 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Approach to Develop a New Hybrid Technique for Trademark Image Retrieval
Nov 08, 2014
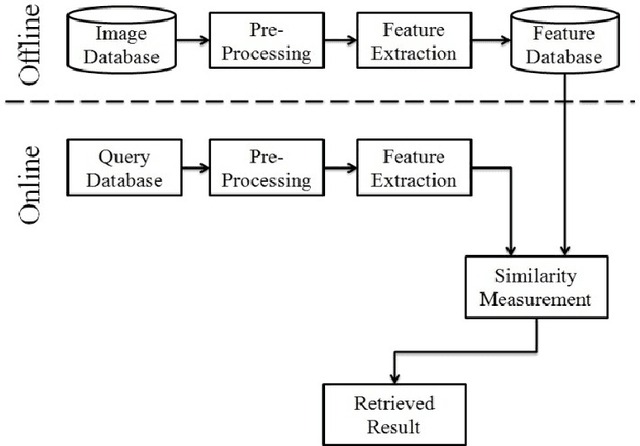
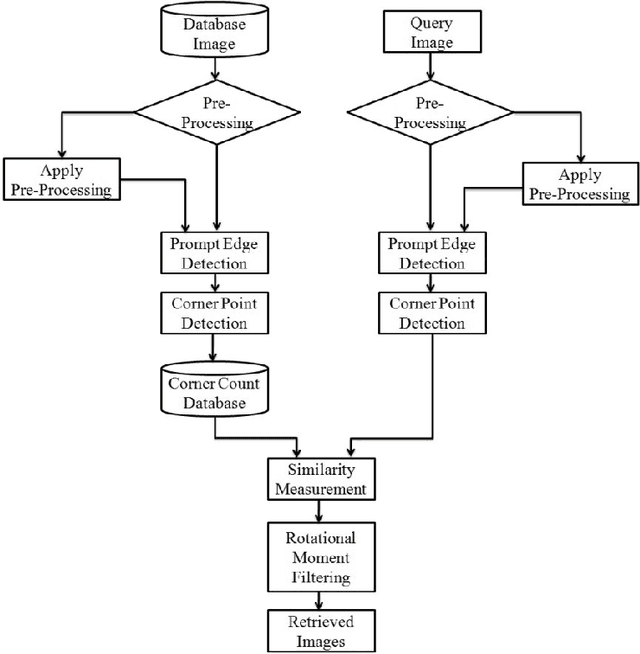
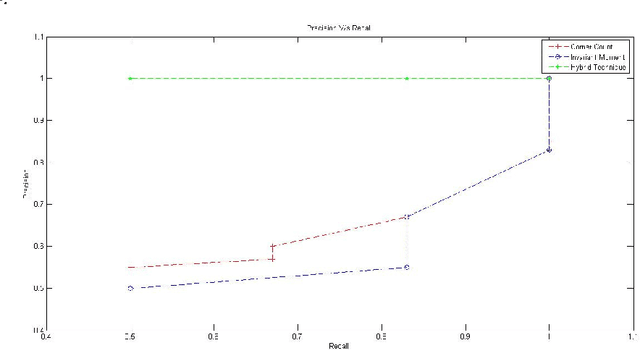
Trademark Image Retrieval is playing a vital role as a part of CBIR System. Trademark is of great significance because it carries the status value of any company. To retrieve such a fake or copied trademark we design a retrieval system which is based on hybrid techniques. It contains a mixture of two different feature vector which combined together to give a suitable retrieval system. In the proposed system we extract the corner feature which is applied on an edge pixel image. This feature is used to extract the relevant image and to more purify the result we apply other feature which is the invariant moment feature. From the experimental result we conclude that the system is 85 percent efficient.
