 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HP2IFS: Head Pose estimation exploiting Partitioned Iterated Function Systems
Mar 25, 2020
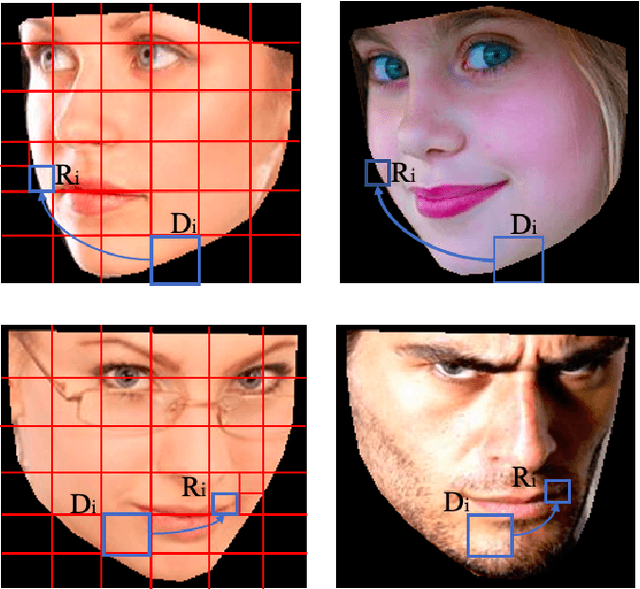
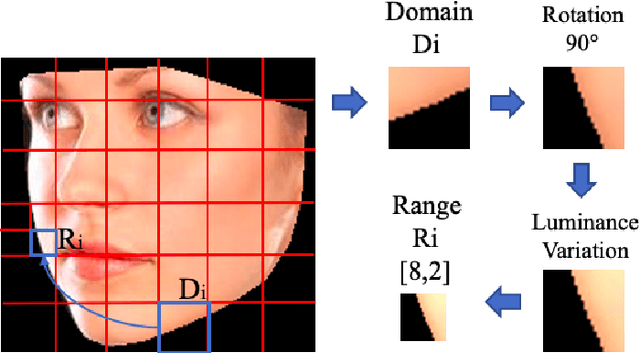
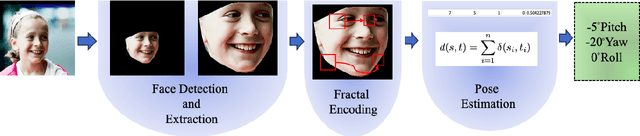
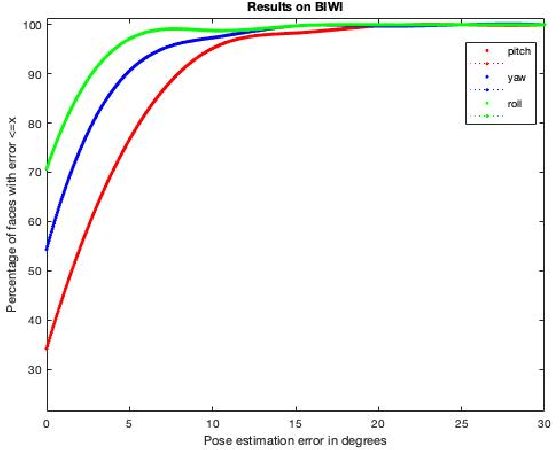
Estimating the actual head orientation from 2D images, with regard to its three degrees of freedom, is a well known problem that is highly significant for a large number of applications involving head pose knowledge. Consequently, this topic has been tackled by a plethora of methods and algorithms the most part of which exploits neural networks. Machine learning methods, indeed, achieve accurate head rotation values yet require an adequate training stage and, to that aim, a relevant number of positive and negative examples. In this paper we take a different approach to this topic by using fractal coding theory and particularly Partitioned Iterated Function Systems to extract the fractal code from the input head image and to compare this representation to the fractal code of a reference model through Hamming distance. According to experiments conducted on both the BIWI and the AFLW2000 databases, the proposed PIFS based head pose estimation method provides accurate yaw/pitch/roll angular values, with a performance approaching that of state of the art of machine-learning based algorithms and exceeding most of non-training based approaches.
