 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Artifact Disentanglement Network for Unsupervised Metal Artifact Reduction
Jun 06, 2019
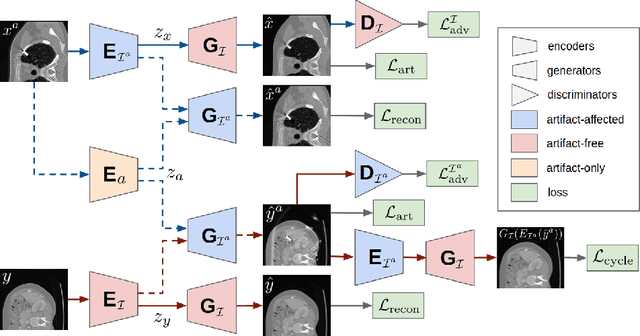
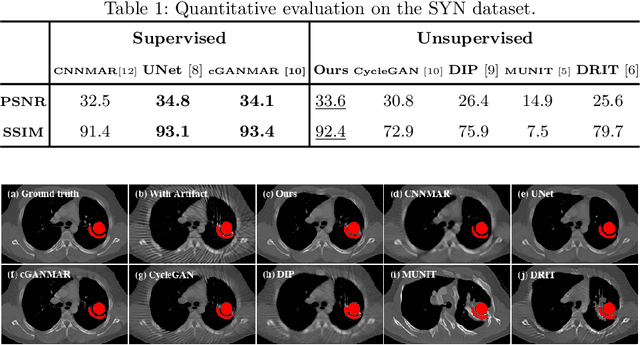
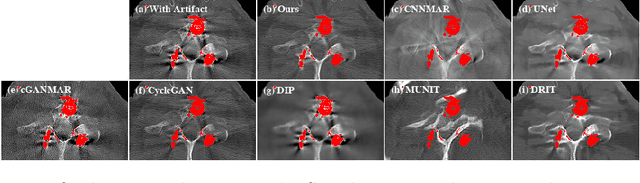
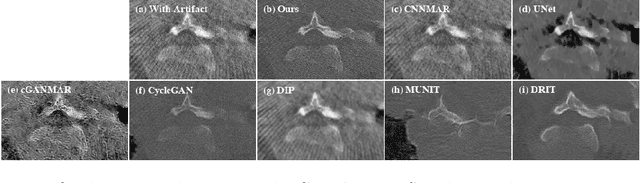
Current deep neural network based approaches to computed tomography (CT) metal artifact reduction (MAR) are supervised methods which rely heavily on synthesized data for training. However, as synthesized data may not perfectly simulate the underlying physical mechanisms of CT imaging, the supervised methods often generalize poorly to clinical applications. To address this problem, we propose, to the best of our knowledge, the first unsupervised learning approach to MAR. Specifically, we introduce a novel artifact disentanglement network that enables different forms of generations and regularizations between the artifact-affected and artifact-free image domains to support unsupervised learning. Extensive experiments show that our method significantly outperforms the existing unsupervised models for image-to-image translation problems, and achieves comparable performance to existing supervised models on a synthesized dataset. When applied to clinical datasets, our method achieves considerable improvements over the supervised models.
