 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Models for Digital Pathology
Oct 29, 2019


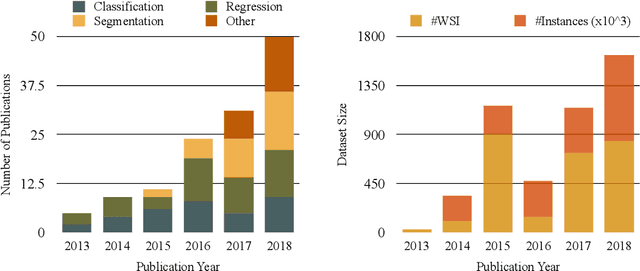
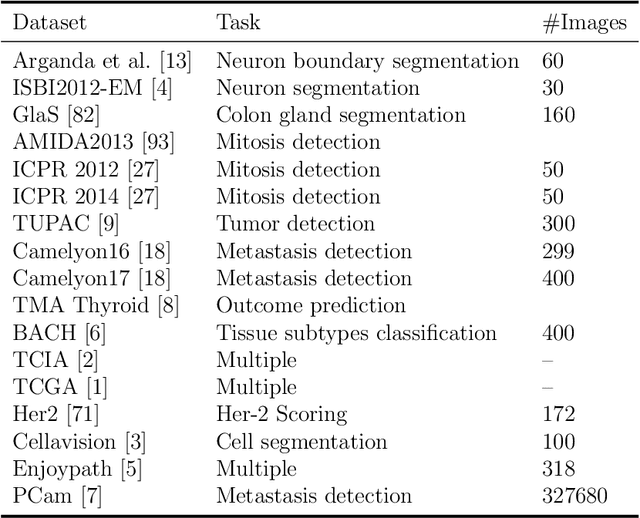
Histopathology images; microscopy images of stained tissue biopsies contain fundamental prognostic information that forms the foundation of pathological analysis and diagnostic medicine. However, diagnostics from histopathology images generally rely on a visual cognitive assessment of tissue slides which implies an inherent element of interpretation and hence subjectivity. Access to digitized histopathology images enabled the development of computational systems aiming at reducing manual intervention and automating parts of pathologists' workflow. Specifically, applications of deep learning to histopathology image analysis now offer opportunities for better quantitative modeling of disease appearance and hence possibly improved prediction of disease aggressiveness and patient outcome. However digitized histopathology tissue slides are unique in a variety of ways and come with their own set of computational challenges. In this survey, we summarize the different challenges facing computational systems for digital pathology and provide a review of state-of-the-art works that developed deep learning-based solutions for the predictive modeling of histopathology images from a detection, stain normalization, segmentation, and tissue classification perspective. We then discuss the challenges facing the validation and integration of such deep learning-based computational systems in clinical workflow and reflect on future opportunities for histopathology derived image measurements and better predictive modeling.
On Learning Vehicle Detection in Satellite Video
Jan 29, 2020
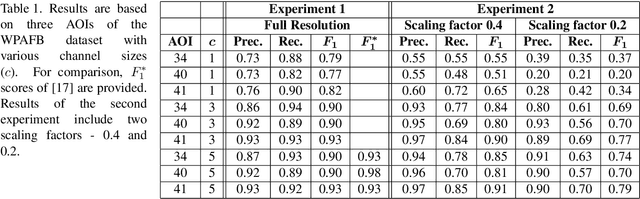

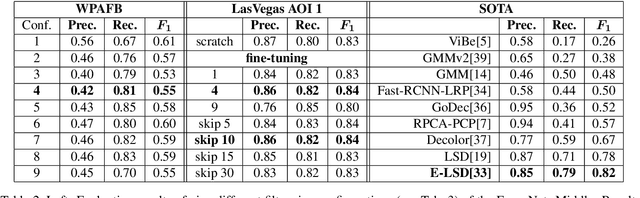
Vehicle detection in aerial and satellite images is still challenging due to their tiny appearance in pixels compared to the overall size of remote sensing imagery. Classical methods of object detection very often fail in this scenario due to violation of implicit assumptions made such as rich texture, small to moderate ratios between image size and object size. Satellite video is a very new modality which introduces temporal consistency as inductive bias. Approaches for vehicle detection in satellite video use either background subtraction, frame differencing or subspace methods showing moderate performance (0.26 - 0.82 $F_1$ score). This work proposes to apply recent work on deep learning for wide-area motion imagery (WAMI) on satellite video. We show in a first approach comparable results (0.84 $F_1$) on Planet's SkySat-1 LasVegas video with room for further improvement.
