 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Relation-aware Graph Attention Network for Visual Question Answering
Mar 29, 2019
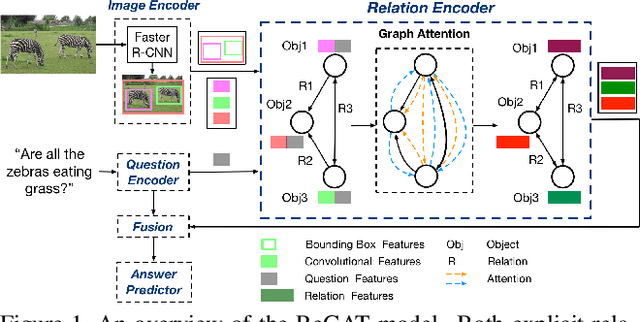

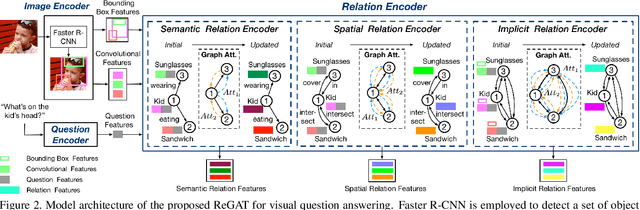
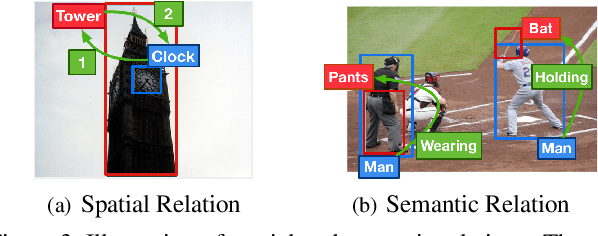
In order to answer semantically-complicated questions about an image, a Visual Question Answering (VQA) model needs to fully understand the visual scene in the image, especially the interactive dynamics between different objects. We propose a Relation-aware Graph Attention Network (ReGAT), which encodes each image into a graph and models multi-type inter-object relations via a graph attention mechanism, to learn question-adaptive relation representations. Two types of visual object relations are explored: (i) Explicit Relations that represent geometric positions and semantic interactions between objects; and (ii) Implicit Relations that capture the hidden dynamics between image regions. Experiments demonstrate that ReGAT outperforms prior state-of-the-art approaches on both VQA 2.0 and VQA-CP v2 datasets. We further show that ReGAT is compatible to existing VQA architectures, and can be used as a generic relation encoder to boost the model performance for VQA.
Gimme Signals: Discriminative signal encoding for multimodal activity recognition
Mar 13, 2020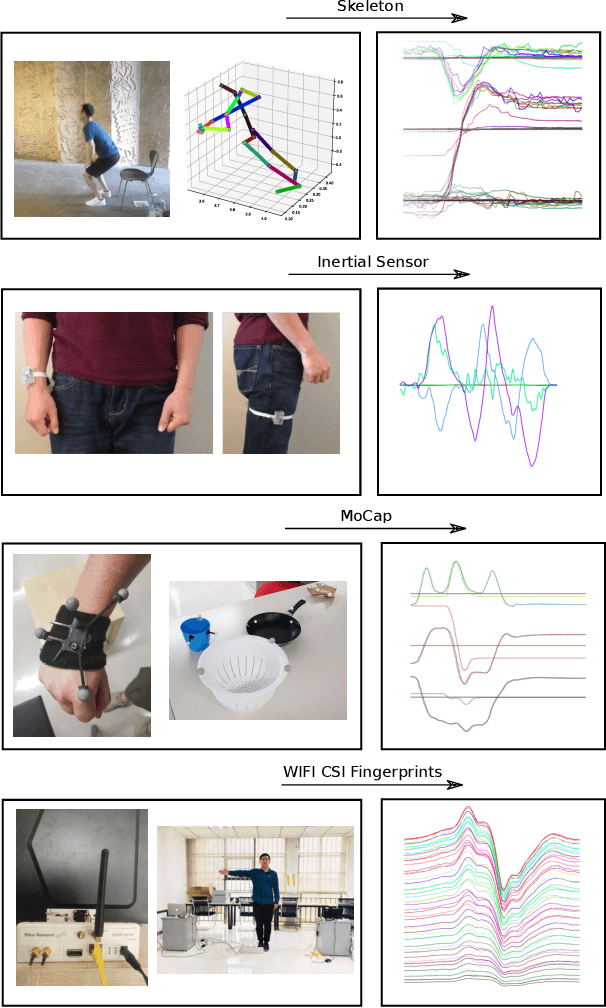
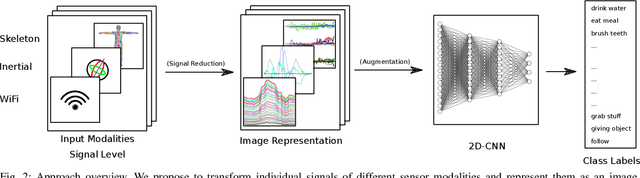
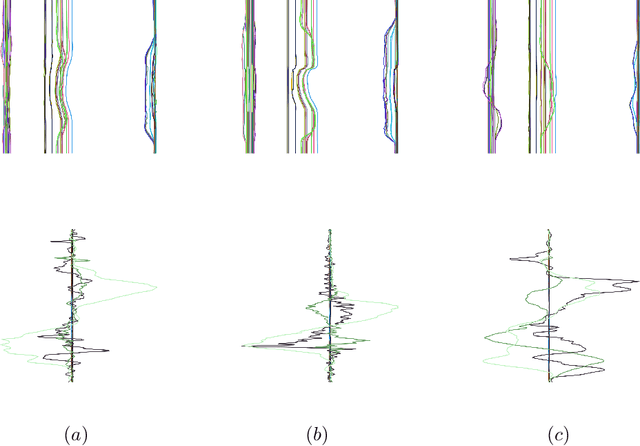

We present a simple, yet effective and flexible method for action recognition supporting multiple sensor modalities. Multivariate signal sequences are encoded in an image and are then classified using a recently proposed EfficientNet CNN architecture. Our focus was to find an approach that generalizes well across different sensor modalities without specific adaptions while still achieving good results. We apply our method to 4 action recognition datasets containing skeleton sequences, inertial and motion capturing measurements as well as \wifi fingerprints that range up to 120 action classes. Our method defines the current best CNN-based approach on the NTU RGB+D 120 dataset, lifts the state of the art on the ARIL Wi-Fi dataset by +6.78%, improves the UTD-MHAD inertial baseline by +14.4%, the UTD-MHAD skeleton baseline by 1.13% and achieves 96.11% on the Simitate motion capturing data (80/20 split). We further demonstrate experiments on both, modality fusion on a signal level and signal reduction to prevent the representation from overloading.
