 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Mining External Imperfect Data for Chest X-ray Disease Screening
Jun 06, 2020
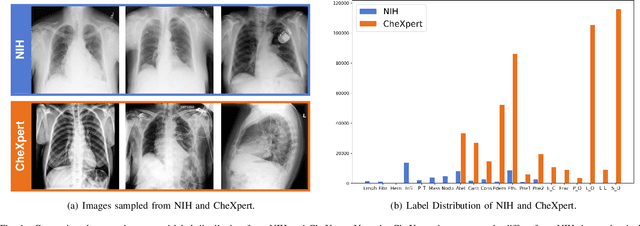
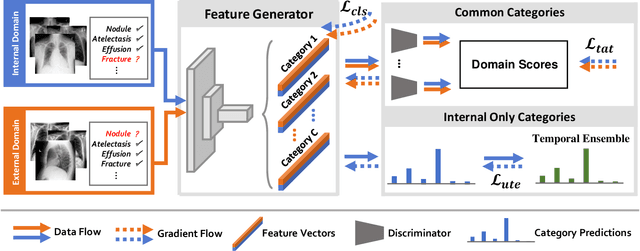
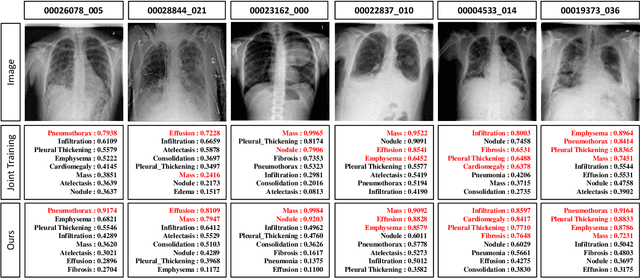
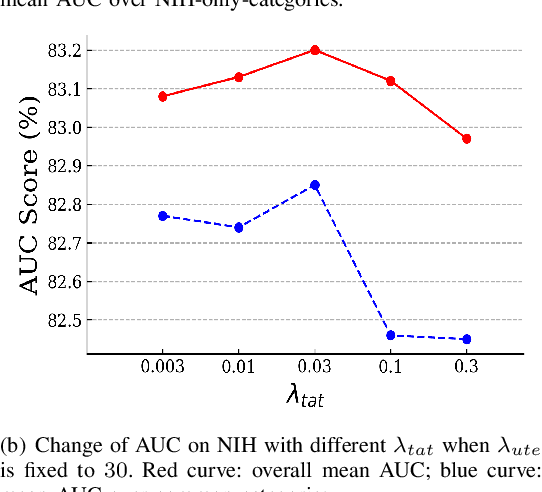
Deep learning approaches have demonstrated remarkable progress in automatic Chest X-ray analysis. The data-driven feature of deep models requires training data to cover a large distribution. Therefore, it is substantial to integrate knowledge from multiple datasets, especially for medical images. However, learning a disease classification model with extra Chest X-ray (CXR) data is yet challenging. Recent researches have demonstrated that performance bottleneck exists in joint training on different CXR datasets, and few made efforts to address the obstacle. In this paper, we argue that incorporating an external CXR dataset leads to imperfect training data, which raises the challenges. Specifically, the imperfect data is in two folds: domain discrepancy, as the image appearances vary across datasets; and label discrepancy, as different datasets are partially labeled. To this end, we formulate the multi-label thoracic disease classification problem as weighted independent binary tasks according to the categories. For common categories shared across domains, we adopt task-specific adversarial training to alleviate the feature differences. For categories existing in a single dataset, we present uncertainty-aware temporal ensembling of model predictions to mine the information from the missing labels further. In this way, our framework simultaneously models and tackles the domain and label discrepancies, enabling superior knowledge mining ability. We conduct extensive experiments on three datasets with more than 360,000 Chest X-ray images. Our method outperforms other competing models and sets state-of-the-art performance on the official NIH test set with 0.8349 AUC, demonstrating its effectiveness of utilizing the external dataset to improve the internal classification.