On Reducing Negative Jacobian Determinant of the Deformation Predicted by Deep Registration Networks
Jun 28, 2019

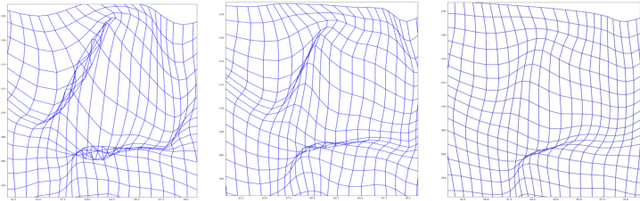
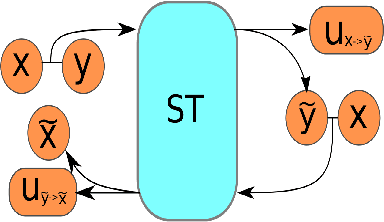
Image registration is a fundamental step in medical image analysis. Ideally, the transformation that registers one image to another should be a diffeomorphism that is both invertible and smooth. Traditional methods like geodesic shooting approach the problem via differential geometry, with theoretical guarantees that the resulting transformation will be smooth and invertible. Most previous research using unsupervised deep neural networks for registration have used a local smoothness constraint (typically, a spatial variation loss) to address the smoothness issue. These networks usually produce non-invertible transformations with ``folding'' in multiple voxel locations, indicated by a negative determinant of the Jacobian matrix of the transformation. While using a loss function that specifically penalizes the folding is a straightforward solution, this usually requires carefully tuning the regularization strength, especially when there are also other losses. In this paper we address this problem from a different angle, by investigating possible training mechanisms that will help the network avoid negative Jacobians and produce smoother deformations. We contribute two independent ideas in this direction. Both ideas greatly reduce the number of folding locations in the predicted deformation, without making changes to the hyperparameters or the architecture used in the existing baseline registration network.
Detecting GAN generated Fake Images using Co-occurrence Matrices
Mar 15, 2019
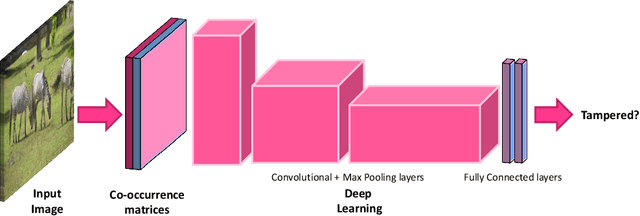
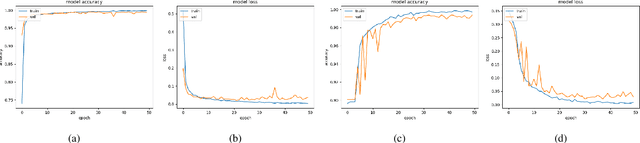
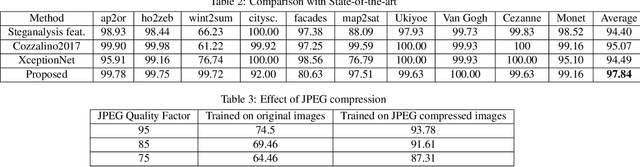
The advent of Generative Adversarial Networks (GANs) has brought about completely novel ways of transforming and manipulating pixels in digital images. GAN based techniques such as Image-to-Image translations, DeepFakes, and other automated methods have become increasingly popular in creating fake images. In this paper, we propose a novel approach to detect GAN generated fake images using a combination of co-occurrence matrices and deep learning. We extract co-occurrence matrices on three color channels in the pixel domain and train a model using a deep convolutional neural network (CNN) framework. Experimental results on two diverse and challenging GAN datasets comprising more than 56,000 images based on unpaired image-to-image translations (cycleGAN [1]) and facial attributes/expressions (StarGAN [2]) show that our approach is promising and achieves more than 99% classification accuracy in both datasets. Further, our approach also generalizes well and achieves good results when trained on one dataset and tested on the other.