A fast and memory-efficient algorithm for smooth interpolation of polyrigid transformations: application to human joint tracking
Jun 02, 2020

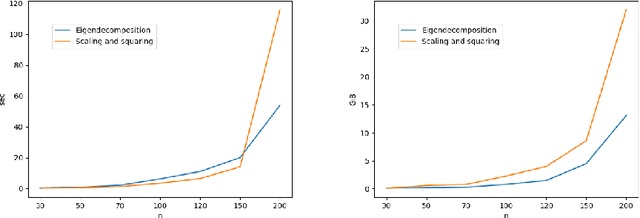
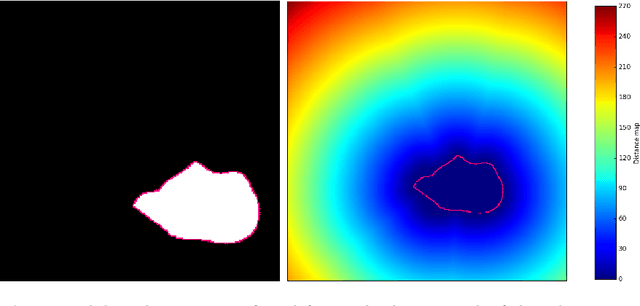
The log Euclidean polyrigid registration framework provides a way to smoothly estimate and interpolate poly-rigid/affine transformations for which the invertibility is guaranteed. This powerful and flexible mathematical framework is currently being used to track the human joint dynamics by first imposing bone rigidity constraints in order to synthetize the spatio-temporal joint deformations later. However, since no closed-form exists, then a computationally expensive integration of ordinary differential equations (ODEs) is required to perform image registration using this framework. To tackle this problem, the exponential map for solving these ODEs is computed using the scaling and squaring method in the literature. In this paper, we propose an algorithm using a matrix diagonalization based method for smooth interpolation of homogeneous polyrigid transformations of human joints during motion. The use of this alternative computational approach to integrate ODEs is well motivated by the fact that bone rigid transformations satisfy the mechanical constraints of human joint motion, which provide conditions that guarantee the diagonalizability of local bone transformations and consequently of the resulting joint transformations. In a comparison with the scaling and squaring method, we discuss the usefulness of the matrix eigendecomposition technique which reduces significantly the computational burden associated with the computation of matrix exponential over a dense regular grid. Finally, we have applied the method to enhance the temporal resolution of dynamic MRI sequences of the ankle joint. To conclude, numerical experiments show that the eigendecomposition method is more capable of balancing the trade-off between accuracy, computation time, and memory requirements.