Anchor Loss: Modulating Loss Scale based on Prediction Difficulty
Sep 24, 2019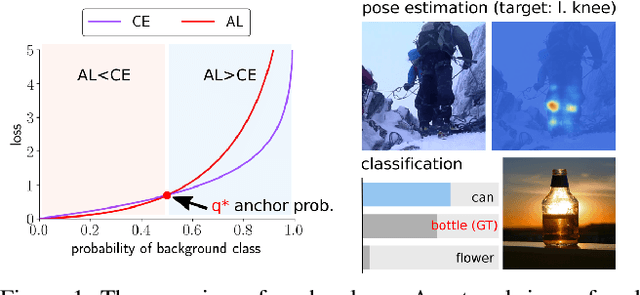
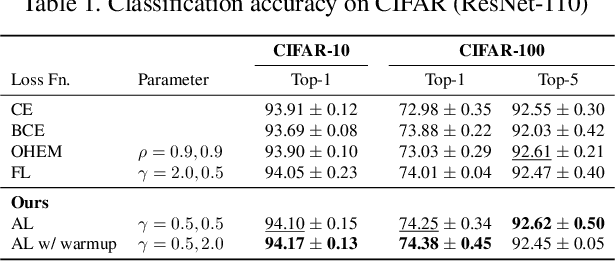
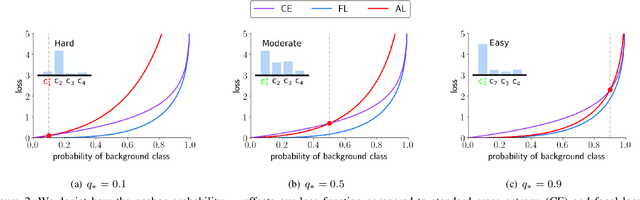

We propose a novel loss function that dynamically rescales the cross entropy based on prediction difficulty regarding a sample. Deep neural network architectures in image classification tasks struggle to disambiguate visually similar objects. Likewise, in human pose estimation symmetric body parts often confuse the network with assigning indiscriminative scores to them. This is due to the output prediction, in which only the highest confidence label is selected without taking into consideration a measure of uncertainty. In this work, we define the prediction difficulty as a relative property coming from the confidence score gap between positive and negative labels. More precisely, the proposed loss function penalizes the network to avoid the score of a false prediction being significant. To demonstrate the efficacy of our loss function, we evaluate it on two different domains: image classification and human pose estimation. We find improvements in both applications by achieving higher accuracy compared to the baseline methods.
Functional Asplund's metrics for pattern matching robust to variable lighting conditions
Sep 04, 2019

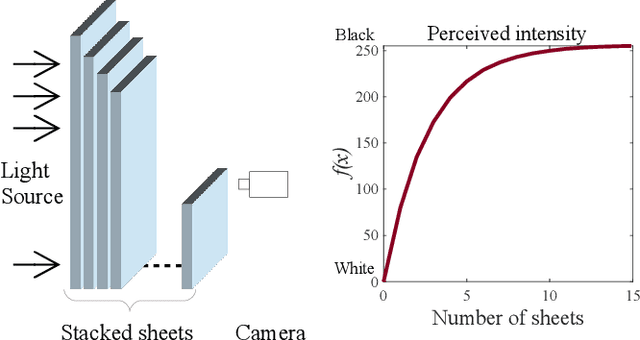
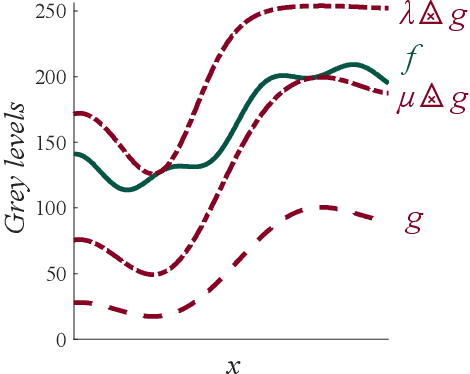
In this paper, we propose a complete framework to process images captured under uncontrolled lighting and especially under low lighting. By taking advantage of the Logarithmic Image Processing (LIP) context, we study two novel functional metrics: i) the LIP-multiplicative Asplund's metric which is robust to object absorption variations and ii) the LIP-additive Asplund's metric which is robust to variations of source intensity and exposure-time. We introduce robust to noise versions of these metrics. We demonstrate that the maps of their corresponding distances between an image and a reference template are linked to Mathematical Morphology. This facilitates their implementation. We assess them in various situations with different lightings and movements. Results show that those maps of distances are robust to lighting variations. Importantly, they are efficient to detect patterns in low-contrast images with a template acquired under a different lighting.
