 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HP2IFS: Head Pose estimation exploiting Partitioned Iterated Function Systems
Mar 25, 2020
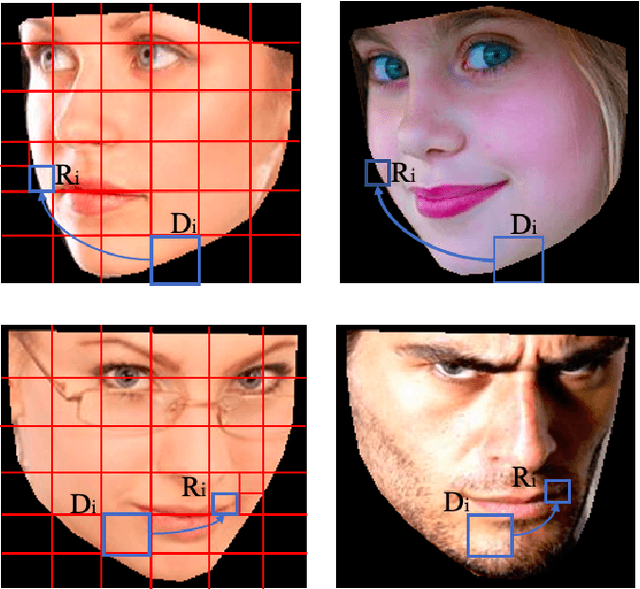
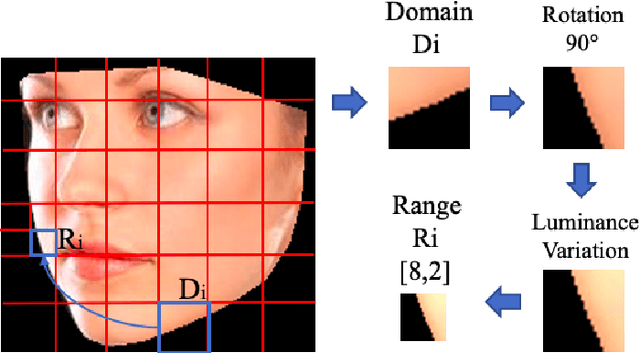
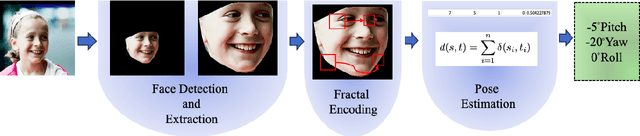
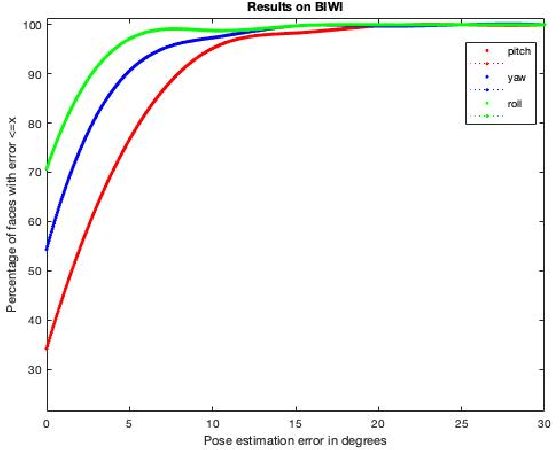
Estimating the actual head orientation from 2D images, with regard to its three degrees of freedom, is a well known problem that is highly significant for a large number of applications involving head pose knowledge. Consequently, this topic has been tackled by a plethora of methods and algorithms the most part of which exploits neural networks. Machine learning methods, indeed, achieve accurate head rotation values yet require an adequate training stage and, to that aim, a relevant number of positive and negative examples. In this paper we take a different approach to this topic by using fractal coding theory and particularly Partitioned Iterated Function Systems to extract the fractal code from the input head image and to compare this representation to the fractal code of a reference model through Hamming distance. According to experiments conducted on both the BIWI and the AFLW2000 databases, the proposed PIFS based head pose estimation method provides accurate yaw/pitch/roll angular values, with a performance approaching that of state of the art of machine-learning based algorithms and exceeding most of non-training based approaches.