The Treasure beneath Convolutional Layers: Cross-convolutional-layer Pooling for Image Classification
Nov 27, 2014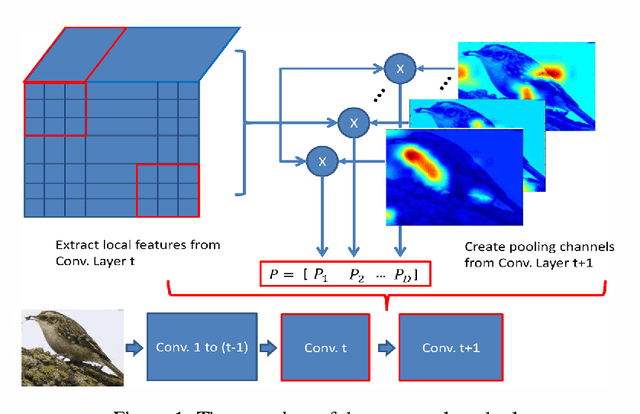
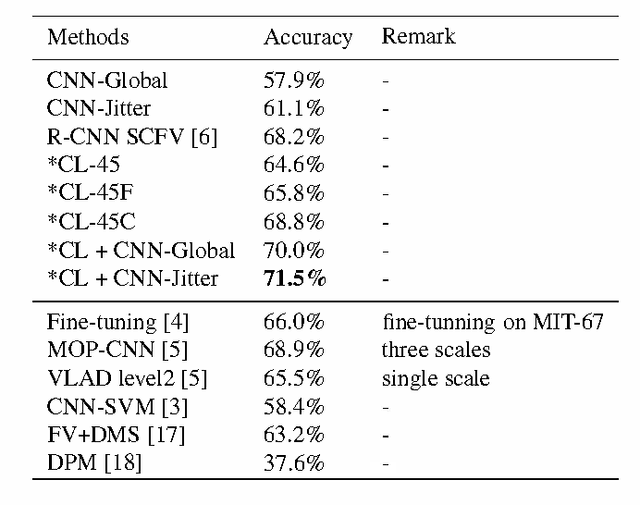

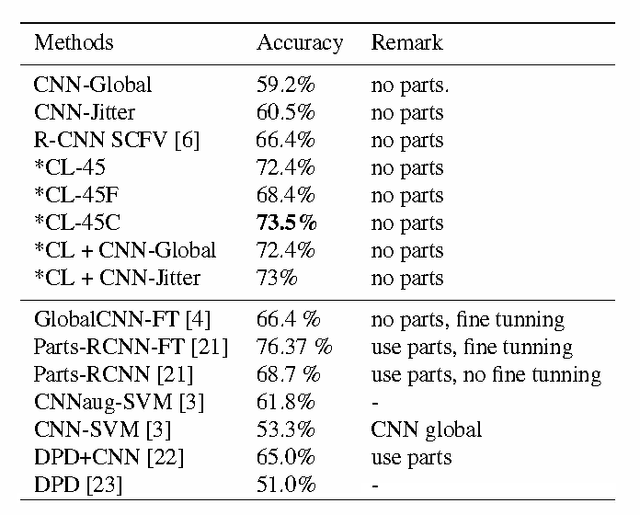
A number of recent studies have shown that a Deep Convolutional Neural Network (DCNN) pretrained on a large dataset can be adopted as a universal image description which leads to astounding performance in many visual classification tasks. Most of these studies, if not all, adopt activations of the fully-connected layer of a DCNN as the image or region representation and it is believed that convolutional layer activations are less discriminative. This paper, however, advocates that if used appropriately convolutional layer activations can be turned into a powerful image representation which enjoys many advantages over fully-connected layer activations. This is achieved by adopting a new technique proposed in this paper called cross-convolutional-layer pooling. More specifically, it extracts subarrays of feature maps of one convolutional layer as local features and pools the extracted features with the guidance of feature maps of the successive convolutional layer. Compared with exising methods that apply DCNNs in the local feature setting, the proposed method is significantly faster since it requires much fewer times of DCNN forward computation. Moreover, it avoids the domain mismatch issue which is usually encountered when applying fully connected layer activations to describe local regions. By applying our method to four popular visual classification tasks, it is demonstrated that the proposed method can achieve comparable or in some cases significantly better performance than existing fully-connected layer based image representations while incurring much lower computational cost.