TaskNorm: Rethinking Batch Normalization for Meta-Learning
Mar 06, 2020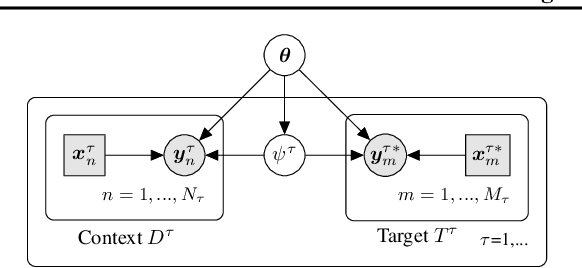

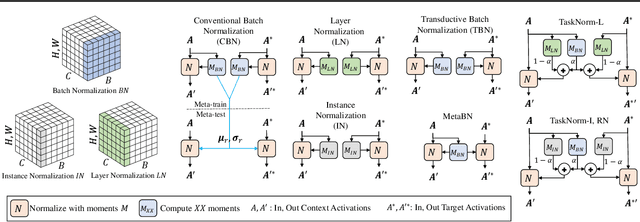
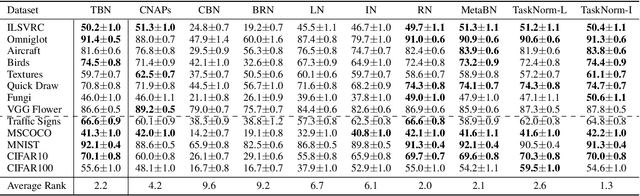
Modern meta-learning approaches for image classification rely on increasingly deep networks to achieve state-of-the-art performance, making batch normalization an essential component of meta-learning pipelines. However, the hierarchical nature of the meta-learning setting presents several challenges that can render conventional batch normalization ineffective, giving rise to the need to rethink normalization in this setting. We evaluate a range of approaches to batch normalization for meta-learning scenarios, and develop a novel approach that we call TaskNorm. Experiments on fourteen datasets demonstrate that the choice of batch normalization has a dramatic effect on both classification accuracy and training time for both gradient based and gradient-free meta-learning approaches. Importantly, TaskNorm is found to consistently improve performance. Finally, we provide a set of best practices for normalization that will allow fair comparison of meta-learning algorithms.
Bending Loss Regularized Network for Nuclei Segmentation in Histopathology Images
Feb 03, 2020
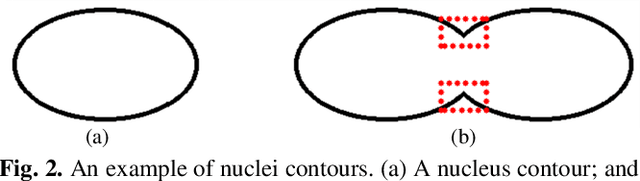
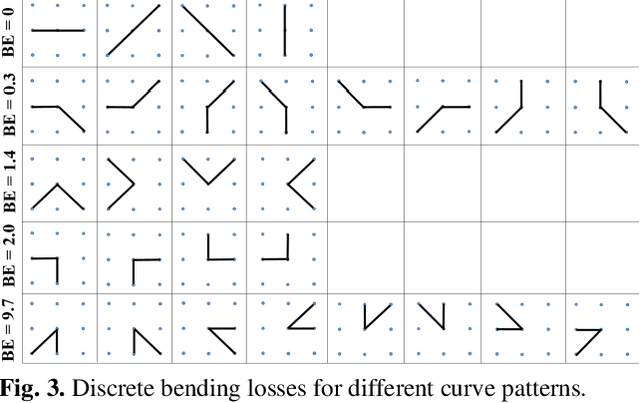
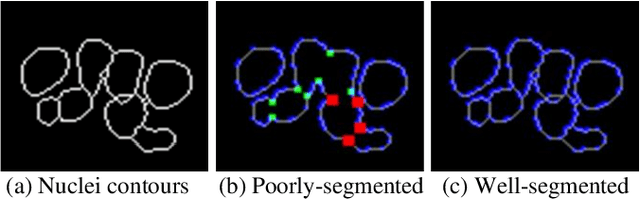
Separating overlapped nuclei is a major challenge in histopathology image analysis. Recently published approaches have achieved promising overall performance on public datasets; however, their performance in segmenting overlapped nuclei are limited. To address the issue, we propose the bending loss regularized network for nuclei segmentation. The proposed bending loss defines high penalties to contour points with large curvatures, and applies small penalties to contour points with small curvature. Minimizing the bending loss can avoid generating contours that encompass multiple nuclei. The proposed approach is validated on the MoNuSeg dataset using five quantitative metrics. It outperforms six state-of-the-art approaches on the following metrics: Aggregate Jaccard Index, Dice, Recognition Quality, and Pan-optic Quality.