Image Compression and Watermarking scheme using Scalar Quantization
Mar 29, 2010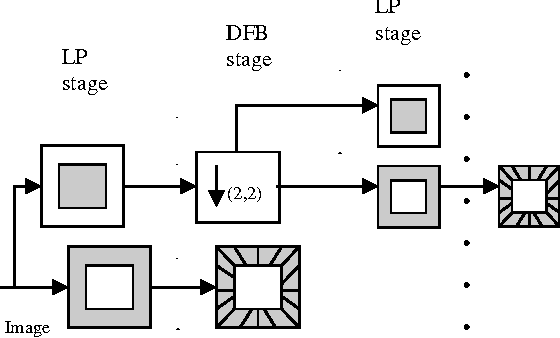
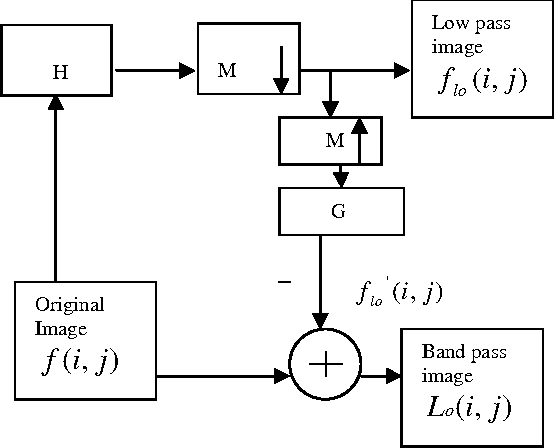
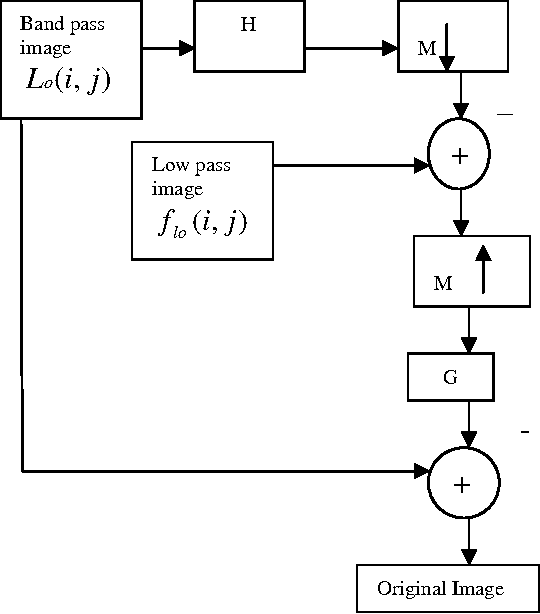
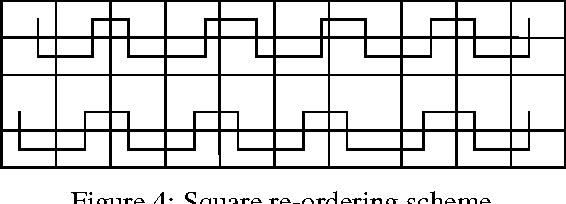
This paper presents a new compression technique and image watermarking algorithm based on Contourlet Transform (CT). For image compression, an energy based quantization is used. Scalar quantization is explored for image watermarking. Double filter bank structure is used in CT. The Laplacian Pyramid (LP) is used to capture the point discontinuities, and then followed by a Directional Filter Bank (DFB) to link point discontinuities. The coefficients of down sampled low pass version of LP decomposed image are re-ordered in a pre-determined manner and prediction algorithm is used to reduce entropy (bits/pixel). In addition, the coefficients of CT are quantized based on the energy in the particular band. The superiority of proposed algorithm to JPEG is observed in terms of reduced blocking artifacts. The results are also compared with wavelet transform (WT). Superiority of CT to WT is observed when the image contains more contours. The watermark image is embedded in the low pass image of contourlet decomposition. The watermark can be extracted with minimum error. In terms of PSNR, the visual quality of the watermarked image is exceptional. The proposed algorithm is robust to many image attacks and suitable for copyright protection applications.
* 11 Pages, IJNGN Journal 2010
Resolution Enhancement of Range Images via Color-Image Segmentation
Oct 28, 2012


We report a method for super-resolution of range images. Our approach leverages the interpretation of LR image as sparse samples on the HR grid. Based on this interpretation, we demonstrate that our recently reported approach, which reconstructs dense range images from sparse range data by exploiting a registered colour image, can be applied for the task of resolution enhancement of range images. Our method only uses a single colour image in addition to the range observation in the super-resolution process. Using the proposed approach, we demonstrate super-resolution results for large factors (e.g. 4) with good localization accuracy.
