 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Score: How to Select Useful Samples
Dec 02, 2018

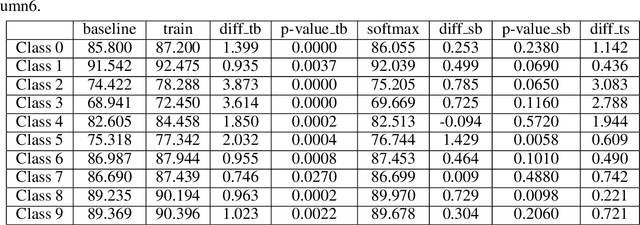
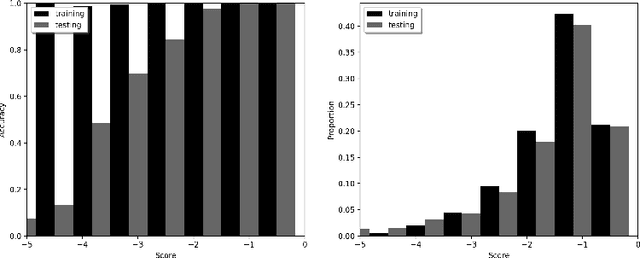
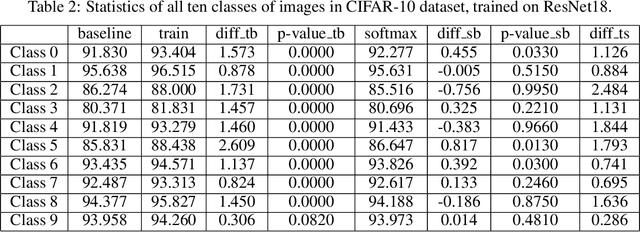
There has long been debates on how we could interpret neural networks and understand the decisions our models make. Specifically, why deep neural networks tend to be error-prone when dealing with samples that output low softmax scores. We present an efficient approach to measure the confidence of decision-making steps by statistically investigating each unit's contribution to that decision. Instead of focusing on how the models react on datasets, we study the datasets themselves given a pre-trained model. Our approach is capable of assigning a score to each sample within a dataset that measures the frequency of occurrence of that sample's chain of activation. We demonstrate with experiments that our method could select useful samples to improve deep neural networks in a semi-supervised leaning setting.
Ada-LISTA: Learned Solvers Adaptive to Varying Models
Feb 19, 2020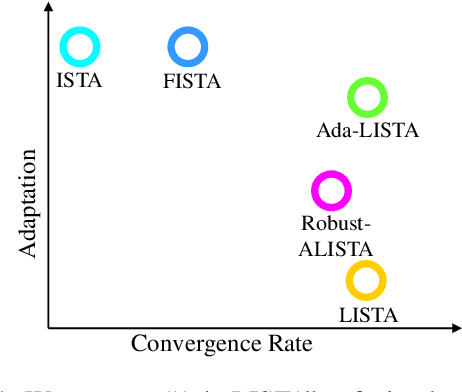


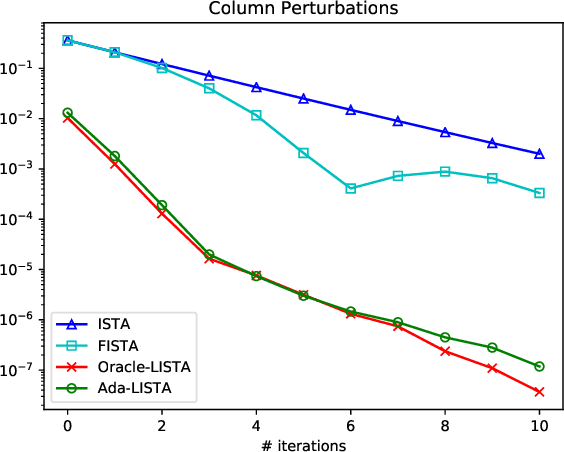
Neural networks that are based on unfolding of an iterative solver, such as LISTA (learned iterative soft threshold algorithm), are widely used due to their accelerated performance. Nevertheless, as opposed to non-learned solvers, these networks are trained on a certain dictionary, and therefore they are inapplicable for varying model scenarios. This work introduces an adaptive learned solver, termed Ada-LISTA, which receives pairs of signals and their corresponding dictionaries as inputs, and learns a universal architecture to serve them all. We prove that this scheme is guaranteed to solve sparse coding in linear rate for varying models, including dictionary perturbations and permutations. We also provide an extensive numerical study demonstrating its practical adaptation capabilities. Finally, we deploy Ada-LISTA to natural image inpainting, where the patch-masks vary spatially, thus requiring such an adaptation.