Deep Fusion Siamese Network for Automatic Kinship Verification
May 30, 2020

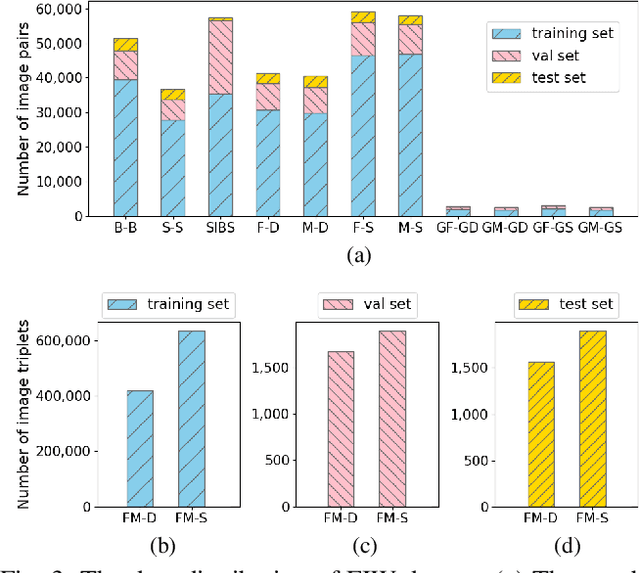
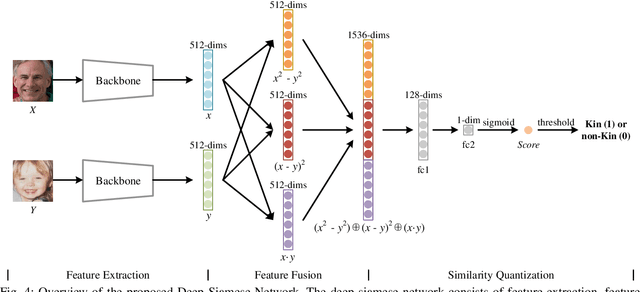
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at {\color{blue}https://github.com/gniknoil/FG2020-kinship}.
* 8 pages, 8 figures
Efficient Splitting-based Method for Global Image Smoothing
Apr 26, 2016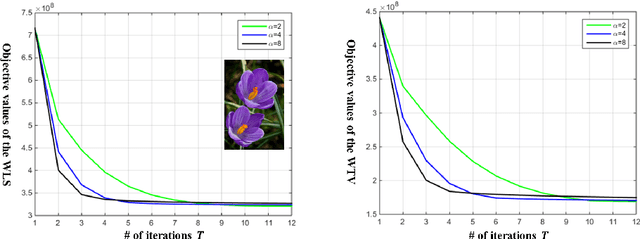

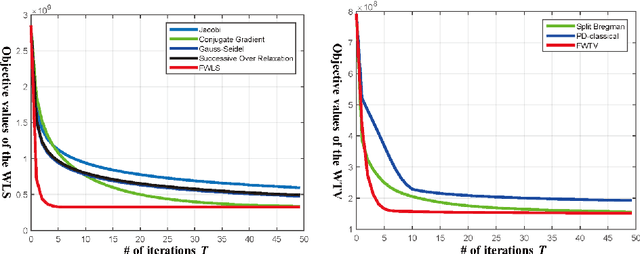
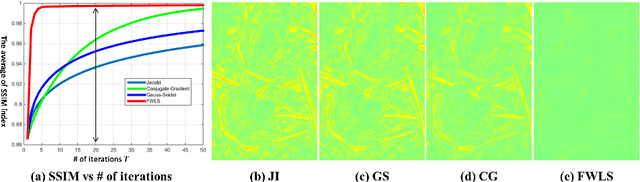
Edge-preserving smoothing (EPS) can be formulated as minimizing an objective function that consists of data and prior terms. This global EPS approach shows better smoothing performance than a local one that typically has a form of weighted averaging, at the price of high computational cost. In this paper, we introduce a highly efficient splitting-based method for global EPS that minimizes the objective function of ${l_2}$ data and prior terms (possibly non-smooth and non-convex) in linear time. Different from previous splitting-based methods that require solving a large linear system, our approach solves an equivalent constrained optimization problem, resulting in a sequence of 1D sub-problems. This enables linear time solvers for weighted-least squares and -total variation problems. Our solver converges quickly, and its runtime is even comparable to state-of-the-art local EPS approaches. We also propose a family of fast iteratively re-weighted algorithms using a non-convex prior term. Experimental results demonstrate the effectiveness and flexibility of our approach in a range of computer vision and image processing tasks.
