 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FMT:Fusing Multi-task Convolutional Neural Network for Person Search
Mar 01, 2020
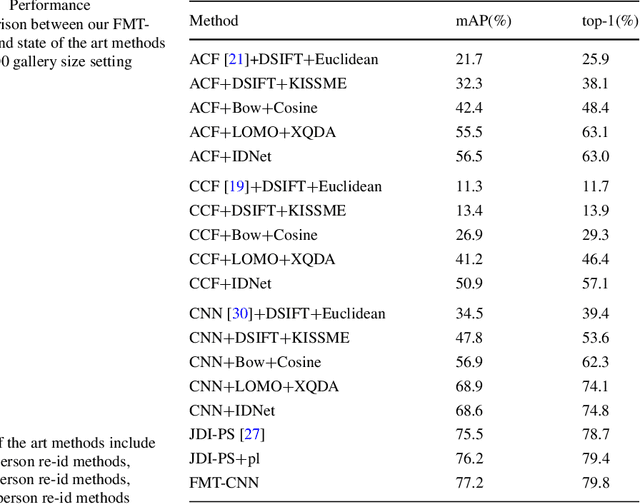
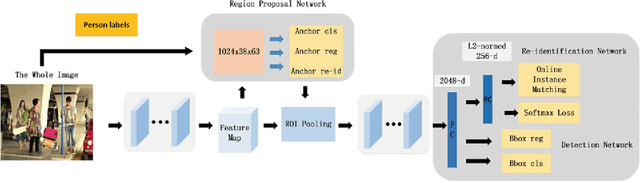
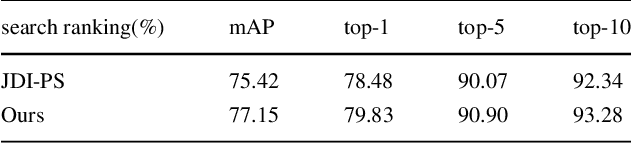
Person search is to detect all persons and identify the query persons from detected persons in the image without proposals and bounding boxes, which is different from person re-identification. In this paper, we propose a fusing multi-task convolutional neural network(FMT-CNN) to tackle the correlation and heterogeneity of detection and re-identification with a single convolutional neural network. We focus on how the interplay of person detection and person re-identification affects the overall performance. We employ person labels in region proposal network to produce features for person re-identification and person detection network, which can improve the accuracy of detection and re-identification simultaneously. We also use a multiple loss to train our re-identification network. Experiment results on CUHK-SYSU Person Search dataset show that the performance of our proposed method is superior to state-of-the-art approaches in both mAP and top-1.
Local Facial Makeup Transfer via Disentangled Representation
Mar 27, 2020
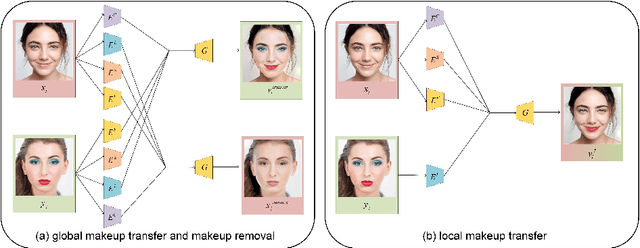
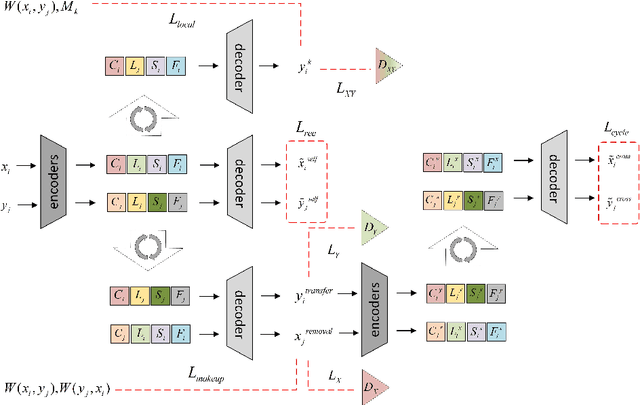

Facial makeup transfer aims to render a non-makeup face image in an arbitrary given makeup one while preserving face identity. The most advanced method separates makeup style information from face images to realize makeup transfer. However, makeup style includes several semantic clear local styles which are still entangled together. In this paper, we propose a novel unified adversarial disentangling network to further decompose face images into four independent components, i.e., personal identity, lips makeup style, eyes makeup style and face makeup style. Owing to the further disentangling of makeup style, our method can not only control the degree of global makeup style, but also flexibly regulate the degree of local makeup styles which any other approaches can't do. For makeup removal, different from other methods which regard makeup removal as the reverse process of makeup, we integrate the makeup transfer with the makeup removal into one uniform framework and obtain multiple makeup removal results. Extensive experiments have demonstrated that our approach can produce more realistic and accurate makeup transfer results compared to the state-of-the-art methods.