Is There Tradeoff between Spatial and Temporal in Video Super-Resolution?
Mar 13, 2020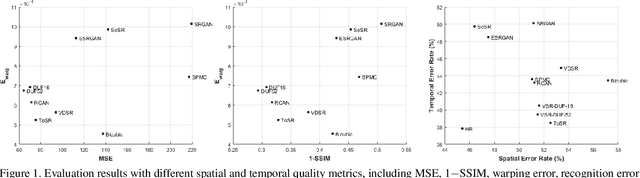
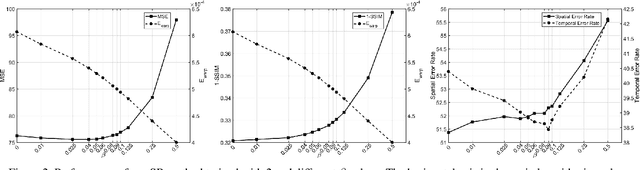
Recent advances of deep learning lead to great success of image and video super-resolution (SR) methods that are based on convolutional neural networks (CNN). For video SR, advanced algorithms have been proposed to exploit the temporal correlation between low-resolution (LR) video frames, and/or to super-resolve a frame with multiple LR frames. These methods pursue higher quality of super-resolved frames, where the quality is usually measured frame by frame in e.g. PSNR. However, frame-wise quality may not reveal the consistency between frames. If an algorithm is applied to each frame independently (which is the case of most previous methods), the algorithm may cause temporal inconsistency, which can be observed as flickering. It is a natural requirement to improve both frame-wise fidelity and between-frame consistency, which are termed spatial quality and temporal quality, respectively. Then we may ask, is a method optimized for spatial quality also optimized for temporal quality? Can we optimize the two quality metrics jointly?
A2D2: Audi Autonomous Driving Dataset
Apr 14, 2020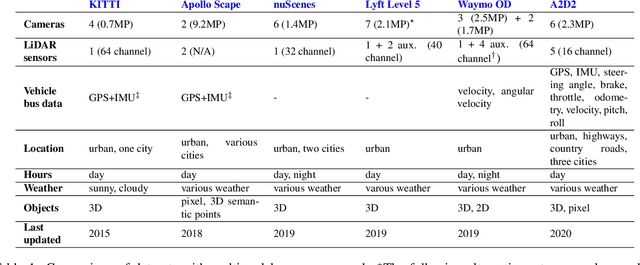



Research in machine learning, mobile robotics, and autonomous driving is accelerated by the availability of high quality annotated data. To this end, we release the Audi Autonomous Driving Dataset (A2D2). Our dataset consists of simultaneously recorded images and 3D point clouds, together with 3D bounding boxes, semantic segmentation, instance segmentation, and data extracted from the automotive bus. Our sensor suite consists of six cameras and five LiDAR units, providing full 360 degree coverage. The recorded data is time synchronized and mutually registered. Annotations are for non-sequential frames: 41,277 frames with semantic segmentation image and point cloud labels, of which 12,497 frames also have 3D bounding box annotations for objects within the field of view of the front camera. In addition, we provide 392,556 sequential frames of unannotated sensor data for recordings in three cities in the south of Germany. These sequences contain several loops. Faces and vehicle number plates are blurred due to GDPR legislation and to preserve anonymity. A2D2 is made available under the CC BY-ND 4.0 license, permitting commercial use subject to the terms of the license. Data and further information are available at http://www.a2d2.audi.
