 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Long-Tailed Recognition Using Class-Balanced Experts
Apr 07, 2020
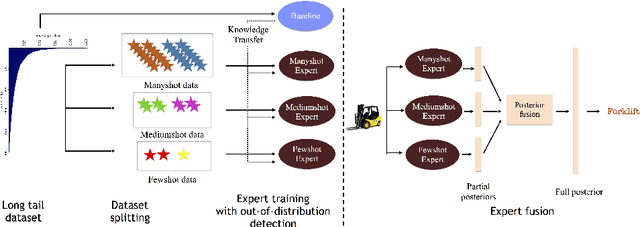
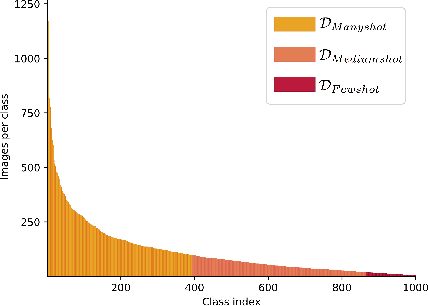

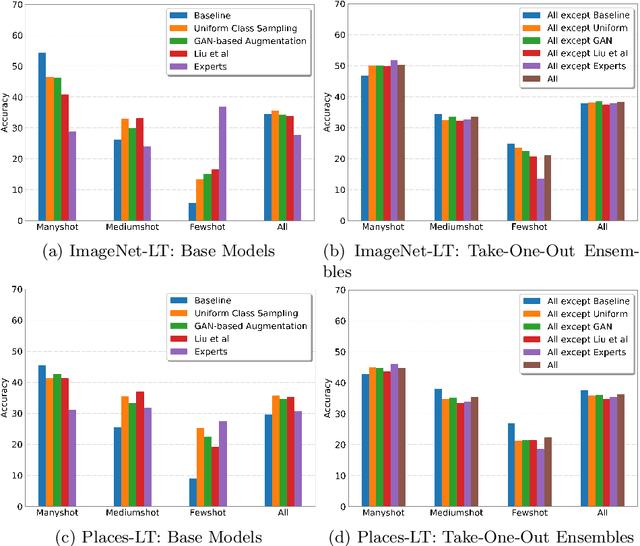
Classic deep learning methods achieve impressive results in image recognition over large-scale artificially-balanced datasets. However, real-world datasets exhibit highly class-imbalanced distributions. In this work we address the problem of long tail recognition wherein the training set is highly imbalanced and the test set is kept balanced. The key challenges faced by any long tail recognition technique are relative imbalance amongst the classes and data scarcity or unseen concepts for mediumshot or fewshot classes. Existing techniques rely on data-resampling, cost sensitive learning, online hard example mining, reshaping the loss objective and complex memory based models to address this problem. We instead propose an ensemble of experts technique that decomposes the imbalanced problem into multiple balanced classification problems which are more tractable. Our ensemble of experts reaches close to state-of-the-art results and an extended ensemble establishes new state-of-the-art on two benchmarks for long tail recognition. We conduct numerous experiments to analyse the performance of the ensemble, and show that in modern datasets relative imbalance is a harder problem than data scarcity.
