing the weather conditions from a single image remains challenging and has not been studied thoroughly. Generally, most previous works treat weather recognition as a single-label classification task, namely, determining whether an image belongs to a specific weather class or not. This treatment is not always appropriate, since more than one weather conditions may appear simultaneously in a single image. To address this problem, we make the first attempt to view weather recognition as a multi-label classification task, i.e., assigning an image more than one labels according to the displayed weather conditions. Specifically, a CNN-RNN based multi-label classification approach is proposed in this paper. The convolutional neural network (CNN) is extended with a channel-wise attention model to extract the most correlated visual features. The Recurrent Neural Network (RNN) further processes the features and excavates the dependencies among weather classes. Finally, the weather labels are predicted step by step. Besides, we construct two datasets for the weather recognition task and explore the relationships among different weather conditions. Experimental results demonstrate the superiority and effectiveness of the proposed approach. The new constructed datasets will be available at https://github.com/wzgwzg/Multi-Label-Weather-Recognition.
Neuromorphologicaly-preserving Volumetric data encoding using VQ-VAE
Feb 13, 2020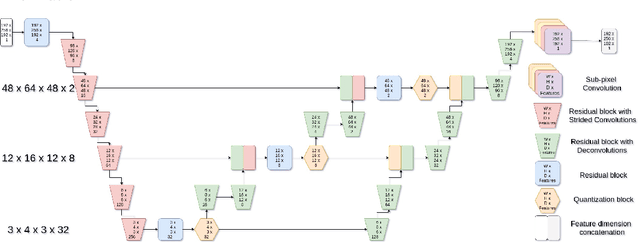
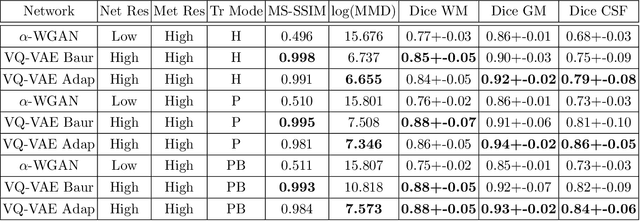
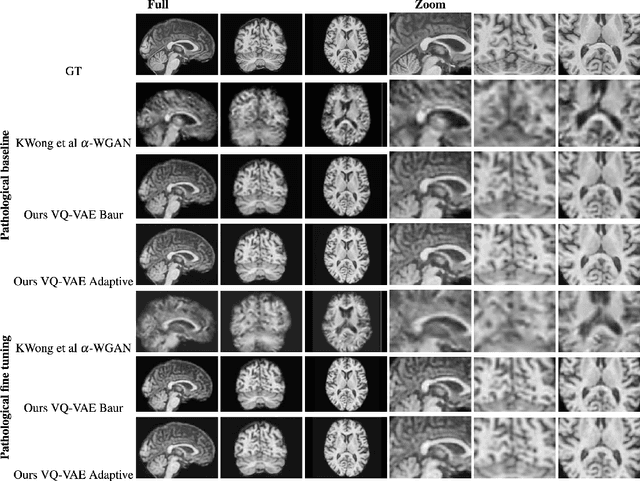
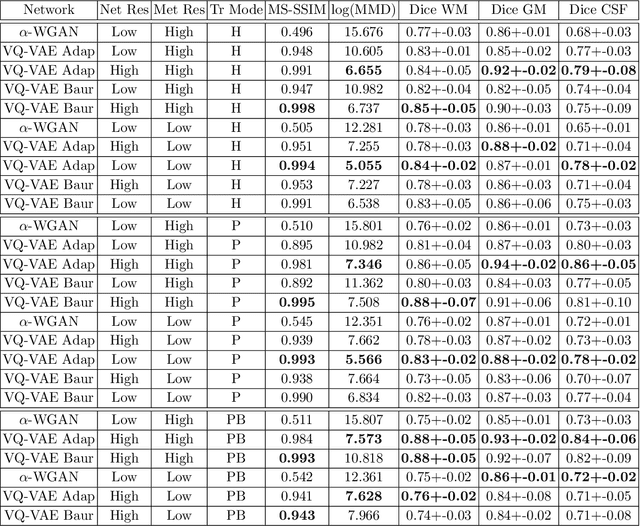
The increasing efficiency and compactness of deep learning architectures, together with hardware improvements, have enabled the complex and high-dimensional modelling of medical volumetric data at higher resolutions. Recently, Vector-Quantised Variational Autoencoders (VQ-VAE) have been proposed as an efficient generative unsupervised learning approach that can encode images to a small percentage of their initial size, while preserving their decoded fidelity. Here, we show a VQ-VAE inspired network can efficiently encode a full-resolution 3D brain volume, compressing the data to $0.825\%$ of the original size while maintaining image fidelity, and significantly outperforming the previous state-of-the-art. We then demonstrate that VQ-VAE decoded images preserve the morphological characteristics of the original data through voxel-based morphology and segmentation experiments. Lastly, we show that such models can be pre-trained and then fine-tuned on different datasets without the introduction of bias.
