 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAG-VAE: End-to-end Joint Inference of Data Representations and Feature Relations
Nov 27, 2019

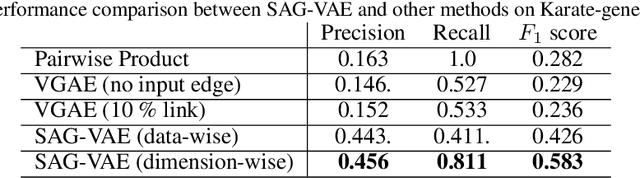
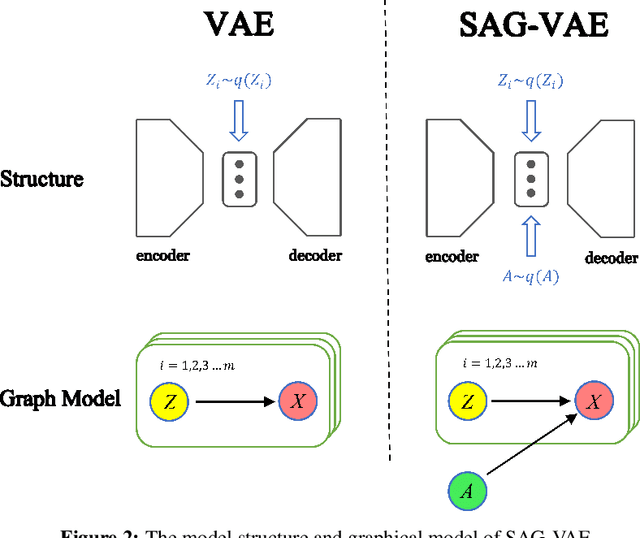
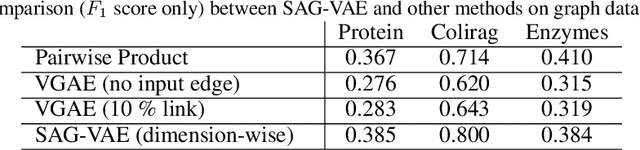
Variational Autoencoders (VAEs) are powerful in data representation inference, but it cannot learn relations between features with its vanilla form and common variations. The ability to capture relations within data can provide the much needed inductive bias necessary for building more robust Machine Learning algorithms with more interpretable results. In this paper, inspired by recent advances in relational learning using Graph Neural Networks, we propose the \textbf{S}elf-\textbf{A}ttention \textbf{G}raph \textbf{V}ariational \textbf{A}uto\textbf{E}ncoder (SAG-VAE) network which can simultaneously learn feature relations and data representations in an end-to-end manner. SAG-VAE is trained by jointly inferring the posterior distribution of two types of latent variables, which denote the data representation and a shared graph structure, respectively. Furthermore, we introduce a novel self-attention graph network that improves the generative capabilities of SAG-VAE by parameterizing the generative distribution allowing SAG-VAE to generate new data via graph convolution, while still trainable via backpropagation. A learnable relational graph representation enhances SAG-VAE's robustness to perturbation and noise, while also providing deeper intuition into model performance. Experiments based on graphs show that SAG-VAE is capable of approximately retrieving edges and links between nodes based entirely on feature observations. Finally, results on image data illustrate that SAG-VAE is fairly robust against perturbations in image reconstruction and sampling.
