 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAM-guided Graph Cut for 3D Instance Segmentation
Dec 25, 2023
This paper addresses the challenge of 3D instance segmentation by simultaneously leveraging 3D geometric and multi-view image information. Many previous works have applied deep learning techniques to 3D point clouds for instance segmentation. However, these methods often failed to generalize to various types of scenes due to the scarcity and low-diversity of labeled 3D point cloud data. Some recent works have attempted to lift 2D instance segmentations to 3D within a bottom-up framework. The inconsistency in 2D instance segmentations among views can substantially degrade the performance of 3D segmentation. In this work, we introduce a novel 3D-to-2D query framework to effectively exploit 2D segmentation models for 3D instance segmentation. Specifically, we pre-segment the scene into several superpoints in 3D, formulating the task into a graph cut problem. The superpoint graph is constructed based on 2D segmentation models, where node features are obtained from multi-view image features and edge weights are computed based on multi-view segmentation results, enabling the better generalization ability. To process the graph, we train a graph neural network using pseudo 3D labels from 2D segmentation models. Experimental results on the ScanNet, ScanNet++ and KITTI-360 datasets demonstrate that our method achieves robust segmentation performance and can generalize across different types of scenes. Our project page is available at https://zju3dv.github.io/sam_graph.
pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction
Dec 21, 2023We introduce pixelSplat, a feed-forward model that learns to reconstruct 3D radiance fields parameterized by 3D Gaussian primitives from pairs of images. Our model features real-time and memory-efficient rendering for scalable training as well as fast 3D reconstruction at inference time. To overcome local minima inherent to sparse and locally supported representations, we predict a dense probability distribution over 3D and sample Gaussian means from that probability distribution. We make this sampling operation differentiable via a reparameterization trick, allowing us to back-propagate gradients through the Gaussian splatting representation. We benchmark our method on wide-baseline novel view synthesis on the real-world RealEstate10k and ACID datasets, where we outperform state-of-the-art light field transformers and accelerate rendering by 2.5 orders of magnitude while reconstructing an interpretable and editable 3D radiance field.
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Dec 22, 2023We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
Brush Your Text: Synthesize Any Scene Text on Images via Diffusion Model
Dec 19, 2023Recently, diffusion-based image generation methods are credited for their remarkable text-to-image generation capabilities, while still facing challenges in accurately generating multilingual scene text images. To tackle this problem, we propose Diff-Text, which is a training-free scene text generation framework for any language. Our model outputs a photo-realistic image given a text of any language along with a textual description of a scene. The model leverages rendered sketch images as priors, thus arousing the potential multilingual-generation ability of the pre-trained Stable Diffusion. Based on the observation from the influence of the cross-attention map on object placement in generated images, we propose a localized attention constraint into the cross-attention layer to address the unreasonable positioning problem of scene text. Additionally, we introduce contrastive image-level prompts to further refine the position of the textual region and achieve more accurate scene text generation. Experiments demonstrate that our method outperforms the existing method in both the accuracy of text recognition and the naturalness of foreground-background blending.
InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following
Dec 30, 2023The ability to provide fine-grained control for generating and editing visual imagery has profound implications for computer vision and its applications. Previous works have explored extending controllability in two directions: instruction tuning with text-based prompts and multi-modal conditioning. However, these works make one or more unnatural assumptions on the number and/or type of modality inputs used to express controllability. We propose InstructAny2Pix, a flexible multi-modal instruction-following system that enables users to edit an input image using instructions involving audio, images, and text. InstructAny2Pix consists of three building blocks that facilitate this capability: a multi-modal encoder that encodes different modalities such as images and audio into a unified latent space, a diffusion model that learns to decode representations in this latent space into images, and a multi-modal LLM that can understand instructions involving multiple images and audio pieces and generate a conditional embedding of the desired output, which can be used by the diffusion decoder. Additionally, to facilitate training efficiency and improve generation quality, we include an additional refinement prior module that enhances the visual quality of LLM outputs. These designs are critical to the performance of our system. We demonstrate that our system can perform a series of novel instruction-guided editing tasks. The code is available at https://github.com/jacklishufan/InstructAny2Pix.git
Unsupervised Segmentation of Colonoscopy Images
Dec 19, 2023Colonoscopy plays a crucial role in the diagnosis and prognosis of various gastrointestinal diseases. Due to the challenges of collecting large-scale high-quality ground truth annotations for colonoscopy images, and more generally medical images, we explore using self-supervised features from vision transformers in three challenging tasks for colonoscopy images. Our results indicate that image-level features learned from DINO models achieve image classification performance comparable to fully supervised models, and patch-level features contain rich semantic information for object detection. Furthermore, we demonstrate that self-supervised features combined with unsupervised segmentation can be used to discover multiple clinically relevant structures in a fully unsupervised manner, demonstrating the tremendous potential of applying these methods in medical image analysis.