Stochasticity in Neural ODEs: An Empirical Study
Feb 22, 2020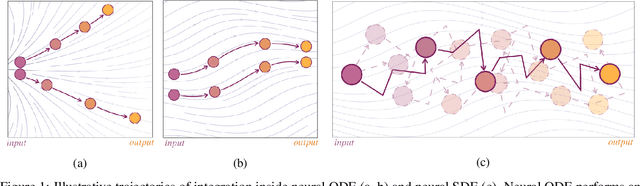
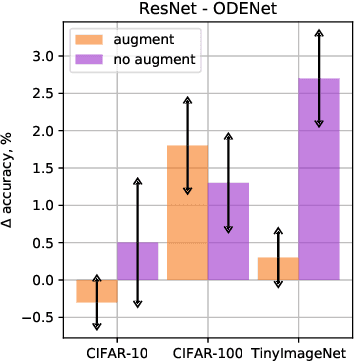
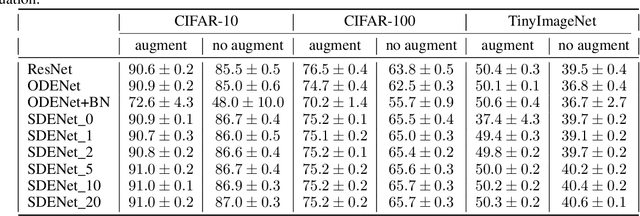
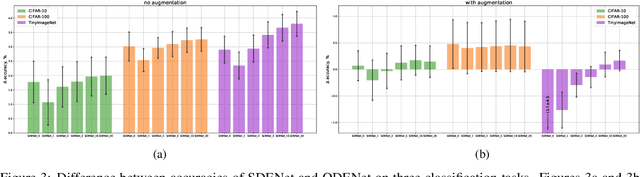
Stochastic regularization of neural networks (e.g. dropout) is a wide-spread technique in deep learning that allows for better generalization. Despite its success, continuous-time models, such as neural ordinary differential equation (ODE), usually rely on a completely deterministic feed-forward operation. This work provides an empirical study of stochastically regularized neural ODE on several image-classification tasks (CIFAR-10, CIFAR-100, TinyImageNet). Building upon the formalism of stochastic differential equations (SDEs), we demonstrate that neural SDE is able to outperform its deterministic counterpart. Further, we show that data augmentation during the training improves the performance of both deterministic and stochastic versions of the same model. However, the improvements obtained by the data augmentation completely eliminate the empirical gains of the stochastic regularization, making the difference in the performance of neural ODE and neural SDE negligible.
Event-based visual place recognition with ensembles of spatio-temporal windows
May 22, 2020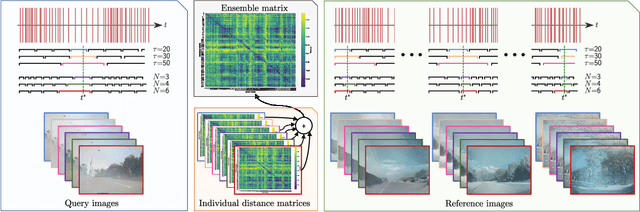


Event cameras are bio-inspired sensors capable of providing a continuous stream of events with low latency and high dynamic range. As a single event only carries limited information about the brightness change at a particular pixel, events are commonly accumulated into spatio-temporal windows for further processing. However, the optimal window length varies depending on the scene, camera motion, the task being performed, and other factors. In this research, we develop a novel ensemble-based scheme for combining spatio-temporal windows of varying lengths that are processed in parallel. For applications where the increased computational requirements of this approach are not practical, we also introduce a new "approximate" ensemble scheme that achieves significant computational efficiencies without unduly compromising the original performance gains provided by the ensemble approach. We demonstrate our ensemble scheme on the visual place recognition (VPR) task, introducing a new Brisbane-Event-VPR dataset with annotated recordings captured using a DAVIS346 color event camera. We show that our proposed ensemble scheme significantly outperforms all the single-window baselines and conventional model-based ensembles, irrespective of the image reconstruction and feature extraction methods used in the VPR pipeline, and evaluate which ensemble combination technique performs best. These results demonstrate the significant benefits of ensemble schemes for event camera processing in the VPR domain and may have relevance to other related processes, including feature tracking, visual-inertial odometry, and steering prediction in driving.
Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
May 22, 2020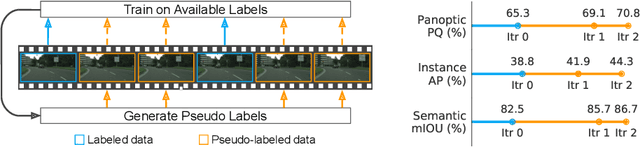

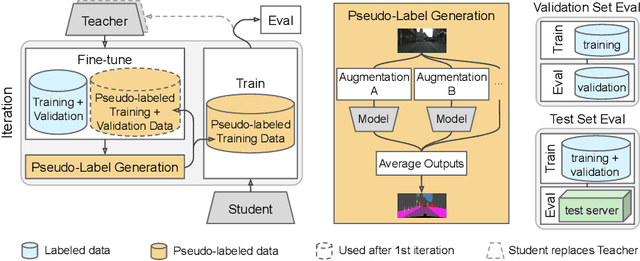
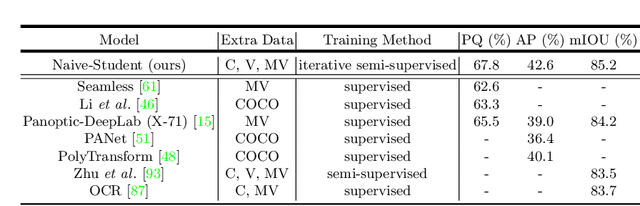
Supervised learning in large discriminative models is a mainstay for modern computer vision. Such an approach necessitates investing in large-scale human-annotated datasets for achieving state-of-the-art results. In turn, the efficacy of supervised learning may be limited by the size of the human annotated dataset. This limitation is particularly notable for image segmentation tasks, where the expense of human annotation is especially large, yet large amounts of unlabeled data may exist. In this work, we ask if we may leverage semi-supervised learning in unlabeled video sequences to improve the performance on urban scene segmentation, simultaneously tackling semantic, instance, and panoptic segmentation. The goal of this work is to avoid the construction of sophisticated, learned architectures specific to label propagation (e.g., patch matching and optical flow). Instead, we simply predict pseudo-labels for the unlabeled data and train subsequent models with both human-annotated and pseudo-labeled data. The procedure is iterated for several times. As a result, our Naive-Student model, trained with such simple yet effective iterative semi-supervised learning, attains state-of-the-art results at all three Cityscapes benchmarks, reaching the performance of 67.8% PQ, 42.6% AP, and 85.2% mIOU on the test set. We view this work as a notable step towards building a simple procedure to harness unlabeled video sequences to surpass state-of-the-art performance on core computer vision tasks.
Speak2Label: Using Domain Knowledge for Creating a Large Scale Driver Gaze Zone Estimation Dataset
Apr 13, 2020

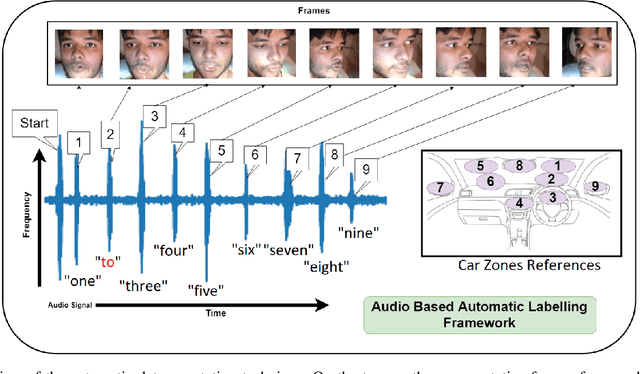
Labelling of human behavior analysis data is a complex and time consuming task. In this paper, a fully automatic technique for labelling an image based gaze behavior dataset for driver gaze zone estimation is proposed. Domain knowledge can be added to the data recording paradigm and later labels can be generated in an automatic manner using speech to text conversion. In order to remove the noise in STT due to different ethnicity, the speech frequency and energy are analysed. The resultant Driver Gaze in the Wild DGW dataset contains 586 recordings, captured during different times of the day including evening. The large scale dataset contains 338 subjects with an age range of 18-63 years. As the data is recorded in different lighting conditions, an illumination robust layer is proposed in the Convolutional Neural Network (CNN). The extensive experiments show the variance in the database resembling real-world conditions and the effectiveness of the proposed CNN pipeline. The proposed network is also fine-tuned for the eye gaze prediction task, which shows the discriminativeness of the representation learnt by our network on the proposed DGW dataset.