Imperceptible Adversarial Attacks on Tabular Data
Dec 13, 2019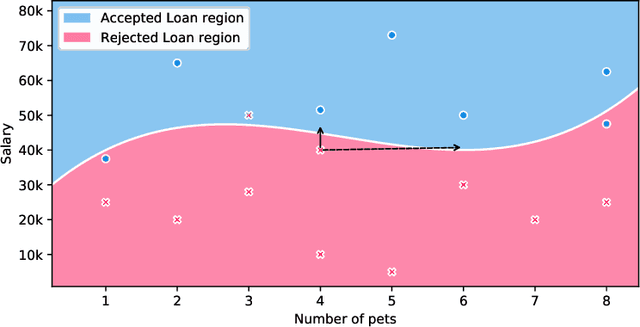
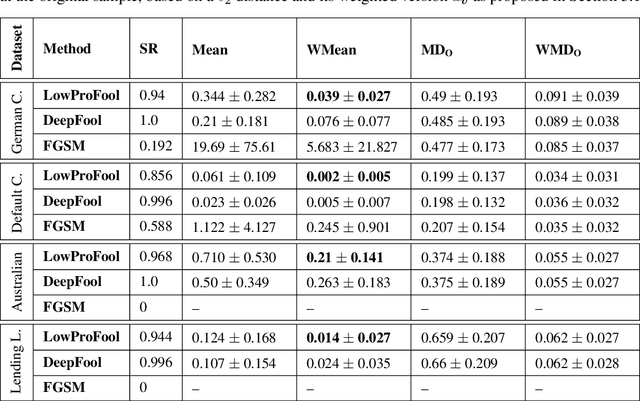
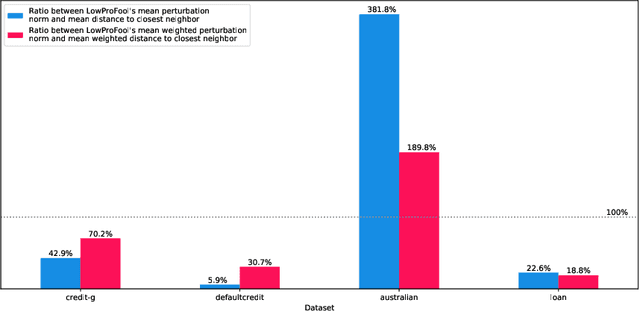
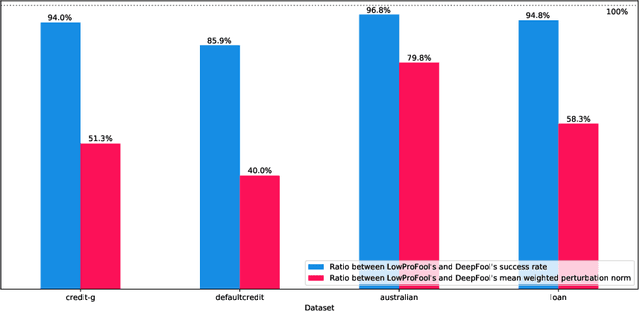
Security of machine learning models is a concern as they may face adversarial attacks for unwarranted advantageous decisions. While research on the topic has mainly been focusing on the image domain, numerous industrial applications, in particular in finance, rely on standard tabular data. In this paper, we discuss the notion of adversarial examples in the tabular domain. We propose a formalization based on the imperceptibility of attacks in the tabular domain leading to an approach to generate imperceptible adversarial examples. Experiments show that we can generate imperceptible adversarial examples with a high fooling rate.
Epipolar Transformers
May 10, 2020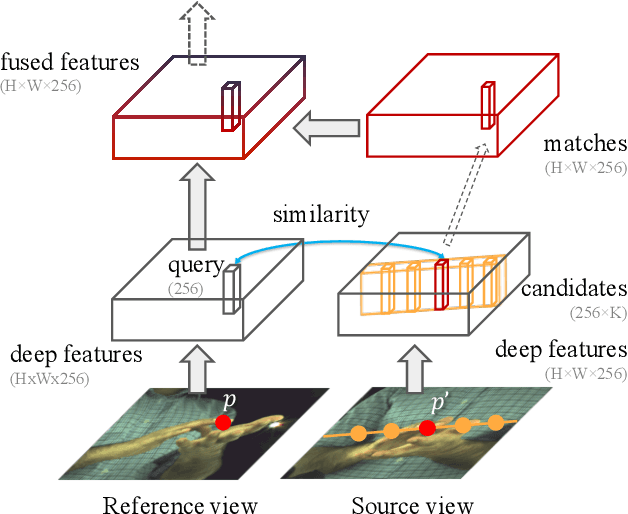
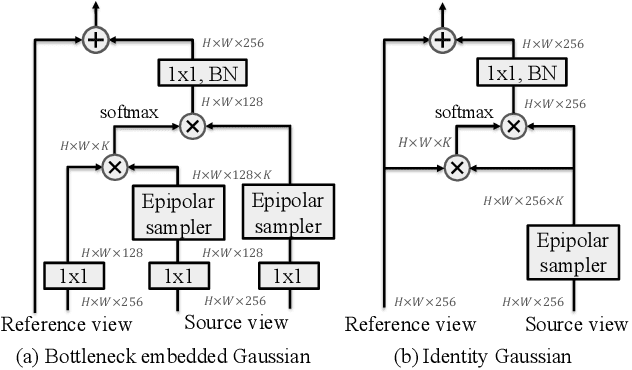


A common approach to localize 3D human joints in a synchronized and calibrated multi-view setup consists of two-steps: (1) apply a 2D detector separately on each view to localize joints in 2D, and (2) perform robust triangulation on 2D detections from each view to acquire the 3D joint locations. However, in step 1, the 2D detector is limited to solving challenging cases which could potentially be better resolved in 3D, such as occlusions and oblique viewing angles, purely in 2D without leveraging any 3D information. Therefore, we propose the differentiable "epipolar transformer", which enables the 2D detector to leverage 3D-aware features to improve 2D pose estimation. The intuition is: given a 2D location p in the current view, we would