A New Model of Array Grammar for generating Connected Patterns on an Image Neighborhood
Jul 31, 2014Study of patterns on images is recognized as an important step in characterization and classification of image. The ability to efficiently analyze and describe image patterns is thus of fundamental importance. The study of syntactic methods of describing pictures has been of interest for researchers. Array Grammars can be used to represent and recognize connected patterns. In any image the patterns are recognized using connected patterns. It is very difficult to represent all connected patterns (CP) even on a small 3 x 3 neighborhood in a pictorial way. The present paper proposes the model of array grammar capable of generating any kind of simple or complex pattern and derivation of connected pattern in an image neighborhood using the proposed grammar is discussed.
PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module
Nov 14, 2019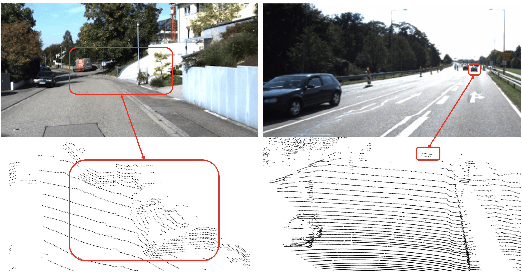
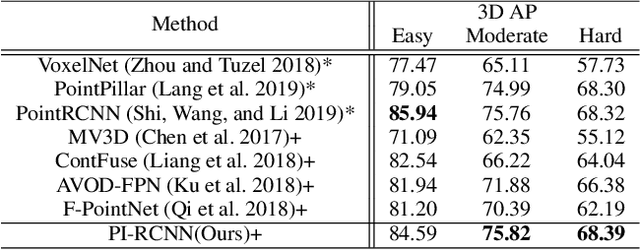
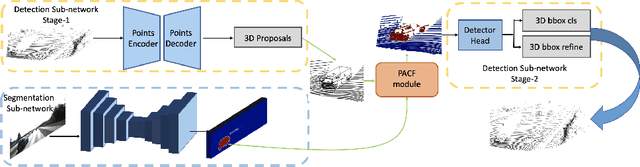
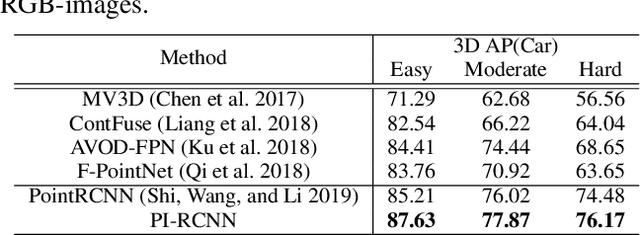
LIDAR point clouds and RGB-images are both extremely essential for 3D object detection. So many state-of-the-art 3D detection algorithms dedicate in fusing these two types of data effectively. However, their fusion methods based on Birds Eye View (BEV) or voxel format are not accurate. In this paper, we propose a novel fusion approach named Point-based Attentive Cont-conv Fusion(PACF) module, which fuses multi-sensor features directly on 3D points. Except for continuous convolution, we additionally add a Point-Pooling and an Attentive Aggregation to make the fused features more expressive. Moreover, based on the PACF module, we propose a 3D multi-sensor multi-task network called Pointcloud-Image RCNN(PI-RCNN as brief), which handles the image segmentation and 3D object detection tasks. PI-RCNN employs a segmentation sub-network to extract full-resolution semantic feature maps from images and then fuses the multi-sensor features via powerful PACF module. Beneficial from the effectiveness of the PACF module and the expressive semantic features from the segmentation module, PI-RCNN can improve much in 3D object detection. We demonstrate the effectiveness of the PACF module and PI-RCNN on the KITTI 3D Detection benchmark, and our method can achieve state-of-the-art on the metric of 3D AP.