Tracking by Instance Detection: A Meta-Learning Approach
Apr 02, 2020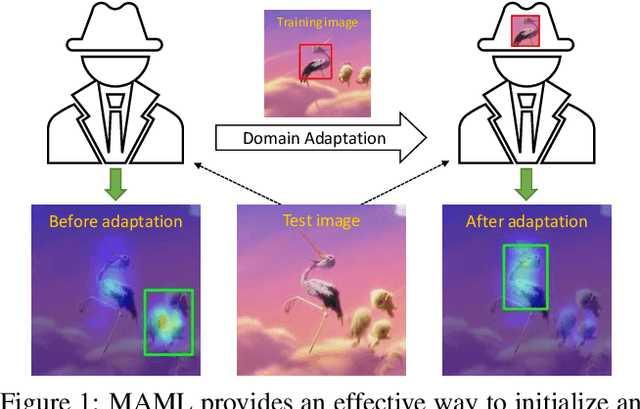
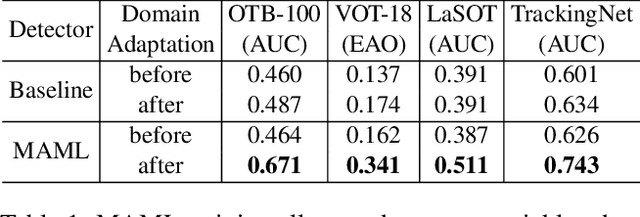
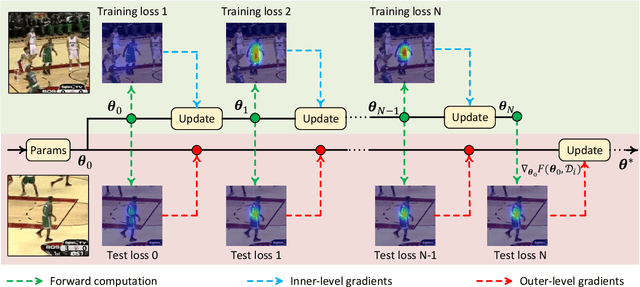
We consider the tracking problem as a special type of object detection problem, which we call instance detection. With proper initialization, a detector can be quickly converted into a tracker by learning the new instance from a single image. We find that model-agnostic meta-learning (MAML) offers a strategy to initialize the detector that satisfies our needs. We propose a principled three-step approach to build a high-performance tracker. First, pick any modern object detector trained with gradient descent. Second, conduct offline training (or initialization) with MAML. Third, perform domain adaptation using the initial frame. We follow this procedure to build two trackers, named Retina-MAML and FCOS-MAML, based on two modern detectors RetinaNet and FCOS. Evaluations on four benchmarks show that both trackers are competitive against state-of-the-art trackers. On OTB-100, Retina-MAML achieves the highest ever AUC of 0.712. On TrackingNet, FCOS-MAML ranks the first on the leader board with an AUC of 0.757 and the normalized precision of 0.822. Both trackers run in real-time at 40 FPS.
Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task
Dec 02, 2019
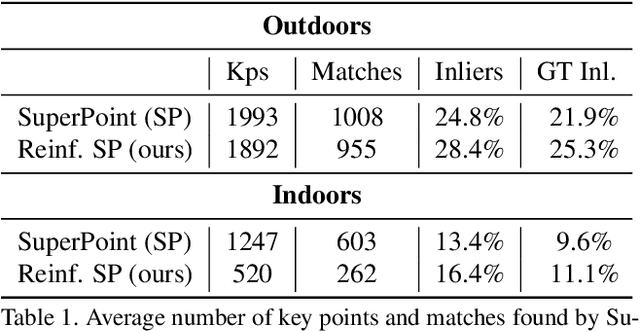
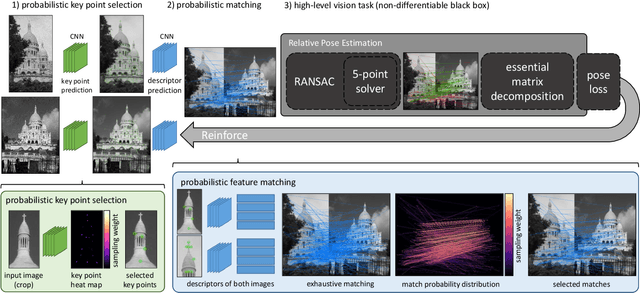
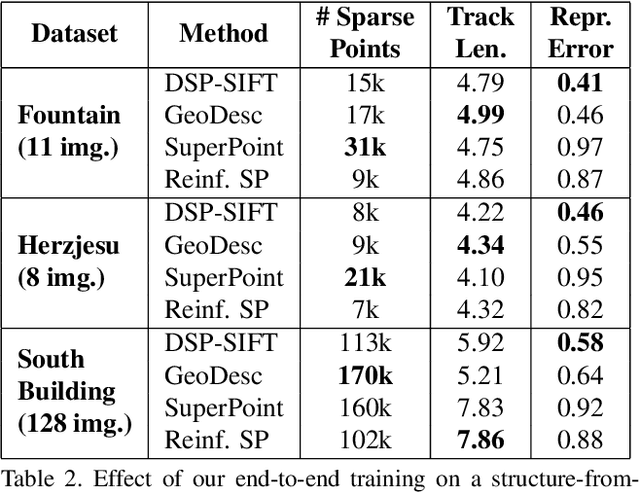
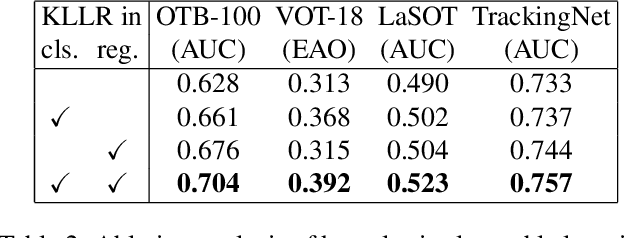
We address a core problem of computer vision: Detection and description of 2D feature points for image matching. For a long time, hand-crafted designs, like the seminal SIFT algorithm, were unsurpassed in accuracy and efficiency. Recently, learned feature detectors emerged that implement detection and description using neural networks. Training these networks usually resorts to optimizing low-level matching scores, often pre-defining sets of image patches which should or should not match, or which should or should not contain key points. Unfortunately, increased accuracy for these low-level matching scores does not necessarily translate to better performance in high-level vision tasks. We propose a new training methodology which embeds the feature detector in a complete vision pipeline, and where the learnable parameters are trained in an end-to-end fashion. We overcome the discrete nature of key point selection and descriptor matching using principles from reinforcement learning. As an example, we address the task of relative pose estimation between a pair of images. We demonstrate that the accuracy of a state-of-the-art learning-based feature detector can be increased when trained for the task it is supposed to solve at test time. Our training methodology poses little restrictions on the task to learn, and works for any architecture which predicts key point heat maps, and descriptors for key point locations.