Iterative training of neural networks for intra prediction
Mar 15, 2020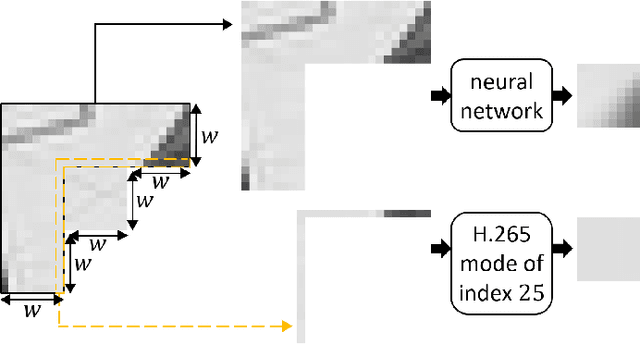



This paper presents an iterative training of neural networks for intra prediction in a block-based image and video codec. First, the neural networks are trained on blocks arising from the codec partitioning of images, each paired with its context. Then, iteratively, blocks are collected from the partitioning of images via the codec including the neural networks trained at the previous iteration, each paired with its context, and the neural networks are retrained on the new pairs. Thanks to this training, the neural networks can learn intra prediction functions that both stand out from those already in the initial codec and boost the codec in terms of rate-distortion. Moreover, the iterative process allows the design of training data cleansings essential for the neural network training. When the iteratively trained neural networks are put into H.265 (HM-16.15), -4.2% of mean dB-rate reduction is obtained, that is -1.8% above the state-of-the-art. By moving them into H.266 (VTM-5.0), the mean dB-rate reduction reaches -1.9%.
Bidirectional Learning for Domain Adaptation of Semantic Segmentation
Apr 24, 2019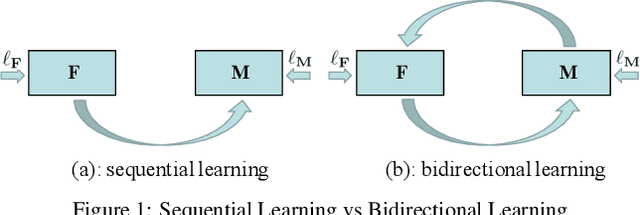
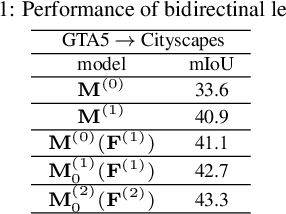
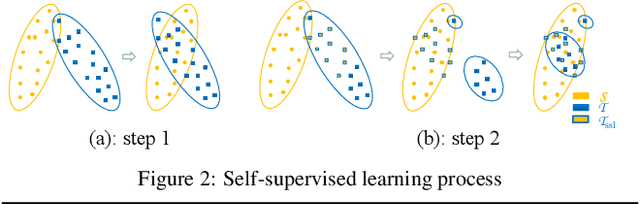
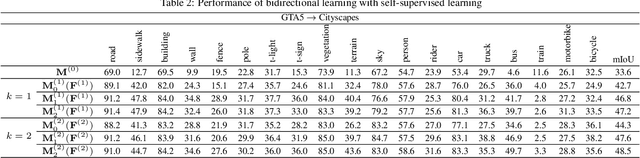
Domain adaptation for semantic image segmentation is very necessary since manually labeling large datasets with pixel-level labels is expensive and time consuming. Existing domain adaptation techniques either work on limited datasets, or yield not so good performance compared with supervised learning. In this paper, we propose a novel bidirectional learning framework for domain adaptation of segmentation. Using the bidirectional learning, the image translation model and the segmentation adaptation model can be learned alternatively and promote to each other. Furthermore, we propose a self-supervised learning algorithm to learn a better segmentation adaptation model and in return improve the image translation model. Experiments show that our method is superior to the state-of-the-art methods in domain adaptation of segmentation with a big margin. The source code is available at https://github.com/liyunsheng13/BDL.