KOALA: Self-Attention Matters in Knowledge Distillation of Latent Diffusion Models for Memory-Efficient and Fast Image Synthesis
Dec 07, 2023Stable diffusion is the mainstay of the text-to-image (T2I) synthesis in the community due to its generation performance and open-source nature. Recently, Stable Diffusion XL (SDXL), the successor of stable diffusion, has received a lot of attention due to its significant performance improvements with a higher resolution of 1024x1024 and a larger model. However, its increased computation cost and model size require higher-end hardware(e.g., bigger VRAM GPU) for end-users, incurring higher costs of operation. To address this problem, in this work, we propose an efficient latent diffusion model for text-to-image synthesis obtained by distilling the knowledge of SDXL. To this end, we first perform an in-depth analysis of the denoising U-Net in SDXL, which is the main bottleneck of the model, and then design a more efficient U-Net based on the analysis. Secondly, we explore how to effectively distill the generation capability of SDXL into an efficient U-Net and eventually identify four essential factors, the core of which is that self-attention is the most important part. With our efficient U-Net and self-attention-based knowledge distillation strategy, we build our efficient T2I models, called KOALA-1B & -700M, while reducing the model size up to 54% and 69% of the original SDXL model. In particular, the KOALA-700M is more than twice as fast as SDXL while still retaining a decent generation quality. We hope that due to its balanced speed-performance tradeoff, our KOALA models can serve as a cost-effective alternative to SDXL in resource-constrained environments.
SR-LIVO: LiDAR-Inertial-Visual Odometry and Mapping with Sweep Reconstruction
Dec 28, 2023Existing LiDAR-inertial-visual odometry and mapping (LIV-SLAM) systems mainly utilize the LiDAR-inertial odometry (LIO) module for structure reconstruction and the visual-inertial odometry (VIO) module for color rendering. However, the accuracy of VIO is often compromised by photometric changes, weak textures and motion blur, unlike the more robust LIO. This paper introduces SR-LIVO, an advanced and novel LIV-SLAM system employing sweep reconstruction to align reconstructed sweeps with image timestamps. This allows the LIO module to accurately determine states at all imaging moments, enhancing pose accuracy and processing efficiency. Experimental results on two public datasets demonstrate that: 1) our SRLIVO outperforms existing state-of-the-art LIV-SLAM systems in both pose accuracy and time efficiency; 2) our LIO-based pose estimation prove more accurate than VIO-based ones in several mainstream LIV-SLAM systems (including ours). We have released our source code to contribute to the community development in this field.