Discriminator Contrastive Divergence: Semi-Amortized Generative Modeling by Exploring Energy of the Discriminator
Apr 05, 2020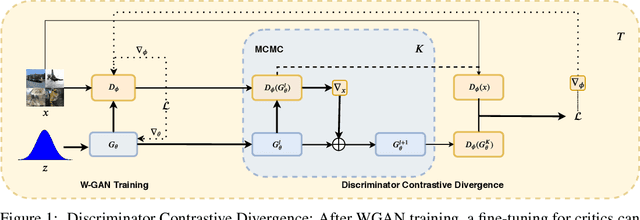
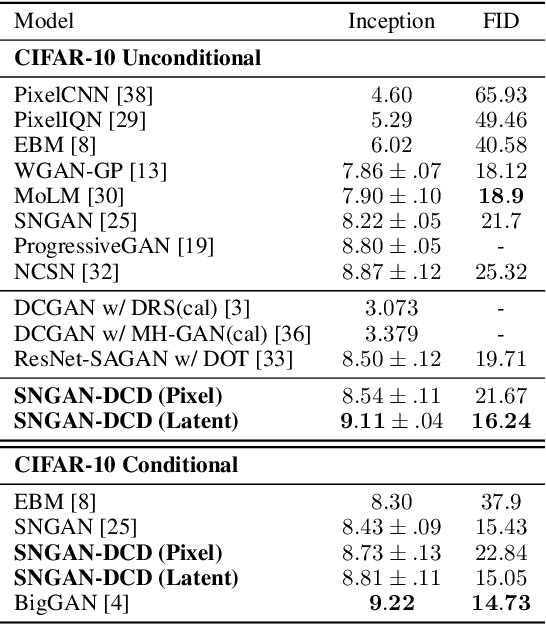
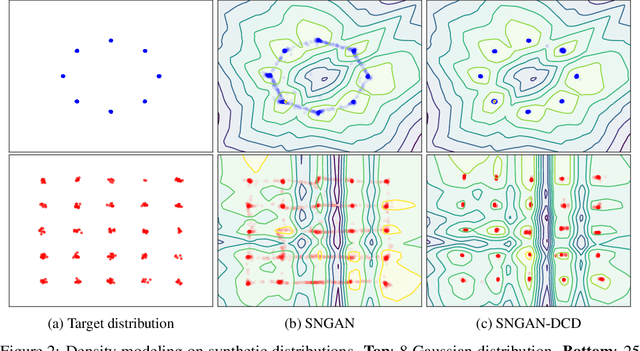
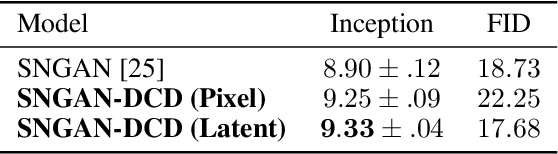
Generative Adversarial Networks (GANs) have shown great promise in modeling high dimensional data. The learning objective of GANs usually minimizes some measure discrepancy, \textit{e.g.}, $f$-divergence~($f$-GANs) or Integral Probability Metric~(Wasserstein GANs). With $f$-divergence as the objective function, the discriminator essentially estimates the density ratio, and the estimated ratio proves useful in further improving the sample quality of the generator. However, how to leverage the information contained in the discriminator of Wasserstein GANs (WGAN) is less explored. In this paper, we introduce the Discriminator Contrastive Divergence, which is well motivated by the property of WGAN's discriminator and the relationship between WGAN and energy-based model. Compared to standard GANs, where the generator is directly utilized to obtain new samples, our method proposes a semi-amortized generation procedure where the samples are produced with the generator's output as an initial state. Then several steps of Langevin dynamics are conducted using the gradient of the discriminator. We demonstrate the benefits of significant improved generation on both synthetic data and several real-world image generation benchmarks.
