 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Relevant-features based Auxiliary Cells for Energy Efficient Detection of Natural Errors
Feb 26, 2020
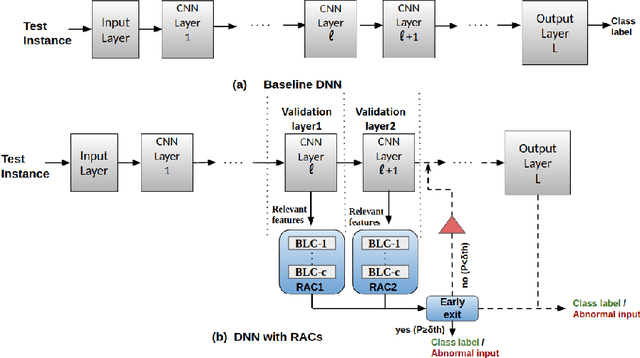
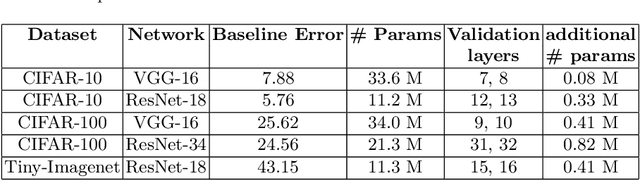
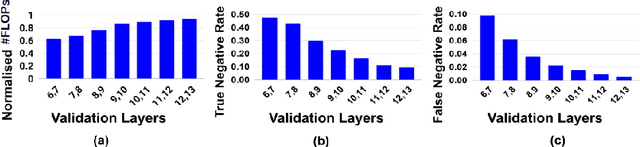
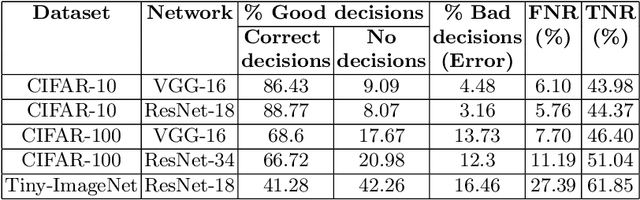
Deep neural networks have demonstrated state-of-the-art performance on many classification tasks. However, they have no inherent capability to recognize when their predictions are wrong. There have been several efforts in the recent past to detect natural errors but the suggested mechanisms pose additional energy requirements. To address this issue, we propose an ensemble of classifiers at hidden layers to enable energy efficient detection of natural errors. In particular, we append Relevant-features based Auxiliary Cells (RACs) which are class specific binary linear classifiers trained on relevant features. The consensus of RACs is used to detect natural errors. Based on combined confidence of RACs, classification can be terminated early, thereby resulting in energy efficient detection. We demonstrate the effectiveness of our technique on various image classification datasets such as CIFAR-10, CIFAR-100 and Tiny-ImageNet.
Personalized Taste and Cuisine Preference Modeling via Images
Feb 26, 2020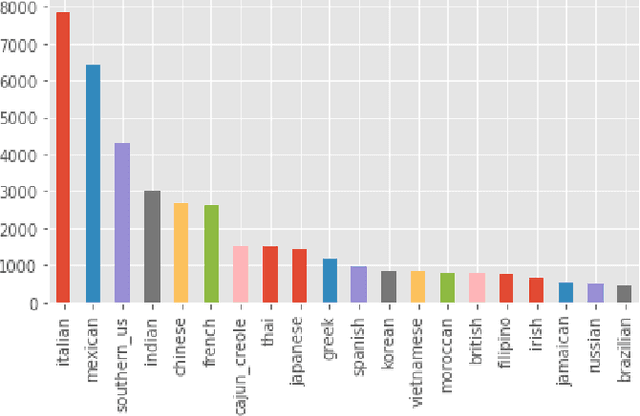
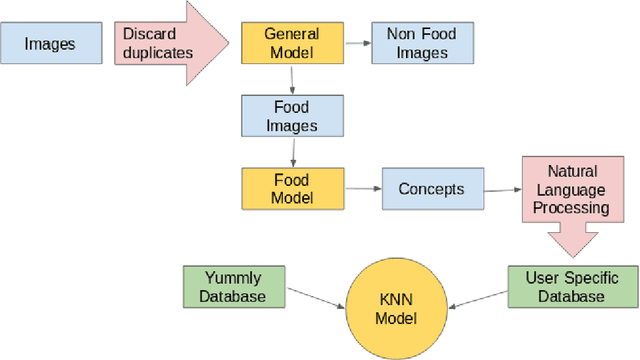
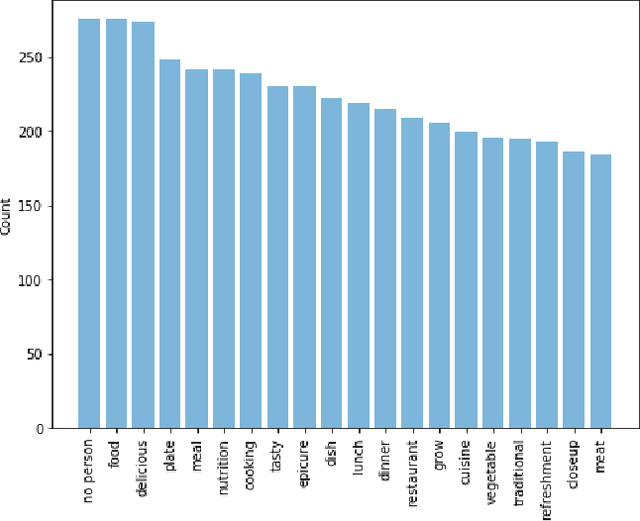
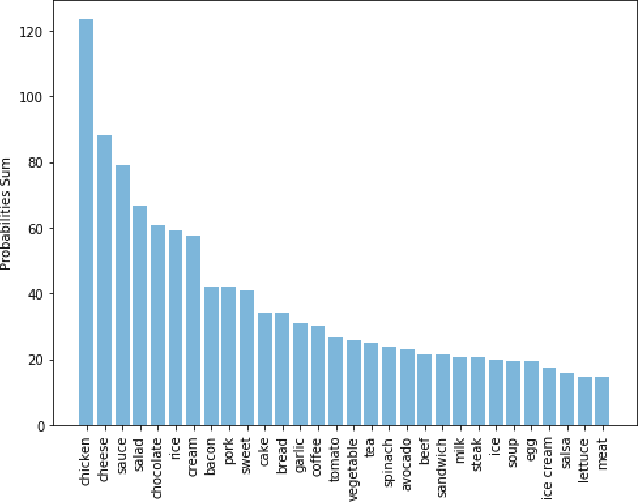
With the exponential growth in the usage of social media to share live updates about life, taking pictures has become an unavoidable phenomenon. Individuals unknowingly create a unique knowledge base with these images. The food images, in particular, are of interest as they contain a plethora of information. From the image metadata and using computer