 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
StyleRemix: An Interpretable Representation for Neural Image Style Transfer
Mar 25, 2019
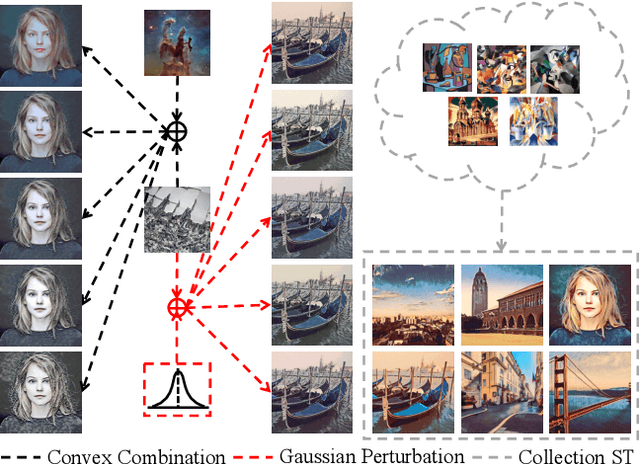

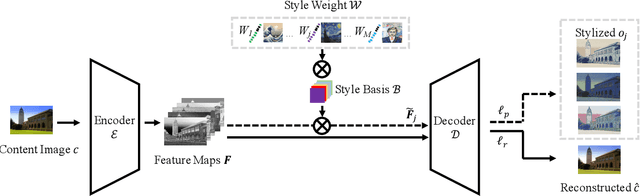
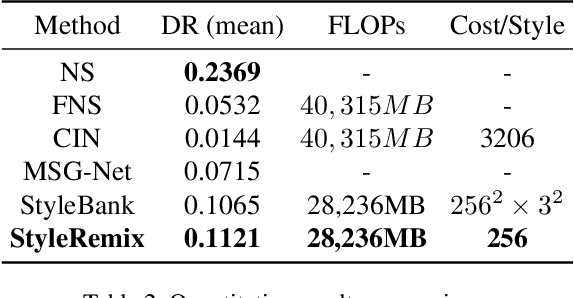
Multi-Style Transfer (MST) intents to capture the high-level visual vocabulary of different styles and expresses these vocabularies in a joint model to transfer each specific style. Recently, Style Embedding Learning (SEL) based methods represent each style with an explicit set of parameters to perform MST task. However, most existing SEL methods either learn explicit style representation with numerous independent parameters or learn a relatively black-box style representation, which makes them difficult to control the stylized results. In this paper, we outline a novel MST model, StyleRemix, to compactly and explicitly integrate multiple styles into one network. By decomposing diverse styles into the same basis, StyleRemix represents a specific style in a continuous vector space with 1-dimensional coefficients. With the interpretable style representation, StyleRemix not only enables the style visualization task but also allows several ways of remixing styles in the smooth style embedding space.~Extensive experiments demonstrate the effectiveness of StyleRemix on various MST tasks compared to state-of-the-art SEL approaches.