Fast Fourier Color Constancy and Grayness Index for ISPA Illumination Estimation Challenge
Sep 17, 2019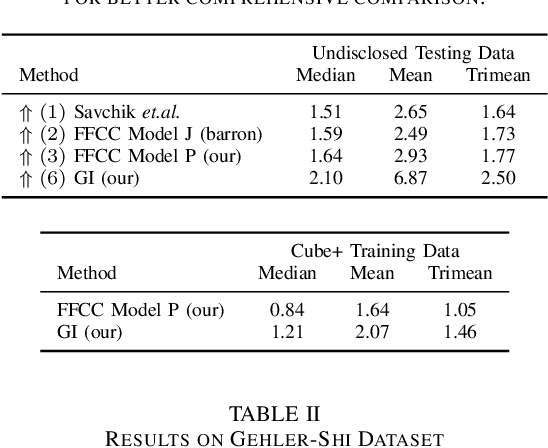

We briefly introduce two submissions to the Illumination Estimation Challenge, in the Int'l Workshop on Color Vision, affiliated to the 11th Int'l Symposium on Image and Signal Processing and Analysis. The Fourier-transform-based submission is ranked 3rd, and the statistical Gray-pixel-based one ranked 6th.
Image Compression and Watermarking scheme using Scalar Quantization
Mar 29, 2010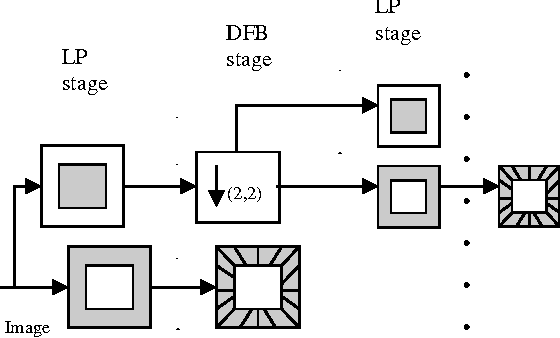
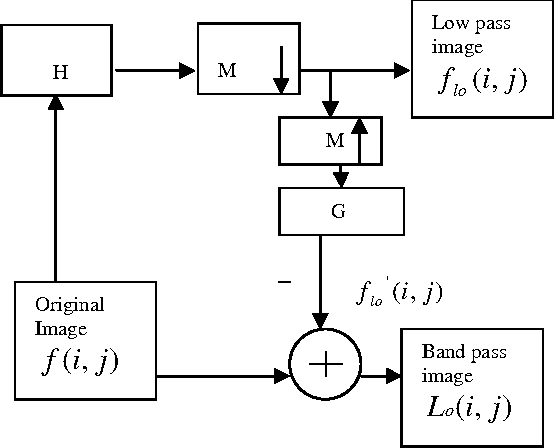
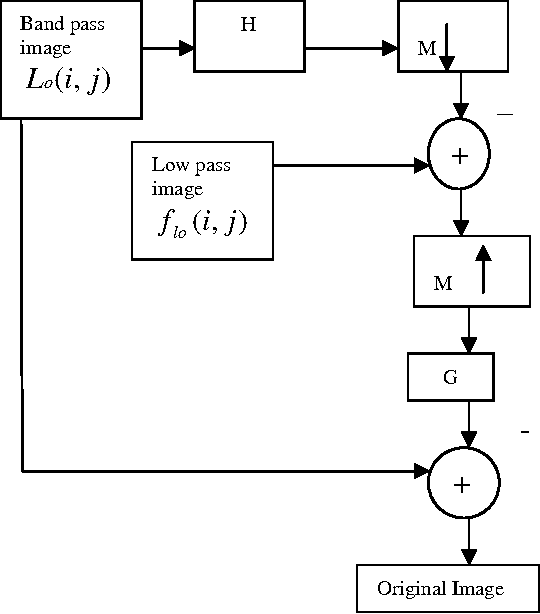
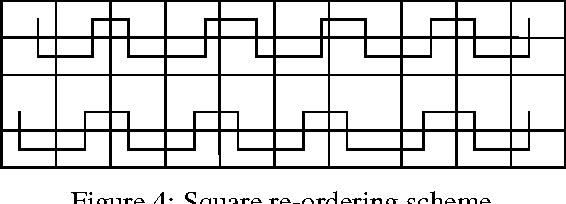
This paper presents a new compression technique and image watermarking algorithm based on Contourlet Transform (CT). For image compression, an energy based quantization is used. Scalar quantization is explored for image watermarking. Double filter bank structure is used in CT. The Laplacian Pyramid (LP) is used to capture the point discontinuities, and then followed by a Directional Filter Bank (DFB) to link point discontinuities. The coefficients of down sampled low pass version of LP decomposed image are re-ordered in a pre-determined manner and prediction algorithm is used to reduce entropy (bits/pixel). In addition, the coefficients of CT are quantized based on the energy in the particular band. The