Report on UG^2+ Challenge Track 1: Assessing Algorithms to Improve Video Object Detection and Classification from Unconstrained Mobility Platforms
Jul 26, 2019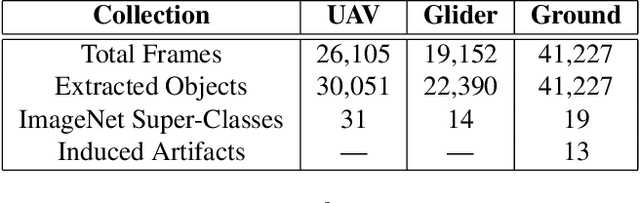
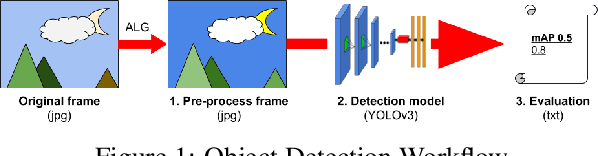
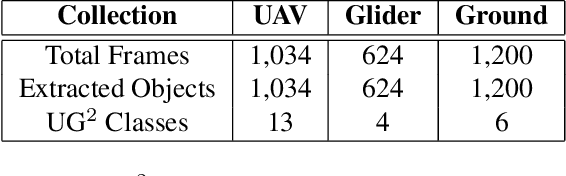
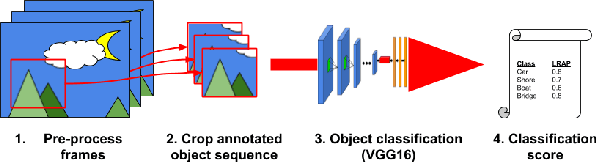
How can we effectively engineer a computer vision system that is able to interpret videos from unconstrained mobility platforms like UAVs? One promising option is to make use of image restoration and enhancement algorithms from the area of computational photography to improve the quality of the underlying frames in a way that also improves automatic visual recognition. Along these lines, exploratory work is needed to find out which image pre-processing algorithms, in combination with the strongest features and supervised machine learning approaches, are good candidates for difficult scenarios like motion blur, weather, and mis-focus --- all common artifacts in UAV acquired images. This paper summarizes the protocols and results of Track 1 of the UG^2+ Challenge held in conjunction with IEEE/CVF CVPR 2019. The challenge looked at two separate problems: (1) object detection improvement in video, and (2) object classification improvement in video. The challenge made use of the UG^2 (UAV, Glider, Ground) dataset, which is an established benchmark for assessing the interplay between image restoration and enhancement and visual recognition. 16 algorithms were submitted by academic and corporate teams, and a detailed analysis of how they performed on each challenge problem is reported here.
Dense Residual Network for Retinal Vessel Segmentation
Apr 07, 2020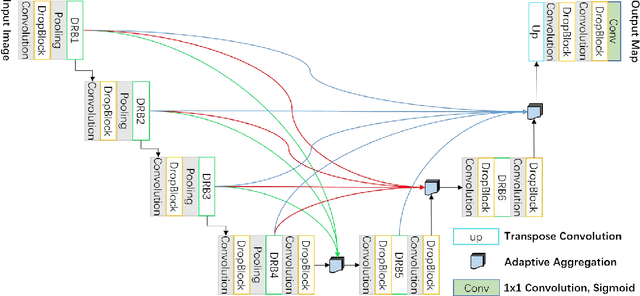
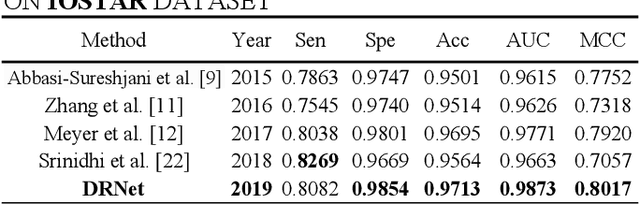
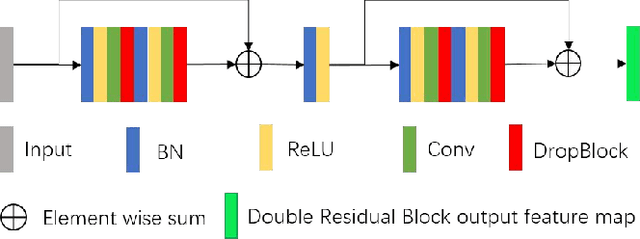
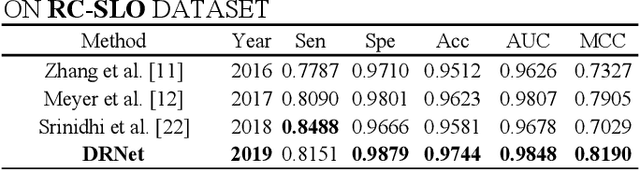
Retinal vessel segmentation plays an imaportant role in the field of retinal image analysis because changes in retinal vascular structure can aid in the diagnosis of diseases such as hypertension and diabetes. In recent research, numerous successful segmentation methods for fundus images have been proposed. But for other retinal imaging modalities, more research is needed to explore vascular extraction. In this work, we propose an efficient method to segment blood vessels in Scanning Laser Ophthalmoscopy (SLO) retinal images. Inspired by U-Net, "feature map reuse" and residual learning, we propose a deep dense residual network structure called DRNet. In DRNet, feature maps of previous blocks are adaptively aggregated into subsequent layers as input, which not only facilitates spatial reconstruction, but also learns more efficiently due to more stable gradients. Furthermore, we introduce DropBlock to alleviate the overfitting problem of the network. We train and test this model on the recent SLO public dataset. The results show that our method achieves the state-of-the-art performance even without data augmentation.