Tree-SNE: Hierarchical Clustering and Visualization Using t-SNE
Feb 13, 2020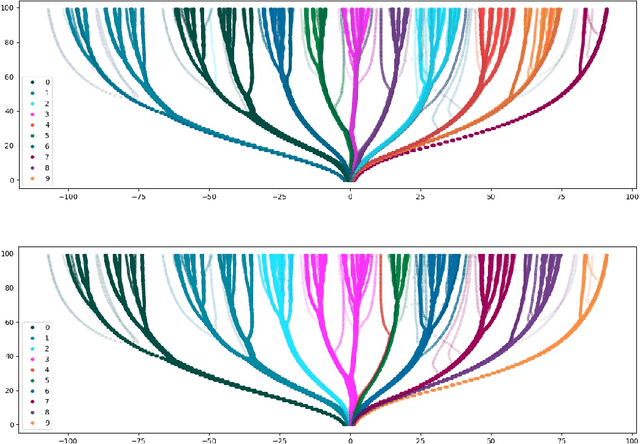
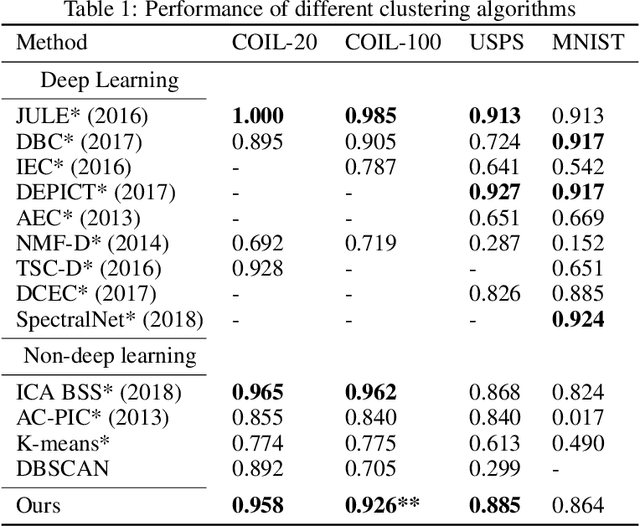
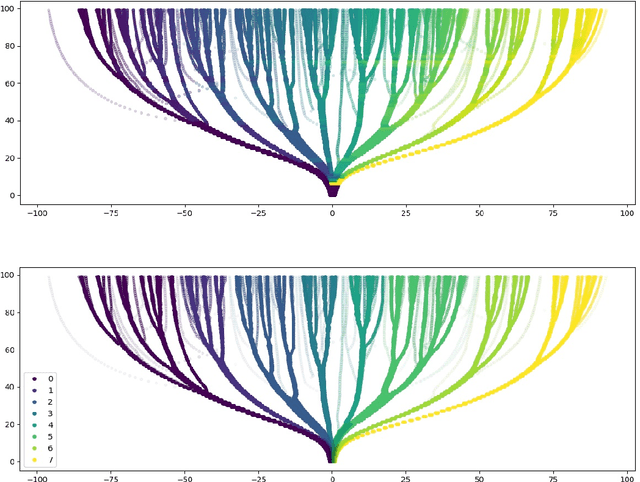
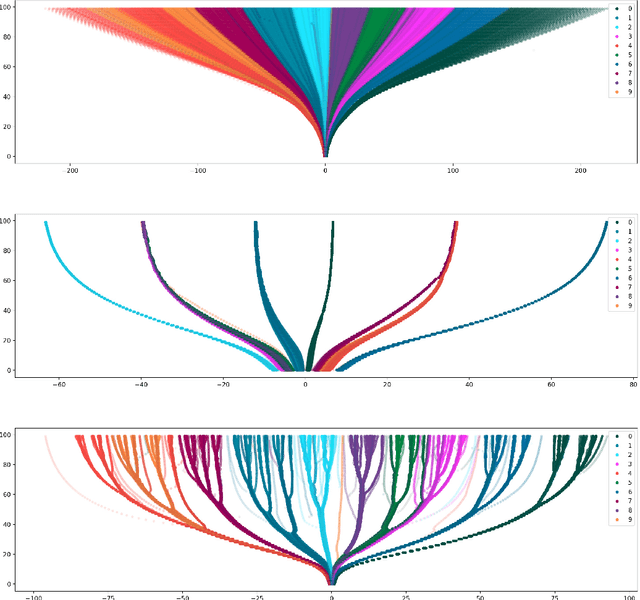
t-SNE and hierarchical clustering are popular methods of exploratory data analysis, particularly in biology. Building on recent advances in speeding up t-SNE and obtaining finer-grained structure, we combine the two to create tree-SNE, a hierarchical clustering and visualization algorithm based on stacked one-dimensional t-SNE embeddings. We also introduce alpha-clustering, which recommends the optimal cluster assignment, without foreknowledge of the number of clusters, based off of the cluster stability across multiple scales. We demonstrate the effectiveness of tree-SNE and alpha-clustering on images of handwritten digits, mass cytometry (CyTOF) data from blood cells, and single-cell RNA-sequencing (scRNA-seq) data from retinal cells. Furthermore, to demonstrate the validity of the visualization, we use alpha-clustering to obtain unsupervised clustering results competitive with the state of the art on several image data sets. Software is available at https://github.com/isaacrob/treesne.
Spatiotemporal Fusion in 3D CNNs: A Probabilistic View
Apr 10, 2020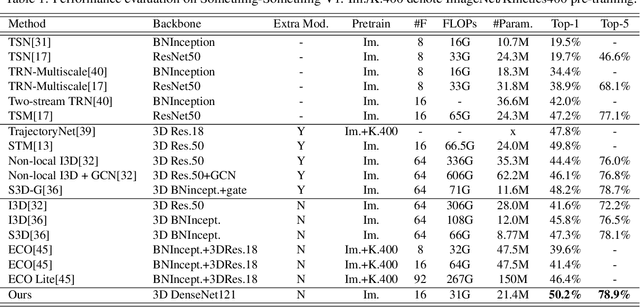

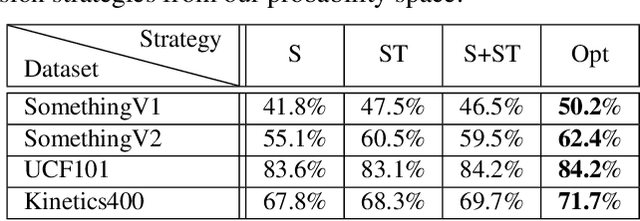
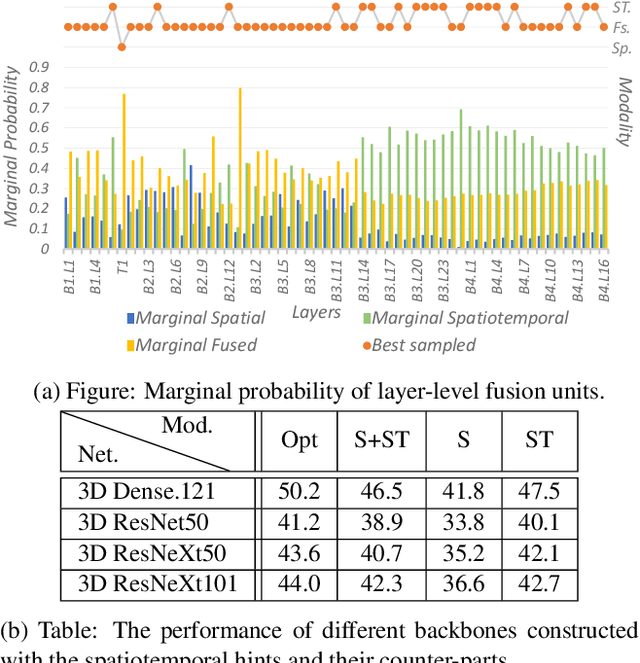