Supervised Contrastive Learning
Apr 23, 2020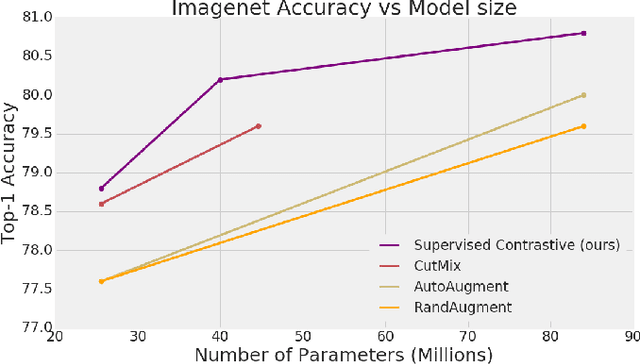
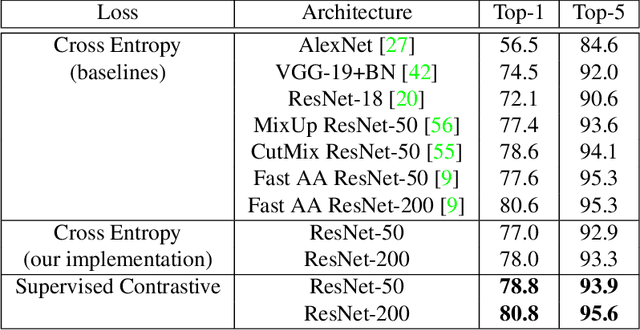
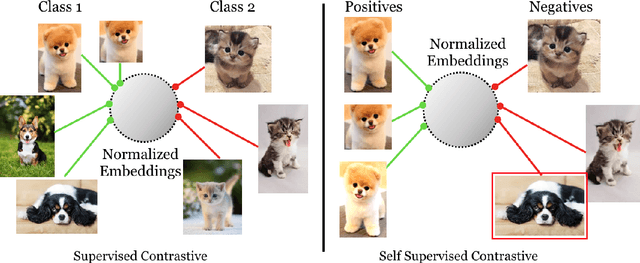
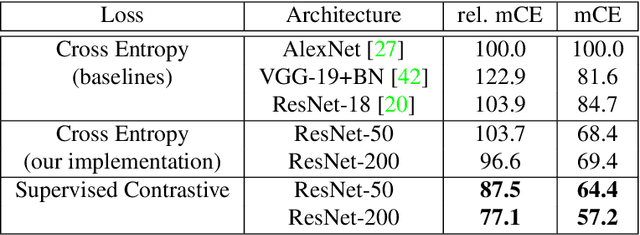
Cross entropy is the most widely used loss function for supervised training of image classification models. In this paper, we propose a novel training methodology that consistently outperforms cross entropy on supervised learning tasks across different architectures and data augmentations. We modify the batch contrastive loss, which has recently been shown to be very effective at learning powerful representations in the self-supervised setting. We are thus able to leverage label information more effectively than cross entropy. Clusters of points belonging to the same class are pulled together in embedding space, while simultaneously pushing apart clusters of samples from different classes. In addition to this, we leverage key ingredients such as large batch sizes and normalized embeddings, which have been shown to benefit self-supervised learning. On both ResNet-50 and ResNet-200, we outperform cross entropy by over 1%, setting a new state of the art number of 78.8% among methods that use AutoAugment data augmentation. The loss also shows clear benefits for robustness to natural corruptions on standard benchmarks on both calibration and accuracy. Compared to cross entropy, our supervised contrastive loss is more stable to hyperparameter settings such as optimizers or data augmentations.
Credible Sample Elicitation by Deep Learning, for Deep Learning
Oct 08, 2019It is important to collect credible training samples $(x,y)$ for building data-intensive learning systems (e.g., a deep learning system). In the literature, there is a line of studies on eliciting distributional information from self-interested agents who hold a relevant information. Asking people to report complex distribution $p(x)$, though theoretically viable, is challenging in practice. This is primarily due to the heavy cognitive loads required for human agents to reason and report this high dimensional information. Consider the example where we are interested in building an image classifier via first collecting a certain category of high-dimensional image data. While classical elicitation results apply to eliciting a complex and generative (and continuous) distribution $p(x)$ for this image data, we are interested in eliciting samples $x_i \sim p(x)$ from agents. This paper introduces a deep learning aided method to incentivize credible sample contributions from selfish and rational agents. The challenge to do so is to design an incentive-compatible score function to score each reported sample to induce truthful reports, instead of an arbitrary or even adversarial one. We show that with accurate estimation of a certain $f$-divergence function we are able to achieve approximate incentive compatibility in eliciting truthful samples. We then present an efficient estimator with theoretical guarantee via studying the variational forms of $f$-divergence function. Our work complements the literature of information elicitation via introducing the problem of \emph{sample elicitation}. We also show a connection between this sample elicitation problem and $f$-GAN, and how this connection can help reconstruct an estimator of the distribution based on collected samples.