Towards General Purpose Vision Foundation Models for Medical Image Analysis: An Experimental Study of DINOv2 on Radiology Benchmarks
Dec 04, 2023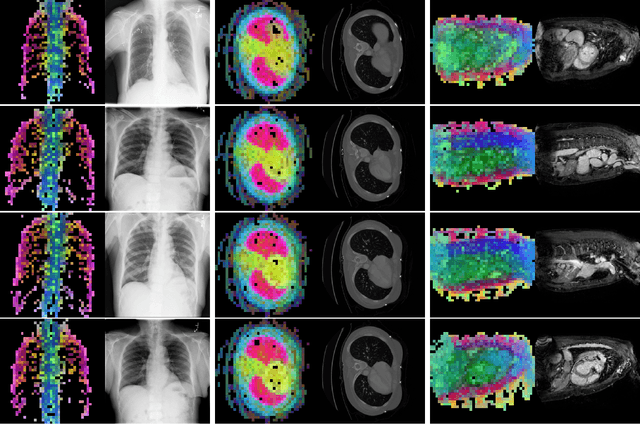
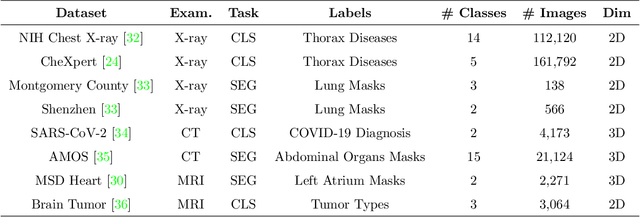
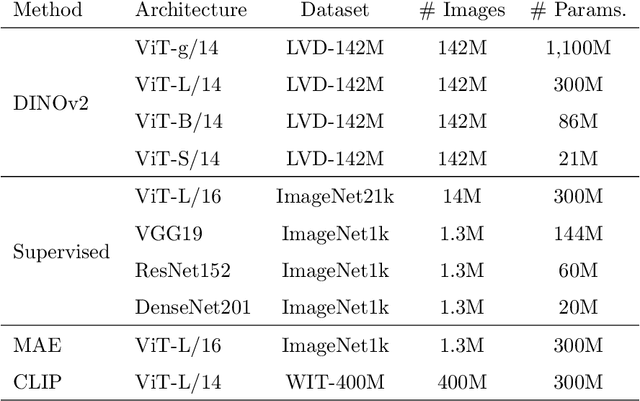
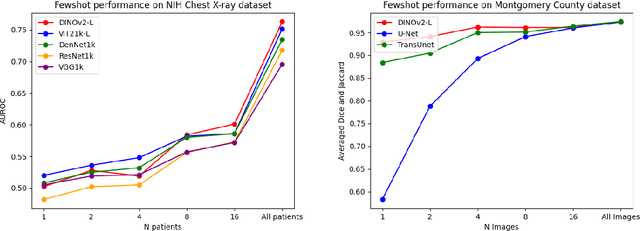
The integration of deep learning systems into the medical domain has been hindered by the resource-intensive process of data annotation and the inability of these systems to generalize to different data distributions. Foundation models, which are models pre-trained on large datasets, have emerged as a solution to reduce reliance on annotated data and enhance model generalizability and robustness. DINOv2, an open-source foundation model pre-trained with self-supervised learning on 142 million curated natural images, excels in extracting general-purpose visual representations, exhibiting promising capabilities across various vision tasks. Nevertheless, a critical question remains unanswered regarding DINOv2's adaptability to radiological imaging, and the clarity on whether its features are sufficiently general to benefit radiology image analysis is yet to be established. Therefore, this study comprehensively evaluates DINOv2 for radiology, conducting over 100 experiments across diverse modalities (X-ray, CT, and MRI). Tasks include disease classification and organ segmentation on both 2D and 3D images, evaluated under different settings like kNN, few-shot learning, linear-probing, end-to-end fine-tuning, and parameter-efficient fine-tuning, to measure the effectiveness and generalizability of the DINOv2 feature embeddings. Comparative analyses with established medical image analysis models, U-Net and TransUnet for segmentation, and CNN and ViT models pre-trained via supervised, weakly supervised, and self-supervised learning for classification, reveal DINOv2's superior performance in segmentation tasks and competitive results in disease classification. The findings contribute insights to potential avenues for optimizing pre-training strategies for medical imaging and enhancing the broader understanding of DINOv2's role in bridging the gap between natural and radiological image analysis.
Research on the Laws of Multimodal Perception and Cognition from a Cross-cultural Perspective -- Taking Overseas Chinese Gardens as an Example
Dec 29, 2023This study aims to explore the complex relationship between perceptual and cognitive interactions in multimodal data analysis,with a specific emphasis on spatial experience design in overseas Chinese gardens. It is found that evaluation content and images on social media can reflect individuals' concerns and sentiment responses, providing a rich data base for cognitive research that contains both sentimental and image-based cognitive information. Leveraging deep learning techniques, we analyze textual and visual data from social media, thereby unveiling the relationship between people's perceptions and sentiment cognition within the context of overseas Chinese gardens. In addition, our study introduces a multi-agent system (MAS)alongside AI agents. Each agent explores the laws of aesthetic cognition through chat scene simulation combined with web search. This study goes beyond the traditional approach of translating perceptions into sentiment scores, allowing for an extension of the research methodology in terms of directly analyzing texts and digging deeper into opinion data. This study provides new perspectives for understanding aesthetic experience and its impact on architecture and landscape design across diverse cultural contexts, which is an essential contribution to the field of cultural communication and aesthetic understanding.