like to first find its corresponding point p' in a neighboring view, and then combine the features at p' with the features at p, thus leading to a 3D-aware feature at p. Inspired by stereo matching, the epipolar transformer leverages epipolar constraints and feature matching to approximate the features at p'. Experiments on InterHand and Human3.6M show that our approach has consistent improvements over the baselines. Specifically, in the condition where no external data is used, our Human3.6M model trained with ResNet-50 backbone and image size 256 x 256 outperforms state-of-the-art by 4.23 mm and achieves MPJPE 26.9 mm.
Self-Supervised Poisson-Gaussian Denoising
Feb 21, 2020
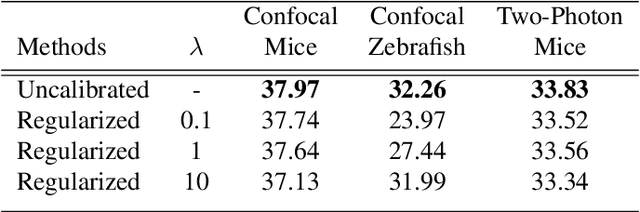
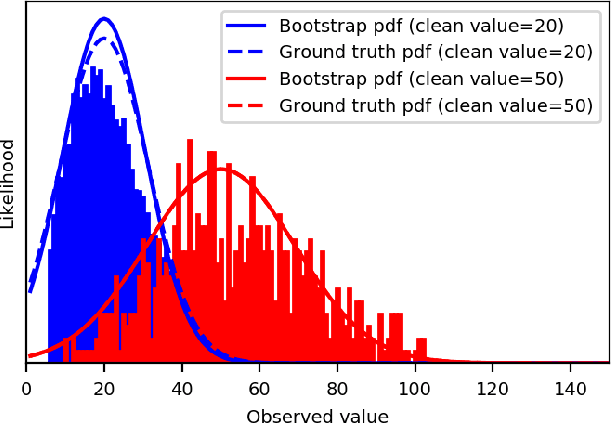
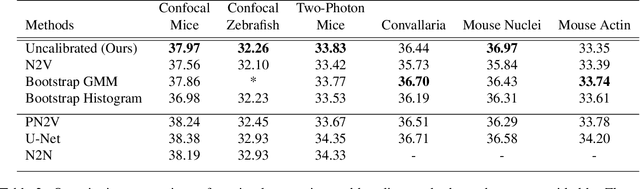
We extend the blindspot model for self-supervised denoising to handle Poisson-Gaussian noise and introduce an improved training scheme that avoids hyperparameters and adapts the denoiser to the test data. Self-supervised models for denoising learn to denoise from only noisy data and do not require corresponding clean images, which are difficult or impossible to acquire in some application areas of interest such as low-light microscopy. We introduce a new training strategy to handle Poisson-Gaussian noise which is the standard noise model for microscope images. Our new strategy eliminates hyperparameters from the loss function, which is important in a self-supervised regime where no ground truth data is available to guide hyperparameter tuning. We show how our denoiser can be adapted to the test data to improve performance. Our evaluation on a microscope image denoising benchmark validates our approach.