WSMN: An optimized multipurpose blind watermarking in Shearlet domain using MLP and NSGA-II
May 07, 2020

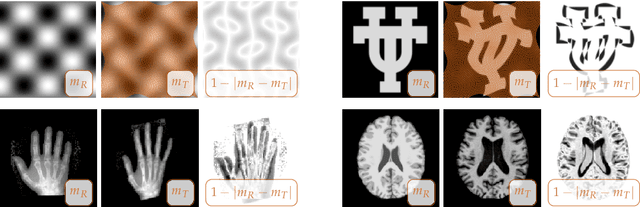
Digital watermarking is a remarkable issue in the field of information security to avoid the misuse of images in multimedia networks. Although access to unauthorized persons can be prevented through cryptography, it cannot be simultaneously used for copyright protection or content authentication with the preservation of image integrity. Hence, this paper presents an optimized multipurpose blind watermarking in Shearlet domain with the help of smart algorithms including MLP and NSGA-II. In this method, four copies of the robust copyright logo are embedded in the approximate coefficients of Shearlet by using an effective quantization technique. Furthermore, an embedded random sequence as a semi-fragile authentication mark is effectively extracted from details by the neural network. Due to performing an effective optimization algorithm for selecting optimum embedding thresholds, and also distinguishing the texture of blocks, the imperceptibility and robustness have been preserved. The experimental results reveal the superiority of the scheme with regard to the quality of watermarked images and robustness against hybrid attacks over other state-of-the-art schemes. The average PSNR and SSIM of the dual watermarked images are 38 dB and 0.95, respectively; Besides, it can effectively extract the copyright logo and locates forgery regions under severe attacks with satisfactory accuracy.
An inexact Newton-Krylov algorithm for constrained diffeomorphic image registration
May 07, 2015
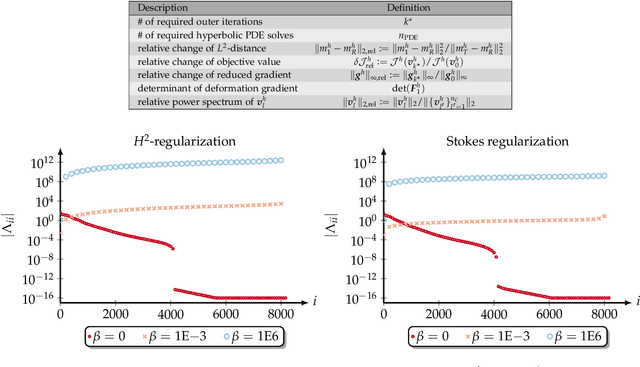

We propose numerical algorithms for solving large deformation diffeomorphic image registration problems. We formulate the nonrigid image registration problem as a problem of optimal control. This leads to an infinite-dimensional partial differential equation (PDE) constrained optimization problem. The PDE constraint consists, in its simplest form, of a hyperbolic transport equation for the evolution of the image intensity. The control variable is the velocity field. Tikhonov regularization on the control ensures well-posedness. We consider standard smoothness regularization based on $H^1$- or $H^2$-seminorms. We augment this regularization scheme with a constraint on the divergence of the velocity field rendering the deformation incompressible and thus ensuring that the determinant of the deformation gradient is equal to one, up to the numerical error. We use a Fourier pseudospectral discretization in space and a Chebyshev pseudospectral discretization in time. We use a preconditioned, globalized, matrix-free, inexact Newton-Krylov method for numerical optimization. A parameter continuation is designed to estimate an optimal regularization parameter. Regularity is ensured by controlling the geometric properties of the deformation field. Overall, we arrive at a black-box solver. We study spectral properties of the Hessian, grid convergence, numerical accuracy, computational efficiency, and deformation regularity of our scheme. We compare the designed Newton-Krylov methods with a globalized preconditioned gradient descent. We study the influence of a varying number of unknowns in time. The reported results demonstrate excellent numerical accuracy, guaranteed local deformation regularity, and computational efficiency with an optional control on local mass conservation. The Newton-Krylov methods clearly outperform the Picard method if high accuracy of the inversion is required.