Blind Deblurring using Deep Learning: A Survey
Jul 23, 2019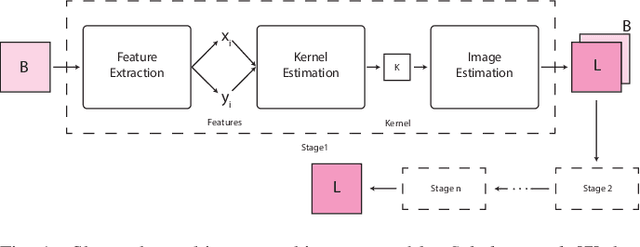
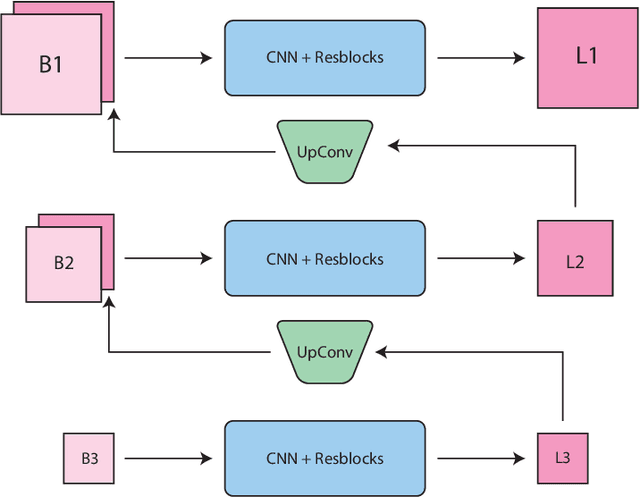
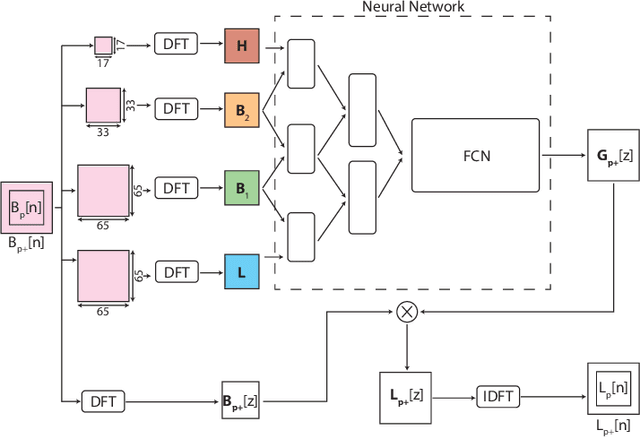
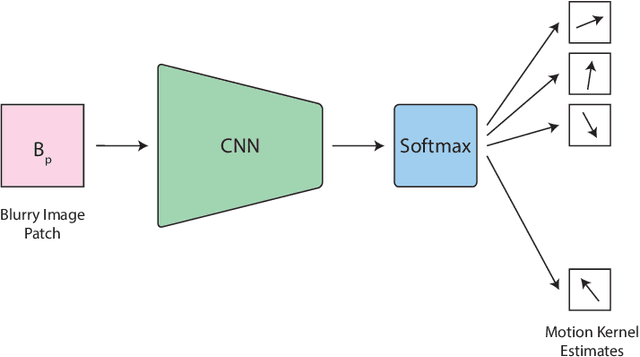
We inspect all the deep learning based solutions and provide holistic understanding of various architectures that have evolved over the past few years to solve blind deblurring. The introductory work used deep learning to estimate some features of the blur kernel and then moved onto predicting the blur kernel entirely, which converts the problem into non-blind deblurring. The recent state of the art techniques are end to end, i.e., they don't estimate the blur kernel rather try to estimate the latent sharp image directly from the blurred image. The benchmarking PSNR and SSIM values on standard datasets of GOPRO and Kohler using various architectures are also provided.