vision tools, we can extract distinct insights for each user to build a personal profile. Using the underlying connection between cuisines and their inherent tastes, we attempt to develop such a profile for an individual based solely on the images of his food. Our study provides insights about an individual's inclination towards particular cuisines. Interpreting these insights can lead to the development of a more precise recommendation system. Such a system would avoid the generic approach in favor of a personalized recommendation system.
Paving the Way for Image Understanding: A New Kind of Image Decomposition is Desired
Jul 22, 2005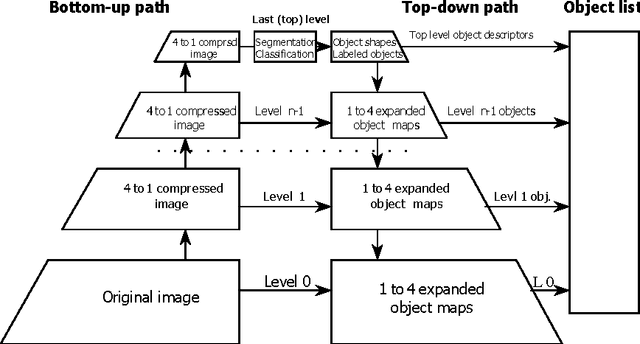



In this paper we present an unconventional image segmentation approach which is devised to meet the requirements of image understanding and pattern recognition tasks. Generally image understanding assumes interplay of two sub-processes: image information content discovery and image information content interpretation. Despite of its widespread use, the notion of "image information content" is still ill defined, intuitive, and ambiguous. Most often, it is used in the Shannon's sense, which means information content assessment averaged over the whole signal ensemble. Humans, however,rarely resort to such estimates. They are very effective in decomposing images into their meaningful constituents and focusing attention to the perceptually relevant image parts. We posit that following the latest findings in human attention vision studies and the concepts of Kolmogorov's complexity theory an unorthodox segmentation approach can be proposed that provides effective image decomposition to information preserving image fragments well suited for subsequent image interpretation. We provide some illustrative examples, demonstrating effectiveness of this approach.
