 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Plug and play methods for magnetic resonance imaging
Mar 20, 2019

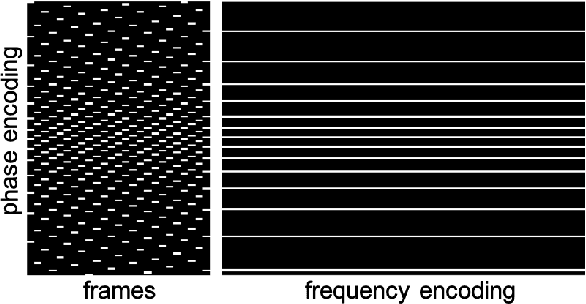
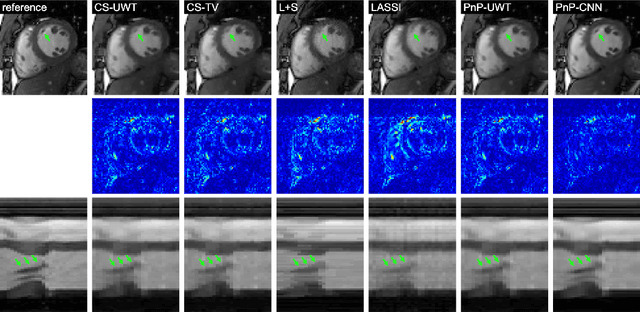
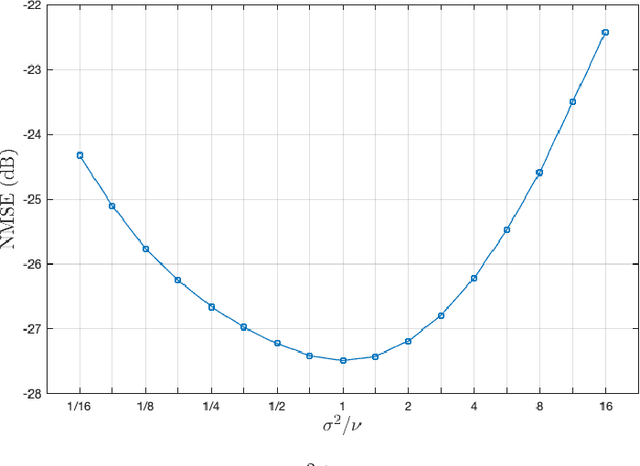
Magnetic Resonance Imaging (MRI) is a non-invasive diagnostic tool that provides excellent soft-tissue contrast without the use of ionizing radiation. But, compared to other clinical imaging modalities (e.g., CT or ultrasound), the data acquisition process for MRI is inherently slow. Furthermore, dynamic applications demand collecting a series of images in quick succession. As a result, reducing acquisition time and improving imaging quality for undersampled datasets have been active areas of research for the last two decades. The combination of parallel imaging and compressive sensing (CS) has been shown to benefit a wide range of MRI applications. More recently, deep learning techniques have been shown to outperform CS methods. Some of these techniques pose the MRI reconstruction as a direct inversion problem and tackle it by training a deep neural network (DNN) to map from the measured Fourier samples and the final image. Considering that the forward model in MRI changes from one dataset to the next, such methods have to be either trained over a large and diverse corpus of data or limited to a specific application, and even then they cannot ensure data consistency. An alternative is to use "plug-and-play" (PnP) algorithms, which iterate image denoising with forward-model based signal recovery. PnP algorithms are an excellent fit for compressive MRI because they decouple image modeling from the forward model, which can change significantly among different scans due to variations in the coil sensitivity maps, sampling patterns, and image resolution. Consequently, with PnP, state-of-the-art image-denoising techniques, such as those based on DNNs, can be directly exploited for compressive MRI image reconstruction. The objective of this article is two-fold: i) to review recent advances in plug-and-play methods, and ii) to discuss their application to compressive MRI image reconstruction.