Augmenting the Pathology Lab: An Intelligent Whole Slide Image Classification System for the Real World
Sep 24, 2019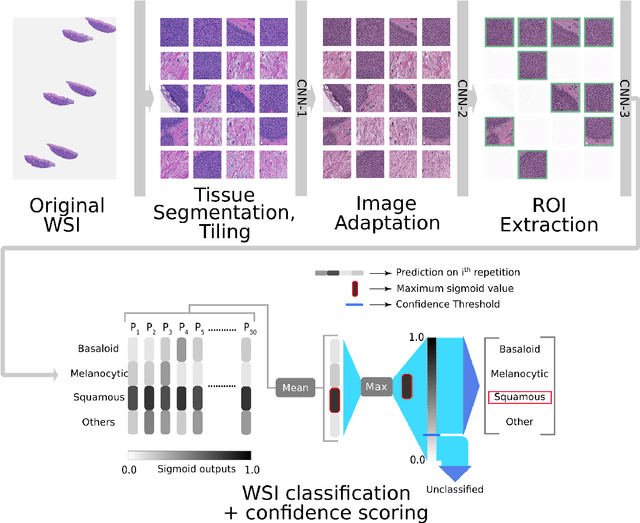
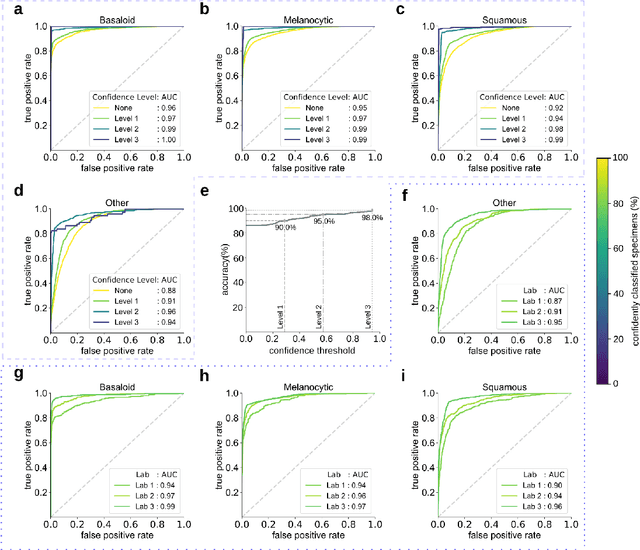
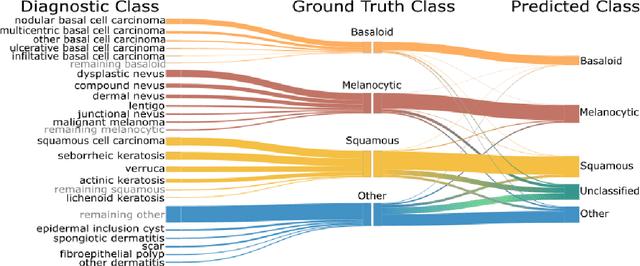

Standard of care diagnostic procedure for suspected skin cancer is microscopic examination of hematoxylin \& eosin stained tissue by a pathologist. Areas of high inter-pathologist discordance and rising biopsy rates necessitate higher efficiency and diagnostic reproducibility. We present and validate a deep learning system which classifies digitized dermatopathology slides into 4 categories. The system is developed using 5,070 images from a single lab, and tested on an uncurated set of 13,537 images from 3 test labs, using whole slide scanners manufactured by 3 different vendors. The system's use of deep-learning-based confidence scoring as a criterion to consider the result as accurate yields an accuracy of up to 98\%, and makes it adoptable in a real-world setting. Without confidence scoring, the system achieved an accuracy of 78\%. We anticipate that our deep learning system will serve as a foundation enabling faster diagnosis of skin cancer, identification of cases for specialist review, and targeted diagnostic classifications.