* 32 pages; 10 figures; 9 tables
Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching
Apr 01, 2018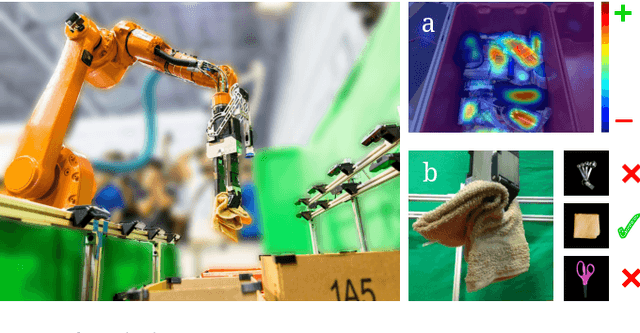


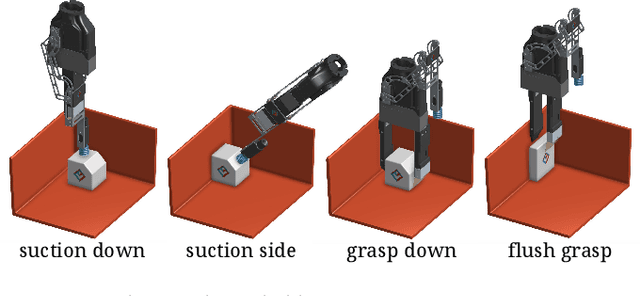
This paper presents a robotic pick-and-place system that is capable of grasping and recognizing both known and novel objects in cluttered environments. The key new feature of the system is that it handles a wide range of object categories without needing any task-specific training data for novel objects. To achieve this, it first uses a category-agnostic affordance prediction algorithm to select and execute among four different grasping primitive behaviors. It then recognizes picked objects with a cross-domain image classification framework that matches observed images to product images. Since product images are readily available for a wide range of objects (e.g., from the web), the system works out-of-the-box for novel objects without requiring any additional training data. Exhaustive experimental results demonstrate that our multi-affordance grasping achieves high success rates for a wide variety of objects in clutter, and our recognition algorithm achieves high accuracy for both known and novel grasped objects. The approach was part of the MIT-Princeton Team system that took 1st place in the stowing task at the 2017 Amazon Robotics Challenge. All code, datasets, and pre-trained models are available online at http://arc.cs.princeton.edu
Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm
May 20, 2020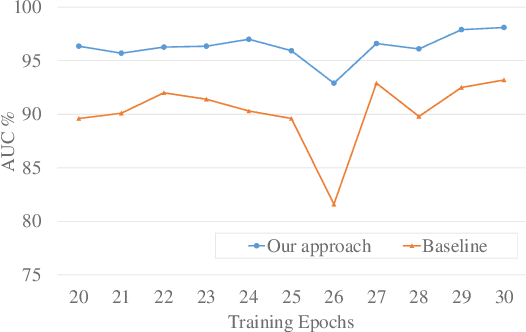

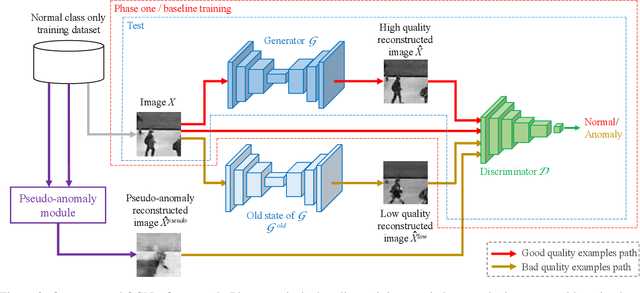

A popular method for anomaly detection is to use the generator of an adversarial network to formulate anomaly scores over reconstruction loss of input. Due to the rare occurrence of anomalies, optimizing such networks can be a cumbersome task. Another possible approach is to use both generator and discriminator for anomaly detection. However, attributed to the involvement of adversarial training, this model is often unstable in a way that the performance fluctuates drastically with each training step. In this study, we propose a framework that effectively generates stable results across a wide range of training steps and allows us to use both the generator and the discriminator of an adversarial model for efficient and robust anomaly detection. Our approach transforms the fundamental role of a discriminator from identifying real and fake data to distinguishing between good and bad quality reconstructions. To this end, we prepare training examples for the good quality reconstruction by employing the current generator, whereas poor quality examples are obtained by utilizing an old state of the same generator. This way, the discriminator learns to detect subtle distortions that often appear in reconstructions of the anomaly inputs. Extensive experiments performed on Caltech-256 and MNIST image datasets for novelty detection show superior results. Furthermore, on UCSD Ped2 video dataset for anomaly detection, our model achieves a frame-level AUC of 98.1%, surpassing recent state-of-the-art methods.