superiority of proposed algorithm to JPEG is observed in terms of reduced blocking artifacts. The results are also compared with wavelet transform (WT). Superiority of CT to WT is observed when the image contains more contours. The watermark image is embedded in the low pass image of contourlet decomposition. The watermark can be extracted with minimum error. In terms of PSNR, the visual quality of the watermarked image is exceptional. The proposed algorithm is robust to many image attacks and suitable for copyright protection applications.
* 11 Pages, IJNGN Journal 2010
Learning Body Shape and Pose from Dense Correspondences
Jul 27, 2019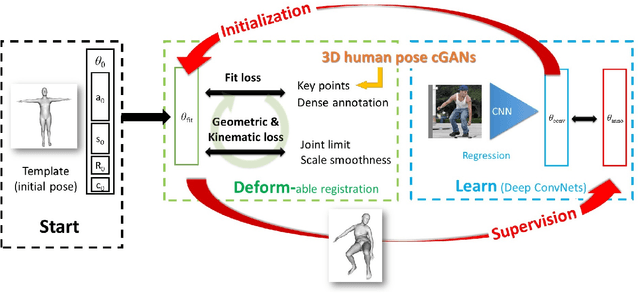

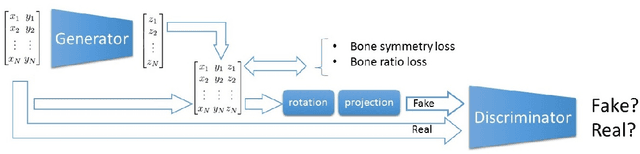

In this paper, we address the problem of learning 3D human pose and body shape from 2D image dataset, without having to use 3D dataset (body shape and pose). The idea is to use dense correspondences between image points and a body surface, which can be annotated on in-the wild 2D images, and extract and aggregate 3D information from them. To do so, we propose a training strategy called ``deform-and-learn" where we alternate deformable surface registration and training of deep convolutional neural networks (ConvNets). Unlike previous approaches, our method does not require 3D pose annotations from a motion capture (MoCap) system or human intervention to validate 3D pose annotations.