Vehicles Detection Based on Background Modeling
Jan 13, 2019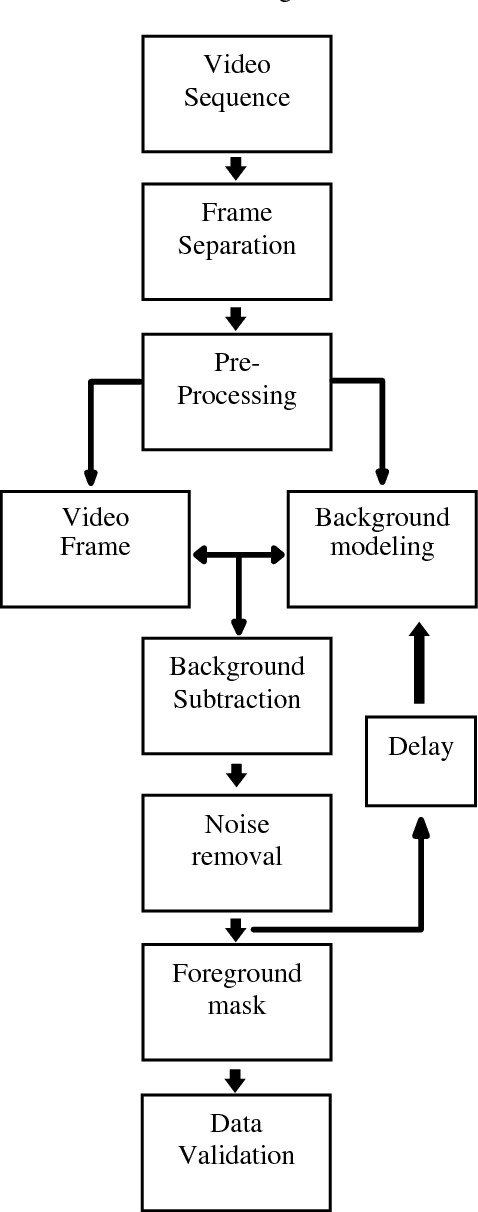
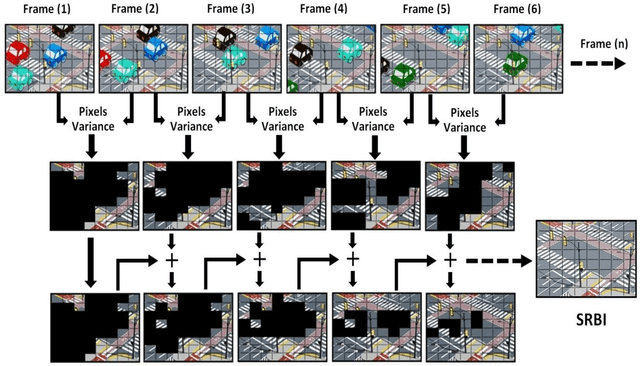


Background image subtraction algorithm is a common approach which detects moving objects in a video sequence by finding the significant difference between the video frames and the static background model. This paper presents a developed system which achieves vehicle detection by using background image subtraction algorithm based on blocks followed by deep learning data validation algorithm. The main idea is to segment the image into equal size blocks, to model the static reference background image (SRBI), by calculating the variance between each block pixels and each counterpart block pixels in the adjacent frame, the system implemented into four different methods: Absolute Difference, Image Entropy, Exclusive OR (XOR) and Discrete Cosine Transform (DCT). The experimental results showed that the DCT method has the highest vehicle detection accuracy.