Multiple Human Association between Top and Horizontal Views by Matching Subjects' Spatial Distributions
Jul 26, 2019

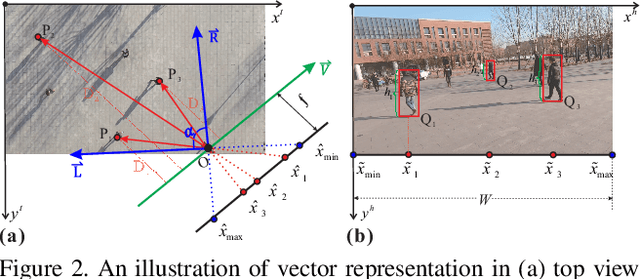
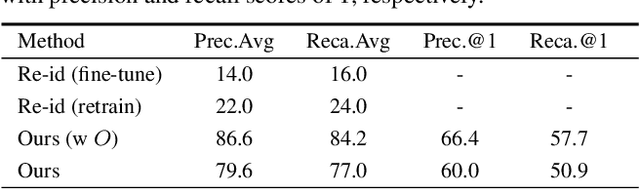
Video surveillance can be significantly enhanced by using both top-view data, e.g., those from drone-mounted cameras in the air, and horizontal-view data, e.g., those from wearable cameras on the ground. Collaborative analysis of different-view data can facilitate various kinds of applications, such as human tracking, person identification, and human activity recognition. However, for such collaborative analysis, the first step is to associate people, referred to as subjects in this paper, across these two views. This is a very challenging problem due to large human-appearance difference between top and horizontal views. In this paper, we present a new approach to address this problem by exploring and matching the subjects' spatial distributions between the two views. More specifically, on the top-view image, we model and match subjects' relative positions to the horizontal-view camera in both views and define a matching cost to decide the actual location of horizontal-view camera and its view angle in the top-view image. We collect a new dataset consisting of top-view and horizontal-view image pairs for performance evaluation and the experimental results show the effectiveness of the proposed method.
The perceptual boost of visual attention is task-dependent in naturalistic settings
Feb 22, 2020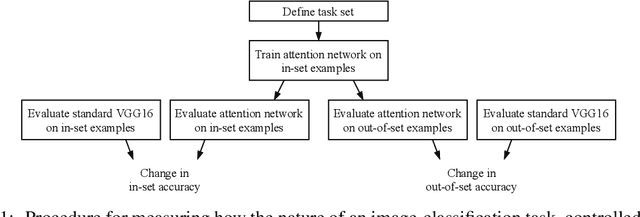
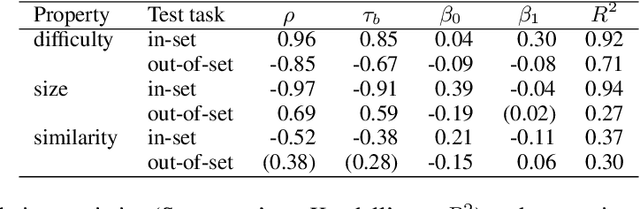
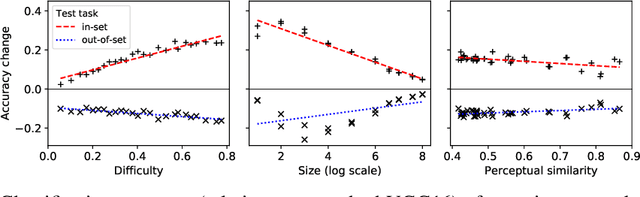
Attentional modulation of neural representations is known to enhance processing of task-relevant visual information. Is the resulting perceptual boost task-dependent in naturalistic settings? We aim to answer this with a large-scale computational experiment. First we design a series of visual tasks, each consisting of classifying images from a particular task set (group of image categories). The nature of a given task is determined by which categories are included in the task set. Then on each task we compare the accuracy of an attention-augmented neural network to that of an attention-free counterpart. We show that, all else being equal, the performance impact of attention is stronger with increasing task-set difficulty, weaker with increasing task-set size, and weaker with increasing perceptual similarity within a task set.