Improving drone localisation around wind turbines using monocular model-based tracking
Feb 27, 2019
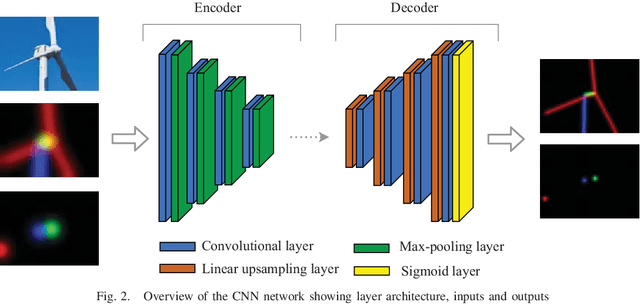
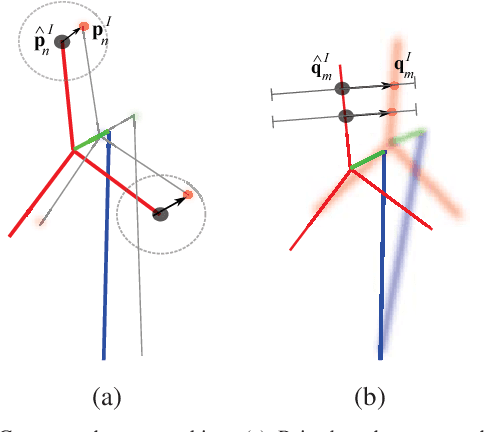

We present a novel method of integrating image-based measurements into a drone navigation system for the automated inspection of wind turbines. We take a model-based tracking approach, where a 3D skeleton representation of the turbine is matched to the image data. Matching is based on comparing the projection of the representation to that inferred from images using a convolutional neural network. This enables us to find image correspondences using a generic turbine model that can be applied to a wide range of turbine shapes and sizes. To estimate 3D pose of the drone, we fuse the network output with GPS and IMU measurements using a pose graph optimiser. Results illustrate that the use of the image measurements significantly improves the accuracy of the localisation over that obtained using GPS and IMU alone.
Hyperspectral and Multispectral Image Fusion based on a Sparse Representation
Sep 19, 2014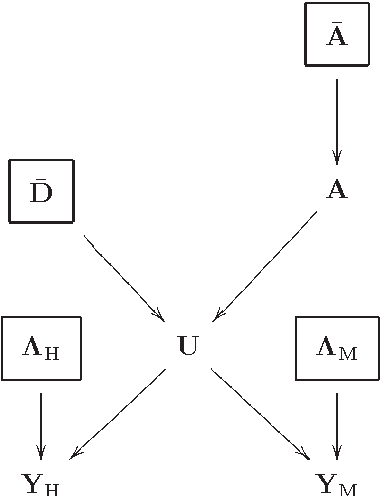

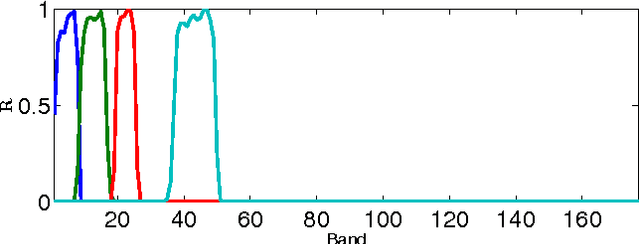

This paper presents a variational based approach to fusing hyperspectral and multispectral images. The fusion process is formulated as an inverse problem whose solution is the target image assumed to live in a much lower dimensional subspace. A sparse regularization term is carefully designed, relying on a decomposition of the scene on a set of dictionaries. The dictionary atoms and the corresponding supports of active coding coefficients are learned from the observed images. Then, conditionally on these dictionaries and supports, the fusion problem is solved via alternating optimization with respect to the target image (using the alternating direction method of multipliers) and the coding coefficients. Simulation results demonstrate the efficiency of the proposed algorithm when compared with the state-of-the-art fusion methods.