Despite the success in still image recognition, deep neural networks for spatiotemporal signal tasks (such as human action recognition in videos) still suffers from low efficacy and inefficiency over the past years. Recently, human experts have put more efforts into analyzing the importance of different components in 3D convolutional neural networks (3D CNNs) to design more powerful spatiotemporal learning backbones. Among many others, spatiotemporal fusion is one of the essentials. It controls how spatial and temporal signals are extracted at each layer during inference. Previous attempts usually start by ad-hoc designs that empirically combine certain convolutions and then draw conclusions based on the performance obtained by training the corresponding networks. These methods only support network-level analysis on limited number of fusion strategies. In this paper, we propose to convert the spatiotemporal fusion strategies into a probability space, which allows us to perform network-level evaluations of various fusion strategies without having to train them separately. Besides, we can also obtain fine-grained numerical information such as layer-level preference on spatiotemporal fusion within the probability space. Our approach greatly boosts the efficiency of analyzing spatiotemporal fusion. Based on the probability space, we further generate new fusion strategies which achieve the state-of-the-art performance on four well-known action recognition datasets.
Auto-Embedding Generative Adversarial Networks for High Resolution Image Synthesis
Mar 29, 2019

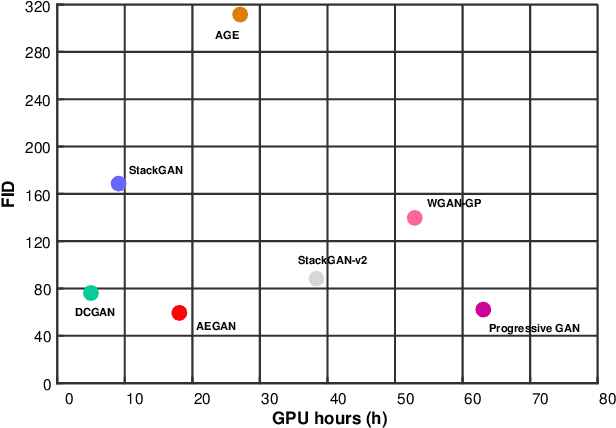
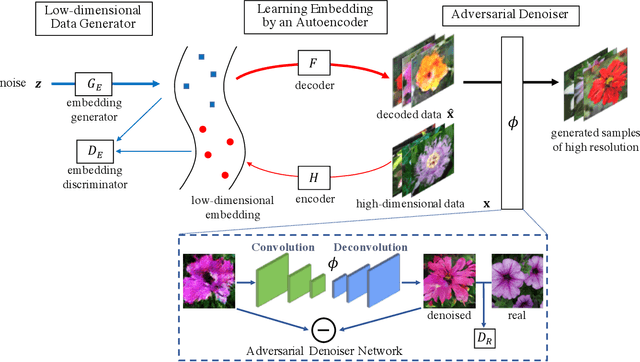
Generating images via the generative adversarial network (GAN) has attracted much attention recently. However, most of the existing GAN-based methods can only produce low-resolution images of limited quality. Directly generating high-resolution images using GANs is nontrivial, and often produces problematic images with incomplete objects. To address this issue, we develop a novel GAN called Auto-Embedding Generative Adversarial Network (AEGAN), which simultaneously encodes the global structure features and captures the fine-grained details. In our network, we use an autoencoder to learn the intrinsic high-level structure of real images and design a novel denoiser network to provide photo-realistic details for the generated images. In the experiments, we are able to produce 512x512 images of promising quality directly from the input noise. The resultant images exhibit better perceptual photo-realism, i.e., with sharper structure and richer details, than other baselines on several datasets, including Oxford-102 Flowers, Caltech-UCSD Birds (CUB), High-Quality Large-scale CelebFaces Attributes (CelebA-HQ), Large-scale Scene Understanding (LSUN) and ImageNet.