AdaptIS: Adaptive Instance Selection Network
Sep 17, 2019
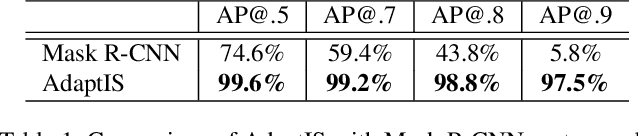

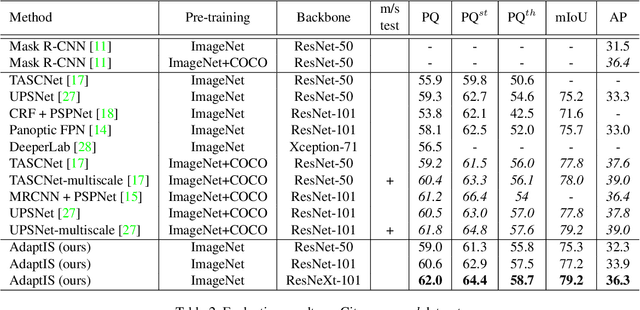
We present Adaptive Instance Selection network architecture for class-agnostic instance segmentation. Given an input image and a point $(x, y)$, it generates a mask for the object located at $(x, y)$. The network adapts to the input point with a help of AdaIN layers, thus producing different masks for different objects on the same image. AdaptIS generates pixel-accurate object masks, therefore it accurately segments objects of complex shape or severely occluded ones. AdaptIS can be easily combined with standard semantic segmentation pipeline to perform panoptic segmentation. To illustrate the idea, we perform experiments on a challenging toy problem with difficult occlusions. Then we extensively evaluate the method on panoptic segmentation benchmarks. We obtain state-of-the-art results on Cityscapes and Mapillary even without pretraining on COCO, and show competitive results on a challenging COCO dataset. The source code of the method and the trained models are available at https://github.com/saic-vul/adaptis.
A block coordinate descent optimizer for classification problems exploiting convexity
Jun 17, 2020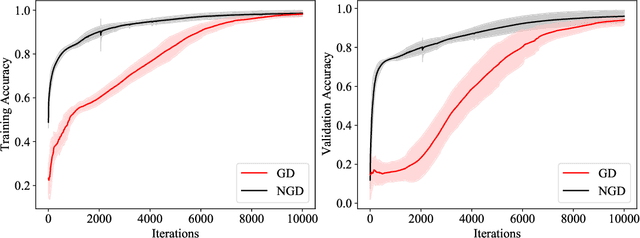
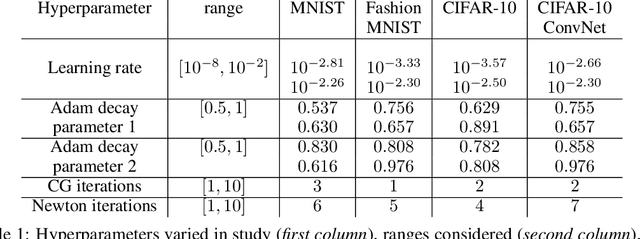
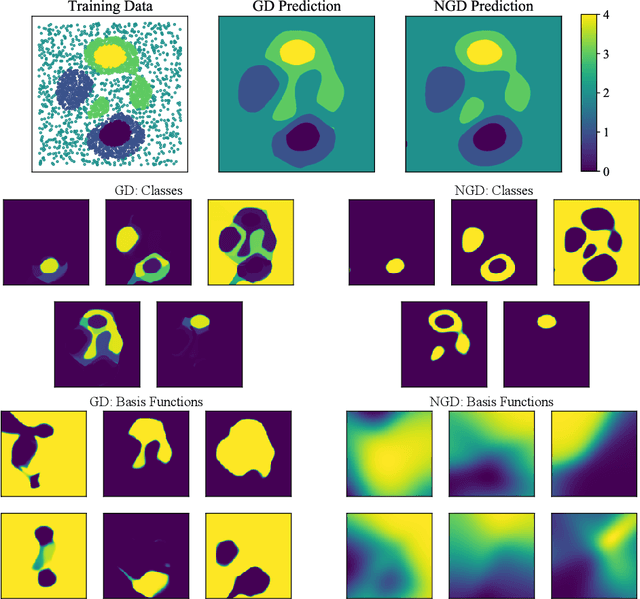
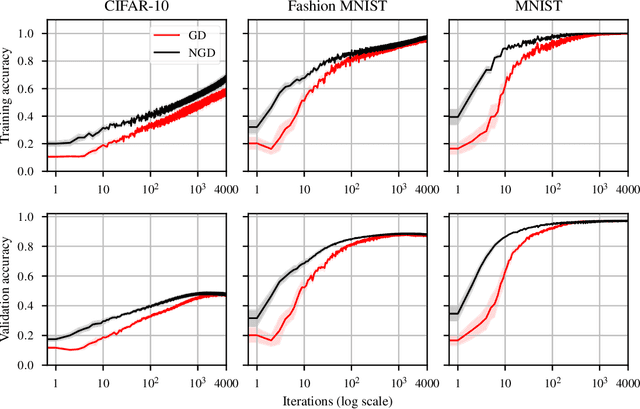
Second-order optimizers hold intriguing potential for deep learning, but suffer from increased cost and sensitivity to the non-convexity of the loss surface as compared to gradient-based approaches. We introduce a coordinate descent method to train deep neural networks for classification tasks that exploits global convexity of the cross-entropy loss in the weights of the linear layer. Our hybrid Newton/Gradient Descent (NGD) method is consistent with the interpretation of hidden layers as providing an adaptive basis and the linear layer as providing an optimal fit of the basis to data. By alternating between a second-order method to find globally optimal parameters for the linear layer and gradient descent to train the hidden layers, we ensure an optimal fit of the adaptive basis to data throughout training. The size of the Hessian in the second-order step scales only with the number weights in the linear layer and not the depth and width of the hidden layers; furthermore, the approach is applicable to arbitrary hidden layer architecture. Previous work applying this adaptive basis perspective to regression problems demonstrated significant improvements in accuracy at reduced training cost, and this work can be viewed as an extension of this approach to classification problems. We first prove that the resulting