Feature Based Fuzzy Rule Base Design for Image Extraction
Jun 16, 2012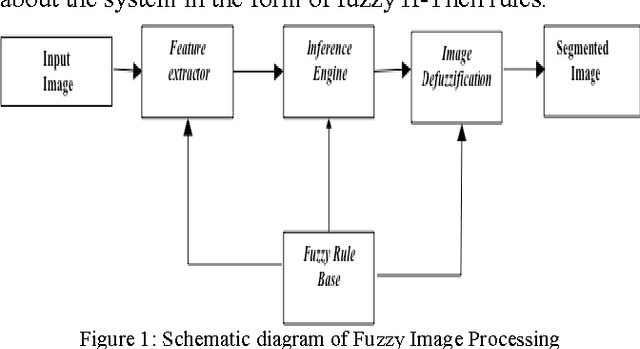
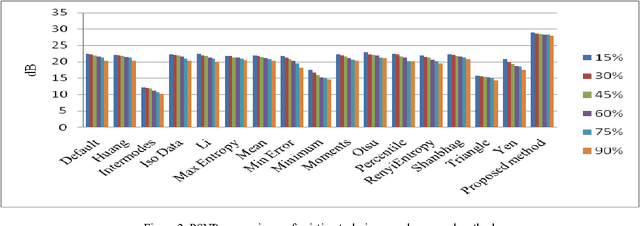

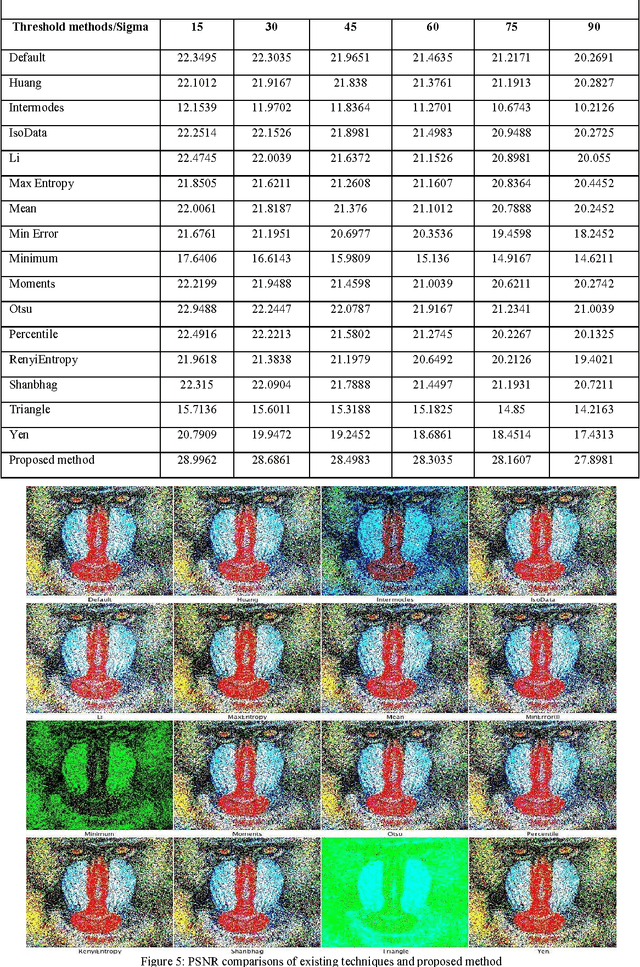
In the recent advancement of multimedia technologies, it becomes a major concern of detecting visual attention regions in the field of image processing. The popularity of the terminal devices in a heterogeneous environment of the multimedia technology gives us enough scope for the betterment of image visualization. Although there exist numerous methods, feature based image extraction becomes a popular one in the field of image processing. The objective of image segmentation is the domain-independent partition of the image into a set of regions, which are visually distinct and uniform with respect to some property, such as grey level, texture or colour. Segmentation and subsequent extraction can be considered the first step and key issue in object recognition, scene understanding and image analysis. Its application area encompasses mobile devices, industrial quality control, medical appliances, robot navigation, geophysical exploration, military applications, etc. In all these areas, the quality of the final results depends largely on the quality of the preprocessing work. Most of the times, acquiring spurious-free preprocessing data requires a lot of application cum mathematical intensive background works. We propose a feature based fuzzy rule guided novel technique that is functionally devoid of any external intervention during execution. Experimental results suggest that this approach is an efficient one in comparison to different other techniques extensively addressed in literature. In order to justify the supremacy of performance of our proposed technique in respect of its competitors, we take recourse to effective metrics like Mean Squared Error (MSE), Mean Absolute Error (MAE) and Peak Signal to Noise Ratio (PSNR).