SR2CNN: Zero-Shot Learning for Signal Recognition
Apr 10, 2020



Signal recognition is one of significant and challenging tasks in the signal processing and communications field. It is often a common situation that there's no training data accessible for some signal classes to perform a recognition task. Hence, as widely-used in image processing field, zero-shot learning (ZSL) is also very important for signal recognition. Unfortunately, ZSL regarding this field has hardly been studied due to inexplicable signal semantics. This paper proposes a ZSL framework, signal recognition and reconstruction convolutional neural networks (SR2CNN), to address relevant problems in this situation. The key idea behind SR2CNN is to learn the representation of signal semantic feature space by introducing a proper combination of cross entropy loss, center loss and autoencoder loss, as well as adopting a suitable distance metric space such that semantic features have greater minimal inter-class distance than maximal intra-class distance. The proposed SR2CNN can discriminate signals even if no training data is available for some signal class. Moreover, SR2CNN can gradually improve itself in the aid of signal detection, because of constantly refined class center vectors in semantic feature space. These merits are all verified by extensive experiments.
Approximating the Ideal Observer for joint signal detection and localization tasks by use of supervised learning methods
May 29, 2020
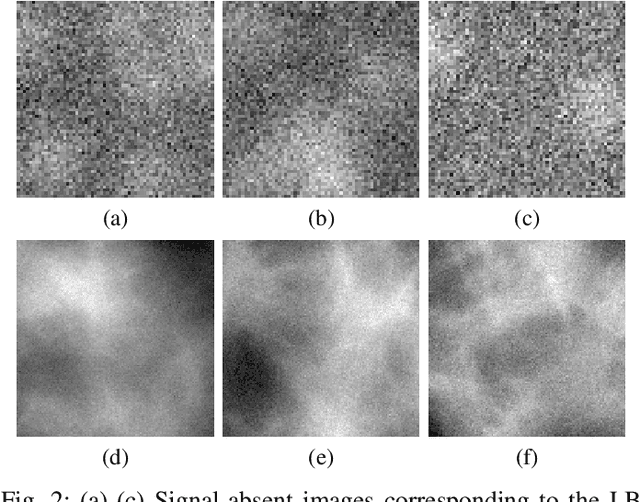

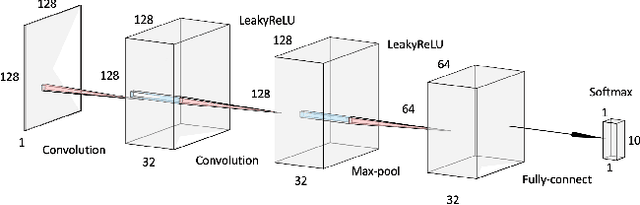
Medical imaging systems are commonly assessed and optimized by use of objective measures of image quality (IQ). The Ideal Observer (IO) performance has been advocated to provide a figure-of-merit for use in assessing and optimizing imaging systems because the IO sets an upper performance limit among all observers. When joint signal detection and localization tasks are considered, the IO that employs a modified generalized likelihood ratio test maximizes observer performance as characterized by the localization receiver operating characteristic (LROC) curve. Computations of likelihood ratios are analytically intractable in the majority of cases. Therefore, sampling-based methods that employ Markov-Chain Monte Carlo (MCMC) techniques have been developed to approximate the likelihood ratios. However, the applications of MCMC methods have been limited to relatively simple object models. Supervised learning-based methods that employ convolutional neural networks have been recently developed to approximate the IO for binary signal detection tasks. In this paper, the ability of supervised learning-based methods to approximate the IO for joint signal detection and localization tasks is explored. Both background-known-exactly and background-known-statistically signal detection and localization tasks are considered. The considered object models include a lumpy object model and a clustered lumpy model, and the considered measurement noise models include Laplacian noise, Gaussian noise, and mixed Poisson-Gaussian noise. The LROC curves produced by the supervised learning-based method are compared to those produced by the MCMC approach or analytical computation when feasible. The potential utility of the proposed method for computing objective measures of IQ for optimizing imaging system performance is explored.
