 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised Recurrent Neural Network for 4D Abdominal and In-utero MR Imaging
Aug 28, 2019
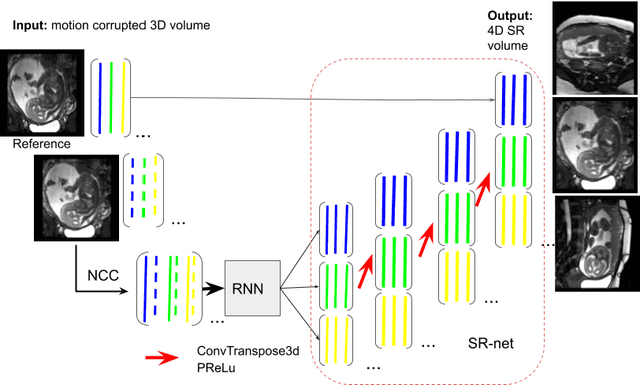

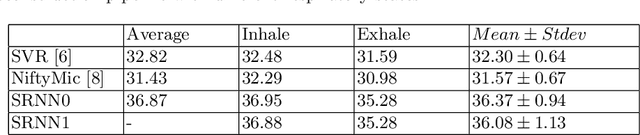
Accurately estimating and correcting the motion artifacts are crucial for 3D image reconstruction of the abdominal and in-utero magnetic resonance imaging (MRI). The state-of-art methods are based on slice-to-volume registration (SVR) where multiple 2D image stacks are acquired in three orthogonal orientations. In this work, we present a novel reconstruction pipeline that only needs one orientation of 2D MRI scans and can reconstruct the full high-resolution image without masking or registration steps. The framework consists of two main stages: the respiratory motion estimation using a self-supervised recurrent neural network, which learns the respiratory signals that are naturally embedded in the asymmetry relationship of the neighborhood slices and cluster them according to a respiratory state. Then, we train a 3D deconvolutional network for super-resolution (SR) reconstruction of the sparsely selected 2D images using integrated reconstruction and total variation loss. We evaluate the classification accuracy on 5 simulated images and compare our results with the SVR method in adult abdominal and in-utero MRI scans. The results show that the proposed pipeline can accurately estimate the respiratory state and reconstruct 4D SR volumes with better or similar performance to the 3D SVR pipeline with less than 20\% sparsely selected slices. The method has great potential to transform the 4D abdominal and in-utero MRI in clinical practice.
Semi-supervised Disentanglement with Independent Vector Variational Autoencoders
Mar 14, 2020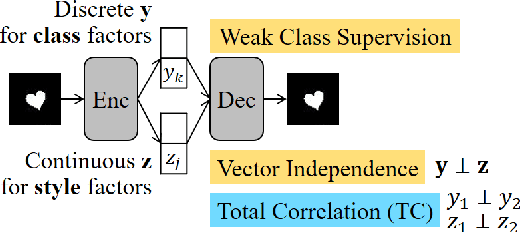
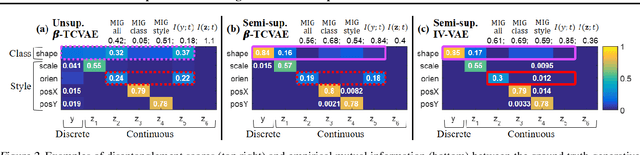