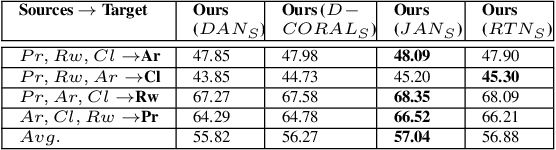
Multi-component Image Translation for Deep Domain Generalization
Dec 21, 2018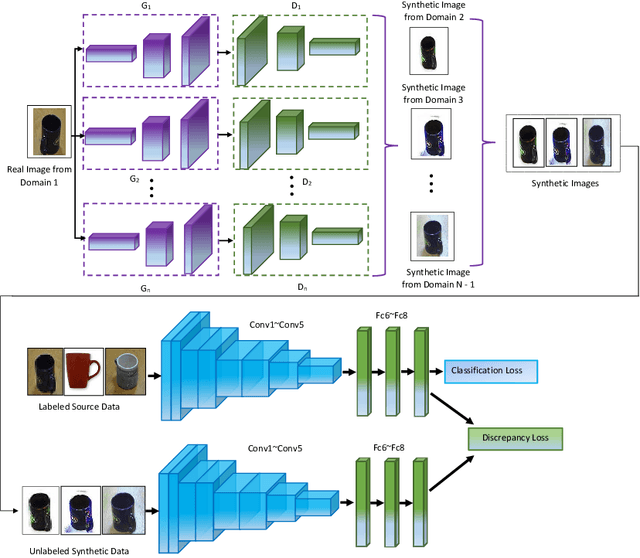
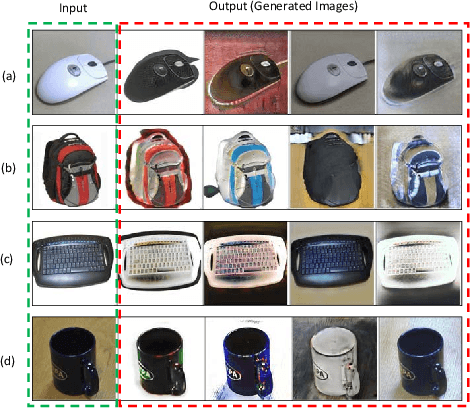
Domain adaption (DA) and domain generalization (DG) are two closely related methods which are both concerned with the task of assigning labels to an unlabeled data set. The only dissimilarity between these approaches is that DA can access the target data during the training phase, while the target data is totally unseen during the training phase in DG. The task of DG is challenging as we have no earlier knowledge of the target samples. If DA methods are applied directly to DG by a simple exclusion of the target data from training, poor performance will result for a given task. In this paper, we tackle the domain generalization challenge in two ways. In our first approach, we propose a novel deep domain generalization architecture utilizing synthetic data generated by a Generative Adversarial Network (GAN). The discrepancy between the generated images and synthetic images is minimized using existing domain discrepancy metrics such as maximum mean discrepancy or correlation alignment. In our second approach, we introduce a protocol for applying DA methods to a DG scenario by excluding the target data from the training phase, splitting the source data to training and validation parts, and treating the validation data as target data for DA. We conduct extensive experiments on four cross-domain benchmark datasets. Experimental results signify our proposed model outperforms the current state-of-the-art methods for DG.