DualDis: Dual-Branch Disentangling with Adversarial Learning
Jun 03, 2019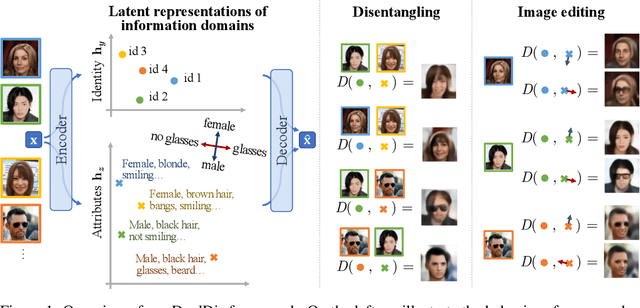
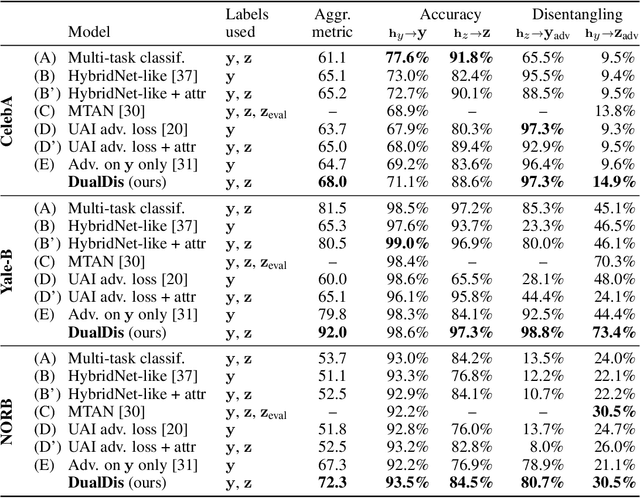
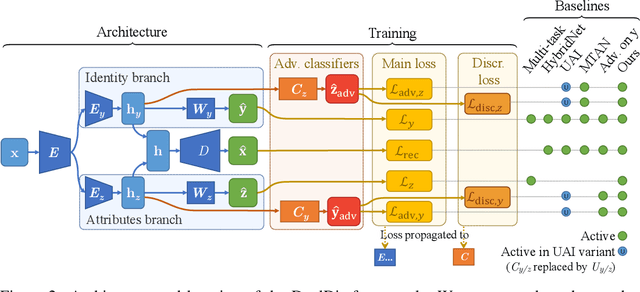
In computer vision, disentangling techniques aim at improving latent representations of images by modeling factors of variation. In this paper, we propose DualDis, a new auto-encoder-based framework that disentangles and linearizes class and attribute information. This is achieved thanks to a two-branch architecture forcing the separation of the two kinds of information, accompanied by a decoder for image reconstruction and generation. To effectively separate the information, we propose to use a combination of regular and adversarial classifiers to guide the two branches in specializing for class and attribute information respectively. We also investigate the possibility of using semi-supervised learning for an effective disentangling even using few labels. We leverage the linearization property of the latent spaces for semantic image editing and generation of new images. We validate our approach on CelebA, Yale-B and NORB by measuring the efficiency of information separation via classification metrics, visual image manipulation and data augmentation.