RealMonoDepth: Self-Supervised Monocular Depth Estimation for General Scenes
Apr 14, 2020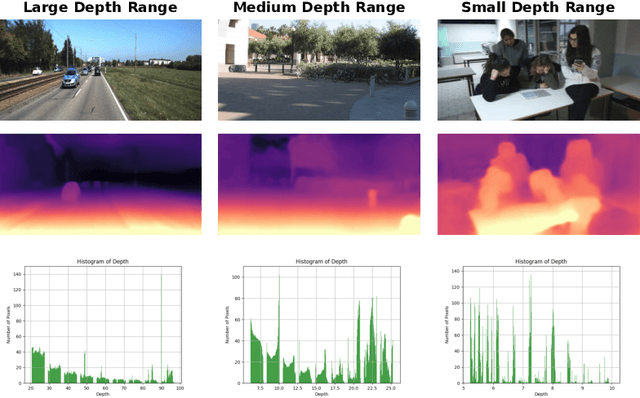
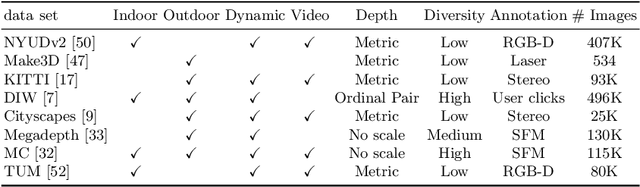

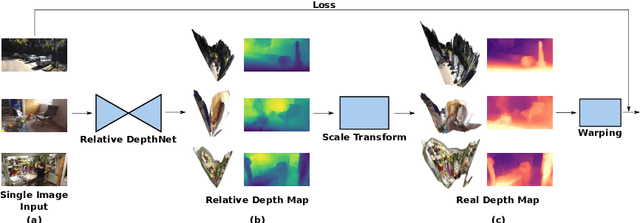
We present a generalised self-supervised learning approach for monocular estimation of the real depth across scenes with diverse depth ranges from 1--100s of meters. Existing supervised methods for monocular depth estimation require accurate depth measurements for training. This limitation has led to the introduction of self-supervised methods that are trained on stereo image pairs with a fixed camera baseline to estimate disparity which is transformed to depth given known calibration. Self-supervised approaches have demonstrated impressive results but do not generalise to scenes with different depth ranges or camera baselines. In this paper, we introduce RealMonoDepth a self-supervised monocular depth estimation approach which learns to estimate the real scene depth for a diverse range of indoor and outdoor scenes. A novel loss function with respect to the true scene depth based on relative depth scaling and warping is proposed. This allows self-supervised training of a single network with multiple data sets for scenes with diverse depth ranges from both stereo pair and in the wild moving camera data sets. A comprehensive performance evaluation across five benchmark data sets demonstrates that RealMonoDepth provides a single trained network which generalises depth estimation across indoor and outdoor scenes, consistently outperforming previous self-supervised approaches.
Bayesian image segmentations by Potts prior and loopy belief propagation
Aug 18, 2014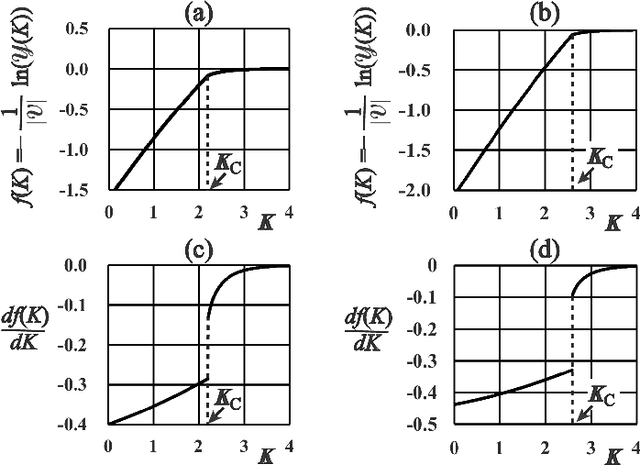
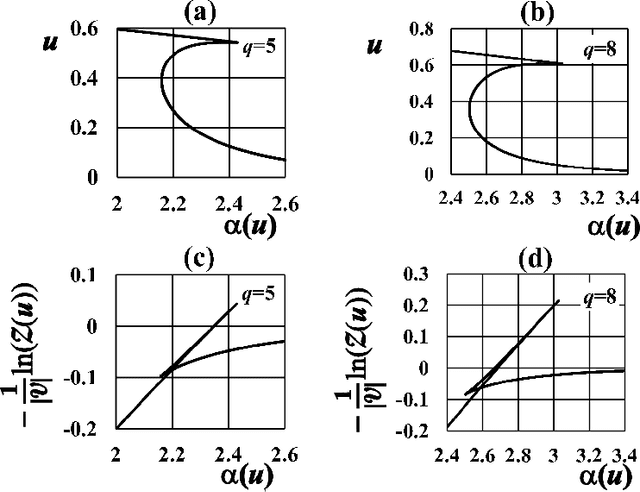

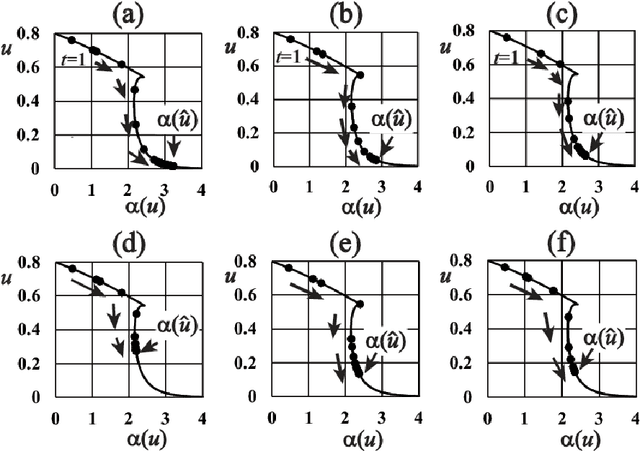