Hessian matrix is symmetric semi-definite, and that the Newton step realizes a global minimizer. By studying classification of manufactured two-dimensional point cloud data, we demonstrate both an improvement in validation error and a striking qualitative difference in the basis functions encoded in the hidden layer when trained using NGD. Application to image classification benchmarks for both dense and convolutional architectures reveals improved training accuracy, suggesting possible gains of second-order methods over gradient descent.
Object classification from randomized EEG trials
Apr 09, 2020

New results suggest strong limits to the feasibility of classifying human brain activity evoked from image stimuli, as measured through EEG. Considerable prior work suffers from a confound between the stimulus class and the time since the start of the experiment. A prior attempt to avoid this confound using randomized trials was unable to achieve results above chance in a statistically significant fashion when the data sets were of the same size as the original experiments. Here, we again attempt to replicate these experiments with randomized trials on a far larger (20x) dataset of 1,000 stimulus presentations of each of forty classes, all from a single subject. To our knowledge, this is the largest such EEG data collection effort from a single subject and is at the bounds of feasibility. We obtain classification accuracy that is marginally above chance and above chance in a statistically significant fashion, and further assess how accuracy depends on the classifier used, the amount of training data used, and the number of classes. Reaching the limits of data collection without substantial improvement in classification accuracy suggests limits to the feasibility of this enterprise.
Unconstrained Biometric Recognition: Summary of Recent SOCIA Lab. Research
Jan 29, 2020
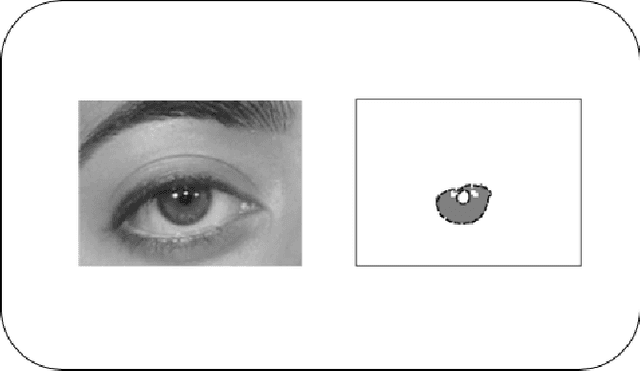
The development of biometric recognition solutions able to work in visual surveillance conditions, i.e., in unconstrained data acquisition conditions and under covert protocols has been motivating growing efforts from the research community. Among the various laboratories, schools and research institutes concerned about this problem, the SOCIA: Soft Computing and Image Analysis Lab., of the University of Beira Interior, Portugal, has been among the most active in pursuing disruptive solutions for obtaining such extremely ambitious kind of automata. This report summarises the research works published by elements of the SOCIA Lab. in the last decade in the scope of biometric recognition in unconstrained conditions. The idea is that it can be used as basis for someone wishing to entering in this research topic.
