 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Statistical methods of Pixel-Based Image Fusion Techniques
Aug 12, 2011
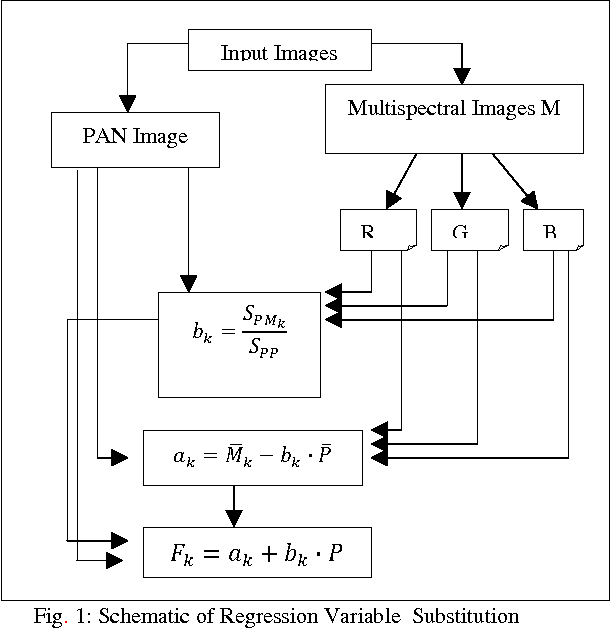
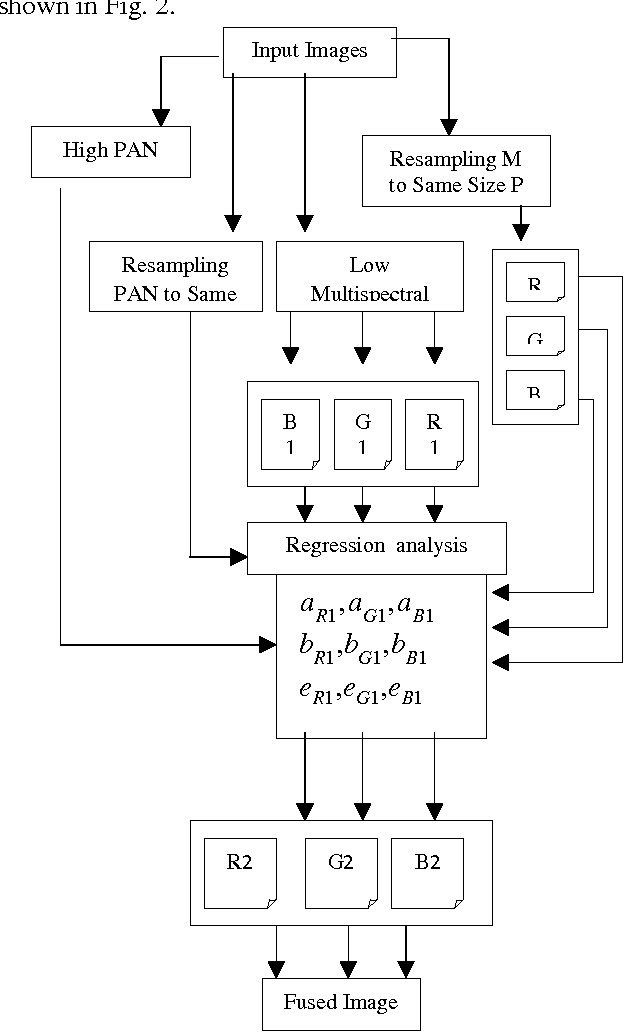
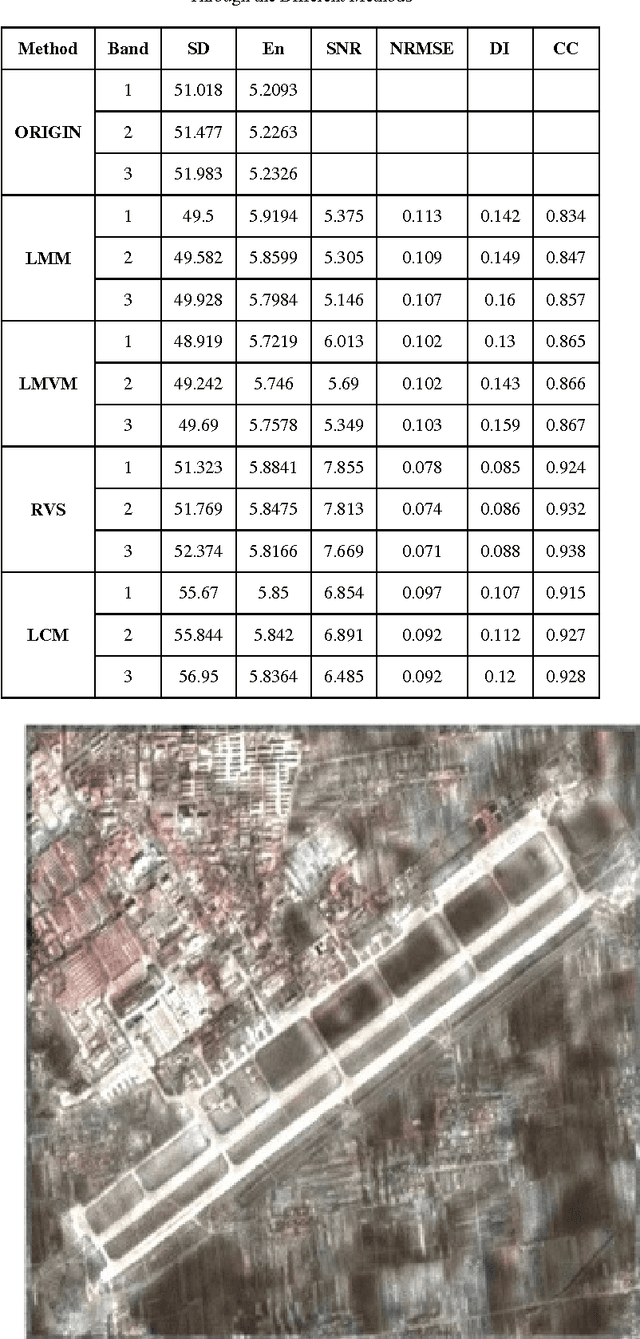
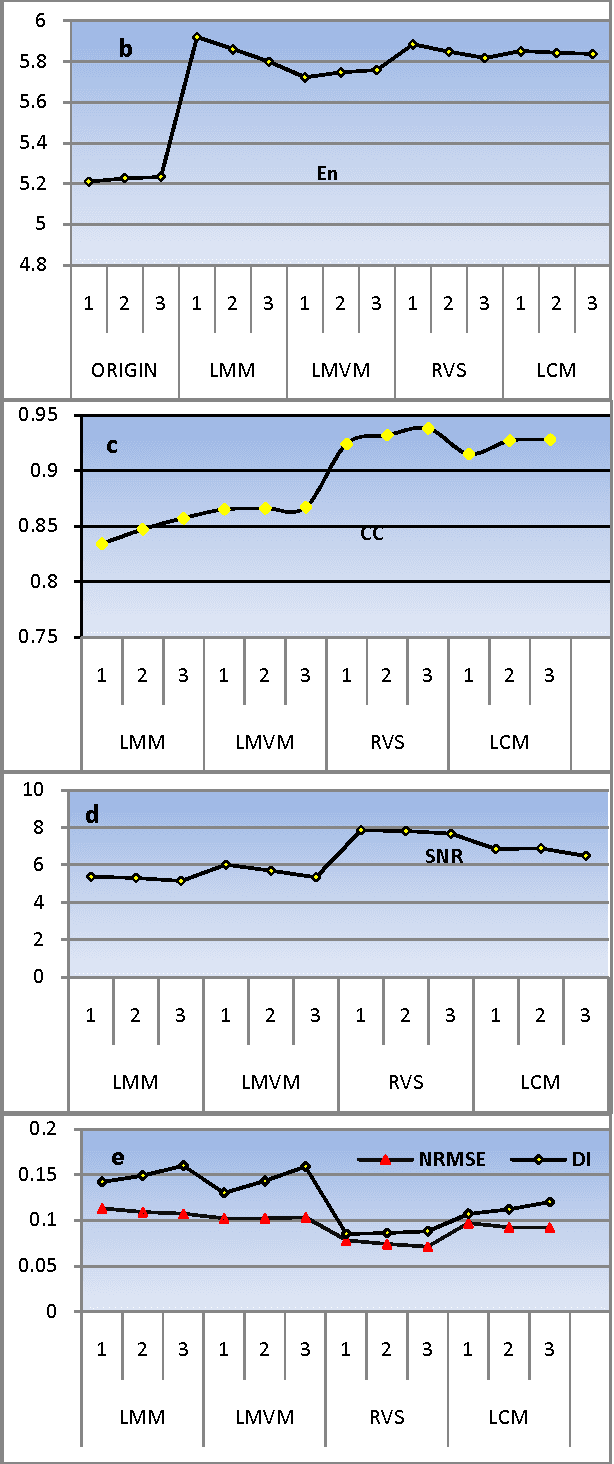
There are many image fusion methods that can be used to produce high-resolution mutlispectral images from a high-resolution panchromatic (PAN) image and low-resolution multispectral (MS) of remote sensed images. This paper attempts to undertake the study of image fusion techniques with different Statistical techniques for image fusion as Local Mean Matching (LMM), Local Mean and Variance Matching (LMVM), Regression variable substitution (RVS), Local Correlation Modeling (LCM) and they are compared with one another so as to choose the best technique, that can be applied on multi-resolution satellite images. This paper also devotes to concentrate on the analytical techniques for evaluating the quality of image fusion (F) by using various methods including Standard Deviation (SD), Entropy(En), Correlation Coefficient (CC), Signal-to Noise Ratio (SNR), Normalization Root Mean Square Error (NRMSE) and Deviation Index (DI) to estimate the quality and degree of information improvement of a fused image quantitatively.