Disp R-CNN: Stereo 3D Object Detection via Shape Prior Guided Instance Disparity Estimation
Apr 07, 2020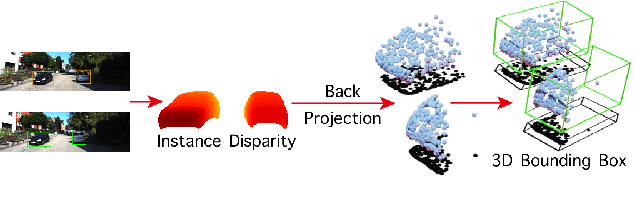
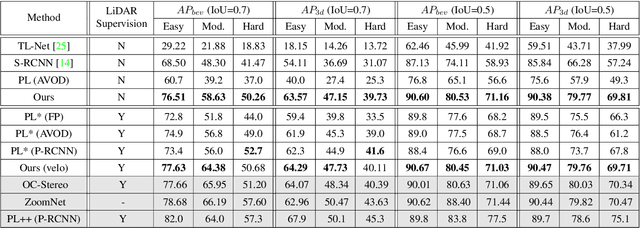
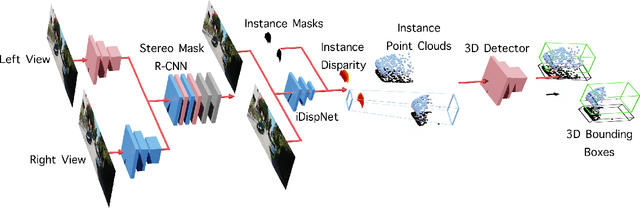
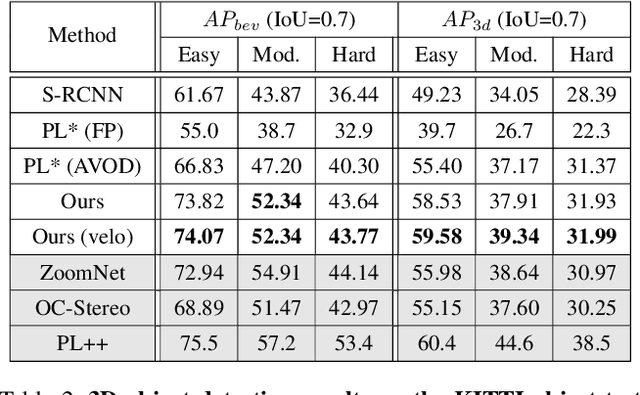
In this paper, we propose a novel system named Disp R-CNN for 3D object detection from stereo images. Many recent works solve this problem by first recovering a point cloud with disparity estimation and then apply a 3D detector. The disparity map is computed for the entire image, which is costly and fails to leverage category-specific prior. In contrast, we design an instance disparity estimation network (iDispNet) that predicts disparity only for pixels on objects of interest and learns a category-specific shape prior for more accurate disparity estimation. To address the challenge from scarcity of disparity annotation in training, we propose to use a statistical shape model to generate dense disparity pseudo-ground-truth without the need of LiDAR point clouds, which makes our system more widely applicable. Experiments on the KITTI dataset show that, even when LiDAR ground-truth is not available at training time, Disp R-CNN achieves competitive performance and outperforms previous state-of-the-art methods by 20% in terms of average precision.