DCDLearn: Multi-order Deep Cross-distance Learning for Vehicle Re-Identification
Mar 25, 2020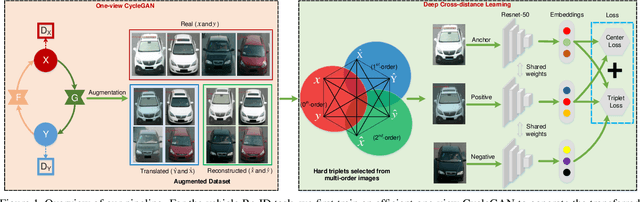

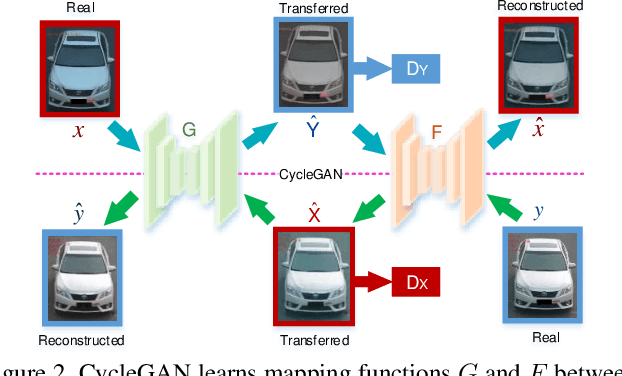
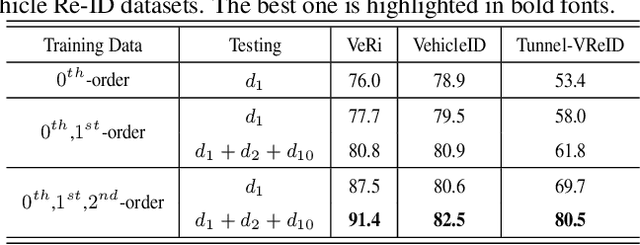
Vehicle re-identification (Re-ID) has become a popular research topic owing to its practicability in intelligent transportation systems. Vehicle Re-ID suffers the numerous challenges caused by drastic variation in illumination, occlusions, background, resolutions, viewing angles, and so on. To address it, this paper formulates a multi-order deep cross-distance learning (\textbf{DCDLearn}) model for vehicle re-identification, where an efficient one-view CycleGAN model is developed to alleviate exhaustive and enumerative cross-camera matching problem in previous works and smooth the domain discrepancy of cross cameras. Specially, we treat the transferred images and the reconstructed images generated by one-view CycleGAN as multi-order augmented data for deep cross-distance learning, where the cross distances of multi-order image set with distinct identities are learned by optimizing an objective function with multi-order augmented triplet loss and center loss to achieve the camera-invariance and identity-consistency. Extensive experiments on three vehicle Re-ID datasets demonstrate that the proposed method achieves significant improvement over the state-of-the-arts, especially for the small scale dataset.
Deep End-to-End Alignment and Refinement for Time-of-Flight RGB-D Module
Sep 17, 2019
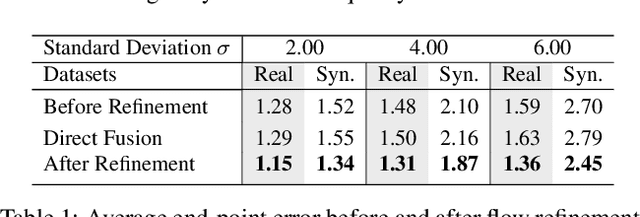
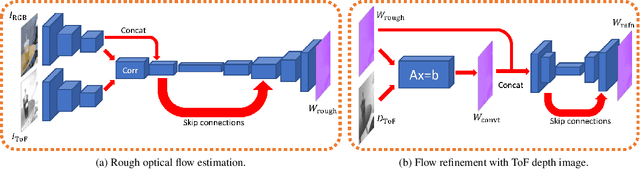
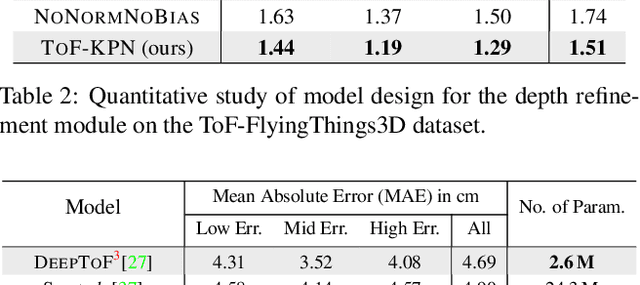
Recently, it is increasingly popular to equip mobile RGB cameras with Time-of-Flight (ToF) sensors for active depth sensing. However, for off-the-shelf ToF sensors, one must tackle two problems in order to obtain high-quality depth with respect to the RGB camera, namely 1) online calibration and alignment; and 2) complicated error correction for ToF depth sensing. In this work, we propose a framework for jointly alignment and refinement via deep learning. First, a cross-modal optical flow between the RGB image and the ToF amplitude image is estimated for alignment. The aligned depth is then refined via an improved kernel predicting network that performs kernel normalization and applies the bias prior to the dynamic convolution. To enrich our data for end-to-end training, we have also synthesized a dataset using tools from computer graphics. Experimental results demonstrate the effectiveness of our approach, achieving state-of-the-art for ToF refinement.