This paper presents a Bayesian image segmentation model based on Potts prior and loopy belief propagation. The proposed Bayesian model involves several terms, including the pairwise interactions of Potts models, and the average vectors and covariant matrices of Gauss distributions in color image modeling. These terms are often referred to as hyperparameters in statistical machine learning theory. In order to determine these hyperparameters, we propose a new scheme for hyperparameter estimation based on conditional maximization of entropy in the Potts prior. The algorithm is given based on loopy belief propagation. In addition, we compare our conditional maximum entropy framework with the conventional maximum likelihood framework, and also clarify how the first order phase transitions in LBP's for Potts models influence our hyperparameter estimation procedures.
* 24 pages, 9 figures
FAMED-Net: A Fast and Accurate Multi-scale End-to-end Dehazing Network
Jun 11, 2019

Single image dehazing is a critical image pre-processing step for subsequent high-level computer vision tasks. However, it remains challenging due to its ill-posed nature. Existing dehazing models tend to suffer from model overcomplexity and computational inefficiency or have limited representation capacity. To tackle these challenges, here we propose a fast and accurate multi-scale end-to-end dehazing network called FAMED-Net, which comprises encoders at three scales and a fusion module to efficiently and directly learn the haze-free image. Each encoder consists of cascaded and densely connected point-wise convolutional layers and pooling layers. Since no larger convolutional kernels are used and features are reused layer-by-layer, FAMED-Net is lightweight and computationally efficient. Thorough empirical studies on public synthetic datasets (including RESIDE) and real-world hazy images demonstrate the superiority of FAMED-Net over other representative state-of-the-art models with respect to model complexity, computational efficiency, restoration accuracy, and cross-set generalization. The code will be made publicly available.