* 14th Scandinavian Conference on Image Analysis (SCIA 2005)
Joint Detection and Tracking in Videos with Identification Features
May 25, 2020
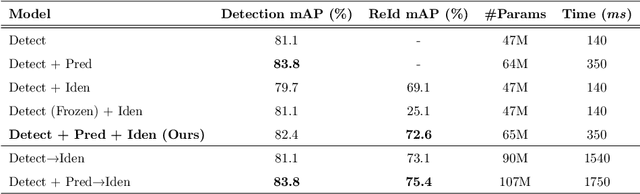
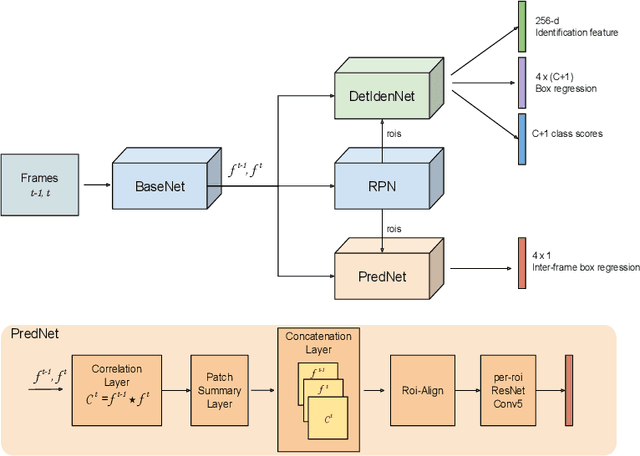
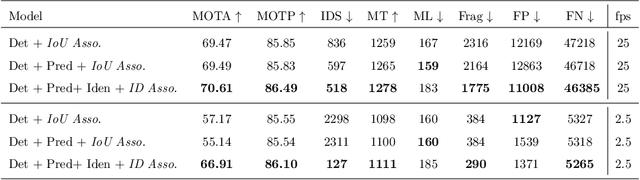
Recent works have shown that combining object detection and tracking tasks, in the case of video data, results in higher performance for both tasks, but they require a high frame-rate as a strict requirement for performance. This is assumption is often violated in real-world applications, when models run on embedded devices, often at only a few frames per second. Videos at low frame-rate suffer from large object displacements. Here re-identification features may support to match large-displaced object detections, but current joint detection and re-identification formulations degrade the detector performance, as these two are contrasting tasks. In the real-world application having separate detector and re-id models is often not feasible, as both the memory and runtime effectively double. Towards robust long-term tracking applicable to reduced-computational-power devices, we propose the first joint optimization of detection, tracking and re-identification features for videos. Notably, our joint optimization maintains the detector performance, a typical multi-task challenge. At inference time, we leverage detections for tracking (tracking-by-detection) when the objects are visible, detectable and slowly moving in the image. We leverage instead re-identification features to match objects which disappeared (e.g. due to occlusion) for several frames or were not tracked due to fast motion (or low-frame-rate videos). Our proposed method reaches the state-of-the-art on MOT, it ranks 1st in the UA-DETRAC'18 tracking challenge among online trackers, and 3rd overall.