Rethinking the Trigger of Backdoor Attack
Apr 09, 2020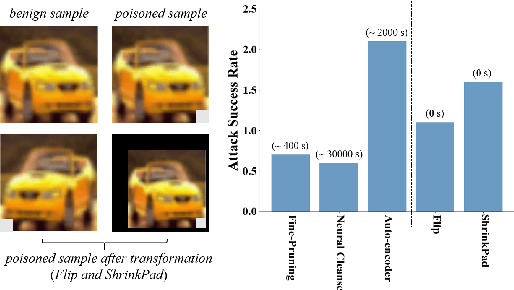
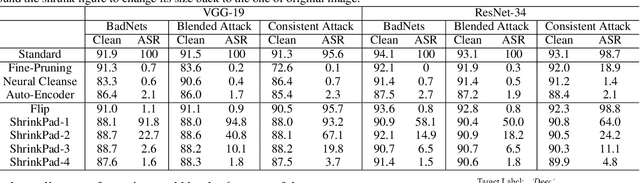
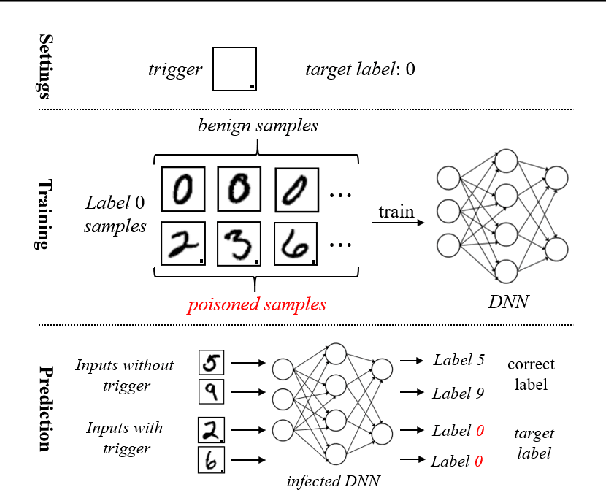
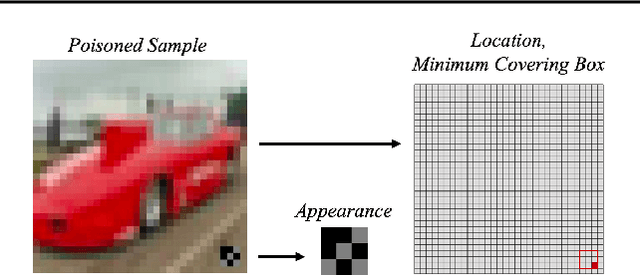
In this work, we study the problem of backdoor attacks, which add a specific trigger ($i.e.$, a local patch) onto some training images to enforce that the testing images with the same trigger are incorrectly predicted while the natural testing examples are correctly predicted by the trained model. Many existing works adopted the setting that the triggers across the training and testing images follow the same appearance and are located at the same area. However, we observe that if the appearance or location of the trigger is slightly changed, then the attack performance may degrade sharply. According to this observation, we propose to spatially transform ($e.g.$, flipping and scaling) the testing image, such that the appearance and location of the trigger (if exists) will be changed. This simple strategy is experimentally verified to be effective to defend many state-of-the-art backdoor attack methods. Furthermore, to enhance the robustness of the backdoor attacks, we propose to conduct the random spatial transformation on the training images with the trigger before feeding into the training process. Extensive experiments verify that the proposed backdoor attack is robust to spatial transformations.