Camera Trace Erasing
Mar 16, 2020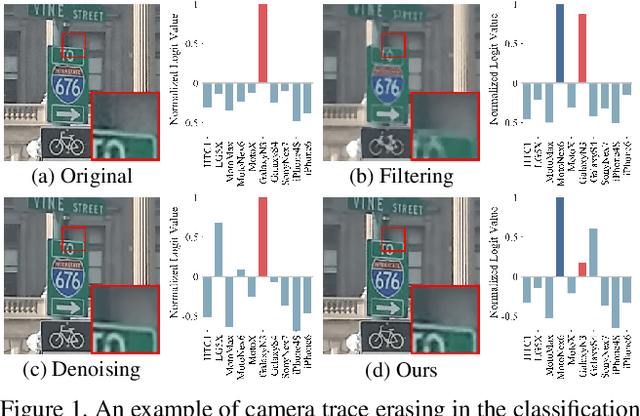
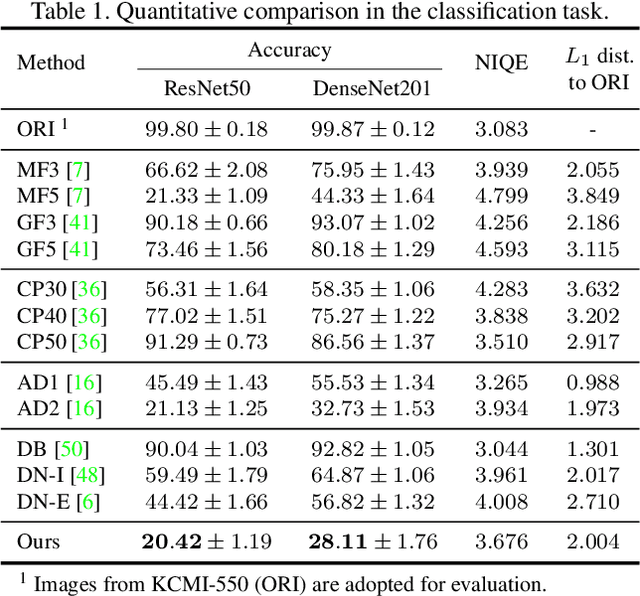
Camera trace is a unique noise produced in digital imaging process. Most existing forensic methods analyze camera trace to identify image origins. In this paper, we address a new low-level vision problem, camera trace erasing, to reveal the weakness of trace-based forensic methods. A comprehensive investigation on existing anti-forensic methods reveals that it is non-trivial to effectively erase camera trace while avoiding the destruction of content signal. To reconcile these two demands, we propose Siamese Trace Erasing (SiamTE), in which a novel hybrid loss is designed on the basis of Siamese architecture for network training. Specifically, we propose embedded similarity, truncated fidelity, and cross identity to form the hybrid loss. Compared with existing anti-forensic methods, SiamTE has a clear advantage for camera trace erasing, which is demonstrated in three representative tasks. Code and dataset are available at https://github.com/ngchc/CameraTE.
Uneven illumination surface defects inspection based on convolutional neural network
May 16, 2019Surface defect inspection based on machine vision is often affected by uneven illumination. In order to improve the inspection rate of surface defects inspection under uneven illumination condition, this paper proposes a method for detecting surface image defects based on convolutional neural network, which is based on the adjustment of convolutional neural networks, training parameters, changing the structure of the network, to achieve the purpose of accurately identifying various defects. Experimental on defect inspection of copper strip and steel images shows that the convolutional neural network can automatically learn features without preprocessing the image, and correct identification of various types of image defects affected by uneven illumination, thus overcoming the drawbacks of traditional machine vision inspection methods under uneven illumination.