Improving Neural Architecture Search Image Classifiers via Ensemble Learning
Mar 14, 2019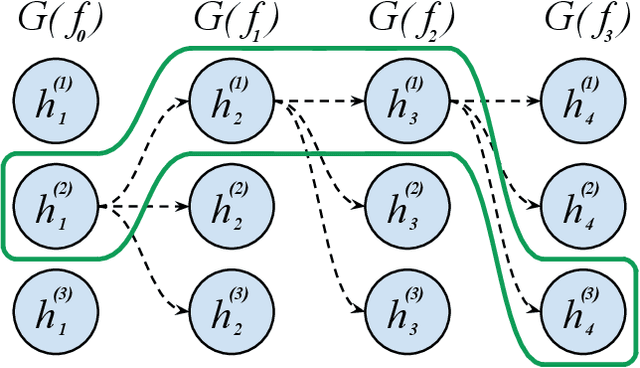
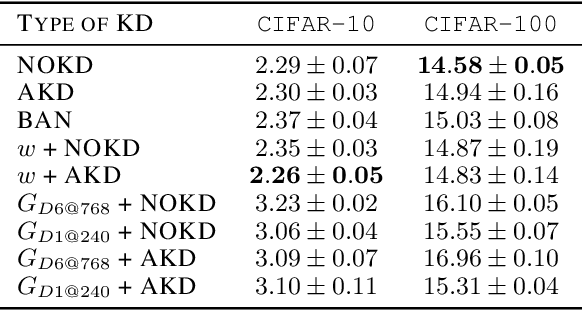
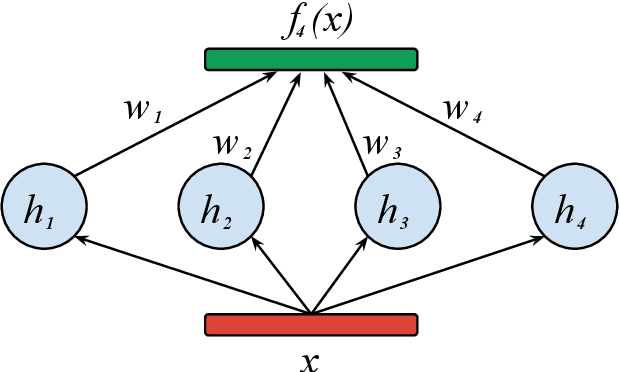
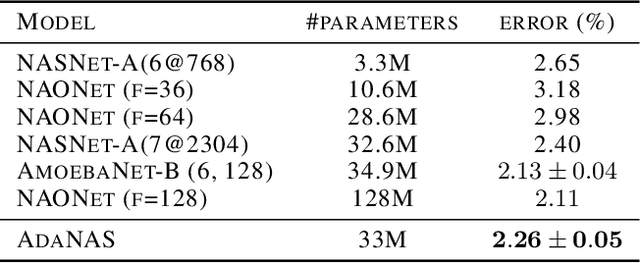
Finding the best neural network architecture requires significant time, resources, and human expertise. These challenges are partially addressed by neural architecture search (NAS) which is able to find the best convolutional layer or cell that is then used as a building block for the network. However, once a good building block is found, manual design is still required to assemble the final architecture as a combination of multiple blocks under a predefined parameter budget constraint. A common solution is to stack these blocks into a single tower and adjust the width and depth to fill the parameter budget. However, these single tower architectures may not be optimal. Instead, in this paper we present the AdaNAS algorithm, that uses ensemble techniques to compose a neural network as an ensemble of smaller networks automatically. Additionally, we introduce a novel technique based on knowledge distillation to iteratively train the smaller networks using the previous ensemble as a teacher. Our experiments demonstrate that ensembles of networks improve accuracy upon a single neural network while keeping the same number of parameters. Our models achieve comparable results with the state-of-the-art on CIFAR-10 and sets a new state-of-the-art on CIFAR-100.