Learning a No-Reference Quality Metric for Single-Image Super-Resolution
Dec 18, 2016
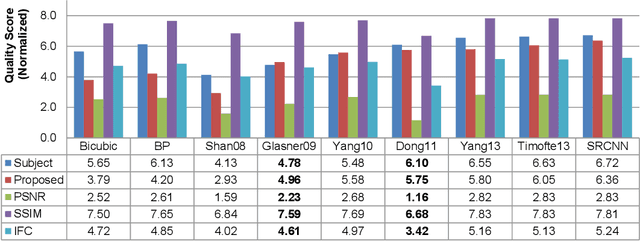

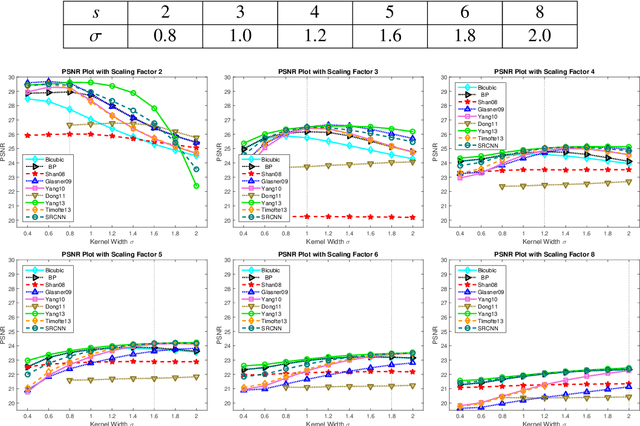
Numerous single-image super-resolution algorithms have been proposed in the literature, but few studies address the problem of performance evaluation based on visual perception. While most super-resolution images are evaluated by fullreference metrics, the effectiveness is not clear and the required ground-truth images are not always available in practice. To address these problems, we conduct human subject studies using a large set of super-resolution images and propose a no-reference metric learned from visual perceptual scores. Specifically, we design three types of low-level statistical features in both spatial and frequency domains to quantify super-resolved artifacts, and learn a two-stage regression model to predict the quality scores of super-resolution images without referring to ground-truth images. Extensive experimental results show that the proposed metric is effective and efficient to assess the quality of super-resolution images based on human perception.
Quality Control of Neuron Reconstruction Based on Deep Learning
Mar 19, 2020
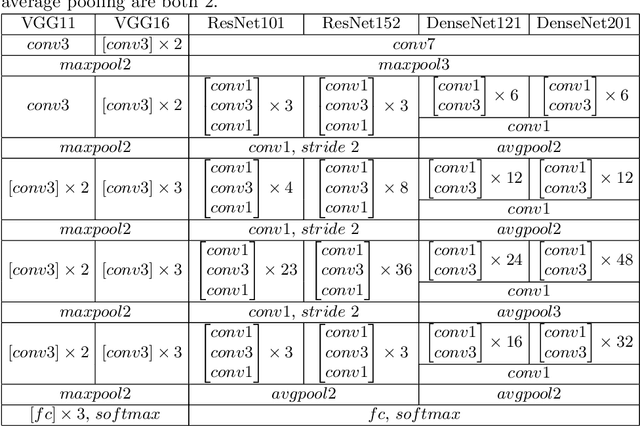
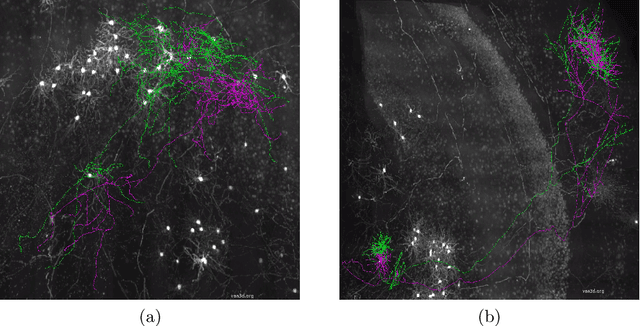
Neuron reconstruction is essential to generate exquisite neuron connectivity map for understanding brain function. Despite the significant amount of effect that has been made on automatic reconstruction methods, manual tracing by well-trained human annotators is still necessary. To ensure the quality of reconstructed neurons and provide guidance for annotators to improve their efficiency, we propose a deep learning based quality control method for neuron reconstruction in this paper. By formulating the quality control problem into a binary classification task regarding each single point, the proposed approach overcomes the technical difficulties resulting from the large image size and complex neuron morphology. Not only it provides the evaluation of reconstruction quality, but also can locate exactly where the wrong tracing begins. This work presents one of the first comprehensive studies for whole-brain scale quality control of neuron reconstructions. Experiments on five-fold cross validation with a large dataset demonstrate that the proposed approach can detect 74.7% errors with only 1.4% false alerts.