Deep Morphological Neural Networks
Sep 04, 2019

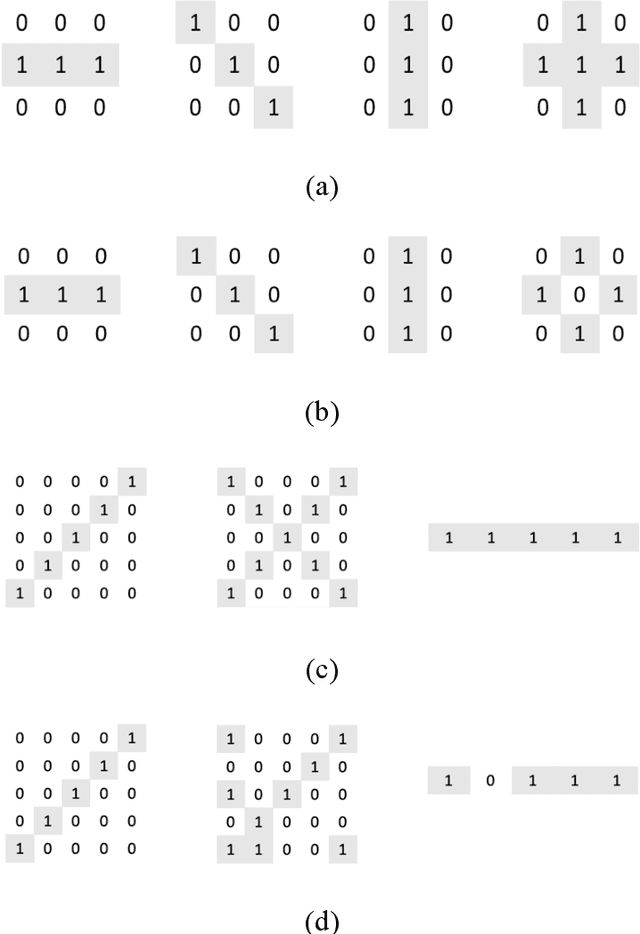
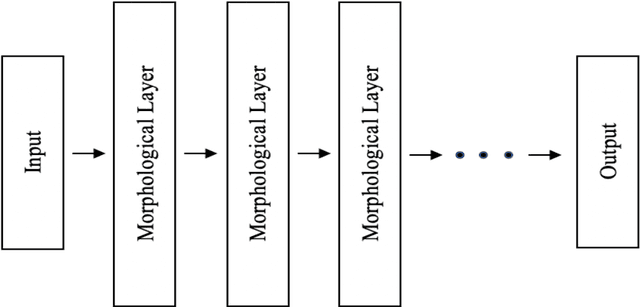
Mathematical morphology is a theory and technique to collect features like geometric and topological structures in digital images. Given a target image, determining suitable morphological operations and structuring elements is a cumbersome and time-consuming task. In this paper, a morphological neural network is proposed to address this problem. Serving as a nonlinear feature extracting layer in deep learning frameworks, the efficiency of the proposed morphological layer is confirmed analytically and empirically. With a known target, a single-filter morphological layer learns the structuring element correctly, and an adaptive layer can automatically select appropriate morphological operations. For practical applications, the proposed morphological neural networks are tested on several classification datasets related to shape or geometric image features, and the experimental results have confirmed the high computational efficiency and high accuracy.
DA-RefineNet:A Dual Input Whole Slide Image Segmentation Algorithm Based on Attention
Jul 23, 2019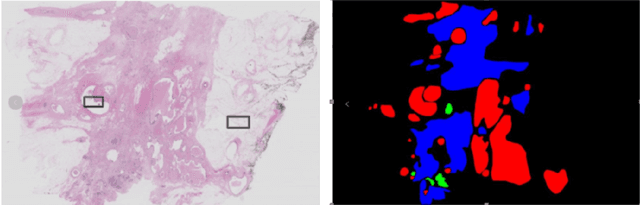
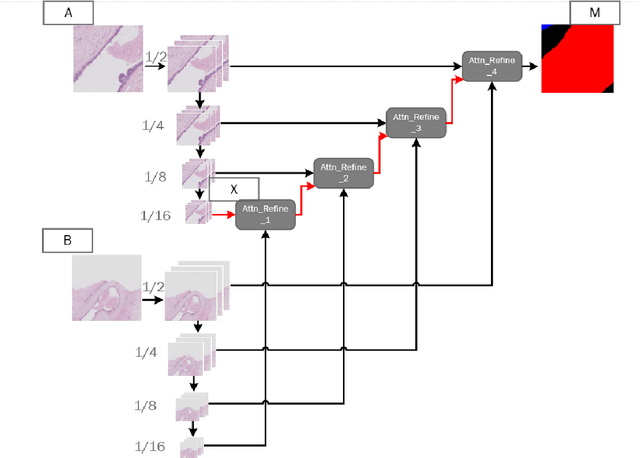
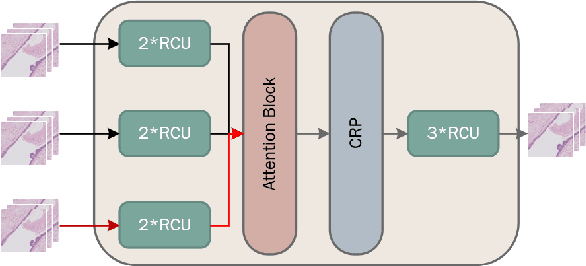
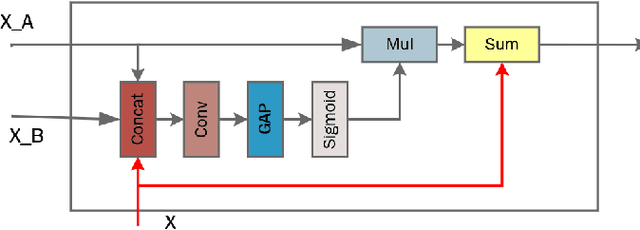
Due to the high resolution of pathological images, the automated semantic segmentation in the medical pathological images has shown greater challenges than that in natural images. Sliding Window method has shown its effect on solving problem caused by the high resolution of whole slide images (WSI). However, owing to its localization, Sliding Window method also suffers from lack of global information. In this paper, a dual input semantic segmentation network based on attention is proposed, in which, one input provides small-scale fine information, the other input provides large-scale coarse information. Compared with single input methods, our method based on dual inputs and attention: DA-RefineNet exhibits a dramatic performance improvement on ICIAR2018 breast cancer segmentation task.