Lightweight Mask R-CNN for Long-Range Wireless Power Transfer Systems
Apr 19, 2020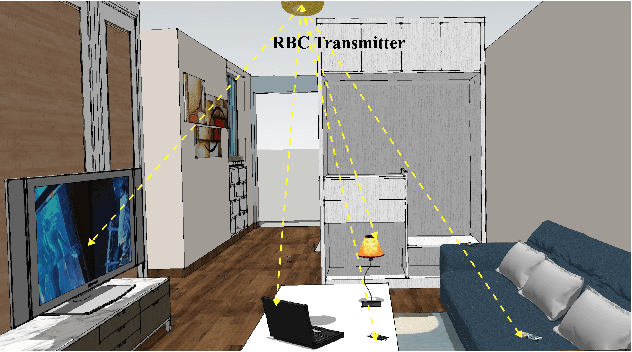
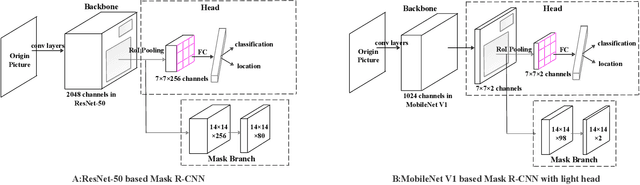


Resonant Beam Charging (RBC) is a wireless charging technology which supports multi-watt power transfer over meter-level distance. The features of safety, mobility and simultaneous charging capability enable RBC to charge multiple mobile devices safely at the same time. To detect the devices that need to be charged, a Mask R-CNN based dection model is proposed in previous work. However, considering the constraints of the RBC system, it's not easy to apply Mask R-CNN in lightweight hardware-embedded devices because of its heavy model and huge computation. Thus, we propose a machine learning detection approach which provides a lighter and faster model based on traditional Mask R-CNN. The proposed approach makes the object detection much easier to be transplanted on mobile devices and reduce the burden of hardware computation. By adjusting the structure of the backbone and the head part of Mask R-CNN, we reduce the average detection time from $1.02\mbox{s}$ per image to $0.6132\mbox{s}$, and reduce the model size from $245\mbox{MB}$ to $47.1\mbox{MB}$. The improved model is much more suitable for the application in the RBC system.
Stochastic Security: Adversarial Defense Using Long-Run Dynamics of Energy-Based Models
May 27, 2020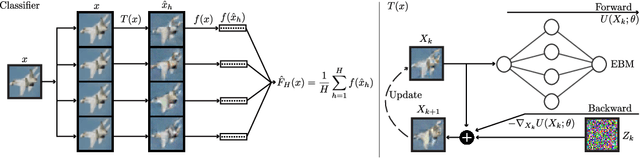
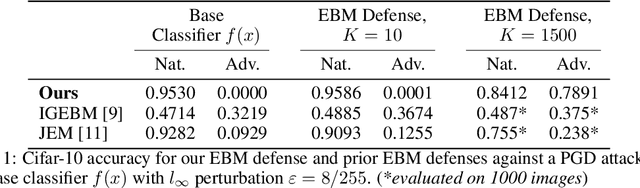


The vulnerability of deep networks to adversarial attacks is a central problem for deep learning from the perspective of both cognition and security. The current most successful defense method is to train a classifier using adversarial images created during learning. Another defense approach involves transformation or purification of the original input to remove adversarial signals before the image is classified. We focus on defending naturally-trained classifiers using Markov Chain Monte Carlo (MCMC) sampling with an Energy-Based Model (EBM) for adversarial purification. In contrast to adversarial training, our approach is intended to secure pre-existing and highly vulnerable classifiers. The memoryless behavior of long-run MCMC sampling will eventually remove adversarial signals, while metastable behavior preserves consistent appearance of MCMC samples after many steps to allow accurate long-run prediction. Balancing these factors can lead to effective purification and robust classification. We evaluate adversarial defense with an EBM using the strongest known attacks against purification. Our contributions are 1) an improved method for training EBM's with realistic long-run MCMC samples, 2) an Expectation-Over-Transformation (EOT) defense that resolves theoretical ambiguities for stochastic defenses and from which the EOT attack naturally follows, and 3) state-of-the-art adversarial defense for naturally-trained classifiers and competitive defense compared to adversarially-trained classifiers on Cifar-10, SVHN, and Cifar-100. Code and pre-trained models are available at https://github.com/point0bar1/ebm-defense.
An End-to-end Framework For Low-Resolution Remote Sensing Semantic Segmentation
Mar 17, 2020



High-resolution images for remote sensing applications are often not affordable or accessible, especially when in need of a wide temporal span of recordings. Given the easy access to low-resolution (LR) images from satellites, many remote sensing works rely on this type of data. The problem is that LR images are not appropriate for semantic segmentation, due to the need for high-quality data for accurate pixel prediction for this task. In this paper, we propose an end-to-end framework that unites a super-resolution and a semantic segmentation module in order to produce accurate thematic maps from LR inputs. It allows the semantic segmentation network to conduct the reconstruction process, modifying the input image with helpful textures. We evaluate the framework with three remote sensing datasets. The results show that the framework is capable of achieving a semantic segmentation performance close to native high-resolution data, while also surpassing the performance of a network trained with LR inputs.