* Keywords: Data Fusion, Resolution Enhancement, Statistical fusion, Correlation Modeling, Matching, pixel based fusion
Deep End-to-End Alignment and Refinement for Time-of-Flight RGB-D Module
Sep 17, 2019
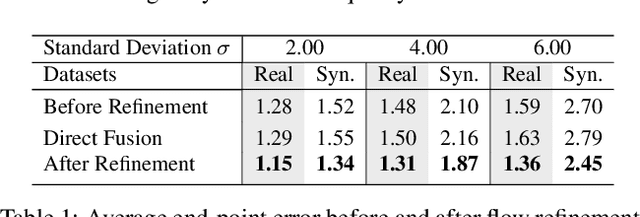
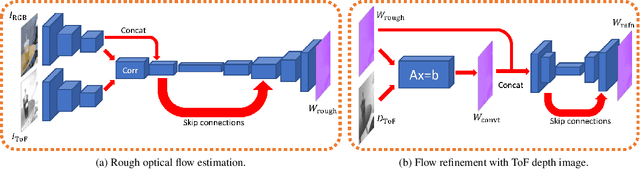
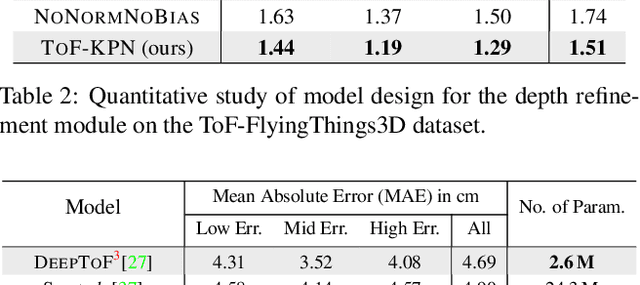
Recently, it is increasingly popular to equip mobile RGB cameras with Time-of-Flight (ToF) sensors for active depth sensing. However, for off-the-shelf ToF sensors, one must tackle two problems in order to obtain high-quality depth with respect to the RGB camera, namely 1) online calibration and alignment; and 2) complicated error correction for ToF depth sensing. In this work, we propose a framework for jointly alignment and refinement via deep learning. First, a cross-modal optical flow between the RGB image and the ToF amplitude image is estimated for alignment. The aligned depth is then refined via an improved kernel predicting network that performs kernel normalization and applies the bias prior to the dynamic convolution. To enrich our data for end-to-end training, we have also synthesized a dataset using tools from computer graphics. Experimental results demonstrate the effectiveness of our approach, achieving state-of-the-art for ToF refinement.