On learning optimized reaction diffusion processes for effective image restoration
Mar 25, 2015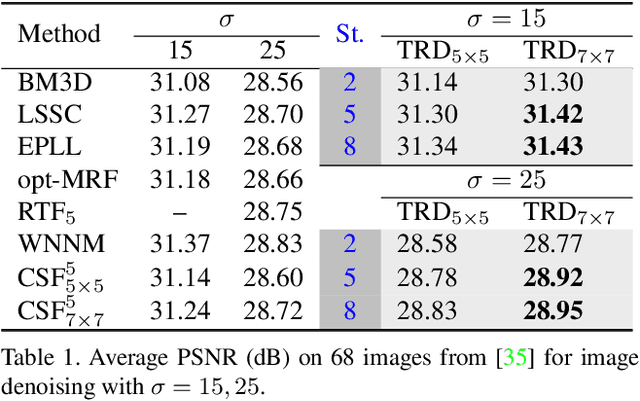

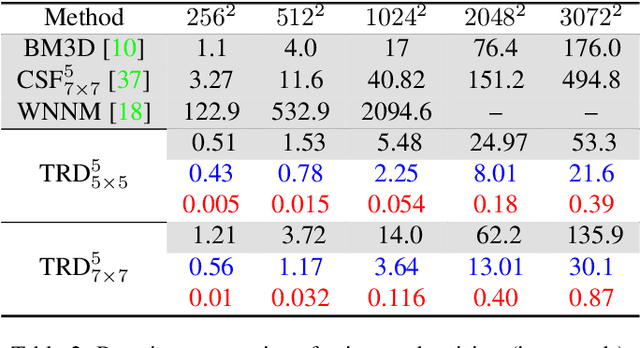
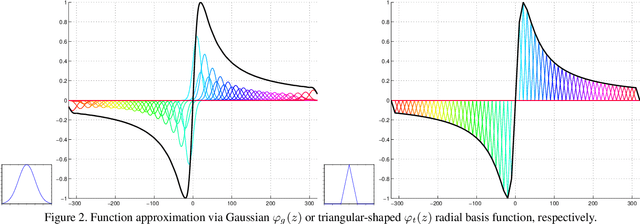
For several decades, image restoration remains an active research topic in low-level computer vision and hence new approaches are constantly emerging. However, many recently proposed algorithms achieve state-of-the-art performance only at the expense of very high computation time, which clearly limits their practical relevance. In this work, we propose a simple but effective approach with both high computational efficiency and high restoration quality. We extend conventional nonlinear reaction diffusion models by several parametrized linear filters as well as several parametrized influence functions. We propose to train the parameters of the filters and the influence functions through a loss based approach. Experiments show that our trained nonlinear reaction diffusion models largely benefit from the training of the parameters and finally lead to the best reported performance on common test datasets for image restoration. Due to their structural simplicity, our trained models are highly efficient and are also well-suited for parallel computation on GPUs.