Deep Face Super-Resolution with Iterative Collaboration between Attentive Recovery and Landmark Estimation
Mar 29, 2020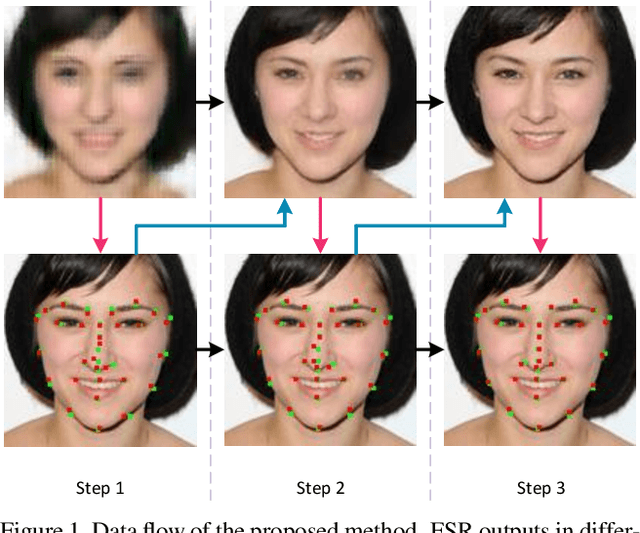
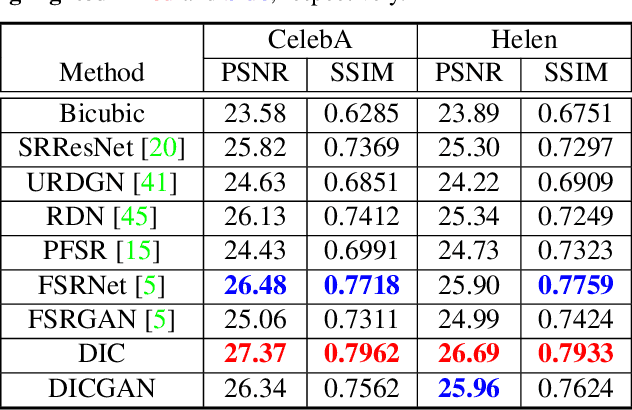
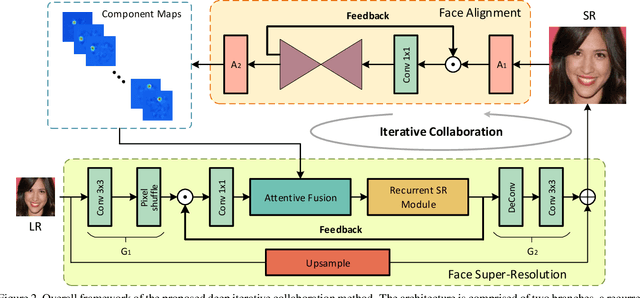
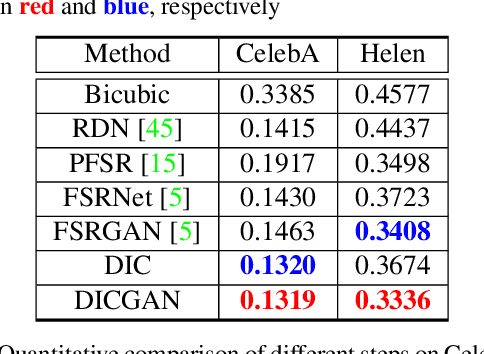
Recent works based on deep learning and facial priors have succeeded in super-resolving severely degraded facial images. However, the prior knowledge is not fully exploited in existing methods, since facial priors such as landmark and component maps are always estimated by low-resolution or coarsely super-resolved images, which may be inaccurate and thus affect the recovery performance. In this paper, we propose a deep face super-resolution (FSR) method with iterative collaboration between two recurrent networks which focus on facial image recovery and landmark estimation respectively. In each recurrent step, the recovery branch utilizes the prior knowledge of landmarks to yield higher-quality images which facilitate more accurate landmark estimation in turn. Therefore, the iterative information interaction between two processes boosts the performance of each other progressively. Moreover, a new attentive fusion module is designed to strengthen the guidance of landmark maps, where facial components are generated individually and aggregated attentively for better restoration. Quantitative and qualitative experimental results show the proposed method significantly outperforms state-of-the-art FSR methods in recovering high-quality face images.