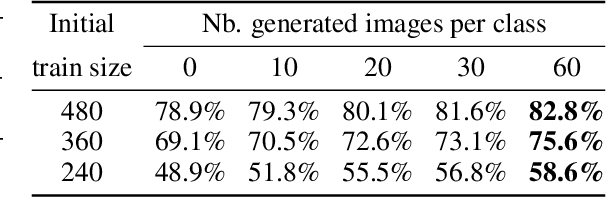
Plug-in Factorization for Latent Representation Disentanglement
May 29, 2019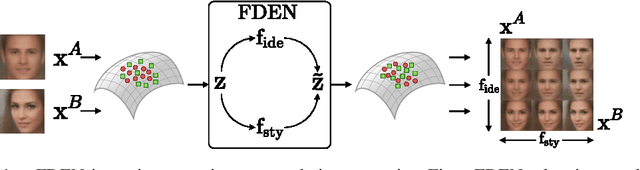
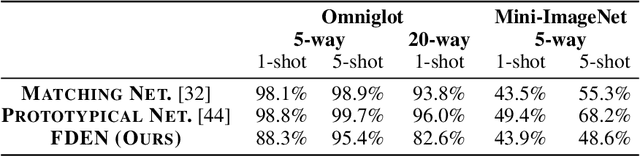
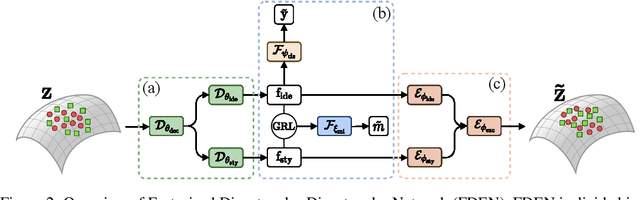
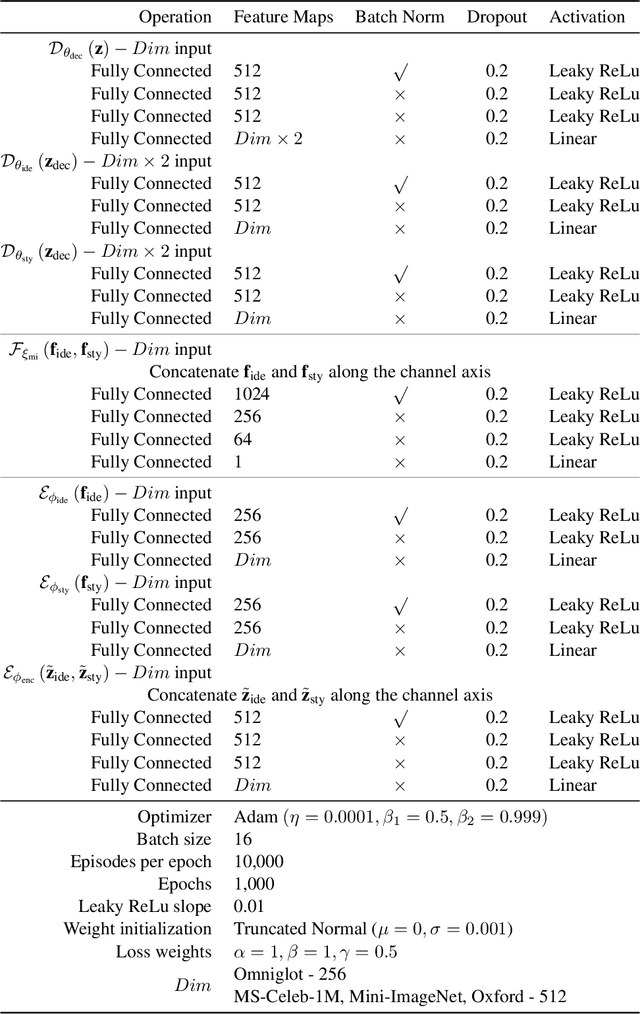
In this work, we propose a Factorized Disentangler-Entangler Network (FDEN) that learns to decompose a latent representation into two mutually independent factors, namely, identity and style. Given a latent representation, the proposed framework draws a set of interpretable factors aligned to identity of an observed data and learns to maximize the independency between these factors. Our work introduces an idea for a plug-in method to disentangle latent representations of already learned deep models with no affect to the model. In doing so, it brings the possibilities of extending state-of-the-art models to solve different tasks and also maintain the performance of its original task. Thus, FDEN is naturally applicable to jointly perform multiple tasks such as few-shot learning and image-to-image translation in a single framework. We show the effectiveness of our work in disentangling a latent representation in two parts. First, to evaluate the alignment of factor to an identity, we perform few-shot learning using only the aligned factor. Then, to evaluate the effectiveness of decomposition of latent representation and to show that plugin method does not affect the deep model in its performance, we perform image-to-image style transfer by mixing factors of different images. These evaluations show, qualitatively and quantitatively, that our proposed framework can indeed disentangle a latent representation.