Leveraging Auxiliary Text for Deep Recognition of Unseen Visual Relationships
Oct 27, 2019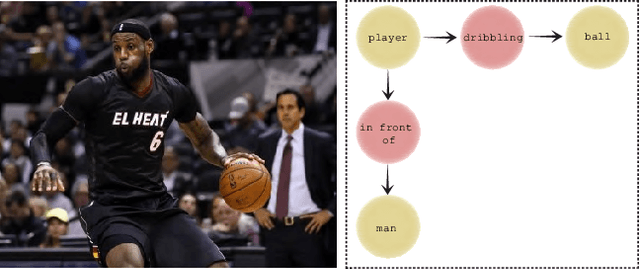
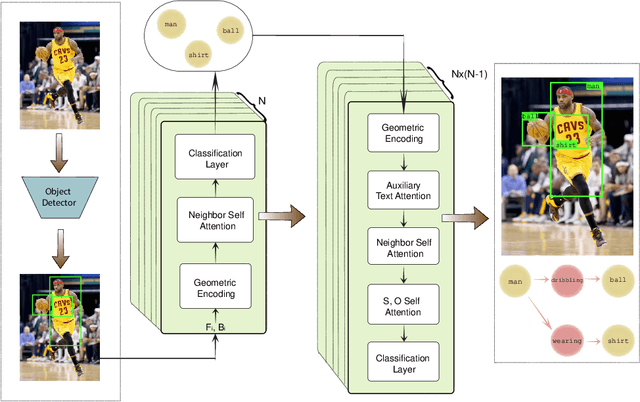
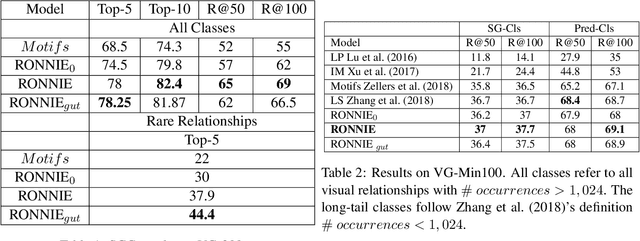
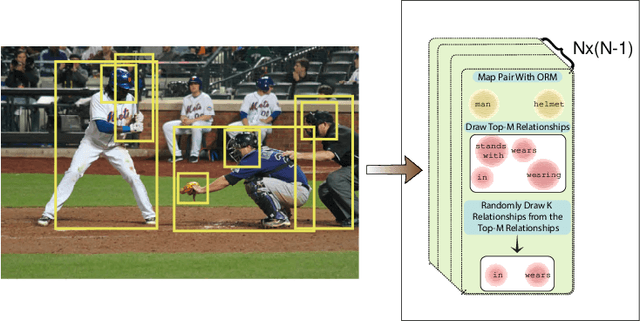
One of the most difficult tasks in scene understanding is recognizing interactions between objects in an image. This task is often called visual relationship detection (VRD). We consider the question of whether, given auxiliary textual data in addition to the standard visual data used for training VRD models, VRD performance can be improved. We present a new deep model that can leverage additional textual data. Our model relies on a shared text--image representation of subject-verb-object relationships appearing in the text, and object interactions in images. Our method is the first to enable recognition of visual relationships missing in the visual training data and appearing only in the auxiliary text. We test our approach on two different text sources: text originating in images and text originating in books. We test and validate our approach using two large-scale recognition tasks: VRD and Scene Graph Generation. We show a surprising result: Our approach works better with text originating in books, and outperforms the text originating in images on the task of unseen relationship recognition. It is comparable to the model which utilizes text originating in images on the task of seen relationship recognition.
Lossless Compression of Deep Neural Networks
Feb 22, 2020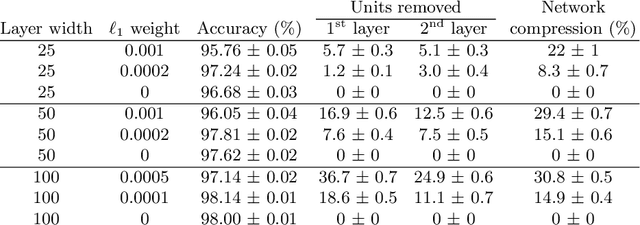

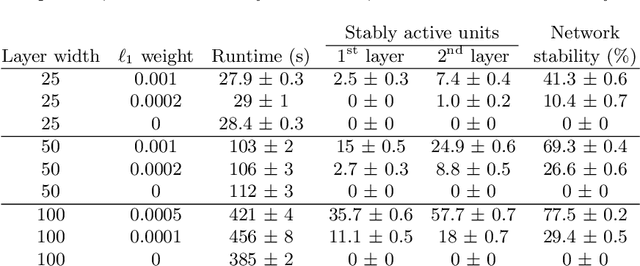
Deep neural networks have been successful in many predictive modeling tasks, such as image and language recognition, where large neural networks are often used to obtain good accuracy. Consequently, it is challenging to deploy these networks under limited computational resources, such as in mobile devices. In this work, we introduce an algorithm that removes units and layers of a neural network while not changing the output that is produced, which thus implies a lossless compression. This algorithm, which we denote as LEO (Lossless Expressiveness Optimization), relies on Mixed-Integer Linear Programming (MILP) to identify Rectified Linear Units (ReLUs) with linear behavior over the input domain. By using L1 regularization to induce such behavior, we can benefit from training over a larger architecture than we would later use in the environment where the trained neural network is deployed.