Resolution Enhancement of Range Images via Color-Image Segmentation
Oct 28, 2012


We report a method for super-resolution of range images. Our approach leverages the interpretation of LR image as sparse samples on the HR grid. Based on this interpretation, we demonstrate that our recently reported approach, which reconstructs dense range images from sparse range data by exploiting a registered colour image, can be applied for the task of resolution enhancement of range images. Our method only uses a single colour image in addition to the range observation in the super-resolution process. Using the proposed approach, we demonstrate super-resolution results for large factors (e.g. 4) with good localization accuracy.
Deep Fusion Siamese Network for Automatic Kinship Verification
Jun 07, 2020

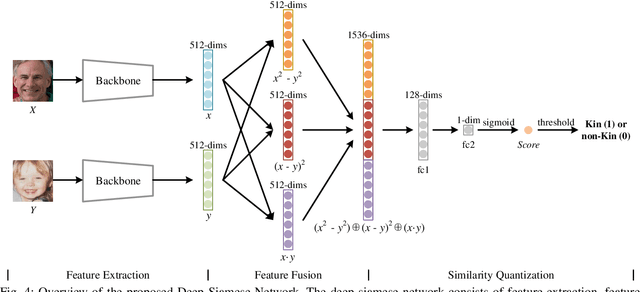
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at https://github.com/gniknoil/FG2020-kinship.
* 8 pages, 8 figures
Weakly Supervised Vessel Segmentation in X-ray Angiograms by Self-Paced Learning from Noisy Labels with Suggestive Annotation
May 27, 2020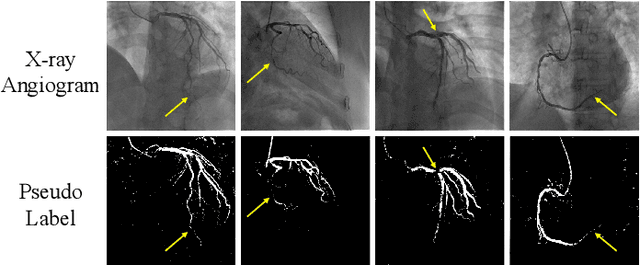
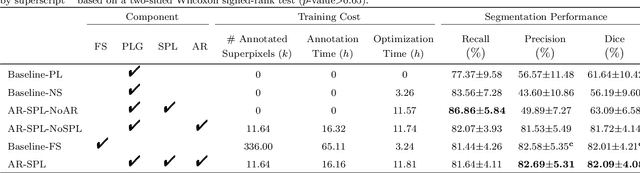
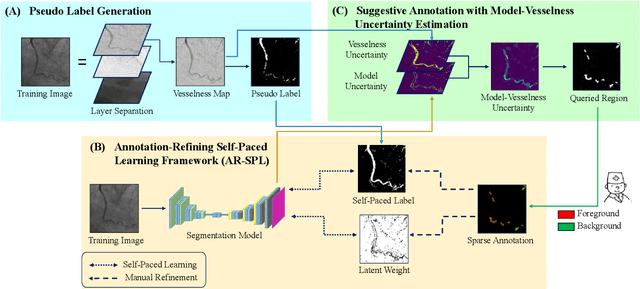
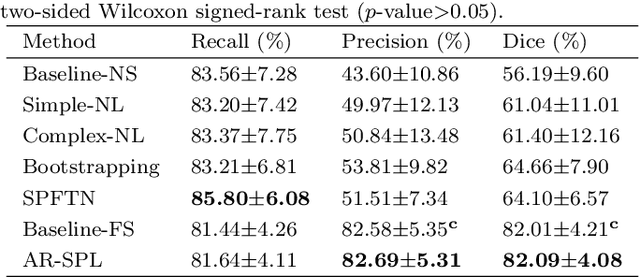
The segmentation of coronary arteries in X-ray angiograms by convolutional neural networks (CNNs) is promising yet limited by the requirement of precisely annotating all pixels in a large number of training images, which is extremely labor-intensive especially for complex coronary trees. To alleviate the burden on the annotator, we propose a novel weakly supervised training framework that learns from noisy pseudo labels generated from automatic vessel enhancement, rather than accurate labels obtained by fully manual annotation. A typical self-paced learning scheme is used to make the training process robust against label noise while challenged by the systematic biases in pseudo labels, thus leading to the decreased performance of CNNs at test time. To solve this problem, we propose an annotation-refining self-paced learning framework (AR-SPL) to correct the potential errors using suggestive annotation. An elaborate model-vesselness uncertainty estimation is also proposed to enable the minimal annotation cost for suggestive annotation, based on not only the CNNs in training but also the geometric features of coronary arteries derived directly from raw data. Experiments show that our proposed framework achieves 1) comparable accuracy to fully supervised learning, which also significantly outperforms other weakly supervised learning frameworks; 2) largely reduced annotation cost, i.e., 75.18% of annotation time is saved, and only 3.46% of image regions are required to be annotated; and 3) an efficient intervention process, leading to superior performance with even fewer manual interactions.