* 4 pages, 4 figures
Robust Federated Learning: The Case of Affine Distribution Shifts
Jun 16, 2020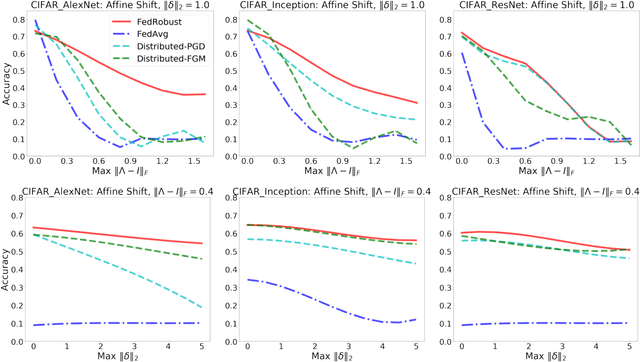

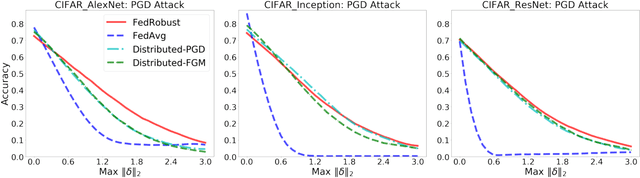
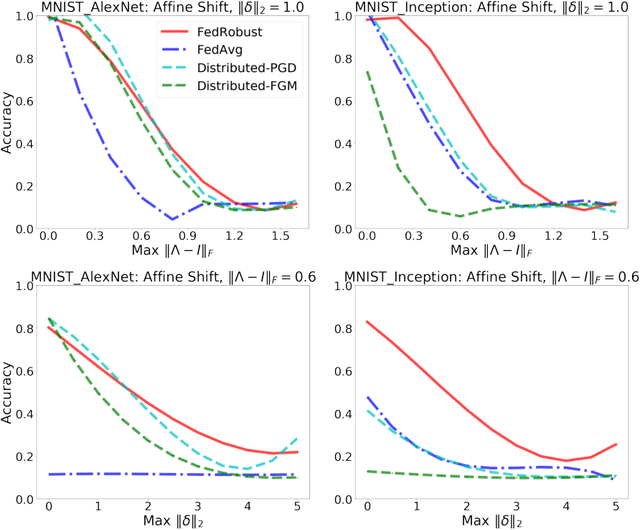
Federated learning is a distributed paradigm that aims at training models using samples distributed across multiple users in a network while keeping the samples on users' devices with the aim of efficiency and protecting users privacy. In such settings, the training data is often statistically heterogeneous and manifests various distribution shifts across users, which degrades the performance of the learnt model. The primary goal of this paper is to develop a robust federated learning algorithm that achieves satisfactory performance against distribution shifts in users' samples. To achieve this goal, we first consider a structured affine distribution shift in users' data that captures the device-dependent data heterogeneity in federated settings. This perturbation model is applicable to various federated learning problems such as image classification where the images undergo device-dependent imperfections, e.g. different intensity, contrast, and brightness. To address affine distribution shifts across users, we propose a Federated Learning framework Robust to Affine distribution shifts (FLRA) that is provably robust against affine Wasserstein shifts to the distribution of observed samples. To solve the FLRA's distributed minimax problem, we propose a fast and efficient optimization method and provide convergence guarantees via a gradient Descent Ascent (GDA) method. We further prove generalization error bounds for the learnt classifier to show proper generalization from empirical distribution of samples to the true underlying distribution. We perform several numerical experiments to empirically support FLRA. We show that an affine distribution shift indeed suffices to significantly decrease the performance of the learnt classifier in a new test user, and our proposed algorithm achieves a significant gain in comparison to standard federated learning and adversarial training methods.
Unsupervised Deep Metric Learning via Auxiliary Rotation Loss
Nov 16, 2019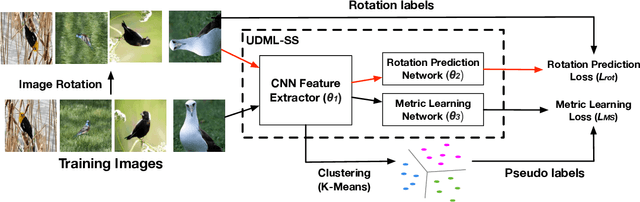
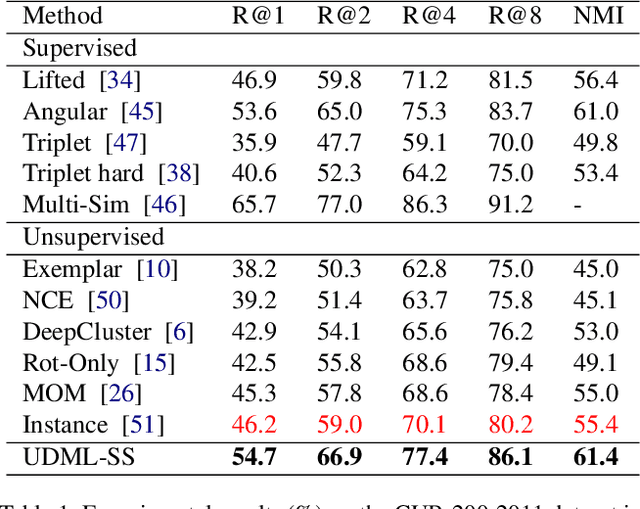

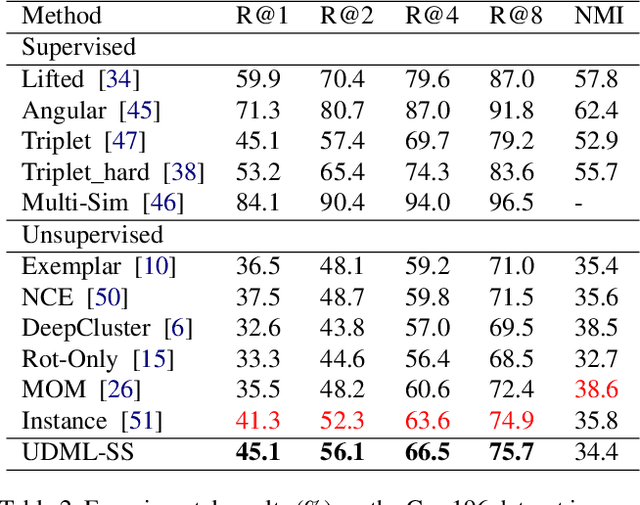