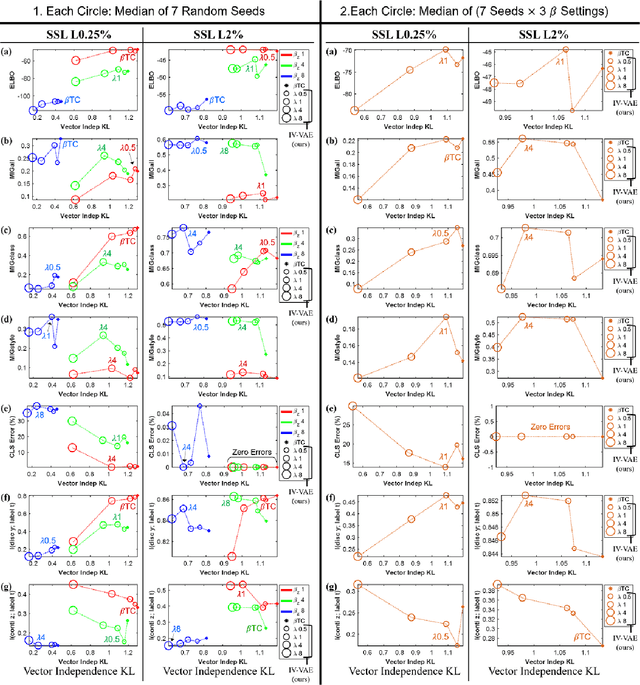
We aim to separate the generative factors of data into two latent vectors in a variational autoencoder. One vector captures class factors relevant to target classification tasks, while the other vector captures style factors relevant to the remaining information. To learn the discrete class features, we introduce supervision using a small amount of labeled data, which can simply yet effectively reduce the effort required for hyperparameter tuning performed in existing unsupervised methods. Furthermore, we introduce a learning objective to encourage statistical independence between the vectors. We show that (i) this vector independence term exists within the result obtained on decomposing the evidence lower bound with multiple latent vectors, and (ii) encouraging such independence along with reducing the total correlation within the vectors enhances disentanglement performance. Experiments conducted on several image datasets demonstrate that the disentanglement achieved via our method can improve classification performance and generation controllability.
Illumination-based Transformations Improve Skin Lesion Segmentation in Dermoscopic Images
Mar 23, 2020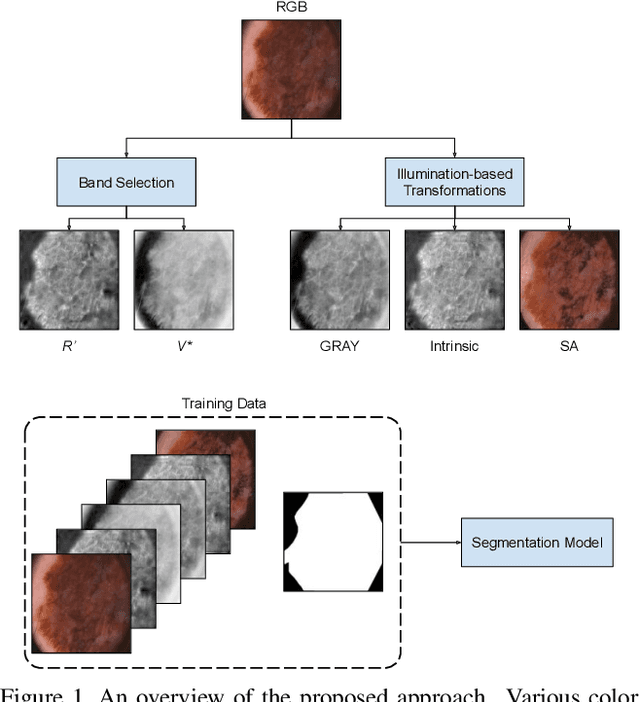
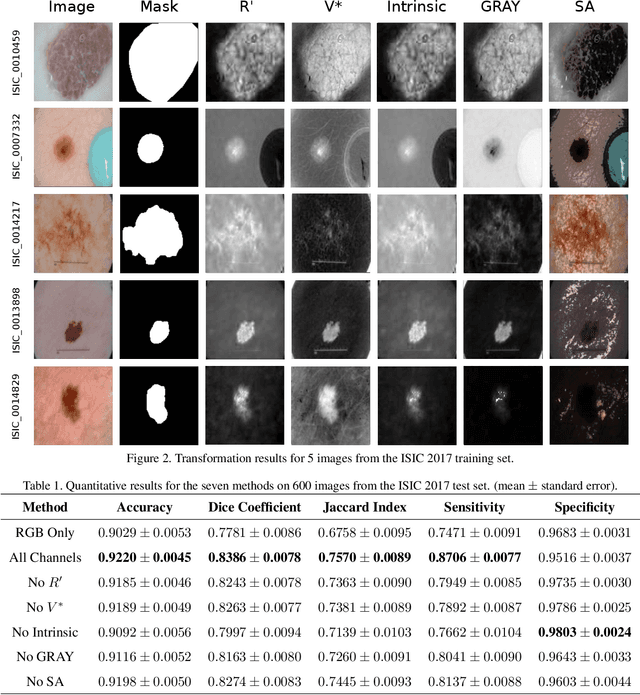

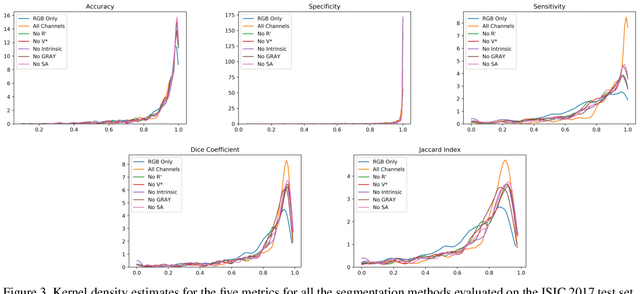
The semantic segmentation of skin lesions is an important and common initial task in the computer aided diagnosis of dermoscopic images. Although deep learning-based approaches have considerably improved the segmentation accuracy, there is still room for improvement by addressing the major challenges, such as variations in lesion shape, size, color and varying levels of contrast. In this work, we propose the first deep semantic segmentation framework for dermoscopic images