Generative Adversarial Networks for LHCb Fast Simulation
Mar 21, 2020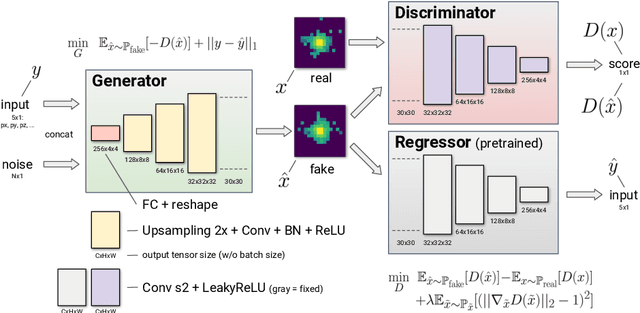
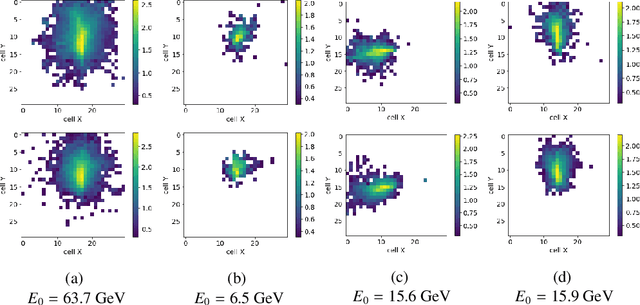
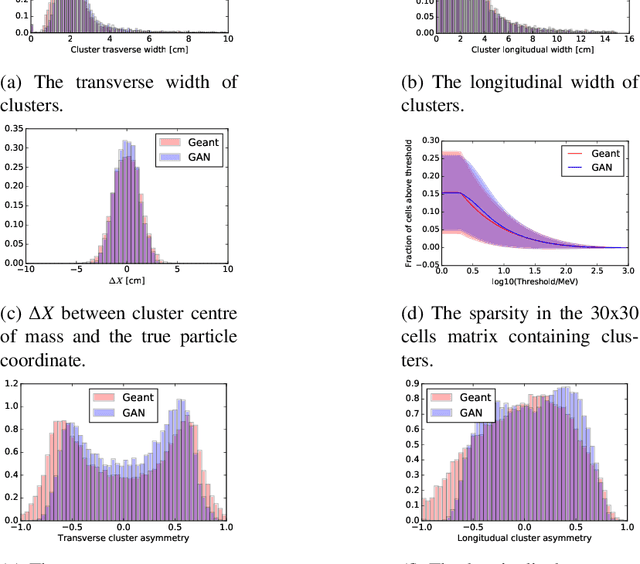
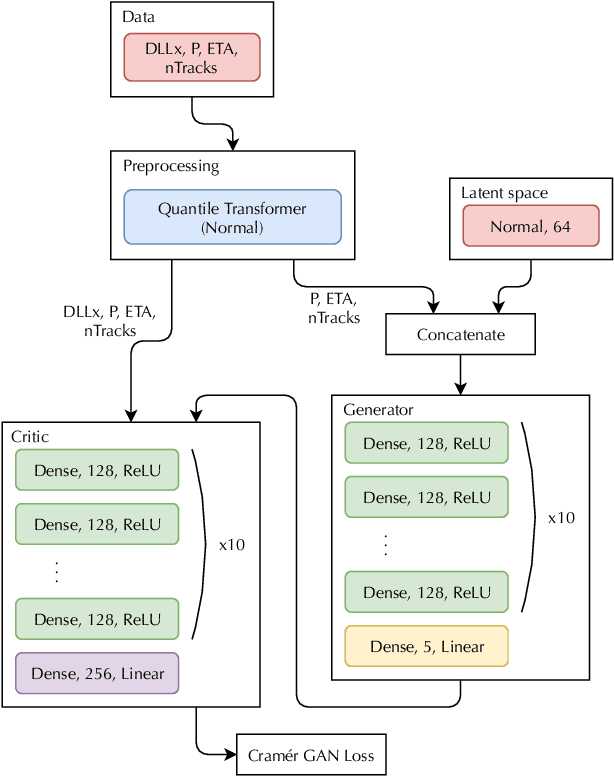
LHCb is one of the major experiments operating at the Large Hadron Collider at CERN. The richness of the physics program and the increasing precision of the measurements in LHCb lead to the need of ever larger simulated samples. This need will increase further when the upgraded LHCb detector will start collecting data in the LHC Run 3. Given the computing resources pledged for the production of Monte Carlo simulated events in the next years, the use of fast simulation techniques will be mandatory to cope with the expected dataset size. In LHCb generative models, which are nowadays widely used for computer vision and image processing are being investigated in order to accelerate the generation of showers in the calorimeter and high-level responses of Cherenkov detector. We demonstrate that this approach provides high-fidelity results along with a significant speed increase and discuss possible implication of these results. We also present an implementation of this algorithm into LHCb simulation software and validation tests.