Deep metric learning is an important area due to its applicability to many domains such as image retrieval and person re-identification. The main drawback of such models is the necessity for labeled data. In this work, we propose to generate pseudo-labels for deep metric learning directly from clustering assignment and we introduce unsupervised deep metric learning (UDML) regularized by a self-supervision (SS) task. In particular, we propose to regularize the training process by predicting image rotations. Our method (UDML-SS) jointly learns discriminative embeddings, unsupervised clustering assignments of the embeddings, as well as a self-supervised pretext task. UDML-SS iteratively cluster embeddings using traditional clustering algorithm (e.g., k-means), and sampling training pairs based on the cluster assignment for metric learning, while optimizing self-supervised pretext task in a multi-task fashion. The role of self-supervision is to stabilize the training process and encourages the model to learn meaningful feature representations that are not distorted due to unreliable clustering assignments. The proposed method performs well on standard benchmarks for metric learning, where it outperforms current state-of-the-art approaches by a large margin and it also shows competitive performance with various metric learning loss functions.
Leaf segmentation through the classification of edges
Apr 05, 2019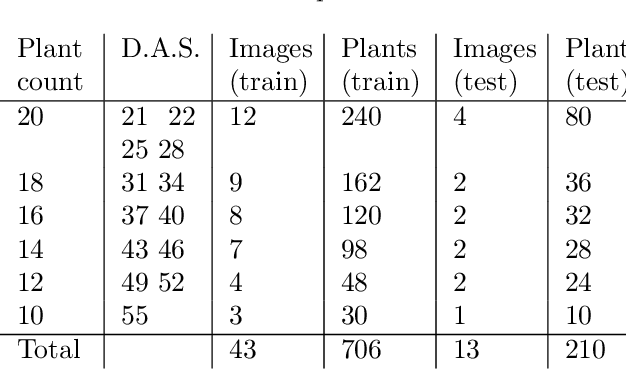

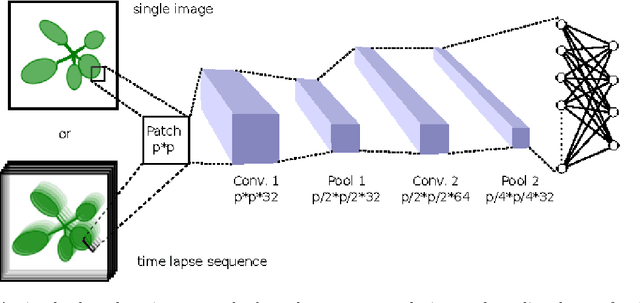
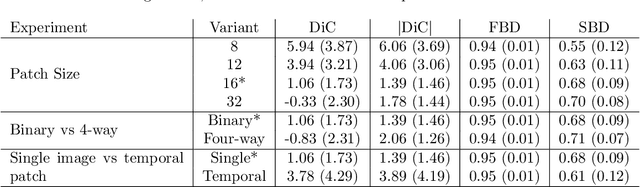
We present an approach to leaf level segmentation of images of Arabidopsis thaliana plants based upon detected edges. We introduce a novel approach to edge classification, which forms an important part of a method to both count the leaves and establish the leaf area of a growing plant from images obtained in a high-throughput phenotyping system. Our technique uses a relatively shallow convolutional neural network to classify image edges as background, plant edge, leaf-on-leaf edge or internal leaf noise. The edges themselves were found using the Canny edge detector and the classified edges can be used with simple image processing techniques to generate a region-based segmentation in which the leaves are distinct. This approach is strong at distinguishing occluding pairs of leaves where one leaf is largely hidden, a situation which has proved troublesome for plant image analysis systems in the past. In addition, we introduce the publicly available plant image dataset that was used for this work.