CenterMask: single shot instance segmentation with point representation
Apr 11, 2020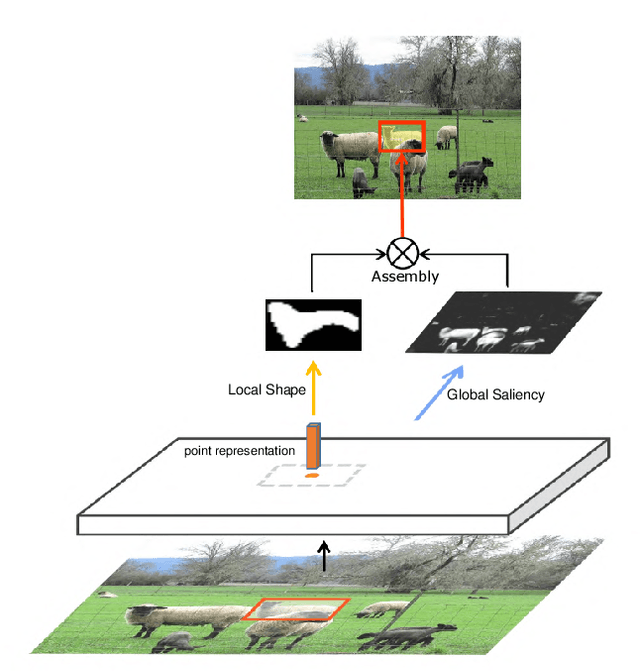


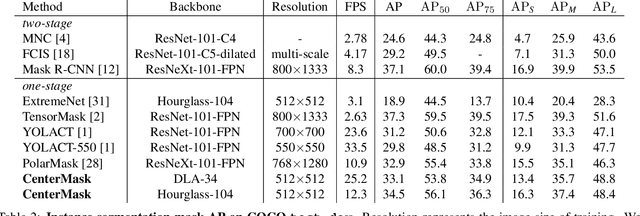
In this paper, we propose a single-shot instance segmentation method, which is simple, fast and accurate. There are two main challenges for one-stage instance segmentation: object instances differentiation and pixel-wise feature alignment. Accordingly, we decompose the instance segmentation into two parallel subtasks: Local Shape prediction that separates instances even in overlapping conditions, and Global Saliency generation that segments the whole image in a pixel-to-pixel manner. The outputs of the two branches are assembled to form the final instance masks. To realize that, the local shape information is adopted from the representation of object center points. Totally trained from scratch and without any bells and whistles, the proposed CenterMask achieves 34.5 mask AP with a speed of 12.3 fps, using a single-model with single-scale training/testing on the challenging COCO dataset. The accuracy is higher than all other one-stage instance segmentation methods except the 5 times slower TensorMask, which shows the effectiveness of CenterMask. Besides, our method can be easily embedded to other one-stage object detectors such as FCOS and performs well, showing the generalization of CenterMask.
Semantic Relatedness Based Re-ranker for Text Spotting
Sep 19, 2019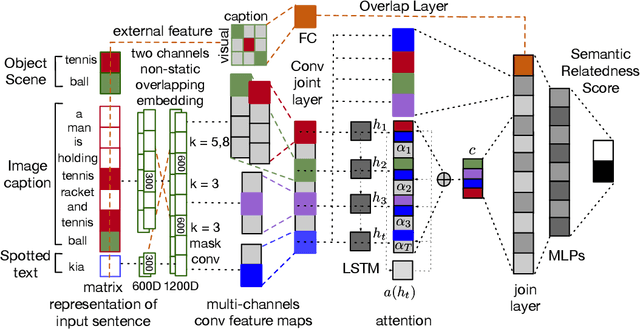
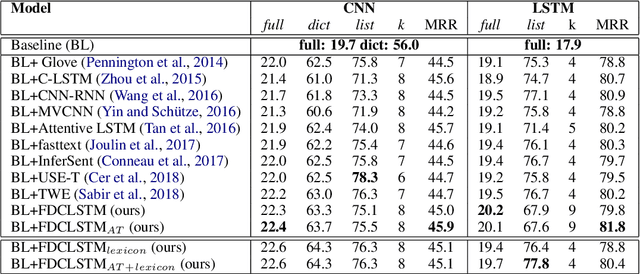
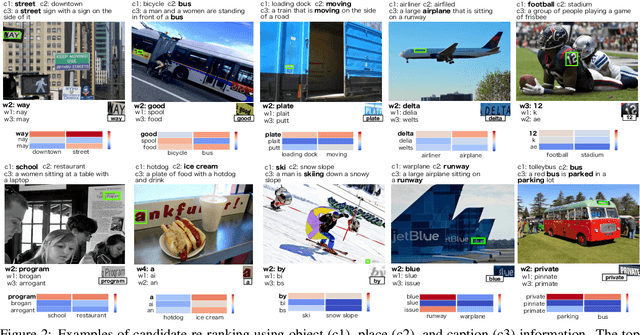
Applications such as textual entailment, plagiarism detection or document clustering rely on the notion of semantic similarity, and are usually approached with dimension reduction techniques like LDA or with embedding-based neural approaches. We present a scenario where semantic similarity is not enough, and we devise a neural approach to learn semantic relatedness. The scenario is text spotting in the wild, where a text in an image (e.g. street sign, advertisement or bus destination) must be identified and recognized. Our goal is to improve the performance of vision systems by leveraging semantic information. Our rationale is that the text to be spotted is often related to the image context in which it appears (word pairs such as Delta-airplane, or quarters-parking are not similar, but are clearly related). We show how learning a word-to-word or word-to-sentence relatedness score can improve the performance of text spotting systems up to 2.9 points, outperforming other measures in a benchmark dataset.