Local Facial Makeup Transfer via Disentangled Representation
Mar 27, 2020
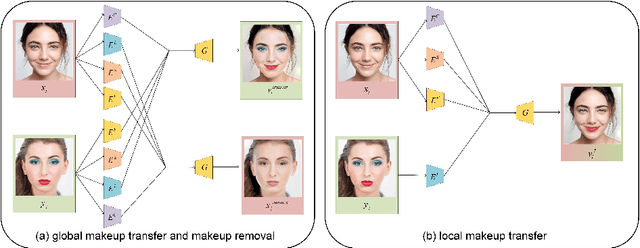
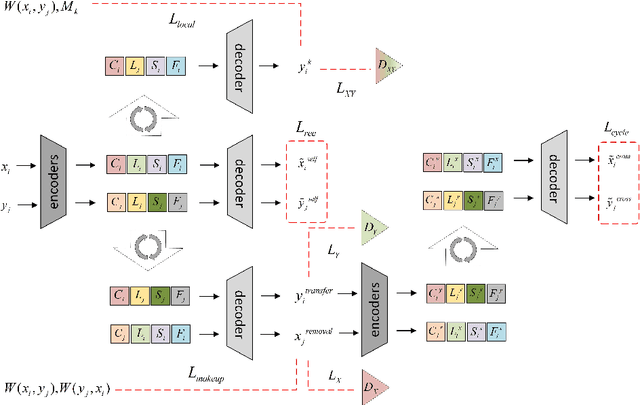

Facial makeup transfer aims to render a non-makeup face image in an arbitrary given makeup one while preserving face identity. The most advanced method separates makeup style information from face images to realize makeup transfer. However, makeup style includes several semantic clear local styles which are still entangled together. In this paper, we propose a novel unified adversarial disentangling network to further decompose face images into four independent components, i.e., personal identity, lips makeup style, eyes makeup style and face makeup style. Owing to the further disentangling of makeup style, our method can not only control the degree of global makeup style, but also flexibly regulate the degree of local makeup styles which any other approaches can't do. For makeup removal, different from other methods which regard makeup removal as the reverse process of makeup, we integrate the makeup transfer with the makeup removal into one uniform framework and obtain multiple makeup removal results. Extensive experiments have demonstrated that our approach can produce more realistic and accurate makeup transfer results compared to the state-of-the-art methods.
Deep Set Prediction Networks
Jun 15, 2019
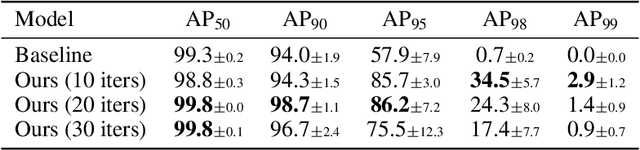
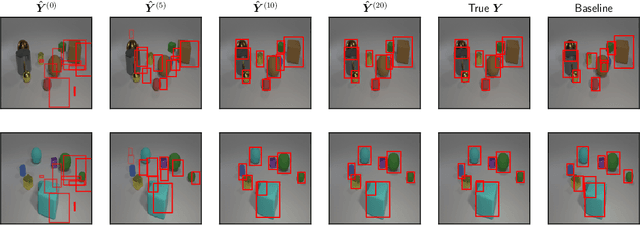
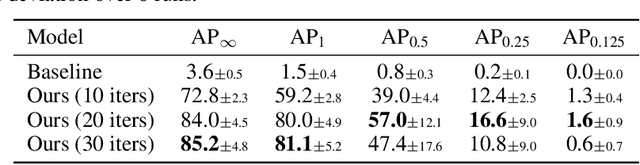
We study the problem of predicting a set from a feature vector with a deep neural network. Existing approaches ignore the set structure of the problem and suffer from discontinuity issues as a result. We propose a general model for predicting sets that properly respects the structure of sets and avoids this problem. With a single feature vector as input, we show that our model is able to auto-encode point sets, predict bounding boxes of the set of objects in an image, and predict the attributes of these objects in an image.
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
May 15, 2019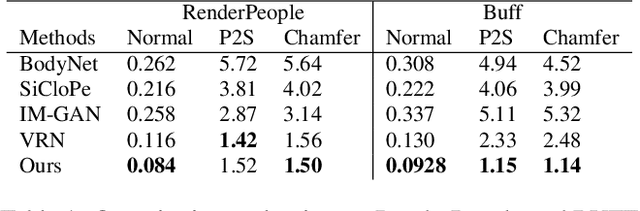
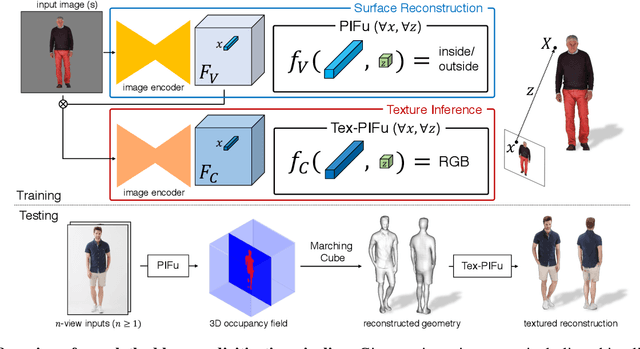

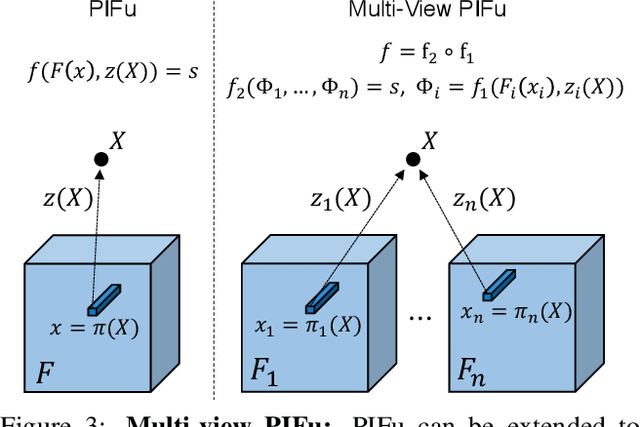