SVD Based Image Processing Applications: State of The Art, Contributions and Research Challenges
Nov 29, 2012


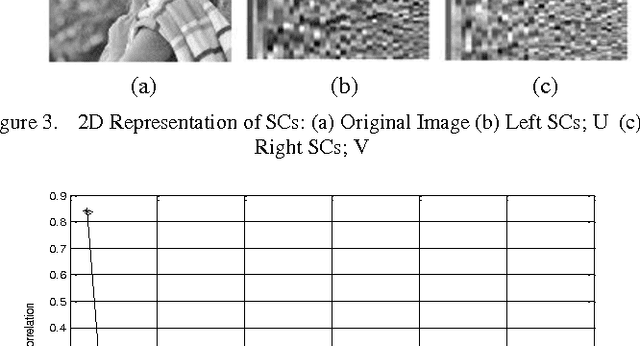
Singular Value Decomposition (SVD) has recently emerged as a new paradigm for processing different types of images. SVD is an attractive algebraic transform for image processing applications. The paper proposes an experimental survey for the SVD as an efficient transform in image processing applications. Despite the well-known fact that SVD offers attractive properties in imaging, the exploring of using its properties in various image applications is currently at its infancy. Since the SVD has many attractive properties have not been utilized, this paper contributes in using these generous properties in newly image applications and gives a highly recommendation for more research challenges. In this paper, the SVD properties for images are experimentally presented to be utilized in developing new SVD-based image processing applications. The paper offers survey on the developed SVD based image applications. The paper also proposes some new contributions that were originated from SVD properties analysis in different image processing. The aim of this paper is to provide a better understanding of the SVD in image processing and identify important various applications and open research directions in this increasingly important area; SVD based image processing in the future research.
Additive Angular Margin for Few Shot Learning to Classify Clinical Endoscopy Images
Mar 26, 2020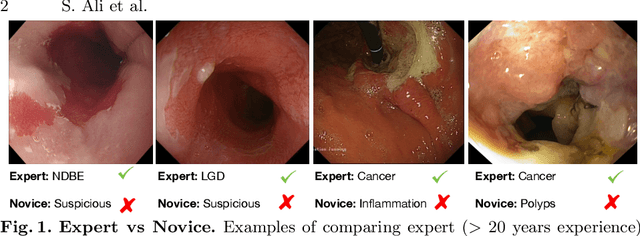
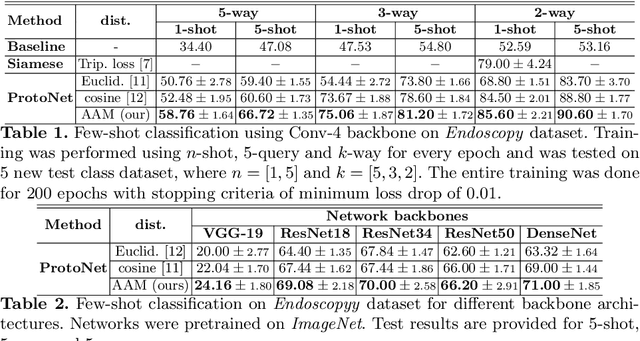
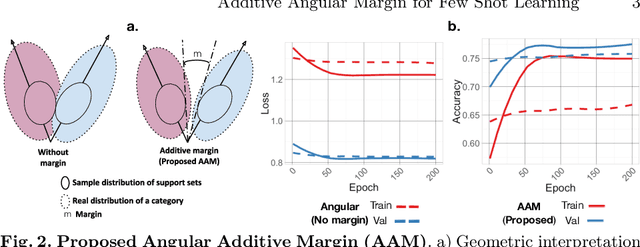
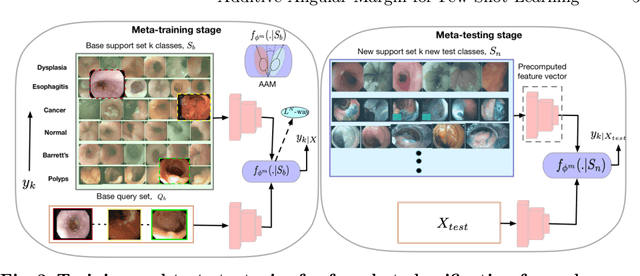
Endoscopy is a widely used imaging modality to diagnose and treat diseases in hollow organs as for example the gastrointestinal tract, the kidney and the liver. However, due to varied modalities and use of different imaging protocols at various clinical centers impose significant challenges when generalising deep learning models. Moreover, the assembly of large datasets from different clinical centers can introduce a huge label bias that renders any learnt model unusable. Also, when using new modality or presence of images with rare patterns, a bulk amount of similar image data and their corresponding labels are required for training these models. In this work, we propose to use a few-shot learning approach that requires less training data and can be used to predict label classes of test samples from an unseen dataset. We propose a novel additive angular margin metric in the framework of prototypical network in few-shot learning setting. We compare our approach to the several established methods on a large cohort of multi-center, multi-organ, and multi-modal endoscopy data. The proposed algorithm outperforms existing state-of-the-art methods.