EPOSIT: An Absolute Pose Estimation Method for Pinhole and Fish-Eye Cameras
Sep 19, 2019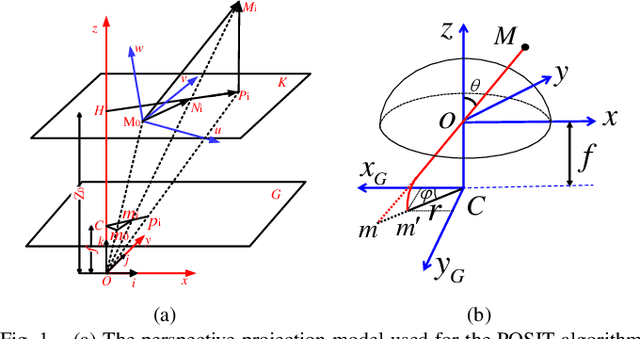
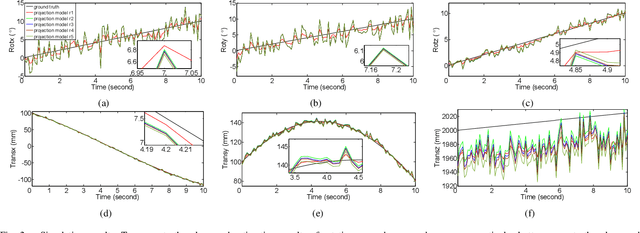
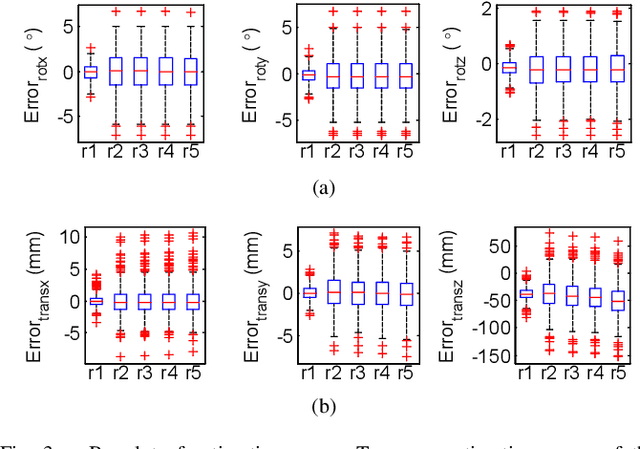
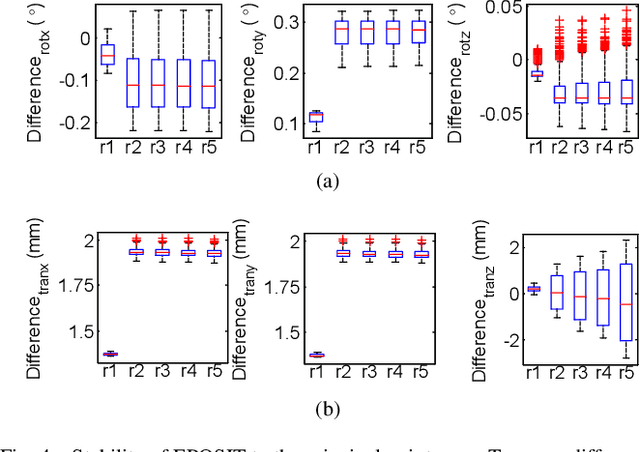
This paper presents a generic 6DOF camera pose estimation method, which can be used for both the pinhole camera and the fish-eye camera. Different from existing methods, relative positions of 3D points rather than absolute coordinates in the world coordinate system are employed in our method, and it has a unique solution. The application scope of POSIT (Pose from Orthography and Scaling with Iteration) algorithm is generalized to fish-eye cameras by combining with the radially symmetric projection model. The image point relationship between the pinhole camera and the fish-eye camera is derived based on their projection model. The general pose expression which fits for different cameras can be acquired by four noncoplanar object points and their corresponding image points. Accurate estimation results are calculated iteratively. Experimental results on synthetic and real data show that the pose estimation results of our method are more stable and accurate than state-of-the-art methods. The source code is available at https://github.com/k032131/EPOSIT.