which incorporates, along with the original RGB images, information extracted using the physics of skin illumination and imaging. In particular, we incorporate information from specific color bands, illumination invariant grayscale images, and shading-attenuated images. We evaluate our method on three datasets: the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset, the DermoFit Image Library, and the PH2 dataset and observe improvements of 12.02%, 4.30%, and 8.86% respectively in the mean Jaccard index over a baseline model trained only with RGB images.
Enhanced Image Classification With a Fast-Learning Shallow Convolutional Neural Network
Aug 15, 2015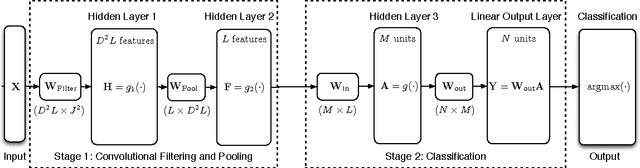
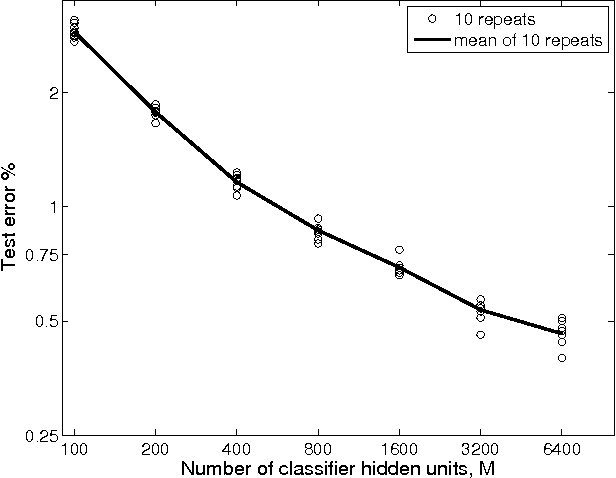
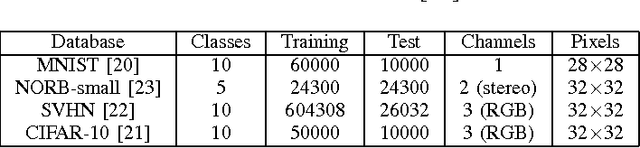

We present a neural network architecture and training method designed to enable very rapid training and low implementation complexity. Due to its training speed and very few tunable parameters, the method has strong potential for applications requiring frequent retraining or online training. The approach is characterized by (a) convolutional filters based on biologically inspired visual processing filters, (b) randomly-valued classifier-stage input weights, (c) use of least squares regression to train the classifier output weights in a single batch, and (d) linear classifier-stage output units. We demonstrate the efficacy of the method by applying it to image classification. Our results match existing state-of-the-art results on the MNIST (0.37% error) and NORB-small (2.2% error) image classification databases, but with very fast training times compared to standard deep network approaches. The network's performance on the Google Street View House Number (SVHN) (4% error) database is also competitive with state-of-the art methods.