Index Network
Aug 11, 2019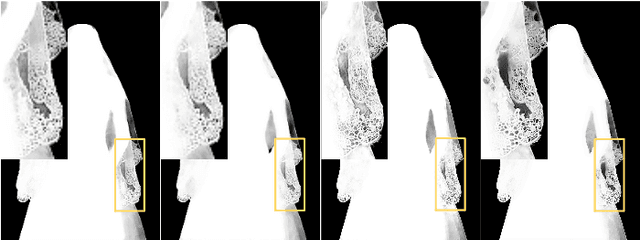
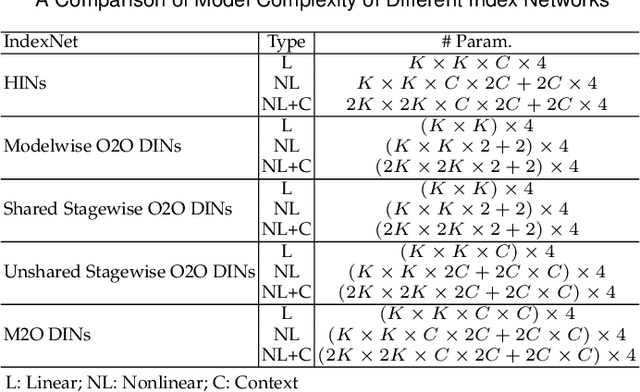
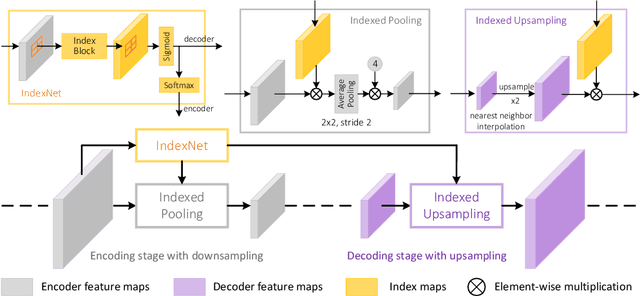
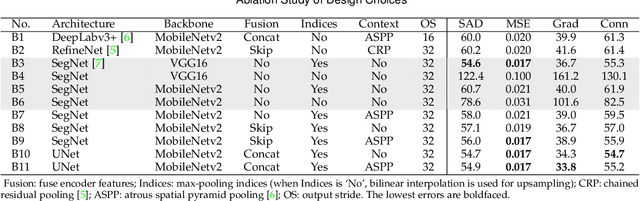
We show that existing upsampling operators can be unified using the notion of the index function. This notion is inspired by an observation in the decoding process of deep image matting where indices-guided unpooling can often recover boundary details considerably better than other upsampling operators such as bilinear interpolation. By viewing the indices as a function of the feature map, we introduce the concept of "learning to index", and present a novel index-guided encoder-decoder framework where indices are self-learned adaptively from data and are used to guide the downsampling and upsampling stages, without extra training supervision. At the core of this framework is a new learnable module, termed Index Network (IndexNet), which dynamically generates indices conditioned on the feature map itself. IndexNet can be used as a plug-in applying to almost all off-the-shelf convolutional networks that have coupled downsampling and upsampling stages, giving the networks the ability to dynamically capture variations of local patterns. In particular, we instantiate and investigate five families of IndexNet and demonstrate their effectiveness on four dense prediction tasks, including image denoising, image matting, semantic segmentation, and monocular depth estimation. Code and models have been made available at: https://tinyurl.com/IndexNetV1
Background Matting
Feb 11, 2020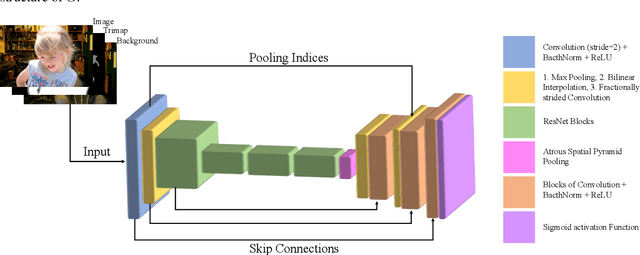
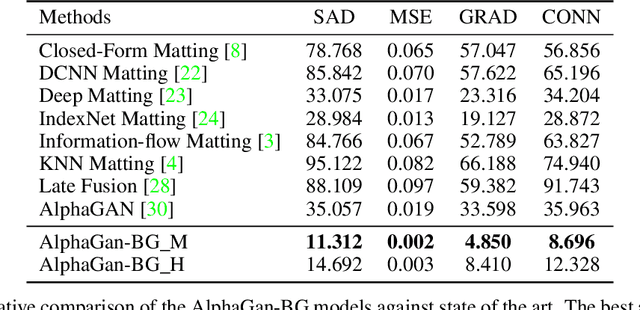


The current state of the art alpha matting methods mainly rely on the trimap as the secondary and only guidance to estimate alpha. This paper investigates the effects of utilising the background information as well as trimap in the process of alpha calculation. To achieve this goal, a state of the art method, AlphaGan is adopted and modified to process the background information as an extra input channel. Extensive experiments are performed to analyse the effect of the background information in image and video matting such as training with mildly and heavily distorted backgrounds. Based on the quantitative evaluations performed on Adobe Composition-1k dataset, the proposed pipeline significantly outperforms the state of the art methods using AlphaMatting benchmark metrics.