A Mean-Field Theory for Learning the Schönberg Measure of Radial Basis Functions
Jun 23, 2020
We develop and analyze a projected particle Langevin optimization method to learn the distribution in the Sch\"{o}nberg integral representation of the radial basis functions from training samples. More specifically, we characterize a distributionally robust optimization method with respect to the Wasserstein distance to optimize the distribution in the Sch\"{o}nberg integral representation. To provide theoretical performance guarantees, we analyze the scaling limits of a projected particle online (stochastic) optimization method in the mean-field regime. In particular, we prove that in the scaling limits, the empirical measure of the Langevin particles converges to the law of a reflected It\^{o} diffusion-drift process. Moreover, the drift is also a function of the law of the underlying process. Using It\^{o} lemma for semi-martingales and Grisanov's change of measure for the Wiener processes, we then derive a Mckean-Vlasov type partial differential equation (PDE) with Robin boundary conditions that describes the evolution of the empirical measure of the projected Langevin particles in the mean-field regime. In addition, we establish the existence and uniqueness of the steady-state solutions of the derived PDE in the weak sense. We apply our learning approach to train radial kernels in the kernel locally sensitive hash (LSH) functions, where the training data-set is generated via a $k$-mean clustering method on a small subset of data-base. We subsequently apply our kernel LSH with a trained kernel for image retrieval task on MNIST data-set, and demonstrate the efficacy of our kernel learning approach. We also apply our kernel learning approach in conjunction with the kernel support vector machines (SVMs) for classification of benchmark data-sets.
Robot Object Retrieval with Contextual Natural Language Queries
Jun 23, 2020
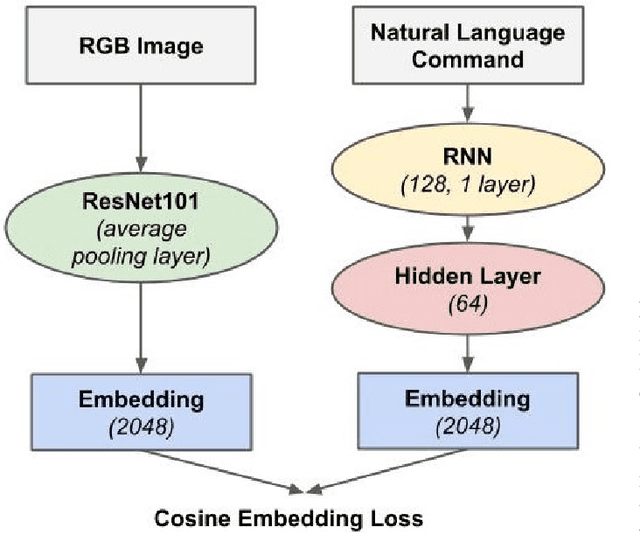
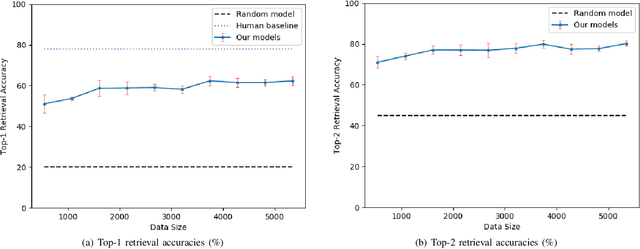

Natural language object retrieval is a highly useful yet challenging task for robots in human-centric environments. Previous work has primarily focused on commands specifying the desired object's type such as "scissors" and/or visual attributes such as "red," thus limiting the robot to only known object classes. We develop a model to retrieve objects based on descriptions of their usage. The model takes in a language command containing a verb, for example "Hand me something to cut," and RGB images of candidate objects and selects the object that best satisfies the task specified by the verb. Our model directly predicts an object's appearance