We introduce Pixel-aligned Implicit Function (PIFu), a highly effective implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object. Using PIFu, we propose an end-to-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images. Highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way. Compared to existing representations used for 3D deep learning, PIFu can produce high-resolution surfaces including largely unseen regions such as the back of a person. In particular, it is memory efficient unlike the voxel representation, can handle arbitrary topology, and the resulting surface is spatially aligned with the input image. Furthermore, while previous techniques are designed to process either a single image or multiple views, PIFu extends naturally to arbitrary number of views. We demonstrate high-resolution and robust reconstructions on real world images from the DeepFashion dataset, which contains a variety of challenging clothing types. Our method achieves state-of-the-art performance on a public benchmark and outperforms the prior work for clothed human digitization from a single image.
CenterMask: single shot instance segmentation with point representation
Apr 11, 2020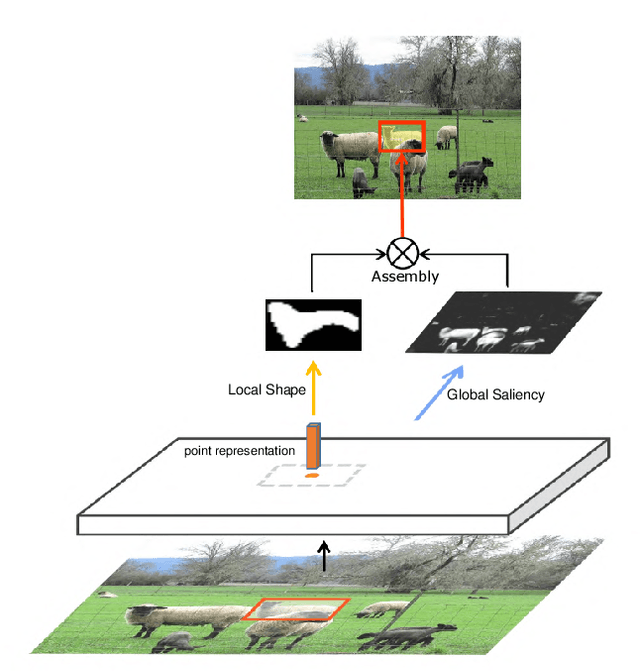


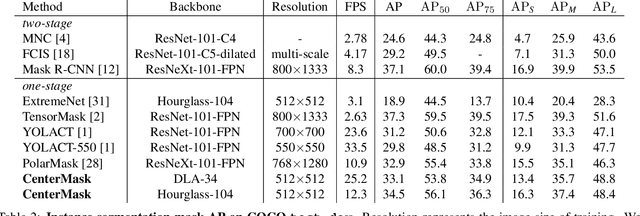
In this paper, we propose a single-shot instance segmentation method, which is simple, fast and accurate. There are two main challenges for one-stage instance segmentation: object instances differentiation and pixel-wise feature alignment. Accordingly, we decompose the instance segmentation into two parallel subtasks: Local Shape prediction that separates instances even in overlapping conditions, and Global Saliency generation that segments the whole image in a pixel-to-pixel manner. The outputs of the two branches are assembled to form the final instance masks. To realize that, the local shape information is adopted from the representation of object center points. Totally trained from scratch and without any bells and whistles, the proposed CenterMask achieves 34.5 mask AP with a speed of 12.3 fps, using a single-model with single-scale training/testing on the challenging COCO dataset. The accuracy is higher than all other one-stage instance segmentation methods except the 5 times slower TensorMask, which shows the effectiveness of CenterMask. Besides, our method can be easily embedded to other one-stage object detectors such as FCOS and performs well, showing the generalization of CenterMask.