Enhancing Salient Object Segmentation Through Attention
May 27, 2019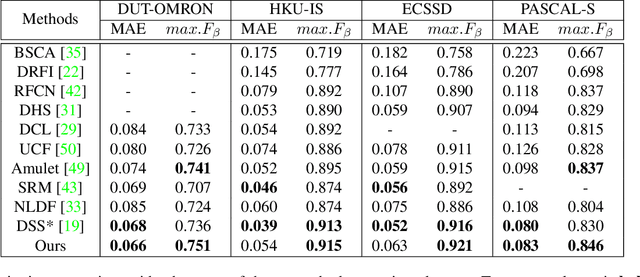
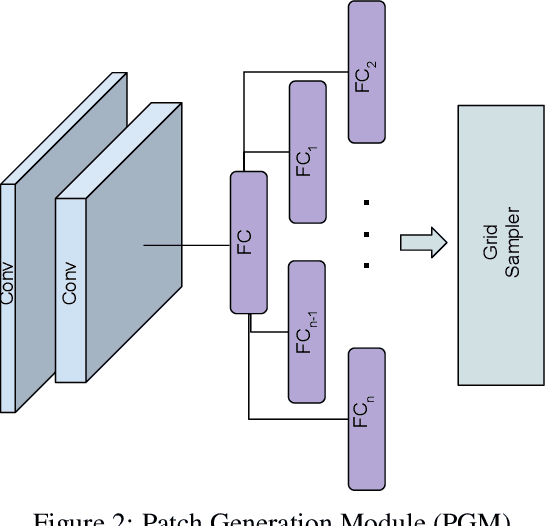
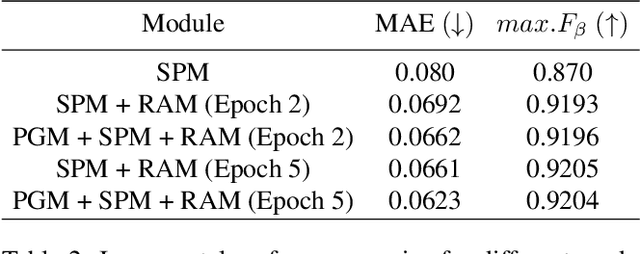
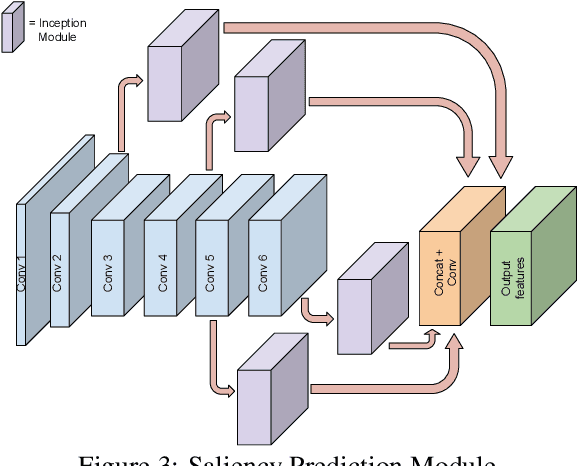
Segmenting salient objects in an image is an important vision task with ubiquitous applications. The problem becomes more challenging in the presence of a cluttered and textured background, low resolution and/or low contrast images. Even though existing algorithms perform well in segmenting most of the object(s) of interest, they often end up segmenting false positives due to resembling salient objects in the background. In this work, we tackle this problem by iteratively attending to image patches in a recurrent fashion and subsequently enhancing the predicted segmentation mask. Saliency features are estimated independently for every image patch, which are further combined using an aggregation strategy based on a Convolutional Gated Recurrent Unit (ConvGRU) network. The proposed approach works in an end-to-end manner, removing background noise and false positives incrementally. Through extensive evaluation on various benchmark datasets, we show superior performance to the existing approaches without any post-processing.