Visual search over billions of aerial and satellite images
Feb 07, 2020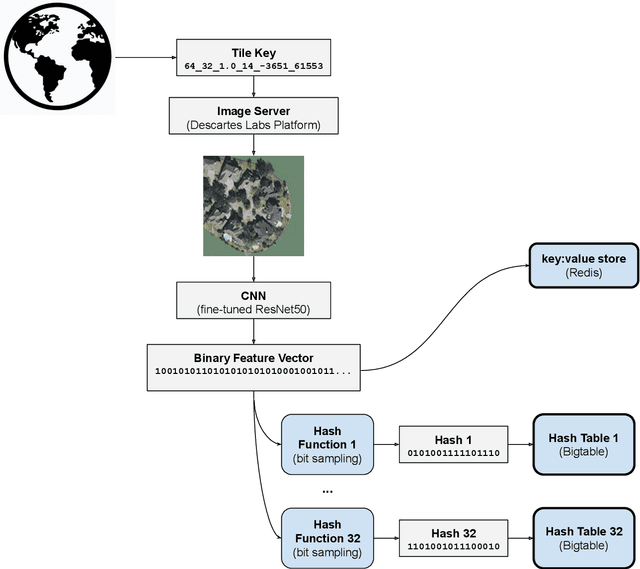
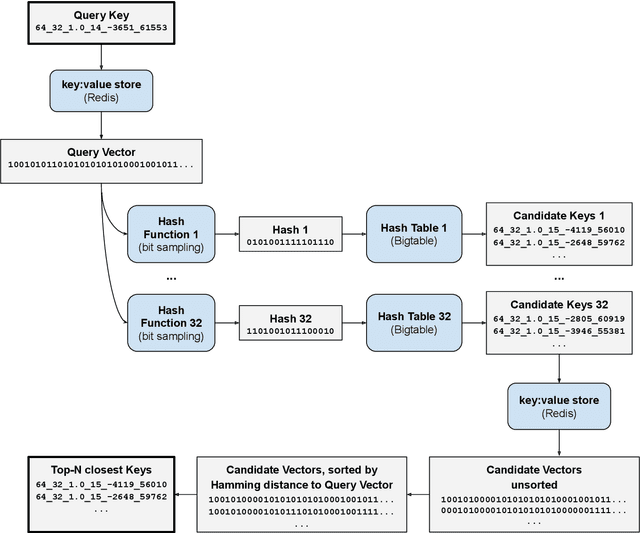


We present a system for performing visual search over billions of aerial and satellite images. The purpose of visual search is to find images that are visually similar to a query image. We define visual similarity using 512 abstract visual features generated by a convolutional neural network that has been trained on aerial and satellite imagery. The features are converted to binary values to reduce data and compute requirements. We employ a hash-based search using Bigtable, a scalable database service from Google Cloud. Searching the continental United States at 1-meter pixel resolution, corresponding to approximately 2 billion images, takes approximately 0.1 seconds. This system enables real-time visual search over the surface of the earth, and an interactive demo is available at https://search.descarteslabs.com.