A Survey on Deep Learning Architectures for Image-based Depth Reconstruction
Jun 14, 2019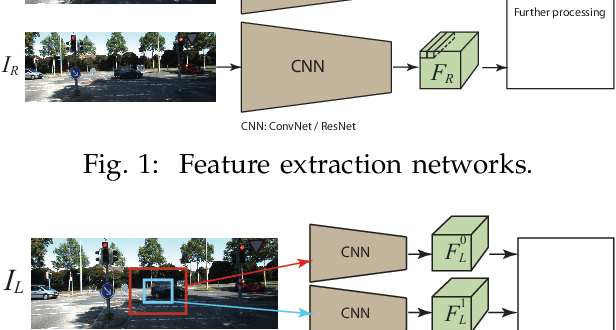
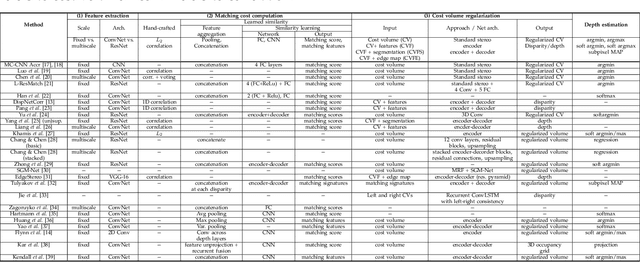
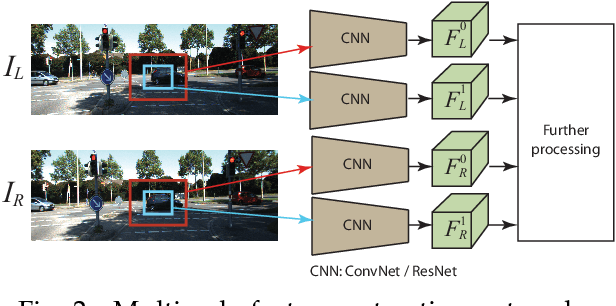
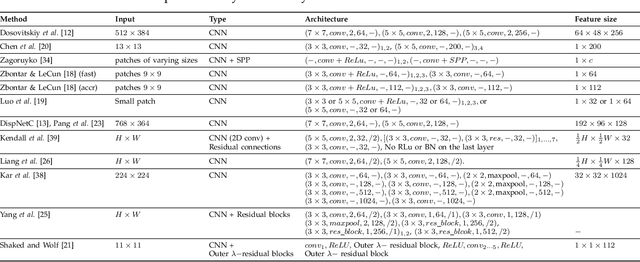
Estimating depth from RGB images is a long-standing ill-posed problem, which has been explored for decades by the computer vision, graphics, and machine learning communities. In this article, we provide a comprehensive survey of the recent developments in this field. We will focus on the works which use deep learning techniques to estimate depth from one or multiple images. Deep learning, coupled with the availability of large training datasets, have revolutionized the way the depth reconstruction problem is being approached by the research community. In this article, we survey more than 100 key contributions that appeared in the past five years, summarize the most commonly used pipelines, and discuss their benefits and limitations. In retrospect of what has been achieved so far, we also conjecture what the future may hold for learning-based depth reconstruction research.