Model Agnostic Defence against Backdoor Attacks in Machine Learning
Aug 28, 2019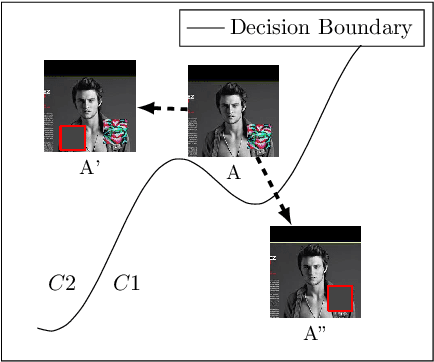
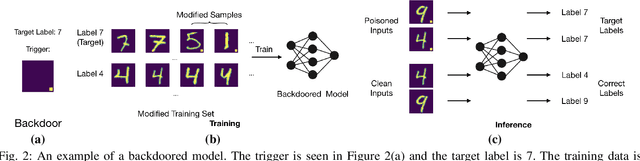

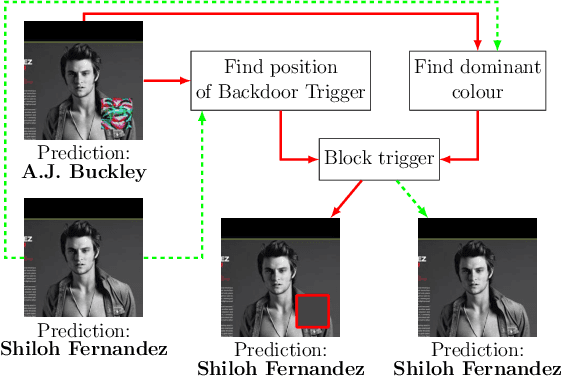
Machine Learning (ML) has automated a multitude of our day-to-day decision making domains such as education, employment and driving automation. The continued success of ML largely depends on our ability to trust the model we are using. Recently, a new class of attacks called Backdoor Attacks have been developed. These attacks undermine the user's trust in ML models. In this work, we present NEO, a model agnostic framework to detect and mitigate such backdoor attacks in image classification ML models. For a given image classification model, our approach analyses the inputs it receives and determines if the model is backdoored. In addition to this feature, we also mitigate these attacks by determining the correct predictions of the poisoned images. An appealing feature of NEO is that it can, for the first time, isolate and reconstruct the backdoor trigger. NEO is also the first defence methodology, to the best of our knowledge that is completely blackbox. We have implemented NEO and evaluated it against three state of the art poisoned models. These models include highly critical applications such as traffic sign detection (USTS) and facial detection. In our evaluation, we show that NEO can detect $\approx$88\% of the poisoned inputs on average and it is as fast as 4.4 ms per input image. We also reconstruct the poisoned input for the user to effectively test their systems.