Memory Enhanced Global-Local Aggregation for Video Object Detection
Mar 26, 2020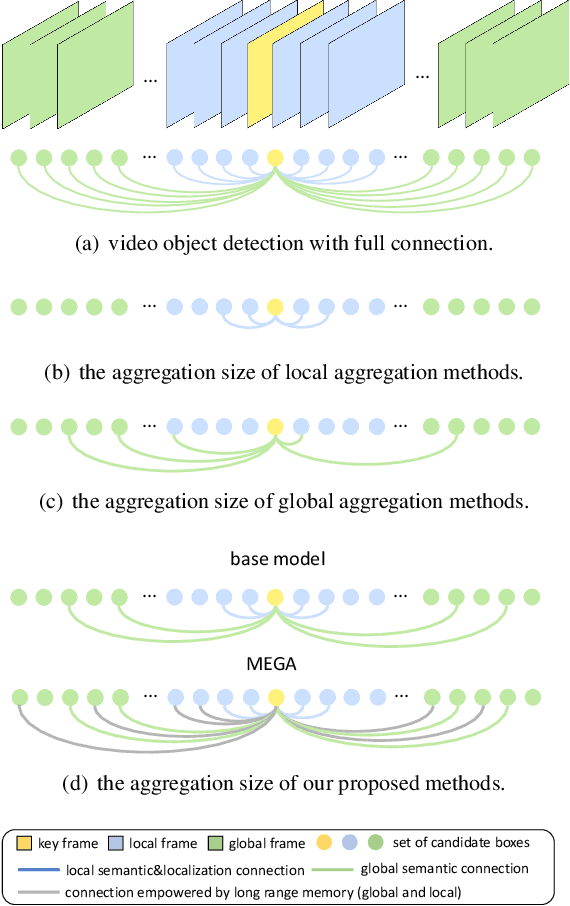
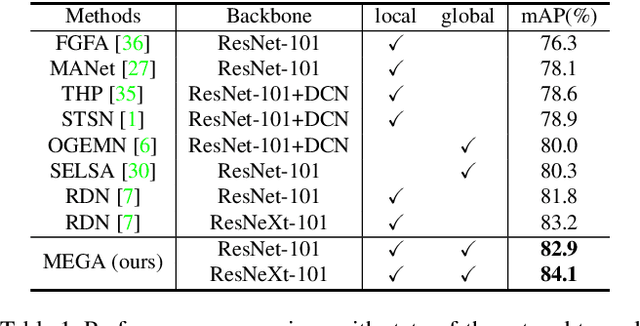
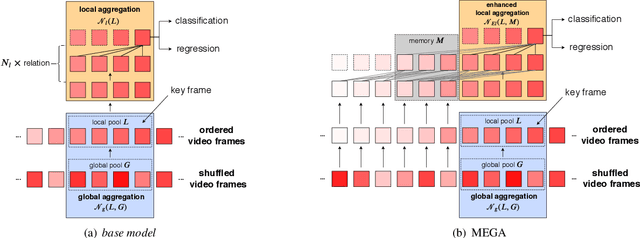
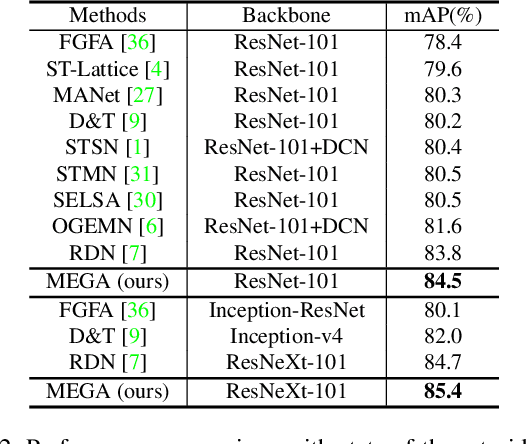
How do humans recognize an object in a piece of video? Due to the deteriorated quality of single frame, it may be hard for people to identify an occluded object in this frame by just utilizing information within one image. We argue that there are two important cues for humans to recognize objects in videos: the global semantic information and the local localization information. Recently, plenty of methods adopt the self-attention mechanisms to enhance the features in key frame with either global semantic information or local localization information. In this paper we introduce memory enhanced global-local aggregation (MEGA) network, which is among the first trials that takes full consideration of both global and local information. Furthermore, empowered by a novel and carefully-designed Long Range Memory (LRM) module, our proposed MEGA could enable the key frame to get access to much more content than any previous methods. Enhanced by these two sources of information, our method achieves state-of-the-art performance on ImageNet VID dataset. Code is available at \url{https://github.com/Scalsol/mega.pytorch}.