Event-based visual place recognition with ensembles of spatio-temporal windows
May 22, 2020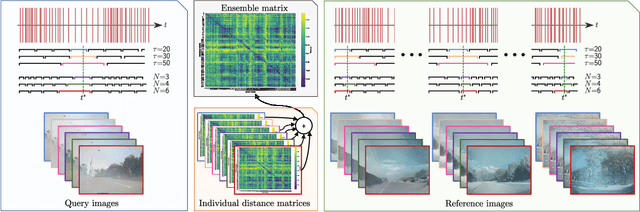


Event cameras are bio-inspired sensors capable of providing a continuous stream of events with low latency and high dynamic range. As a single event only carries limited information about the brightness change at a particular pixel, events are commonly accumulated into spatio-temporal windows for further processing. However, the optimal window length varies depending on the scene, camera motion, the task being performed, and other factors. In this research, we develop a novel ensemble-based scheme for combining spatio-temporal windows of varying lengths that are processed in parallel. For applications where the increased computational requirements of this approach are not practical, we also introduce a new "approximate" ensemble scheme that achieves significant computational efficiencies without unduly compromising the original performance gains provided by the ensemble approach. We demonstrate our ensemble scheme on the visual place recognition (VPR) task, introducing a new Brisbane-Event-VPR dataset with annotated recordings captured using a DAVIS346 color event camera. We show that our proposed ensemble scheme significantly outperforms all the single-window baselines and conventional model-based ensembles, irrespective of the image reconstruction and feature extraction methods used in the VPR pipeline, and evaluate which ensemble combination technique performs best. These results demonstrate the significant benefits of ensemble schemes for event camera processing in the VPR domain and may have relevance to other related processes, including feature tracking, visual-inertial odometry, and steering prediction in driving.
Rethinking the CSC Model for Natural Images
Sep 12, 2019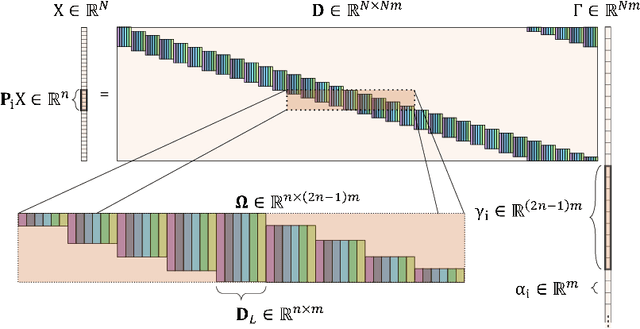
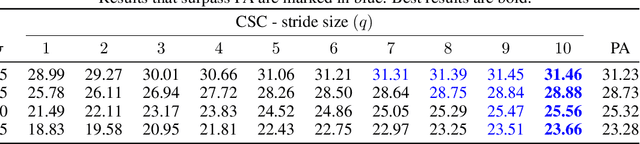
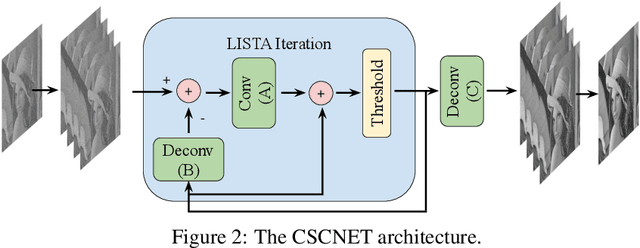
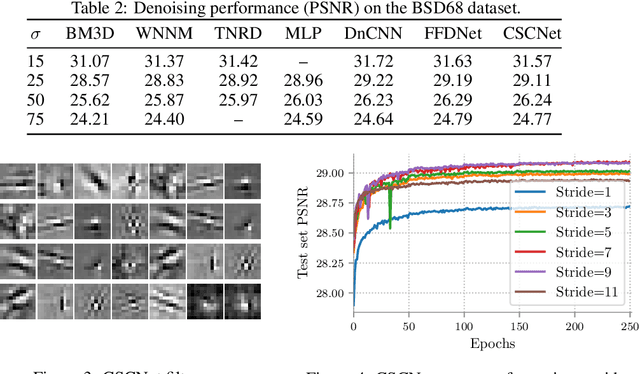
Sparse representation with respect to an overcomplete dictionary is often used when regularizing inverse problems in signal and image processing. In recent years, the Convolutional Sparse Coding (CSC) model, in which the dictionary consists of shift-invariant filters, has gained renewed interest. While this model has been successfully used in some image processing problems, it still falls behind traditional patch-based methods on simple tasks such as denoising. In this work we provide new insights regarding the CSC model and its capability to represent natural images, and suggest a Bayesian connection between this model and its patch-based ancestor. Armed with these observations, we suggest a novel feed-forward network that follows an MMSE approximation process to the CSC model, using strided convolutions. The performance of this supervised architecture is shown to be on par with state of the art methods while using much fewer parameters.