from the object's use specified by a verb phrase. We do not need to explicitly specify an object's class label. Our approach allows us to predict high level concepts like an object's utility based on the language query. Based on contextual information present in the language commands, our model can generalize to unseen object classes and unknown nouns in the commands. Our model correctly selects objects out of sets of five candidates to fulfill natural language commands, and achieves an average accuracy of 62.3% on a held-out test set of unseen ImageNet object classes and 53.0% on unseen object classes and unknown nouns. Our model also achieves an average accuracy of 54.7% on unseen YCB object classes, which have a different image distribution from ImageNet objects. We demonstrate our model on a KUKA LBR iiwa robot arm, enabling the robot to retrieve objects based on natural language descriptions of their usage. We also present a new dataset of 655 verb-object pairs denoting object usage over 50 verbs and 216 object classes.
Global Wheat Head Detection (GWHD) dataset: a large and diverse dataset of high resolution RGB labelled images to develop and benchmark wheat head detection methods
Apr 25, 2020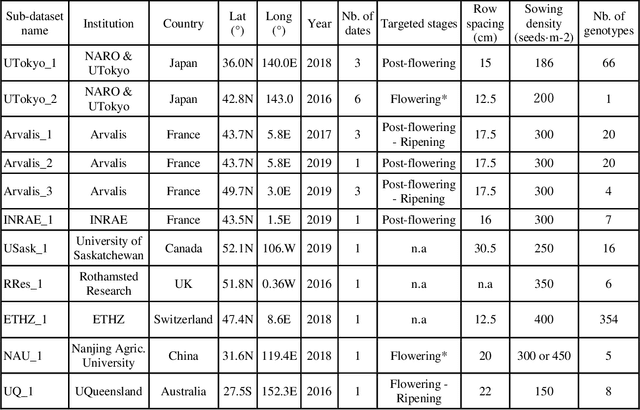

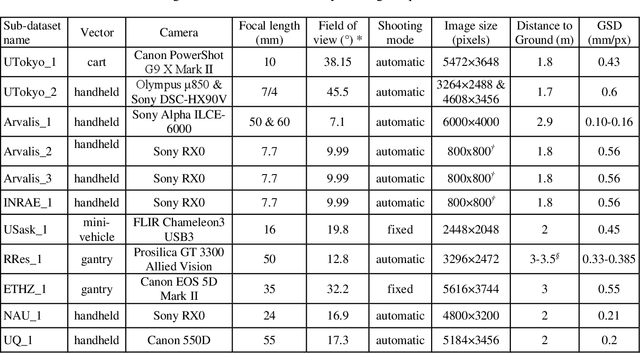

Detection of wheat heads is an important task allowing to estimate pertinent traits including head population density and head characteristics such as sanitary state, size, maturity stage and the presence of awns. Several studies developed methods for wheat head detection from high-resolution RGB imagery. They are based on computer vision and machine learning and are generally calibrated and validated on limited datasets. However, variability in observational conditions, genotypic differences, development stages, head orientation represents a challenge in computer vision. Further, possible blurring due to motion or wind and overlap between heads for dense populations make this task even more complex. Through a joint international collaborative effort, we have built a large, diverse and well-labelled dataset, the Global Wheat Head detection (GWHD) dataset. It contains 4,700 high-resolution RGB images and 190,000 labelled wheat heads collected from several countries around the world at different growth stages with a wide range of genotypes. Guidelines for image acquisition, associating minimum metadata to respect FAIR principles and consistent head labelling methods are proposed when developing new head detection datasets. The GWHD is publicly available at http://www.global-wheat.com/ and aimed at developing and benchmarking methods for wheat head detection.