Improved Super-Resolution Convolution Neural Network for Large Images
Jul 26, 2019
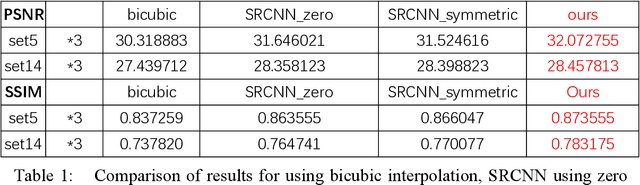
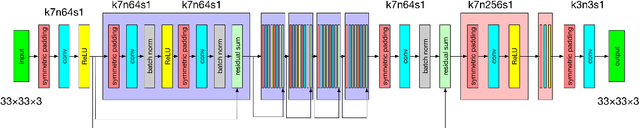

Single image super-resolution (SISR) is a very popular topic nowadays, which has both research value and practical value. In daily life, we crop a large image into sub-images to do super-resolution and then merge them together. Although convolution neural network performs very well in the research field, if we use it to do super-resolution, we can easily observe cutting lines from merged pictures. To address these problems, in this paper, we propose a refined architecture of SRCNN with 'Symmetric padding', 'Random learning' and 'Residual learning'. Moreover, we have done a lot of experiments to prove our model performs best among a lot of the state-of-art methods.
Assessment of SAR Image Filtering using Adaptive Stack Filters
Jul 18, 2012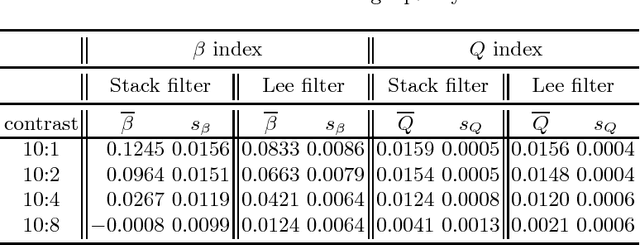
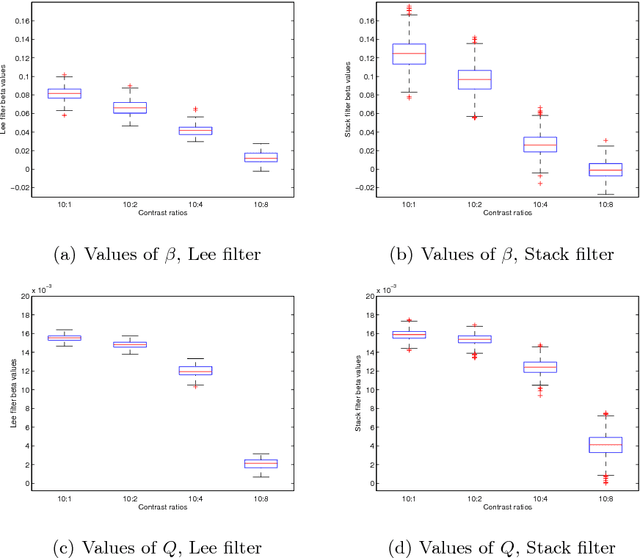

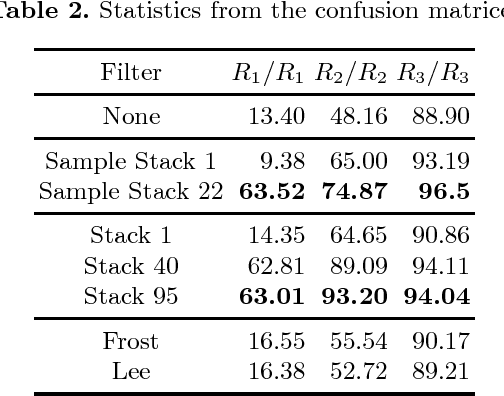
Stack filters are a special case of non-linear filters. They have a good performance for filtering images with different types of noise while preserving edges and details. A stack filter decomposes an input image into several binary images according to a set of thresholds. Each binary image is then filtered by a Boolean function, which characterizes the filter. Adaptive stack filters can be designed to be optimal; they are computed from a pair of images consisting of an ideal noiseless image and its noisy version. In this work we study the performance of adaptive stack filters when they are applied to Synthetic Aperture Radar (SAR) images. This is done by evaluating the quality of the filtered images through the use of suitable image quality indexes and by measuring the classification accuracy of the resulting images.