Inter-Region Affinity Distillation for Road Marking Segmentation
Apr 11, 2020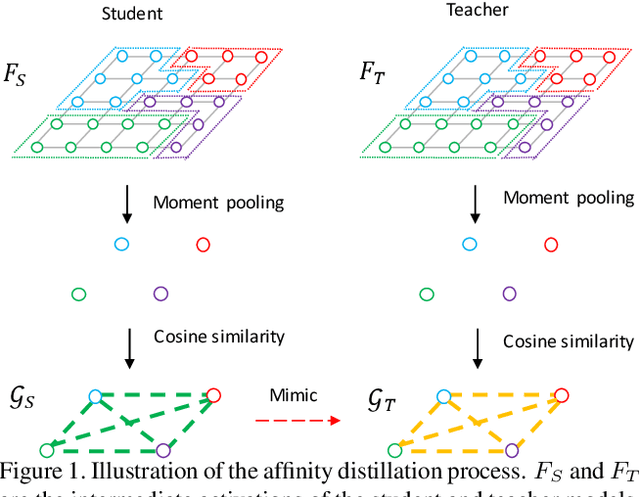
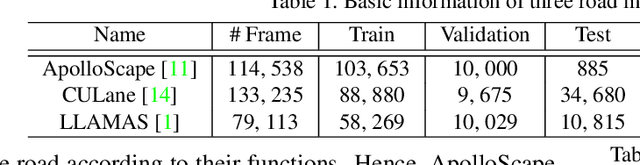
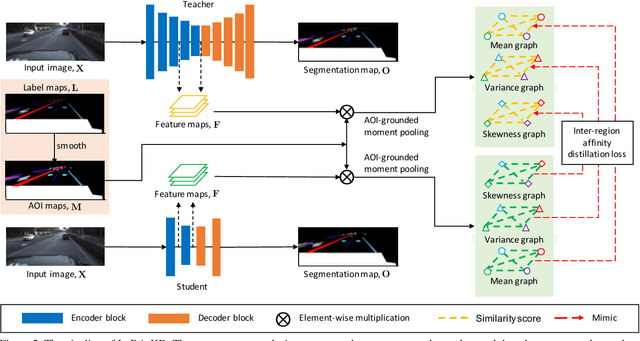
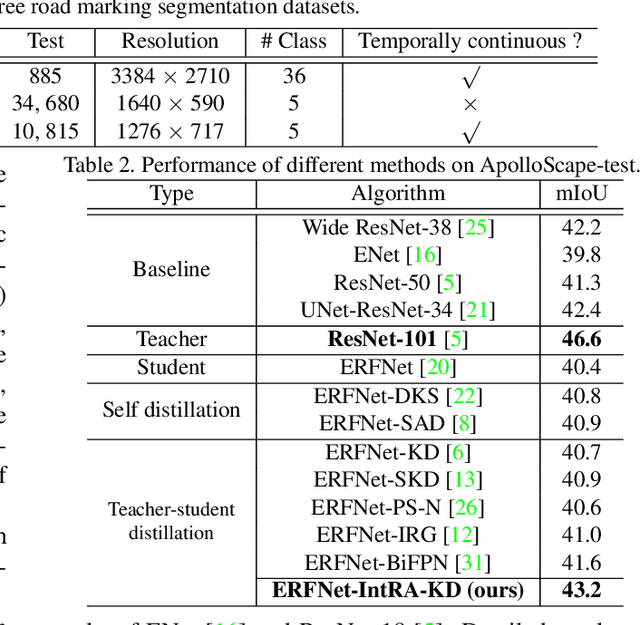
We study the problem of distilling knowledge from a large deep teacher network to a much smaller student network for the task of road marking segmentation. In this work, we explore a novel knowledge distillation (KD) approach that can transfer 'knowledge' on scene structure more effectively from a teacher to a student model. Our method is known as Inter-Region Affinity KD (IntRA-KD). It decomposes a given road scene image into different regions and represents each region as a node in a graph. An inter-region affinity graph is then formed by establishing pairwise relationships between nodes based on their similarity in feature distribution. To learn structural knowledge from the teacher network, the student is required to match the graph generated by the teacher. The proposed method shows promising results on three large-scale road marking segmentation benchmarks, i.e., ApolloScape, CULane and LLAMAS, by taking various lightweight models as students and ResNet-101 as the teacher. IntRA-KD consistently brings higher performance gains on all lightweight models, compared to previous distillation methods. Our code is available at https://github.com/cardwing/Codes-for-IntRA-KD.