Learning light field synthesis with Multi-Plane Images: scene encoding as a recurrent segmentation task
Feb 13, 2020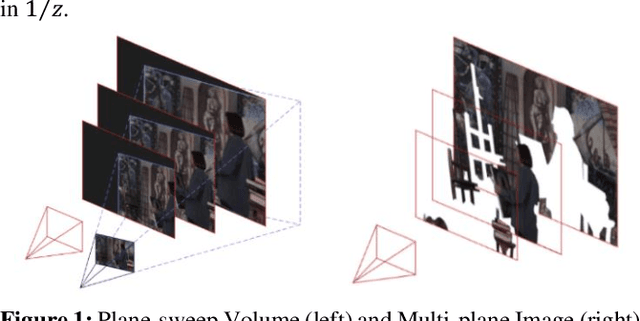
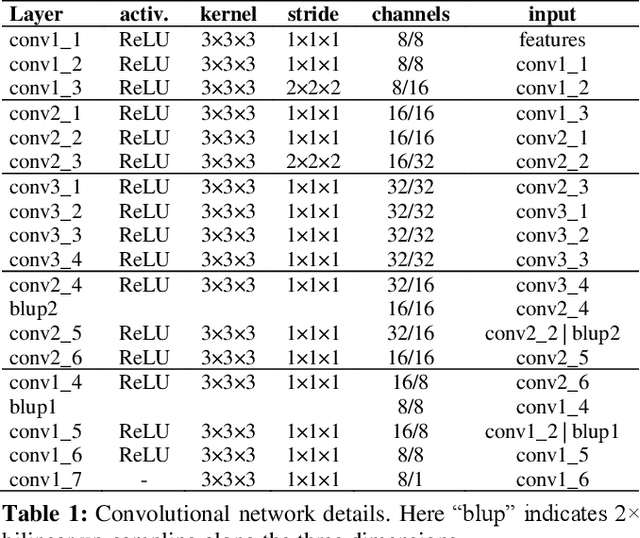

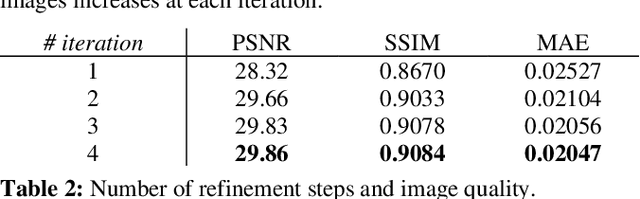
In this paper we address the problem of view synthesis from large baseline light fields, by turning a sparse set of input views into a Multi-plane Image (MPI). Because available datasets are scarce, we propose a lightweight network that does not require extensive training. Unlike latest approaches, our model does not learn to estimate RGB layers but only encodes the scene geometry within MPI alpha layers, which comes down to a segmentation task. A Learned Gradient Descent (LGD) framework is used to cascade the same convolutional network in a recurrent fashion in order to refine the volumetric representation obtained. Thanks to its low number of parameters, our model trains successfully on a small light field video dataset and provides visually appealing results. It also exhibits convenient generalization properties regarding both the number of input views, the number of depth planes in the MPI, and the number of refinement iterations.