Diagnosis and Analysis of Celiac Disease and Environmental Enteropathy on Biopsy Images using Deep Learning Approaches
Jun 11, 2020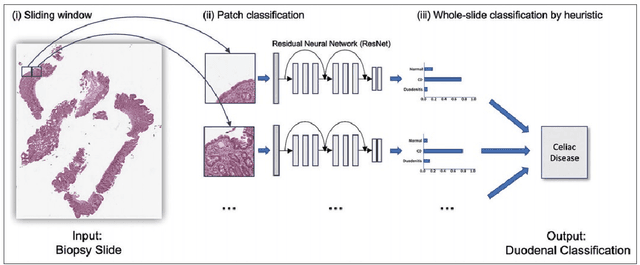
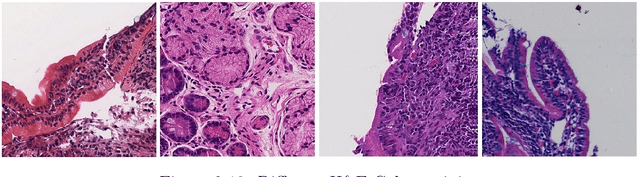


Celiac Disease (CD) and Environmental Enteropathy (EE) are common causes of malnutrition and adversely impact normal childhood development. Both conditions require a tissue biopsy for diagnosis and a major challenge of interpreting clinical biopsy images to differentiate between these gastrointestinal diseases is striking histopathologic overlap between them. In the current study, we propose four diagnosis techniques for these diseases and address their limitations and advantages. First, the diagnosis between CD, EE, and Normal biopsies is considered, but the main challenge with this diagnosis technique is the staining problem. The dataset used in this research is collected from different centers with different staining standards. To solve this problem, we use color balancing in order to train our model with a varying range of colors. Random Multimodel Deep Learning (RMDL) architecture has been used as another approach to mitigate the effects of the staining problem. RMDL combines different architectures and structures of deep learning and the final output of the model is based on the majority vote. CD is a chronic autoimmune disease that affects the small intestine genetically predisposed children and adults. Typically, CD rapidly progress from Marsh I to IIIa. Marsh III is sub-divided into IIIa (partial villus atrophy), Marsh IIIb (subtotal villous atrophy), and Marsh IIIc (total villus atrophy) to explain the spectrum of villus atrophy along with crypt hypertrophy and increased intraepithelial lymphocytes. In the second part of this study, we proposed two ways for diagnosing different stages of CD. Finally, in the third part of this study, these two steps are combined as Hierarchical Medical Image Classification (HMIC) to have a model to diagnose the disease data hierarchically.