Deep convolutional neural networks for face and iris presentation attack detection: Survey and case study
Apr 25, 2020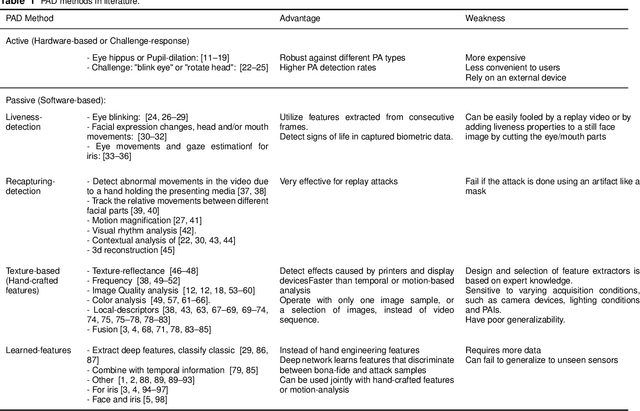

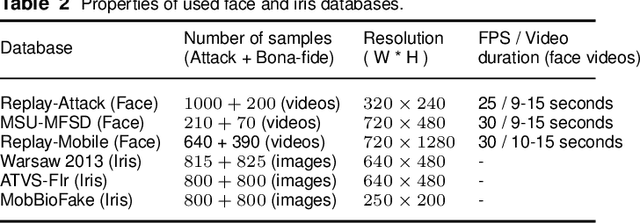

Biometric presentation attack detection is gaining increasing attention. Users of mobile devices find it more convenient to unlock their smart applications with finger, face or iris recognition instead of passwords. In this paper, we survey the approaches presented in the recent literature to detect face and iris presentation attacks. Specifically, we investigate the effectiveness of fine tuning very deep convolutional neural networks to the task of face and iris antispoofing. We compare two different fine tuning approaches on six publicly available benchmark datasets. Results show the effectiveness of these deep models in learning discriminative features that can tell apart real from fake biometric images with very low error rate. Cross-dataset evaluation on face PAD showed better generalization than state of the art. We also performed cross-dataset testing on iris PAD datasets in terms of equal error rate which was not reported in literature before. Additionally, we propose the use of a single deep network trained to detect both face and iris attacks. We have not noticed accuracy degradation compared to networks trained for only one biometric separately. Finally, we analyzed the learned features by the network, in correlation with the image frequency components, to justify its prediction decision.
Satellite Pose Estimation with Deep Landmark Regression and Nonlinear Pose Refinement
Aug 30, 2019
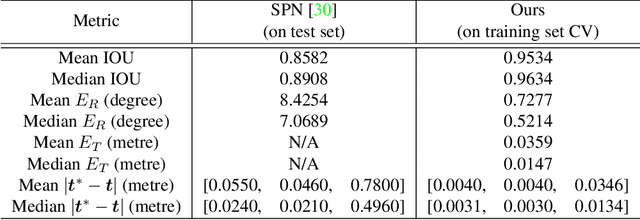
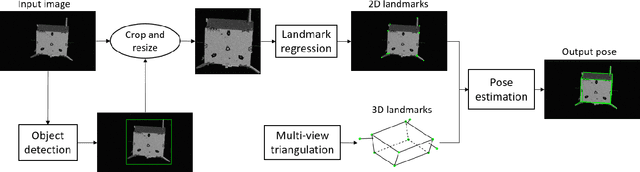

We propose an approach to estimate the 6DOF pose of a satellite, relative to a canonical pose, from a single image. Such a problem is crucial in many space proximity operations, such as docking, debris removal, and inter-spacecraft communications. Our approach combines machine learning and geometric optimisation, by predicting the coordinates of a set of landmarks in the input image, associating the landmarks to their corresponding 3D points on an a priori reconstructed 3D model, then solving for the object pose using non-linear optimisation. Our approach is not only novel for this specific pose estimation task, which helps to further open up a relatively new domain for machine learning and computer vision, but it also demonstrates superior accuracy and won the first place in the recent Kelvins Pose Estimation Challenge organised by the European Space Agency (ESA).