Predictive Sampling with Forecasting Autoregressive Models
Feb 23, 2020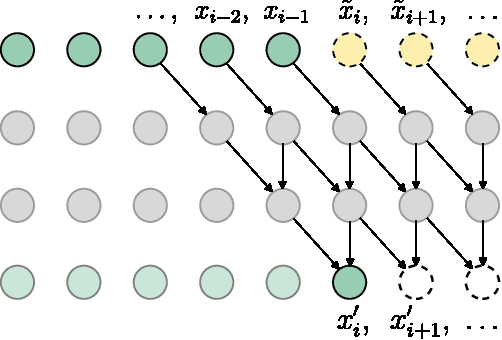
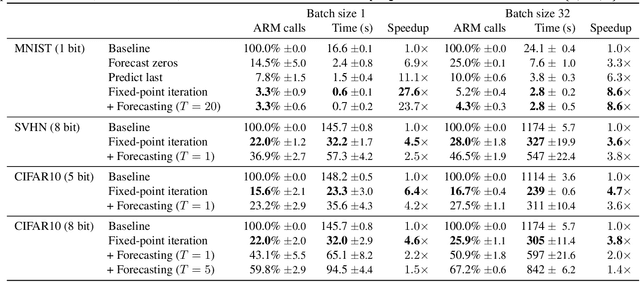
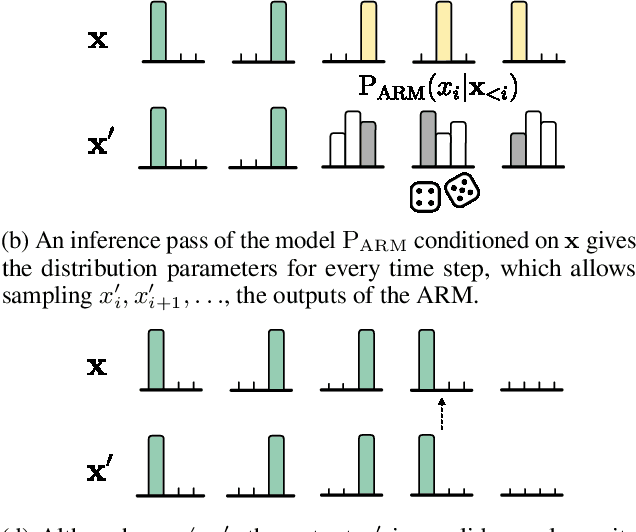
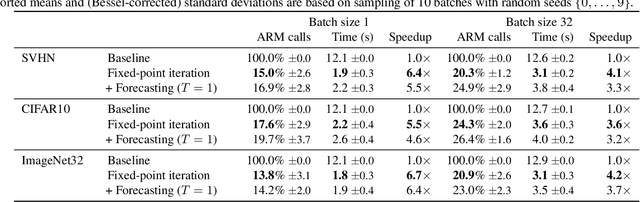
Autoregressive models (ARMs) currently hold state-of-the-art performance in likelihood-based modeling of image and audio data. Generally, neural network based ARMs are designed to allow fast inference, but sampling from these models is impractically slow. In this paper, we introduce the predictive sampling algorithm: a procedure that exploits the fast inference property of ARMs in order to speed up sampling, while keeping the model intact. We propose two variations of predictive sampling, namely sampling with ARM fixed-point iteration and learned forecasting modules. Their effectiveness is demonstrated in two settings: i) explicit likelihood modeling on binary MNIST, SVHN and CIFAR10, and ii) discrete latent modeling in an autoencoder trained on SVHN, CIFAR10 and Imagenet32. Empirically, we show considerable improvements over baselines in number of ARM inference calls and sampling speed.
Monocular Direct Sparse Localization in a Prior 3D Surfel Map
Feb 23, 2020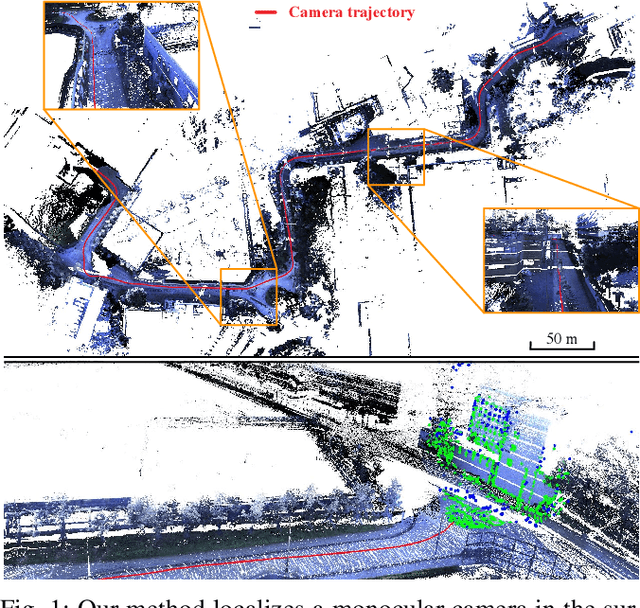
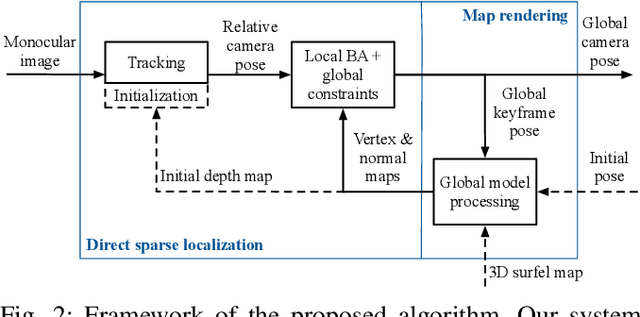
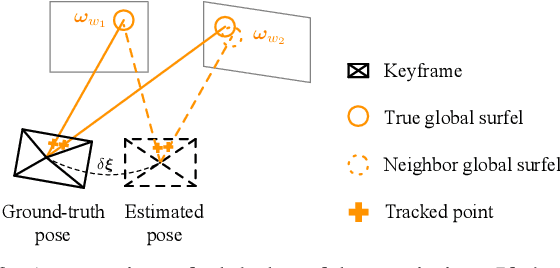