Residual Attention U-Net for Automated Multi-Class Segmentation of COVID-19 Chest CT Images
Apr 12, 2020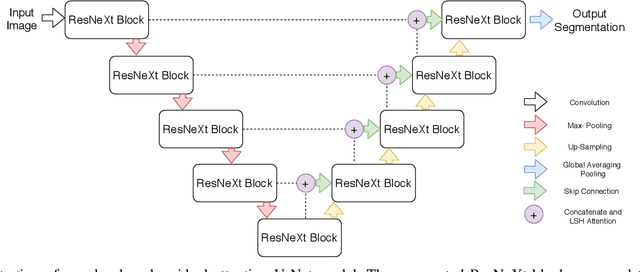
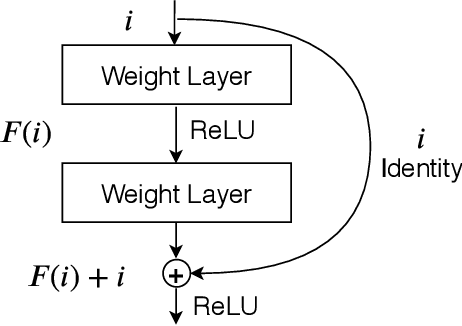
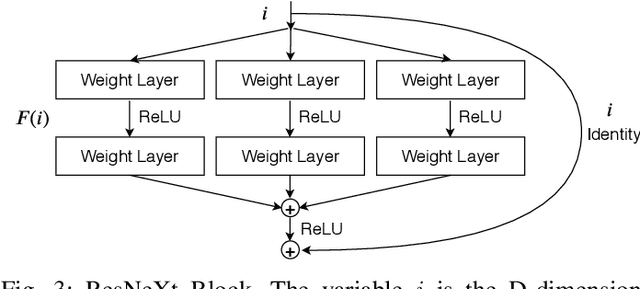
The novel coronavirus disease 2019 (COVID-19) has been spreading rapidly around the world and caused significant impact on the public health and economy. However, there is still lack of studies on effectively quantifying the lung infection caused by COVID-19. As a basic but challenging task of the diagnostic framework, segmentation plays a crucial role in accurate quantification of COVID-19 infection measured by computed tomography (CT) images. To this end, we proposed a novel deep learning algorithm for automated segmentation of multiple COVID-19 infection regions. Specifically, we use the Aggregated Residual Transformations to learn a robust and expressive feature representation and apply the soft attention mechanism to improve the capability of the model to distinguish a variety of symptoms of the COVID-19. With a public CT image dataset, we validate the efficacy of the proposed algorithm in comparison with other competing methods. Experimental results demonstrate the outstanding performance of our algorithm for automated segmentation of COVID-19 Chest CT images. Our study provides a promising deep leaning-based segmentation tool to lay a foundation to quantitative diagnosis of COVID-19 lung infection in CT images.
Stochastic Latent Residual Video Prediction
Feb 21, 2020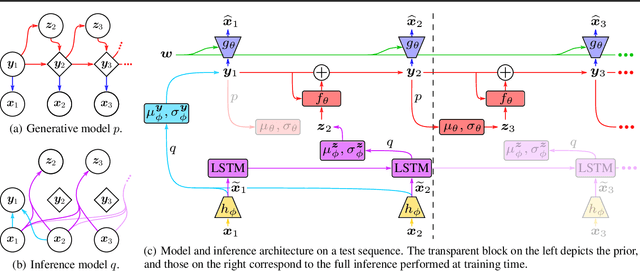

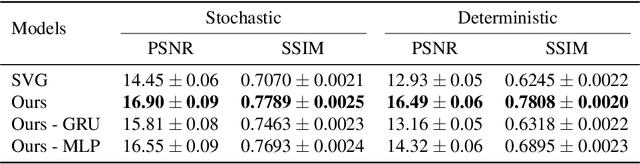
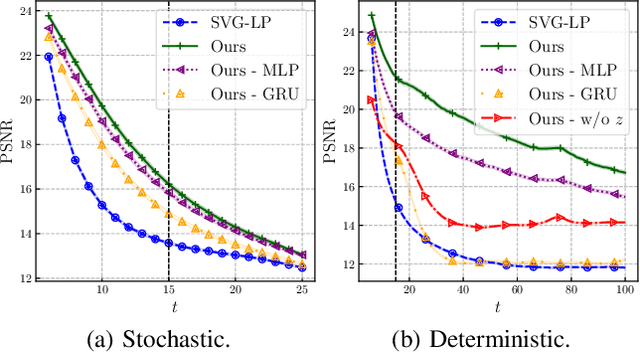
Designing video prediction models that account for the inherent uncertainty of the future is challenging. Most works in the literature are based on stochastic image-autoregressive recurrent networks, which raises several performance and applicability issues. An alternative is to use fully latent temporal models which untie frame synthesis and temporal dynamics. However, no such model for stochastic video prediction has been proposed in the literature yet, due to design and training difficulties. In this paper, we overcome these difficulties by introducing a novel stochastic temporal model whose dynamics are governed in a latent space by a residual update rule. This first-order scheme is motivated by discretization schemes of differential equations. It naturally models video dynamics as it allows our simpler, more interpretable, latent model to outperform prior state-of-the-art methods on challenging datasets.