Adversarial Sparsity Attacks on Deep Neural Networks
Jun 18, 2020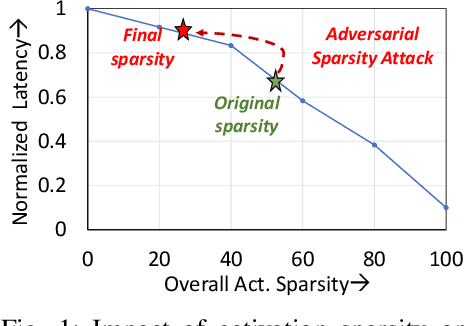
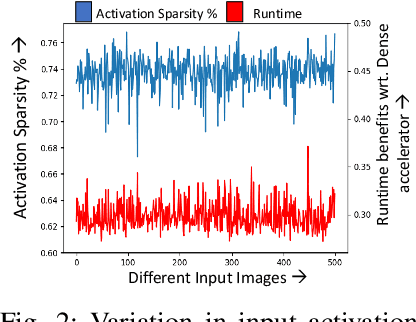
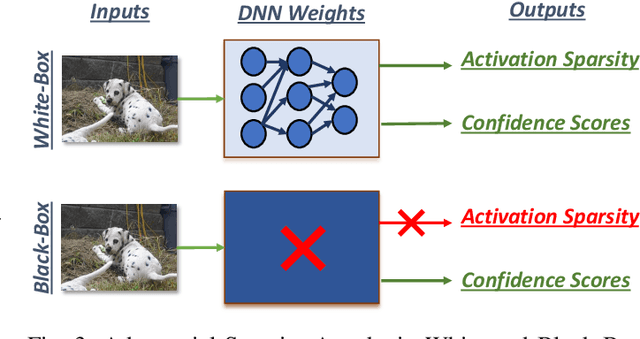
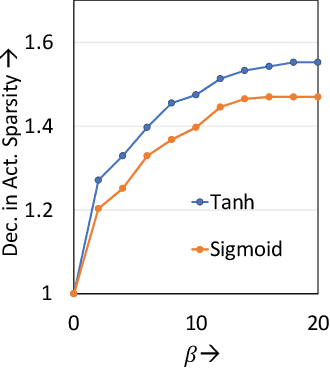
Adversarial attacks have exposed serious vulnerabilities in Deep Neural Networks (DNNs) through their ability to force misclassifications through human-imperceptible perturbations to DNN inputs. We explore a new direction in the field of adversarial attacks by suggesting attacks that aim to degrade the computational efficiency of DNNs rather than their classification accuracy. Specifically, we propose and demonstrate sparsity attacks, which adversarial modify a DNN's inputs so as to reduce sparsity (or the presence of zero values) in its internal activation values. In resource-constrained systems, a wide range of hardware and software techniques have been proposed that exploit sparsity to improve DNN efficiency. The proposed attack increases the execution time and energy consumption of sparsity-optimized DNN implementations, raising concern over their deployment in latency and energy-critical applications. We propose a systematic methodology to generate adversarial inputs for sparsity attacks by formulating an objective function that quantifies the network's activation sparsity, and minimizing this function using iterative gradient-descent techniques. We launch both white-box and black-box versions of adversarial sparsity attacks on image recognition DNNs and demonstrate that they decrease activation sparsity by up to 1.82x. We also evaluate the impact of the attack on a sparsity-optimized DNN accelerator and demonstrate degradations up to 1.59x in latency, and also study the performance of the attack on a sparsity-optimized general-purpose processor. Finally, we evaluate defense techniques such as activation thresholding and input quantization and demonstrate that the proposed attack is able to withstand them, highlighting the need for further efforts in this new direction within the field of adversarial machine learning.