In this paper, we introduce an approach to tracking the pose of a monocular camera in a prior surfel map. By rendering vertex and normal maps from the prior surfel map, the global planar information for the sparse tracked points in the image frame is obtained. The tracked points with and without the global planar information involve both global and local constraints of frames to the system. Our approach formulates all constraints in the form of direct photometric errors within a local window of the frames. The final optimization utilizes these constraints to provide the accurate estimation of global 6-DoF camera poses with the absolute scale. The extensive simulation and real-world experiments demonstrate that our monocular method can provide accurate camera localization results under various conditions.
BASS Net: Band-Adaptive Spectral-Spatial Feature Learning Neural Network for Hyperspectral Image Classification
Dec 02, 2016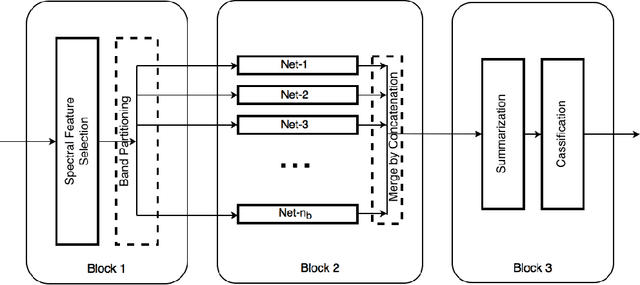
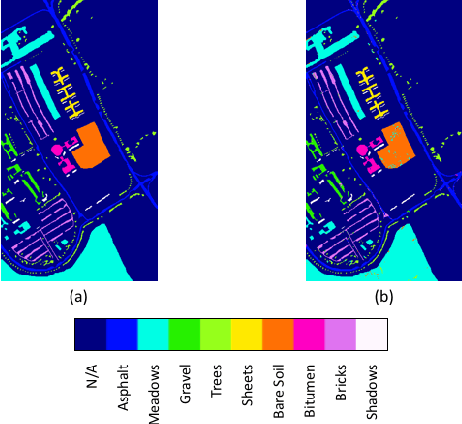
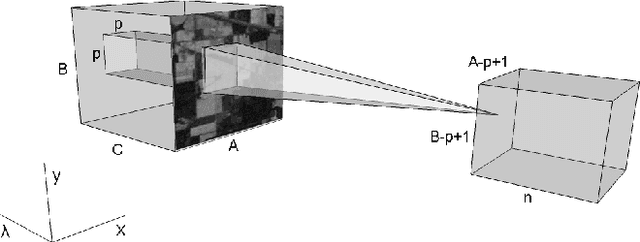
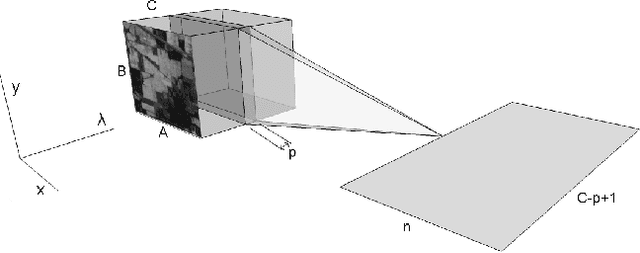
Deep learning based landcover classification algorithms have recently been proposed in literature. In hyperspectral images (HSI) they face the challenges of large dimensionality, spatial variability of spectral signatures and scarcity of labeled data. In this article we propose an end-to-end deep learning architecture that extracts band specific spectral-spatial features and performs landcover classification. The architecture has fewer independent connection weights and thus requires lesser number of training data. The method is found to outperform the highest reported accuracies on popular hyperspectral image data sets.