Inter-Region Affinity Distillation for Road Marking Segmentation
Apr 11, 2020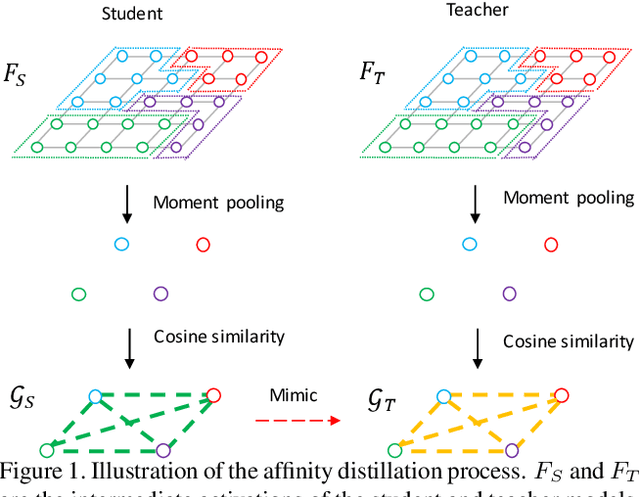
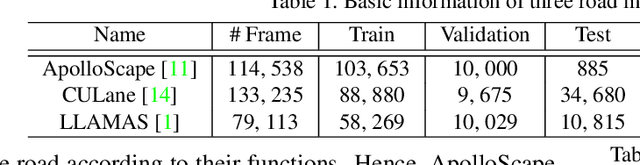
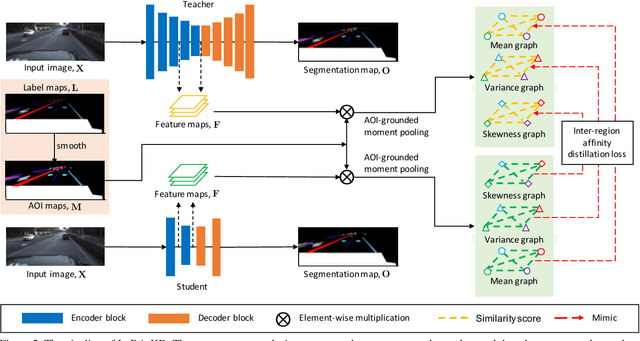
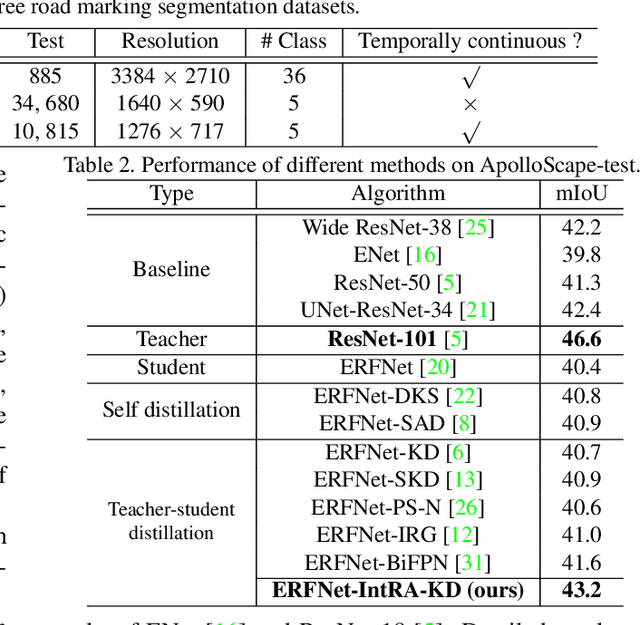
We study the problem of distilling knowledge from a large deep teacher network to a much smaller student network for the task of road marking segmentation. In this work, we explore a novel knowledge distillation (KD) approach that can transfer 'knowledge' on scene structure more effectively from a teacher to a student model. Our method is known as Inter-Region Affinity KD (IntRA-KD). It decomposes a given road scene image into different regions and represents each region as a node in a graph. An inter-region affinity graph is then formed by establishing pairwise relationships between nodes based on their similarity in feature distribution. To learn structural knowledge from the teacher network, the student is required to match the graph generated by the teacher. The proposed method shows promising results on three large-scale road marking segmentation benchmarks, i.e., ApolloScape, CULane and LLAMAS, by taking various lightweight models as students and ResNet-101 as the teacher. IntRA-KD consistently brings higher performance gains on all lightweight models, compared to previous distillation methods. Our code is available at https://github.com/cardwing/Codes-for-IntRA-KD.