Distilling Spikes: Knowledge Distillation in Spiking Neural Networks
May 01, 2020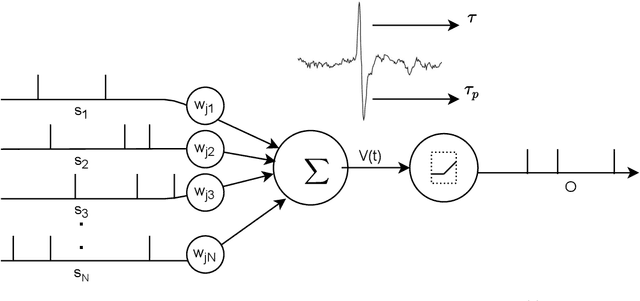
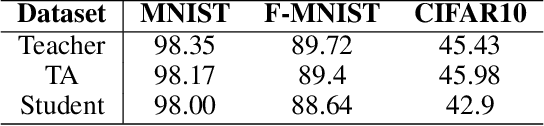
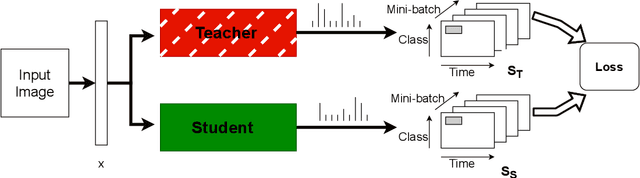
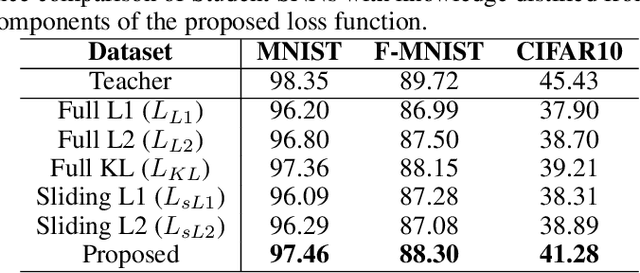
Spiking Neural Networks (SNN) are energy-efficient computing architectures that exchange spikes for processing information, unlike classical Artificial Neural Networks (ANN). Due to this, SNNs are better suited for real-life deployments. However, similar to ANNs, SNNs also benefit from deeper architectures to obtain improved performance. Furthermore, like the deep ANNs, the memory, compute and power requirements of SNNs also increase with model size, and model compression becomes a necessity. Knowledge distillation is a model compression technique that enables transferring the learning of a large machine learning model to a smaller model with minimal loss in performance. In this paper, we propose techniques for knowledge distillation in spiking neural networks for the task of image classification. We present ways to distill spikes from a larger SNN, also called the teacher network, to a smaller one, also called the student network, while minimally impacting the classification accuracy. We demonstrate the effectiveness of the proposed method with detailed experiments on three standard datasets while proposing novel distillation methodologies and loss functions. We also present a multi-stage knowledge distillation technique for SNNs using an intermediate network to obtain higher performance from the student network. Our approach is expected to open up new avenues for deploying high performing large SNN models on resource-constrained hardware platforms.