Knowledge Distillation for Incremental Learning in Semantic Segmentation
Nov 08, 2019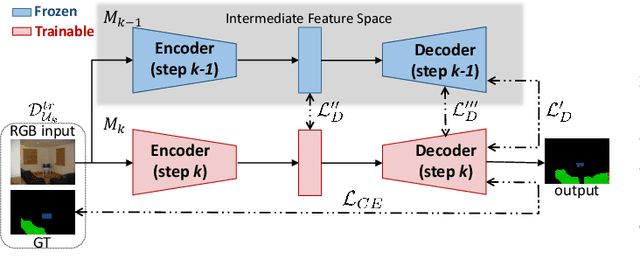
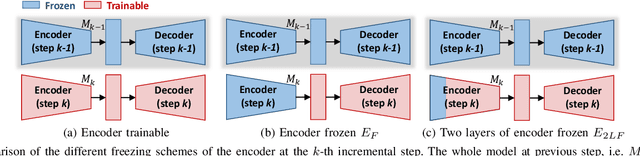


Although deep learning architectures have shown remarkable results in scene understanding problems, they exhibit a critical drop of overall performance due to catastrophic forgetting when they are required to incrementally learn to recognize new classes without forgetting the old ones. This phenomenon impacts on the deployment of artificial intelligence in real world scenarios where systems need to learn new and different representations over time. Current approaches for incremental learning deal only with the image classification and object detection tasks. In this work we formally introduce the incremental learning problem for semantic segmentation. To avoid catastrophic forgetting we propose to distill the knowledge of the previous model to retain the information about previously learned classes, whilst updating the current model to learn the new ones. We developed three main methodologies of knowledge distillation working on both the output layers and the internal feature representations. Furthermore, differently from other recent frameworks, we do not store any image belonging to the previous training stages while only the last model is used to preserve high accuracy on previously learned classes. Extensive results were conducted on the Pascal VOC2012 dataset and show the effectiveness of the proposed approaches in different incremental learning scenarios.
Perceptual Embedding Consistency for Seamless Reconstruction of Tilewise Style Transfer
Jun 03, 2019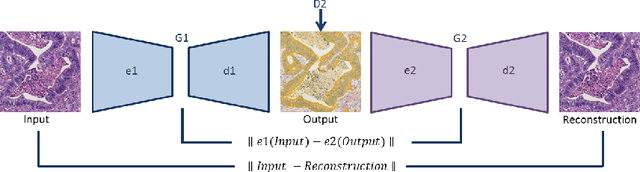


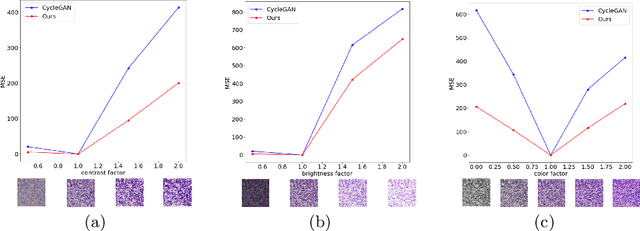
Style transfer is a field with growing interest and use cases in deep learning. Recent work has shown Generative Adversarial Networks(GANs) can be used to create realistic images of virtually stained slide images in digital pathology with clinically validated interpretability. Digital pathology images are typically of extremely high resolution, making tilewise analysis necessary for deep learning applications. It has been shown that image generators with instance normalization can cause a tiling artifact when a large image is reconstructed from the tilewise analysis. We introduce a novel perceptual embedding consistency loss significantly reducing the tiling artifact created in the reconstructed whole slide image (WSI). We validate our results by comparing virtually stained slide images with consecutive real stained tissue slide images. We also demonstrate that our model is more robust to contrast, color and brightness perturbations by running comparative sensitivity analysis tests.