Putting visual object recognition in context
Dec 09, 2019


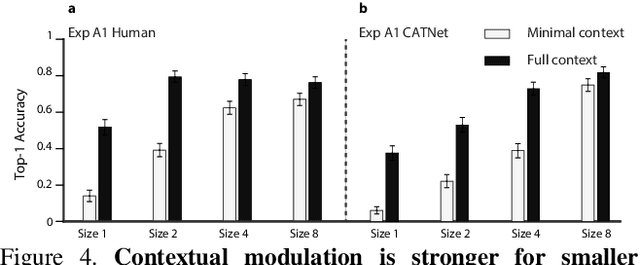
Context plays an important role in visual recognition. Recent studies have shown that visual recognition networks can be fooled by placing objects in inconsistent contexts (e.g. a cow in the ocean). To understand and model the role of contextual information in visual recognition, we systematically and quantitatively investigated ten critical properties of where, when, and how context modulates recognition including amount of context, context and object resolution, geometrical structure of context, context congruence, time required to incorporate contextual information, and temporal dynamics of contextual modulation. The tasks involve recognizing a target object surrounded with context in a natural image. As an essential benchmark, we first describe a series of psychophysics experiments, where we alter one aspect of context at a time, and quantify human recognition accuracy. To computationally assess performance on the same tasks, we propose a biologically inspired context aware object recognition model consisting of a two-stream architecture. The model processes visual information at the fovea and periphery in parallel, dynamically incorporates both object and contextual information, and sequentially reasons about the class label for the target object. Across a wide range of behavioral tasks, the model approximates human level performance without retraining for each task, captures the dependence of context enhancement on image properties, and provides initial steps towards integrating scene and object information for visual recognition.