Image segmentation with superpixel-based covariance descriptors in low-rank representation
May 18, 2016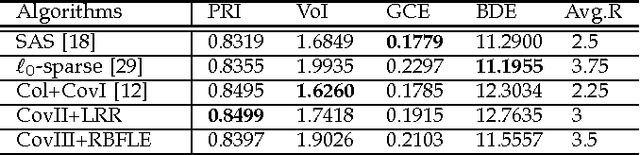
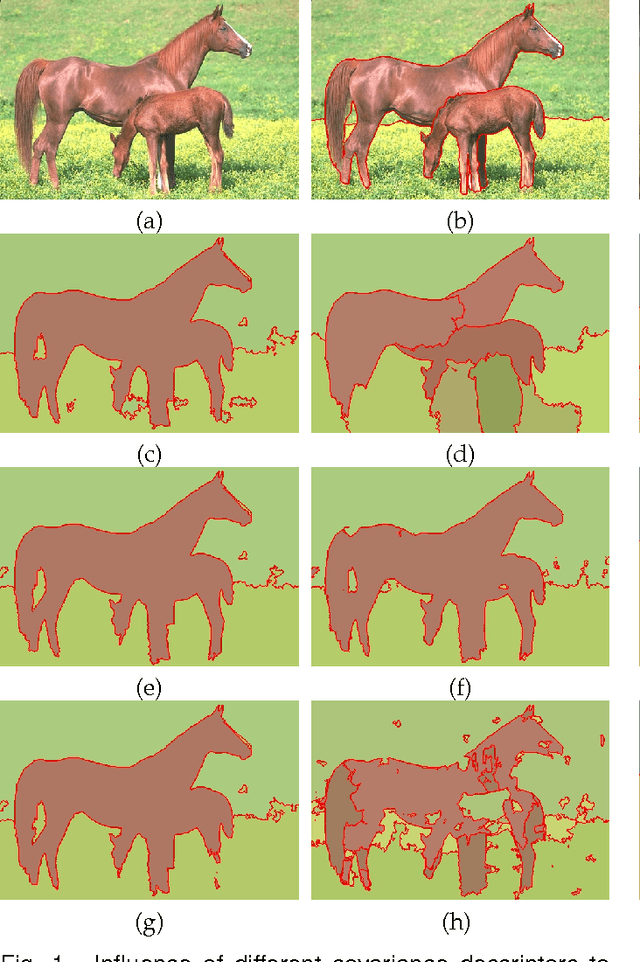
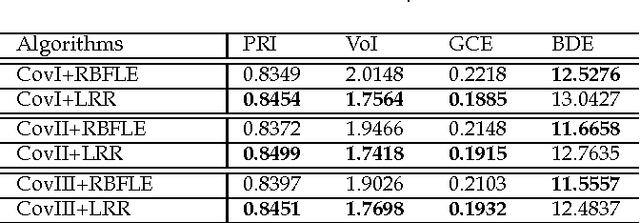
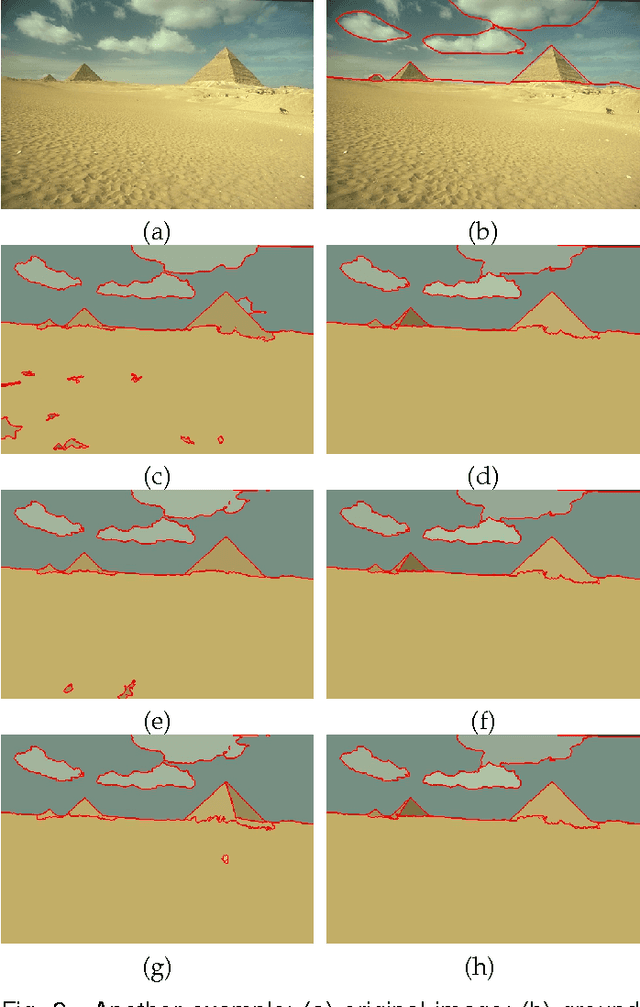
This paper investigates the problem of image segmentation using superpixels. We propose two approaches to enhance the discriminative ability of the superpixel's covariance descriptors. In the first one, we employ the Log-Euclidean distance as the metric on the covariance manifolds, and then use the RBF kernel to measure the similarities between covariance descriptors. The second method is focused on extracting the subspace structure of the set of covariance descriptors by extending a low rank representation algorithm on to the covariance manifolds. Experiments are carried out with the Berkly Segmentation Dataset, and compared with the state-of-the-art segmentation algorithms, both methods are competitive.