$Π-$nets: Deep Polynomial Neural Networks
Mar 26, 2020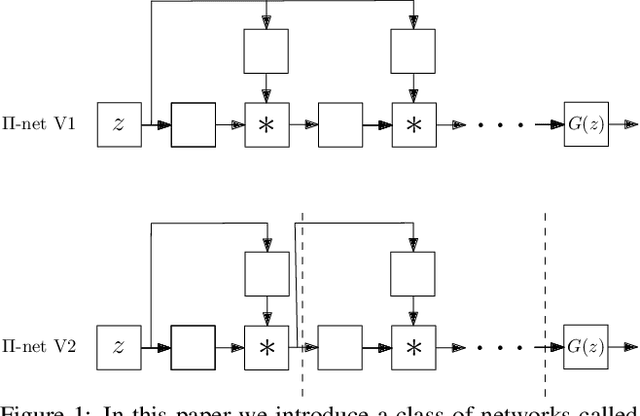
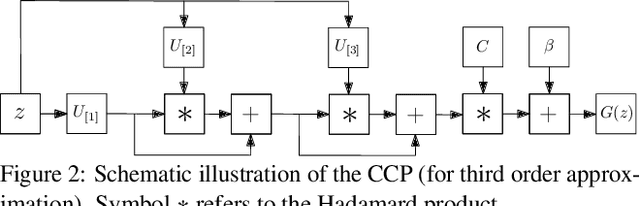
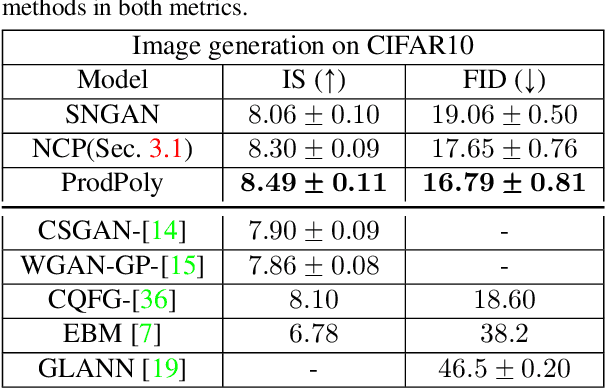
Deep Convolutional Neural Networks (DCNNs) is currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. $\Pi$-Nets can be implemented using special kind of skip connections and their parameters can be represented via high-order tensors. We empirically demonstrate that $\Pi$-Nets have better representation power than standard DCNNs and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in challenging tasks, such as image generation. Lastly, our framework elucidates why recent generative models, such as StyleGAN, improve upon their predecessors, e.g., ProGAN.
Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances
Oct 23, 2019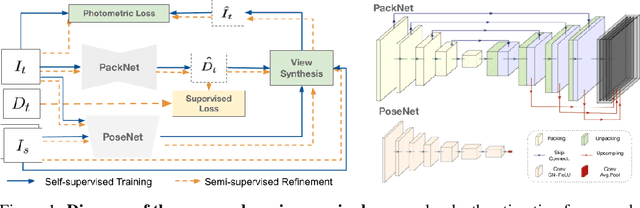
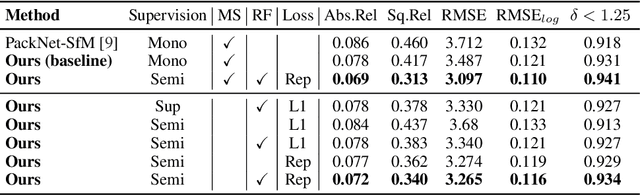
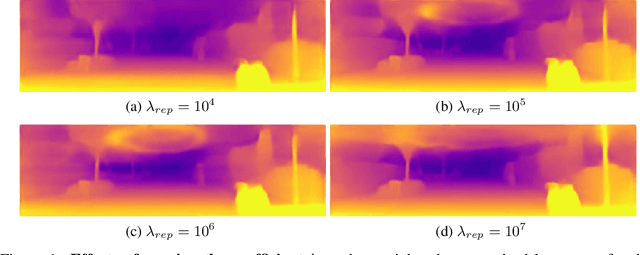
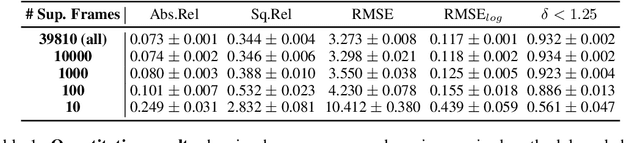
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art.