Improving Human Annotation in Single Object Tracking
Nov 07, 2019

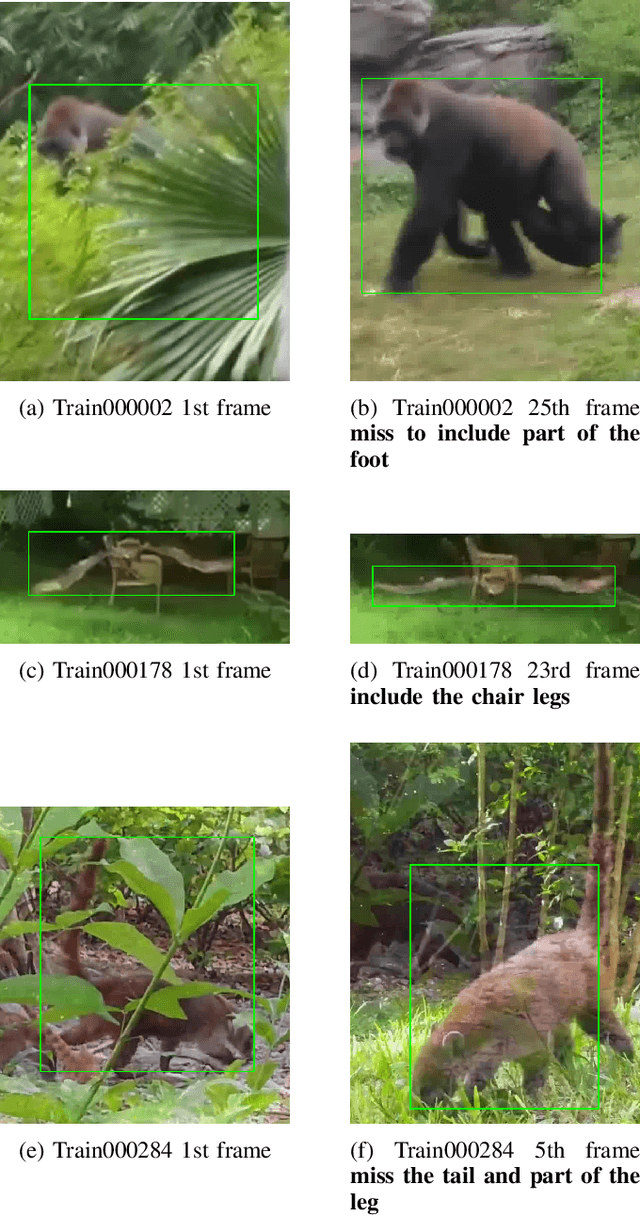
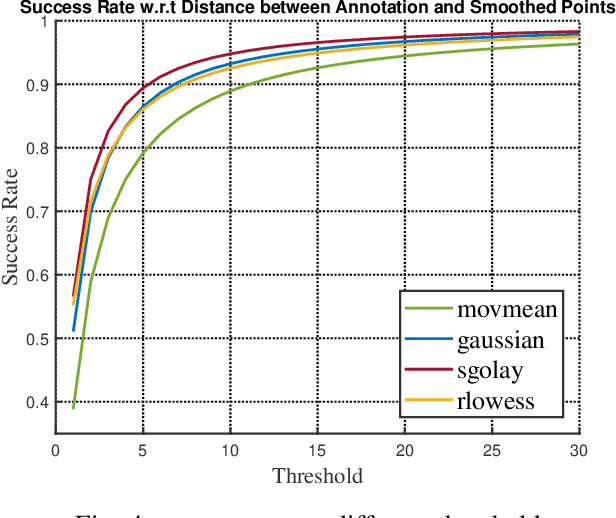
Human annotation is always considered as ground truth in video object tracking tasks. It is used in both training and evaluation purposes. Thus, ensuring its high quality is an important task for the success of trackers and evaluations between them. In this paper, we give a qualitative and quantitative analysis of the existing human annotations. We show that human annotation tends to be non-smooth and is prone to partial visibility and deformation. We propose a smoothing trajectory strategy with the ability to handle moving scenes. We use a two-step adaptive image alignment algorithm to find the canonical view of the video sequence. We then use different techniques to smooth the trajectories at certain degree. Once we convert back to the original image coordination, we can compare with the human annotation. With the experimental results, we can get more consistent trajectories. At a certain degree, it can also slightly improve the trained model. If go beyond a certain threshold, the smoothing error will start eating up the benefit. Overall, our method could help extrapolate the missing annotation frames or identify and correct human annotation outliers as well as help improve the training data quality.