Label-similarity Curriculum Learning
Nov 15, 2019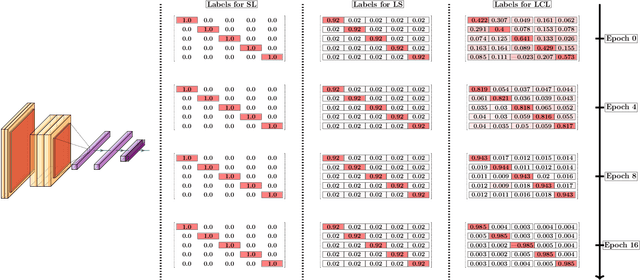
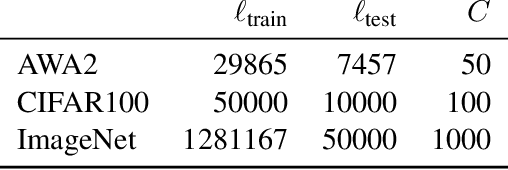
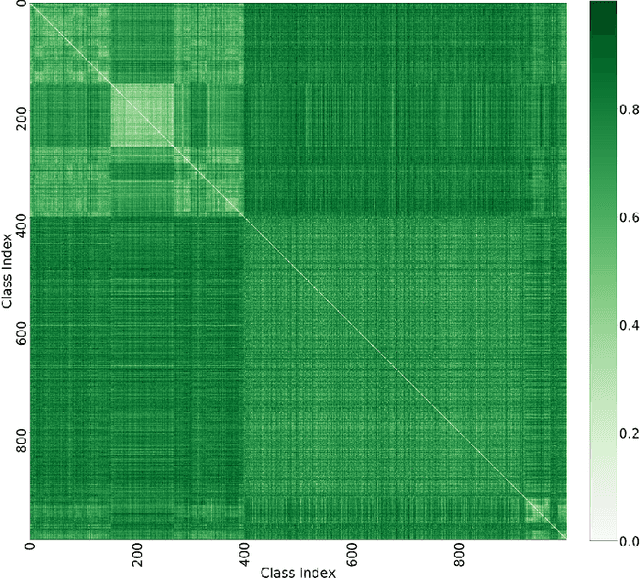

Curriculum learning can improve neural network training by guiding the optimization to desirable optima. We propose a novel curriculum learning approach for image classification that adapts the loss function by changing the label representation. The idea is to use a probability distribution over classes as target label, where the class probabilities reflect the similarity to the true class. Gradually, this label representation is shifted towards the standard one-hot-encoding. That is, in the beginning minor mistakes are corrected less than large mistakes, resembling a teaching process in which broad concepts are explained first before subtle differences are taught. The class similarity can be based on prior knowledge. For the special case of the labels being natural words, we propose a generic way to automatically compute the similarities. The natural words are embedded into Euclidean space using a standard word embedding. The probability of each class is then a function of the cosine similarity between the vector representations of the class and the true label. The proposed label-similarity curriculum learning (LCL) approach was empirically evaluated on several popular deep learning architectures for image classification task applied to three datasets, ImageNet, CIFAR100, and AWA2. In all scenarios, LCL was able to improve the classification accuracy on the test data compared to standard training.
Hcore-Init: Neural Network Initialization based on Graph Degeneracy
Apr 16, 2020



Neural networks are the pinnacle of Artificial Intelligence, as in recent years we witnessed many novel architectures, learning and optimization techniques for deep learning. Capitalizing on the fact that neural networks inherently constitute multipartite graphs among neuron layers, we aim to analyze directly their structure to extract meaningful information that can improve the learning process. To our knowledge graph mining techniques for enhancing learning in neural networks have not been thoroughly investigated. In this paper we propose an adapted version of the k-core structure for the complete weighted multipartite graph extracted from a deep learning architecture. As a multipartite graph is a combination of bipartite graphs, that are in turn the incidence graphs of hypergraphs, we design k-hypercore decomposition, the hypergraph analogue of k-core degeneracy. We applied k-hypercore to several neural network architectures, more specifically to convolutional neural networks and multilayer perceptrons for image recognition tasks after a very short pretraining. Then we used the information provided by the hypercore numbers of the neurons to re-initialize the weights of the neural network, thus biasing the gradient optimization scheme. Extensive experiments proved that k-hypercore outperforms the state-of-the-art initialization methods.
Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
Dec 10, 2019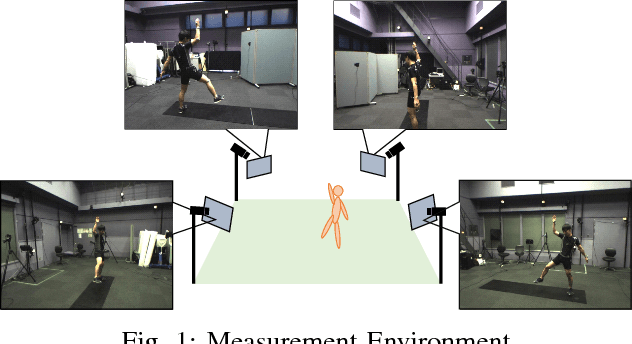

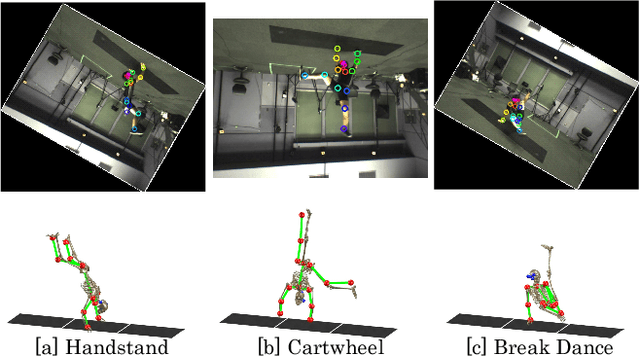
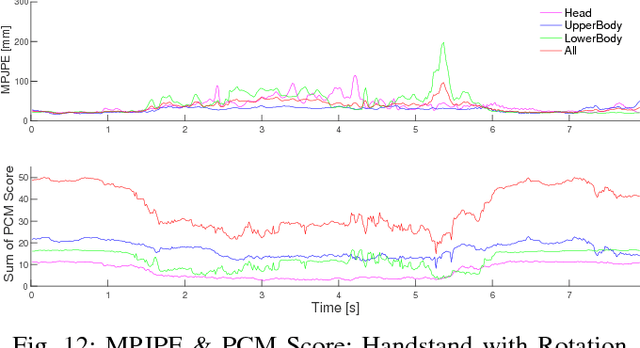
This paper discusses video motion capture, namely, 3D reconstruction of human motion from multi-camera images. After the Part Confidence Maps are computed from each camera image, the proposed spatiotemporal filter is applied to deliver the human motion data with accuracy and smoothness for human motion analysis. The spatiotemporal filter uses the human skeleton and mixes temporal smoothing in two-time inverse kinematics computations. The experimental results show that the mean per joint position error was 26.1mm for regular motions and 38.8mm for inverted motions.
Lending Orientation to Neural Networks for Cross-view Geo-localization
Mar 29, 2019
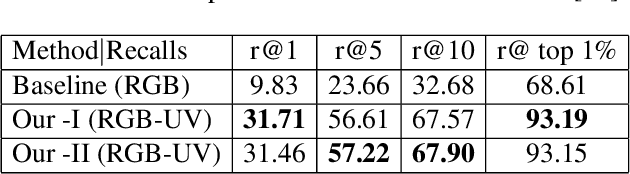
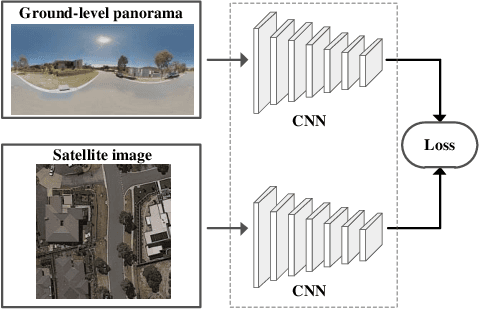

This paper studies image-based geo-localization (IBL) problem using ground-to-aerial cross-view matching. The goal is to predict the spatial location of a ground-level query image by matching it to a large geotagged aerial image database (e.g., satellite imagery). This is a challenging task due to the drastic differences in their viewpoints and visual appearances. Existing deep learning methods for this problem have been focused on maximizing feature similarity between spatially close-by image pairs, while minimizing other images pairs which are far apart. They do so by deep feature embedding based on visual appearance in those ground-and-aerial images. However, in everyday life, humans commonly use {\em orientation} information as an important cue for the task of spatial localization. Inspired by this insight, this paper proposes a novel method which endows deep neural networks with the `commonsense' of orientation. Given a ground-level spherical panoramic image as query input (and a large georeferenced satellite image database), we design a Siamese network which explicitly encodes the orientation (i.e., spherical directions) of each pixel of the images. Our method significantly boosts the discriminative power of the learned deep features, leading to a much higher recall and precision outperforming all previous methods. Our network is also more compact using only 1/5th number of parameters than a previously best-performing network. To evaluate the generalization of our method, we also created a large-scale cross-view localization benchmark containing 100K geotagged ground-aerial pairs covering a city. Our codes and datasets are available at \url{https://github.com/Liumouliu/OriCNN}.