ChromaGAN: An Adversarial Approach for Picture Colorization
Jul 23, 2019
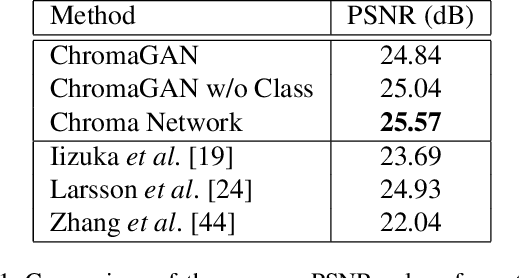
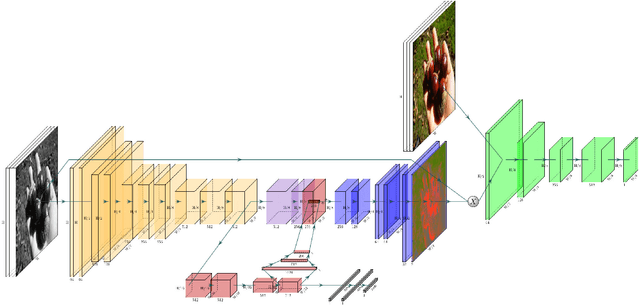

The colorization of grayscale images is an ill-posed problem, with multiple correct solutions. In this paper, an adversarial learning approach is proposed. A generator network is used to infer the chromaticity of a given grayscale image. The same network also performs a semantic classification of the image. This network is framed in an adversarial model that learns to colorize by incorporating perceptual and semantic understanding of color and class distributions. The model is trained via a fully self-supervised strategy. Qualitative and quantitative results show the capacity of the proposed method to colorize images in a realistic way, achieving top-tier performances relative to the state-of-the-art.
Dense Relational Captioning: Triple-Stream Networks for Relationship-Based Captioning
Apr 01, 2019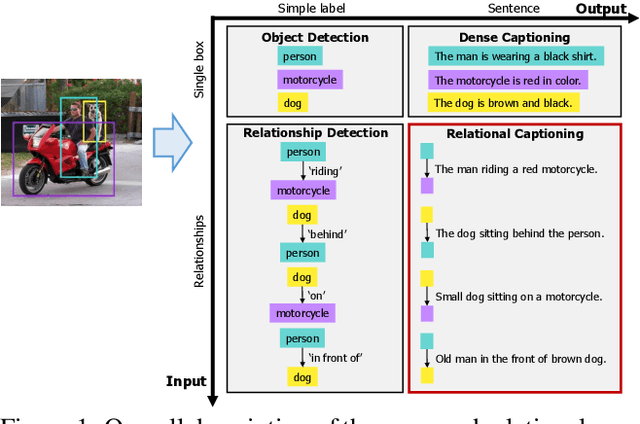
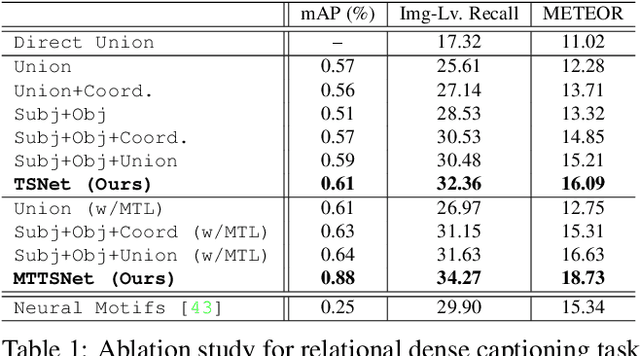
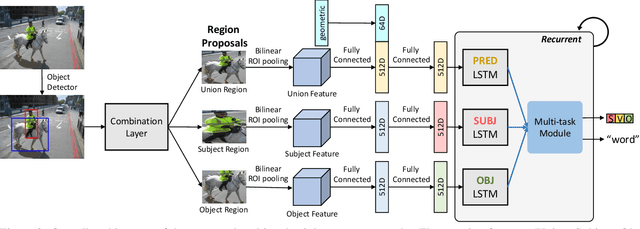
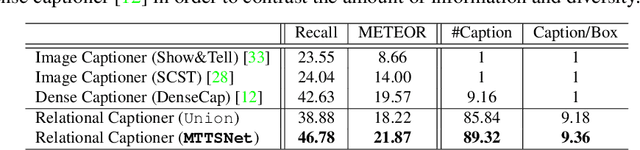
Our goal in this work is to train an image captioning model that generates more dense and informative captions. We introduce "relational captioning," a novel image captioning task which aims to generate multiple captions with respect to relational information between objects in an image. Relational captioning is a framework that is advantageous in both diversity and amount of information, leading to image understanding based on relationships. Part-of speech (POS, i.e. subject-object-predicate categories) tags can be assigned to every English word. We leverage the POS as a prior to guide the correct sequence of words in a caption. To this end, we propose a multi-task triple-stream network (MTTSNet) which consists of three recurrent units for the respective POS and jointly performs POS prediction and captioning. We demonstrate more diverse and richer representations generated by the proposed model against several baselines and competing methods.