A Novel Approach to Develop a New Hybrid Technique for Trademark Image Retrieval
Nov 08, 2014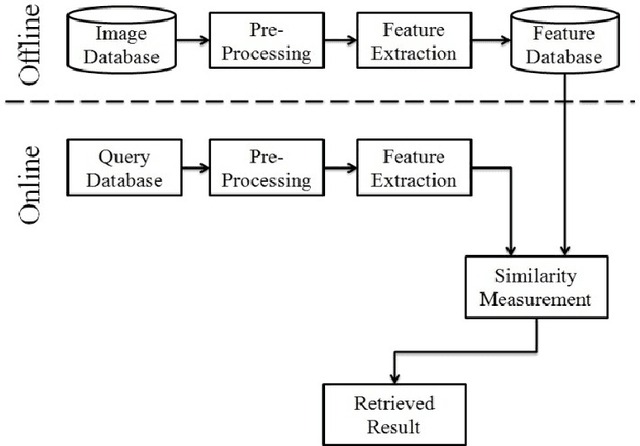
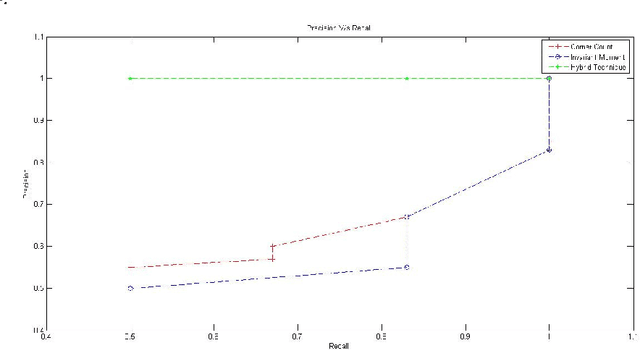
Trademark Image Retrieval is playing a vital role as a part of CBIR System. Trademark is of great significance because it carries the status value of any company. To retrieve such a fake or copied trademark we design a retrieval system which is based on hybrid techniques. It contains a mixture of two different feature vector which combined together to give a suitable retrieval system. In the proposed system we extract the corner feature which is applied on an edge pixel image. This feature is used to extract the relevant image and to more purify the result we apply other feature which is the invariant moment feature. From the experimental result we conclude that the system is 85 percent efficient.
Shape-Aware Complementary-Task Learning for Multi-Organ Segmentation
Aug 14, 2019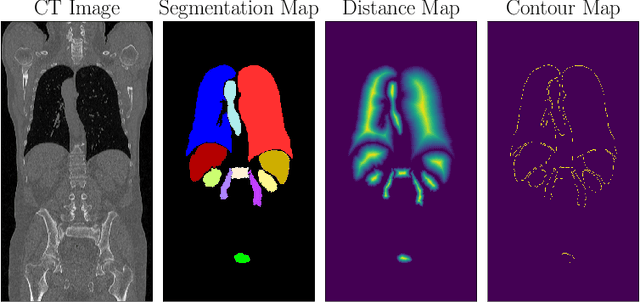
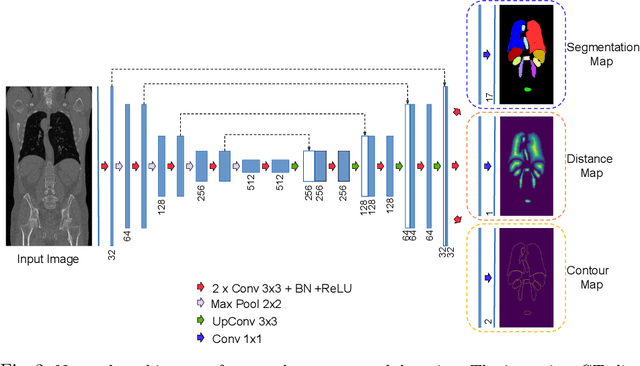

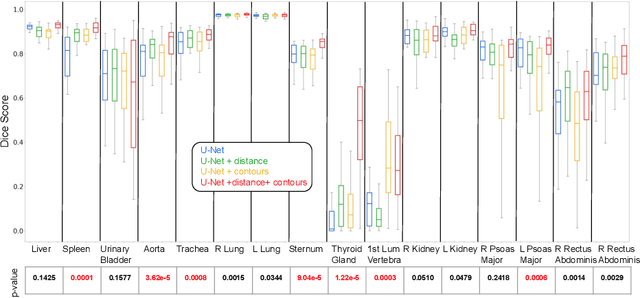
Multi-organ segmentation in whole-body computed tomography (CT) is a constant pre-processing step which finds its application in organ-specific image retrieval, radiotherapy planning, and interventional image analysis. We address this problem from an organ-specific shape-prior learning perspective. We introduce the idea of complementary-task learning to enforce shape-prior leveraging the existing target labels. We propose two complementary-tasks namely i) distance map regression and ii) contour map detection to explicitly encode the geometric properties of each organ. We evaluate the proposed solution on the public VISCERAL dataset containing CT scans of multiple organs. We report a significant improvement of overall dice score from 0.8849 to 0.9018 due to the incorporation of complementary-task learning.