Privacy Adversarial Network: Representation Learning for Mobile Data Privacy
Jun 08, 2020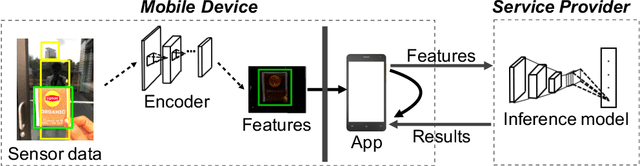

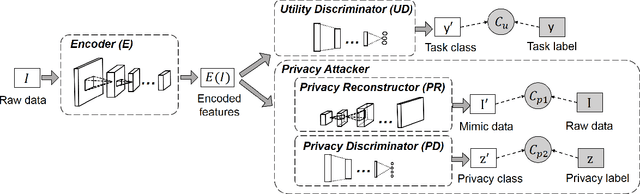
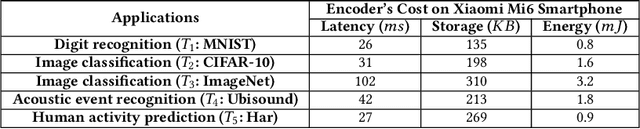
The remarkable success of machine learning has fostered a growing number of cloud-based intelligent services for mobile users. Such a service requires a user to send data, e.g. image, voice and video, to the provider, which presents a serious challenge to user privacy. To address this, prior works either obfuscate the data, e.g. add noise and remove identity information, or send representations extracted from the data, e.g. anonymized features. They struggle to balance between the service utility and data privacy because obfuscated data reduces utility and extracted representation may still reveal sensitive information. This work departs from prior works in methodology: we leverage adversarial learning to a better balance between privacy and utility. We design a \textit{representation encoder} that generates the feature representations to optimize against the privacy disclosure risk of sensitive information (a measure of privacy) by the \textit{privacy adversaries}, and concurrently optimize with the task inference accuracy (a measure of utility) by the \textit{utility discriminator}. The result is the privacy adversarial network (\systemname), a novel deep model with the new training algorithm, that can automatically learn representations from the raw data. Intuitively, PAN adversarially forces the extracted representations to only convey the information required by the target task. Surprisingly, this constitutes an implicit regularization that actually improves task accuracy. As a result, PAN achieves better utility and better privacy at the same time! We report extensive experiments on six popular datasets and demonstrate the superiority of \systemname compared with alternative methods reported in prior work.